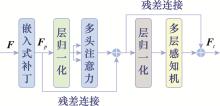
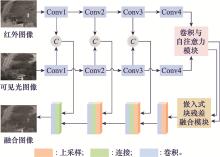
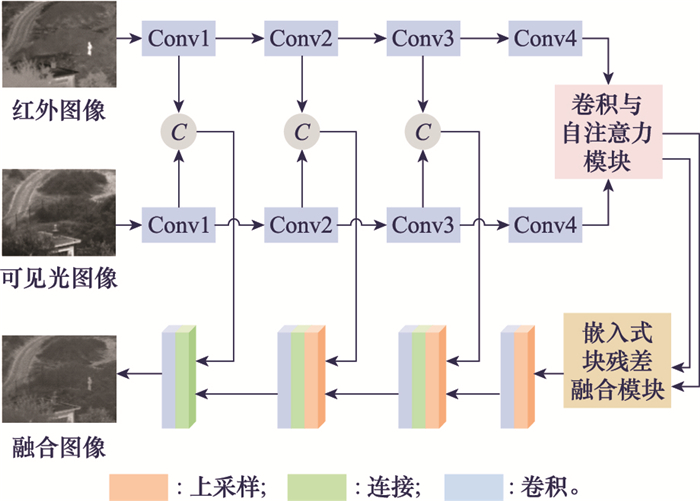
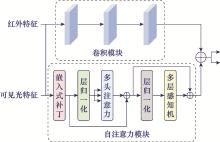
| 1 |
李舒涵, 许宏科, 武治宇. 基于红外与可见光图像融合的交通标志检测[J]. 现代电子技术, 2020, 43 (3): 45- 49.
|
|
LI S H , XU H K , WU Z Y . Traffic sign detection based on infrared and visible image fusion[J]. Modern Electronics Technique, 2020, 43 (3): 45- 49.
|
| 2 |
BIKASH M , SANJAY A , RUTUPARNA P , et al. A survey on region based imagefusion methods[J]. Information Fusion, 2019, 48, 119- 132.
doi: 10.1016/j.inffus.2018.07.010
|
| 3 |
李霖, 王红梅, 李辰凯. 红外与可见光图像深度学习融合方法综述[J]. 红外与激光工程, 2022, 51 (12): 337- 356.
|
|
LI L , WANG H M , LI C K . A review of deep learning fusion methods for infrared and visible images[J]. Infrared and Laser Engineering, 2022, 51 (12): 337- 356.
|
| 4 |
王新赛, 冯小二, 李明明. 基于能量分割的空间域图像融合算法研究[J]. 红外技术, 2022, 44 (7): 726- 731.
|
|
WANG X S , FENG X E , LI M M . Research on spatial domain image fusion algorithm based on energy segmentation[J]. Infrared Technology, 2022, 44 (7): 726- 731.
|
| 5 |
LIU Y , CHEN X , PENG H , et al. Multi-focus image fusion with a deep convolutional neural network[J]. Information Fusion, 2017, 36, 191- 207.
doi: 10.1016/j.inffus.2016.12.001
|
| 6 |
RAM P K, SAI S V, VENKATESH B R. DeepFuse: a deep unsupervised approach for exposure fusion with extreme exposure image pairs[C]//Proc. of the IEEE International Conference on Computer Vision, 2017: 4714-4722.
|
| 7 |
MA J Y , YU W , LIANG P W , et al. FusionGAN: a generative adversarial network for infrared and visible image fusion[J]. Information Fusion, 2019, 48, 11- 26.
doi: 10.1016/j.inffus.2018.09.004
|
| 8 |
XU H, MA J Y, LE Z L, et al. FusionDN: a unified densely connected network for image fusion[C]//Proc. of the AAAI Conference on Artificial Intelligence, 2020: 12484-12491
|
| 9 |
XIAO B , XU B C , BI X L , et al. Global-feature encoding U-Net (GEU-Net) for multi-focus image fusion[J]. IEEE Trans. on Image Processing, 2021, 30, 163- 175.
doi: 10.1109/TIP.2020.3033158
|
| 10 |
FANG Y M , YAN J B , LI L D , et al. No reference quality assessment for screen content images with both local and global feature representation[J]. IEEE Trans. on Image Processing, 2018, 27 (4): 1600- 1610.
doi: 10.1109/TIP.2017.2781307
|
| 11 |
QU L H, LIU S L, WANG M N, et al. TransMEF: a transformer-based multi-exposure image fusion framework using self-supervised multi-task learning[C]//Proc. of the AAAI Conference on Artificial Intelligence, 2022: 2126-2134.
|
| 12 |
MA J Y , TANG L F , FAN F , et al. SwinFusion: cross-domain long-range learning for general image fusion via swin transformer[J]. IEEE/CAA Journal of Automatica Sinica, 2022, 9 (7): 1200- 1217.
doi: 10.1109/JAS.2022.105686
|
| 13 |
TANG W , HE F Z , LIU Y , et al. DATFuse: infrared and visible image fusion via dual attention transformer[J]. IEEE Trans. on Circuits and System for Video Technology, 2023, 33 (7): 3159- 3172.
doi: 10.1109/TCSVT.2023.3234340
|
| 14 |
PENG Z L, HUANG W, GU S Z, et al. Conformer: local features coupling global representations for visual recognition[C]//Proc. of the IEEE/CVF International Conference on Computer Vision, 2021: 367-376.
|
| 15 |
WANG J X , XI X L , LI D M , et al. FusionGRAM: an infrared and visible image fusion framework based on gradient residual and attention mechanism[J]. IEEE Trans. on Instrumentation and Measurement, 2023, 72, 5005412.
|
| 16 |
QIU Y J, WANG R X, TAO D P, et al. Embedded block residual network: a recursive restoration model for single-image super-resolution[C]//Proc. of the IEEE/CVF International Conference on Computer Vision, 2019: 4179-4188.
|
| 17 |
TOET A . The TNO multiband image data collection[J]. Data in Brief, 2017, 15, 249- 251.
doi: 10.1016/j.dib.2017.09.038
|
| 18 |
JIA X Y, ZHU C, LI M Z, et al. LLVIP: a visible-infrared paired dataset for low-light vision[C]//Proc. of the IEEE International Conference on Computer Vision, 2021: 3496-3504.
|
| 19 |
LIU J Y, FAN X, HUANG Z B, et al. Target-aware dual adversarial learning and a multi-scenario multi-modality benchmark to fuse infrared and visible for object detection[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022: 5802-5811.
|
| 20 |
EMADALDEN A, UZAIR A B, HUANG M X, et al. Image fusion based on discrete cosine transform with high compression[C]//Proc. of the 7th International Conference on Signal and Image Processing, 2022: 606-610.
|
| 21 |
ZHU Z Q , ZHENG M Y , QI G Q , et al. A phase congruency and local laplacian energy based multi-modality medical image fusion method in NSCT domain[J]. IEEE Access, 2019, 7, 20811- 20824.
doi: 10.1109/ACCESS.2019.2898111
|
| 22 |
GUO H, CHEN J Y, YANG X, et al. Visible-infrared image fusion based on double-density wavelet and thermal exchange optimization[C]//Proc. of the IEEE 5th Advanced Information Technology, Electronic and Automation Control Conference, 2021: 2151-2154.
|
| 23 |
NAIDU VPS . Image fusion technique using multi-resolution singular value decomposition[J]. Defence Science Journal, 2011, 61, 479- 484.
doi: 10.14429/dsj.61.705
|
| 24 |
MA J Y , CHEN C , LI C , et al. Infrared and visible image fusion via gradient transfer and total variation minimization[J]. Information Fusion, 2016, 31, 100- 109.
doi: 10.1016/j.inffus.2016.02.001
|
| 25 |
LI H , WU X J . DenseFuse: a fusion approach to infrared and visible images[J]. IEEE Trans. on Image Processing, 2019, 28 (5): 2614- 2623.
doi: 10.1109/TIP.2018.2887342
|
| 26 |
XU H , MA J Y , JIANG J J , et al. U2Fusion: a unified unsupervised image fusion network[J]. IEEE Trans. on Pattern Analysis and Machine Intelligence, 2022, 44 (1): 502- 518.
doi: 10.1109/TPAMI.2020.3012548
|
| 27 |
LIU W, DRAGOMIR A, DUMITRU E, et al. SSD: single shot multibox detector[C]//Proc. of the European Conference on Computer Vision, 2016: 21-37.
|
| 28 |
REN S Q , HE K M , GIRSHICK R , et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE. on Pattern Analysis and Machine Intelligence, 2017, 39 (6): 1137- 1149.
doi: 10.1109/TPAMI.2016.2577031
|
| 29 |
REDMON J, FARHAD A. Yolov3: an incremental improvement[EB/OL]. [2023-05-29]. http://arxiv.org/pdf/1804.02767
|
| 30 |
ALEXEY B, WANG C Y, LIAO H Y. Yolov4: optimal speed and accuracy of object detection[EB/OL]. [2023-05-29]. https://arxiv.org/abs/2004.10934.
|
| 31 |
GE Z, LIU S T, WANG F, et al. Yolox: exceeding Yolo series in 2021[EB/OL]. [2023-05-29]. https://arxiv.org/abs/2107.08430.
|