
系统工程与电子技术 ›› 2022, Vol. 44 ›› Issue (3): 884-899.doi: 10.12305/j.issn.1001-506X.2022.03.21
何立1, 沈亮3, 李辉1,2,*, 王壮1, 唐文泉1
收稿日期:2021-01-18
出版日期:2022-03-01
发布日期:2022-03-10
通讯作者:
李辉
作者简介:何立(1996—), 男, 硕士研究生, 主要研究方向为深度强化学习技术|沈亮(1980—), 男, 研究员级高级工程师, 硕士, 主要研究方向为航空武器装备体系设计工程|李辉(1970—), 男, 教授, 博士, 主要研究方向为智能计算、战场仿真、虚拟现实|王壮(1987—), 男, 博士研究生, 主要研究方向为军事人工智能、深度强化学习技术|唐文泉(1993—), 男, 硕士研究生, 主要研究方向为深度强化学习技术
基金资助:Li HE1, Liang SHEN3, Hui LI1,2,*, Zhuang WANG1, Wenquan TANG1
Received:2021-01-18
Online:2022-03-01
Published:2022-03-10
Contact:
Hui LI
摘要:
策略重用(policy reuse, PR)作为一种迁移学习(transfer learning, TL)方法, 通过利用任务之间的内在联系, 将过去学习到的经验、知识用于加速学习当前的目标任务, 不仅能够在很大程度上解决传统强化学习(reinforcement learning, RL)收敛速度慢、资源消耗大等问题, 而且避免了在相似问题上难以复用的问题。本文综述了RL中的PR方法, 将现有方法细分为策略重构、奖励设计、问题转换、相似性度量等方面来分别介绍和分析各自的特点, 及其在多智能体场景和深度RL(deep RL, DRL)中的扩展。并且, 介绍了源和目标任务之间的映射方法。最后, 基于当前PR的应用, 叙述了该课题在未来发展方向上的一些猜想和假设。
中图分类号:
何立, 沈亮, 李辉, 王壮, 唐文泉. 强化学习中的策略重用: 研究进展[J]. 系统工程与电子技术, 2022, 44(3): 884-899.
Li HE, Liang SHEN, Hui LI, Zhuang WANG, Wenquan TANG. Survey on policy reuse in reinforcement learning[J]. Systems Engineering and Electronics, 2022, 44(3): 884-899.
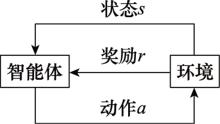
图1
RL基本框架"
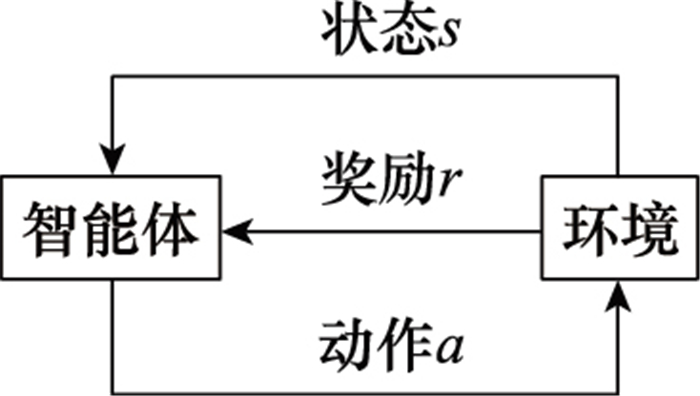
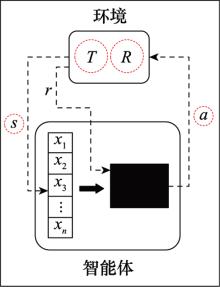
图2
智能体与环境交互过程"
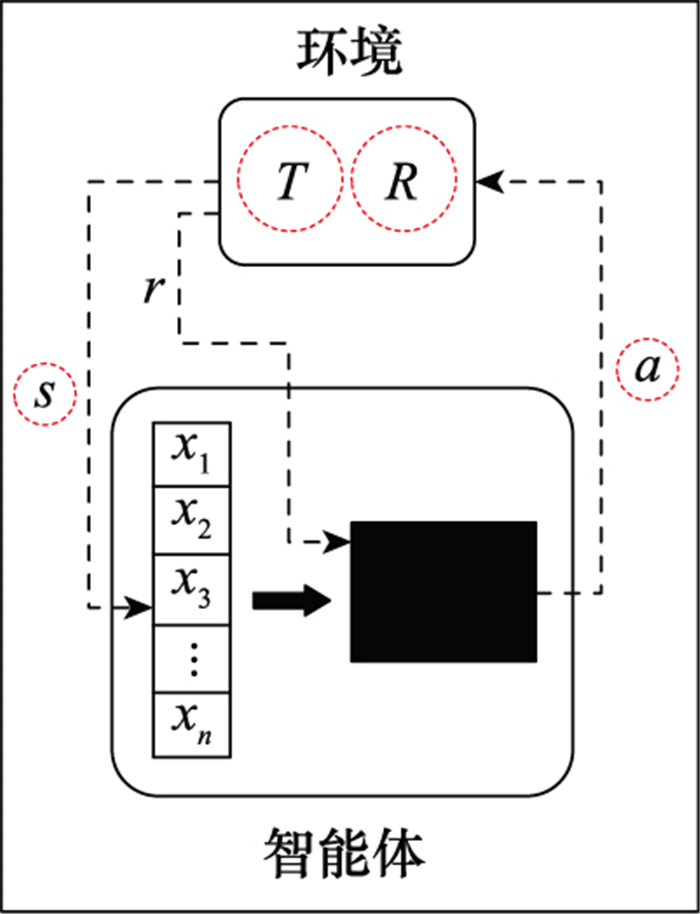
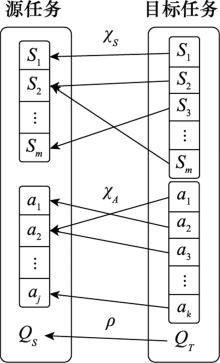
图3
源和目标任务间的映射"
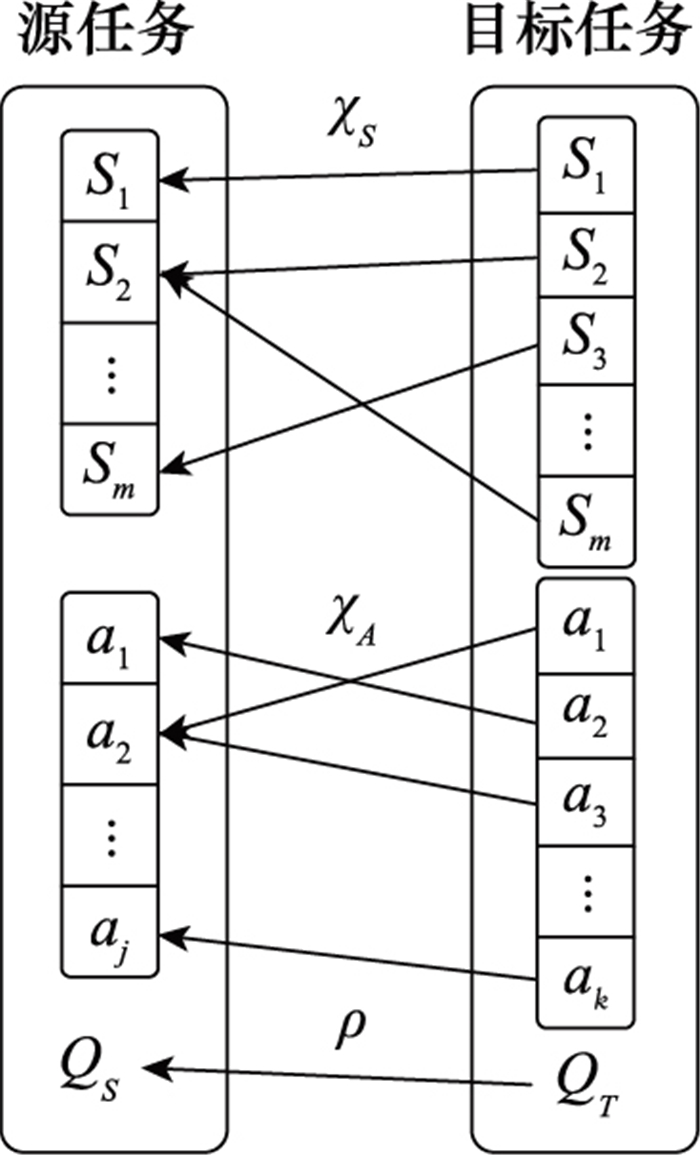
表1
任务间映射方法总结"
| 文献 | RL框架 | MDP区别 | 映射函数 |
| [ | Sarsa | S, A | QS→QT |
| [ | Q-learning | A, R | QS→Advice |
| [ | Sarsa(λ) | S, R | M(sA)→r′ |
| [ | 无限制 | SS×AS≠ST×AT | |
| [ | 值迭代 | S | SS→ST |

图4
OFU定向策略工作示意图"
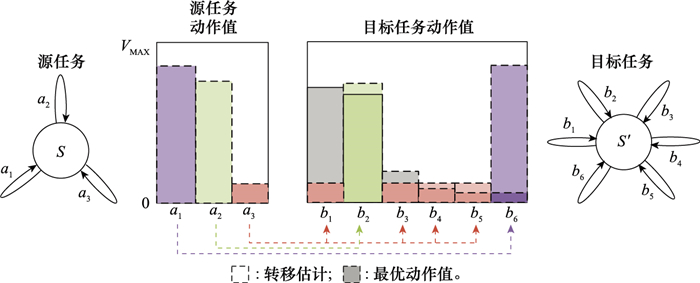
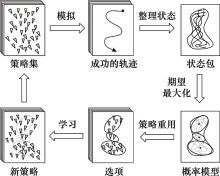
图5
ILPSS工作流程图"
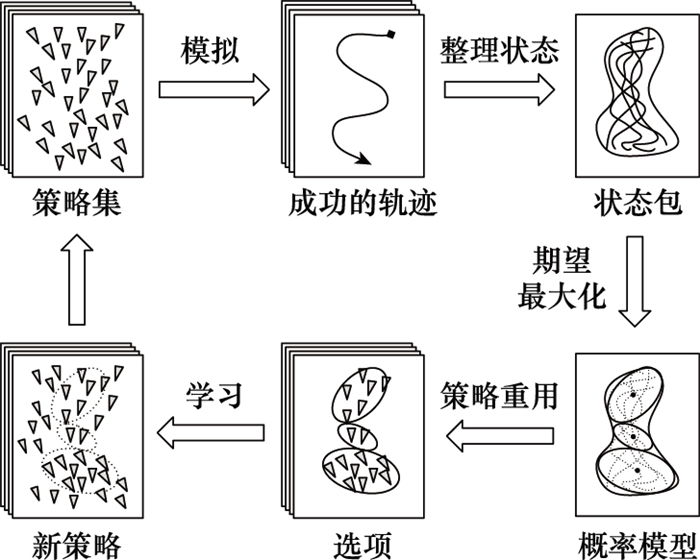
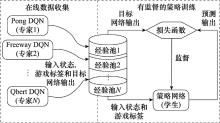
图6
多任务策略蒸馏"

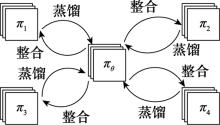
图7
共享策略工作过程"
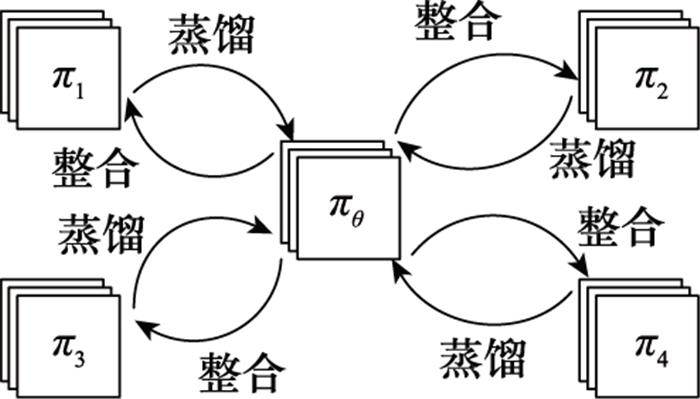
表2
策略重构类方法总结"
| 文献 | 算法名称 | 方法类别 | 完成工作 |
| [ | 具有后继特征的广义策略改进 | 外部协助(专家策略) | 在拥有不同奖励函数的源任务上训练专家策略, 并用神经网络评估专家策略, 选择Q值最大的专家策略来重用 |
| [ | AC框架中的专家演示 | 外部协助(离线专家演示) | 使用预训练后的值函数加速基于AC框架的算法如DDPG |
| [ | 深度Q学习 | 外部协助(在线专家演示) | 抛弃预训练的过程, 将专家演示直接用于RL阶段进行训练 |
| [ | 基于DDPG框架和HEB的专家演示 | 外部协助(离线与在线结合的专家演示) | 结合离线预训练和在线学习的方法来使用专家演示, 使用DDPG框架学习 |
| [ | PRQL | 概率探索 | 在重用策略库的过程中同时增加选择随机的动作的概率以避免收敛到次优策略 |
| [ | DQL+OFU | 概率探索 | 结合DQL算法和定向探索策略OFU学习目标任务 |
| [ | ILPSS | 策略蒸馏/整合 | 构建出用神经网络拟合概率模型的采样轨迹去学习目标策略的增量框架 |
| [ | 策略蒸馏 | 策略蒸馏/整合 | 将多个任务最优策略蒸馏整合到单个策略后重用 |
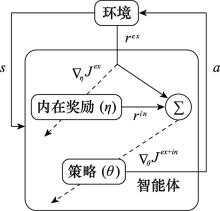
图8
LIRPG智能体学习过程的抽象表示"
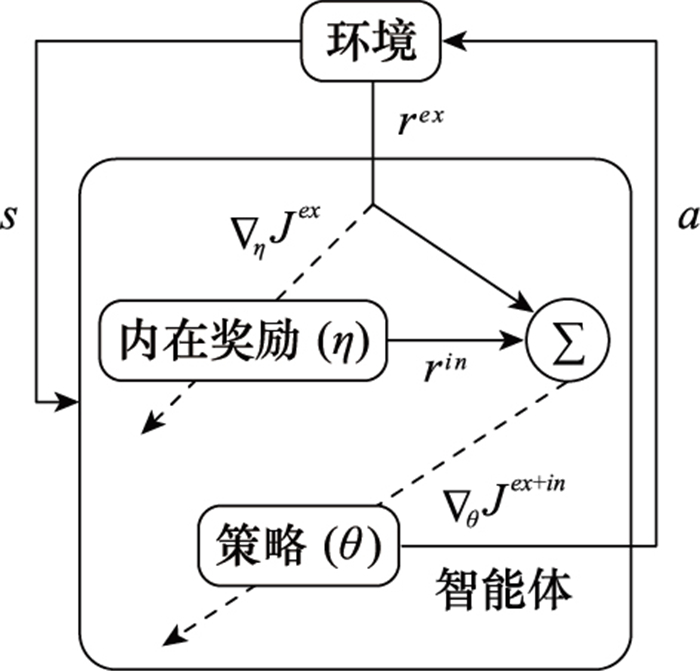
表3
奖励设计类方法总结"
| 文献 | 算法 | MDP的区别 | 奖励设计函数的形式 | 算法分析 |
| [ | PBRS | Ms=Mt | F=γΦ(s′)-Φ(s) | 用定义在状态空间上的势函数的差值作为附加奖励值, 并能保证最优策略的不变性 |
| [ | PBA | Ms=Mt | F=γΦ(s′, a′)-Φ(s, a) | 在保证最优策略不变性的前提下, 将势函数扩展到基于状态-动作对上, 能用更加具体的信息去指导智能体选择动作 |
| [ | DPB | Ms=Mt | F=γΦ(s′, t′)-Φ(s, t) | 将状态与时间结合创建动态的势函数, 除了能保证最优策略的不变性之外, 在多智能体环境中纳什均衡解也不会改变 |
| [ | DPBA | Ms=Mt | Ft=γΦt+1(s′, a′)-Φt(s, a) | 能将任何先验知识作为额外奖励加入动态势函数, 提高了算法的通用性 |
| [ | PTS | Ss≠St, As≠At | Ft=γΦt+1(s′, a′)-Φt(s, a) | 将源策略编码成基于动态势函数的奖励设计函数, 对次优的源策略具有更强的鲁棒性 |
| [ | LIRPG | Ms=Mt | 利用外在奖励优化内在奖励并使用内外奖励的和去更新策略, 适用于大部分的RL算法 |
图9
PTF"
表4
相似性度量类方法总结"
| 文献 | 完成工作 | 优点 | 缺点 |
| [ | 交互模拟形式量化MDP之间的差异 | 量化了MDP之间的差异 | 需要手动定义任务之间的度量, 只适用于离散状态空间, 计算量大 |
| [ | 半自动方法, 手动定义源和目标任务之间的关系 | 度量源域和目标域之间的相似性更为准确 | 半自动, 需要人类定义源域和目标域之间的关系, 通用性差 |
| [ | 从智能体与环境交互收集的样本中估计任务相似性 | 全自动, 智能体自主学习度量相似性并进行PR | 容易导致经验过拟合 |
| [ | 用自模拟度量构造不稳定环境下MDP分布之间的距离, 并以此结合小公式集来迁移策略 | 提供了PR在不稳定环境下的解决思路 | 不适用庞大的状态空间和连续状态空间问题 |
| [ | Hausdorff度量方法计算有限个MDP之间的距离, Kantorovich度量方法计算概率分布之间的距离 | 提供了度量不同任务状态集和概率分布之间的方法 | 存在错误度量的问题, 不适用于连续状态空间问题 |
| [ | 使用KL散度衡量策略之间的差异来筛选策略, 并完成策略库的重建 | 避免重用源策略的无用部分而导致的负迁移问题, 保证了策略库的健壮性和有效性 | 不适用于连续动作空间问题 |
| [ | Jensen-Shannon度量方法计算概率分布之间的距离 | 最大限度地重用了源策略, 并通过限制目标任务中的探索提高了重用效率 | 只适用于离散的状态空间和动作空间问题 |
表5
PR方法对比"
| 方法 | 优点 | 缺点 |
| 策略重构类 | 简单, 短时间内达到较好的效果 | 难以保证源策略完全适用于目标任务, 导致效果次优 |
| 奖励设计类 | 克服稀疏奖励, 只需细微改动RL框架 | 奖励函数设计困难, 收敛较慢 |
| 问题转换类 | 简化问题, 利用已有问题模型解决 | 现有问题模型较少, 约束条件苛刻 |
| 相似性度量类 | 直观选择最优的源策略 | 相似性度量标准不统一, 通用性较差 |
表6
PR方法中的DRL框架总结"
| 文献 | 方法 | PR方法 | DRL框架 | 优点 | 缺点 |
| [ | 深度Q学习 | 外部协助 | DQN | 所需演示数据少, 初始性能提升快 | 不适用连续动作空间问题 |
| [ | PTS | 奖励设计 | DQN | 对次优源策略更为鲁棒 | 不能进行多任务PR |
| [ | GAIL | 奖励设计 | TRPO | 直接从专家轨迹中学习策略, 效率更高 | 受专家策略质量的影响较大 |
| [ | POfD | 奖励设计 | TRPO, PPO | 所需演示数据少, 能有效解决稀疏奖励问题 | 初始性能低, 收敛速度较慢 |
| [ | DDPGfD | 外部协助 | DDPG | 无模型、通用性强 | 对缓冲区频繁存取, 效率较低 |
| [ | Distral | 策略蒸馏/整合 | A3C | 实现了多任务PR | 计算量较大 |
表7
PR方法应用总结"
| 文献 | PR方法 | 应用 |
| [ | 策略重构 | 机器人导航 |
| [ | 策略重构 | 机器人足球 |
| [ | 策略蒸馏/整合 | Atari |
| [ | 奖励设计 | Dota2 |
| [ | 策略重构、问题转换 | 导航游戏 |
| 1 | SUTTON R S , BARTO A G . Reinforcement learning: an introduction[M]. Cambridge, MA: The MIT Press, 2018. |
| 2 |
ARULKUMARAN K , DEISENROTH M P , BRUNDAGE M , et al. Deep reinforcement learning: a brief survey[J]. IEEE Signal Processing Magazine, 2017, 34 (6): 26- 38.
doi: 10.1109/MSP.2017.2743240 |
| 3 |
LEVINE S , PASTOR P , KRIZHEVSKY A , et al. Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection[J]. The International Journal of Robotics Research, 2018, 37 (4-5): 421- 436.
doi: 10.1177/0278364917710318 |
| 4 | VINYALS O, EWALDS T, BARTUNOV S, et al. StarCraft Ⅱ: a new challenge for reinforcement learning[EB/OL]. [2020-12-16]. https://arXiv:1708.04782, 2017. |
| 5 |
SILVER D , SCHRITTWIESER J , SIMONYAN K , et al. Mastering the game of go without human knowledge[J]. Nature, 2017, 550 (7676): 354- 359.
doi: 10.1038/nature24270 |
| 6 | ZHU Z D, LIN K X, ZHOU J Y. Transfer learning in deep reinforcement learning: a survey[EB/OL]. [2020-12-16]. https://arXiv:2009.07888, 2020. |
| 7 | BELLMAN R . A Markovian decision process[J]. Journal of Mathematics and Mechanics, 1957, 6 (5): 679- 684. |
| 8 |
WATKINS C J , DAYAN P . Q-learning[J]. Machine Learning, 1992, 8 (3-4): 279- 292.
doi: 10.1007/BF00992698 |
| 9 | SUTTON R S, MCALLESTER D A, SINGH S P, et al. Policy gradient methods for reinforcement learning with function approximation[C]//Proc. of the Advances in Neural Information Processing Systems, 1999: 1057-1063. |
| 10 | SILVER D, LEVER G, HEESS N, et al. Deterministic policy gradient algorithms[C]//Proc. of the 31st International Confe-rence on Machine Learning, 2014, 32: 387-395. |
| 11 |
MNIH V , KAVUKCUOGLU K , SILVER D , et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518 (7540): 529- 533.
doi: 10.1038/nature14236 |
| 12 | MNIH V, KAVUKCUOGLU K, SILVER D, et al. Playing Atari with deep reinforcement learning[EB/OL]. [2020-12-16]. https://arXiv:1312.5602, 2013. |
| 13 | LILLICRAP T P, HUNT J, PRITZEL A, et al. Continuous control with deep reinforcement learning[C]//Proc. of the International Conference on Learning Representations, 2016. |
| 14 | KONDA V R, TSITSIKLIS J N. Actor-critic algorithms[C]//Proc. of the Advances in Neural Information Processing Systems, 2000: 1008-1014. |
| 15 | MNIH V, BADIA A P, MIRZA M, et al. Asynchronous methods for deep reinforcement learning[C]//Proc. of the International Conference on Machine Learning, 2016: 1928-1937. |
| 16 | SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[EB/OL]. [2020-12-16]. https://arXiv:1707.06347, 2017. |
| 17 | TAYLOR M E, STONE P. Behavior transfer for value-function-based reinforcement learning[C]//Proc. of the 4th International Joint Conference on Autonomous Agents and Multiagent Systems, 2005: 53-59. |
| 18 | FERNANDEZ F, VELOSO M. Exploration and policy reuse[R]. Pittsburgh: Carnegie Mellon University, 2005: 123-139. |
| 19 | TAYLOR M E , STONE P , LIU Y . Transfer learning via inter-task mappings for temporal difference learning[J]. Journal of Machine Learning Research, 2007, 8 (1): 2125- 2167. |
| 20 | TORREY L, WALKER T, SHAVLIK J, et al. Using advice to transfer knowledge acquired in one reinforcement learning task to another[C]//Proc. of the European Conference on Machine Learning, 2005: 412-424. |
| 21 | GUPTA A, DEVIN C, LIU Y X, et al. Learning invariant feature spaces to transfer skills with reinforcement learning[C]//Proc. of the International Conference on Learning Representations, 2017. |
| 22 | KONIDARIS G, BARTO A. Autonomous shaping: knowledge transfer in reinforcement learning[C]//Proc. of the 23rd International Conference on Machine Learning, 2006: 489-496. |
| 23 | AMMAR H B, TAYLOR M E. Reinforcement learning transfer via common subspaces[C]//Proc. of the 11th International Confe-rence on Adaptive and Learning Agents, 2012: 21-36. |
| 24 | BOCSI B, CSATO L, PETERS J. Alignment-based transfer learning for robot models[C]//Proc. of the International Joint Conference on Neural Networks, 2013. |
| 25 | AMMAR H B, EATON E, RUVOLO P, et al. Unsupervised cross-domain transfer in policy gradient reinforcement learning via manifold alignment[C]//Proc. of the 29th Association for the Advance of Artificial Intelligence, 2015: 2504-2510. |
| 26 | WANG C, MAHADEVAN S. Manifold alignment without correspondence[C]//Proc. of the 21st International Joint Confe-rence on Artificial Intelligence, 2009: 1273-1278. |
| 27 |
BADRINARAYANAN V , KENDALL A , CIPOLLA R . Segnet: a deep convolutional encoder-decoder architecture for image segmentation[J]. IEEE Trans.on Pattern Analysis and Machine Intelligence, 2017, 39 (12): 2481- 2495.
doi: 10.1109/TPAMI.2016.2644615 |
| 28 | AMMAR H B, TUYLS K, TAYLOR M E, et al. Reinforcement learning transfer via sparse coding[C]//Proc. of the 11th International Conference on Autonomous Agents and Multiagent Systems, 2012: 383-390. |
| 29 | LEE H, BATTLE A, RAINA R, et al. Efficient sparse coding algorithms[C]//Proc. of the Advances in Neural Information Processing Systems, 2007: 801-808. |
| 30 | LAZARIC A, RESTELLI M, BONARINI A. Transfer of samples in batch reinforcement learning[C]//Proc. of the 25th International Conference on Machine Learning, 2008: 544-551. |
| 31 | LIU F C, LING Z, MU T Z, et al. State alignment-based imitation learning[C]//Proc. of the International Conference on Learning Representations, 2019. |
| 32 | SILVA B N, MACKWORTH A. Using spatial hints to improve policy reuse in a reinforcement learning agent[C]//Proc. of the 9th International Conference on Autonomous Agents and Multiagent Systems, 2010: 317-324. |
| 33 | FERNANDEZ F, VELOSO M. Probabilistic policy reuse in a reinforcement learning agent[C]//Proc. of the 5th International Joint Conference on Autonomous Agents and Multiagent Systems, 2006: 720-727. |
| 34 | BARRETO A, DABNEY W, MUNOS R, et al. Successor features for transfer in reinforcement learning[C]//Proc. of the Advances in Neural Information Processing Systems, 2017: 4055-4065. |
| 35 | KURENKOV A, MANDLEKAR A, SAVARESE S, et al. Ac-teach: a Bayesian actor-critic method for policy learning with an ensemble of suboptimal teachers[C]//Proc. of the IEEE International Conference on Robotics and Automation, 2019: 717-734. |
| 36 | ZHANG X Q, MA H M. Pretraining deep actor-critic reinforcement learning algorithms with expert demonstrations[EB/OL]. [2020-12-16]. https://arXiv:1801.10459, 2018. |
| 37 |
SILVER D , HUANG A , MADDISON C J , et al. Mastering the game of go with deep neural networks and tree search[J]. Nature, 2016, 529 (7587): 484- 489.
doi: 10.1038/nature16961 |
| 38 | SCHAAL A. Learning from demonstration[C]//Proc. of the Advances in Neural Information Processing Systems, 1997: 1040-1046. |
| 39 | HESTER T, ECERIK M V, PIETQUIN O, et al. Deep Q-learning from demonstrations[C]//Proc. of the 32nd AAAI Conference on Artificial Intelligence, 2018: 3223-3230. |
| 40 | BRYS T, SUAY H, CHERNOVA S, et al. Reinforcement learning from demonstration through shaping[C]//Proc. of the International Joint Conference on Artificial Intelligence, 2015: 3352-3358. |
| 41 | NAIR A, MCGREW B, ZAREMBA W, et al. Overcoming exploration in reinforcement learning with demonstrations[C]//Proc. of the IEEE International Conference on Robotics and Automation, 2018: 6292-6299. |
| 42 | KIM B, PINEAU J, PRECUP D, et al. Learning from limited demonstrations[C]//Proc. of the Advances in Neural Information Processing Systems, 2013: 2859-2867. |
| 43 | GAO Y, XU H Z, LIN J, et al. Reinforcement learning from imperfect demonstrations[C]//Proc. of the International Conference on Learning Representations, 2018. |
| 44 | BOWLING M, VELOSO M. Reusing learned policies between similar problems[C]//Proc. of the AⅡA-98 Workshop on New Trends in Robotics, 1998. |
| 45 | FERNANDEZ F , VELOSO M . Learning domain structure through probabilistic policy reuse in reinforcement learning[J]. Artificial Intelligence, 2013, 2 (1): 13- 27. |
| 46 | FERNANDEZ F, VELOSO M. Policy reuse for transfer lear-ning across tasks with different state and action spaces[C]//Proc. of the International Conference on Machine Learning Workshop on Structural Knowledge Transfer for Machine Learning, 2006. |
| 47 | 李学俊, 陈士洋, 张以文, 等. Keepaway抢球任务中基于策略重用的迁移学习算法[J]. 计算机科学, 2015, 42 (4): 190- 194. |
| LI X J , CHEN S Y , ZHANG Y W , et al. Transfer learning algorithm between keepaway tasks based on policy reuse[J]. Computer Science, 2015, 42 (4): 190- 194. | |
| 48 |
KOGA M L , SILVA V F , COSTA A H . Stochastic abstract policies: generalizing knowledge to improve reinforcement learning[J]. IEEE Trans.on Cybernetics, 2015, 45 (1): 77- 88.
doi: 10.1109/TCYB.2014.2319733 |
| 49 | NARAYAN A, LI Z, LEONG T Y. SEAPoT-RL: selective exploration algorithm for policy transfer in RL[C]//Proc. of the 31st AAAI Conference on Artificial Intelligence, 2017: 4975-4977. |
| 50 | TIMOTHY M, CHOE Y. Directed exploration in reinforcement learning with transferred knowledge[C]//Proc. of the 10th European Workshop on Reinforcement Learning, 2012: 59-76. |
| 51 |
MATTHEW E , TAYLOR S P . An introduction to inter-task transfer for reinforcement learning[J]. AI Magazine, 2011, 32 (1): 15- 34.
doi: 10.1609/aimag.v32i1.2329 |
| 52 | ALEXANDER L, STRH L, LANGFORD J, et al. PAC mo-del-free reinforcement learning[C]//Proc. of the 23rd International Conference on Machine Learning, 2006, 148: 881-888. |
| 53 | BERNSTEIN D S. Reusing old policies to accelerate learning on new MDPs[R]. Amherst: University of Massachusetts, 1999. |
| 54 | HAWASLY M, RAMAMOORTHY S. Lifelong learning of structure in the space of policies[C]//Proc. of the AAAI Spring Symposium: Lifelong Machine Learning, 2013. |
| 55 | RUSU A A, COLMENREJO S G, GULCEHRE C, et al. Policy distillation[C]//Proc. of the International Conference on Learning Representations, 2015. |
| 56 | YIN H, PAN S J. Knowledge transfer for deep reinforcement learning with hierarchical experience replay[C]//Proc. of the 31st AAAI Conference on Artificial Intelligence, 2017: 1640-1646. |
| 57 | PARISOTTO E, BA J L, SALAKHUTDUNOV R. Actor-mimic: deep multitask and transfer reinforcement learning[C]//Proc. of the International Conference on Learning Representations, 2016. |
| 58 | TEH Y, BAPST V, CZARNECKI W M, et al. Distral: robust multi-task reinforcement learning[C]//Proc. of the Advances in Neural Information Processing Systems, 2017: 4496-4506. |
| 59 | 常田, 章宗长, 俞扬. 随机集成策略迁移[J]. 计算机科学与探索. https://kns.cnki.net/kcms/detail/11.5602.TP.20210608.1108.015.html, 2021. |
| CHANG T, ZHANG Z C, YU Y. Stochastic ensemble policy transfer[J]. Journal of Frontiers of Computer Science and Technology. https://kns.cnki.net/kcms/detail/11.5602.TP.20210608.1108.015.html, 2021. | |
| 60 | MACKAY D, ADAMS R. Bayesian online changepoint detection[R]. Cambridge: Harvard, 2007. |
| 61 | NG A Y, HARADA D, RUSSELL S. Policy invariance under reward transformations: theory and application to reward shaping[C]//Proc. of the International Conference on Machine Learning, 1999: 278-287. |
| 62 | WIEWIORA E, COTTRELL G W, ELKA N. Principled methods for advising reinforcement learning agents[C]//Proc. of the 20th International Conference on Machine Learning, 2003: 792-799. |
| 63 | DEVLIN S M, KUDENKO D. Dynamic potential-based reward shaping[C]//Proc. of the 11th International Conference on Autonomous Agents and Multiagent Systems, 2012: 433-440. |
| 64 | HARUTYUNYAN A, DEVLIN S, VRANCX P, et al. Expres-sing arbitrary reward functions as potential-based advice[C]//Proc. of the 29th AAAI Conference on Artificial Intelligence, 2015: 2652-2658. |
| 65 | BRYS T, HARUTYUNYAN A, TAYLOR M E, et al. Policy transfer using reward shaping[C]//Proc. of the International Conference on Autonomous Agents and Multiagent Systems, 2015: 181-188. |
| 66 | VECERIK M, HESTER T, SCHOLZ J, et al. Leveraging demonstrations for deep reinforcement learning on robotics problems with sparse rewards[EB/OL]. [202-12-16]. https://arXiv:1707.08817, 2017. |
| 67 | GIMELFARB M, SANNER S, LEE C. Contextual policy transfer in reinforcement learning domains via deep mixtures-of-experts[EB/OL]. [2020-12-16]. https://arXiv:2003.00203, 2020. |
| 68 | ZHENG Z, OH J, SINGH S. On learning intrinsic rewards for policy gradient methods[C]//Proc. of the Conference and Workshop on Neural Information Processing Systems, 2018: 4649-4659. |
| 69 | MAROM O, ROSMAN B. Belief reward shaping in reinforcement learning[C]//Proc. of the 32nd Association for the Advance of Artificial Intelligence, 2018: 3762-3769. |
| 70 | TENORIO A C, MORALES E F, VILLASENOR L. Dynamic reward shaping: training a robot by voice[C]//Proc. of the Advances in Artificial Intelligence-IBERAMIA, 2010: 483-492. |
| 71 | SU P H, VANDYKE D, GASIC M, et al. Reward shaping with recurrent neural networks for speeding up on-line policy learning in spoken dialogue systems[C]//Proc. of the Special Interest Group on Discourse and Dialogue, 2015: 417-421. |
| 72 | LI S Y, ZHANG C J. An optimal online method of selecting source policies for reinforcement learning[C]//Proc. of the Association for the Advance of Artificial Intelligence, 2018: 3562-3570. |
| 73 | LI S Y, GU F D, ZHU G X, et al. Context-aware policy reuse[C]//Proc. of the 18th International Conference on Autonomous Agents and Multiagent Systems, 2019: 989-997. |
| 74 | ZHENG Y, HAO J Y, ZHANG Z Z, et al. Efficient policy detecting and reusing for non-stationarity in Markov games[C]//Proc. of the 19th International Conference on Autonomous Agents and Multiagent Systems, 2020: 2053-2055. |
| 75 | YANG T P, WANG W X, TANG H Y, et al. Learning when to transfer among agents: an efficient multiagent transfer learning framework[EB/OL]. [2021-6-29]. http://dblp.uni-trier.de/db/journals/corr/corr2002.html#abs-2002-08030, 2020. |
| 76 | FERNS N, CASTRO P S, PRECUP D, et al. Methods for computing state similarity in Markov decision processes[C]//Proc. of the 22nd Conference on Uncertainty in Artificial Intelligence, 2006: 174-181. |
| 77 |
FERNS N , PANANGADEN P , PRECUP D . Bisimulation metrics for continuous Markov decision processes[J]. SIAM Journal on Computing, 2011, 40 (6): 1662- 1714.
doi: 10.1137/10080484X |
| 78 | CASTRO P S, PRECUP D. Using bisimulation for policy transfer in MDPs[C]//Proc. of the International Conference on Autonomous Agents and Multiagent Systems, 2010: 1399-1400. |
| 79 | TAYLOR M E , STONE P H . Transfer learning for reinforcement learning domains: a survey[J]. Journal of Machine Learning Research, 2009, 10 (1): 1633- 1685. |
| 80 | AMMAR H B, MOCANU D C, TAYLOR M E, et al. Automatically mapped transfer between reinforcement learning tasks via three-way restricted Boltzmann machines[C]//Proc. of the European Conference on Machine Learning, 2013: 449-464. |
| 81 | AMMAR H B, EATON E, TAYLOR M E, et al. An automated measure of MDP similarity for transfer in reinforcement learning[C]//Proc. of the Workshops at the 28th AAAI Conference on Artificial Intelligence, 2014: 31-37. |
| 82 |
朱斐, 刘全, 傅启明, 等. 一种不稳定环境下的策略搜索及迁移方法[J]. 电子学报, 2017, 45 (2): 257- 266.
doi: 10.3969/j.issn.0372-2112.2017.02.001 |
|
ZHU F , LIU Q , FU Q M , et al. A policy search and transfer approach in the non-stationary environment[J]. Acta Electro-nica Sinica, 2017, 45 (2): 257- 266.
doi: 10.3969/j.issn.0372-2112.2017.02.001 |
|
| 83 | FERNS N , CASTRO P S , PRECUP D , et al. Methods for computing state similarity in Markov decision process[J]. Computer Science, 2012, 19 (3): 174- 181. |
| 84 | WHITESON S, TANNER B, TAYLOR M E, et al. Protecting against evaluation overfitting in empirical reinforcement learning[C]//Proc. of the IEEE Symposium on Adaptive Dynamic Programming and Reinforcement Learning, 2011: 120-127. |
| 85 | WANG H C, YANG T P, HAO J Y, et al. Heuristically adaptive policy reuse in reinforcement learning[EB/OL]. [2021-6-29]. https://ala2019.vub.ac.be/papers/ALA2019_paper_24.pdf. |
| 86 | SONG J H, GAO Y, WANG H, et al. Measuring the distance between finite Markov decision processes[C]//Proc. of the International Conference on Autonomous Agents and Multiagent Systems, 2016: 468-476. |
| 87 | BRAUN D, MAYBERRY J, POWERS A, et al. The geometry of the hausdorff metric[EB/OL]. [2020-12-16]. http://faculty.gvsu.edu/schlicks/Hausdorff_paper.pdf, 2003. |
| 88 |
DENG Y X , DU W J . The kantorovich metric in computer science: a brief survey[J]. Electronic Notes in Theoretical Computer Science, 2009, 253 (3): 73- 82.
doi: 10.1016/j.entcs.2009.10.006 |
| 89 | HO J, ERMON S. Generative adversarial imitation learning[C]//Proc. of the Advances in Neural Information Processing Systems, 2016: 4565-4573. |
| 90 | SCHULMAN J, LEVINE S, ABBEEL P, et al. Trust region policy optimization[C]//Proc. of the International Conference on Machine Learning, 2015: 1889-1897. |
| 91 | GOODFELLOW I, POUGET J, MIRZA M, et al. Generative adversarial nets[C]//Proc. of the Neural Information Proces-sing Systems, 2014: 2672-2680. |
| 92 | KANG B Y, JIE Z Q, FENG J S. Policy optimization with demonstrations[C]//Proc. of the International Conference on Machine Learning, 2018: 2474-2483. |
| 93 | SCHMITT S, HUDSON J J, ZIDEK A, et al. Kickstarting deep reinforcement learning[EB/OL]. [2020-12-16]. https://arXiv:1803.03835, 2018. |
| 94 |
SHAPLEY S . Stochastic games[J]. Proceedings of the Natio-nal Academy of Sciences, 1953, 39 (10): 1095- 1100.
doi: 10.1073/pnas.39.10.1095 |
| 95 |
ROSMAN B , HAWASLY M , RAMAMOORTHY S . Bayesian policy reuse[J]. Machine Learning, 2016, 104 (1): 99- 127.
doi: 10.1007/s10994-016-5547-y |
| 96 | ZHENG Y, MENG Z P, HAO J Y, et al. A deep bayesian po-licy reuse approach against non-stationary agents[C]//Proc. of the 32nd Conference on Neural Information Processing Systems, 2018: 962-972. |
| 97 | PABLO H, KAISERS M. Towards a fast detection of opponents in repeated stochastic games[C]//Proc. of the 1st Workshop on Transfer in Reinforcement Learning at AAMAS, 2017: 239-257. |
| 98 | CRANDALL J W. Just add Pepper: extending learning algorithms for repeated matrix games to repeated Markov games[C]//Proc. of the 11th International Conference on Autonomous Agents and Multiagent Systems, 2012: 104-111. |
| 99 | HERNANDEZ-LEAL P, TAYLOR M E, ROSMAN B S. Identifying and tracking switching, non-stationary opponents: a Bayesian approach[C]//Proc. of the AAAI Multiagent Interaction without Prior Coordination Workshop, 2016. |
| 100 | YANG T P, HAO J Y, MENG Z P, et al. Bayes-ToMoP: a fast detection and best response algorithm towards sophisticated opponents[C]//Proc. of the International Foundation for Autonomous Agents and Multiagent Systems, 2016: 2282-2284. |
| 101 | GU S, HOLLY E, LILLICRAP T, et al. Deep reinforcement learning for robotic manipulation with asynchronous off-policy updates[C]//Proc. of the IEEE International Conference on Robotics and Automation, 2017: 3389-3396. |
| 102 | RAJESWARAN A, GHOTRA S, RAVINDRAN B, et al. Epopt: learning robust neural network policies using model ensembles[C]//Proc. of the International Conference on Learning Representations, 2017. |
| 103 | CHASLOT G, SAITO J, BOUZY B, et al. Monte-Carlo strategies for computer Go[C]//Proc. of the 18th Belgian-Dutch Conference on Artificial Intelligence, 2006: 83-90. |
| 104 |
ONTANON S , SYNNAEVE G , URIARTE A , et al. A survey of real-time strategy game AI research and competition in starcraft[J]. IEEE Trans.on Computational Intelligence and AI in Games, 2013, 5 (4): 293- 311.
doi: 10.1109/TCIAIG.2013.2286295 |
| 105 | OpenAI. Dota2 blog[EB/OL]. [2020-12-16]. https://openai.com/blog/openai-five/. |
| [1] | 杨立儒, 刘永祥, 杨威. 基于迁移学习的雷达杂波幅度统计模型选择[J]. 系统工程与电子技术, 2022, 44(8): 2457-2467. |
| [2] | 朱霸坤, 朱卫纲, 李伟, 杨莹, 高天昊. 基于马尔可夫的多功能雷达认知干扰决策建模研究[J]. 系统工程与电子技术, 2022, 44(8): 2488-2497. |
| [3] | 王冠, 茹海忠, 张大力, 马广程, 夏红伟. 弹性高超声速飞行器智能控制系统设计[J]. 系统工程与电子技术, 2022, 44(7): 2276-2285. |
| [4] | 孟泠宇, 郭秉礼, 杨雯, 张欣伟, 赵柞青, 黄善国. 基于深度强化学习的网络路由优化方法[J]. 系统工程与电子技术, 2022, 44(7): 2311-2318. |
| [5] | 孙晶明, 虞盛康, 孙俊. 基于元学习的雷达小样本目标识别方法及改进[J]. 系统工程与电子技术, 2022, 44(6): 1839-1845. |
| [6] | 郭冬子, 黄荣, 许河川, 孙立伟, 崔乃刚. 再入飞行器深度确定性策略梯度制导方法研究[J]. 系统工程与电子技术, 2022, 44(6): 1942-1949. |
| [7] | 韩明仁, 王玉峰. 基于强化学习的全电推进卫星变轨优化方法[J]. 系统工程与电子技术, 2022, 44(5): 1652-1661. |
| [8] | 周晓玲, 张朝霞, 鲁雅, 王倩, 王琨琨. 基于改进R-FCN的SAR图像识别[J]. 系统工程与电子技术, 2022, 44(4): 1202-1209. |
| [9] | 吴涛, 王伦文, 朱敬成. 基于迁移学习和注意力机制的伪装图像分割[J]. 系统工程与电子技术, 2022, 44(2): 376-384. |
| [10] | 朱霸坤, 朱卫纲, 李伟, 杨莹, 高天昊. 基于先验知识的多功能雷达智能干扰决策方法[J]. 系统工程与电子技术, 2022, 44(12): 3685-3695. |
| [11] | 杨清清, 高盈盈, 郭玙, 夏博远, 杨克巍. 基于深度强化学习的海战场目标搜寻路径规划[J]. 系统工程与电子技术, 2022, 44(11): 3486-3495. |
| [12] | 曾斌, 张鸿强, 李厚朴. 针对无人潜航器的反潜策略研究[J]. 系统工程与电子技术, 2022, 44(10): 3174-3181. |
| [13] | 万齐天, 卢宝刚, 赵雅心, 温求遒. 基于深度强化学习的驾驶仪参数快速整定方法[J]. 系统工程与电子技术, 2022, 44(10): 3190-3199. |
| [14] | 曾斌, 王睿, 李厚朴, 樊旭. 基于强化学习的战时保障力量调度策略研究[J]. 系统工程与电子技术, 2022, 44(1): 199-208. |
| [15] | 江志炜, 黄洋, 吴启晖. 基于核函数强化学习的抗干扰频点分配[J]. 系统工程与电子技术, 2021, 43(6): 1547-1556. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||