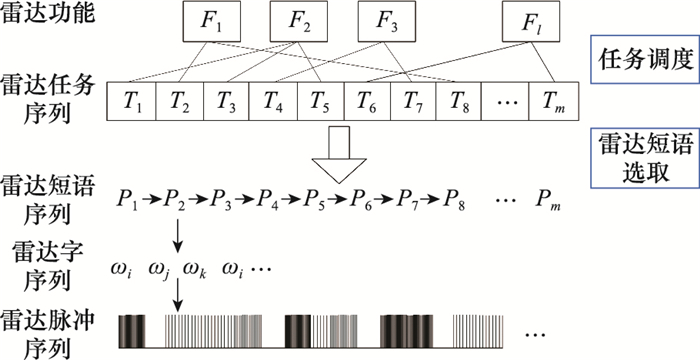
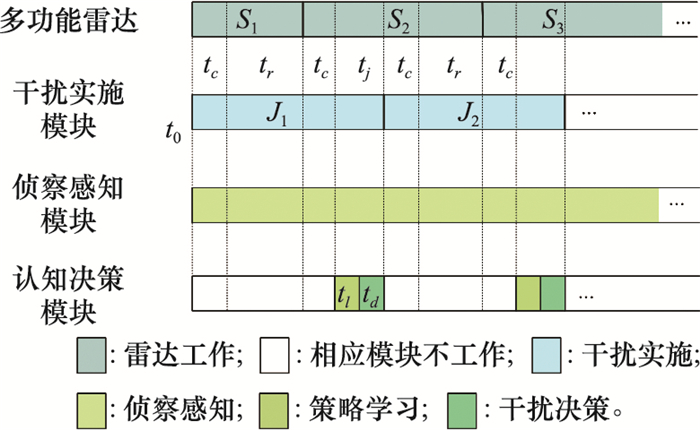
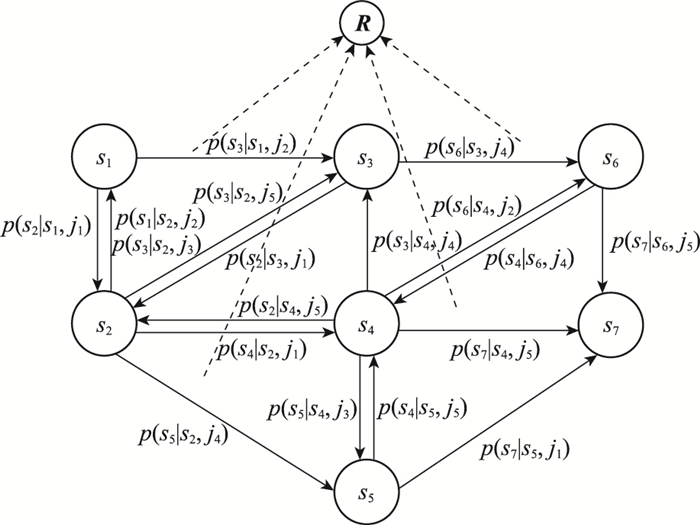
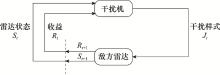
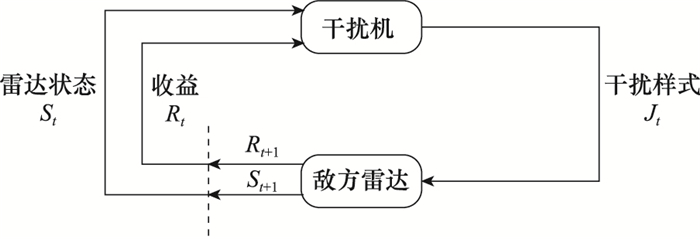
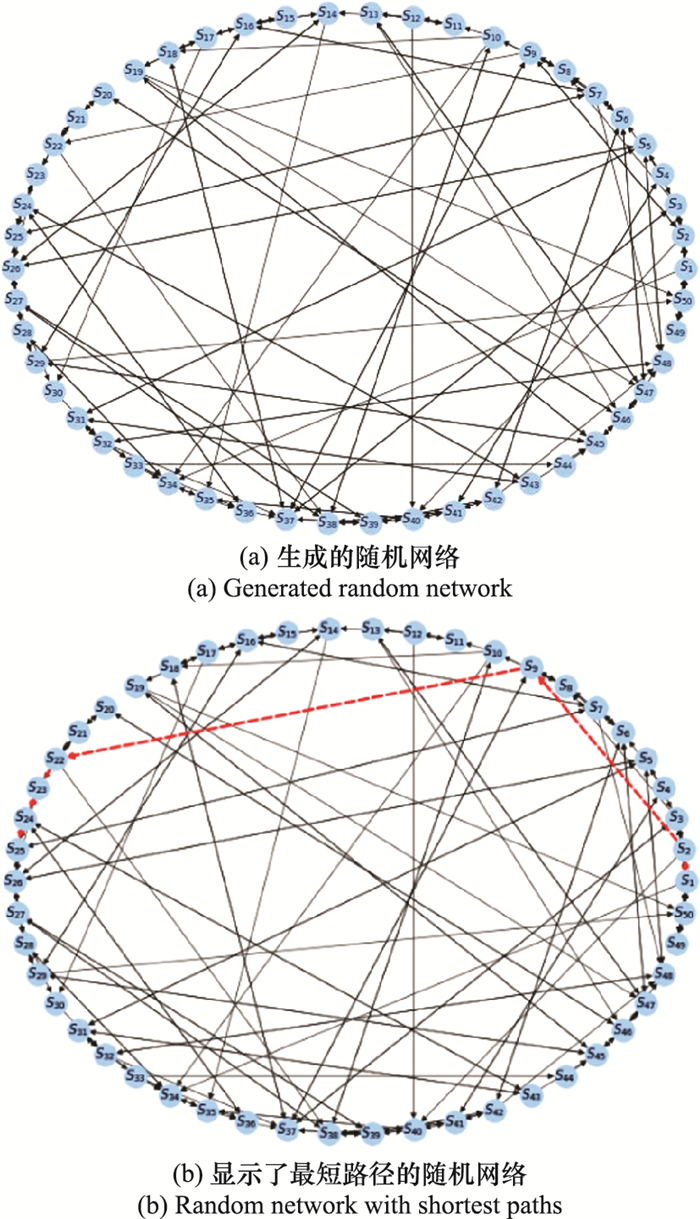
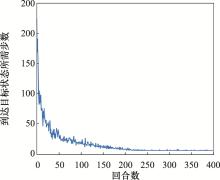
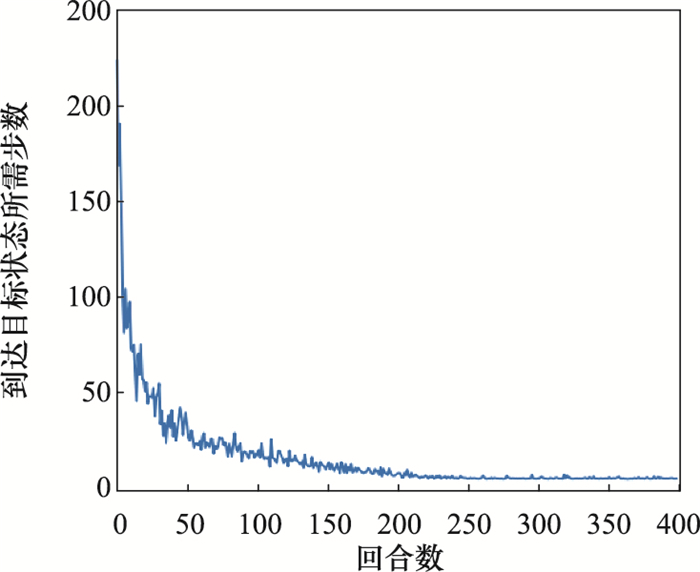
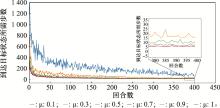
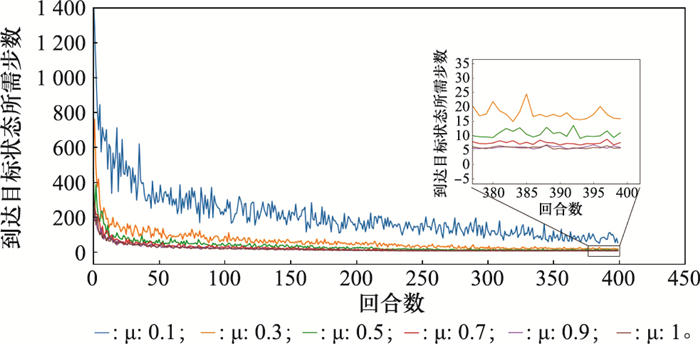
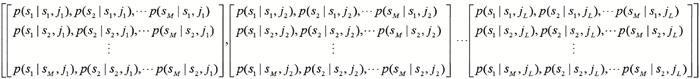| 1 |
王沙飞, 李岩, 徐迈, 等. 认知电子战原理与技术[M]. 北京: 国防工业出版社, 2018: 10- 11.
|
|
WANG S F , LI Y , XU M , et al. Principle and technology of cognitive electronic warfare[M]. Beijing: National Defense Industry Press, 2018: 10- 11.
|
| 2 |
GONG L L, LUO J Q, WU S L. A radar emitter identification method based on pulse match template sequence[C]//Proc. of the IEEE 2nd International Conference on Signal Processing Systems, 2010, 3: 153-156.
|
| 3 |
周脉成. 基于博弈论的雷达干扰决策技术研究[D]. 西安: 西安电子科技大学, 2014: 29-32.
|
|
ZHOU M C. Research on radar jamming decision technology based on game theory[D]. Xi'an: Xidian University, 2014: 29-32.
|
| 4 |
BACHMANN D J , EVANS R J , MORAN B . Game theoretic analysis of adaptive radar jamming[J]. IEEE Trans.on Aerospace and Electronic Systems, 2011, 47 (2): 1081- 1100.
doi: 10.1109/TAES.2011.5751244
|
| 5 |
HE B, SU H T. Joint power allocation and beamforming between a multistatic radar and jammer based on game theory[C]// Proc. of the IEEE 11th International Conference on Communication Software and Networks, 2019: 337-341.
|
| 6 |
孙宏伟, 童宁宁, 孙富君. 基于D-S证据理论的电子干扰模式选择[J]. 弹箭与制导学报, 2003, (S2): 218- 220.
|
|
SUN H W , TONG N N , SUN F J . Jamming design selection based on D-S theory[J]. Journal of Projectiles, Rockets, Missiles and Guidance, 2003, (S2): 218- 220.
|
| 7 |
TANG Z , GAO X G . Research on the self-defence electronic jamming decision-making based on the discrete dynamic Bayesian network[J]. Journal of Systems Engineering and Electronics, 2008, 19 (4): 702- 708.
doi: 10.1016/S1004-4132(08)60142-5
|
| 8 |
SILVER D , SCHRITTWIESER J L , SIMONYAN K , et al. Mastering the game of go without human knowledge[J]. Nature, 2017, 550 (7676): 354- 359.
doi: 10.1038/nature24270
|
| 9 |
YOO J , JANG D , KIM H J , et al. Hybrid reinforcement learning control for a micro quadrotor flight[J]. IEEE Control Systems Letters, 2020, 5 (2): 505- 510.
|
| 10 |
GUO X X , YAN W S , CUI R X . Reinforcement learning-based nearly optimal control for constrained-input partially unknown systems using differentiator[J]. IEEE Trans.on Neural Networks and Learning Systems, 2019, 31 (11): 4713- 4725.
|
| 11 |
ZHAO Z Y, WANG Q, LI X L. Deep reinforcement learning based lane detection and localization[EB/OL]. [2021-05-20]. https://www.sciencedirect.com/science/article/pii/S0925231220310833.
|
| 12 |
PARK H , SIM M K , CHOI D G . An intelligent financial portfolio trading strategy using deep Q-learning[J]. Expert Systems with Applications, 2020, 158, 113573.
doi: 10.1016/j.eswa.2020.113573
|
| 13 |
MANDOW L , PÉREZ-DE-LA-CRUZ J L , RODRÍGUEZ-GAVILÁN A B , et al. Architectural planning with shape grammars and reinforcement learning: habitability and energy efficiency[J]. Engineering Applications of Artificial Intelligence, 2020, 96, 103909.
doi: 10.1016/j.engappai.2020.103909
|
| 14 |
邢强, 贾鑫, 朱卫纲. 基于Q-学习的智能雷达对抗[J]. 系统工程与电子技术, 2018, 40 (5): 1031- 1035.
|
|
XING Q , JIA X , ZHU W G . Intelligent radar countermeasure based on Q-learning[J]. Systems Engineering and Electronics, 2018, 40 (5): 1031- 1035.
|
| 15 |
李云杰, 朱云鹏, 高梅国. 基于Q-学习算法的认知雷达对抗过程设计[J]. 北京理工大学学报, 2015, 35 (11): 1194- 1199.
|
|
LI Y J , ZHU Y P , GAO M G . Design of cognitive radar jamming basedon Q-learning algorithm[J]. Transactions of Beijing Institute of Technology, 2015, 35 (11): 1194- 1199.
|
| 16 |
QIANG X, ZHU W G, XIN J. Research on method of intelligent radar confrontation based on reinforcement learning[C]//Proc. of the IEEE 2nd International Conference on Computational Intelligence and Applications, 2017.
|
| 17 |
XING Q, ZHU W G, JIA X. Intelligent countermeasure design of radar working-modes unknown[C]//Proc. of the IEEE International Conference on Signal Processing, Communications and Computing, 2017.
|
| 18 |
张柏开, 朱卫纲. 对多功能雷达的DQN认知干扰决策方法[J]. 系统工程与电子技术, 2020, 42 (4): 819- 825.
|
|
ZHNAG B K , ZHU W G . DQN based decision-making method of cognitive jamming against multifunctional radar[J]. Systems Engineering and Electronics, 2020, 42 (4): 819- 825.
|
| 19 |
CHARLISH A. Autonomous agents for multi-function radar resource management[D]. London: University College London, 2011.
|
| 20 |
张光义. 相控阵雷达技术[M]. 北京: 国防工业出版社, 2009: 30- 32.
|
|
ZHANG G Y . Phased array radar technology[M]. Beijing: National Defense Industry Press, 2009: 30- 32.
|
| 21 |
VISNEVSKI N, KRISHNAMURTHY V, HAYKIN S, et al. Multi-function radar emitter modelling: a stochastic discrete event system approach[C]//Proc. of the IEEE Conference on Decision & Control, 2004.
|
| 22 |
VISNEVSKI N , KRISHNAMURTHY V , WANG A , et al. Syntactic modeling and signal processing of multifunction radars: a stochastic context-free grammar approach[J]. Proceedings of the IEEE, 2007, 95 (5): 1000- 1025.
doi: 10.1109/JPROC.2007.893252
|
| 23 |
WANG A , KRISHNAMURTHY V . Signal interpretation of multifunction radars: modeling and statistical signal processing with stochastic context-free grammar[J]. IEEE Trans.on Signal Processing, 2008, 56 (3): 1106- 1109.
doi: 10.1109/TSP.2007.908949
|
| 24 |
欧健. 多功能雷达行为辨识与预测技术研究[D]. 长沙: 国防科技大学, 2017: 20-30
|
|
OU J. Research on behavior recognition and prediction techniques against multi-function radar[D]. Changsha: National University of Defence Technology, 2017: 20-30.
|
| 25 |
林石, 伍燕平, 肖进. 认知雷达对抗中的未知雷达状态识别方法分析[J]. 电子技术与软件工程, 2020, (13): 65- 66.
|
|
LIN S , WU Y P , XIAO J . Analysis of unknown radar state recognition method in cognitive radar countermeasure[J]. Electronic Technology & Software Engineering, 2020, (13): 65- 66.
|
| 26 |
LIU Z M . Recognition of multifunction radars via hierarchically mining and exploiting pulse group patterns[J]. IEEE Trans.on Aerospace and Electronic Systems, 2020, 56 (6): 4659- 4672.
doi: 10.1109/TAES.2020.2999163
|
| 27 |
杨秋, 顾杰, 魏平. 利用幅度重排的机载火控雷达工作模式识别方法[J]. 西安电子科技大学学报, 2021, 48 (2): 42- 48.
|
|
YANG Q , GU J , WEI P . Recognition of operation model of airborne fire control radar using amplitude rearrangement[J]. Journal of Xidian University, 2021, 48 (2): 42- 48.
|
| 28 |
王勇军. 一种改进的事件驱动的MFR雷达字提取方法[J]. 现代雷达, 2019, 41 (3): 17- 20.17-20, 26
|
|
WANG Y J . Novel approach of radar word extraction for MFRs based on event-drive method[J]. Modern Radar, 2019, 41 (3): 17- 20.17-20, 26
|
| 29 |
刘海军, 樊昀, 李悦, 等. 多功能雷达建模中的雷达字提取技术研究[J]. 国防科技大学学报, 2010, 32 (2): 91- 96.
doi: 10.3969/j.issn.1001-2486.2010.02.017
|
|
LIU H J , FAN J , LI R , et al. Research on extracting of radar words in modeling of multi-function radar[J]. Journal of National University of Defense Technology, 2010, 32 (2): 91- 96.
doi: 10.3969/j.issn.1001-2486.2010.02.017
|
| 30 |
MIRANDA S , BAKER C , WOODBRIDGE K , et al. Know- ledge-based resource management for multifunction radar: a look at scheduling and task prioritization[J]. IEEE Signal Processing Magazine, 2006, 23 (1): 66- 76.
doi: 10.1109/MSP.2006.1593338
|
| 31 |
MIRANDA S L C , BAKER C J , WOODBRIDGE K , et al. Comparison of scheduling algorithms for multifunction radar[J]. IET Radar, Sonar & Navigation, 2007, 1 (6): 414- 424.
|
| 32 |
张友益, 徐才宏. 雷达对抗及反对抗作战能力评估与验证[M]. 北京: 国防工业出版社, 2019: 10- 11.
|
|
ZHANG Y Y , XU C H . Evaluation and verification of radar countermeasure and countermeasure[M]. Beijing: National Defense Industry Press, 2019: 10- 11.
|