
系统工程与电子技术 ›› 2025, Vol. 47 ›› Issue (4): 1285-1299.doi: 10.12305/j.issn.1001-506X.2025.04.25
熊威1,2, 张栋1,2,*, 任智1,2, 杨书恒1,2
收稿日期:2024-04-26
出版日期:2025-04-25
发布日期:2025-05-28
通讯作者:
张栋
作者简介:熊威(2000—), 男, 博士研究生, 主要研究方向为飞行器集群智能规划与自主控制基金资助:Wei XIONG1,2, Dong ZHANG1,2,*, Zhi REN1,2, Shuheng YANG1,2
Received:2024-04-26
Online:2025-04-25
Published:2025-05-28
Contact:
Dong ZHANG
摘要:
有人/无人机协同是目前无人机空战发展的趋势, 智能决策是实现有人机与无人机协同打击的关键。高动态战场环境、非对称作战任务和异构多源协同体系, 导致无人机自主能力和实时性较差, 策略训练困难, 是有人/无人机协同打击研究的难点。基于有人/无人机协同的忠诚僚机方案, 设计典型的有人/无人机协同打击样式, 提出一种基于改进多智能体双延迟深度确定性(multi-agent twin delayed deep deterministic, MATD3)策略梯度算法的强化学习方法。首先, 设计基于MATD3策略梯度算法、课程学习(curriculum learning, CL)的协同机动决策训练框架和基于迁移学习的预训练(pre-train, PT)策略, 解决有人/无人机协同打击策略训练困难的问题。其次, 建立面向有人/无人机协同机动的多机协同奖励函数和状态空间。最后, 结合设计的搭载六自由度仿真模型的数字仿真推演平台, 验证训练得到的打击策略具有高效的打击和生存能力, 能够指导未来有人/无人机协同打击作战的实际应用。
中图分类号:
熊威, 张栋, 任智, 杨书恒. 面向有人/无人机协同打击的智能决策方法研究[J]. 系统工程与电子技术, 2025, 47(4): 1285-1299.
Wei XIONG, Dong ZHANG, Zhi REN, Shuheng YANG. Research on intelligent decision-making methods for coordinated attack by manned aerial vehicles and unmanned aerial vehicles[J]. Systems Engineering and Electronics, 2025, 47(4): 1285-1299.
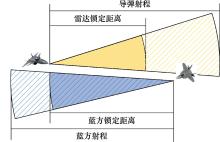
图1
态势感知能力与打击范围"
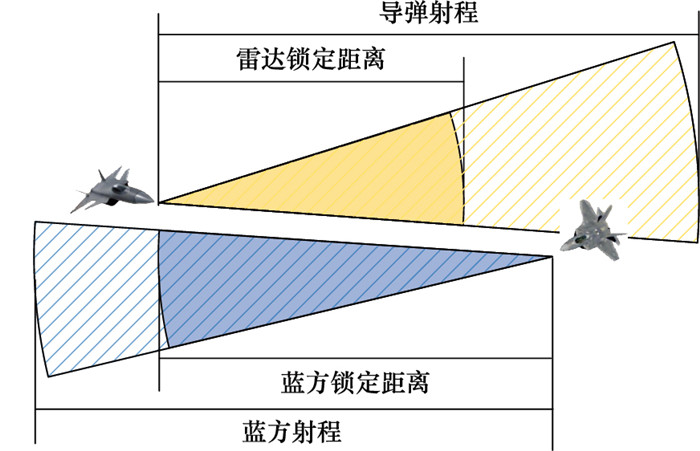
图2
有人/无人机协同空战决策流程"
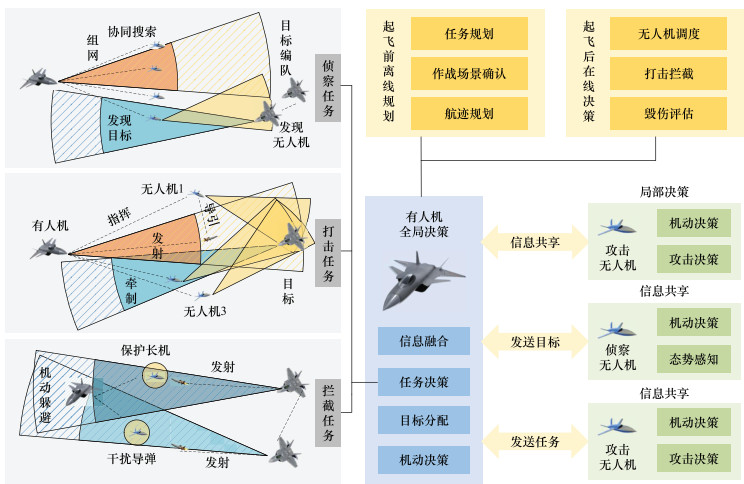
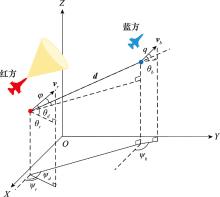
图3
两机相对态势"
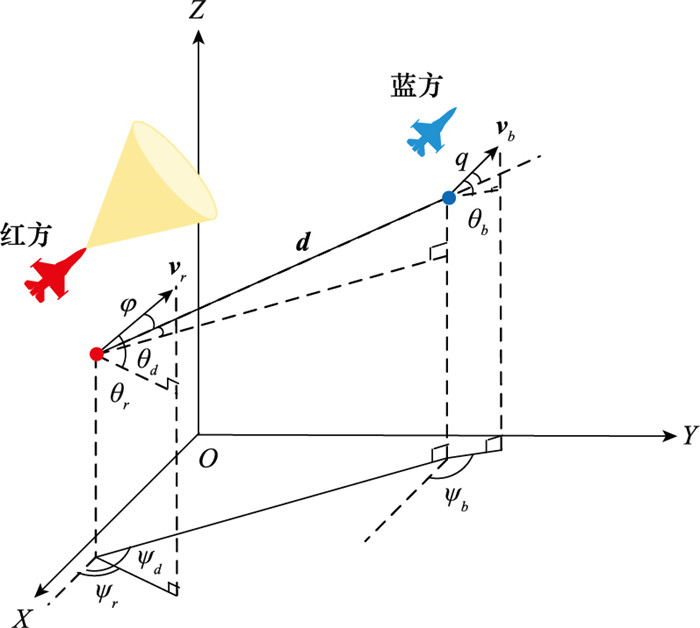
图4
TD3算法框架"
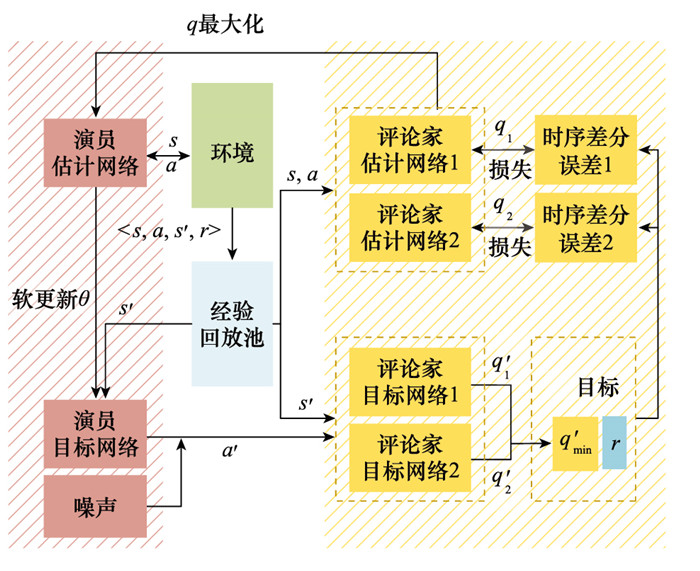
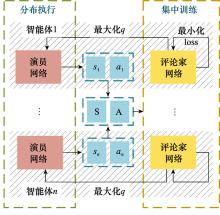
图5
MATD3算法架构"
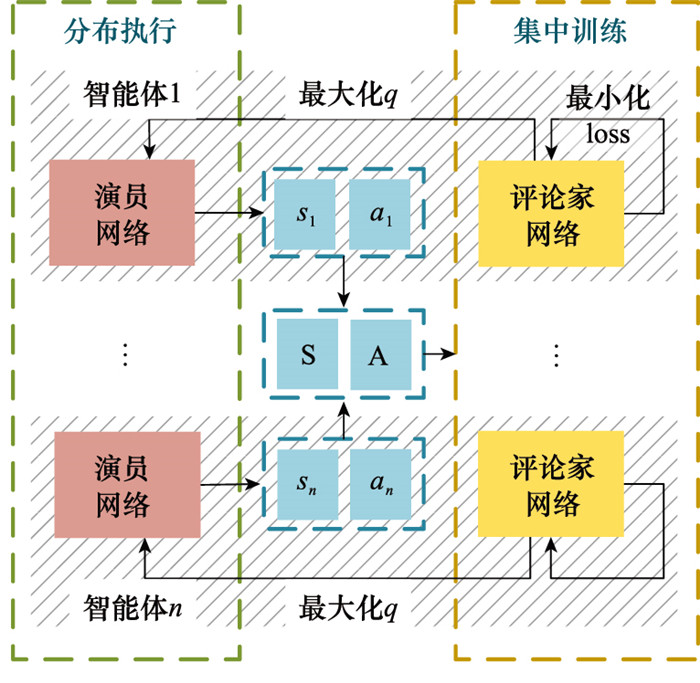
图6
改进MATD3训练流程"
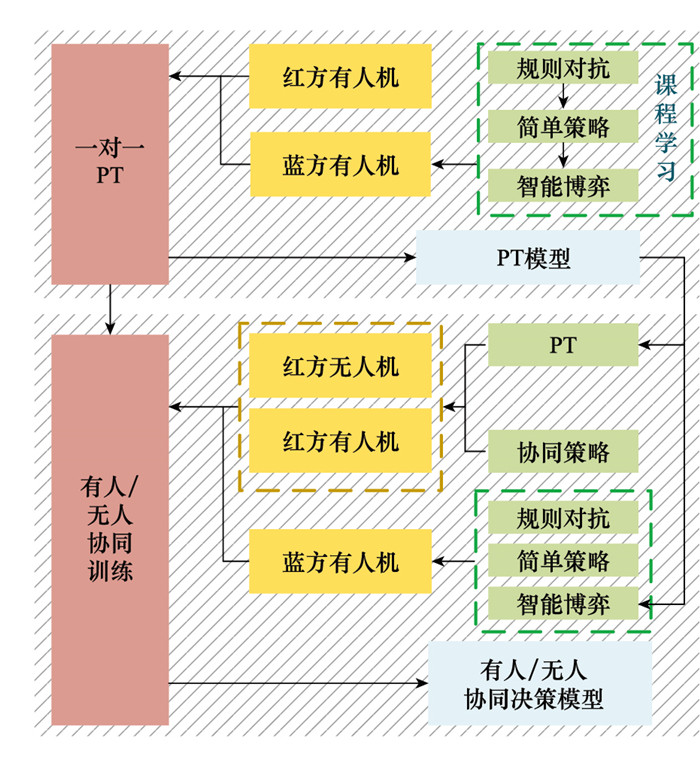
表1
状态空间"
| 状态 | 定义 | 状态 | 定义 | |
| s1 | xr0/xmax | s2 | xr1/xmax | |
| s3 | xr2/xmax | s4 | yr0/ymax | |
| s5 | yr1/ymax | s6 | yr2/ymax | |
| s7 | hr0/hmax | s8 | hr1/hmax | |
| s9 | hr2/hmax | s10 | xb/xmax | |
| s11 | yb/ymax | s12 | hb/hmax | |
| s13 | |dr0b|/dmax | s14 | |dr1b|/dmax | |
| s15 | |dr2b|/dmax | s16 | |dr0r1|/dmax | |
| s17 | |dr0r2|/dmax | s18 | θd0/π | |
| s19 | θd1/π | s20 | θd2/π | |
| s21 | θd01/π | s22 | θd02/π | |
| s23 | d0/π | s24 | d1/π | |
| s25 | d2/π | s26 | d01/π | |
| s27 | d02/π | s28 | |vr0|/vmax | |
| s29 | |vr1|/vmax | s30 | |vr2|/vmax | |
| s31 | |vb|/vmax | s32 | θr0/π | |
| s33 | θr1/π | s34 | θr2/π | |
| s35 | θb/π | s36 | r0/π | |
| s37 | r1/π | s38 | r2/π | |
| s39 | b/π | s40 | nxr0/nxmax | |
| s41 | nxr1/nxmax | s42 | nxr2/nxmax | |
| s43 | nyr0/nymax | s44 | nyr1/nymax | |
| s45 | nyr2/nymax | s46 | γr0/π | |
| s47 | γr1/π | s48 | γr2/π | |
| s49 | o1 | s50 | o2 |
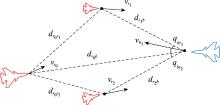
图7
红蓝双方相对位置关系"
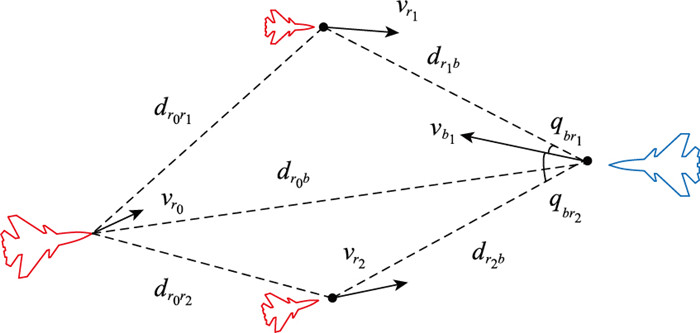
表2
红方有人机参数"
| 参数 | 范围 | 参数 | 范围 | |
| nx | [-1, 5] | θ | [-π/3, π/3] | |
| ny | [-1.5, 2] | φM | π/6 | |
| nz | [-3, 3] | dM/km | [1, 100] | |
| v/(m/s) | [150, 400] | dR/km | [0, 50] |
表3
蓝方有人机参数"
| 参数 | 范围 | 参数 | 范围 | |
| nx | [-1, 5] | θ | [-π/3, π/3] | |
| ny | [-1.5, 2] | φM | π/6 | |
| nz | [-3, 3] | dM/km | [1, 100] | |
| v/(m/s) | [150, 400] | dR/km | [0, 60] |
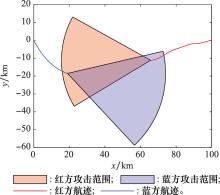
图8
蓝方盘旋机动策略下双方航迹"
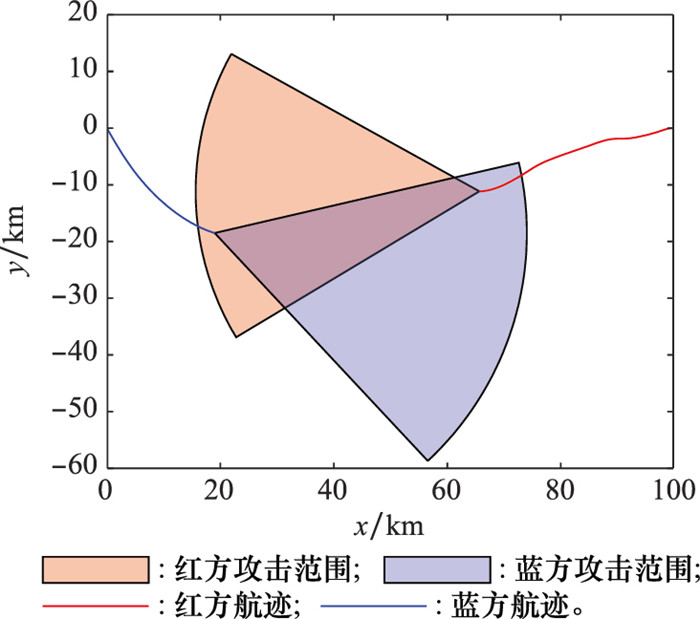
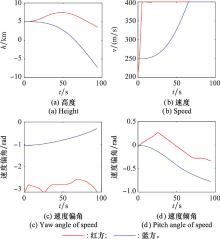
图9
蓝方盘旋机动策略下双方状态"
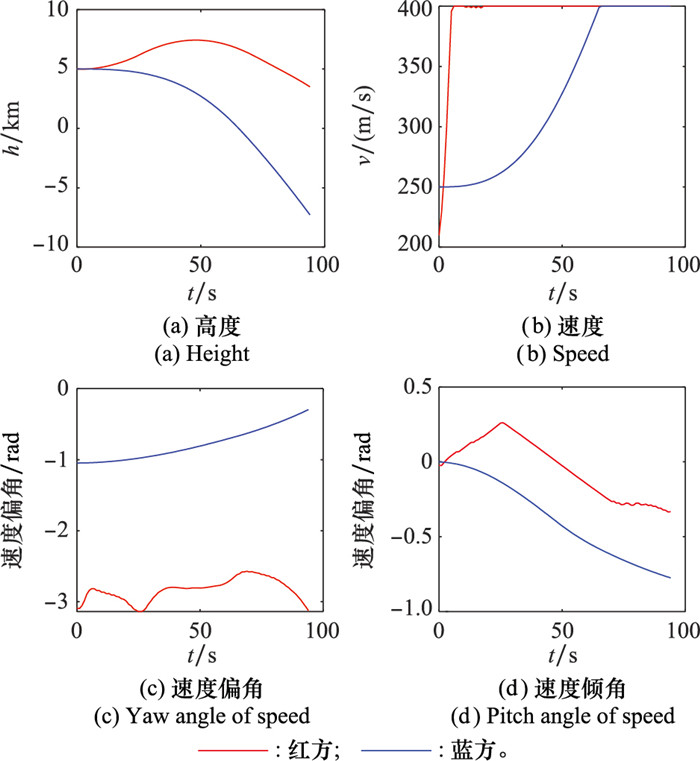
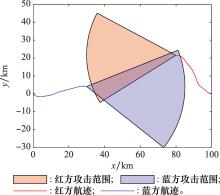
图10
两机自博弈对抗航迹"
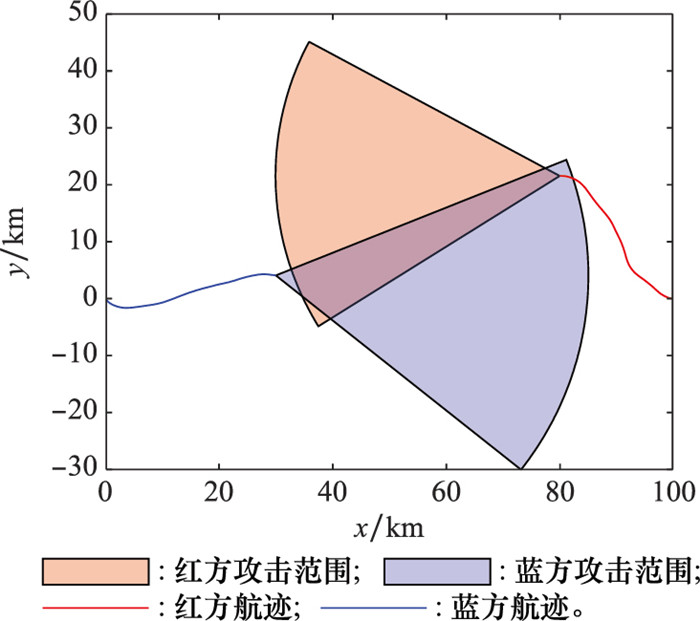
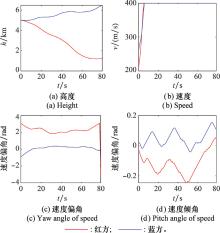
图11
两机自博弈对抗状态"
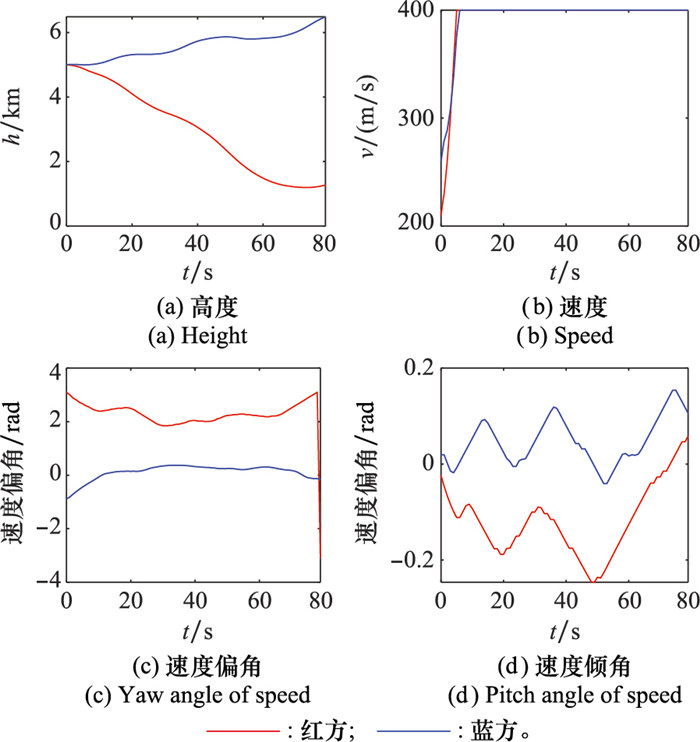
图12
自博弈训练时双方胜率"
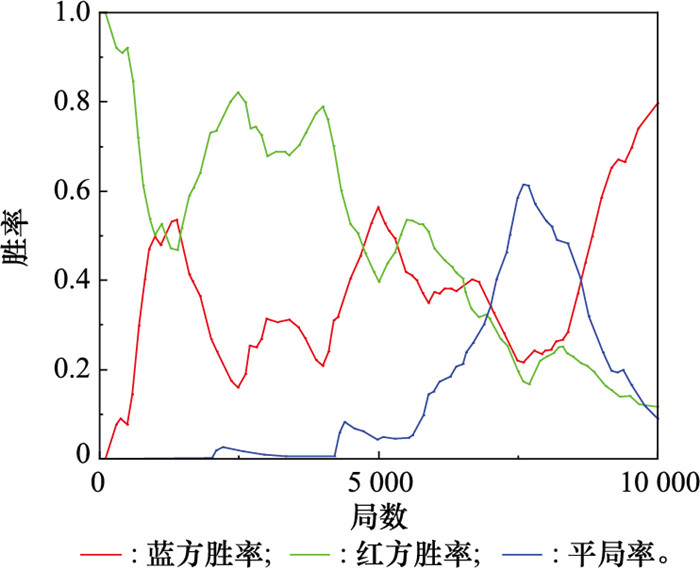
表4
无人机参数"
| 参数 | 范围 | 参数 | 范围 | |
| nx | [-1, 5] | θ | [-π/3, π/3] | |
| ny | [-1.5, 0.5] | φM | π/3 | |
| nz | [-3, 3] | dM/km | [1, 10] | |
| v/(m/s) | [150, 300] | dR/km | [0, 20] |
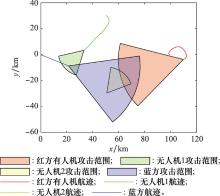
图13
蓝方平飞运动策略下双方航迹"
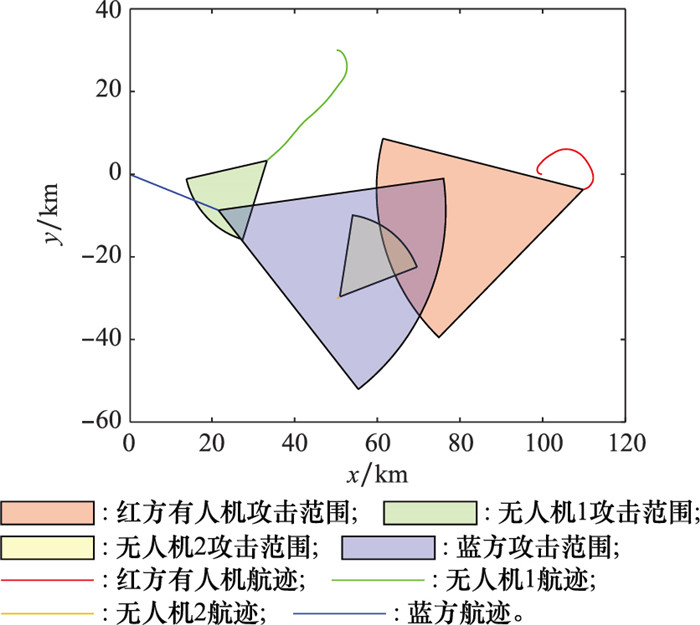
图14
蓝方平飞策略下红方单步平均奖励"
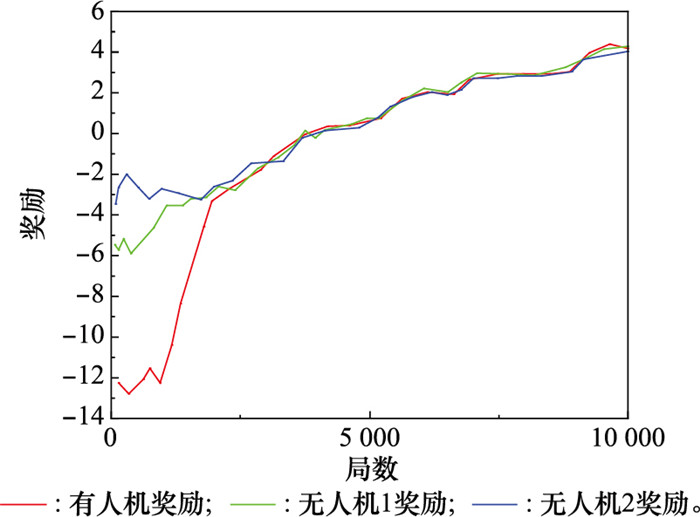
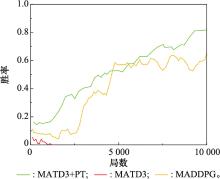
图15
蓝方平飞策略下红方胜率"
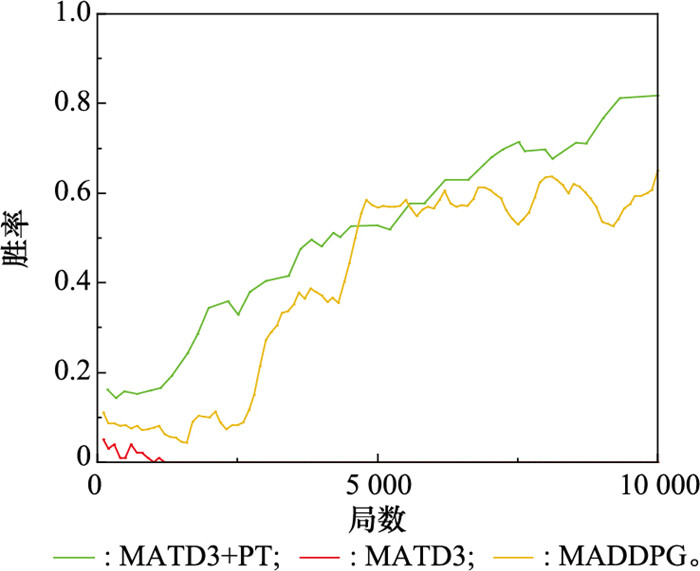
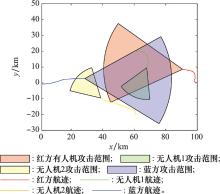
图16
蓝方采用策略1时双方的航迹"
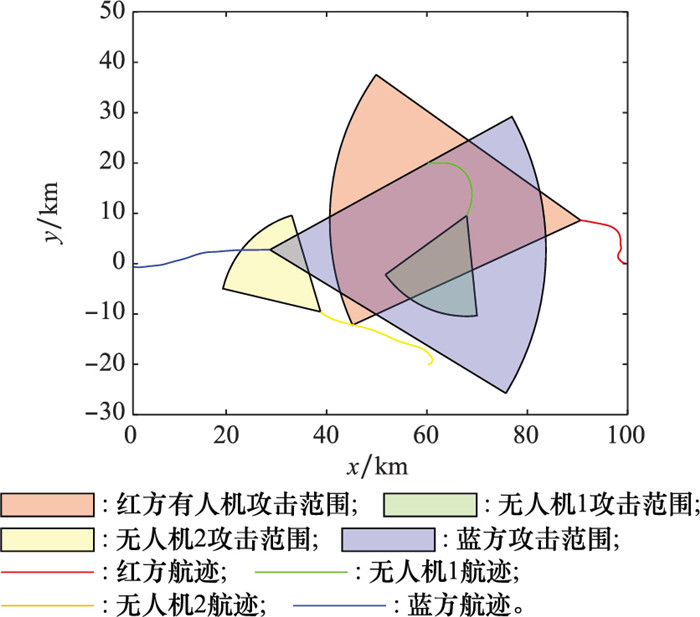
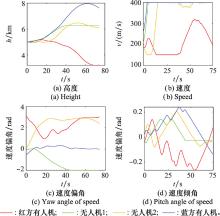
图17
蓝方采用策略1下双方状态"
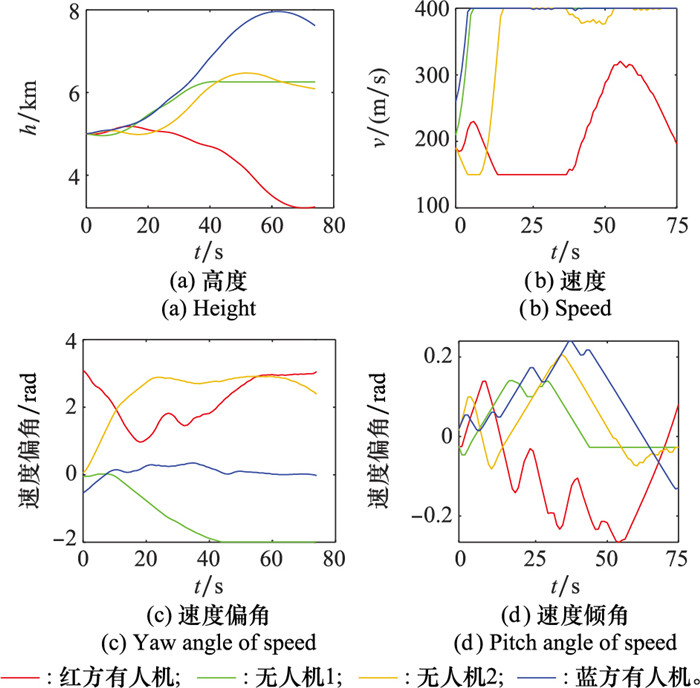
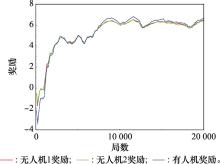
图18
蓝方策略1下红方单步平均奖励"
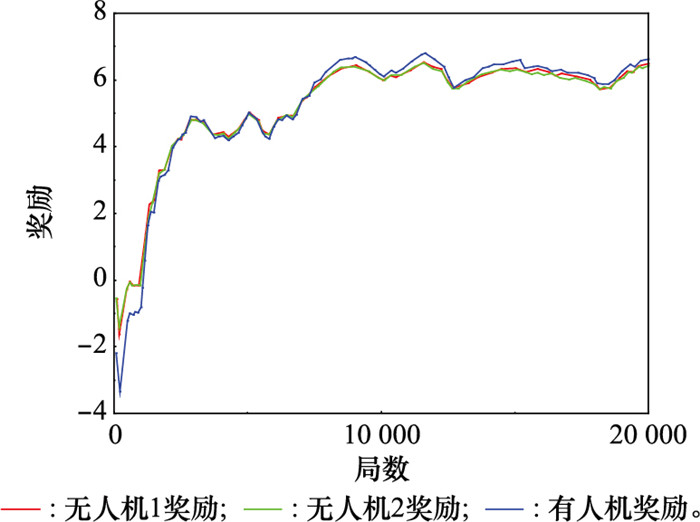
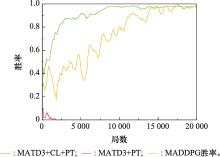
图19
蓝方策略1下红方胜率"
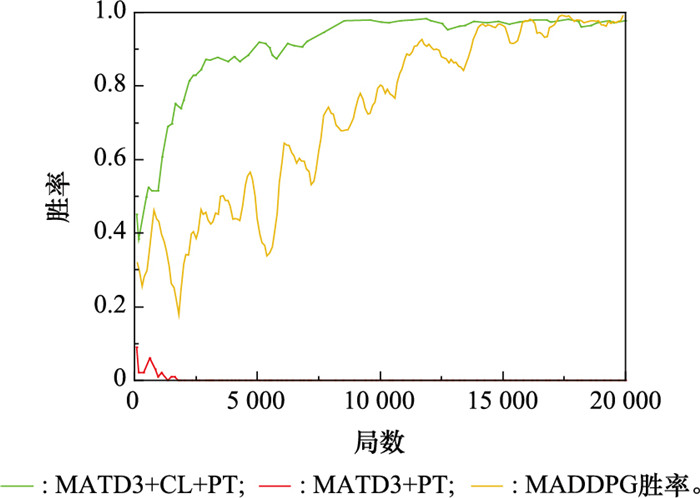
图20
蓝方采用策略2时双方的航迹"
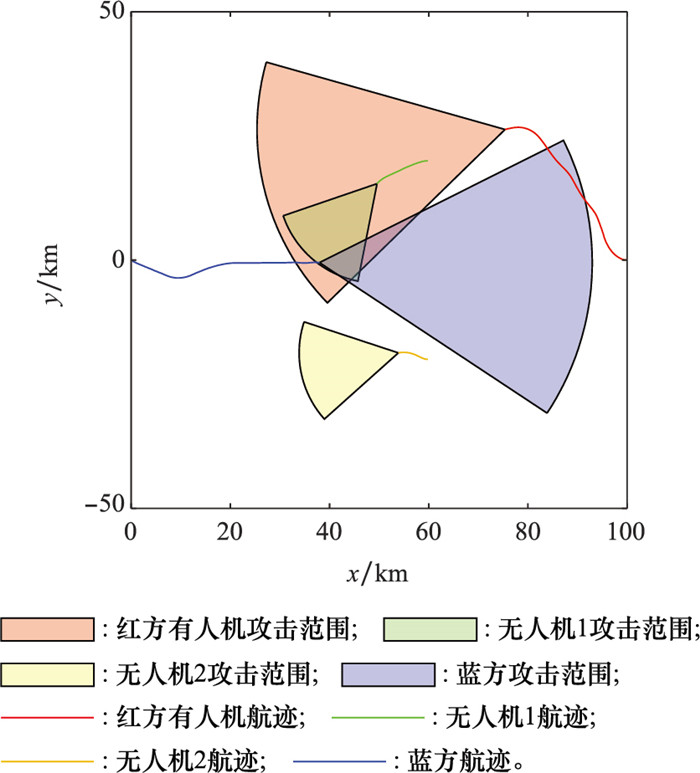
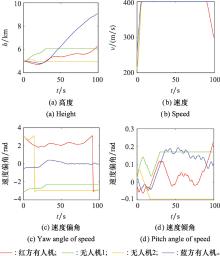
图21
蓝方采用策略2时双方的状态"
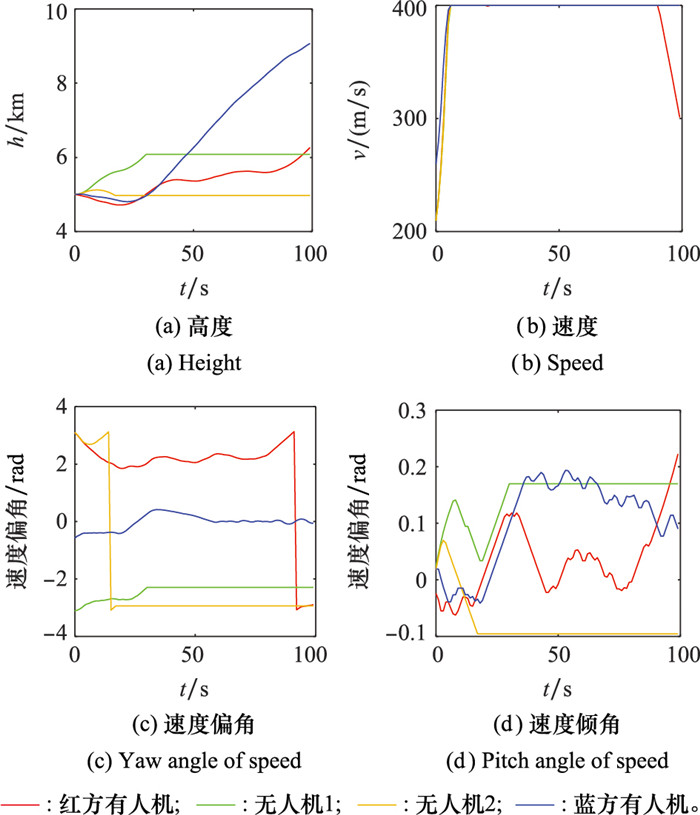

图22
高精度空战对抗推演平台架构"
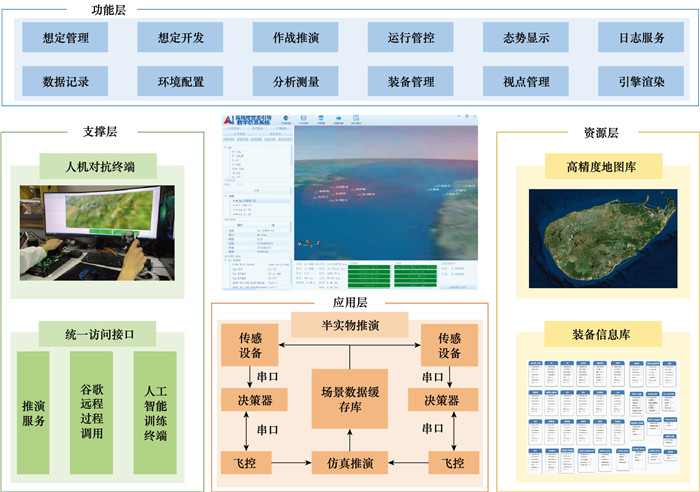
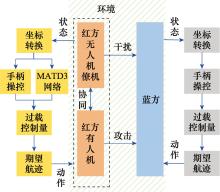
图23
人在回路仿真测试流程"
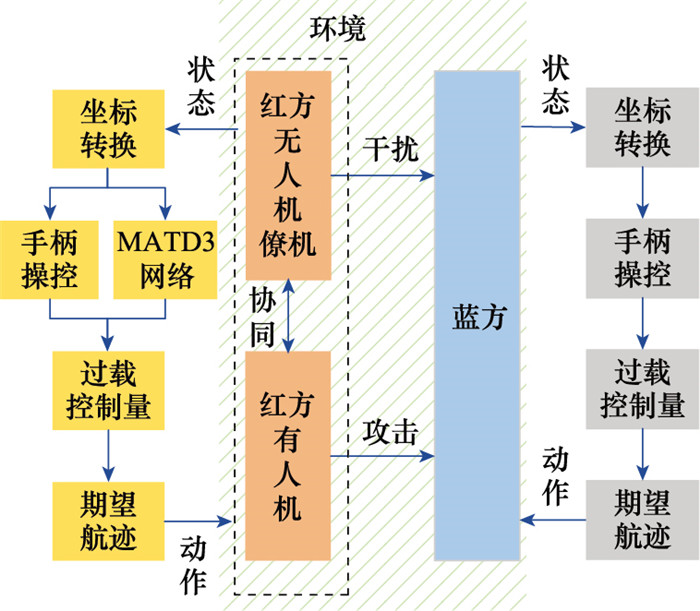

图24
软件仿真过程主界面"
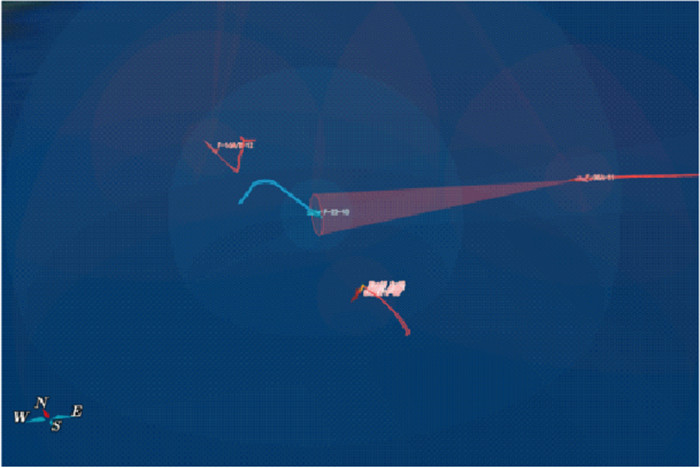
图25
双方飞行器状态"
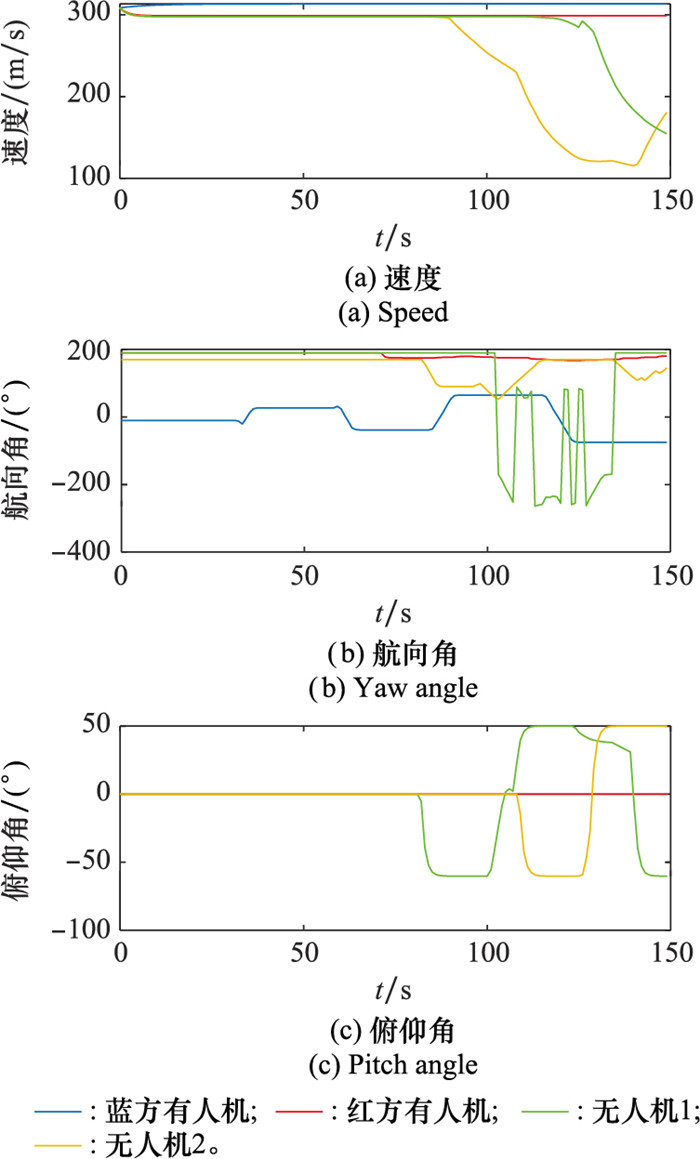
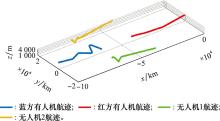
图26
软件仿真航迹"
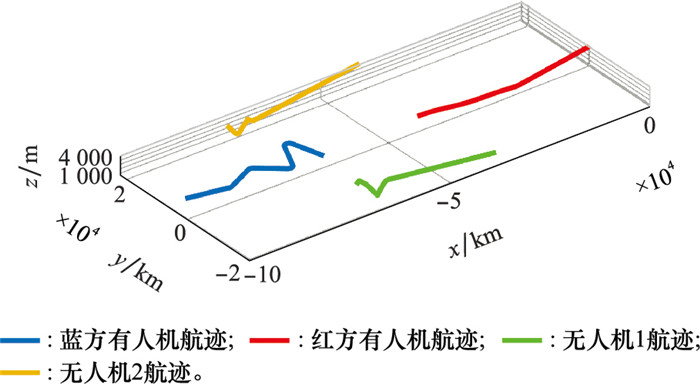
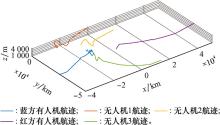
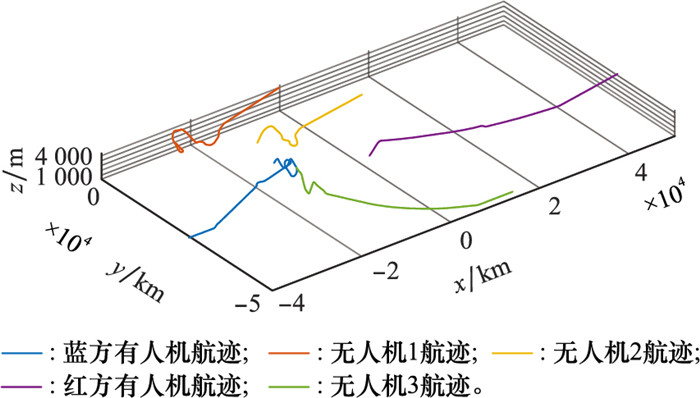
图27
3架无人机条件下软件仿真航迹"
| 1 | 丁达理, 谢磊, 王渊. 有人机/无人机协同作战运用及对战争形态影响[J]. 无人系统技术, 2020, 3 (4): 1- 9. |
| DING D L , XIE L , WANG Y . The application of manned/unmanned aerial vehicle cooperative combat and its influence on war form[J]. Unmanned Systems Technology, 2020, 3 (4): 1- 9. | |
| 2 | United States Department of Defense. Unmanned systems integrated roadmap FY2013-2038[R]. Washington, DC: United States Department of Defense, 2013. |
| 3 | 贾高伟, 侯中喜. 美军有/无人机协同作战研究现状与分析[J]. 国防科技, 2017, 38 (6): 57- 59. |
| JIA G W , HOU Z X . The analysis and current situation about the United States military manned/unmanned aerial vehicle[J]. National Defense Science and Technology, 2017, 38 (6): 57- 59. | |
| 4 |
王新尧, 曹云峰, 孙厚俊, 等. 基于DoDAF的有人/无人机协同作战体系结构建模[J]. 系统工程与电子技术, 2020, 42 (10): 2265- 2274.
doi: 10.3969/j.issn.1001-506X.2020.10.15 |
|
WANG X Y , CAO Y F , SUN H J , et al. Modeling for cooperative combat system architecture of manned/unmanned aerial vehicle based on DoDAF[J]. Systems Engineering and Electronics, 2020, 42 (10): 2265- 2274.
doi: 10.3969/j.issn.1001-506X.2020.10.15 |
|
| 5 | 张路, 邓静, 邵正途. 俄军有人机与无人机协同作战分析及启示[J]. 舰船电子对抗, 2022, 45 (3): 1- 6. |
| ZHANG L , DENG J , SHAO Z T . Analysis and enlightenment of manned and unmanned aerial vehicles cooperative operation for Russian army[J]. Shipboard Electronic Countermeasure, 2022, 45 (3): 1- 6. | |
| 6 | 李樾, 韩维, 陈清阳, 等. 凸优化算法在有人/无人机协同系统航迹规划中的应用[J]. 宇航学报, 2020, 41 (3): 276- 286. |
| LI Y , HAN W , CHEN Q Y , et al. Application of convex optimization algorithm in trajectory planning of manned/unmanned cooperative system[J]. Journal of Astronautics, 2020, 41 (3): 276- 286. | |
| 7 |
XING D J , ZHEN Z Y , GONG H J . Offense-defense confrontation decision making for dynamic UAV swarm versus UAV swarm[J]. Proceedings of the Institution of Mechanical Engineers, 2019, 233 (15): 5689- 5702.
doi: 10.1177/0954410019853982 |
| 8 |
BAPNAR B , KOYUNCU E . Assessment of aerial combat game via optimization-based receding horizon control[J]. IEEE Access, 2020, 8, 35853- 35863.
doi: 10.1109/ACCESS.2020.2974792 |
| 9 | 胡利平, 梁晓龙, 何吕龙, 等. 基于情景分析的航空集群决策规则库构建方法[J]. 航空学报, 2020, 41 (S1): 723737. |
| HU L P , LIANG X L , HE L L , et al. Construction method of aviation swarm decision rule base based on scenario analysis[J]. Acta Aeronautica et Astronautica Sinica, 2020, 41 (S1): 723737. | |
| 10 | YANG Q M, ZHU Y, ZHANG J D, et al. UAV air combat autonomous maneuver decision based on DDPG algorithm[C]//Proc. of the IEEE 15th International Conference on Control and Automation, 2019: 37-42. |
| 11 |
MA Y Y , WANG G Q , HU X X , et al. Cooperative occupancy decision making of multi-UAV in beyond-visual-range air combat: a game theory approach[J]. IEEE Access, 2020, 8, 11624- 11634.
doi: 10.1109/ACCESS.2019.2933022 |
| 12 |
XU J W , DENG Z H , SONG Q , et al. Multi-UAV counter-game model based on uncertain information[J]. Applied Mathe-matic and Computation, 2020, 366, 124684.
doi: 10.1016/j.amc.2019.124684 |
| 13 |
YANG Q M , ZHANG J D , SHI G Q , et al. Maneuver decision of UAV in short-range air combat based on deep reinforcement learning[J]. IEEE Access, 2020, 8, 363- 378.
doi: 10.1109/ACCESS.2019.2961426 |
| 14 | TANG R Z, ZHOU Z M, ZHANG C L, et al. The applications of artificial intelligence in situation assessment and game countermeasure during unmanned air combat[C]//Proc. of the IEEE International Conference on Unmanned Systems, 2019: 909-913. |
| 15 | KANESHIGE J, KRISHNAKUMAR K. Artificial immune system approach for air combat maneuvering[C]//Proc. of the Intelligent Computing: Theory and Applications, 2008: 68-79. |
| 16 | ASLAN S , ERKIN T . A multi-population immune plasma al gorithm for path planning of unmanned combat aerial vehicle[J]. Advanced Engineering Informatics, 2023, 55 (C): 101829. |
| 17 |
LI S Y , CHEN M , WANG Y H , et al. Air combat decision- making of multiple UCAVs based on constraint strategy games[J]. Defence Technology, 2022, 18 (3): 368- 383.
doi: 10.1016/j.dt.2021.01.005 |
| 18 |
RUAN W Y , DUAN H B , DENG Y M . Autonomous maneuver decisions via transfer learning pigeon-inspired optimization for UCAVs in dogfight engagements[J]. IEEE-CAA Journal of Automatica Sinica, 2022, 9 (9): 1639- 1657.
doi: 10.1109/JAS.2022.105803 |
| 19 |
LI S Y , CHEN M , WANG Y H , et al. A fast algorithm to solve large-scale matrix games based on dimensionality reduction and its application in multiple unmanned combat air vehicles attack-defense decision-making[J]. Information Sciences, 2022, 594, 305- 321.
doi: 10.1016/j.ins.2022.02.025 |
| 20 | GENG W X, KONG F E, MA D Q. Study on tactical decision of UAV medium range air combat[C]//Proc. of the 26th Chinese Control and Decision Conference, 2014: 135-139. |
| 21 | HE X M, ZU W, CHANG H X, et al. Autonomous maneuvering decision research of UAV based on experience knowledge representation[C]//Proc. of the 28th Chinese Control and Decision Conference, 2016: 161-166. |
| 22 |
KAUFMANN E , BAUERSFELD L , LOQUERCIO A , et al. Champion-level drone racing using deep reinforcement learning[J]. Nature, 2023, 620 (7976): 982- 987.
doi: 10.1038/s41586-023-06419-4 |
| 23 |
AKROUR R , TATEO D , PETERS J . Continuous action reinforcement learning from a mixture of interpretable experts[J]. IEEE Trans.on Pattern Analysis and Machine Intelligence, 2022, 44 (10): 6795- 6806.
doi: 10.1109/TPAMI.2021.3103132 |
| 24 |
LI B , HUANG J Y , BAI S X , et al. Autonomous air combat decision-making of UAV based on parallel self-play reinforcement learning[J]. CAAI Trans.on Intelligence Technology, 2023, 8 (1): 64- 81.
doi: 10.1049/cit2.12109 |
| 25 | LI Y F , SHI J P , JIANG W , et al. Autonomous maneuver decision-making for a UCAV in short-range aerial combat based on an MS-DDQN algorithm[J]. Defence Technology, 2022, 8 (9): 1697- 1714. |
| 26 | TIAN Z K, CHEN R Z, LI L, et al. Decompose a task into generalizable subtasks in multi-agent reinforcement learning [C]//Proc. of the Advances in Neural Information Processing Systems, 2024: 78514-78532. |
| 27 |
ZHAN G , ZHANG X M , LI Z C , et al. Multiple-UAV reinforcement learning algorithm based on improved PPO in ray framework[J]. Drones, 2022, 6 (7): 166.
doi: 10.3390/drones6070166 |
| 28 |
谭目来, 丁达理, 谢磊, 等. 基于模糊专家系统与IDE算法的UCAV逃逸机动决策[J]. 系统工程与电子技术, 2022, 44 (6): 1984- 1993.
doi: 10.12305/j.issn.1001-506X.2022.06.26 |
|
TAN M L , DING D L , XIE L , et al. UCAV escape maneuvering decision based on fuzzy expert system and IDE algorithm[J]. Systems Engineering and Electronics, 2022, 44 (6): 1984- 1993.
doi: 10.12305/j.issn.1001-506X.2022.06.26 |
|
| 29 | FUJIMOTO S, HOOF H V, MEGER D. Addressing function approximation error in actor-critic methods[C]//Proc. of the 35th International Conference on Machine Learning, 2018: 1587-1596. |
| 30 |
CHEN P C , LIU S C , WANG X Z , et al. Physics-shielded multi-agent deep reinforcement learning for safe active voltage control with photovoltaic/battery energy storage systems[J]. IEEE Trans.on Smart Grid, 2023, 14 (4): 2656- 2667.
doi: 10.1109/TSG.2022.3228636 |
| 31 |
ZHAO T T , LI F , HE L J , et al. DRL-based secure aggregation and resource orchestration in MEC-enabled hierarchical federated learning[J]. IEEE Internet of Things Journal, 2023, 10 (20): 17865- 17880.
doi: 10.1109/JIOT.2023.3277553 |
| 32 | 杨书恒, 张栋, 熊威, 等. 基于可解释性强化学习的空战机动决策方法[J]. 航空学报, 2024, 45 (18): 252- 269. |
| YANG S H , ZHANG D , XIONG W , et al. A decision-making method for air combat maneuver based on explainable reinforcement learning[J]. Acta Aeronautica et Astronautica Sinica, 2024, 45 (18): 252- 269. | |
| 33 | AUSTIN F , CARBONE G , FALCO M , et al. Game theory for automated maneuvering during air-to-air combat[J]. Journal of Guidance Control and Dynamics, 1990, 13 (6): 1143- 1149. |
| [1] | 马鹏, 蒋睿, 王斌, 徐盟飞, 侯长波. 基于隐式对手建模的策略重构抗智能干扰方法[J]. 系统工程与电子技术, 2025, 47(4): 1355-1363. |
| [2] | 唐开强, 傅汇乔, 刘佳生, 邓归洲, 陈春林. 基于深度强化学习的带约束车辆路径分层优化研究[J]. 系统工程与电子技术, 2025, 47(3): 827-841. |
| [3] | 陈夏瑢, 李际超, 陈刚, 刘鹏, 姜江. 基于异质网络的装备体系组合发展规划问题[J]. 系统工程与电子技术, 2025, 47(3): 855-861. |
| [4] | 张庭瑜, 曾颖, 李楠, 黄洪钟. 基于深度强化学习的航天器功率-信号复合网络优化算法[J]. 系统工程与电子技术, 2024, 46(9): 3060-3069. |
| [5] | 夏雨奇, 黄炎焱, 陈恰. 基于深度Q网络的无人车侦察路径规划[J]. 系统工程与电子技术, 2024, 46(9): 3070-3081. |
| [6] | 杨志鹏, 陈子浩, 曾长, 林松, 毛金娣, 张凯. 复杂环境下的飞行器在线航路规划决策方法[J]. 系统工程与电子技术, 2024, 46(9): 3166-3175. |
| [7] | 郭宏达, 娄静涛, 徐友春, 叶鹏, 李永乐, 陈晋生. 基于MADDPG的多无人车协同事件触发通信[J]. 系统工程与电子技术, 2024, 46(7): 2525-2533. |
| [8] | 张梦钰, 豆亚杰, 陈子夷, 姜江, 杨克巍, 葛冰峰. 深度强化学习及其在军事领域中的应用综述[J]. 系统工程与电子技术, 2024, 46(4): 1297-1308. |
| [9] | 李彦铃, 罗飞舟, 葛致磊. 基于鲁棒观测器的深度强化学习垂直起降运载器姿态稳定研究[J]. 系统工程与电子技术, 2024, 46(3): 1038-1047. |
| [10] | 吴冯国, 陶伟, 李辉, 张建伟, 郑成辰. 基于深度强化学习算法的无人机智能规避决策[J]. 系统工程与电子技术, 2023, 45(6): 1702-1711. |
| [11] | 唐进, 梁彦刚, 白志会, 黎克波. 基于DQN的旋翼无人机着陆控制算法[J]. 系统工程与电子技术, 2023, 45(5): 1451-1460. |
| [12] | 唐斯琪, 潘志松, 胡谷雨, 吴炀, 李云波. 深度强化学习在天基信息网络中的应用——现状与前景[J]. 系统工程与电子技术, 2023, 45(3): 886-901. |
| [13] | 李信, 李勇军, 赵尚弘. 基于深度强化学习的卫星光网络波长路由算法[J]. 系统工程与电子技术, 2023, 45(1): 264-270. |
| [14] | 王冠, 茹海忠, 张大力, 马广程, 夏红伟. 弹性高超声速飞行器智能控制系统设计[J]. 系统工程与电子技术, 2022, 44(7): 2276-2285. |
| [15] | 孟泠宇, 郭秉礼, 杨雯, 张欣伟, 赵柞青, 黄善国. 基于深度强化学习的网络路由优化方法[J]. 系统工程与电子技术, 2022, 44(7): 2311-2318. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||