
系统工程与电子技术 ›› 2023, Vol. 45 ›› Issue (1): 193-201.doi: 10.12305/j.issn.1001-506X.2023.01.23
• 制导、导航与控制 • 上一篇
任智1,2, 张栋1,2,*, 唐硕1,2
收稿日期:2021-08-12
出版日期:2023-01-01
发布日期:2023-01-03
通讯作者:
张栋
作者简介:任智(1999—), 男, 博士研究生, 主要研究方向为飞行器集群智能规划与自主控制基金资助:Zhi REN1,2, Dong ZHANG1,2,*, Shuo TANG1,2
Received:2021-08-12
Online:2023-01-01
Published:2023-01-03
Contact:
Dong ZHANG
摘要:
针对飞行器在线航迹规划对算法实时性与结果最优性要求高的问题,基于强化学习方法改进三维A*算法。首先,引入收缩因子改进代价函数的启发信息加权方法提升算法时间性能;其次,建立算法实时性与结果最优性的性能变化度量模型,结合深度确定性策略梯度方法设计动作-状态与奖励函数,对收缩因子进行优化训练;最后,在多场景下对改进后的三维A*算法进行仿真验证。仿真结果表明,改进算法能够在保证航迹结果最优性的同时有效提升算法时间性能。
中图分类号:
任智, 张栋, 唐硕. 基于强化学习的改进三维A*算法在线航迹规划[J]. 系统工程与电子技术, 2023, 45(1): 193-201.
Zhi REN, Dong ZHANG, Shuo TANG. Improved three-dimensional A* algorithm of real-time path planning based on reinforcement learning[J]. Systems Engineering and Electronics, 2023, 45(1): 193-201.
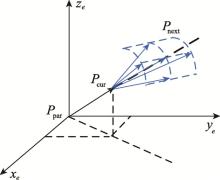
图1
拓展方式示意图"

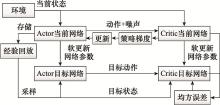
图2
Actor-Critic双网络架构示意图"
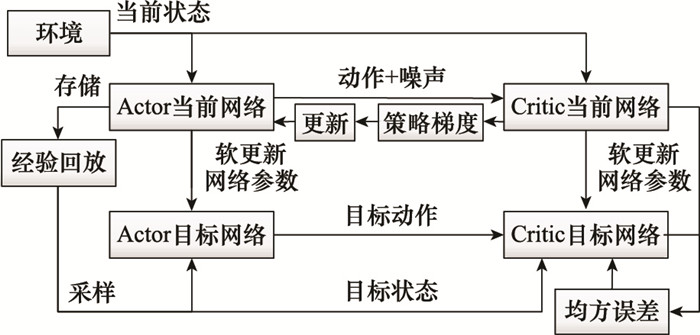
图3
算法循环结构示意图"
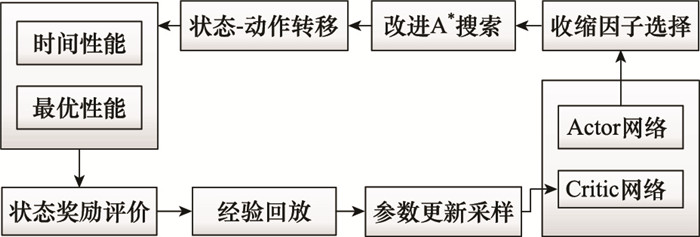

图4
结合DDPG算法流程图"
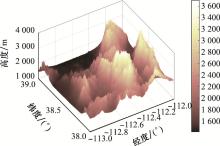
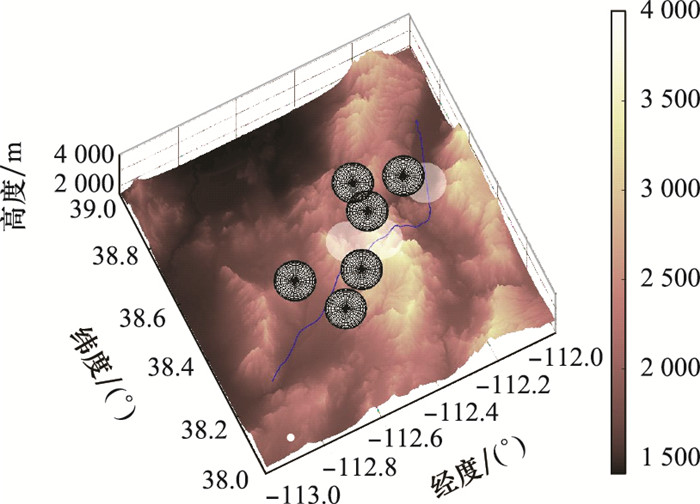
图5
战场环境地面地形图"
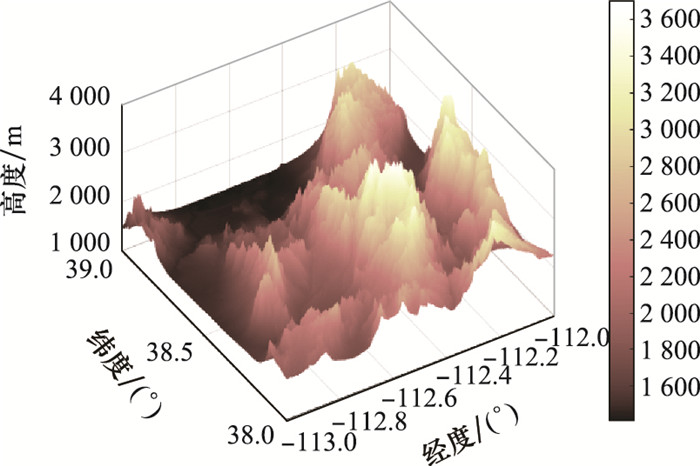
表1
飞行器性能参数表"
| 序号 | 性能 | 性能参数 |
| 1 | 飞行速度/(m/s) | 200 |
| 2 | 安全飞行高度/m | 500 |
| 3 | 最大俯仰角/(°) | 20 |
| 4 | 最大航向角/(°) | 45 |
| 5 | 最小转弯半径/m | 1 242.6 |
表2
禁飞区参数表"
| 序号 | 经纬坐标/(°) | 威胁半径/km |
| 1 | (112.4, 38.6) | 5 |
| 2 | (112.7, 38.4) | 5 |
| 3 | (112.5, 38.44) | 5 |
| 4 | (112.6, 38.25) | 5 |
| 5 | (112.4, 38.4) | 5 |
| 6 | (112.2, 38.5) | 5 |

图6
标准A*算法与改进A*算法规划结果平面图"
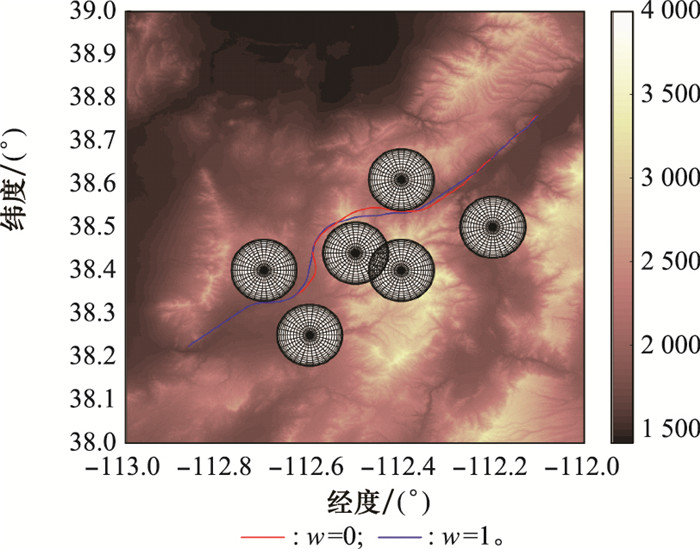
图7
标准A*算法与改进A*算法规划结果三维图"
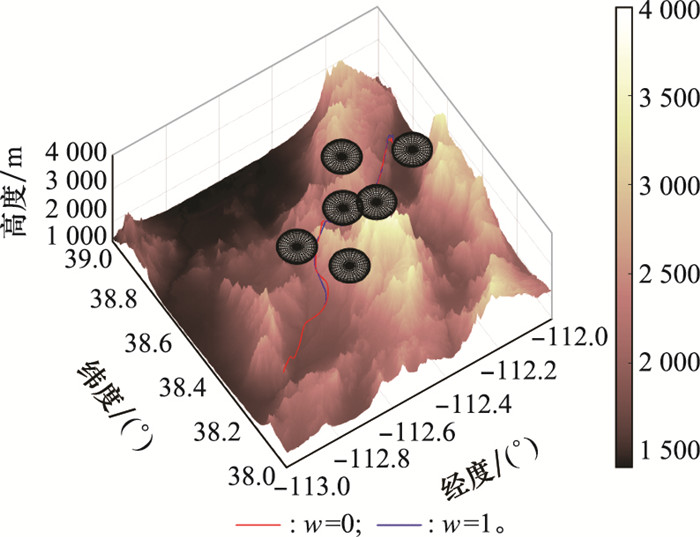
表3
奖励函数参数表"
| 序号 | 性能 | 性能参数 |
| 1 | ti*/s | 264.13 |
| 2 | timax/s | 0.932 |
| 3 | ei* | 49 |
| 4 | eimax | 53 |
表4
卷积神经网络参数表"
| 序号 | 性能 | 性能参数 |
| 1 | Actor网络学习率 | 0.001 |
| 2 | Critic网络学习率 | 0.002 |
| 3 | Batch训练样本大小 | 128 |
| 4 | 经验回放池大小 | 10 000 |
| 5 | 软策略更新因子 | 0.01 |
| 6 | 收缩因子初值 | 0.4 |
| 7 | 即时回报收敛因子 | 0.9 |

图8
改进算法最优性能变化图"
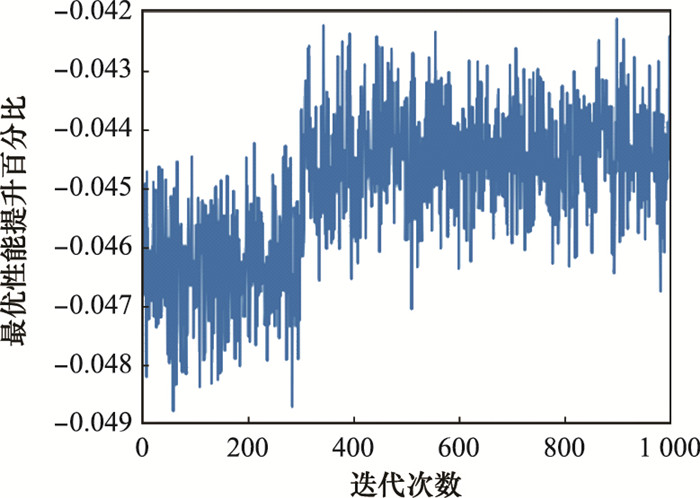
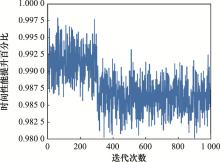
图9
改进算法时间性能变化图"
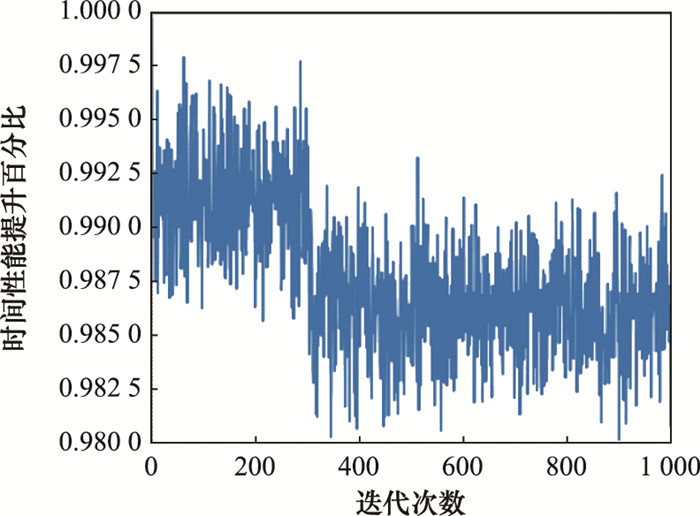
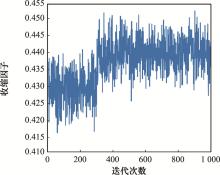
图10
迭代收敛的收缩因子图"
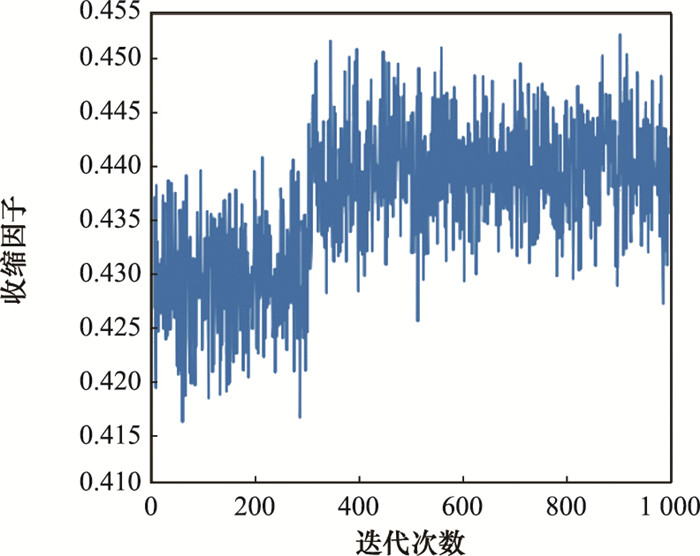
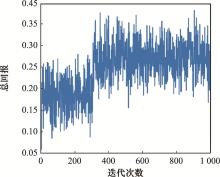
图11
迭代收敛的总回报图"
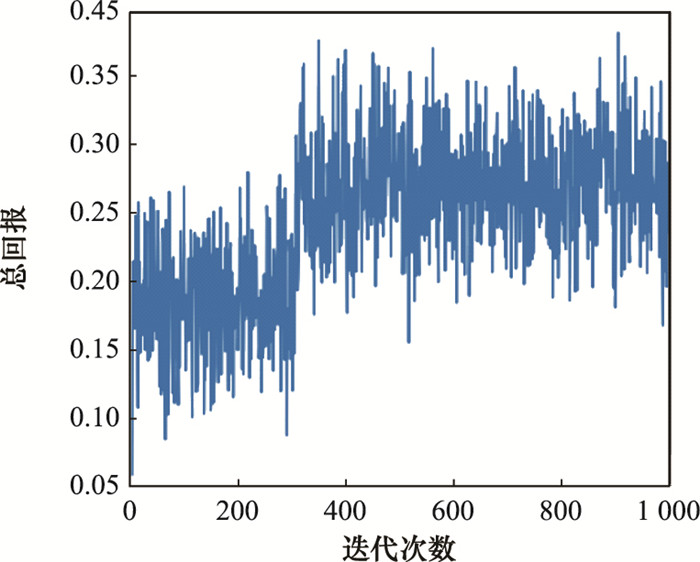
表5
仿真场景参数表"
| 场景 | 起始节点 | 目标节点 | 禁飞区1 | 禁飞区2 | 禁飞区3 | 禁飞区4 | 禁飞区5 | 禁飞区6 |
| 1 | (112.9, 38.2) | (112.1, 38.8) | (112.4, 38.6) | (112.7, 38.4) | (112.5, 38.44) | (112.6, 38.25) | (112.4, 38.4) | (112.2, 38.5) |
| 2 | (112.9, 38.7) | (112.1, 38.2) | (112.4, 38.6) | (112.7, 38.4) | (112.5, 38.44) | (112.6, 38.25) | (112.4, 38.4) | (112.2, 38.5) |
| 3 | (112.9, 38.5) | (112.1, 38.4) | (112.4, 38.6) | (112.7, 38.4) | (112.5, 38.44) | (112.6, 38.25) | (112.4, 38.4) | (112.2, 38.5) |
| 4 | (112.9, 38.2) | (112.1, 38.8) | (112.7, 38.3) | (112.4, 38.6) | (112.4, 38.3) | (112.2, 38.4) | (112.6, 38.3) | (112.6, 38.4) |
| 5 | (112.9, 38.7) | (112.1, 38.2) | (112.7, 38.3) | (112.4, 38.6) | (112.4, 38.3) | (112.2, 38.4) | (112.6, 38.3) | (112.6, 38.4) |
| 6 | (112.9, 38.5) | (112.1, 38.4) | (112.7, 38.3) | (112.4, 38.6) | (112.4, 38.3) | (112.2, 38.4) | (112.6, 38.3) | (112.6, 38.4) |
表6
各场景仿真结果表"
| 场景 | DDPG训练策略 | 指数衰减方法 | |||
| 仿真时间/s | 节点 | 仿真时间/s | 节点 | ||
| 1 | 1.373 | 52 | 9.612 | 69 | |
| 2 | 2.651 | 61 | 38.347 | 76 | |
| 3 | 0.894 | 54 | 2.811 | 54 | |
| 4 | 1.081 | 46 | 4.692 | 50 | |
| 5 | 1.670 | 52 | 19.793 | 74 | |
| 6 | 0.612 | 47 | 6.185 | 48 | |
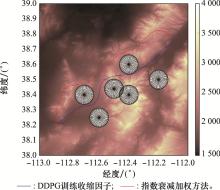
图12
两种改进A*算法规划结果平面图"
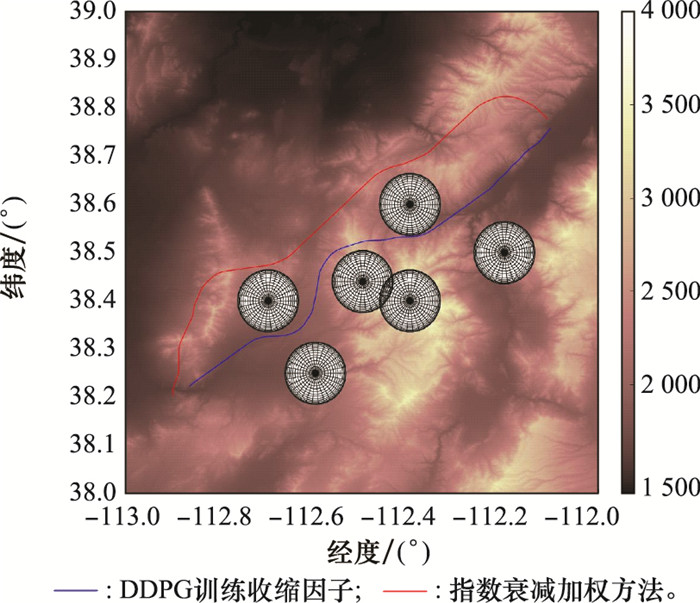
图13
两种改进A*算法规划结果三维图"

图14
动态场景改进算法规划结果平面图"
图15
动态场景改进A*算法规划结果三维图"
| 1 |
PARK S O , MIN C L , KIM J . Trajectory planning with collision avoidance for redundant robots using Jacobian and artificial potential field-based real-time inverse kinematics[J]. International Journal of Control, Automation and Systems, 2020, 18 (8): 2095- 2107.
doi: 10.1007/s12555-019-0076-7 |
| 2 | JAMSHIDI V , NEKOUKAR V , REFAN M H . Analysis of parallel genetic algorithm and parallel particle swarm optimization algorithm UAV path planning on controller area network[J]. Journal of Control, Automation and Electrical Systems, 2019, 31 (1): 129- 140. |
| 3 | QU C Z , GAI W D , ZHONG M Y , et al. A novel reinforcement learning based grey wolf optimizer algorithm for unmanned aerial vehicles (UAVs) path planning[J]. Applied Soft Computing, 2020, 89 (1): 106099. |
| 4 | RASHID R, PERUMAL N, ELAMVAZUTHI I, et al. Mobile robot path planning using ant colony optimization[C]//Proc. of the 2nd IEEE International Symposium on Robotics and Manufacturing Automation, 2016: 16657753. |
| 5 | XU Z , ZHANG E , CHEN Q W . Rotary unmanned aerial vehicles path planning in rough terrain based on multi-objective particle swarm optimization[J]. Journal of Systems Engineering and Electronics, 2020, 31 (1): 130- 141. |
| 6 |
LAI Q , XU G H . A new path planning method of mobile robot based on adaptive dynamic firefly algorithm[J]. Modern Physics Letters B, 2020, 34 (29): 2050322.
doi: 10.1142/S0217984920503224 |
| 7 | SHANG E , DAI B , NIE Y M , et al. An improved A-Star based path planning algorithm for autonomous land vehicles[J]. International Journal of Advanced Robotic Systems, 2020, 17 (5) |
| 8 |
ZHANG A , CHONG L , BI W H . Rectangle expansion A* pathfinding for grid maps[J]. Chinese Journal of Aeronautics, 2016, 29 (5): 1385- 1396.
doi: 10.1016/j.cja.2016.04.023 |
| 9 | 赵真明, 孟正大. 基于加权A*算法的服务型机器人路径规划[J]. 华中科技大学学报(自然科学版), 2008, 36 (S1): 196- 198. |
| ZHAO Z M , MENG Z D . Path planning of service robot based on weighted A* algorithm[J]. Journal of Huazhong University of Science and Technology (Natural Science Edition), 2008, 36 (S1): 196- 198. | |
| 10 | REN Y Y, SONG X R, GAO S. Research on path planning of mobile robot based on improved A* in special environment[C]//Proc. of the 3rd IEEE International Symposium on Autonomous Systems, 2019: 12-16. |
| 11 | LIU S W, MA Y. Research for bidirectional path planning based on an improved A* algorithm[C]//Proc. of the IEEE International Conference on Advances in Electrical Engineering and Computer Applications, 2020: 1036-1039. |
| 12 | SHANG E, DAI B, NIE Y M, et al. A guide-line and key-point based A-star path planning algorithm for autonomous land vehicles[C]//Proc. of the 23rd IEEE International Conference on Intelligent Transportation Systems, 2020. |
| 13 | 王生印, 龙腾, 王祝, 等. 基于即时修复式稀疏A*算法的动态航迹规划[J]. 系统工程与电子技术, 2018, 40 (12): 2714- 2721. |
| WANG S Y , LONG T , WANG Z , et al. Dynamic path planning based on real-time repair sparse A* algorithm[J]. Systems Engineering and Electronics, 2018, 40 (12): 2714- 2721. | |
| 14 | 王维, 裴东, 冯璋. 改进A*算法的移动机器人最短路径规划[J]. 计算机应用, 2018, 38 (5): 1523- 1526. |
| WANG W , PEI D , FENG Z . Shortest path planning for mobile robots based on improved A* algorithm[J]. Journal of Computer Applications, 2018, 38 (5): 1523- 1526. | |
| 15 | 李晨溪, 曹雷, 张永亮, 等. 基于知识的深度强化学习研究综述[J]. 系统工程与电子技术, 2017, 39 (11): 2603- 2613. |
| LI C X , CAO L , ZHANG Y L , et al. A review of knowledge based deep reinforcement learning[J]. Systems Engineering and Electronics, 2017, 39 (11): 2603- 2613. | |
| 16 | CHEN H Y , JI Y , NIU L . Reinforcement learning path planning algorithm based on obstacle area expansion strategy[J]. Intelligent Service Robotics, 2020, 13 (6): 289- 297. |
| 17 | LIN X G, GUO R X. Path planning of unmanned surface vehicle based on improved Q-learning algorithm[C]//Proc. of the 3rd IEEE International Conference on Electronic Information Technology and Computer Engineering, 2019: 302-306. |
| 18 | LI Y B, ZHANG S T, YE F, et al. A UAV path planning method based on deep reinforcement learning[C]//Proc. of the IEEE USNC-CNC-URSI North American Radio Science Meeting, 2020: 93-94. |
| 19 | 董培方, 张志安, 梅新虎, 等. 引入势场及陷阱搜索的强化学习路径规划算法[J]. 计算机工程与应用, 2018, 54 (16): 129- 134. |
| DONG P F , ZHANG Z A , MEI X H , et al. Reinforcement learning path planning algorithm based on gravitational potential field and trap search[J]. Computer Engineering and Applications, 2018, 54 (16): 129- 134. | |
| 20 | ZHENG S F , LIU H . Improved multi-agent deep deterministic policy gradient for path planning-based crowd simulation[J]. IEEE Access, 2019, 7, 147755- 147770. |
| 21 | GAO J L , YE W J , GUO J , et al. Deep reinforcement learning for indoor mobile robot path planning[J]. Sensors, 2020, 20 (19): 5493. |
| 22 | GAO X , FANG Y W , WU Y L . Fuzzy Q learning algorithm for dual-aircraft path planning to cooperatively detect targets by passive radars[J]. Journal of Systems Engineering and Electronics, 2013, 24 (5): 800- 810. |
| 23 | LI B H , WU Y J . Path planning for UAV ground target tracking via deep reinforcement learning[J]. IEEE Access, 2020, 8, 29064- 29074. |
| 24 | CHEN Y, HU J L, HIRASAWA K, et al. Optimizing reserve size in genetic algorithms with reserve selection using reinforcement learning[C]//Proc. of the IEEE SICE Annual Conference, 2007: 1341-1347. |
| 25 | ADARSG S, HUNG L, SUSHIL L, et al. Deep reinforcement learning using genetic algorithm for parameter optimization[C]//Proc. of the 3rd IEEE International Conference on Robotic Computing, 2019: 596-601. |
| 26 | SYED I A M, MOINUL I, MD M U. Q-learning based particle swarm optimization algorithm for optimal path planning of swarm of mobile robots[C]//Proc. of the 1st IEEE International Conference on Advances in Science, Engineering and Robo-tics Technology, 2019. |
| 27 | 封硕, 郑宝娟, 陈文兴, 等. 支持强化学习RNSGA-Ⅱ算法在航迹规划中应用[J]. 计算机工程与应用, 2020, 56 (3): 246- 251. |
| FENG S , ZHENG B J , CHEN W X , et al. Application of reinforcement learning RNSGA- Ⅱ algorithm in flight path planning[J]. Computer Engineering and Applications, 2020, 56 (3): 246- 251. | |
| 28 | 曾国奇, 赵民强, 刘方圆, 等. 基于网格PRM的无人机多约束航路规划[J]. 系统工程与电子技术, 2016, 38 (10): 2310- 2316. |
| ZENG G Q , ZHAO M Q , LIU F Y , et al. Multi-constraints UAV path planning based on grid PRM[J]. Systems Engineering and Electronics, 2016, 38 (10): 2310- 2316. | |
| 29 | WU X L , XU L , ZHEN R , et al. Bi-directional adaptive A* algorithm toward optimal path planning for large-scale UAV under multi-constraints[J]. IEEE Access, 2020, 8, 85431- 85440. |
| 30 | XU Z Y, TANG J, MENG J S, et al. Experience-driven networking: a deep reinforcement learning based approach[C]//Proc. of the IEEE Conference on Computer Communications, 2018: 1871-1879. |
| 31 | XU Z, LIU X, CHEN Q L. Application of improved Astar algorithm in global path planning of unmanned vehicles[C]//Proc. of the IEEE Chinese Automation Congress, 2019: 2075-2080. |
| [1] | 马子杰, 谢拥军. 体系作战下巡航导弹的动态隐身[J]. 系统工程与电子技术, 2022, 44(9): 2826-2831. |
| [2] | 朱霸坤, 朱卫纲, 李伟, 杨莹, 高天昊. 基于马尔可夫的多功能雷达认知干扰决策建模研究[J]. 系统工程与电子技术, 2022, 44(8): 2488-2497. |
| [3] | 王冠, 茹海忠, 张大力, 马广程, 夏红伟. 弹性高超声速飞行器智能控制系统设计[J]. 系统工程与电子技术, 2022, 44(7): 2276-2285. |
| [4] | 孟泠宇, 郭秉礼, 杨雯, 张欣伟, 赵柞青, 黄善国. 基于深度强化学习的网络路由优化方法[J]. 系统工程与电子技术, 2022, 44(7): 2311-2318. |
| [5] | 郭冬子, 黄荣, 许河川, 孙立伟, 崔乃刚. 再入飞行器深度确定性策略梯度制导方法研究[J]. 系统工程与电子技术, 2022, 44(6): 1942-1949. |
| [6] | 韩明仁, 王玉峰. 基于强化学习的全电推进卫星变轨优化方法[J]. 系统工程与电子技术, 2022, 44(5): 1652-1661. |
| [7] | 何立, 沈亮, 李辉, 王壮, 唐文泉. 强化学习中的策略重用: 研究进展[J]. 系统工程与电子技术, 2022, 44(3): 884-899. |
| [8] | 朱霸坤, 朱卫纲, 李伟, 杨莹, 高天昊. 基于先验知识的多功能雷达智能干扰决策方法[J]. 系统工程与电子技术, 2022, 44(12): 3685-3695. |
| [9] | 杨清清, 高盈盈, 郭玙, 夏博远, 杨克巍. 基于深度强化学习的海战场目标搜寻路径规划[J]. 系统工程与电子技术, 2022, 44(11): 3486-3495. |
| [10] | 曾斌, 张鸿强, 李厚朴. 针对无人潜航器的反潜策略研究[J]. 系统工程与电子技术, 2022, 44(10): 3174-3181. |
| [11] | 万齐天, 卢宝刚, 赵雅心, 温求遒. 基于深度强化学习的驾驶仪参数快速整定方法[J]. 系统工程与电子技术, 2022, 44(10): 3190-3199. |
| [12] | 曾斌, 王睿, 李厚朴, 樊旭. 基于强化学习的战时保障力量调度策略研究[J]. 系统工程与电子技术, 2022, 44(1): 199-208. |
| [13] | 江志炜, 黄洋, 吴启晖. 基于核函数强化学习的抗干扰频点分配[J]. 系统工程与电子技术, 2021, 43(6): 1547-1556. |
| [14] | 刘家义, 岳韶华, 王刚, 姚小强, 张杰. 复杂任务下的多智能体协同进化算法[J]. 系统工程与电子技术, 2021, 43(4): 991-1002. |
| [15] | 闫安, 陈章, 董朝阳, 何康辉. 基于模糊强化学习的双轮机器人姿态平衡控制[J]. 系统工程与电子技术, 2021, 43(4): 1036-1043. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||