
系统工程与电子技术 ›› 2021, Vol. 43 ›› Issue (4): 991-1002.doi: 10.12305/j.issn.1001-506X.2021.04.16
刘家义1,2( ), 岳韶华1,2(), 王刚1,2(), 姚小强1,2(), 张杰1,2,*()
), 岳韶华1,2(), 王刚1,2(), 姚小强1,2(), 张杰1,2,*()
收稿日期:2020-05-07
出版日期:2021-03-25
发布日期:2021-03-31
通讯作者:
张杰
E-mail:sixandone1@163.com;zhouguoan@sina.cn;iamwg@163.com;yiceiul@163.com;afeu_zhangjie@163.com
作者简介:刘家义 (1996-), 男, 硕士研究生, 主要研究方向为防空反导指挥控制系统、基于强化学习的智能决策。E-mail: 基金资助:
Jiayi LIU1,2(), Shaohua YUE1,2(), Gang WANG1,2(), Xiaoqiang YAO1,2(), Jie ZHANG1,2,*()
Received:2020-05-07
Online:2021-03-25
Published:2021-03-31
Contact:
Jie ZHANG
E-mail:sixandone1@163.com;zhouguoan@sina.cn;iamwg@163.com;yiceiul@163.com;afeu_zhangjie@163.com
摘要:
针对多智能体系统在处理复杂任务时存在的低效率、高冗积、多智能体系统内协同模型算法存在交互冲突、资源损耗过高等问题, 提出一种基于复杂任务的多智能体系统优化算法。在差分进化算法与局部优化算法的基础上对二者进行优化, 结合强化学习的训练框架, 构建训练网络, 通过对学习步长进行修订, 改变种群迭代优化准则, 使得种群在计算力充足的情况下可以实现全局收益最大化, 有效解决了指挥控制系统过程中的协同优化问题。
中图分类号:
刘家义, 岳韶华, 王刚, 姚小强, 张杰. 复杂任务下的多智能体协同进化算法[J]. 系统工程与电子技术, 2021, 43(4): 991-1002.
Jiayi LIU, Shaohua YUE, Gang WANG, Xiaoqiang YAO, Jie ZHANG. Cooperative evolution algorithm of multi-agent system under complex tasks[J]. Systems Engineering and Electronics, 2021, 43(4): 991-1002.
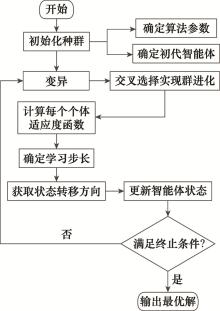
图1
MAC算法流程图"
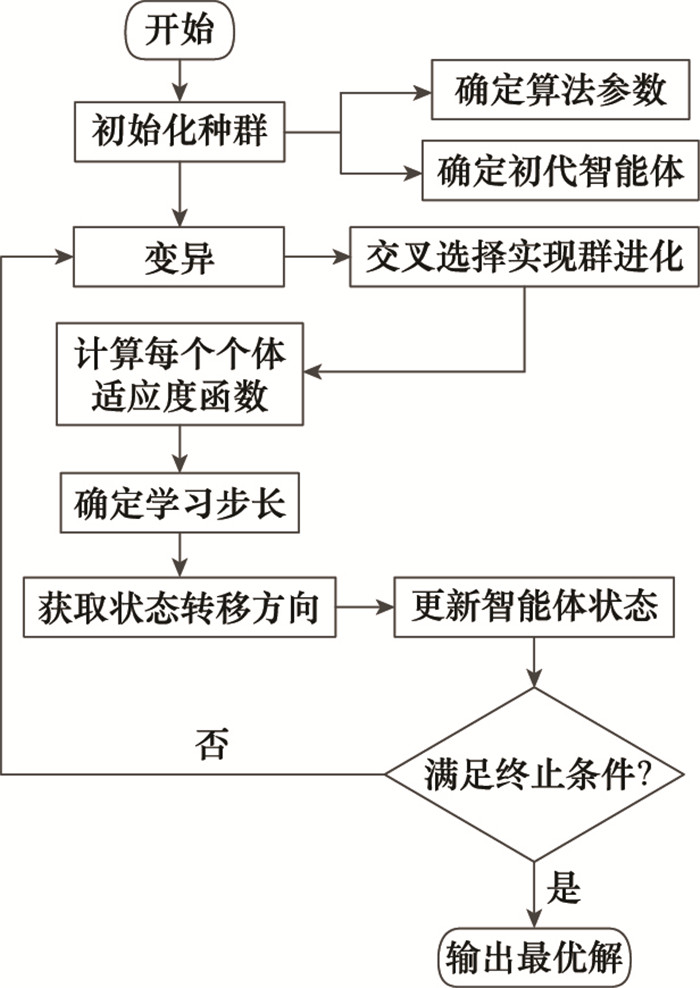
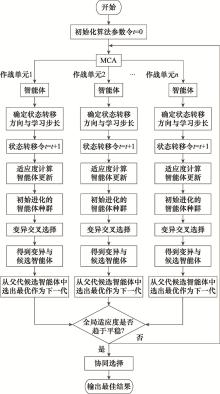
图2
算法实现过程"


图3
训练网络结构"
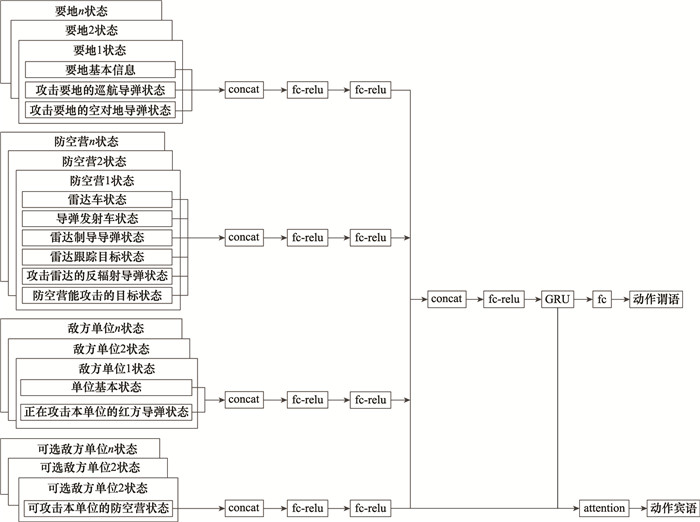

图4
GRU单元"
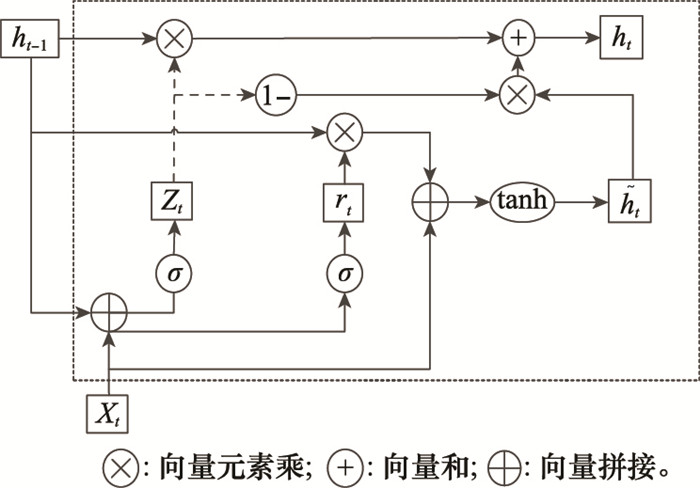
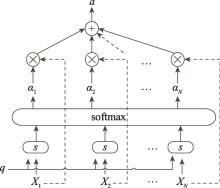
图5
偏好度机制"
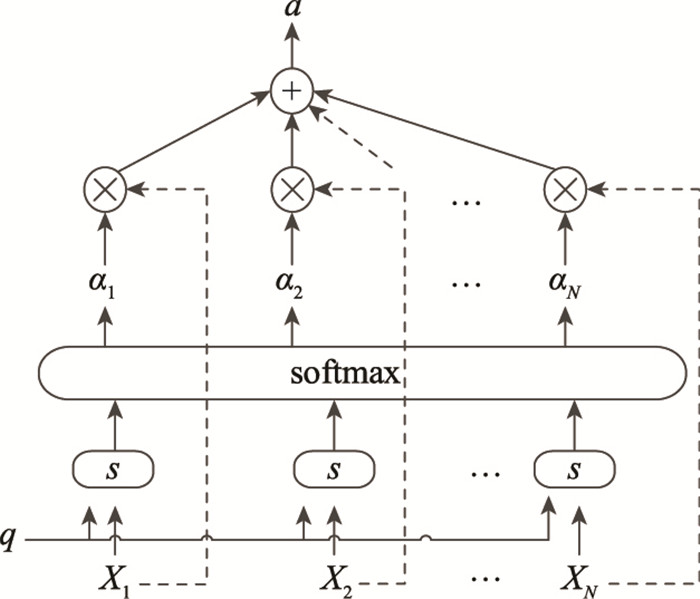
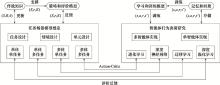
图6
多智能体协同行为决策模型研究框架"
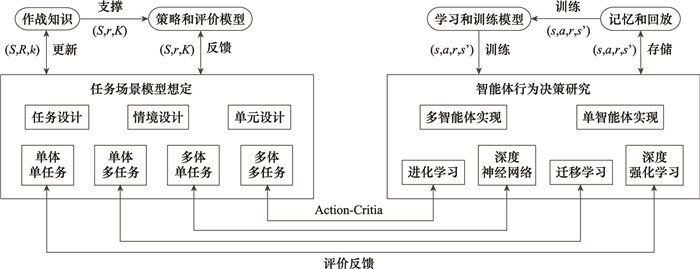
表1
无约束优化测试函数"
| 编号 | 优化函数 | 变量取值范围 | 最优值 |
| D1 | | [-2 048, 2 048] | 3 905.926 2 |
| D2 | | [-5.12, 5.12] | 0 |
| D3 | | [-10, 10] | 0 |
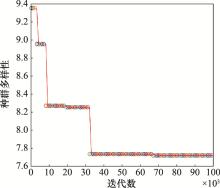
图7
MCA收敛趋势"
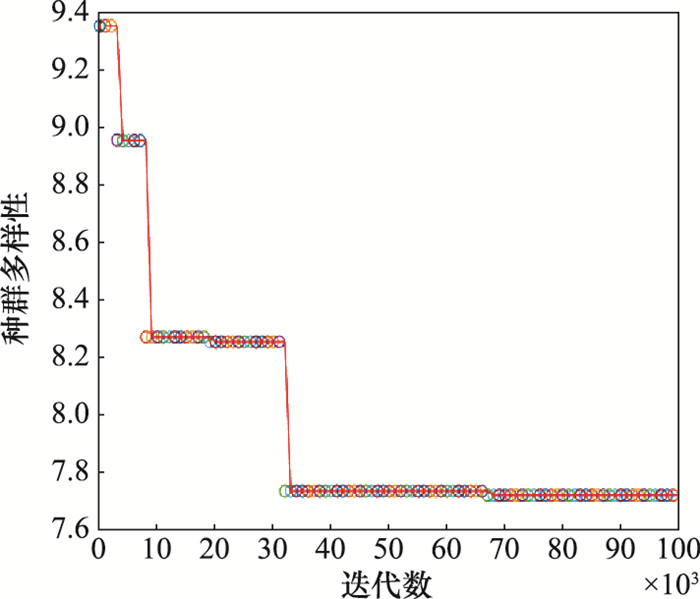
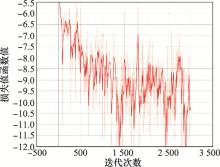
图8
算法损失值迭代分析"
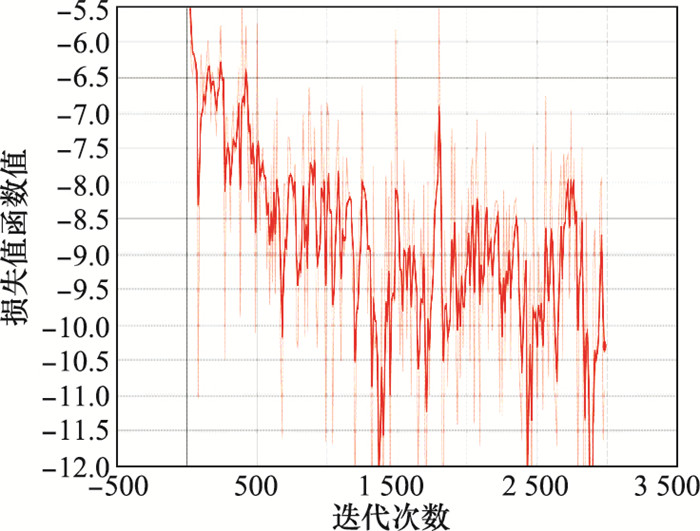

图9
巡航导弹超低空突防"
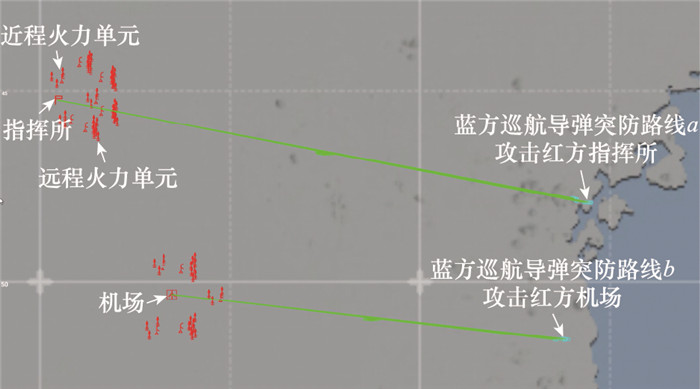

图10
无人机突防"


图11
发射反辐射导弹"


图12
机动逃逸"


图13
轰炸机突防"

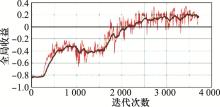
图14
全局收益函数"
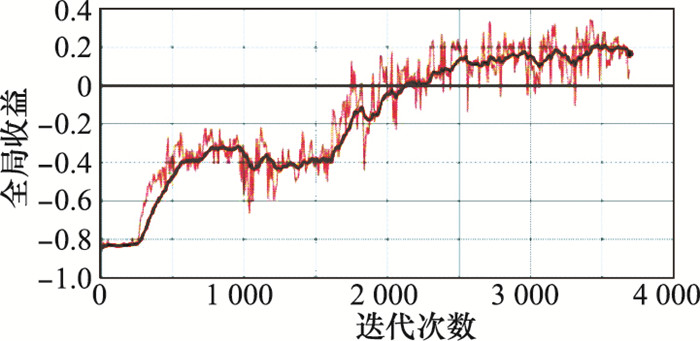

图15
训练学习网络"

图16
全局损失函数"

| 1 |
GUAN Y , JI Z , ZHANG L , et al. Controllability of heterogeneous multi-agent systems under directed and weighted topology[J]. International Journal of Control, 2016, 89 (5): 1009- 1024.
doi: 10.1080/00207179.2015.1110756 |
| 2 | MU N , LIAO X , HUANG T . Event-based consensus control for a linear directed multiagent system with time delay[J]. IEEE Trans.on Circuits & Systems Ⅱ Express Briefs, 2017, 62 (3): 281- 285. |
| 3 | CHEN C L P , WEN G X , LIU Y J , et al. Observer-based adaptive backstepping consensus tracking control for high-order nonlinear semi-strict-feedback multiagent systems[J]. IEEE Trans.on Cybernetics, 2017, 46 (7): 1591- 1601. |
| 4 | ZHANG J , WANG Z , ZHANG H . Data-based optimal control of multi-agent systems: a reinforcement learning design approach[J]. IEEE Trans.on Neural Networks & Learning Systems, 2017, 29 (8): 3339- 3348. |
| 5 |
CHEN Y , WEN G , PENG Z , et al. Consensus of fractional-order multiagent system via sampled-data event-triggered control[J]. Journal of the Franklin Institute, 2019, 356 (17): 10241- 10259.
doi: 10.1016/j.jfranklin.2018.01.043 |
| 6 | WHITBROOK A , MENG Q , CHUNG P W H . Addressing robustness in time-critical, distributed, task allocation algorithms[J]. Applied Intelligence, 2018, 69 (2): 1- 15. |
| 7 | GOLPAYEGANI F , SAHAF Z , DUSPARIC I , et al. Participant selection for short-term collaboration in open multi-agent systems[J]. Simulation Modelling Practice and Theory, 2018, 83 (16): 149- 161. |
| 8 |
费为银, 梁勇. 非利普希茨条件下连续局部鞅驱动的集值随机微分方程[J]. 数学学报, 2013, 56 (4): 561- 574.
doi: 10.3969/j.issn.1005-3085.2013.04.009 |
|
FEI W Y , LIANG Y . Set-valued stochastic differential equations driven by continuous local martingales under the condition of philipschitz[J]. Acta Mathematica Sinica, 2013, 56 (4): 561- 574.
doi: 10.3969/j.issn.1005-3085.2013.04.009 |
|
| 9 | 邱宇航. 协作协进化算法应用于多智能体协作的研究[D]. 杭州: 浙江工业大学, 2005. |
| QIU Y H. Research on cooperative coevolutionary algorithm applied to multi-agent collaboration[D]. Hangzhou: Zhejiang University of Technology, 2005. | |
| 10 | 柴国飞. 多智能体协同定位与Sink节点位置隐私保护研究[D]. 杭州: 浙江大学, 2015. |
| CHAI G F. Research on multi-agent cooperative location and Sink node location privacy protection[D]. Hangzhou: Zhejiang University, 2015. | |
| 11 | PREVITALI F, IOCCHI L P. Tracking: distributed multi-agent multi-object tracking through multi-clustered particle filtering[C]//Proc. of the IEEE International Conference on Multisensor Fusion and Integration for Intelligent Systems, 2015: 86-93. |
| 12 |
GONG Z W , TAN X , YANG Y J . Optimal weighting models based on linear uncertain constraints in intuitionistic fuzzy prefe-rencerelations[J]. Journal of the Operational Research Society, 2019, 70 (8): 1296- 1307.
doi: 10.1080/01605682.2018.1489349 |
| 13 |
GLAU K , MAHLSTEDT M . Improved error bound for multivariate Chebyshev polynomial interpolation[J]. International Journal of Computer Mathematics, 2019, 96 (11): 2302- 2314.
doi: 10.1080/00207160.2019.1599364 |
| 14 |
ZHANG B , SUN X , LIU S , et al. Adaptive differential evolution-based receding horizon control design for multi-UAV formation reconfiguration[J]. International Journal of Control, Automation and Systems, 2019, 17 (12): 3009- 3020.
doi: 10.1007/s12555-018-0421-2 |
| 15 | GAO X G , ZHOU C L , CHAO F , et al. A data-driven robotic Chinese calligraphy system using convolutional auto-encoder and differential evolution[J]. Knowledge-Based Systems, 2019, 182 (15): 104- 115. |
| 16 | ONTIVEROS-ROBLES E L , MELIN P . A hybrid design of shadowed type-2 fuzzy inference systems applied in diagnosis problems[J]. Engineering Applications of Artificial Intelligence, 2019, 86 (10): 43- 55. |
| 17 | OJHA V , ABRAHAM A , SNÁŠEL V . Heuristic design of fuzzy inference systems: A review of three decades of research[J]. Engineering Applications of Artificial Intelligence, 2019, 85 (6): 845- 864. |
| 18 | ZHENG M C , LIU Y . Multiple-rules reasoning based on Triple I method on Atanassov's intuitionistic fuzzy sets[J]. International Journal of Approximate Reasoning, 2019, 113 (61): 196- 206. |
| 19 |
邝航宇, 金晶, 苏勇. 自适应遗传算法交叉变异算子的改进[J]. 计算机工程与应用, 2006, (12): 93- 96, 99.
doi: 10.3321/j.issn:1002-8331.2006.12.028 |
|
KUANG H Y , JIN J , SU Y . Improvement of cross mutation operator of adaptive genetic algorithm[J]. Computer Engineering and Application, 2006, (12): 93- 96, 99.
doi: 10.3321/j.issn:1002-8331.2006.12.028 |
|
| 20 |
龚建华. 深度优先搜索算法及其改进[J]. 现代电子技术, 2007, 32 (22): 90- 92.
doi: 10.3969/j.issn.1004-373X.2007.22.032 |
|
GONG J H . Depth first search algorithm and its improvement[J]. Modern Electronics Technique, 2007, 32 (22): 90- 92.
doi: 10.3969/j.issn.1004-373X.2007.22.032 |
|
| 21 | GOLPAYEGANI F , SAHAF Z , DUSPARIC I , et al. Participant selection for short-term collaboration in open multi-agent systems[J]. Simulation Modelling Practice and Theory, 2017, 83 (9): 149- 161. |
| 22 |
LIAN F , CHAKRABORTTY A , DUEL-HALLEN A . Game-theoretic multi-agent control and network cost allocation under communication constraints[J]. IEEE Journal on Selected Areas in Communications, 2017, 35 (2): 330- 340.
doi: 10.1109/JSAC.2017.2659338 |
| 23 | BRITTANY R H . Application of adaptive-network-based fuzzy inference systems to the parameter optimization of a biochemical rule-based model[J]. Computers in Biology and Medicine, 2019, 107 (9): 153- 160. |
| 24 |
GUPTA S . Modeling trust based risk management in cloud adoption using fuzzy inference system[J]. International Journal of Technology Diffusion, 2017, 8 (1): 52- 60.
doi: 10.4018/IJTD.2017010104 |
| 25 |
CHAABANI A , BECHIKH S , SAID L B . A co-evolutionary hybrid decomposition-based algorithm for bi-level combinatorial optimization problems[J]. Soft Computing, 2019, 24 (1): 1- 19.
doi: 10.1007/s00500-019-04337-0 |
| 26 | LIANG Z P , WANG X Y , LIN Q Z , et al. A novel multi-objective co-evolutionary algorithm based on decomposition approach[J]. Applied Soft Computing Journal, 2018, 73 (5): 50- 66. |
| 27 |
COLBY M , TUMER K . Fitness function shaping in multiagent cooperative co-evolutionary algorithms[J]. Autonomous Agents and Multi-Agent Systems, 2017, 31 (2): 179- 206.
doi: 10.1007/s10458-015-9318-0 |
| 28 | WANG F , CHEN B , LIN C , et al. Distributed adaptive neural control for stochastic nonlinear multiagents ystems[J]. IEEE Trans.on Cybernetics, 2017, 47 (99): 1795- 1803. |
| 29 |
HEREDIA P C , MOU S H . Distributed multi-agent reinforcement learning by actor-critic method[J]. IFAC-PapersOnLine, 2019, 52 (20): 363- 368.
doi: 10.1016/j.ifacol.2019.12.182 |
| 30 |
VIDHATE D A . Cooperative multi-agent joint action learning algorithm (CMJAL) for decision making in retail shop application[J]. International Journal of Agent Technologies and Systems, 2017, 9 (1): 1- 19.
doi: 10.4018/IJATS.2017010101 |
| 31 | ALAGOZ O , AYVACI M U S , LINDEROTH J T . Optimally solving Markov decision processes with total expected discounted reward function: Linear programming revisited[J]. Computers & Industrial Engineering, 2015, 87 (9): 311- 316. |
| [1] | 朱霸坤, 朱卫纲, 李伟, 杨莹, 高天昊. 基于马尔可夫的多功能雷达认知干扰决策建模研究[J]. 系统工程与电子技术, 2022, 44(8): 2488-2497. |
| [2] | 王冠, 茹海忠, 张大力, 马广程, 夏红伟. 弹性高超声速飞行器智能控制系统设计[J]. 系统工程与电子技术, 2022, 44(7): 2276-2285. |
| [3] | 孟泠宇, 郭秉礼, 杨雯, 张欣伟, 赵柞青, 黄善国. 基于深度强化学习的网络路由优化方法[J]. 系统工程与电子技术, 2022, 44(7): 2311-2318. |
| [4] | 郭冬子, 黄荣, 许河川, 孙立伟, 崔乃刚. 再入飞行器深度确定性策略梯度制导方法研究[J]. 系统工程与电子技术, 2022, 44(6): 1942-1949. |
| [5] | 韩明仁, 王玉峰. 基于强化学习的全电推进卫星变轨优化方法[J]. 系统工程与电子技术, 2022, 44(5): 1652-1661. |
| [6] | 张普, 薛惠锋, 高山, 左轩. 具有混合执行器故障的多智能体分布式有限时间自适应协同容错控制[J]. 系统工程与电子技术, 2022, 44(4): 1220-1229. |
| [7] | 何立, 沈亮, 李辉, 王壮, 唐文泉. 强化学习中的策略重用: 研究进展[J]. 系统工程与电子技术, 2022, 44(3): 884-899. |
| [8] | 朱霸坤, 朱卫纲, 李伟, 杨莹, 高天昊. 基于先验知识的多功能雷达智能干扰决策方法[J]. 系统工程与电子技术, 2022, 44(12): 3685-3695. |
| [9] | 杨清清, 高盈盈, 郭玙, 夏博远, 杨克巍. 基于深度强化学习的海战场目标搜寻路径规划[J]. 系统工程与电子技术, 2022, 44(11): 3486-3495. |
| [10] | 曾斌, 张鸿强, 李厚朴. 针对无人潜航器的反潜策略研究[J]. 系统工程与电子技术, 2022, 44(10): 3174-3181. |
| [11] | 万齐天, 卢宝刚, 赵雅心, 温求遒. 基于深度强化学习的驾驶仪参数快速整定方法[J]. 系统工程与电子技术, 2022, 44(10): 3190-3199. |
| [12] | 曾斌, 王睿, 李厚朴, 樊旭. 基于强化学习的战时保障力量调度策略研究[J]. 系统工程与电子技术, 2022, 44(1): 199-208. |
| [13] | 罗哲, 权婉珍, 张朴睿, 杨小冈. 单边Lipschitz非线性多智能体系统一致性追踪控制[J]. 系统工程与电子技术, 2022, 44(1): 279-284. |
| [14] | 江志炜, 黄洋, 吴启晖. 基于核函数强化学习的抗干扰频点分配[J]. 系统工程与电子技术, 2021, 43(6): 1547-1556. |
| [15] | 闫安, 陈章, 董朝阳, 何康辉. 基于模糊强化学习的双轮机器人姿态平衡控制[J]. 系统工程与电子技术, 2021, 43(4): 1036-1043. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||