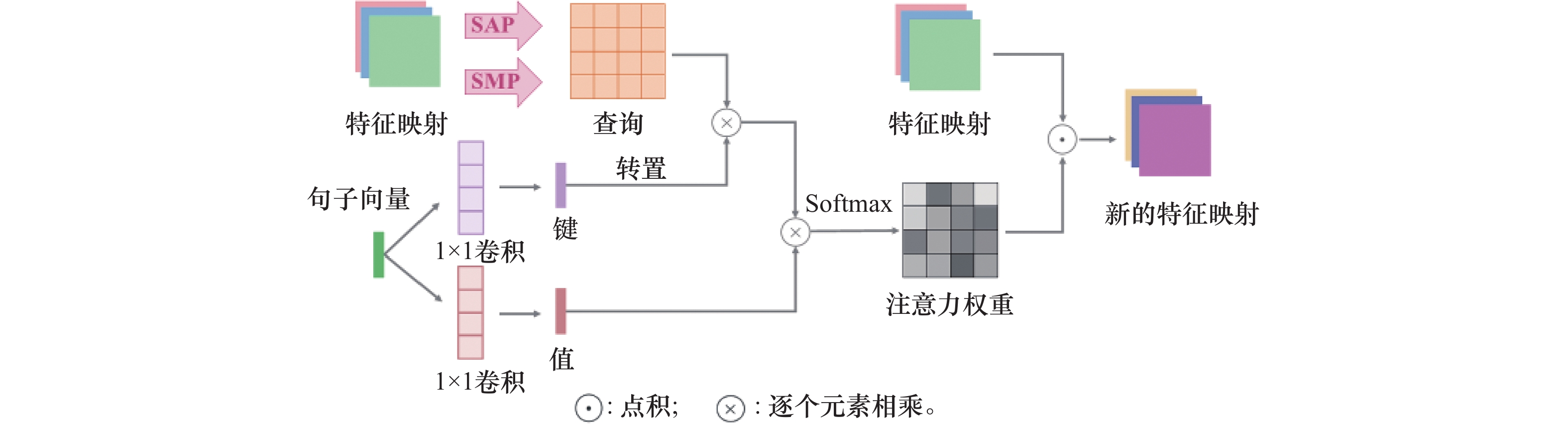
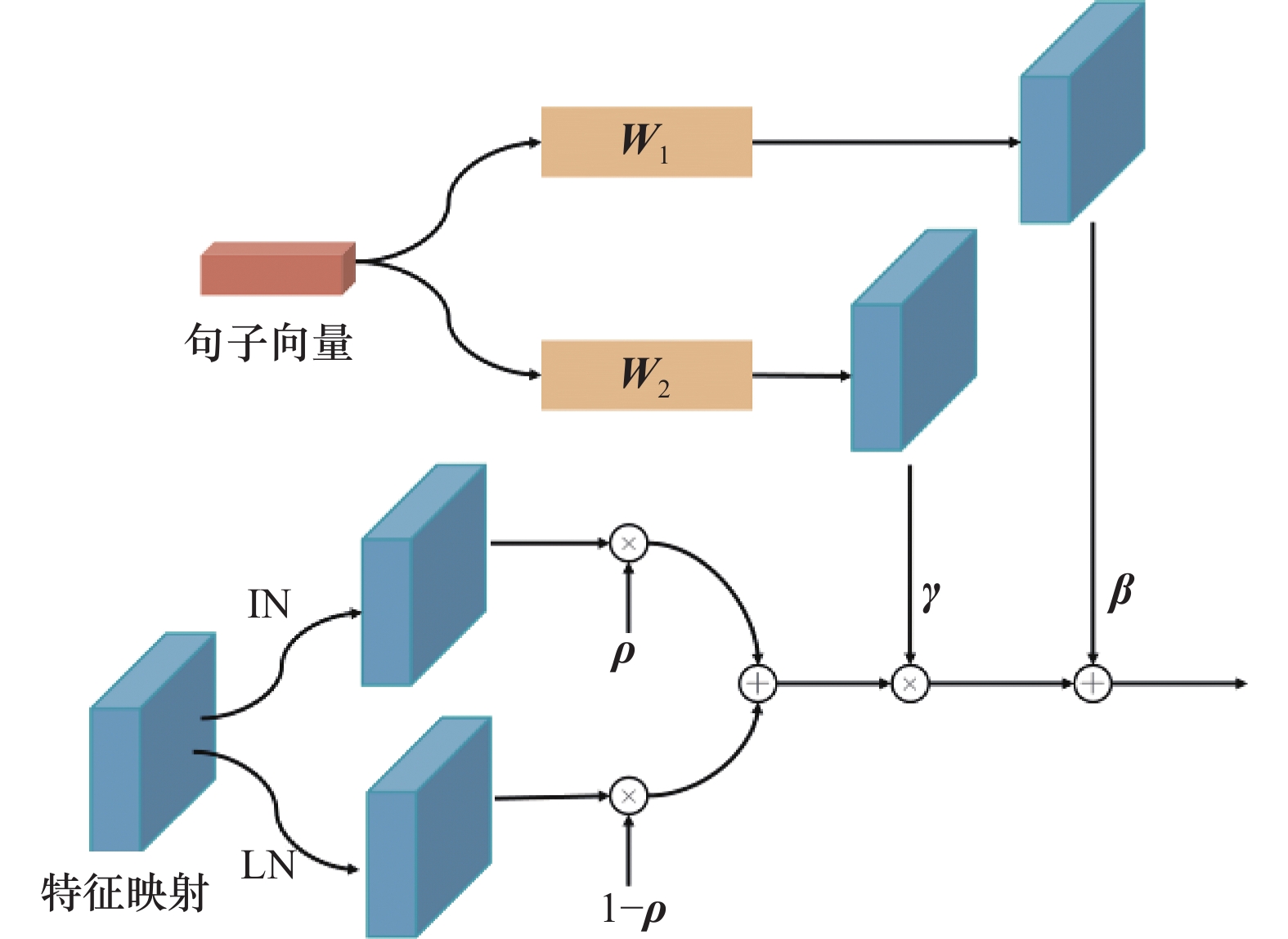
| 1 |
LI B W, QI X J, LUKASIEWICZ T, et al. Controllable text-to-image generation[C]//Proc. of the Advances in Neural Information Processing Systems, 2019: 2065−2075.
|
| 2 |
MA S, FU J, CHEN C W, et al. DA-GAN: instance-level image translation by deep attention generative adversarial networks[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2018: 5657−5666.
|
| 3 |
QIAO T T, ZHANG J, XU D Q, et al. MirrorGAN: learning text-toimage generation by redescription[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2019: 1505−1514.
|
| 4 |
XU T, ZHANG P C, HUANG Q Y, et al. AttnGAN: fine-grained text to image generation with attentional generative adversarial networks[C]// Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2018: 1316−1324.
|
| 5 |
YUAN M, PENG Y. Text-to-image synthesis via symmetrical distillation networks[C]//Proc. of the 26th ACM International Conference on Multimedia, 2018: 1407−1415.
|
| 6 |
ZHANG H, XU T, LI H S, et al. StackGAN++: realistic image synthesis with stacked generative adversarial networks[J]. IEEE Trans. on Pattern Analysis and Machine Intelligence, 2018, 41 (8): 1947- 1962.
|
| 7 |
TAO M, TANG H, WU S S, et al. DF-GAN: deep fusion generative adversarial networks for text-to-image synthesis[EB/OL]. [2025-03-01]. https://arxiv.org/abs/2008.05865v1.
|
| 8 |
ZHANG Z , SCHOMAKER L. DiverGAN: an efficient and effective single-stage framework for diverse text-to-image generation[J]. Neurocomputing, 2022, 473, 182- 198.
doi: 10.1016/j.neucom.2021.12.005
|
| 9 |
IOFFE S, SZEGEDY C. Batch normalization: accelerating deep network training by reducing internal covariate shift[C]//Proc. of the International Conference on Machine Learning, 2015: 448–456.
|
| 10 |
WAH C, BRANSON S, WELINDER P, et al. The Caltech UCSD Birds-200-2011 dataset [J]. California Institute of Technology, 2011: 16119123.
|
| 11 |
LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context[C]//Proc. of the European Conference on Computer Vision, 2014: 740–755.
|
| 12 |
刘戎翔, 吴琳, 谢智歌, 等. 基于生成对抗网络的防空体系态势辅助分析[J]. 系统工程与电子技术, 2022, 44 (8): 2522- 2529.
|
|
LIU R X , WU L, XIE Z G , et al. Auxiliary situation analysis for air defense system based on generative adversarial network[J]. Systems Engineering and Electronics, 2022, 44 (8): 2522- 2529.
|
| 23 |
马兰, 孟诗君, 吴志军. 基于BERT与生成对抗的民航陆空通话意图挖掘[J]. 系统工程与电子技术, 2024, 46 (2): 740- 750.
|
|
MA L, MENG S J , WU Z J. Intention mining for civil aviation radiotelephony communication based on BERT and generative adversarial[J]. Systems Engineering and Electronics, 2024, 46 (2): 740- 750.
|
| 24 |
田相轩, 石志强. 基于改进型生成对抗网络的指挥信息系统模拟数据生成算法[J]. 系统工程与电子技术, 2021, 43 (1): 163- 170.
|
|
TIAN X X, SHI Z Q. Simulation data generation algorithm based on evolutional generative adversarial networks for command information system[J]. Systems Engineering and Electronics, 2021, 43 (1): 163- 170.
|
| 25 |
邵凯, 朱苗苗, 王光宇. 基于生成对抗与卷积神经网络的调制识别方法[J]. 系统工程与电子技术, 2022, 44 (3): 1036- 1043.
|
|
SHAO K , ZHU M M , WANG G Y. Modulation recognition method based on generative adversarial andconvolutional neural network[J]. Systems Engineering and Electronics, 2022, 44 (3): 1036- 1043.
|
| 26 |
胡涛. 基于生成对抗网络的文本描述图像生成研究[D]. 合肥: 中国科学技术大学, 2021.
|
|
HU T . Research on text-to-image generation based on generative adversarial networks[D]. Hefei: University of Science and Technology of China, 2021.
|
| 13 |
KINGMA D P, BA J. Adam: a method for stochastic optimization[C]//Proc. of the International Conference on Learning Representations, 2015.
|
| 14 |
陈丽, 方梓涵, 梅立泉. 基于GAN的直扩信号生成算法[J]. 系统工程与电子技术, 2023, 45 (5): 1544- 1552.
|
|
CHEN L, FANG Z H, MEI L Q. DSS signal generation algorithm based on GAN[J]. Systems Engineering and Electronics, 2023, 45 (5): 1544- 1552.
|
| 15 |
SALIMANS T, GOODFELLOW I, ZAREMBA W, et al. Improved techniques for training GANs[C]//Proc. of the Advances in Neural Information Processing Systems, 2016: 2234–2242.
|
| 16 |
SZEGEDY C, VANHOUCKE V, IOFFE S, et al. Rethinking the inception architecture for computer vision[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2016: 2818–2826.
|
| 17 |
LI W B, ZHANG P C, ZHANG L, et al. Object driven text-to-image synthesis via adversarial training[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2019: 12174−12182.
|
| 18 |
ZHU M F, PAN P B, CHEN W, et al. DM-GAN: dynamic memory generative adversarial networks for text-to-image synthesis[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2019: 5802−5810.
|
| 19 |
ZHANG Z X , SCHOMAKER L. Optimizing and interpreting the latent space of the conditional text-to-image GANs[J]. Neural Comput & Applic, 2024, 36, 2549- 2572.
|
| 20 |
ZHANG Z X , SCHOMAKER L. Fusion-s2igan: an efficient and effective single-stage framework for speech-to-image generation[J]. Neural Comput & Applic, 2024, 36, 10567- 10584.
|
| 21 |
GAFNI O, POLYAK A, ASHUAL O, et al. Make-a-scene: scene-based text-to-image generation with human priors[C]//Proc. of the Computer Vision, 2022: 89-106.
|
| 22 |
RAMESH A, DHARIWAL P, NICHOL A, et al. Hierarchical text-conditional image generation with clip latents.[EB/OL]. [2025-03-01]. https://arxiv.org/pdf/2204.06125.
|

 ), 杨任农, 李永林, 左家亮, 胡利平, 陈双艳
), 杨任农, 李永林, 左家亮, 胡利平, 陈双艳