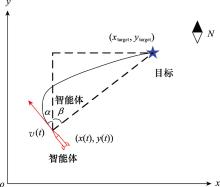
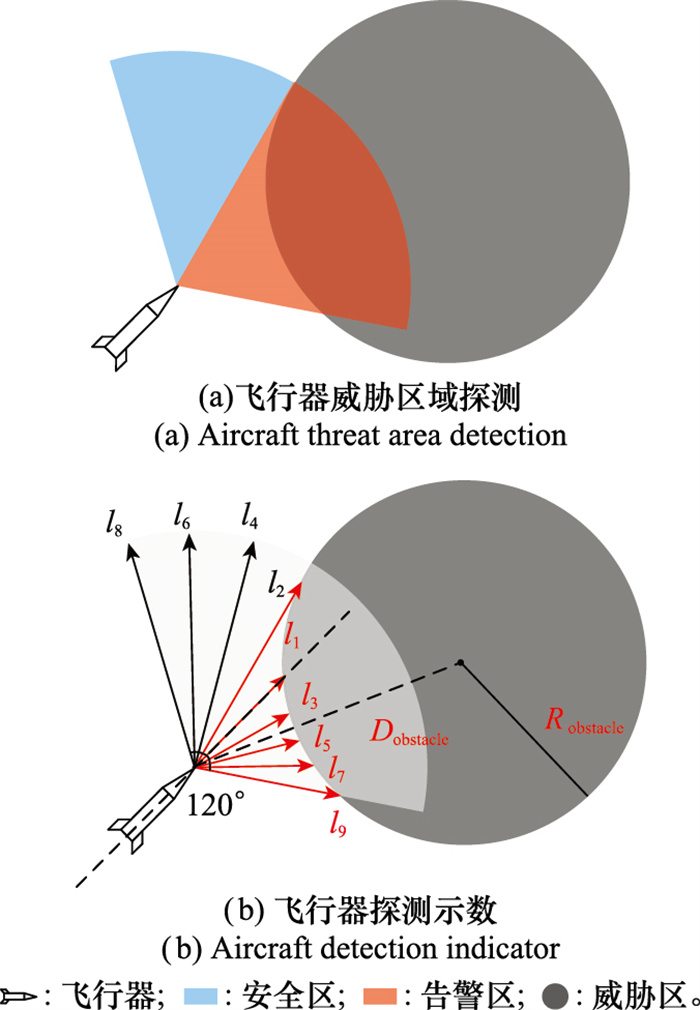
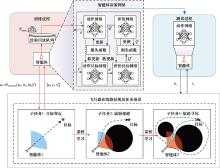
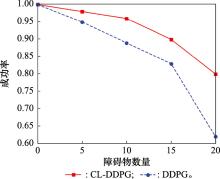
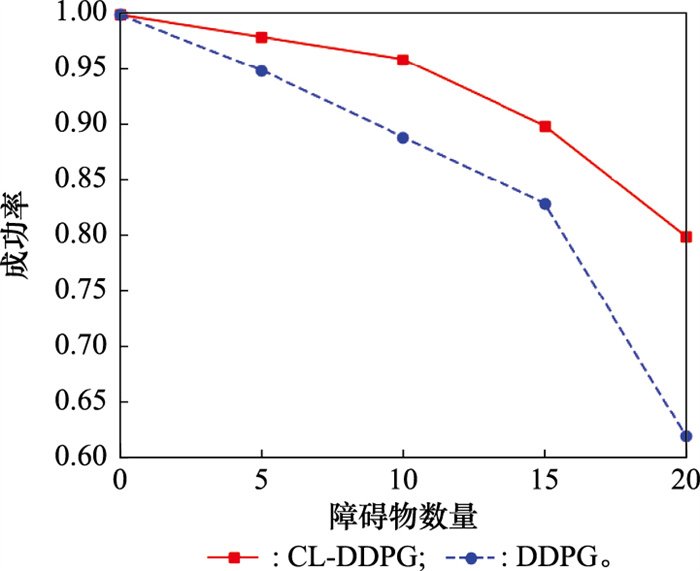
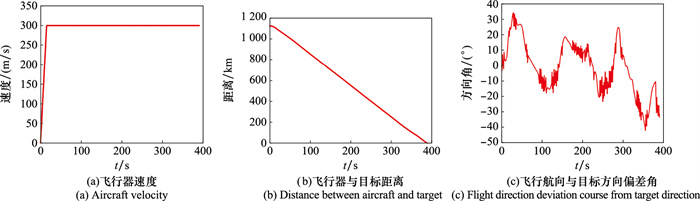
| 1 |
GUIX H,ZHANGJ F,PENGZ H.Trajectory clustering for arrival aircraft via new trajectory representation[J].Journal of Systems Engineering and Electronics,2021,32(2):473-486.
doi: 10.23919/JSEE.2021.000040
|
| 2 |
NIKLASG,TOBIASB,DIRKN.Deep reinforcement learning with combinatorial actions spaces: an application to prescriptive maintenance[J].Computers & Industrial Engineering,2023,179(1):109165.
|
| 3 |
WANGX Y,YANGY P,WANGD,et al.Mission-oriented cooperative 3D path planning for modular solar-powered aircraft with energy optimization[J].Chinese Journal of Aeronautics,2022,35(1):98-109.
doi: 10.1016/j.cja.2021.04.015
|
| 4 |
LIB,YANGZ P,CHEND Q,et al.Maneuvering target tracking of UAV based on MN-DDPG and transfer learning[J].Defence Technology,2021,17(2):457-466.
doi: 10.1016/j.dt.2020.11.014
|
| 5 |
LIUC S,ZHANGS J.Novel robust control framework for morphing aircraft[J].Journal of Systems Engineering and Electronics,2013,24(2):281-287.
doi: 10.1109/JSEE.2013.00035
|
| 6 |
OBAJEMUO,MAHFOUFM,MAIYARL M,et al.Real-time four-dimensional trajectory generation based on gain-sche-duling control and a high-fidelity aircraft model[J].Engineering,2021,7(4):495-506.
doi: 10.1016/j.eng.2021.01.009
|
| 7 |
赵岩,吴建峰,高育鹏.基于多智能体导航的高超飞行器信息融合方法[J].系统工程与电子技术,2020,42(2):405-413.
doi: 10.3969/j.issn.1001-506X.2020.02.20
|
|
ZHAOY,WUJ F,GAOY P.Information fusion method of hypersonic vehicle based on multi-agent navigation[J].Systems Engineering and Electronics,2020,42(2):405-413.
doi: 10.3969/j.issn.1001-506X.2020.02.20
|
| 8 |
陈宗基,张汝麟,张平,等.飞行器控制面临的机遇与挑战[J].自动化学报,2013,39(6):703-710.
|
|
CHENZ J,ZHANGR L,ZHANGP,et al.Flight control: challenges and opportunities[J].Acta Automatica Sinica,2013,39(6):703-710.
|
| 9 |
DUCHONF,BABINECA,KAJANM,et al.Path planning with modified a star algorithm for a mobile robot[J].Procedia Engineering,2014,96(1):59-69.
|
| 10 |
LIUJ H,YANGJ,LIUH P,et al.An improved ant colony algorithm for robot path planning[J].Soft Computing,2017,21(1):5829-5839.
|
| 11 |
LI X Q, QIU L, AZIZ S, et al. Control method of UAV based on RRT * for target tracking in cluttered environment[C]//Proc. of the 7th International Conference on Power Electronics Systems and Applications-Smart Mobility, Power Transfer & Security, 2017.
|
| 12 |
杨杰. 具有端点方向约束的快速航迹规划方法研究[D]. 武汉: 华中科技大学, 2013.
|
|
YANG J. Research on fast route planning method adapted to directional endpoint constraints[D]. Wuhan: Huazhong University of Science and Technology, 2013.
|
| 13 |
高科,宋佳,艾绍洁,等.高超声速飞行器再入段LQR自抗扰控制方法设计[J].宇航学报,2020,41(11):1418-1423.
doi: 10.3873/j.issn.1000-1328.2020.11.007
|
|
GAOK,SONGJ,AIS J,et al.LQR active disturbance rejection control method design for hypersonic vehicles in reentry phase[J].Journal of Astronautics,2020,41(11):1418-1423.
doi: 10.3873/j.issn.1000-1328.2020.11.007
|
| 14 |
MNIHV,KAVUKCUOGLUK,SILVERD,et al.Human-level control through deep reinforcement learning[J].Nature,2015,518(7540):529-533.
doi: 10.1038/nature14236
|
| 15 |
LILLICRAP T P, HUNT J J, PRITZEL A, et al. Continuous control with deep reinforcement learning[EB/OL]. [2023-04-30]. http://www.arxiv.org/abs/1509.02971.
|
| 16 |
HUANGC Q,DONGK S,HUANGH Q,et al.Autonomous air combat maneuver decision using Bayesian inference and moving horizon optimization[J].Journal of Systems Engineering and Electronics,2018,29(1):86-97.
doi: 10.21629/JSEE.2018.01.09
|
| 17 |
WALKER O, VANEGAS F, GONZALEZ F, et al. A deep reinforcement learning framework for UAV navigation in indoor environments[C]//Proc. of the IEEE Aerospace Confe-rence, 2019.
|
| 18 |
LEVINES,FINNC,DARRELLT,et al.End-to-end training of deep visuomotor policies[J].The Journal of Machine Learning Research,2016,17(1):1334-1373.
|
| 19 |
张运涛. 面向无人机自主避障导航的深度强化学习算法研究[D]. 南京: 东南大学, 2021.
|
|
ZHANG Y T. Research on deep reinforcement learning for autonomous obstacle avoidance and navigation of UAV[D]. Nanjing: Southeast University, 2021.
|
| 20 |
WANK F,GAOX G,HUZ J,et al.Robust motion control for UAV in dynamic uncertain environments using deep reinforcement learning[J].Remote Sensing,2020,12(4):640-660.
doi: 10.3390/rs12040640
|
| 21 |
ZHANGC M,ZHUY W,YANGL P,et al.An optimal gui-dance method for free-time orbital pursuit-evasion game[J].Journal of Systems Engineering and Electronics,2022,33(6):1294-1308.
|
| 22 |
LIY F,SHIJ P,JIANGW,et al.Autonomous maneuver decision-making for a UCAV in short-range aerial combat based on an MS-DDQN algorithm[J].Defence Technology,2022,18(9):1697-1714.
doi: 10.1016/j.dt.2021.09.014
|
| 23 |
ZHANGH,JIAOZ X,SHANGY X,et al.Ground maneuver for front-wheel drive aircraft via deep reinforcement learning[J].Chinese Journal of Aeronautics,2021,34(10):166-176.
doi: 10.1016/j.cja.2021.03.029
|
| 24 |
LIUQ,SHIL,SUNL L,et al.Path planning for UAV-mounted mobile edge computing with deep reinforcement learning[J].IEEE Trans.on Vehicular Technology,2020,69(3):5723-5728.
|
| 25 |
LIY H,WANGH L,WUT C,et al.Attitude control for hypersonic reentry vehicles: an efficient deep reinforcement learning method[J].Applied Soft Computing,2023,123(1):108865.
|
| 26 |
RUMMERY G A, NIRANJAN M. On-line Q-learning using connectionist systems[D]. Cambridge: University of Cambridge, 1994.
|
| 27 |
王冠,茹海忠,张大力,等.弹性高超声速飞行器智能控制系统设计[J].系统工程与电子技术,2022,44(7):2276-2285.
doi: 10.12305/j.issn.1001-506X.2022.07.24
|
|
WANGG,RUH Z,ZHANGD L,et al.Design of intelligent control system for flexible hypersonic vehicle[J].Systems Engineering and Electronics,2022,44(7):2276-2285.
doi: 10.12305/j.issn.1001-506X.2022.07.24
|
| 28 |
YANG Q M, ZHU Y, ZHANG J D, et al. UAV air combat autonomous maneuver decision based on DDPG algorithm[C]//Proc. of the IEEE 15th International Conference on Control and Automation, 2019: 37-42.
|
| 29 |
NARVEKAR S, SINAPOV J, LEONETTI M, et al. Source task creation for curriculum learning[C]//Proc. of the ICAAMS 18th International Conference on Autonomous Agents & Multiagent Systems, 2016: 566-574.
|
| 30 |
DUW B,GUOT,CHENJ,et al.Cooperative pursuit of unauthorized UAVs in urban airspace via multi-agent reinforcement learning[J].Transportation Research Part C: Emerging Technologies,2021,128(1):103-122.
|