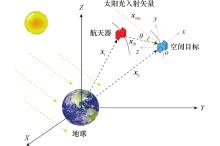
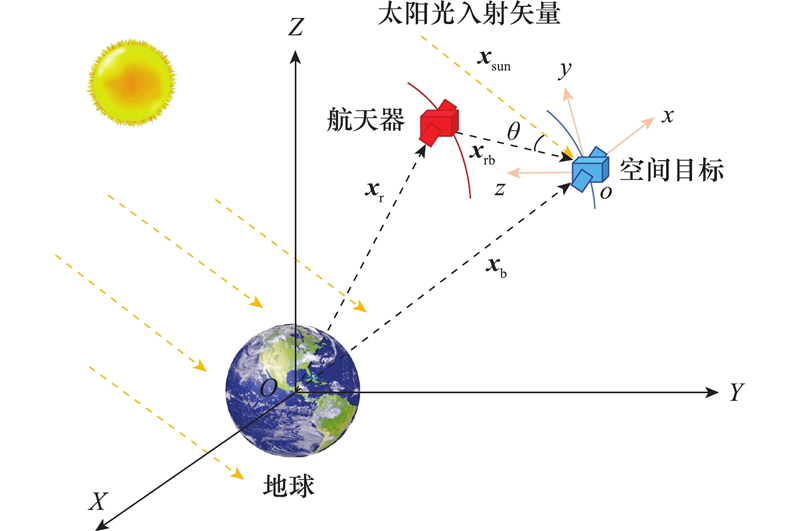
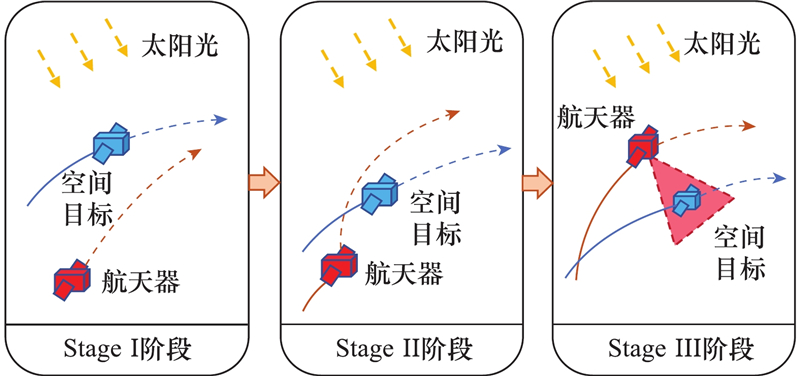
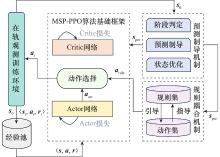
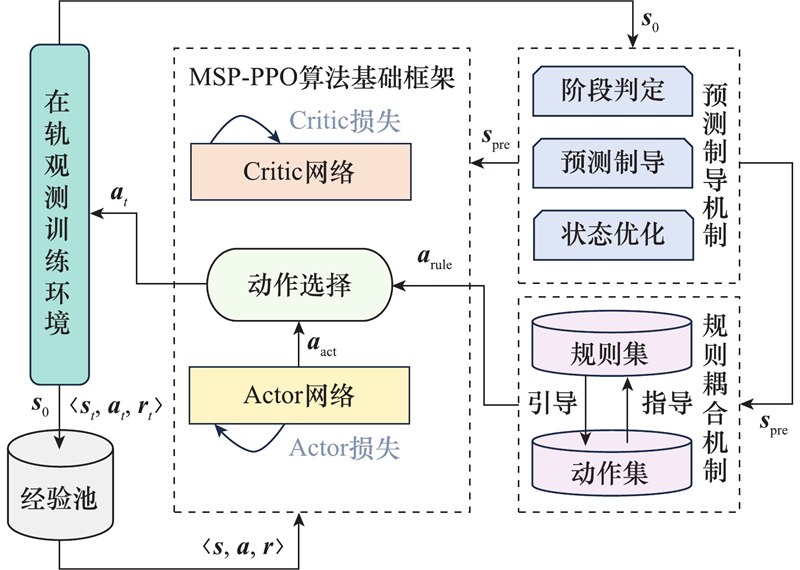
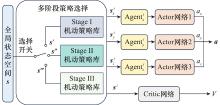
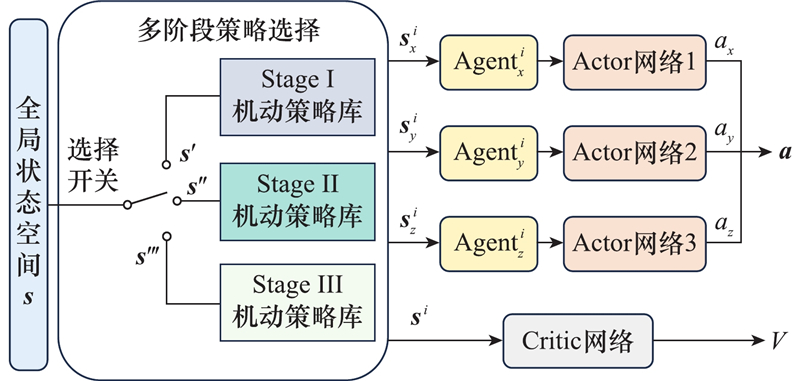
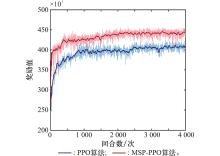
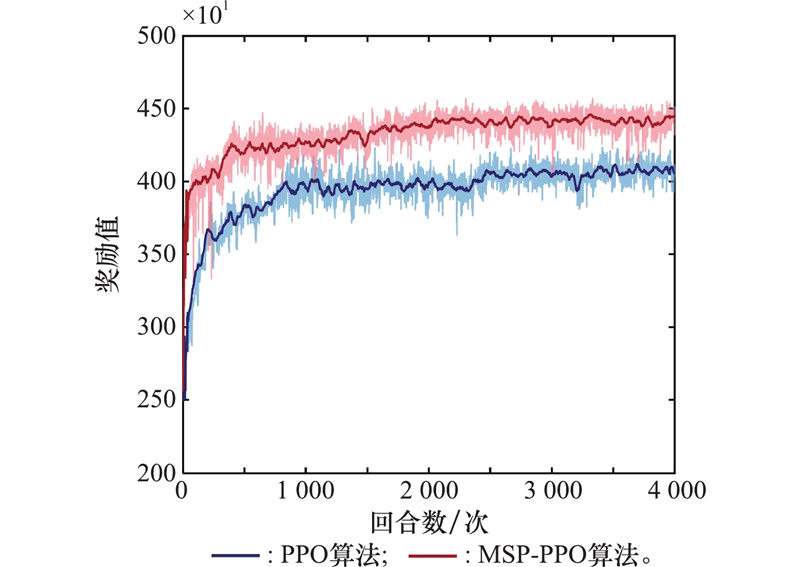
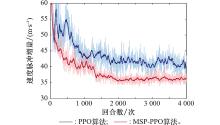
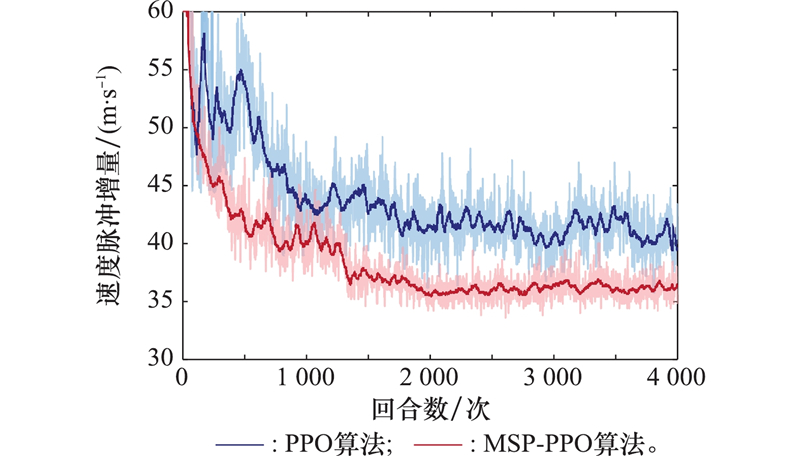
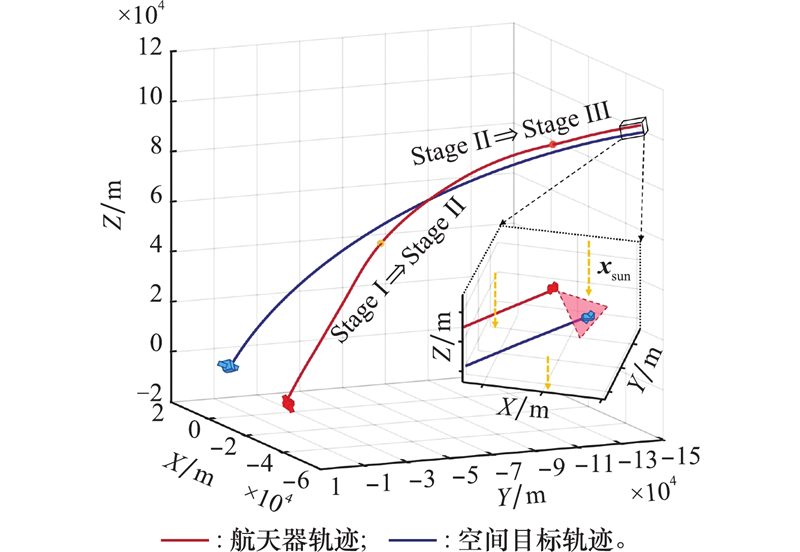
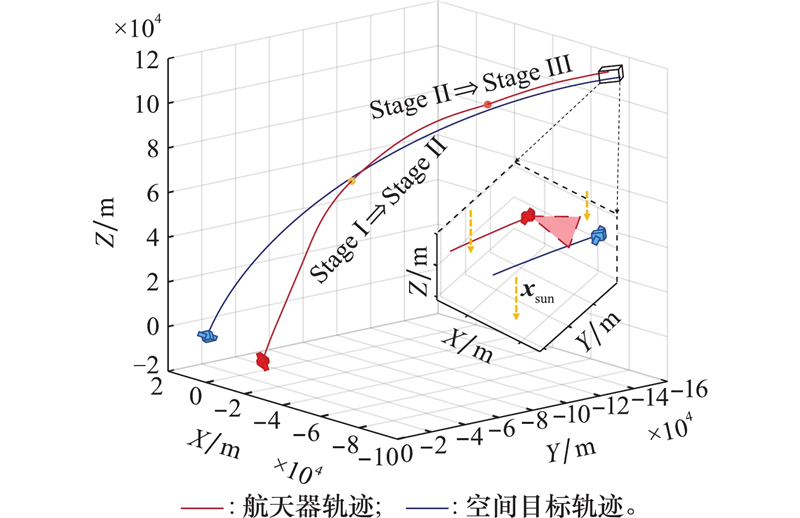
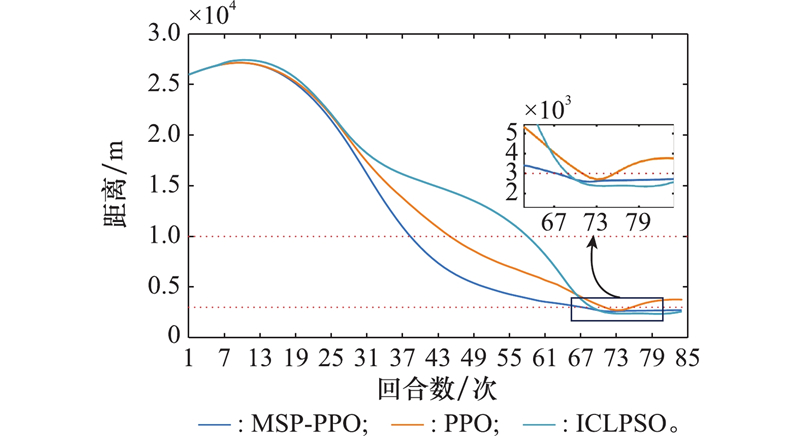
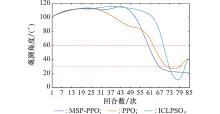
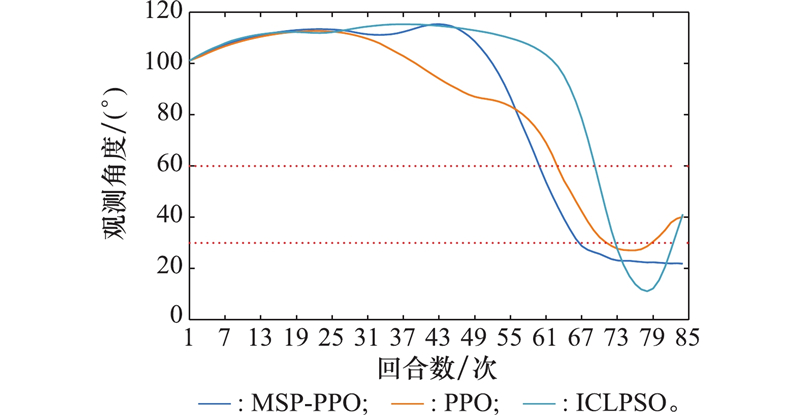
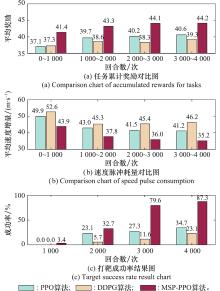
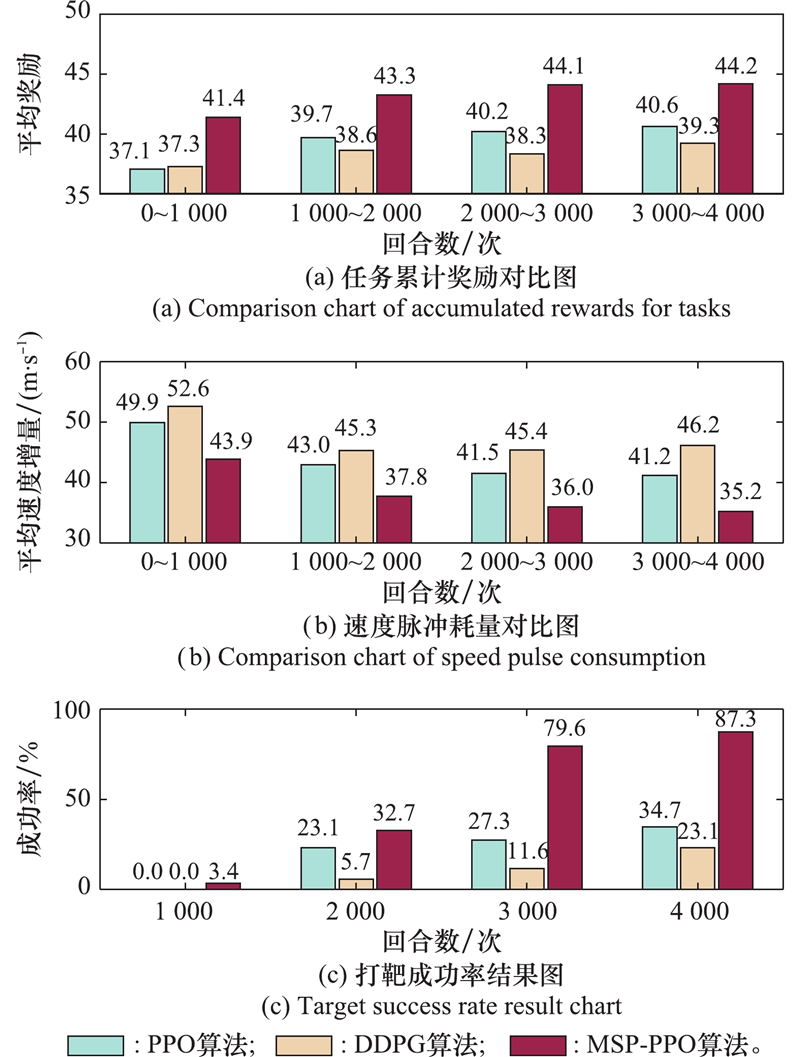
| 1 |
ABAD A F, MA O, PHAM K, et al. A review of space robotics technologies for on-orbit servicing[J]. Progress in Aerospace Sciences, 2014, 68, 1- 26.
doi: 10.1016/j.paerosci.2014.03.002
|
| 2 |
LI W J, CHENG D Y, LIU X G, et al. On-orbit service(OOS)of spacecraft: a review of engineering developments[J]. Progress in Aerospace Sciences, 2019, 108, 32- 120.
doi: 10.1016/j.paerosci.2019.01.004
|
| 3 |
周雅兰, 郭延宁, 李文龙, 等. 空间可修系统的维修性分析、评价与验证技术[J]. 系统工程与电子技术, 2019, 41 (11): 2647- 2655.
|
|
ZHOU Y L, GUO Y N, LI W L, et al. Maintainability analysis, evaluation and verification technology for space maintain-able systems[J]. Systems Engineering and Electronics, 2019, 41 (11): 2647- 2655.
|
| 4 |
HATTY I. Viability of on-orbit servicing spacecraft to prolong the operational life of satellites[J]. Journal of Space Safety Engineering, 2022, 9 (2): 263- 268.
doi: 10.1016/j.jsse.2022.02.011
|
| 5 |
FAGHIHI S, TAVANA S, ANTON H J. Optimal pose design for close-proximity on-orbit inspection[J]. Journal of Guidance, Control, and Dynamics, 2024, 47 (4): 609- 622.
|
| 6 |
ZHANG H T, LI Z, WANG W L, et al. Trajectory planning for optical satellite’s continuous surveillance of geostationary spacecraft[J]. IEEE Access, 2021, 9, 14282- 14293.
|
| 7 |
王涵巍, 张嘉城, 朱阅訸. 异构编队卫星近距离操作轨迹规划方法[J]. 系统工程与电子技术, 2024, 46 (3): 1048- 1057.
|
|
WANG H W, ZHANG J C, ZHU Y H. A trajectory planning method for proximity operations of heterogeneous formation satellites[J]. Systems Engineering and Electronics, 2024, 46 (3): 1048- 1057.
|
| 8 |
WANG J X, CHEN R, CHEN Z J, et al. Trajectory planning for complex shaped spacecraft proximity based on critical safety curve and disturbed fluid[J]. IEEE Trans. on Aerospace and Electronic Systems, 2023, 59 (5): 5930- 5942.
|
| 9 |
CHEN R, DONG M, BAI Y Z, et al. Trajectory planning and control of spacecraft avoiding dynamic debris swarm[J]. Aerospace Science and Technology, 2024, 151 (4): 109- 121.
|
| 10 |
LIANG W K, ZHI H, HAN P, et al. GEO satellite on-orbit refueling and debris removal hybrid mission planning under uncertainty[J]. Advances in Space Research, 2024, 74 (5): 2376- 2387.
doi: 10.1016/j.asr.2024.05.059
|
| 11 |
HE H Q, SHI P, ZHAO Y S. Adaptive connected hierarchical optimization algorithm for minimum energy spacecraft attitude maneuver path planning[J]. Astro-dynamics, 2023, 7 (2): 197- 209.
|
| 12 |
文启翟, 康志宇, 卫国宁, 等. 子母型航天器抵近观测任务流程规划方法研究[J]. 系统工程与电子技术, 2023, 45 (12): 3941- 3948.
|
|
WEN Q D, KANG Z Y, WEI G N, et al. Research on the approach observation mission flow planning method of parent-child spacecraft[J]. Systems Engineering and Electronics, 2023, 45 (12): 3941- 3948.
|
| 13 |
李君龙, 李松洲, 周荻. 一种多约束条件下的三脉冲交会优化设计方法[J]. 系统工程与电子技术, 2022, 44 (8): 2612- 2620.
doi: 10.12305/j.issn.1001-506X.2022.08.26
|
|
LI J L, LI S Z, ZHOU D. Optimization method for three-impulse rendezvous under multi-constraints[J]. Systems Engineering and Electronics, 2022, 44 (8): 2612- 2620.
doi: 10.12305/j.issn.1001-506X.2022.08.26
|
| 14 |
XUE W H, WANG B C, HUANG X X, et al. Spacecraft attitude maneuver planning with multi-sensor pointing constraints using improved RRT-star algorithm[J]. Advances in Space Research, 2023, 72 (5): 1485- 1495.
doi: 10.1016/j.asr.2023.04.024
|
| 15 |
HE H Q, SHI P, ZHAO Y S. Hierarchical optimization algorithm and applications of spacecraft trajectory optimization[J]. Aero Space, 2022, 9 (2): 81- 113.
|
| 16 |
ZHANG G X, WEN C X, HAN H W, et al. Aerocapture trajec-tory planning using hierarchical differential dynamic program-ming[J]. Journal of Spacecraft and Rockets, 2022, 59 (5): 1647- 1659.
doi: 10.2514/1.A35264
|
| 17 |
NAKKA Y K, HONIG W, CHOI C, et al. Information-based guidance and control architecture for multi-spacecraft on-orbit inspection[J]. Journal of Guidance, Control, and Dynamics, 2022, 45 (7): 1184- 1201.
|
| 18 |
HOVELL K, ULRICH S. Deep reinforcement learning for spacecraft proximity operations guidance[J]. Journal of Spacecraft and Rockets, 2021, 58 (2): 254- 264.
doi: 10.2514/1.A34838
|
| 19 |
JIANG R, YE D, XIAO Y, et al. Orbital interception pursuit strategy for random evasion using deep reinforcement learning[J]. Space: Science & Technology, 2023, 3 (5): 2692- 2695.
|
| 20 |
CHENG L, WANG Z B, JIANG F H, et al. Real time optimal control for spacecraft orbit transfer via multiscale deep neural networks[J]. IEEE Trans. on Aerospace and Electronic Systems, 2018, 55 (5): 2436- 2450.
|
| 21 |
ZHAO Y J, YANG H W, LI S. Real-time trajectory optimization for collision-free asteroid landing based on deep neural networks[J]. Advances in Space Research, 2022, 70 (1): 112- 124.
doi: 10.1016/j.asr.2022.04.006
|
| 22 |
TIPALDI M, IERVOLINO R, MASSENIO P R. Reinforcement learning in spacecraft control applications: advances, prospects, and challenges[J]. Annual Reviews in Control, 2022, 54, 1- 23.
doi: 10.1016/j.arcontrol.2022.07.004
|
| 23 |
WU J F, WEI C L, ZHANG H B, et al. Learning-based spacecraft reactive anti-hostile-rendezvous maneuver control in complex space environments[J]. Advances in Space Research, 2023, 72 (10): 4531- 4552.
doi: 10.1016/j.asr.2023.08.043
|
| 24 |
ANDREA B, CAPRA L, LAVAGNA M. Deep reinforcement learning spacecraft guidance with state uncertainty for autonomous shape reconstruction of uncooperative target[J]. Advances in Space Research, 2024, 73 (11): 5741- 5755.
doi: 10.1016/j.asr.2023.07.007
|
| 25 |
WU J F, WEI C L, ZHANG H B, et al. Learning-based spacecraft multi-constraint rapid trajectory planning for emergency collision avoidance[J]. Aerospace Science and Technology, 2024, 149 (3): 189- 212.
|
| 26 |
QU Q Y, LIU K X, WANG W, et al. Spacecraft proximity maneuvering and rendezvous with collision avoidance based on reinforcement learning[J]. IEEE Trans. on Aerospace and Electronic Systems, 2022, 58 (6): 5823- 5834.
doi: 10.1109/TAES.2022.3180271
|
| 27 |
孙雷翔, 郭延宁, 邓武东, 等. 一种超参数自适应航天器交会变轨策略优化方法[J]. 宇航学报, 2024, 45 (1): 52- 62.
doi: 10.3873/j.issn.1000-1328.2024.01.006
|
|
SUN L X, GUO Y N, DENG W D, et al. An adaptive hyperparameter strategy optimiz-ation method for spacecraft rendezvous and orbital transfer[J]. Journal of Astronautics, 2024, 45 (1): 52- 62.
doi: 10.3873/j.issn.1000-1328.2024.01.006
|
| 28 |
KANTA P S, INDRADEEP K, PAVITAR P S, et al. Advancing spacecraft rendezvous and docking through safety reinforcement learning and ubiquitous learning principles[J]. Computers in Human Behavior, 2024, 153 (3): 358- 391.
|
| 29 |
LORENZO C, ANDREA B, MICHELE L. Network architecture and action space analysis for deep reinforcement learning towards spacecraft autonomous guidance[J]. Advances in Space Research, 2023, 71 (9): 3787- 3802.
doi: 10.1016/j.asr.2022.11.048
|
| 30 |
GENG Y Z, YUAN L, GUO Y N, et al. Impulsive guidance of optimal pursuit with conical imaging zone for the evader[J]. Aerospace Science and Technology, 2023, 142 (11): 108- 126.
|