
系统工程与电子技术 ›› 2022, Vol. 44 ›› Issue (1): 199-208.doi: 10.12305/j.issn.1001-506X.2022.01.25
曾斌1, 王睿2,*, 李厚朴3, 樊旭1
收稿日期:2020-11-28
出版日期:2022-01-01
发布日期:2022-01-19
通讯作者:
王睿
作者简介:曾斌(1970—), 男, 教授, 博士, 主要研究方向为信息管理|王睿(1975—), 女, 馆员, 硕士, 主要研究方向为信息管理|李厚朴(1985—), 男, 副教授, 博士, 主要研究方向为计算机代数分析|樊旭(1989—), 男, 工程师硕士, 主要研究方向为信息管理
基金资助:Bin ZENG1, Rui WANG2,*, Houpu LI3, Xu FAN1
Received:2020-11-28
Online:2022-01-01
Published:2022-01-19
Contact:
Rui WANG
摘要:
智能化后装保障调度是当前军事领域的研究热点之一, 其中复杂多变的战场环境要求战时保障具有良好的自适应性。针对此问题, 提出了基于马尔可夫决策过程的强化学习模型, 能够主动学习最佳派遣策略, 根据历史数据和当前态势预判后续变化。为了考虑不确定事件的影响, 在模型求解算法中增加了基于概率统计模型的仿真流程; 为了减少随机事件带来的计算复杂性, 利用决策后状态变量重新设计了贝尔曼迭代方程; 为了解决状态空间的维度灾问题, 提出了基于基函数组合的近似函数。仿真实验表明,强化学习能力的引入能够显著提高战时保障调度性能。
中图分类号:
曾斌, 王睿, 李厚朴, 樊旭. 基于强化学习的战时保障力量调度策略研究[J]. 系统工程与电子技术, 2022, 44(1): 199-208.
Bin ZENG, Rui WANG, Houpu LI, Xu FAN. Scheduling strategies research based on reinforcement learning for wartime support force[J]. Systems Engineering and Electronics, 2022, 44(1): 199-208.
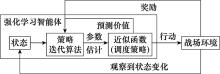
图1
调度策略强化学习流程图"
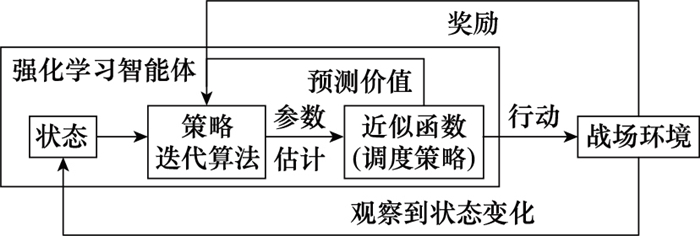
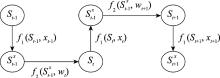
图2
阶段3的决策前和决策后状态关系"
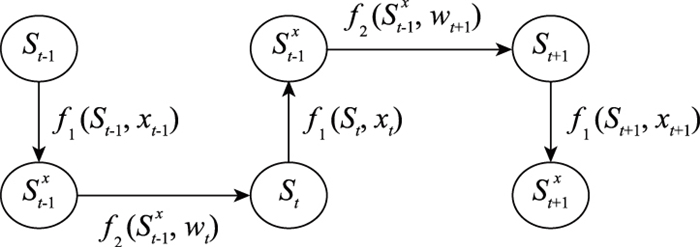
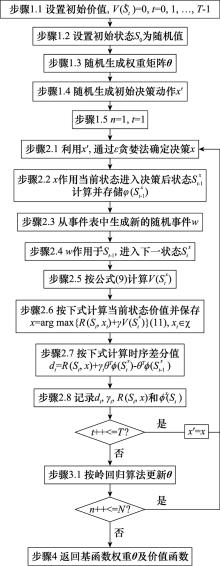
图3
基于时序差分的策略迭代算法流程图"
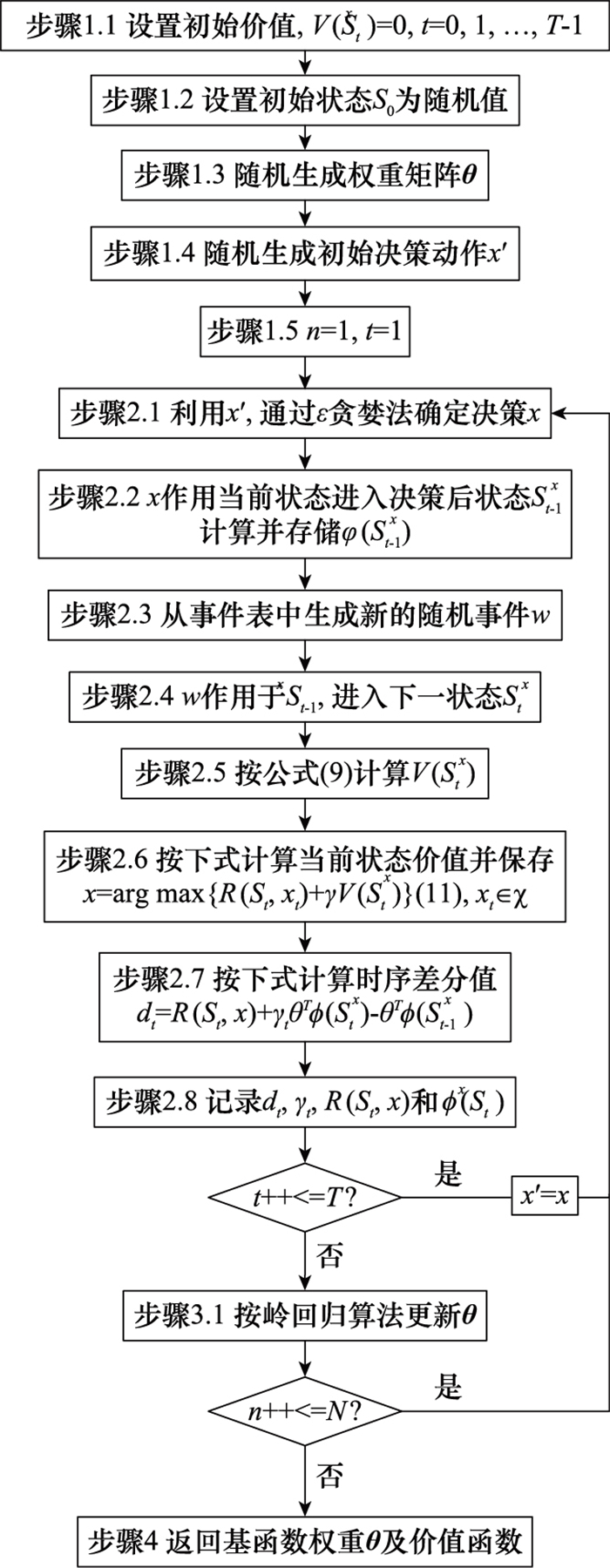
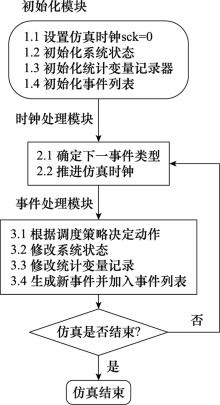
图4
仿真流程图"
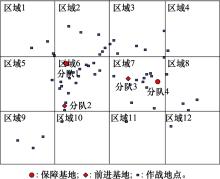
图5
作战行动场景"
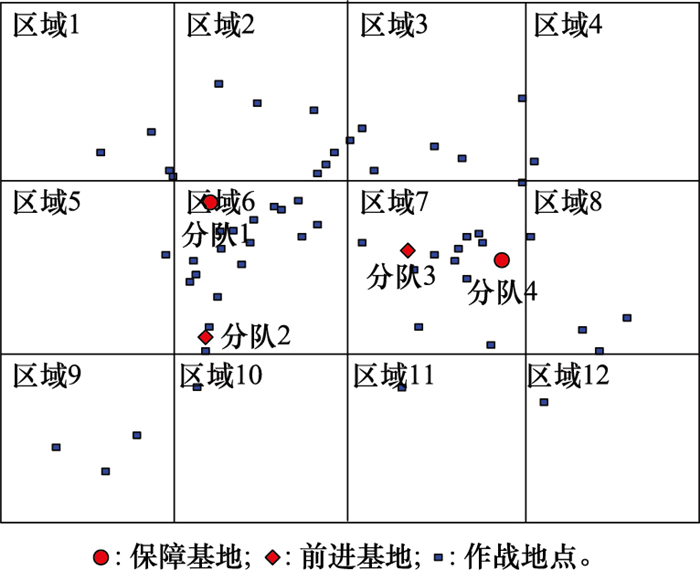
表1
按区域-优先级分类的保障申请概率"
| 作战区域 | 优先级 | ||
| 紧急 | 重要 | 一般 | |
| 1 | 0.008 0 | 0.008 0 | 0.034 1 |
| 2 | 0.018 2 | 0.018 2 | 0.077 3 |
| 3 | 0.015 0 | 0.015 0 | 0.063 9 |
| 4 | 0.002 7 | 0.002 7 | 0.011 4 |
| 5 | 0.004 6 | 0.004 6 | 0.019 3 |
| 6 | 0.049 6 | 0.049 6 | 0.210 9 |
| 7 | 0.034 8 | 0.034 8 | 0.148 0 |
| 8 | 0.009 5 | 0.009 5 | 0.040 4 |
| 9 | 0.008 7 | 0.008 7 | 0.037 0 |
| 10 | 0.004 6 | 0.004 6 | 0.019 5 |
| 11 | 0.002 8 | 0.002 8 | 0.011 9 |
| 12 | 0.001 5 | 0.001 5 | 0.006 0 |
表2
保障分队至各区域运输时间均值"
| 作战区域 | 保障分队 | |||
| 分队1 | 分队2 | 分队3 | 分队4 | |
| 1 | 51.689 | 66.657 | 73.665 | 83.989 |
| 2 | 58.997 | 73.966 | 65.113 | 73.639 |
| 3 | 73.381 | 83.702 | 63.339 | 66.146 |
| 4 | 83.129 | 90.959 | 66.423 | 62.208 |
| 5 | 45.475 | 52.612 | 65.170 | 75.718 |
| 6 | 48.728 | 52.504 | 58.221 | 68.596 |
| 7 | 66.371 | 67.606 | 45.847 | 45.999 |
| 8 | 86.781 | 86.022 | 64.537 | 55.094 |
| 9 | 100.590 | 84.631 | 108.610 | 116.710 |
| 10 | 75.851 | 58.163 | 81.231 | 89.782 |
| 11 | 77.564 | 69.977 | 62.538 | 64.677 |
| 12 | 94.617 | 90.921 | 72.327 | 63.278 |
表3
设计方案对应的计算时间"
| 实验方案序号 | N | T | 计算时间/s |
| 1 | 5 | 5 000 | 18.5 |
| 2 | 5 | 10 000 | 38.7 |
| 3 | 5 | 20 000 | 75.2 |
| 4 | 10 | 5 000 | 37.6 |
| 5 | 10 | 10 000 | 74.9 |
| 6 | 10 | 20 000 | 151.3 |
| 7 | 20 | 5 000 | 74.6 |
| 8 | 20 | 10 000 | 149.2 |
| 9 | 20 | 20 000 | 301.3 |
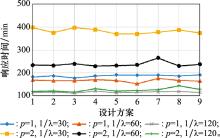
图6
不同设计方案下的保障响应时间"
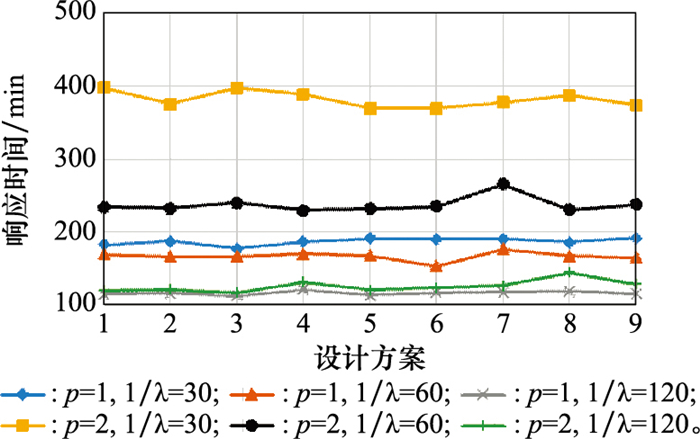
表4
不同场景下优化分配策略"
| 作战区域 | 系统状态场景 | |||||
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 1 | 1 | 2 | 1 | 3 | 1 | 2 |
| 2 | 1 | 3 | 1 | 3 | 1 | 3 |
| 3 | 3 | 3 | 3 | 3 | 1 | 3 |
| 4 | 4 | 4 | 3 | 4 | 1 | 3 |
| 5 | 1 | 2 | 1 | 3 | 1 | 2 |
| 6 | 1 | 2 | 1 | 3 | 1 | 2 |
| 7 | 4+ | 4+ | 3 | 4+ | 2+ | 3 |
| 8 | 4 | 4 | 3 | 4 | 2 | 3 |
| 9 | 2 | 2 | 2 | 3 | 2 | 2 |
| 10 | 2 | 2 | 2 | 3 | 2 | 2 |
| 11 | 4+ | 4+ | 3 | 4+ | 2 | 3 |
| 12 | 4 | 4 | 3 | 4 | 2 | 3 |
表5
实验比较结果"
| 1/λ | 改时率/% | URT/s | IRT/s | Busy/% | CT/s |
| 30 | 55.9±0.86 | 191.5 | 368.9 | 88.9 | 75.6 |
| 60 | 29.8±1.06 | 155.0 | 236.5 | 81.2 | 148.8 |
| 120 | 1.1±1.53 | 115.6 | 123.7 | 32.5 | 74.6 |
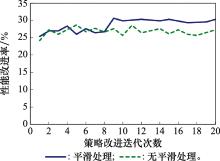
图7
平滑函数对算法性能的影响"
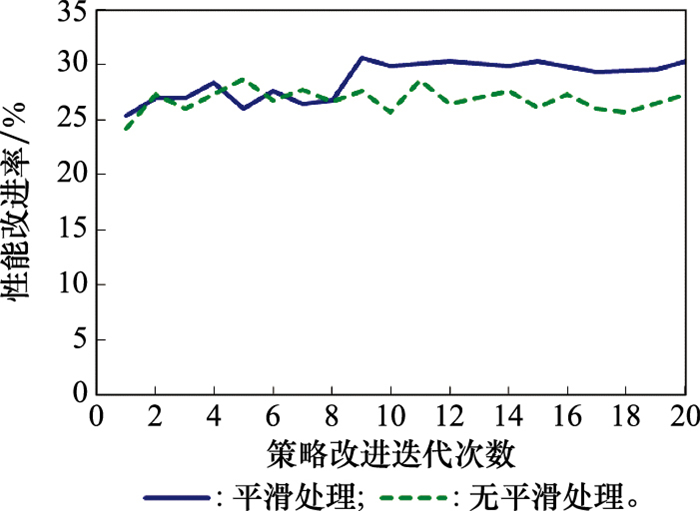
图8
相较最近分配的性能改进率"
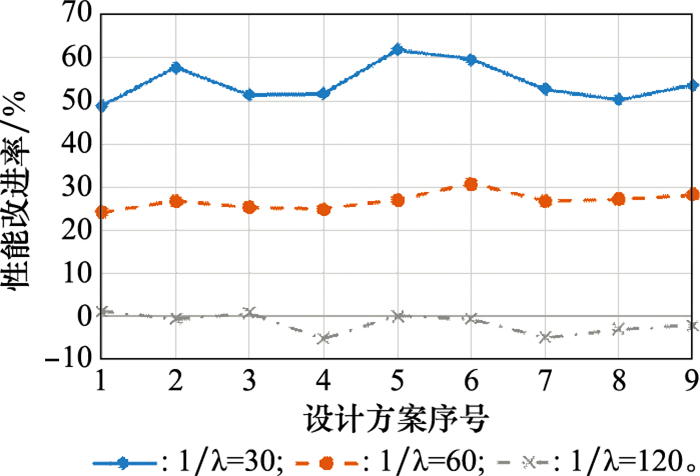

图9
优先级比例变化的影响"
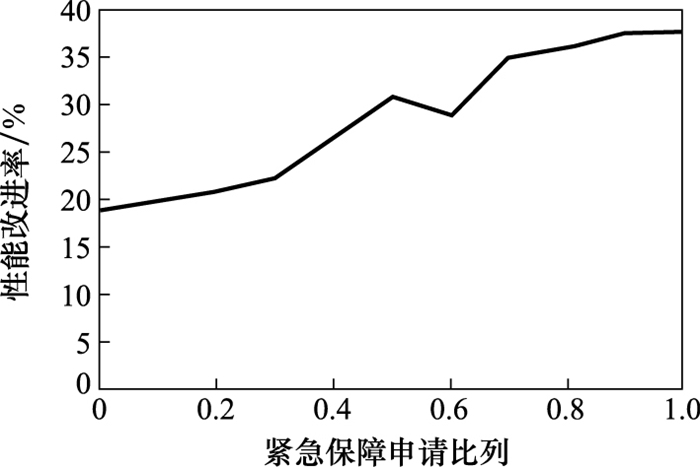
表6
速度提高时最近分配策略的性能"
| Spd Inc | 改进率/% | URT/min | IRT/min | 占用率/% |
| 基准速度 | - | 285.4 | 286.7 | 89.3% |
| 25 | 50.1 | 168.5 | 166.8 | 78.6 |
| 50 | 89.5 | 104.8 | 104.1 | 61.6 |
| 75 | 126.1 | 77.2 | 76.8 | 47.8 |
表7
速度提高时优化分配策略的性能"
| Spd Inc | 改进率/% | URT/min | IRT/min | 占用率/% |
| 基准速度 | 30.8 | 152.6 | 236.5 | 81.0 |
| 25 | 68.3 | 117.2 | 141.7 | 69.6 |
| 50 | 102.8 | 90.8 | 103.4 | 56.6 |
| 75 | 127.1 | 77.8 | 81.5 | 46.9 |
| 1 |
XUE B , TONG N N . DIOD: fast and efficient weakly semi-supervised deep complex ISAR object detection[J]. IEEE Trans.on Cybernetics, 2019, 49 (11): 3991- 4003.
doi: 10.1109/TCYB.2018.2856821 |
| 2 |
XUE B , TONG N N . Real-world ISAR object recognition using deep multimodal relation learning[J]. IEEE Trans.on Cybernetics, 2020, 50 (10): 4256- 4267.
doi: 10.1109/TCYB.2019.2933224 |
| 3 |
昝翔, 陈春良, 张仕新, 等. 多约束条件下战时装备维修任务分配方法[J]. 兵工学报, 2017, 38 (8): 1603- 1609.
doi: 10.3969/j.issn.1000-1093.2017.08.019 |
|
ZAN X , CHEN C L , ZHANG S X , et al. Task allocation method for wartime equipment maintenance under multiple constraint conditions[J]. Acta Armamentarii, 2017, 38 (8): 1603- 1609.
doi: 10.3969/j.issn.1000-1093.2017.08.019 |
|
| 4 | 何岩, 赵劲松, 王少聪, 等. 基于维修优先级的战时装备维修保障力量优化调度[J]. 军事交通学院学报, 2019, 21 (5): 42- 46. |
| HE Y , ZHAO J S , WANG S C , et al. Maintenance priority-based optimization and scheduling of equipment maintenance support strength in wartime[J]. Journal of Military Transportation University, 2019, 21 (5): 42- 46. | |
| 5 | 曾斌, 姚路, 胡炜, 等. 考虑不确定因素影响的保障任务调度算法[J]. 系统工程与电子技术, 2016, 38 (3): 595- 601. |
| ZENG B , YAO L , HU W , et al. Scheduling algorithm for maintenance tasks under uncertainty[J]. Systems Engineering and Electronics, 2016, 38 (3): 595- 601. | |
| 6 |
刘彦, 陈春良, 昝翔, 等. 复杂约束条件下伴随修理任务多目标动态调度[J]. 兵工学报, 2019, 40 (3): 621- 628.
doi: 10.3969/j.issn.1000-1093.2019.03.022 |
|
LIU Y , CHEN C L , ZAN X , et al. Multi-objective dynamic scheduling with accompanying repair tasks under complex constraints[J]. Acta Armamentarii, 2019, 40 (3): 621- 628.
doi: 10.3969/j.issn.1000-1093.2019.03.022 |
|
| 7 |
任帆, 吕学志, 王宪文, 等. 巡回修理中的维修任务调度策略[J]. 火力与指挥控制, 2013, 38 (12): 171- 175.
doi: 10.3969/j.issn.1002-0640.2013.12.045 |
|
REN F , LYU X Z , WANG X W , et al. Research on maintenance task scheduling strategies in contact repairing[J]. Fire Control & Command Control, 2013, 38 (12): 171- 175.
doi: 10.3969/j.issn.1002-0640.2013.12.045 |
|
| 8 | DAVIS L T , BEERY P , PAULO E . Investigation of integration and potential conflicts for distributed maritime operations and integrated air and missile defense[J]. Naval Engineers Journal, 2020, 132 (1): 83- 95. |
| 9 | DAY W G , COOPER E , PHUNG K , et al. Prolonged stabilization during a mass casualty incident at sea in the era of distributed maritime operations[J]. Military medicine, 2020, 185 (11): 2192- 2197. |
| 10 | 令狐昌应, 王少聪, 李文羚, 等. 战时装备维修保障方案生成与优化需求分析[J]. 军事交通学院学报, 2020, 22 (1): 24- 28. |
| LINGHU C Y , WANG S C , LI W L , et al. Analysis on generation and optimization of equipment maintenance support plan in wartime[J]. Journal of Military Transportation University, 2020, 22 (1): 24- 28. | |
| 11 | JI S G , ZHENG Y , WANG Z Y , et al. A deep reinforcement learning-enabled dynamic redeployment system for mobile ambulances[J]. Proc.of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 2019, 3 (1): 1- 20. |
| 12 |
HAMASHA M M , RUMBE G . Determining optimal policy for emergency department using Markov decision process[J]. World Journal of Engineering, 2017, 14 (5): 467- 472.
doi: 10.1108/WJE-12-2016-0148 |
| 13 |
NI Y , WANG K , ZHAO L D . A Markov decision process model of allocating emergency medical resource among multi-priority injuries[J]. International Journal of Mathematics in Operational Research, 2017, 10 (1): 1- 17.
doi: 10.1504/IJMOR.2017.080738 |
| 14 | JOO S H, OGAWA Y, SEKIMOTO Y. Decision-Making system for road-recovery considering human mobility by applying deep q-network[C]//Proc. of the IEEE International Conference on Big Data, 2019: 4075-4084. |
| 15 | WAGNER J, ROOPAEI M. Edge based decision making in disaster response systems[C]//Proc. of the 10th Annual Computing and Communication Workshop and Conference, 2020: 469-473. |
| 16 |
KENEALLY S K , ROBBINS M J , LUNDAY B J . A Markov decision process model for the optimal dispatch of military medical evacuation assets[J]. Health Care Management Science, 2016, 19 (2): 111- 129.
doi: 10.1007/s10729-014-9297-8 |
| 17 |
HUANG Q , HUANG R H , HAO W , et al. Adaptive power system emergency control using deep reinforcement learning[J]. IEEE Trans.on Smart Grid, 2020, 11 (2): 1171- 1182.
doi: 10.1109/TSG.2019.2933191 |
| 18 |
BAI W W , LI T S , TONG S C . NN reinforcement learning adaptive control for a class of nonstrict-feedback discrete-time systems[J]. IEEE Trans.on Cybernetics, 2020, 50 (11): 4573- 4584.
doi: 10.1109/TCYB.2020.2963849 |
| 19 | KLINK P, ABDULSAMAD H, BELOUSOV B, et al. Self-paced contextual reinforcement learning[C]//Proc. of the Conference on Robot Learning, 2020: 513-529. |
| 20 | WANG C , JU P , LEI S B , et al. Markov decision process-based resilience enhancement for distribution systems: an approximate dynamic programming approach[J]. IEEE Trans.on Smart Grid, 2019, 11 (3): 2498- 2510. |
| 21 |
WANG C , LEI S B , JU P , et al. MDP-based distribution network reconfiguration with renewable distributed generation: approximate dynamic programming approach[J]. IEEE Trans.on Smart Grid, 2020, 11 (4): 3620- 3631.
doi: 10.1109/TSG.2019.2963696 |
| 22 | YU X , SHEN S Q . An integrated decomposition and approximate dynamic programming approach for on-demand ride pooling[J]. IEEE Trans.on Intelligent Transportation Systems, 2019, 21 (9): 3811- 3820. |
| 23 |
DORNHEIM J , LINK N , GUMBSCH P . Model-free adaptive optimal control of episodic fixed-horizon manufacturing processes using reinforcement learning. international journal of control[J]. Automation and Systems, 2020, 18 (6): 1593- 604.
doi: 10.1007/s12555-019-0120-7 |
| 24 |
ULMER M W , GOODSON J C , MATTFELD D C , et al. Offline-online approximate dynamic programming for dynamic vehicle routing with stochastic requests[J]. Transportation Science, 2019, 53 (1): 185- 202.
doi: 10.1287/trsc.2017.0767 |
| 25 |
LEI L , XU H J , XIONG X , et al. Joint computation offloading and multiuser scheduling using approximate dynamic programming in NB-IoT edge computing system[J]. IEEE Internet of Things Journal, 2019, 6 (3): 5345- 5362.
doi: 10.1109/JIOT.2019.2900550 |
| 26 | DAI J G , SHI P . Inpatient overflow: an approximate dynamic programming approach[J]. Manufacturing & Service Operations Management, 2019, 21 (4): 894- 911. |
| 27 |
BIKKER I A , MES M R K , SAURÉ A , et al. Online capacity planning for rehabilitation treatments: an approximate dynamic programming approach[J]. Probability in the Engineering and Informational Sciences, 2020, 34 (3): 381- 405.
doi: 10.1017/S0269964818000402 |
| 28 | BHANDARI J, RUSSO D, SINGAL R. A finite time analysis of temporal difference learning with linear function approximation[C]//Proc. of the Conference on Learning Theory. 2018: 1691-1692. |
| 29 |
XIE W J , DENG X W . Scalable algorithms for the sparse ridge regression[J]. SIAM Journal on Optimization, 2020, 30 (4): 3359- 3386.
doi: 10.1137/19M1245414 |
| 30 | DOS SANTOS MIGNON A , DA ROCHA R L A . An adaptive implementation of ε-greedy in reinforcement learning[J]. Procedia Computer Science, 2017, 109 (2): 1146- 1151. |
| [1] | 朱霸坤, 朱卫纲, 李伟, 杨莹, 高天昊. 基于马尔可夫的多功能雷达认知干扰决策建模研究[J]. 系统工程与电子技术, 2022, 44(8): 2488-2497. |
| [2] | 王冠, 茹海忠, 张大力, 马广程, 夏红伟. 弹性高超声速飞行器智能控制系统设计[J]. 系统工程与电子技术, 2022, 44(7): 2276-2285. |
| [3] | 孟泠宇, 郭秉礼, 杨雯, 张欣伟, 赵柞青, 黄善国. 基于深度强化学习的网络路由优化方法[J]. 系统工程与电子技术, 2022, 44(7): 2311-2318. |
| [4] | 郭冬子, 黄荣, 许河川, 孙立伟, 崔乃刚. 再入飞行器深度确定性策略梯度制导方法研究[J]. 系统工程与电子技术, 2022, 44(6): 1942-1949. |
| [5] | 韩明仁, 王玉峰. 基于强化学习的全电推进卫星变轨优化方法[J]. 系统工程与电子技术, 2022, 44(5): 1652-1661. |
| [6] | 何立, 沈亮, 李辉, 王壮, 唐文泉. 强化学习中的策略重用: 研究进展[J]. 系统工程与电子技术, 2022, 44(3): 884-899. |
| [7] | 朱霸坤, 朱卫纲, 李伟, 杨莹, 高天昊. 基于先验知识的多功能雷达智能干扰决策方法[J]. 系统工程与电子技术, 2022, 44(12): 3685-3695. |
| [8] | 杨清清, 高盈盈, 郭玙, 夏博远, 杨克巍. 基于深度强化学习的海战场目标搜寻路径规划[J]. 系统工程与电子技术, 2022, 44(11): 3486-3495. |
| [9] | 曾斌, 张鸿强, 李厚朴. 针对无人潜航器的反潜策略研究[J]. 系统工程与电子技术, 2022, 44(10): 3174-3181. |
| [10] | 万齐天, 卢宝刚, 赵雅心, 温求遒. 基于深度强化学习的驾驶仪参数快速整定方法[J]. 系统工程与电子技术, 2022, 44(10): 3190-3199. |
| [11] | 江志炜, 黄洋, 吴启晖. 基于核函数强化学习的抗干扰频点分配[J]. 系统工程与电子技术, 2021, 43(6): 1547-1556. |
| [12] | 曾斌, 姚路, 李厚朴. 警戒海域反潜直升机优化调度研究[J]. 系统工程与电子技术, 2021, 43(6): 1586-1595. |
| [13] | 曾斌, 张泉先, 李厚朴. 不确定条件下后装协同保障链优化调度[J]. 系统工程与电子技术, 2021, 43(5): 1277-1286. |
| [14] | 刘家义, 岳韶华, 王刚, 姚小强, 张杰. 复杂任务下的多智能体协同进化算法[J]. 系统工程与电子技术, 2021, 43(4): 991-1002. |
| [15] | 闫安, 陈章, 董朝阳, 何康辉. 基于模糊强化学习的双轮机器人姿态平衡控制[J]. 系统工程与电子技术, 2021, 43(4): 1036-1043. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||