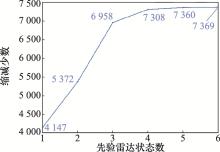
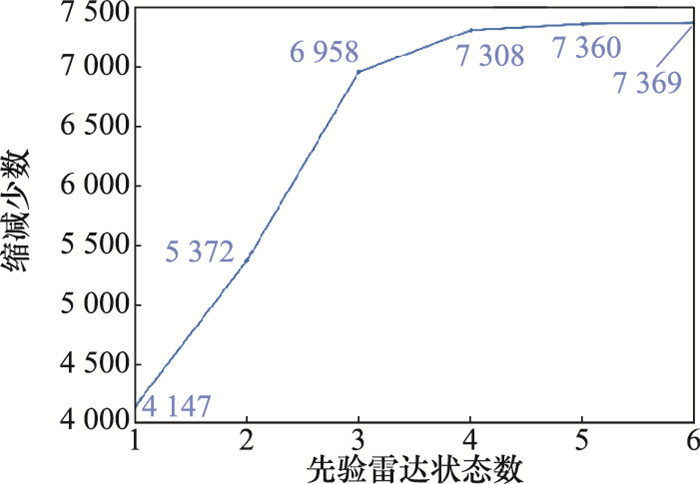
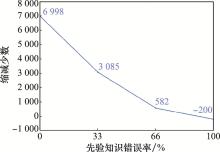
| 1 |
MARK A R , JAMES A S , WILLIAM A H . Principles of modern radar: basic principles[M]. Raleigh, NC, USA: Scitech, 2010.
|
| 2 |
王沙飞, 李岩, 徐迈, 等. 认知电子战原理与技术[M]. 北京: 国防工业出版社, 2018.
|
|
WANG S F , LI Y , XU M , et al. Principle and technology of cognitive electronic warfare[M]. Beijing: National Defense Industry Press, 2018.
|
| 3 |
LI K , JIU B , LIU H W , et al. Game theoretic strategies design for monostatic radar and jammer based on mutual information[J]. IEEE Access, 2019, 7, 72257- 72266.
doi: 10.1109/ACCESS.2019.2920398
|
| 4 |
SONG X F, WILLETT P, ZHOU S L, et al. The power game between a MIMO radar and jammer[C]//Proc. of the IEEE International Conference on Acoustics, Speech and Signal Processing, 2012.
|
| 5 |
SONG X F , WILLETT P , ZHOU S L , et al. The MIMO radar and jammer games[J]. IEEE Trans.on Signal Processing, 2011, 60 (2): 687- 699.
|
| 6 |
赫彬, 苏洪涛. 认知雷达抗干扰中的博弈论分析综述[J]. 电子与信息学报, 2021, 43 (5): 1199- 1211.
|
|
HE B , SU H T . A review of game theory analysis in cognitive radar anti-jamming[J]. Journal of Electronics and Information Technology, 2021, 43 (5): 1199- 1211.
|
| 7 |
HAN L , NING Q , CHEN B C , et al. Ground threat evaluation and jamming allocation model with Markov chain for aircraft[J]. IET Radar, Sonar & Navigation, 2020, 14 (7): 1039- 1045.
|
| 8 |
OSNER N R , DU PLESSIS W P . Threat evaluation and jamming allocation[J]. IET Radar Sonar & Navigation, 2017, 11 (3): 459- 465.
|
| 9 |
LI T P , WANG Z L , LIU J Y . Evaluating effect of blanket jamming on radar via robust time-frequency analysis and peak to average power ratio[J]. IEEE Access, 2020, 8, 214504- 214519.
doi: 10.1109/ACCESS.2020.3040514
|
| 10 |
邢强, 朱卫纲, 贾鑫, 等. 干扰规则库未知条件下的干扰决策[J]. 系统工程与电子技术, 2019, 41 (2): 298- 303.
|
|
XING Q , ZHU W G , JIA X , et al. Jamming decision under condition of unknown jamming rule base[J]. Systems Engineering and Electronics, 2019, 41 (2): 298- 303.
|
| 11 |
TANG Z , GAO X G . Research on the self-defence electronic jamming decision-making based on the discrete dynamic Bayesian network[J]. Journal of Systems Engineering and Electronics, 2008, 19 (4): 702- 708.
doi: 10.1016/S1004-4132(08)60142-5
|
| 12 |
SILVER D , SCHRITTWIESER J , SIMONYAN K , et al. Mastering the game of go without human knowledge[J]. Nature, 2017, 550 (7676): 354- 359.
doi: 10.1038/nature24270
|
| 13 |
YOO J , JANG D , KIM H J , et al. Hybrid reinforcement learning control for a micro quadrotor flight[J]. IEEE Control Systems Letters, 2020, 5 (2): 505- 510.
|
| 14 |
GUO X X , YAN W S , CUI R X . Reinforcement learning-based nearly optimal control for constrained-input partially unknown systems using differentiator[J]. IEEE Trans.on Neural Networks and Learning Systems, 2019, 31 (11): 4713- 4725.
|
| 15 |
MANDOW L , PÉREZ-DE-LA-CRUZ J L , RODRÍGUEZ-GAVILÁN A B , et al. Architectural planning with shape grammars and reinforcement learning: habitability and energy efficiency[J]. Engineering Applications of Artificial Intelligence, 2020, 96, 103909.
doi: 10.1016/j.engappai.2020.103909
|
| 16 |
WU J D , ZHONG B W , LI W H , et al. Battery thermal-and health-constrained energy management for hybrid electric bus based on soft actor-critic DRL algorithm[J]. IEEE Trans.on Industrial Informatics, 2020, 17 (6): 3751- 3761.
|
| 17 |
WU J D , ZHONG B W , LIU K L , et al. Battery-involved energy management for hybrid electric bus based on expert-assistance deep deterministic policy gradient algorithm[J]. IEEE Trans.on Vehicular Technology, 2020, 69 (11): 12786- 12796.
doi: 10.1109/TVT.2020.3025627
|
| 18 |
PARK H , SIM M K , CHOI D . An intelligent financial portfolio trading strategy using deep Q-learning[J]. Expert Systems with Applications, 2020, 158, 113573.
doi: 10.1016/j.eswa.2020.113573
|
| 19 |
李云杰, 朱云鹏, 高梅国. 基于Q-学习算法的认知雷达对抗过程设计[J]. 北京理工大学学报, 2015, 35 (11): 1194- 1199.
|
|
LI Y J , ZHU Y P , GAO M J . Design of cognitive radar jamming based on Q-learning algorithm[J]. Transactions of Beijing Institute of Technology, 2015, 35 (11): 1194- 1199.
|
| 20 |
WANG Y H, ZHANG T X, XU L X, et al. Model-free reinforcement learning based multi-stage smart noise jamming[C]// Proc. of the IEEE Radar Conference, 2019.
|
| 21 |
邢强, 贾鑫, 朱卫纲. 基于Q-学习的智能雷达对抗[J]. 系统工程与电子技术, 2018, 40 (5): 1031- 1035.
|
|
XING Q , JIA X , ZHU W G . Intelligent radar countermeasure based on Q-learning[J]. Systems Engineering and Electronics, 2018, 40 (5): 1031- 1035.
|
| 22 |
张柏开, 朱卫纲. 对多功能雷达的DQN认知干扰决策方法[J]. 系统工程与电子技术, 2020, 42 (4): 819- 825.
|
|
ZHANG B K , ZHU W G . DQN based decision-making method of cognitive jamming against multifunctional radar[J]. Systems Engineering and Electronics, 2020, 42 (4): 819- 825.
|
| 23 |
ZHONG J , WANG T , CHENG L L , et al. Collision-free path planning for welding manipulator via hybrid algorithm of deep reinforcement learning and inverse kinematics[J]. Complex & Intelligent Systems, 2022, 8, 1899- 1912.
|
| 24 |
SHI Q , WANG D Y , LYU L , et al. Deep reinforcement learning-based attitude motion control for humanoid robots with stability constraints[J]. Industrial Robot: the International Journal of Robotics Research and Application, 2020, 47 (3): 335- 347.
doi: 10.1108/IR-11-2019-0240
|
| 25 |
YANG S D, WANG H, GAO Y, et al. An optimal algorithm for the stochastic bandits with knowing near-optimal mean reward[C]//Proc. of the 17th International Conference on Autonomous Agents and Multi Agent Systems, 2018: 2130-2132.
|
| 26 |
SUI Z Z , PU Z Q , YI J Q , et al. Formation control with collision avoidance through deep reinforcement learning using model- guided demonstration[J]. IEEE Trans.on Neural Networks and Learning Systems, 2020, 32 (6): 2358- 2372.
|
| 27 |
SUTTON R S , BARTO A G . Reinforcement learning: an introduction[M]. 2nd ed Cambridge, Massachusetts USA: MIT Press, 2018.
|
| 28 |
WATKINS C J , DAYAN P J M L . Q-learning[J]. Machine Learning, 1992, 8 (3): 279- 292.
|
| 29 |
VISNEVSKI N, KRISHNAMURTHY V, HAYKIN S, et al. Multi-function radar emitter modelling: a stochastic discrete event system approach[C]//Proc. of the IEEE 42nd International Conference on Decision and Control, 2003: 6295-6300.
|
| 30 |
VISNEVSKI N , KRISHNAMURTHY V , WANG A , et al. Syntactic modeling and signal multifunction radars: a stochastic context-free grammar approach[J]. Proceedings of the IEEE, 2007, 95 (5): 1000- 1025.
|
| 31 |
张光义. 相控阵雷达技术[M]. 北京: 国防工业出版社, 2009: 30- 32.
|
|
ZHANG G Y . Phased array radar technology[M]. Beijing: National Defense Industry Press, 2009: 30- 32.
|
| 32 |
LIU Z M . Recognition of multifunction radars via hierarchically mining and exploiting pulse group patterns[J]. IEEE Trans.on Aerospace and Electronic Systems, 2020, 56 (6): 4659- 4672.
|
| 33 |
XU X S , BI D P , PAN J F . Method for functional state recognition of multifunction radars based on recurrent neural networks[J]. IET Radar, Sonar & Navigation, 2021, 15 (7): 724- 732.
|
| 34 |
MIRANDA S , BAKER C , WOODBRIDGE K , et al. Comparison of scheduling algorithms for multifunction radar[J]. IET Radar, Sonar & Navigation, 2007, 1 (6): 414- 424.
|
| 35 |
NGUYEN N H , DOǦANÇAY K , DAVIS L M . Adaptive waveform and Cartesian estimate selection for multistatic target tracking[J]. Signal Processing, 2015, 111, 13- 25.
|
| 36 |
ORMAN A , POTTS C N , SHAHANI A , et al. Scheduling for a multifunction phased array radar system[J]. European Journal of Operational research, 1996, 90 (1): 13- 25.
|
| 37 |
ROY V , SIMONETTO A , LEUS G . Spatio-temporal sensor management for environmental field estimation[J]. Signal Processing, 2016, 128, 369- 381.
|
| 38 |
NG A Y , HARADA D , RUSSELL S . Policy invariance under reward transformations: theory and application to reward shaping[J]. ICML, 1999, 99, 278- 287.
|
| 39 |
GUO Q , NAN P L , WAN J . Signal classification method based on data mining for multi-mode radar[J]. Journal of Systems Engineering and Electronics, 2016, 27 (5): 1010- 1017.
|