
系统工程与电子技术 ›› 2026, Vol. 48 ›› Issue (2): 694-704.doi: 10.12305/j.issn.1001-506X.2026.02.29
王旭, 蔡光斌, 余晓亚, 叶子绮, 单斌
收稿日期:2025-01-15
修回日期:2025-03-06
出版日期:2025-06-10
发布日期:2025-06-10
通讯作者:
蔡光斌
作者简介:王 旭(1998—),男,硕士研究生,主要研究方向为飞行器智能控制、人工智能基金资助:Xu WANG, Guangbin CAI, Xiaoya YU, Ziqi YE, Bin SHAN
Received:2025-01-15
Revised:2025-03-06
Online:2025-06-10
Published:2025-06-10
Contact:
Guangbin CAI
摘要:
针对高超声速飞行器姿态控制中的强非线性和大不确定性特点,以及传统强化学习算法在多重控制需求下训练收敛性和控制精度的不足,提出一种双动态自适应近端策略优化(proximal policy optimization, PPO)算法。算法通过软动态裁剪机制和策略驱动的熵调整机制,实现控制精度与执行机构保护的平衡,并在此基础上构建了集成气动特性和执行机构特性的综合仿真验证环境。结合比例-积分-微分控制思想,对状态观测空间进行了优化设计。仿真结果表明,与基准PPO算法相比,所提算法的收敛速度提升了22%,并显著改善了控制精度和动作平滑性。在不同飞行工况下,该方法展现出优异的策略适应性和鲁棒性,有效提升了飞行器的姿态控制性能。
中图分类号:
王旭, 蔡光斌, 余晓亚, 叶子绮, 单斌. 基于双动态PPO算法的高超声速飞行器姿态控制[J]. 系统工程与电子技术, 2026, 48(2): 694-704.
Xu WANG, Guangbin CAI, Xiaoya YU, Ziqi YE, Bin SHAN. Attitude control of hypersonic vehicle based on dual-dynamic PPO algorithm[J]. Systems Engineering and Electronics, 2026, 48(2): 694-704.

图1
高超声速飞行器纵向运动力学示意图"
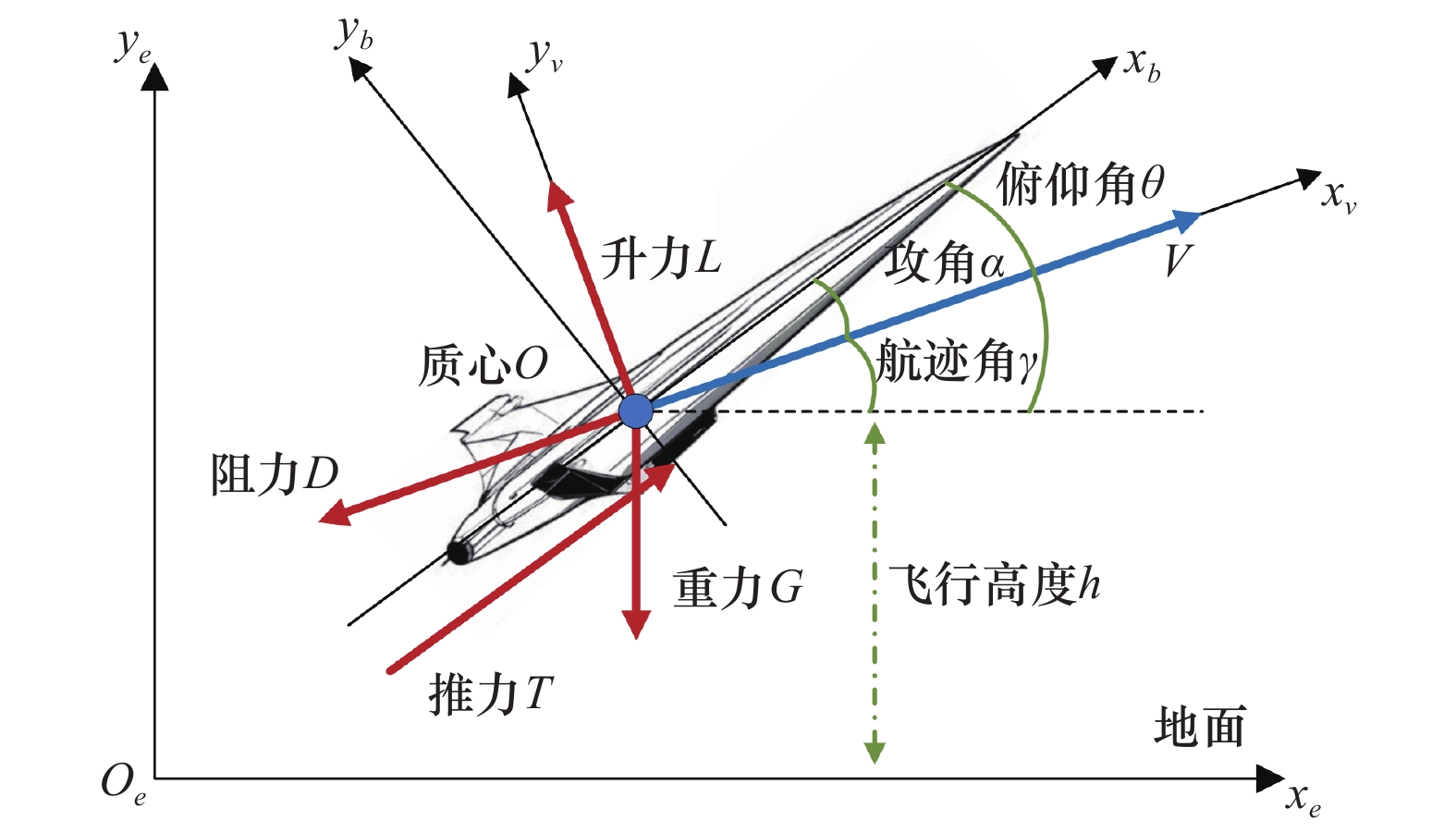
图2
强化学习训练过程"
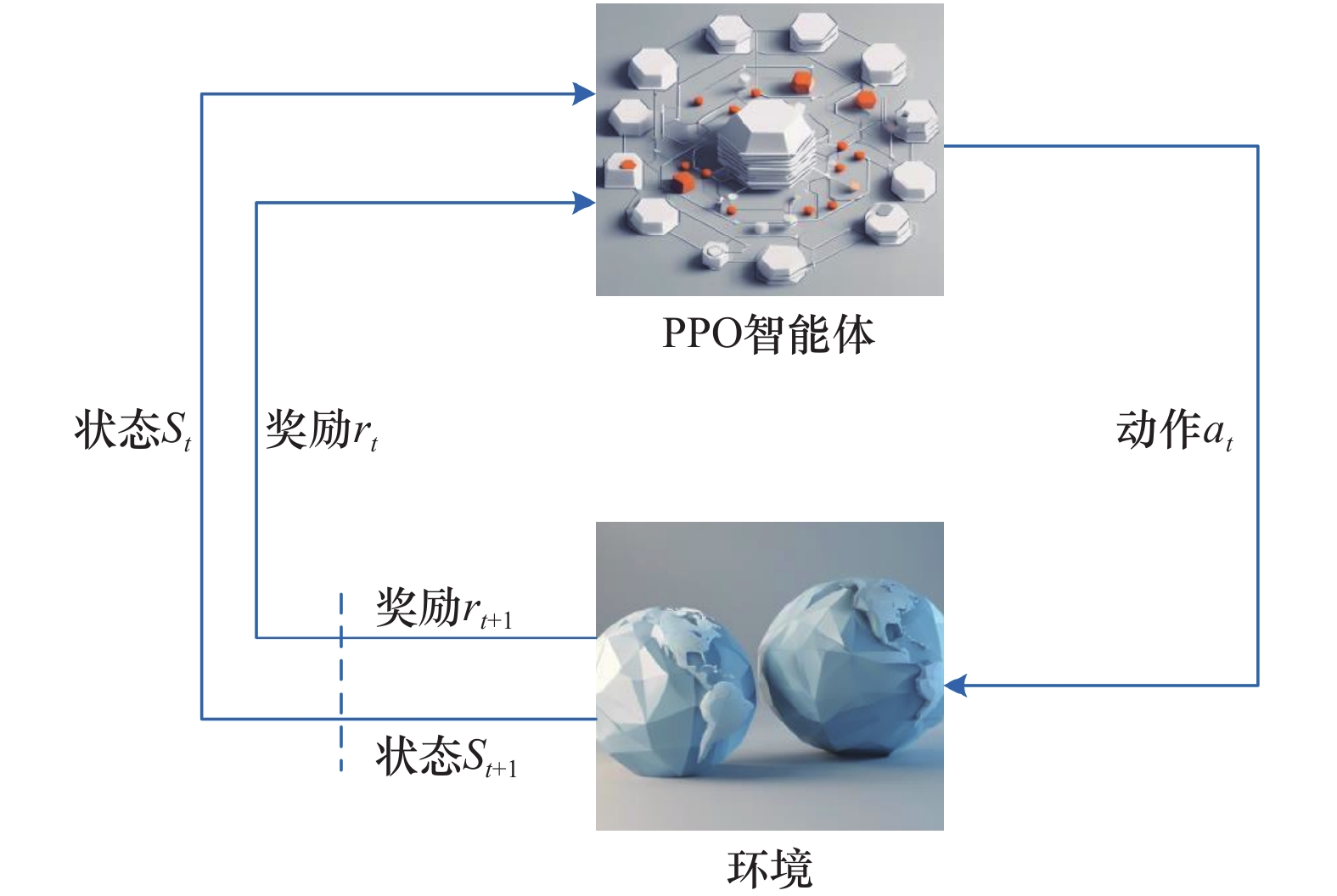
图3
PPO-Clip算法流程图"
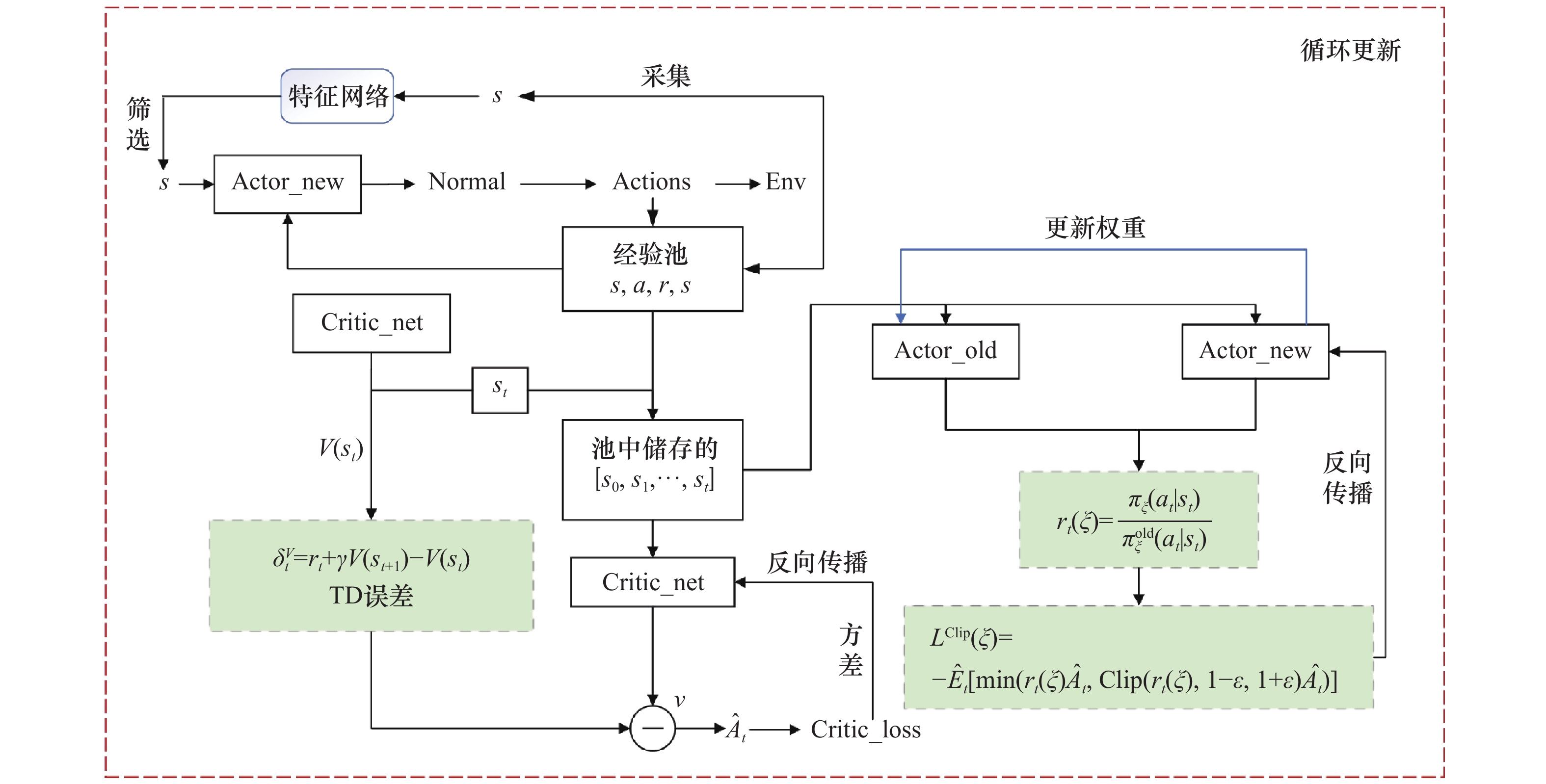
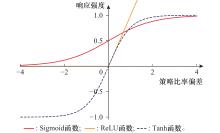
图4
常用激活函数对比"
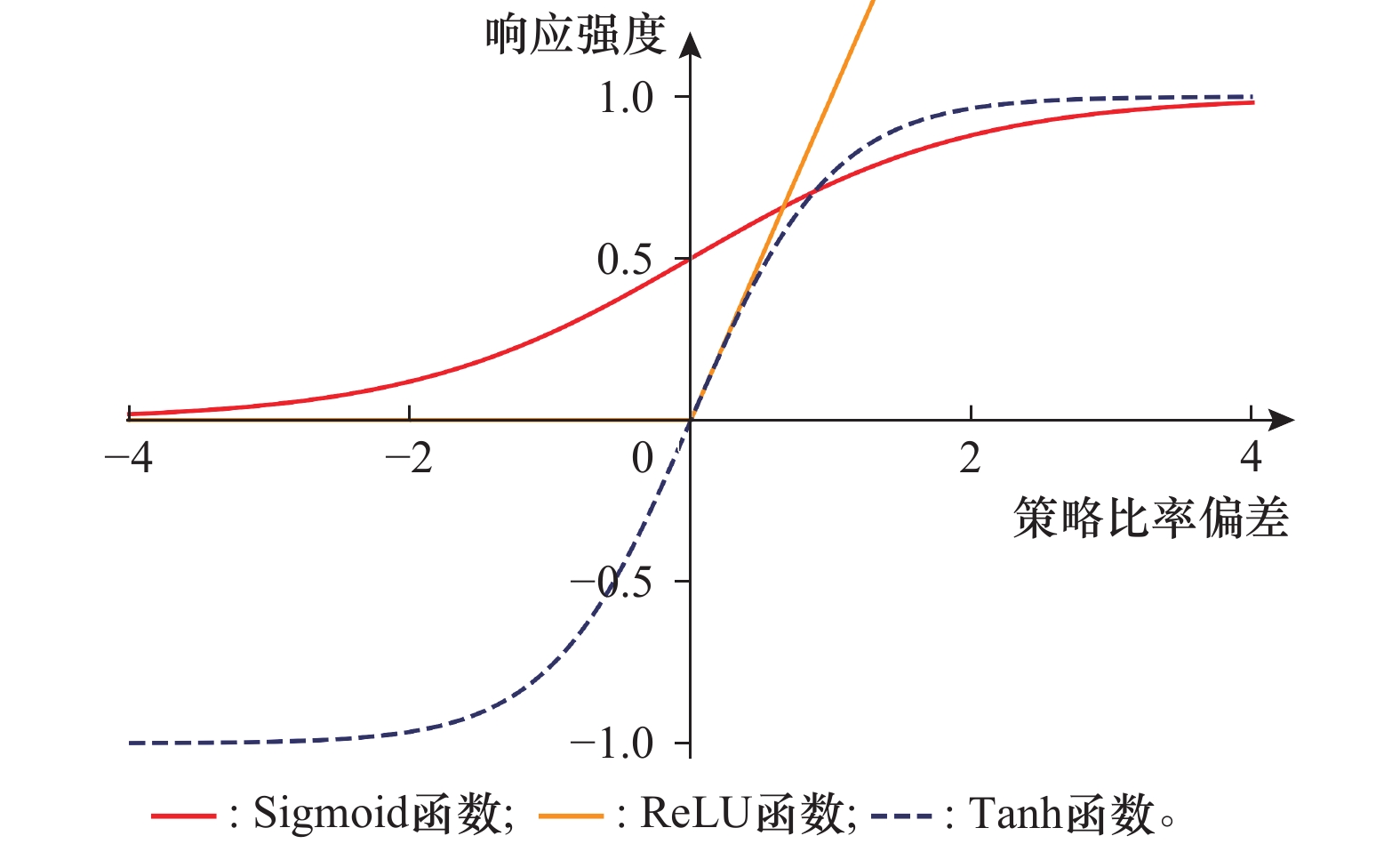
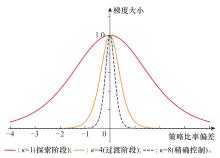
图5
不同$ \kappa $值下的归一化梯度曲线"
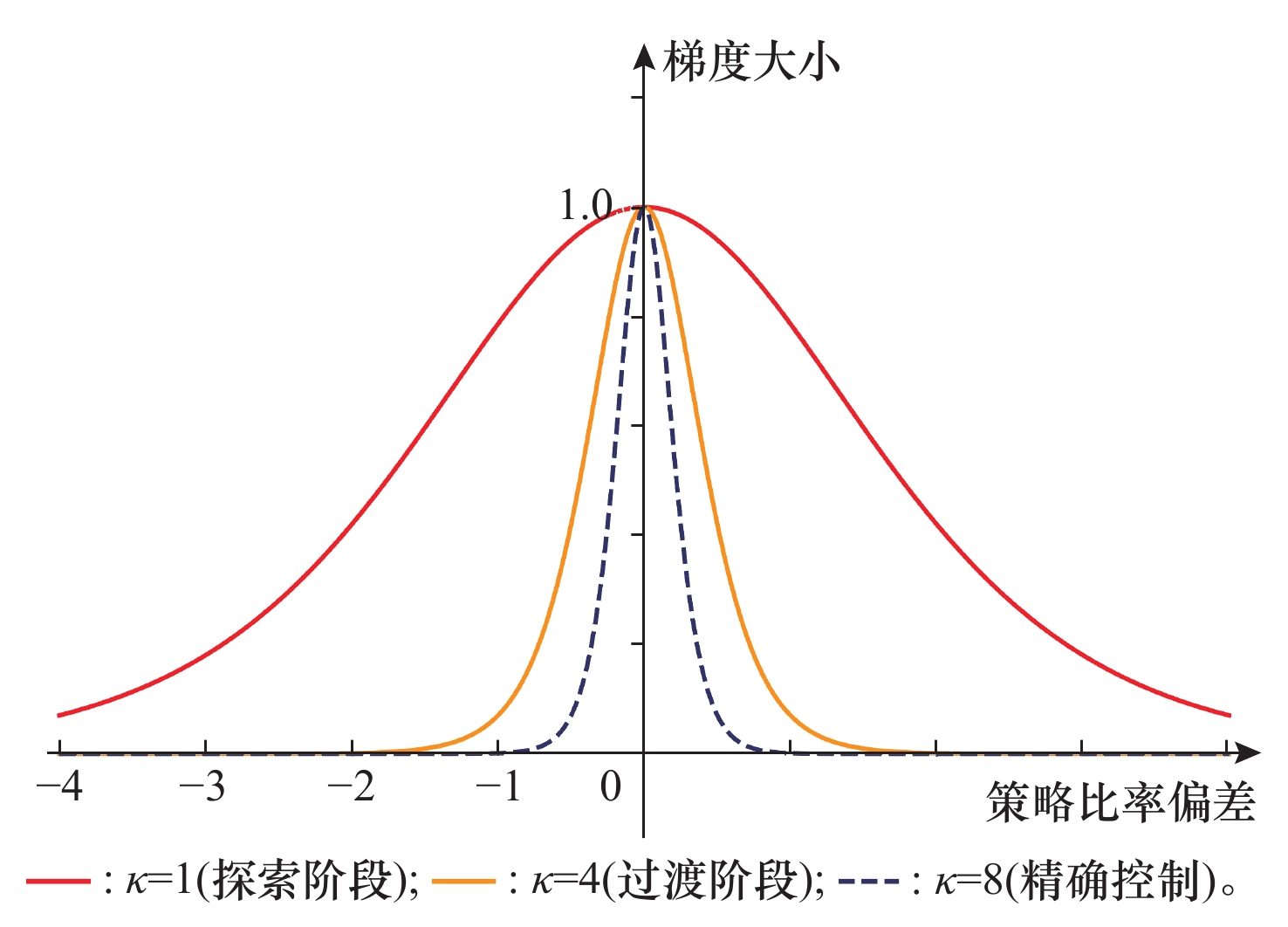
图6
基于D2A-PPO的高超声速飞行器姿态控制框图"
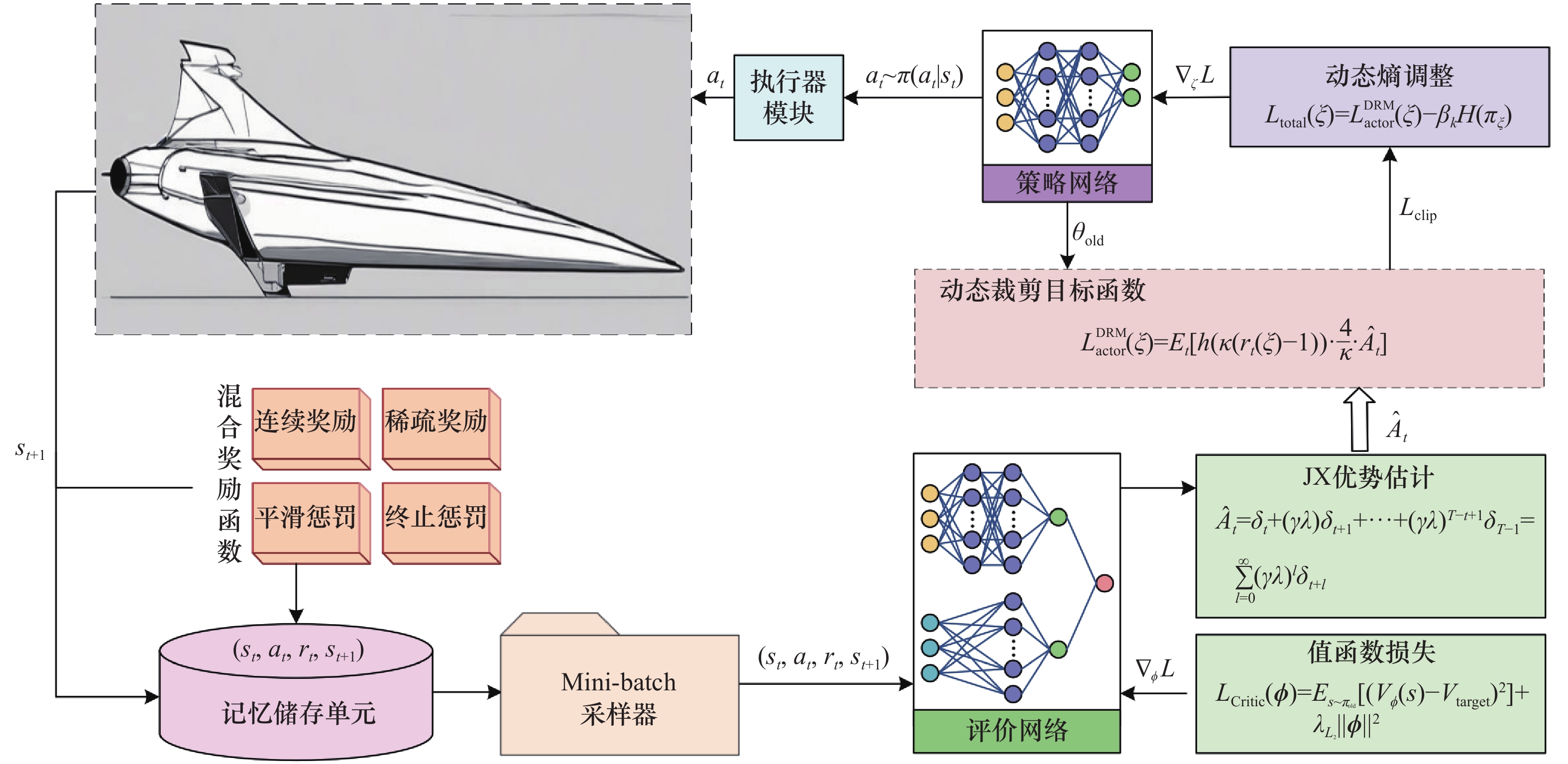
表1
D2A-PPO算法超参数设置"
| 参数 | 数值 | 参数 | 数值 | |
| 最大训练回合 | 2×104 | Actor 学习率 | 10−5 | |
| 每回合最大步数 | Critic学习率 | 10−5 | ||
| 系统采样时间 | 0.02 | 折扣因子 | 0.99 | |
| GAE系数 | 0.95 | Mini-batch | 32 | |
| Clip | 0.2 | 熵正则系数 | 10−2 | |
| [ | 熵系数衰减率 | 0.99 | ||
| 更新周期 | 10 | 正则系数 | 10−3 |
表2
神经网络结构参数"
| 网络层 | 策略网络 | 价值网络 | |||
| 神经元数 | 激活函数 | 神经元数 | 激活函数 | ||
| 输入层 | 3 | None | 6 | None | |
| 隐藏层1 | 150 | Tanh | 150 | Tanh | |
| 隐藏层2 | 150 | Tanh | 150 | Tanh | |
| 输出层 | 2 | Softplus | 1 | Linear | |
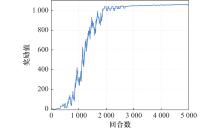
图7
D2A-PPO训练奖励值曲线"
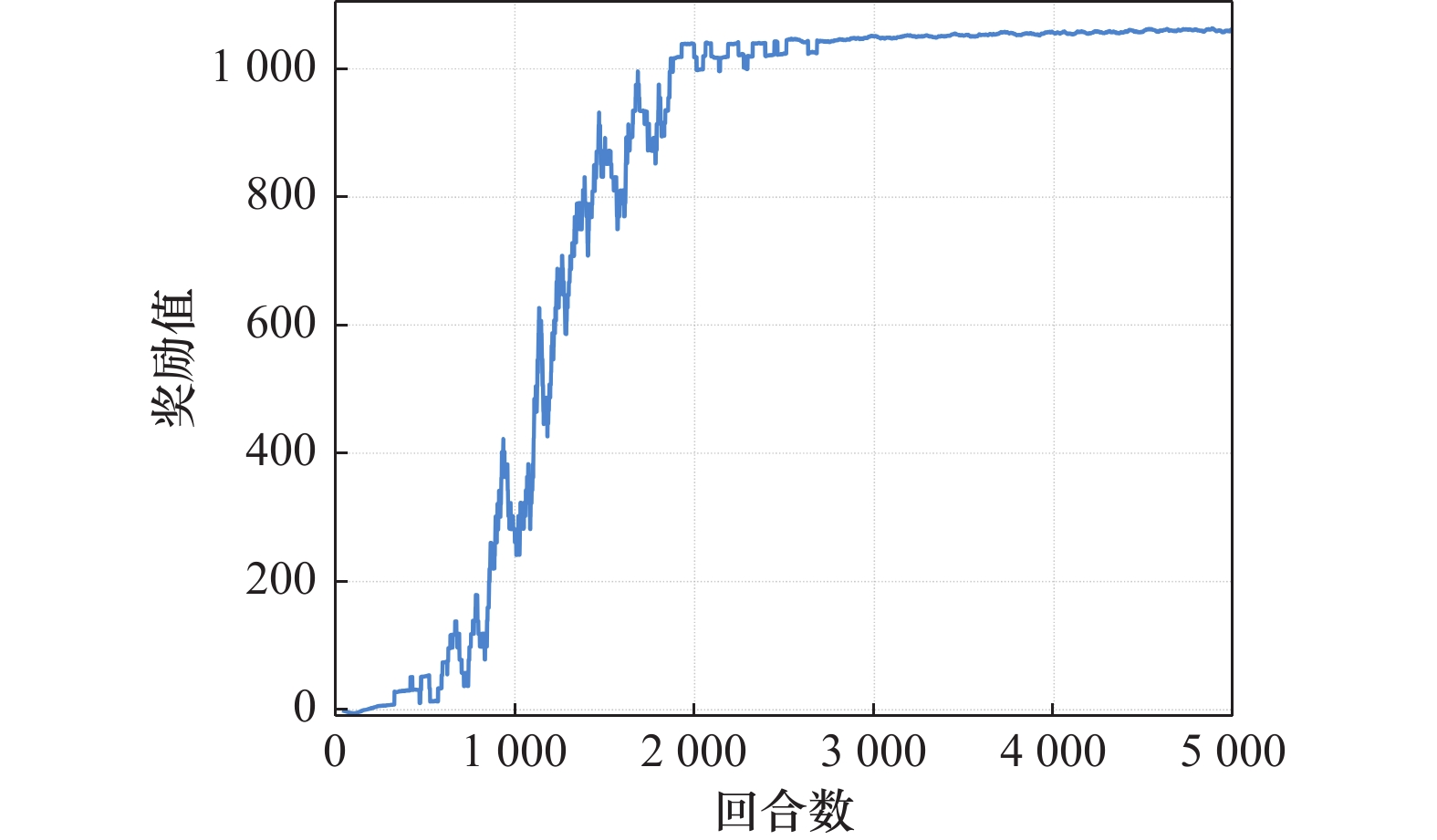
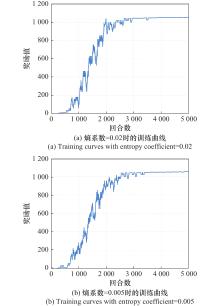
图8
不同熵系数下PPO算法的训练奖励对比"
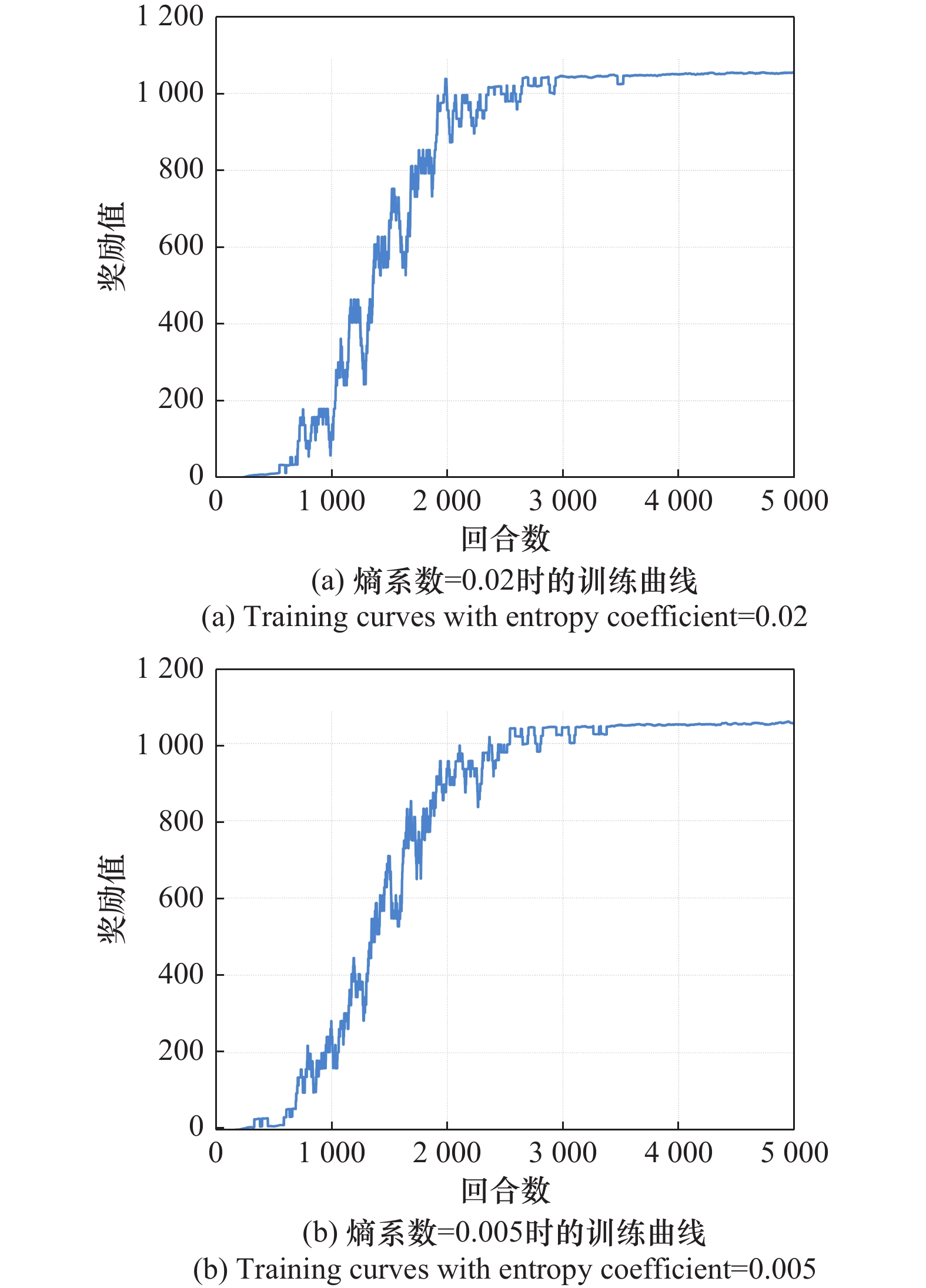
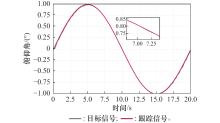
图9
正弦参考信号跟踪效果"
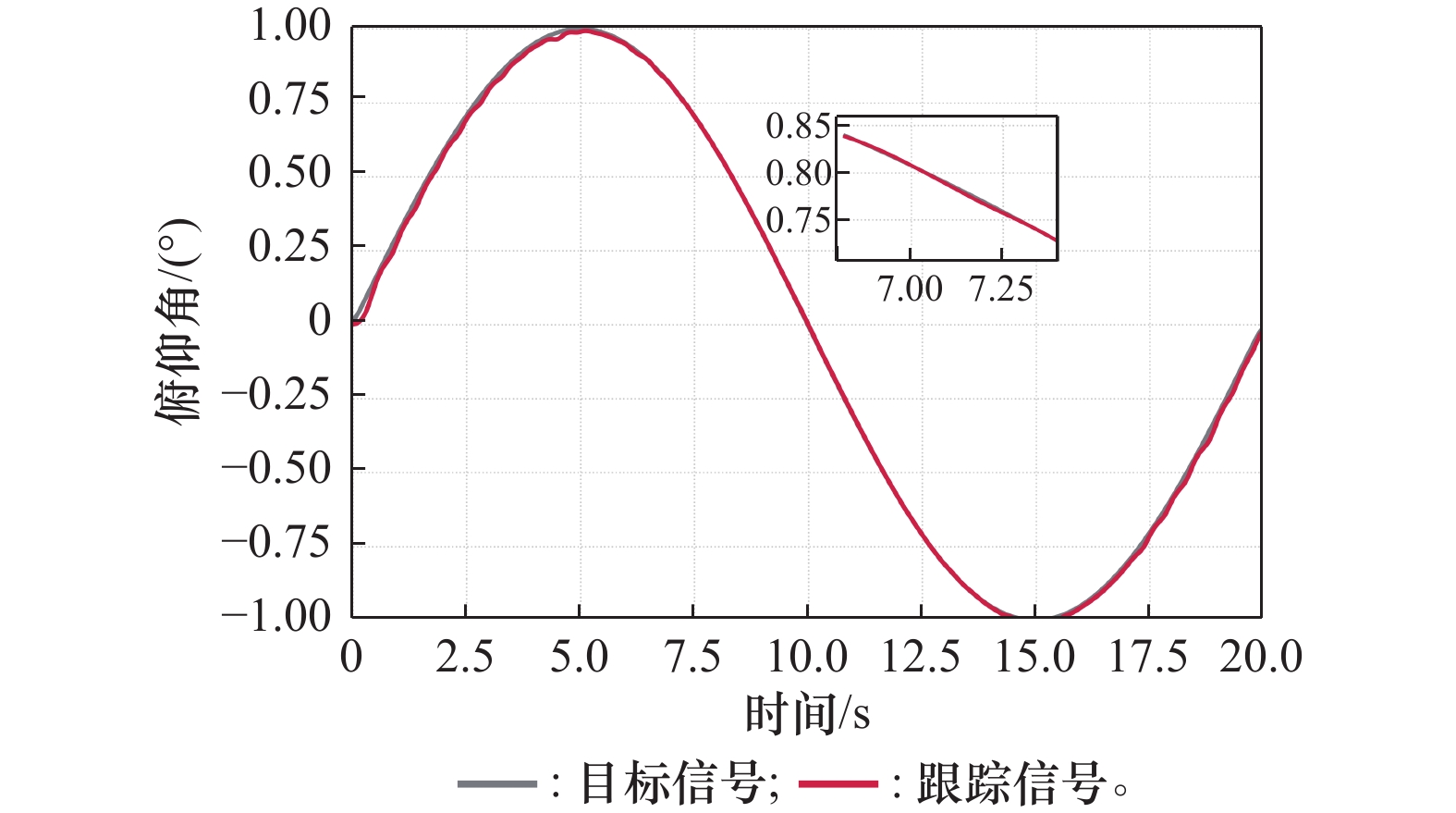
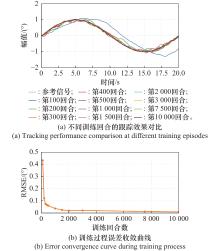
图10
强化学习控制器的训练效果与误差分析"
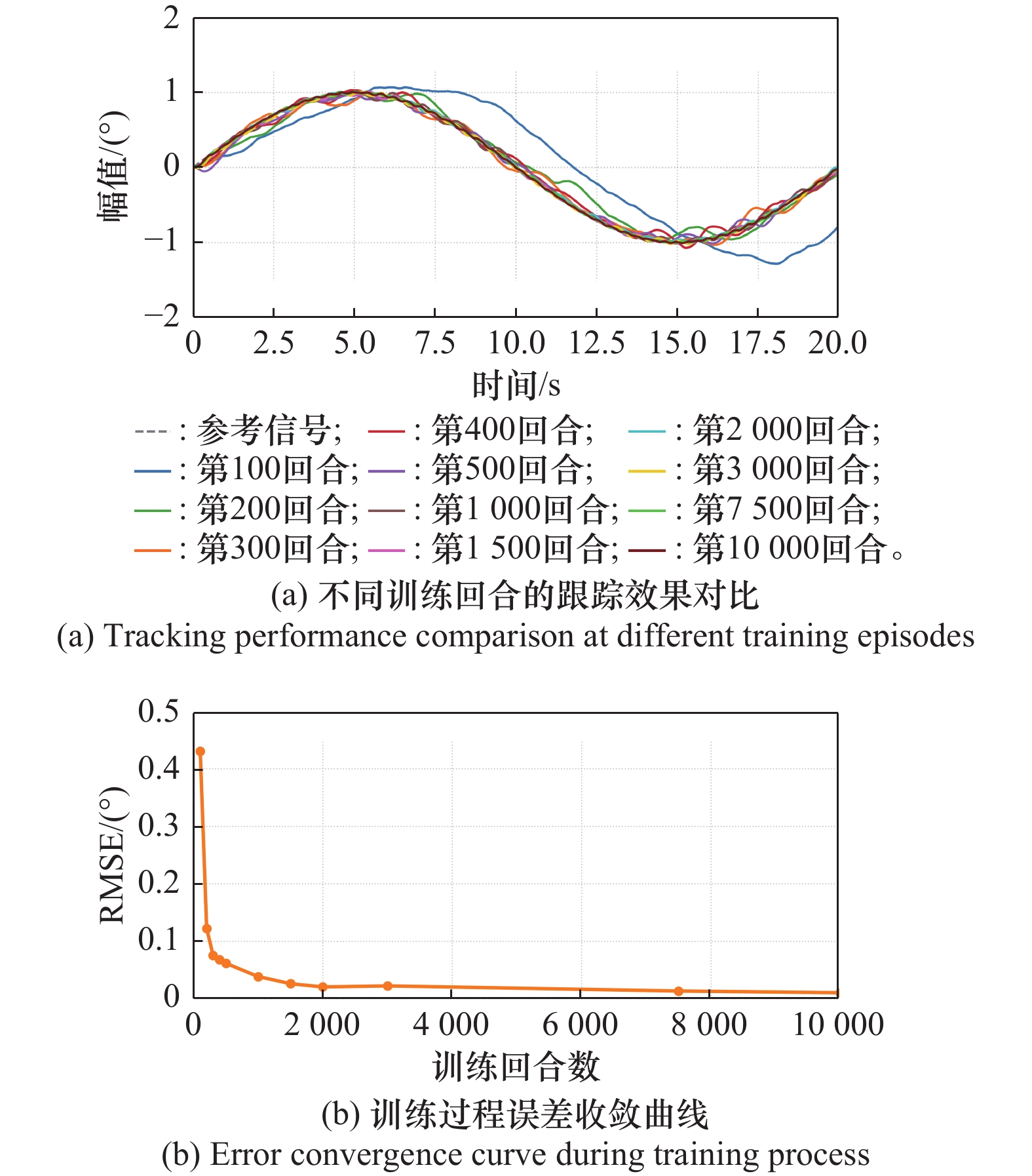
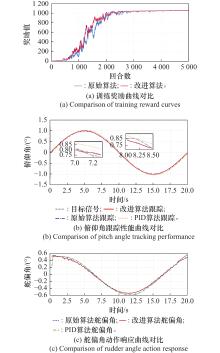
图11
正弦信号下算法性能对比分析"
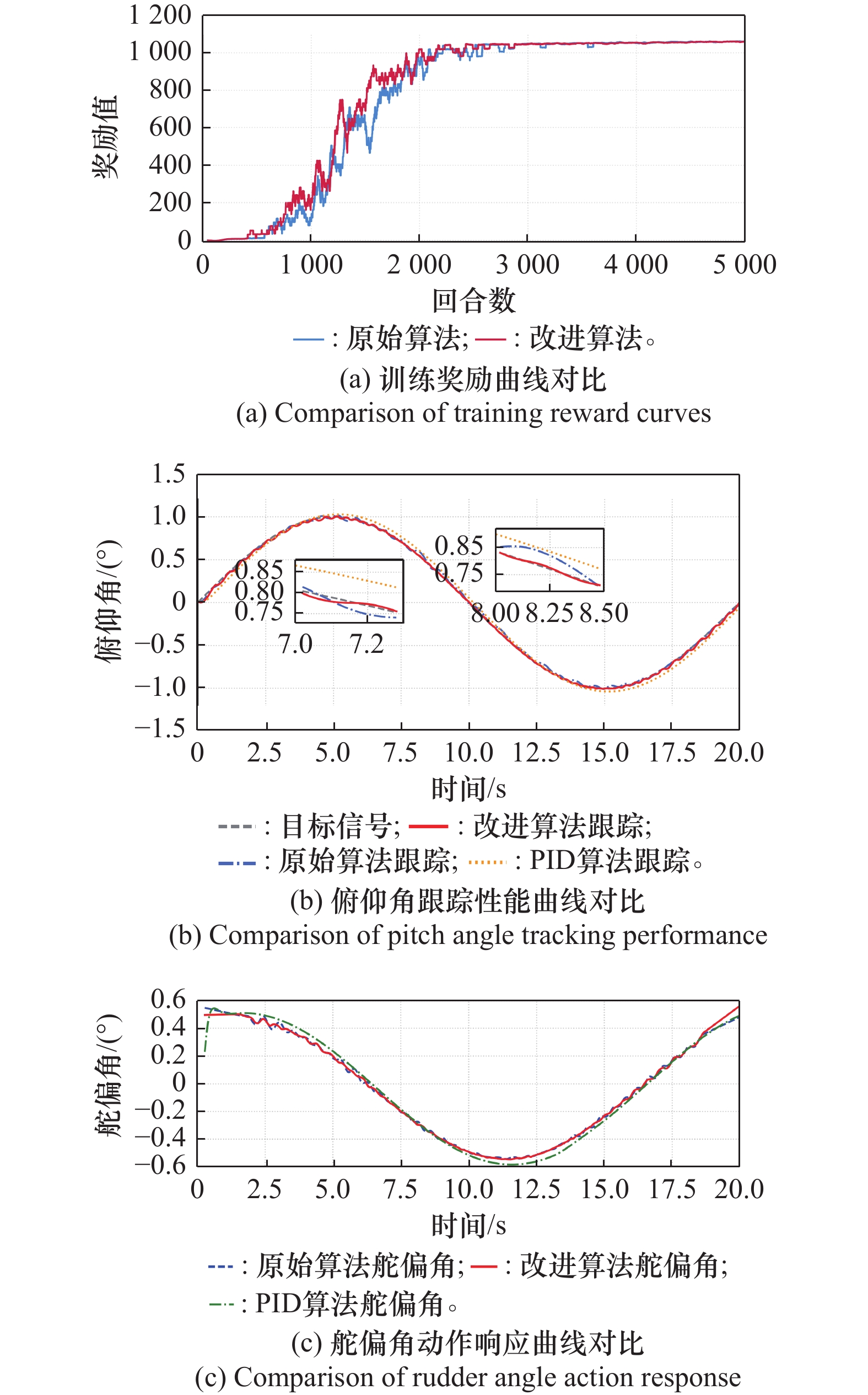
图12
阶跃信号下算法性能对比分析"
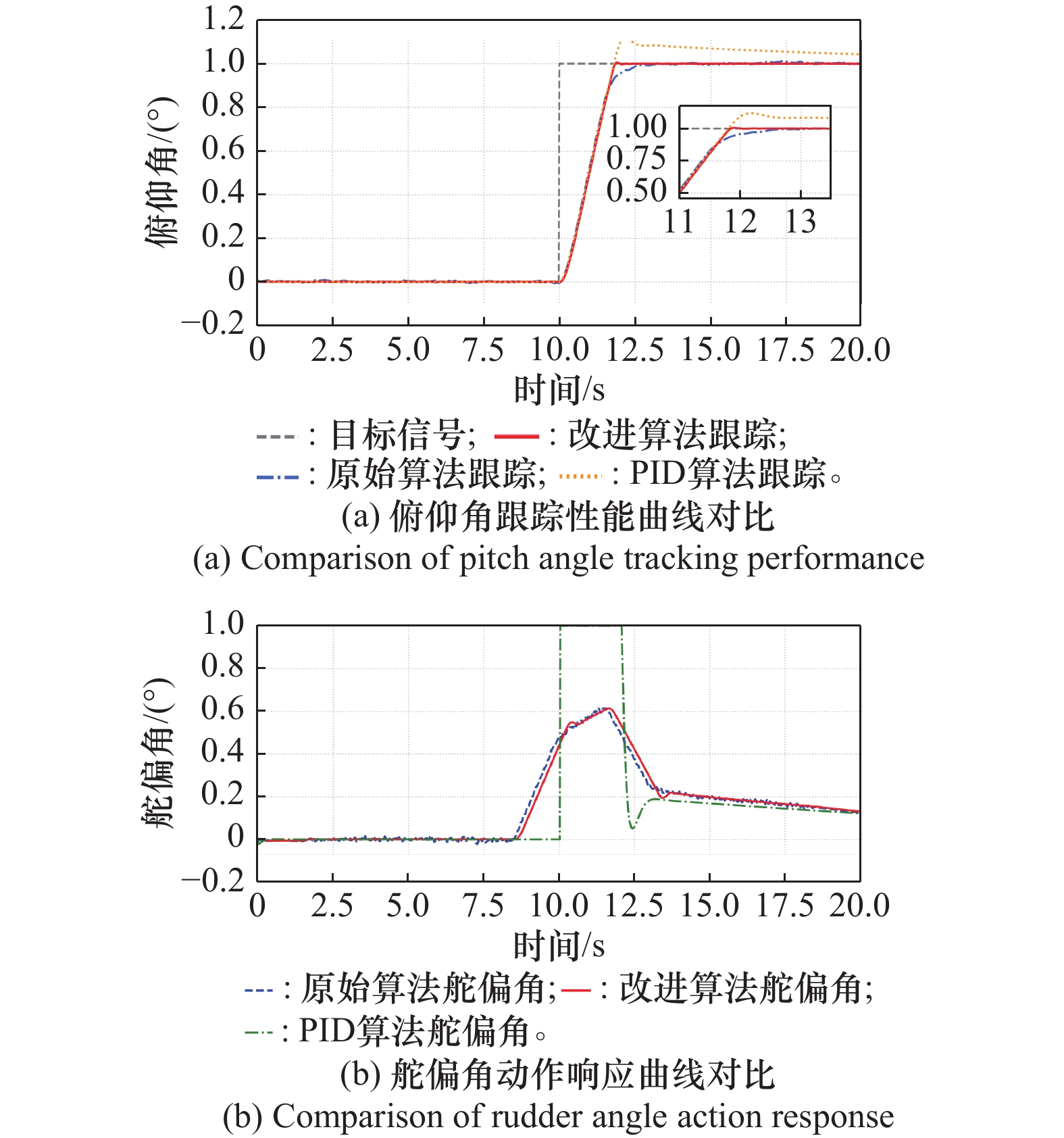
图13
复杂叠加信号下算法性能对比分析"
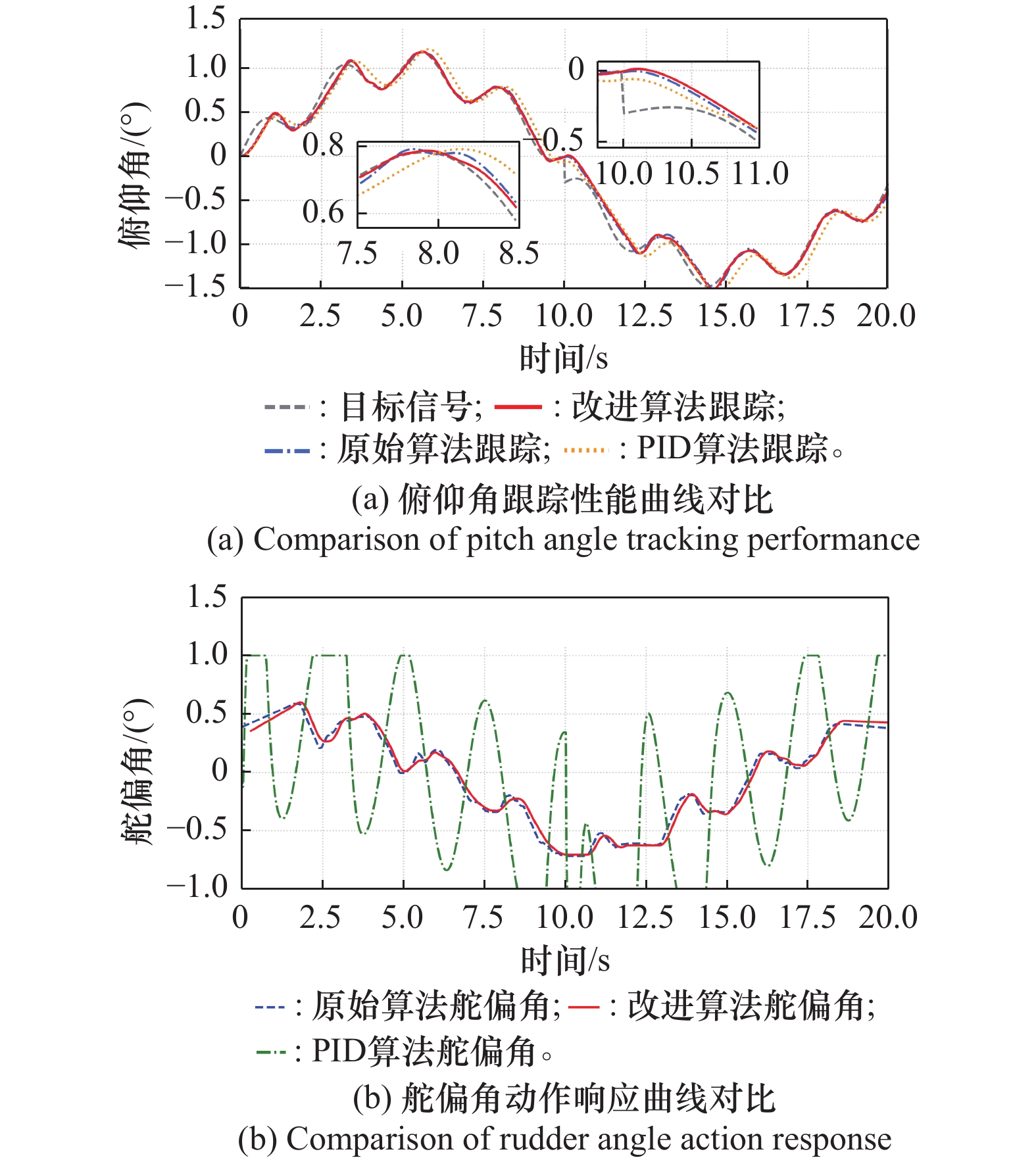
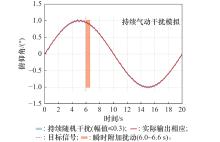
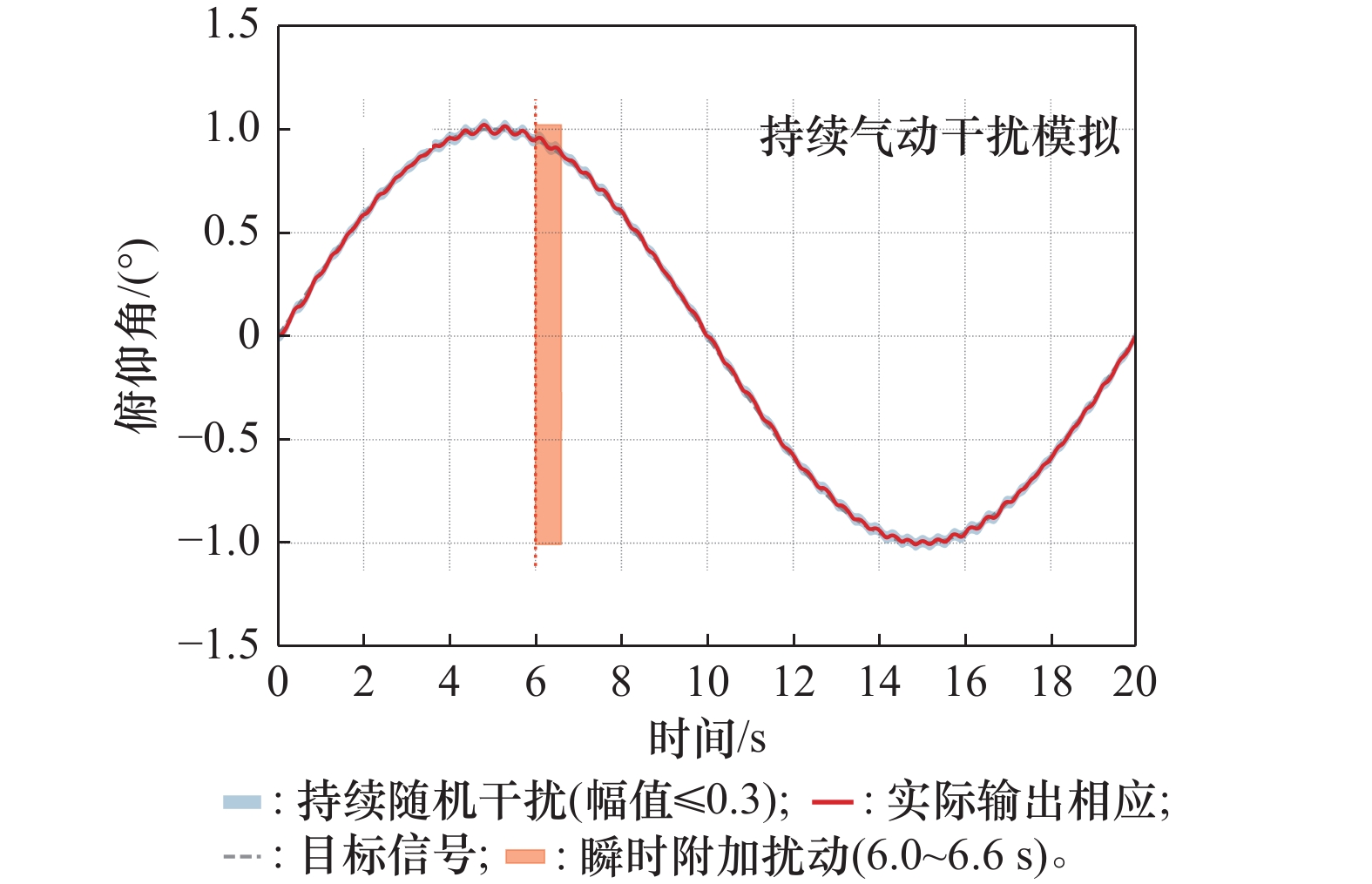
图14
复合扰动工况下的俯仰角跟踪效果"
| 1 |
XU H, CAI G B, MU C X, et al. Analytical reentry guidance framework based on swarm intelligence optimization and altitude-energy profile[J]. Chinese Journal of Aeronautics, 2023, 36 (12): 336- 348.
doi: 10.1016/j.cja.2023.07.029 |
| 2 |
LIU S X, YAN B B, HUANG W, et al. Current status and prospects of terminal guidance laws for intercepting hypersonic vehicles in near space: a review[J]. Journal of Zhejiang University-SCIENCE A, 2023, 24 (5): 387- 403.
doi: 10.1016/j.cja.2021.10.037 |
| 3 | 张远, 黄旭, 路坤锋, 等. 高超声速飞行器控制技术研究进展与展望[J]. 宇航学报, 2022, 43 (7): 866- 879. |
| ZHANG Y, HUANG X, LU K F, et al. Research progress and prospects of control technology for hypersonic vehicles[J]. Journal of Astronautics, 2022, 43 (7): 866- 879. | |
| 4 |
DING Y B, YUE X K, CHEN G S, et al. Review of control and guidance technology on hypersonic vehicle[J]. Chinese Journal of Aeronautics, 2022, 35 (7): 1- 18.
doi: 10.1016/j.cja.2021.10.037 |
| 5 | HAN X, ZHENG Z Z, LIU L, et al. Online policy iteration ADP-based attitude-tracking control for hypersonic vehicles[J]. Aerospace Science and Technology, 2020, 106, 106233. |
| 6 |
GAMBHIRE S J, KISHORE D R, LON-DHE P S, et al. Review of sliding mode based control techniques for control system applications[J]. International Journal of Dynamics and Control, 2021, 9 (1): 363- 378.
doi: 10.1007/s40435-020-00638-7 |
| 7 | DONE Z, BIN J, HAO Y. Backstepping-based decentralized fault-tolerant control of hypersonic vehicles in PDE-ODE form[J]. IEEE Trans. on Automatic Control, 2021, 67 (3): 1210- 1225. |
| 8 | 赵昱宇, 索超, 王雨潇. 基于微分平坦的高超声速飞行器跟踪控制方法[J]. 系统工程与电子技术, 2024, 46 (3): 1084- 1092. |
| ZHAO Y Y, SUO C, WANG Y X. Differential flatness-based tracking control method for hypersonic vehicle[J]. Systems Engineering and Electronics, 2024, 46 (3): 1084- 1092. | |
| 9 | CAI G B, WU T, HAO M R, et al. Dynamic event-triggered gain-scheduled H∞ control for a polytopic LPV model of morphing aircraft[J]. IEEE Trans. on Aerospace and Electronic Systems, 2024, 61(1): 93−106. |
| 10 | ZHANG X, HU W, WEI C, et al. Nonlinear disturbance observer based adaptive super-twisting sliding mode control for generic hypersonic vehicles with coupled multisource disturbances[J]. European Journal of Control, 2021, 5 (7): 253- 262. |
| 11 | GUO R Y, DING Y B, YUE X K. Active adaptive continuous nonsingular terminal sliding mode controller for hypersonic vehicle[J]. Aerospace Science and Technology, 2023, 137, 108279. |
| 12 |
ZHAO H W, YANG L. Global adaptive neural backstepping control of a flexible hypersonic vehicle with disturbance estimation[J]. Aircraft Engineering and Aerospace Technology, 2022, 94 (4): 492- 504.
doi: 10.1108/AEAT-08-2020-0178 |
| 13 | 唐伟强, 甲成超, 石文科, 等. 高超声速飞行器积分滑模自抗扰控制研究[J]. 现代防御技术, 2024, 52 (5): 40- 50. |
| TANG W Q, JIA C C, SHI W K, et al. Research on integral sliding mode active disturbance rejection control for hypersonic vehicle[J]. Modern Defence Technology, 2024, 52 (5): 40- 50. | |
| 14 |
LIU L, LIU Y X, ZHOU L L, et al. Cascade ADRC with neural network-based ESO for hypersonic vehicle[J]. Journal of the Franklin Institute, 2023, 360 (12): 9115- 9138.
doi: 10.1016/j.jfranklin.2022.09.019 |
| 15 |
AZAR A T, KOUBAA A, ALI M N, et al. Drone deep reinforcement learning: a review[J]. Electronics, 2021, 10 (9): 999.
doi: 10.3390/electronics10090999 |
| 16 | ZHANG M H, WU Y H, LI C Y. Reinforcement learning strategy for spacecraft attitude hyperagile tracking control with uncertainties[J]. Aerospace Science and Technology, 2021, 119, 107126. |
| 17 |
LIU Y C, HUANG C Y. DDPG-based a-daptive robust tracking control for aerial manipulators with decoupling approach[J]. IEEE Trans. on Cybernetics, 2022, 52 (8): 8258- 8271.
doi: 10.1109/TCYB.2021.3049555 |
| 18 | 黄旭, 柳嘉润, 贾晨辉, 等. 强化学习控制方法及在类火箭飞行器上的应用[J]. 宇航学报, 2023, 44 (5): 708- 718. |
| HUANG X, LIU J R, JIA C H, et al. Reinforcement learning control methods and their applications to rocket-like vehicles[J]. Journal of Astronautics, 2023, 44 (5): 708- 718. | |
| 19 |
XU L, YUE H J, YU S, et al. Modified deep deterministic policy gradient based on active disturbance rejection control for hypersonic vehicles[J]. Neural Computing and Applications, 2024, 36 (8): 4071- 4081.
doi: 10.1007/s00521-023-09302-5 |
| 20 | 马少捷, 惠俊鹏, 王宇航, 等. 变形飞行器深度强化学习姿态控制方法研究[J]. 航天控制, 2022, 40 (6): 3- 10. |
| MA S J, HUI J P, WANG Y H, et al. Research on deep reinforcement learning attitude control method for deformed vehicle[J]. Aerospace Control, 2022, 40 (6): 3- 10. | |
| 21 |
SHI L, WANG X S, CHENG Y H. Safe reinf-orcement learning-based robust approximate optimal control for hypersonic flight vehicles[J]. IEEE Trans. on Vehicular Technology, 2023, 72 (9): 11401- 11414.
doi: 10.1109/TVT.2023.3264243 |
| 22 | ZHU Y, PAN M, ZHOU W, et al. Intelligent direct thrust control for multivariable turbofan engine based on reinforcement and deep learning methods[J]. Aerospace Science and Technology, 2022, 13 (1): 107972. |
| 23 |
SONG J, LUO Y, ZHAO M, et al. Fault-tolerant integrated guidance and control design for hypersonic vehicle based on PPO[J]. Mathematics, 2022, 10 (18): 3401.
doi: 10.3390/math10183401 |
| 24 |
PAPINI M, PIROTTA M, RESTELLI M. Smoothing policies and safe policy gradients[J]. Machine Learning, 2022, 111 (11): 4081- 4137.
doi: 10.1007/s10994-022-06232-6 |
| 25 | 王冠, 茹海忠, 张大力, 等. 弹性高超声速飞行器智能控制系统设计[J]. 系统工程与电子技术, 2022, 44 (7): 2276- 2285. |
| WANG G, RU H Z, ZHANG D L, et al. Design of intelligent control system for flexible hypersonic vehicle[J]. Systems Engineering and Electronics, 2022, 44 (7): 2276- 2285. | |
| 26 | TANG W Q, LONG W K, GAO H Y. Model predictive control of hypersonic vehicles accommodating constraints[J]. IET Control Theory & Applications, 2017, 11 (15): 2599- 2606. |
| 27 | ZHANG J W, ZHANG Z H, HAN S, et al. Proximal policy optimization via enhanced exploration efficiency[J]. Information Sciences, 2022, 6 (9): 750- 765. |
| 28 | DAI J T, JI J M, YANG L, et al. Augmented proximal policy optimization for safe rein-forcement learning[C]//Proc. of the AAAI Conference on Artificial Intelligence, 2023: 7288−7295. |
| 29 | CHEN X, DIAO D C, CHEN H C, et al. The sufficiency of off-policyness and soft clipping: PPO is still insufficient according to an off-policy measure[C]// Proc. of the AAAI Conference on Artificial Intelligence. 2023: 7078-7086. |
| 30 | SUMIEA E H, ABDULKADIR S J, ALHUSSIAN H S, et al. Deterministic policy gradient algorithms[C]// Proc. of the International Conference on Machine Learning, 2014: 387−395. |
| 31 | GU Y, CHENG Y, CHEN C L P, et al. Proximal policy optimization with policy feedback[J]. IEEE Trans. on Systems, Man, and Cybernetics: Systems, 2021, 52 (7): 4600- 4610. |
| 32 | CHENG Y H, HUANG L Y, WANG X S. Authentic boundary proximal policy optimization[J]. IEEE Trans. on Cybernetics, 2021, 52 (9): 9428- 9438. |
| 33 |
LECUN Y, BENGIO Y, HINTON G. Deep learning[J]. Nature, 2015, 521 (7553): 436- 444.
doi: 10.1038/nature14539 |
| 34 | SRIVASTAVA A, SALAOAKA S M. Parameterized MDPs and reinforcement learning problems—a maximum entropy principle-based framework[J]. IEEE Trans. on Cybernetics, 2021, 52 (9): 9339- 9351. |
| 35 | 胡军. 高超声速飞行器非线性自适应姿态控制[J]. 宇航学报, 2017, 38 (12): 1281- 1288. |
| HU J. Nonlinear adaptive attitude controlfor hypersonic vehicles[J]. Journal of Astronautics, 2017, 38 (12): 1281- 1288. |
| [1] | 薛锦妍, 张雅声, 陶雪峰, 杨茗棋, 赵帅龙. GEO航天器轨道机动控制研究进展[J]. 系统工程与电子技术, 2026, 48(1): 290-300. |
| [2] | 宋传龙, 张倩武, 何健, 周文骏, 王辉, 孔巍巍, 田文波. 基于MADDPG算法的星地协同边缘计算任务卸载方法[J]. 系统工程与电子技术, 2026, 48(1): 350-360. |
| [3] | 魏潇龙, 吴亚荣, 姚登凯, 赵顾颢. 基于深度强化学习的无人机空战机动分层决策算法[J]. 系统工程与电子技术, 2025, 47(9): 2993-3003. |
| [4] | 朱运豆, 孙海权, 胡笑旋. 基于指针网络架构的多星协同成像任务规划方法[J]. 系统工程与电子技术, 2025, 47(7): 2246-2255. |
| [5] | 孟麟芝, 孙小涓, 胡玉新, 高斌, 孙国庆, 牟文浩. 面向卫星在轨处理的强化学习任务调度算法[J]. 系统工程与电子技术, 2025, 47(6): 1917-1929. |
| [6] | 郑康洁, 张新宇, 王伟菘, 刘震生. DQN与规则结合的智能船舶动态自主避障决策[J]. 系统工程与电子技术, 2025, 47(6): 1994-2001. |
| [7] | 刘书含, 李彤, 李富强, 杨春刚. 意图态势双驱动的数据链抗干扰通信机制[J]. 系统工程与电子技术, 2025, 47(6): 2055-2064. |
| [8] | 黄迅, 陈柏屹, 彭寿勇, 刘燕斌, 杨犇, 庞浩然. 控制约束下的高超声速飞行器轨迹优化策略[J]. 系统工程与电子技术, 2025, 47(5): 1646-1654. |
| [9] | 熊威, 张栋, 任智, 杨书恒. 面向有人/无人机协同打击的智能决策方法研究[J]. 系统工程与电子技术, 2025, 47(4): 1285-1299. |
| [10] | 马鹏, 蒋睿, 王斌, 徐盟飞, 侯长波. 基于隐式对手建模的策略重构抗智能干扰方法[J]. 系统工程与电子技术, 2025, 47(4): 1355-1363. |
| [11] | 张兰, 张彪, 梁天一, 朱辉杰. 面向电磁信息智能控制的生成对抗网络研究进展[J]. 系统工程与电子技术, 2025, 47(3): 730-744. |
| [12] | 唐开强, 傅汇乔, 刘佳生, 邓归洲, 陈春林. 基于深度强化学习的带约束车辆路径分层优化研究[J]. 系统工程与电子技术, 2025, 47(3): 827-841. |
| [13] | 陈夏瑢, 李际超, 陈刚, 刘鹏, 姜江. 基于异质网络的装备体系组合发展规划问题[J]. 系统工程与电子技术, 2025, 47(3): 855-861. |
| [14] | 黄绍洧, 都延丽, 刘燕斌, 王跃萍, 刘武. 有限时间收敛的自适应滑模协同末制导[J]. 系统工程与电子技术, 2025, 47(3): 961-969. |
| [15] | 刘洋, 孟凡一, 陈刚. 基于强化学习的变形飞行器抗扰补偿控制方法[J]. 系统工程与电子技术, 2025, 47(12): 4130-4142. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||