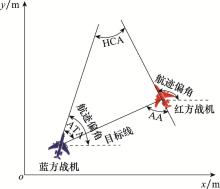
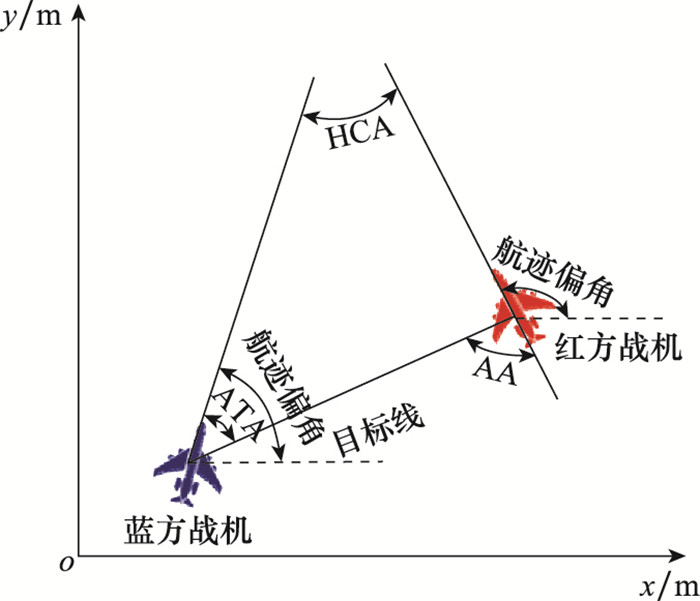
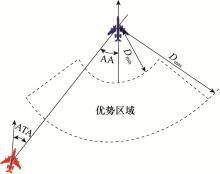
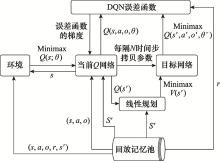
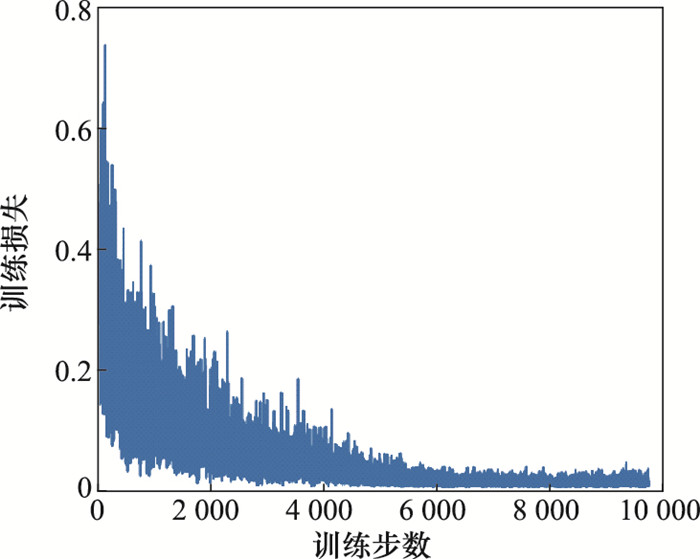
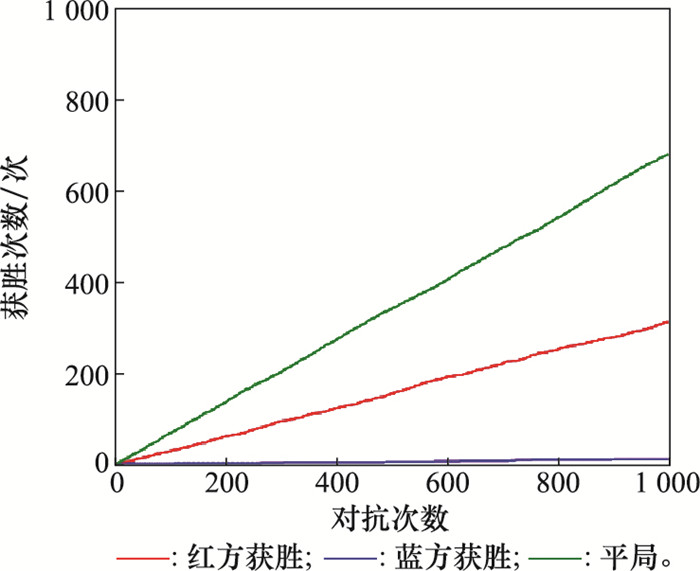
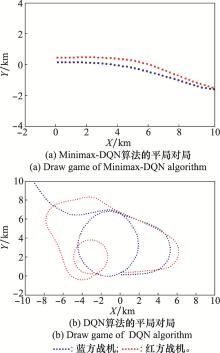
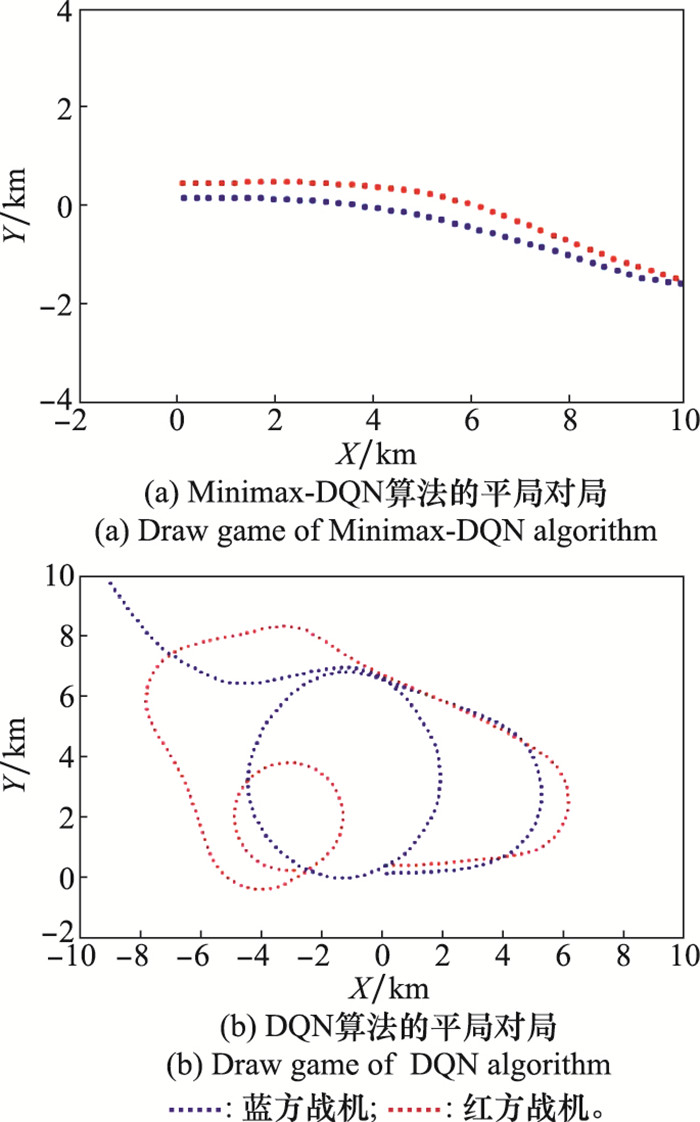
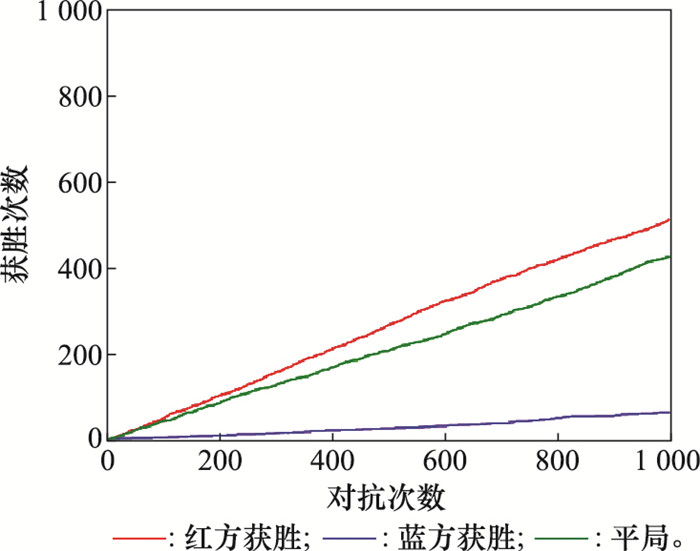
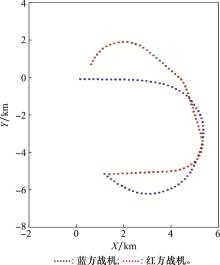
| 1 |
孔江涛.面向双机空战机动决策的置信规则推理技术研究[D].长沙:国防科学技术大学, 2015.
|
|
KONG J T. Research of belief-rule-based reasoning technology for learning air combat maneuvers[D]. Changsha: National University of Defense Technology, 2015.
|
| 2 |
HUANG C Q , DONG K S , HUANG H Q , et al. Autonomous air combat maneuver decision using Bayesian inference and moving horizon optimization[J]. Journal of Systems Engineering and Electronics, 2018, 29 (1): 90- 101.
|
| 3 |
VIRTANEN K , KARELAHTI J , RAIVIO T . Modeling air combat by a moving horizon influence diagram game[J]. Journal of Guidance Control & Dynamics, 2006, 29 (5): 1080- 1091.
|
| 4 |
CHAPPELL A R. Knowledge-based reasoning in the Paladin tactical decision generation system[C]//Proc.of the 11th Digital Avionics Systems Conference, 1992: 155-160.
|
| 5 |
HORIE K , CONWAY B A . Optimal fighter pursuit-evasion maneuvers found via two-sided optimization[J]. Journal of Guidance, Control, and Dynamics, 2006, 29 (1): 105- 112.
doi: 10.2514/1.3960
|
| 6 |
SU M C , LAI S C , LIN S C , et al. A new approach to multi-aircraft air combat assignments[J]. Swarm and Evolutionary Computation, 2012, 6, 39- 46.
doi: 10.1016/j.swevo.2012.03.003
|
| 7 |
董肖杰, 余敏建. 基于博弈论的自由空战指挥引导对策问题研究[J]. 航空计算技术, 2017, 47 (2): 80- 84, 88.
|
|
DONG X J , YU M J . Study on countermeasure of free air combat command and guide based on game theory[J]. Aeronautical Computing Technique, 2017, 47 (2): 80- 84, 88.
|
| 8 |
梅丹, 刘锦涛, 高丽. 基于近似动态规划与零和博弈的空战机动决策[J]. 兵工自动化, 2017, 36 (3): 35- 39.
|
|
MEI D , LIU J T , GAO L . Maneuver decision of air combat based on approximate dynamic programming and zero-sum game[J]. Ordnance Industry Automation, 2017, 36 (3): 35- 39.
|
| 9 |
罗元强, 孟光磊. 基于马尔可夫网络的无人机机动决策方法研究[J]. 系统仿真学报, 2017, 29 (S1): 110- 116.
|
|
LUO Y Q , MENG G L . Research on UAV maneuver decision-making method based on markov network[J]. Journal of System Simulation, 2017, 29 (S1): 110- 116.
|
| 10 |
王炫, 王维嘉, 宋科璞, 等. 基于进化式专家系统树的无人机空战决策技术[J]. 兵工自动化, 2019, 38 (1): 48- 53.
|
|
WANG X , WANG W J , SONG K P , et al. UAV air combat decision based on evolutionary expert system tree[J]. Ordnance Industry Automation, 2019, 38 (1): 48- 53.
|
| 11 |
邓可, 彭宣淇, 周德云. 基于矩阵对策与遗传算法的无人机空战决策[J]. 火力与指挥控制, 2019, 44 (12): 61- 66, 71.
|
|
DENG K , PENG X Q , ZHOU D Y . Study on air combat decision method of UAV based on matrix game and genetic algorithm[J]. Fire Control & Command Control, 2019, 44 (12): 61- 66, 71.
|
| 12 |
周光霞,周方.美军人工智能空战系统阿尔法初探[C]//第六届中国指挥控制大会, 2018: 66-70.
|
|
ZHOU G X, ZHOU F. A preliminary study of the alpha of the US army's Artificial intelligence air combat system[C]//Proc.of the 6th China Command and Control Conference, 2018: 66-70.
|
| 13 |
SILVER D , SCHRITTWIESER J , SIMONYAN K , et al. Mastering the game of Go without human knowledge[J]. Nature, 2017, 550 (7676): 354- 359.
|
| 14 |
VINCENT F L , PETER H , RIASHAT I , et al. An introduction to deep reinforcement learning[J]. Foundations and Trends in Machine Learning, 2018, 11 (3/4): 219- 354.
|
| 15 |
MA Y F , MA X L , SONG X . A case study on air combat decision using approximated dynamic programming[J]. Mathematical Problems in Engineering, 2014, (4): 183- 193.
|
| 16 |
LITTMAN M L. Markov games as a framework for multi-agent reinforcement learning[C]//Proc.of the 11th International Conference on Machine Learning, 1994: 157-163.
|
| 17 |
CORCHON L C , MARINI M A . Handbook of game theory and industrial organization, volume I, theory[M]. Miami: Edward Elgar, 2018.
|
| 18 |
PAVLIDIS N G , PARSOPOULOS K E , VRAHATIS M N . Computing Nash equilibria through computational intelligence methods[J]. Journal of Computational & Applied Mathematics, 2005, 175 (1): 113- 136.
|
| 19 |
BARDHAN R. An SDRE based differential game approach for maneuvering target interception[C]//Proc.of the AIAA Guidance, Navigation and Control Conference, 2015: 704-711.
|
| 20 |
OYLER D W , KABAMBA P T , GIRARDA R . Pursuit-evasion games in the presence of obstacles[J]. Automatica, 2016, 65 (c): 1- 11.
|
| 21 |
MCGREGOR S , BUCKINGHAM H , DIETTERICH T G , et al. Interactive visualization for testing Markov decision processes: MDPVIS[J]. Journal of Visual Languages & Computing, 2017, 39 (4): 93- 106.
|
| 22 |
张堃, 李珂, 时昊天, 等. 基于深度强化学习的UAV航路自主引导机动控制决策算法[J]. 系统工程与电子技术, 2020, 42 (7): 1567- 1574.
|
|
ZHANG K , LI K , SHI H T , et al. Autonomous guidance maneuver control and decision-making algorithm based on deep reinforcement learning UAV route[J]. Systems Engineering and Electronics, 2020, 42 (7): 1567- 1574.
|
| 23 |
MAO M Y , ZHANG A , ZHOU D , et al. Reinforcement learning of UCAV air combat based on maneuver prediction[J]. Electronics Optics & Control, 2019, 26 (2): 5- 10.
|
| 24 |
LECUN Y , BENGIO Y , HINTON G . Deep learning[J]. Nature,, 2015, 521 (7553): 436- 444.
|
| 25 |
NGUYEN T, NGUYEN N D, NAHAVANDI S. Multi-agent deep reinforcement learning with human strategies[C]//Proc.of the IEEE International Conference on Industrial Technology, 2019: 1357-1362.
|
| 26 |
SEWAK M . Deep reinforcement learning: frontiers of artificial intelligence[M]. Singapore: Springer, 2019: 95- 108.
|
| 27 |
SHAPLEY L S . Stochastic games[J]. Proceedings of the National Academy of Sciences, 1953, 39 (10): 1095- 1100.
|
| 28 |
SCHWARTZ H M . Multi-agent machine learning: a reinforcement approach[M]. New Jersey: Wiley Publishing, 2014.
|
| 29 |
JAMES S M , JONATHAN P H , BRIAN W , et al. Air-combat strategy using approximate dynamic programming[J]. Journal of Guidance, Control, and Dynamics, 2010, 33 (5): 1641- 1654.
|
| 30 |
樊会涛. 第五代空空导弹的特点及关键技术[J]. 航空科学技术, 2011, (3): 1- 5.
|
|
FAN H T . Characteristics and key technologies of the fifth generation of air to air missiles[J]. Aeronautical Science & Technology, 2011, (3): 1- 5.
|
| 31 |
WATKINS C J C H. Learning from delayed rewards[D]. London: University of Cambridge, 1989.
|
| 32 |
MNIH V , KAVUKCUOGLU K , SILVER D , et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518 (7540): 529- 533.
|

 ), 李辉1,2(
), 李辉1,2(