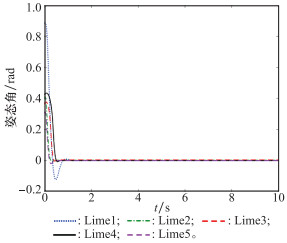
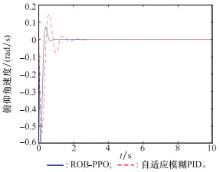
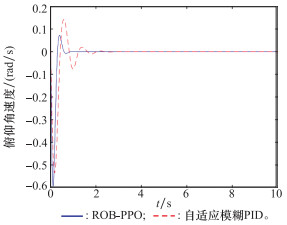
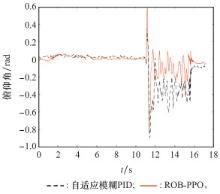
| 1 |
ZHOU Y M , ZHAO H R , LIU Y L . An evaluative review of the VTOL technologies for unmanned and manned aerial vehicles[J]. Computer Communications, 2020, 149, 356- 369.
doi: 10.1016/j.comcom.2019.10.016
|
| 2 |
LIU H , LIU Y , WANG Y , et al. Recovery control strategy of reusable launch vehicle based on dynamic model[J]. Journal of Aerospace Engineering, 2019, 32 (5): 04019035.
|
| 3 |
HUDSON G C. History of the phoenix VTOL SSTO and recent developments in single-stage launch systems[C]//Proc. of the 4th International Space Conference of Pacific-basin Societies, 1991: 329-351.
|
| 4 |
COX K L. Design development of the Apollo lunar module[C]//Proc. of the NASA Washington 4th Inter-Center Control Systems Conference, 1978.
|
| 5 |
FREEMAN D C , TALAY T A , AUSTIN R E . Reusable launch vehicle technology program[J]. Acta Astronautica, 1997, 41 (11): 777- 790.
doi: 10.1016/S0094-5765(97)00197-5
|
| 6 |
NARUO Y, TOKUDOME S I, ISHⅡ M, et al. Design and operational aspect of LOX/LH2 propulsion system of reusable vehicle testing (RVT)[C]//Proc. of the AIAA/NAL-NASDA-ISAS 10th International Space Planes and Hypersonic Systems and Technologies Conference, 2001: 20-23.
|
| 7 |
DREYER L. Latest developments on SpaceX's Falcon 1 and Falcon 9 launch vehicles and Dragon spacecraft[C]//Proc. of the IEEE Aerospace Conference, 2009.
|
| 8 |
SAGLIANO M, TSUKAMOTO T, HEIDEIDECKER A, et al. Robust control for reusable rockets via structured H∞ synthesis[C]//Proc. of the 11th International ESA Conference on GNC Systems, 2021.
|
| 9 |
SIMLICIO P , MARCOS A , BENNANI S . Reusable launchers: development of a coupled flight mechanics, guidance and control benchmark[J]. Journal of Spacecraft and Rockets, 2020, 57 (1): 74- 89.
doi: 10.2514/1.A34429
|
| 10 |
WU X , XIAO B , QU Y . Modeling and sliding mode-based attitude tracking control of a quadrotor UAV with time-varying mass[J]. ISA Transactions, 2019, 126, 436- 443.
|
| 11 |
ALTAN A , HACIOGLU R . Model predictive control of three-axis gimbal system mounted on UAV for real-time target tracking under external disturbances[J]. Mechanical Systems and Signal Processing, 2020, 138, 106548.
doi: 10.1016/j.ymssp.2019.106548
|
| 12 |
LIU D Y , LIU H , ZHANG J S , et al. Adaptive attitude controller design for tail-sitter unmanned aerial vehicles[J]. Journal of Vibration and Control, 2021, 27 (1/2): 185- 196.
|
| 13 |
KUANTAMA E , VESSELENYI T , DZITAC S , et al. PID and fuzzy-PID control model for quadcopter attitude with disturbance parameter[J]. International Journal of Computers Communications & Control, 2017, 12 (4): 519- 532.
|
| 14 |
WANG L , ZHANG J . Adaptive fuzzy PID control of a vertical takeoff and landing aircraft[J]. ISA Transactions, 2021, 117, 308- 318.
|
| 15 |
SANTOSO F , GARRATT M A , ANAVATTI S G . Hybrid PD-fuzzy and PD controllers for trajectory tracking of a quadrotor unmanned aerial vehicle: autopilot designs and real-time flight tests[J]. IEEE Trans.on Systems, Man, and Cybernetics: Systems, 2021, 51 (3): 1817- 1829.
|
| 16 |
LI X , LI Y . Adaptive fuzzy PID control for flexible aircraft[J]. Aerospace Science and Technology, 2021, 117, 106467.
|
| 17 |
GE Z L , LI Y L , MA S X . Attitude stabilization of rocket elastic vibration based on robust observer[J]. Aerospace, 2022, 9 (12): 765.
doi: 10.3390/aerospace9120765
|
| 18 |
贾振宇, 刘子龙. 一种通过强化学习的四旋翼姿态控制算法[J]. 小型微型计算机系统, 2021, 42 (10): 2074- 2078.
doi: 10.3969/j.issn.1000-1220.2021.10.010
|
|
JIA Z Y , LIU Z L . A quadcopter attitude control algorithm via reinforcement learning[J]. Journal of Small Microcomputer Systems, 2021, 42 (10): 2074- 2078.
doi: 10.3969/j.issn.1000-1220.2021.10.010
|
| 19 |
SANTOSO F , GARRATT M A , ANAVATTI S G . State-of-the-art intelligent flight control systems in unmanned aerial vehicles[J]. IEEE Trans.on Automation Science and Engineering, 2017, 15 (2): 613- 627.
|
| 20 |
YECHIEL O , GUTERMAN H . A survey of adaptive control[J]. International Robotics & Automation Journal, 2017, 3 (2): 290- 292.
|
| 21 |
WASLANDER S L, HOFFMANN G M, JANG J S, et al. Multi-agent quadrotor tested control design: integral sliding mode vs. reinforcement learning[C]//Proc. of the IEEE/RSJ International Conference on Intelligent Robots and Systems, 2005: 3712-3717.
|
| 22 |
WAN K F , LI B , GAO X G , et al. A learning-based flexible autonomous motion control method for UAV in dynamic unknown environments[J]. Journal of Systems Engineering and Electronics, 2021, 32 (6): 1490- 1508.
doi: 10.23919/JSEE.2021.000126
|
| 23 |
MALDONADO-RAMIREZ A , RIOS-CABRERA R , LOPEZ-JUAREZ I . A visual path-following learning approach for industrial robots using DRL[J]. Robotics and Computer-Integrated Manufacturing, 2021, 71, 102130.
doi: 10.1016/j.rcim.2021.102130
|
| 24 |
PENG Y F , TAN G Z , SI H W , et al. DRL-GAT-SA: deep reinforcement learning for autonomous driving planning based on graph attention networks and simplex architecture[J]. Journal of Systems Architecture, 2022, 126, 102505.
doi: 10.1016/j.sysarc.2022.102505
|
| 25 |
裴培, 何绍溟, 王江, 等. 一种深度强化学习制导控制一体化算法[J]. 宇航学报, 2021, 42 (10): 1293- 1304.
doi: 10.3873/j.issn.1000-1328.2021.10.010
|
|
PEI P , HE S M , WANG J , et al. Integrated guidance and control algorithm based on deep reinforcement learning[J]. Journal of Astronautics, 2021, 42 (10): 1293- 1304.
doi: 10.3873/j.issn.1000-1328.2021.10.010
|
| 26 |
章胜, 周攀, 何扬, 等. 基于深度强化学习的空战机动决策试验研究[J]. 航空学报, 2023, 44 (10): 122- 135.
|
|
ZHANG S , ZHOU P , HE Y , et al. Experimental study on air combat maneuver decision-making based on deep reinforcement learning[J]. Acta Aeronautica et Astronautica Sinica, 2023, 44 (10): 122- 135.
|
| 27 |
PI C H , HU K C , CHENG S , et al. Low-level autonomous control and tracking of quadrotor using reinforcement learning[J]. Control Engineering Practice, 2020, 95, 104222.
doi: 10.1016/j.conengprac.2019.104222
|
| 28 |
徐世东. 挠性航天器振动抑制及姿态模糊控制方法研究[D]. 哈尔滨: 哈尔滨工业大学, 2018.
|
|
XU S D. Research on vibration suppression and attitude fuzzy control method of flexible spacecraft[D]. Harbin: Harbin Institute of Technology, 2018.
|
| 29 |
李学峰, 王青, 王辉, 等. 运载火箭飞行控制系统设计与验证[M]. 北京: 国防工业出版社, 2014: 23- 25.
|
|
LI X F , WANG Q , WANG H , et al. Design and verification of flight control system for launch vehicles[M]. Beijing: National Defense Industry Press, 2014: 23- 25.
|
| 30 |
SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[EB/OL]. [2023-02-10]. https://arxiv.org/pdf/1707.06347.pdf.
|
| 31 |
RAMÓN I. VERDÉS K , YURY O , et al. Aguilar, robust observer design with prescribed settling-time bound and finite varying gains[J]. European Journal of Control, 2022, 100667.
|
| 32 |
CRUZ-ZAVALA E , MORENO J A . Levant's arbitrary-order exact differentiator: a Lyapunov approach[J]. IEEE Trans.on Automatic Control, 2019, 64 (7): 3034- 3039.
doi: 10.1109/TAC.2018.2874721
|
| 33 |
ZHANG Z B , LI X H , AN J P , et al. Model-free attitude control of spacecraft based on PID-guide TD3 algorithm[J]. International Journal of Aerospace Engineering, 2020, 8874619.
|
| 34 |
付宇鹏, 邓向阳, 何明, 等. 基于强化学习的固定翼飞机姿态控制方法研究[J]. 控制与决策, 2023, 38 (9): 2505- 2510.
|
|
FU Y P , DENG X Y , HE M , et al. Research on attitude control of fixed-wing aircraft based on reinforcement learning[J]. Control and Decision, 2023, 38 (9): 2505- 2510.
|