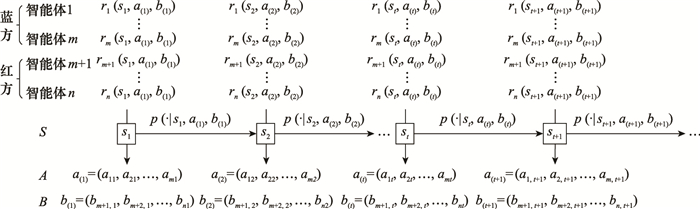
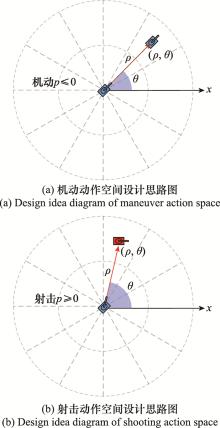
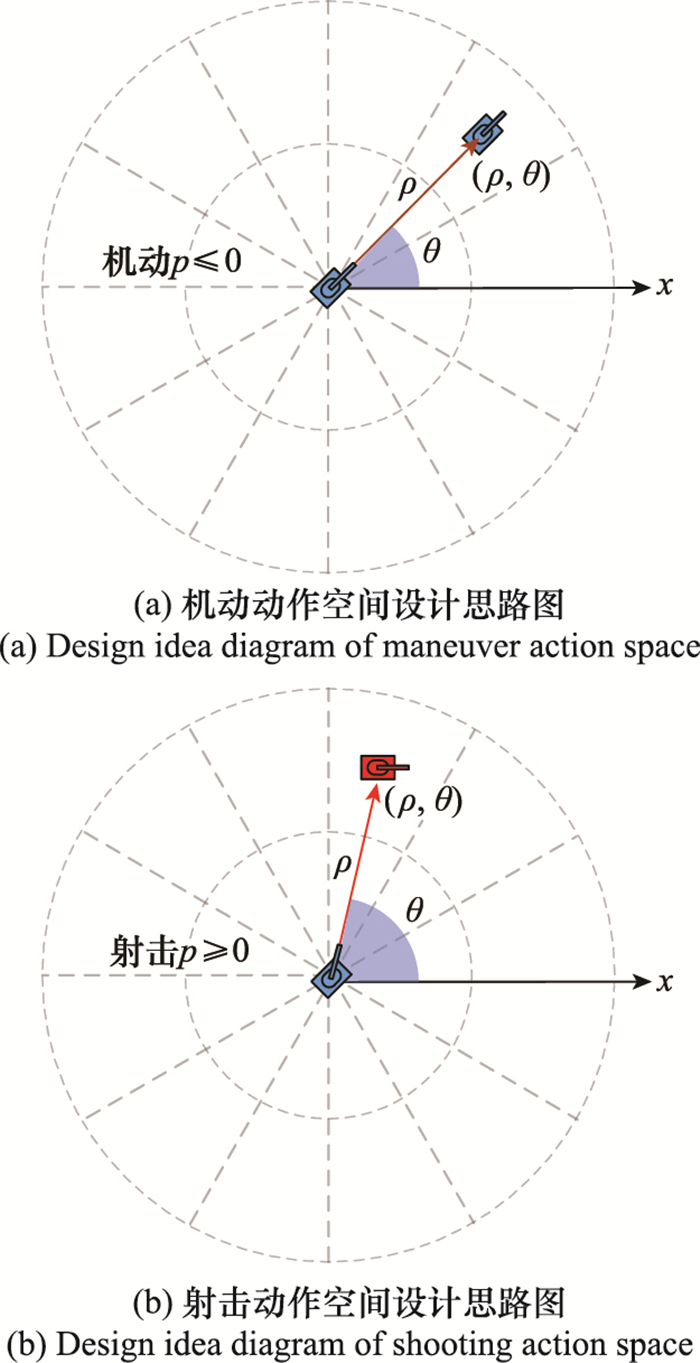
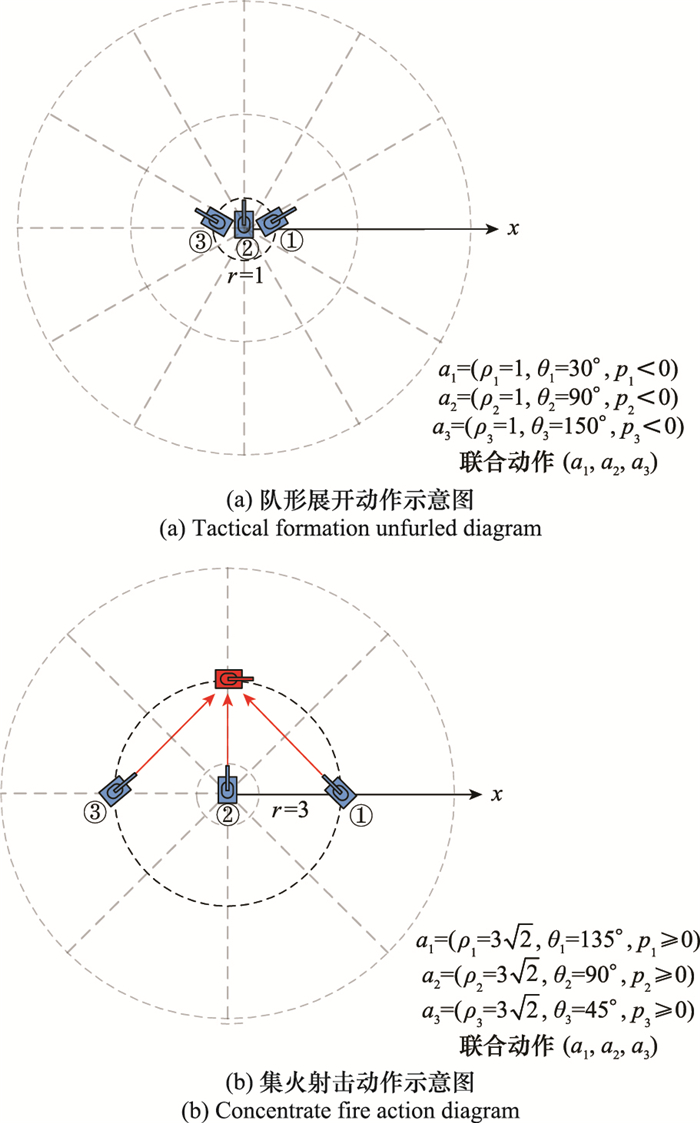
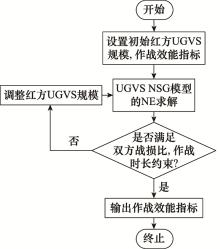
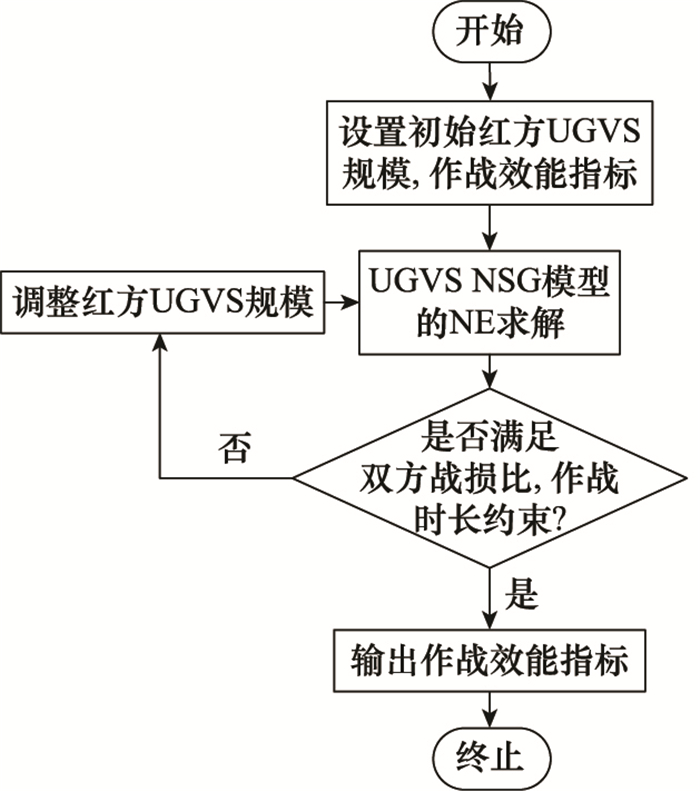
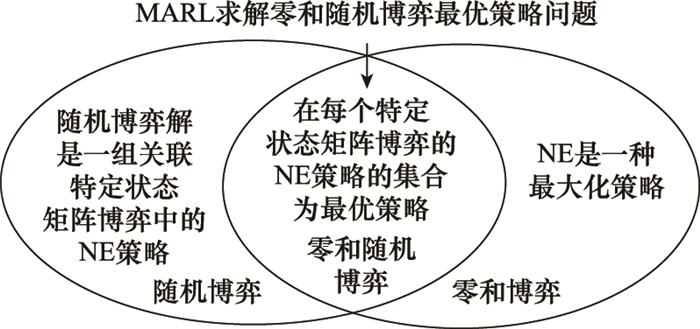
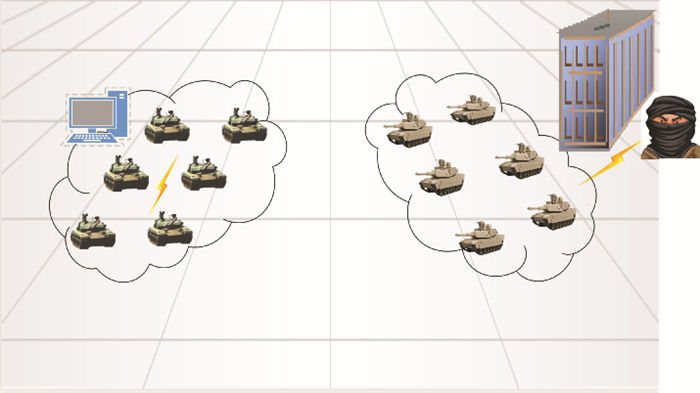
| 1 |
李风雷, 卢昊, 宋闯, 等. 智能化战争与无人系统技术的发展[J]. 无人系统技术, 2018, 1 (2): 14- 23.
|
|
LI F L , LU H , SONG C , et al. Development of intelligent warfare and unmanned system technology[J]. Unmanned Systems Technology, 2018, 1 (2): 14- 23.
|
| 2 |
中国航天科工集团第三研究院三一〇所. 自主系统与人工智能领域科技发展报告[M]. 北京: 国防工业出版社, 2019: 167- 169.
|
|
No.310 Institute of the Third Research Institute of China Aerospace Science and Industry Corporation . Scientific and technological development report in autonomous systems and artificial intelligence[M]. Beijing: Defense Industry Press, 2019: 167- 169.
|
| 3 |
吴明曦. 智能化战争[M]. 北京: 国防工业出版社, 2020: 194- 212.
|
|
WU M X . Intelligent warfare[M]. Beijing: Defense Industry Press, 2020: 194- 212.
|
| 4 |
周玉臣, 林圣琳, 马萍, 等. 武器装备效能评估研究进展[J]. 系统仿真学报, 2020, 32 (8): 1413- 1424.
|
|
ZHOU Y C , LIN S L , MA P , et al. Research progress on weapon and equipment effectiveness evaluation[J]. Journal of System Simulation, 2020, 32 (8): 1413- 1424.
|
| 5 |
雷永林, 朱智, 甘斌, 等. 基于仿真的复杂武器系统作战效能评估框架研究[J]. 系统仿真学报, 2020, 32 (9): 1654- 1663.
|
|
LEI Y L , ZHU Z , GAN B , et al. Combat effectiveness simulation evaluation framework of complex weapon system[J]. Journal of System Simulation, 2020, 32 (9): 1654- 1663.
|
| 6 |
杨克巍, 杨志伟, 谭跃进, 等. 面向体系贡献率的装备体系评估方法研究综述[J]. 系统工程与电子技术, 2019, 41 (2): 88- 98.
|
|
YANG K W , YANG Z W , TAN Y J , et al. Review of the evaluation methods of equipment system of systems facing the contribution rate[J]. Systems Engineering and Electronics, 2019, 41 (2): 88- 98.
|
| 7 |
李航, 李明, 胡明昱. 体系作战探索性仿真技术[J]. 计算机仿真, 2020, 37 (8): 8- 11, 95.
|
|
LI H , LI M , HU M Y . Exploratory simulation experiment[J]. Computer Simulation, 2020, 37 (8): 8- 11, 95.
|
| 8 |
冯磊. CGF协同行为建模关键技术研究[D]. 长沙: 国防科学技术大学, 2011.
|
|
FENG L. Research on key technologies of CGF cooperative behavior modeling[D]. Changsha: National University of Defense Technology, 2011.
|
| 9 |
岳师光. 面向计算机生成兵力的意图识别建模与推理方法研究[D]. 长沙: 国防科学技术大学, 2016.
|
|
YUE S G. Research on modeling and inference of cgf-oriented intention recognition[D]. Changsha: National University of Defense Technology, 2016.
|
| 10 |
胡晓峰, 贺筱媛, 陶九阳. 认知仿真: 是复杂系统建模的新途径吗?[J]. 科技导报, 2018, 36 (12): 46- 54.
|
|
HU X F , HE X Y , TAO J Y . Cognitive simulation: a new approach to complex system modeling?[J]. Science & Technology Review, 2018, 36 (12): 46- 54.
|
| 11 |
黄柯棣, 刘宝宏, 黄健, 等. 作战仿真技术综述[J]. 系统仿真学报, 2004, 16 (9): 1887- 1895.
doi: 10.3969/j.issn.1004-731X.2004.09.011
|
|
HUANG K D , LIU B H , HUANG J , et al. A survey of military simulation technologies[J]. Journal of System Simulation, 2004, 16 (9): 1887- 1895.
doi: 10.3969/j.issn.1004-731X.2004.09.011
|
| 12 |
袁宏皓, 袁成. 体系效能评估技术发展综述[J]. 飞航导弹, 2019, 413 (5): 63- 67.
|
|
YUAN H H , YUAN C . Review on the development of system efficiency evaluation technology[J]. Winged Missiles Journal, 2019, 413 (5): 63- 67.
|
| 13 |
HERNANDEZ L P , KARTAL B , TAYLOR M E . A survey and critique of multiagent deep reinforcement learning[J]. Autonomous Agents and Multi-agent Systems, 2019, 33 (6): 750- 797.
|
| 14 |
YANG Y D, WANG J. An overview of multi-agent reinforcement learning from game theoretical perspective[EB/OL]. [2021-02-08]. http://arxiv.org/pdf/2011.0583.pdf.
|
| 15 |
苏炯铭. 多智能体即时策略对抗方法与实践[M]. 北京: 科学出版社, 2019: 16- 42.
|
|
SU J M . Methods and practices of multi-agent real-time strategy confrontation[M]. Beijing: Science Press, 2019: 16- 42.
|
| 16 |
PENG P, YUAN Q, WEN Y, et al. Multiagent bidirectionally-coordinated nets for learning to play starcraft combat games[EB/OL]. [2021-02-08]. http://arxiv.org/pdf/1703.1069.pdf.
|
| 17 |
ZHANG J , WANG G , YUE S H , et al. Multi-agent system application in accordance with game theory in bi-directional coordination network model[J]. Journal of Systems Engineering and Electronics, 2020, 31 (2): 279- 289.
|