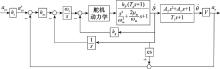
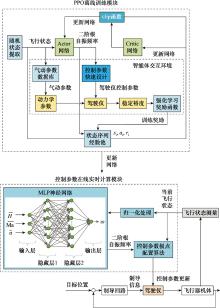
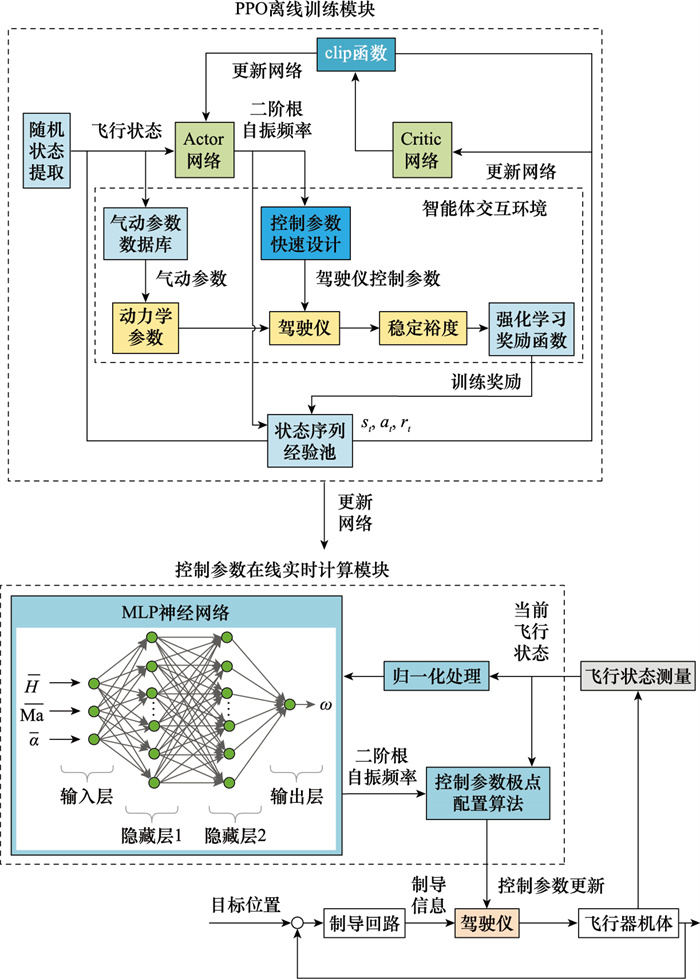
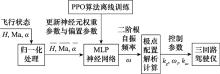
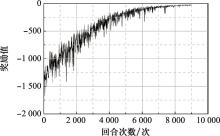
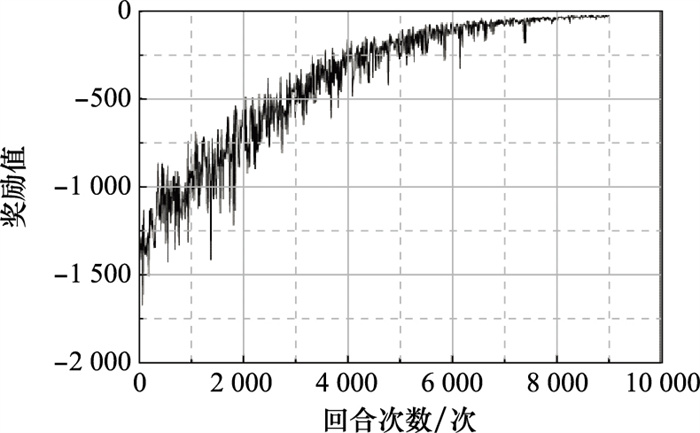
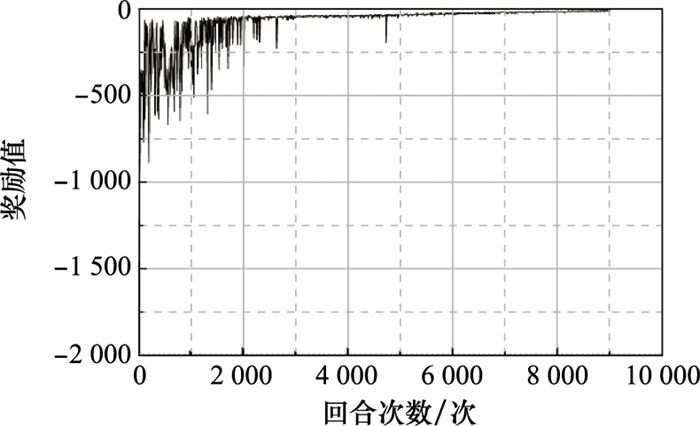
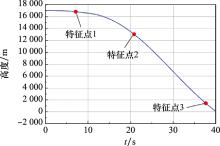
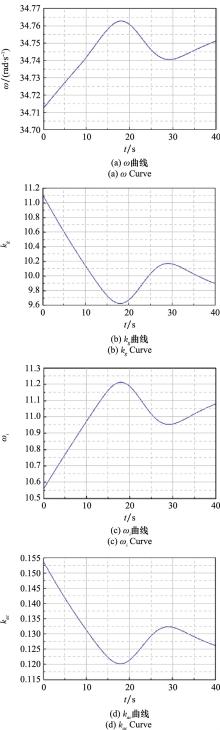
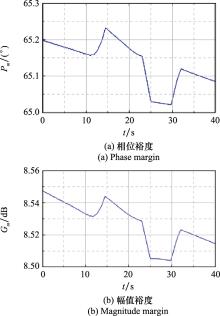
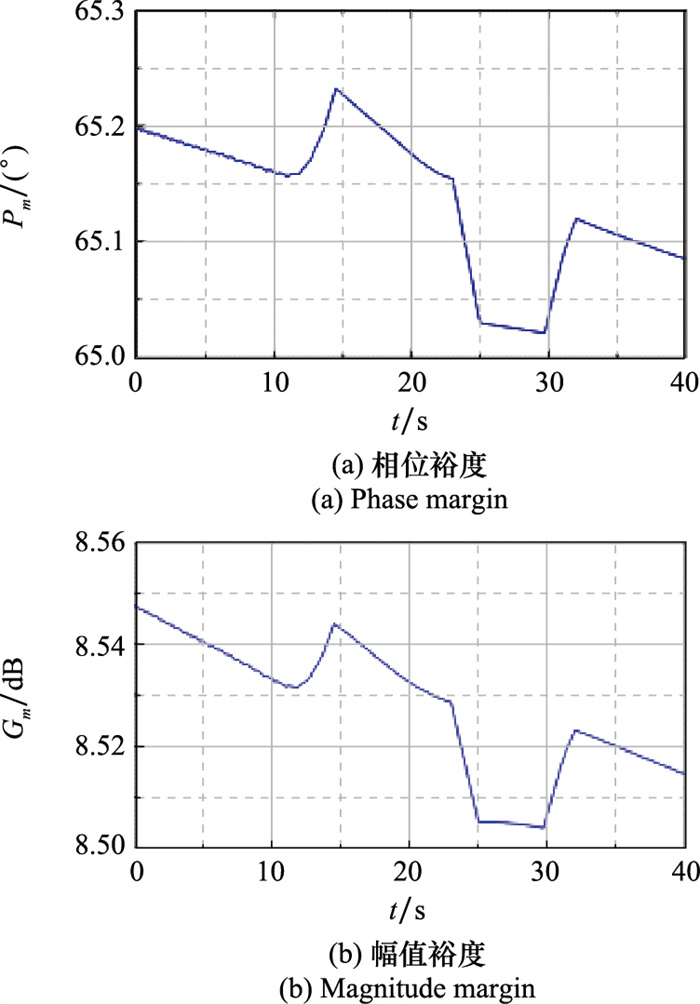
| 1 |
GARNELL P . Guided weapon control systems[M]. Oxford: Pergamon Press, 1980.
|
| 2 |
温求遒, 夏群力, 祁载康. 三回路驾驶仪开环穿越频率约束极点配置设计[J]. 系统工程与电子技术, 2009, 31 (2): 420- 423.
doi: 10.3321/j.issn:1001-506X.2009.02.039
|
|
WEN Q Q , XIA Q L , QI Z K . Pole placement design with open-loop crossover frequency constraint for three-loop autopilot[J]. Systems Engineering and Electronics, 2009, 31 (2): 420- 423.
doi: 10.3321/j.issn:1001-506X.2009.02.039
|
| 3 |
孙宝彩, 祁载康. 带状态反馈约束的驾驶仪极点配置设计方法[J]. 系统仿真学报, 2006, 18, 892- 896.
doi: 10.3969/j.issn.1004-731X.2006.z2.252
|
|
SUN B C , QI Z K . Study of pole placement method for state feedback constrained autopilot design[J]. Journal of System Simulation, 2006, 18, 892- 896.
doi: 10.3969/j.issn.1004-731X.2006.z2.252
|
| 4 |
朱敬举, 祁载康, 夏群力. 三回路驾驶仪的极点配置方法设计[J]. 弹箭与制导学报, 2007, 27 (4): 8- 12.
doi: 10.3969/j.issn.1673-9728.2007.04.003
|
|
ZHU J J , QI Z K , XIA Q L . Pole assignment method for three-loop autopilot design[J]. Journal of Projectiles, Rockets, Missiles and Guidance, 2007, 27 (4): 8- 12.
doi: 10.3969/j.issn.1673-9728.2007.04.003
|
| 5 |
王辉, 林德福, 祁载康. 导弹伪攻角反馈三回路驾驶仪设计分析[J]. 系统工程与电子技术, 2012, 34 (1): 129- 135.
|
|
WANG H , LIN D F , QI Z K . Design and analysis of missile three-loop autopilot with pseudo-angle of attack feedback[J]. Systems Engineering and Electronics, 2012, 34 (1): 129- 135.
|
| 6 |
ZENG X , ZHU Y W , YANG L , et al. A guidance method for coplanar orbital interception based on reinforcement learning[J]. Journal of Systems Engineering and Electronics, 2021, 32 (4): 927- 938.
doi: 10.23919/JSEE.2021.000079
|
| 7 |
LI Y , QIU X H , LIU X D , et al. Deep reinforcement learning and its application in autonomous fitting optimization for attack areas of UCAVs[J]. Journal of Systems Engineering and Electronics, 2020, 31 (4): 734- 742.
doi: 10.23919/JSEE.2020.000048
|
| 8 |
MA Y , CHANG T Q , FAN W H . A single-task and multi-decision evolutionary game model based on multi-agent reinforcement learning[J]. Journal of Systems Engineering and Electronics, 2021, 32 (3): 642- 657.
doi: 10.23919/JSEE.2021.000055
|
| 9 |
MIN F , FRANS C G . Collaborative multi-agent reinforcement learning based on experience propagation[J]. Journal of Systems Engineering and Electronics, 2013, 24 (4): 683- 689.
doi: 10.1109/JSEE.2013.00079
|
| 10 |
RICHARD S S , ANDREW G B . Reinforcement learning: an introduction[M]. 2nd ed Cambridge, Massachusetts: The MIT Press, 2014.
|
| 11 |
LAKSHAY A, ATRI D. Reinforcement learning for sequential low-thrust orbit raising problem[C]//Proc. of the AIAA SciTech Forum, 2020.
|
| 12 |
MARGHERITA P, MICHÈLE L. Deep reinforcement learning approach for small bodies shape reconstruction enhancement[C]//Proc. of the AIAA SciTech Forum, 2020.
|
| 13 |
CAN B, BURAK Y, GOKHAN I. High fidelity progressive reinforcement learning for agile maneuvering UAVs[C]//Proc. of the AIAA SciTech Forum, 2020.
|
| 14 |
HANNAH C L, JOHN V. Application of computational intelligence for command & control of unmanned air systems[C]//Proc. of the AIAA SciTech Forum, 2019.
|
| 15 |
JACOB G E , ROHAN S . Bridging reinforcement learning and online learning for spacecraft attitude control[J]. Journal of Aerospace Information Systems, 2022, 19 (1): 62- 69.
doi: 10.2514/1.I010958
|
| 16 |
SATOSHI S , SATASHI S , AKIRA O , et al. Closed-loop flow separation control using the deep Q network over airfoil[J]. AIAA Journal, 2020, 10 (58): 4260- 4270.
|
| 17 |
ROBERT C, LIAM F, COLIN G, et al. Closed-loop Q-learning control of a small unmanned aircraft[C]//Proc. of the AIAA SciTech Forum, 2020.
|
| 18 |
SHANELLE G C, INSEOK H. Deep reinforcement learning control for aerobatic maneuvering of agile fixed-wing aircraft[C]//Proc. of the AIAA SciTech Forum, 2020.
|
| 19 |
DANIEL M, GERTJAN L. Design and evaluation of advanced intelligent flight controllers[C]//Proc. of the AIAA SciTech Forum, 2020.
|
| 20 |
KANTA Y, NAOYA O, RYU F. Exploration of long time-of-flight three-body transfers using deep reinforcement learning[C]//Proc. of the AIAA SciTech Forum, 2020.
|
| 21 |
HIROSHI K, SEIJI T, EIJI S. Feedback control of Karman vortex shedding from a cylinder using deep reinforcement learning[C]//Proc. of the Flow Control Conference, 2018.
|
| 22 |
SUNGYUNG L, MATTHEW S, BRETT S, et al. Markov neural network for guidance, navigation and control[C]//AIAA SciTech 2020 Forum, 2020.
|
| 23 |
ANDREW H, HANSPETER S. Spacecraft command and control with safety guarantees using shielded deep reinforcement learning[C]//Proc. of the AIAA SciTech Forum, 2020.
|
| 24 |
南杨, 李中键, 叶文伟. 基于强化学习的飞行自动驾驶仪设计[J]. 电子设计工程, 2013, 21 (10): 45- 47.
doi: 10.3969/j.issn.1674-6236.2013.10.014
|
|
NAN Y , LI Z J , YE W W . Design of autopilot for aircraft based on reinforcement learning[J]. Electronic Design Engineering, 2013, 21 (10): 45- 47.
doi: 10.3969/j.issn.1674-6236.2013.10.014
|
| 25 |
范军芳, 张鑫. 基于强化学习的微小型弹药两回路驾驶仪设计[J]. 战术导弹技术, 2019, 4, 48- 54.
|
|
FAN J F , ZHANG X . Design two-loop autopilot based on reinforcement learning for miniature munition[J]. Tactical Missile Technology, 2019, 4, 48- 54.
|
| 26 |
甄岩, 郝明瑞. 基于深度强化学习的智能PID控制方法研究[J]. 战术导弹技术, 2019, 5, 37- 43.
|
|
ZHEN Y , HAO M R . Research on intelligent PID control method based on deep reinforcement learning[J]. Tactical Missile Technology, 2019, 5, 37- 43.
|
| 27 |
ZARCHAN P . Tactical and strategic missile guidance[M]. Washington D C: American Institute of Aeronautics and Astronautics, 1994.
|
| 28 |
JOHN S, FILIP W, ALEC R, et al. Proximal policy optimization algorithms[EB/OL]. [2021-12-01]. https://arxiv.org/abs/1707.06347.
|
| 29 |
JOHN S, SERGEY L, PHILIPP M, et al. Trust region policy optimization[C]//Proc. of the 32nd International Conference on Machine Learning, 2015: 1889-1897.
|
| 30 |
EVAN G , PETER L B , JONATHAN B . Variance reduction techniques for gradient estimates in reinforcement learning[J]. Journal of Machine Learning Research, 2015, 5, 1471- 1530.
|
| 31 |
JOHN S, PHILIPP M, SERGEY L, et al. High-dimensional continuous control using generalized advantage estimation[C]//Proc. of the International Conference on Learning Representations, 2016.
|
| 32 |
NICOLAS H, DHRUVA T, SRINIVASAN S, et al. Emergence of locomotion behaviours in rich environments[EB/OL]. [2021-12-01]. https://arxiv.org/abs/1707.02286.
|