
系统工程与电子技术 ›› 2021, Vol. 43 ›› Issue (11): 3338-3351.doi: 10.12305/j.issn.1001-506X.2021.11.35
宋波1,2,*, 叶伟1, 孟祥辉2
收稿日期:2021-01-13
出版日期:2021-11-01
发布日期:2021-11-12
通讯作者:
宋波
作者简介:宋波(1992—), 男, 硕士研究生, 主要研究方向为认知无线电、强化学习|叶伟(1969—), 男, 教授, 博士, 主要研究方向为雷达对抗、电磁频谱智能作战|孟祥辉(1986—), 男, 工程师, 本科, 主要研究方向为电磁频谱管理
Bo SONG1,2,*, Wei YE1, Xianghui MENG2
Received:2021-01-13
Online:2021-11-01
Published:2021-11-12
Contact:
Bo SONG
摘要:
认知无线电和动态频谱分配技术是解决频谱资源短缺问题的有效手段。随着近年来深度学习和强化学习等机器学习技术迅速发展, 以多智能体强化学习为代表的群体智能技术不断取得突破, 使得分布式智能动态频谱分配成为可能。本文详细梳理了强化学习和多智能体强化学习领域关键研究成果, 以及基于多智能体强化学习的动态频谱分配过程建模方法与算法研究。并将现有算法归结为独立Q-学习、合作Q-学习、联合Q-学习和多智能体行动器-评判器算法4种, 分析了这些方法的优点与不足, 总结并给出了基于多智能体强化学习的动态频谱分配方法的关键问题与解决思路。
中图分类号:
宋波, 叶伟, 孟祥辉. 基于多智能体强化学习的动态频谱分配方法综述[J]. 系统工程与电子技术, 2021, 43(11): 3338-3351.
Bo SONG, Wei YE, Xianghui MENG. Review of multi-agent reinforcement learning based dynamic spectrum allocation method[J]. Systems Engineering and Electronics, 2021, 43(11): 3338-3351.
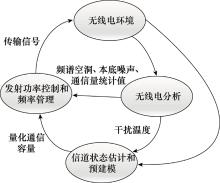
图1
认知环的感知与决策过程"
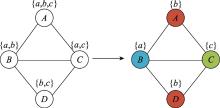
图2
基于图论的频谱分配模型"
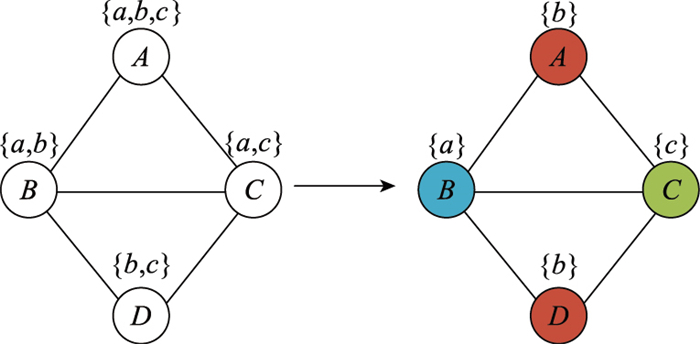
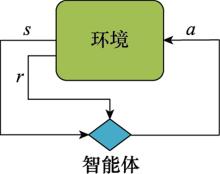
图3
MDP示意图"
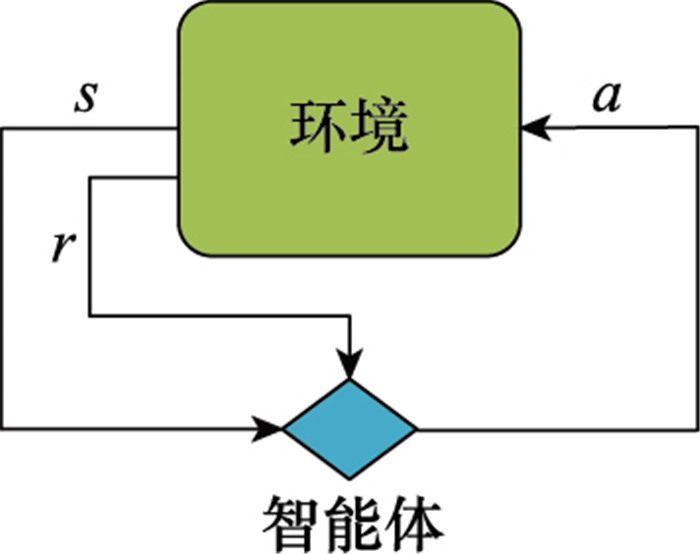
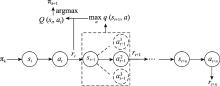
图4
Q-学习更新过程"
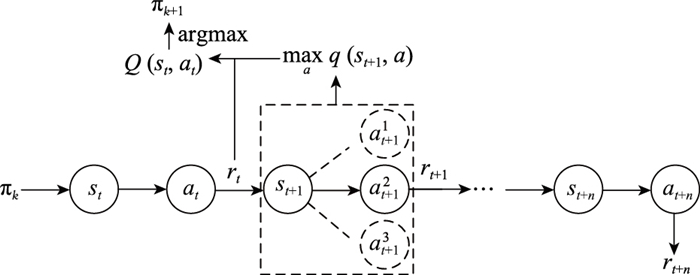
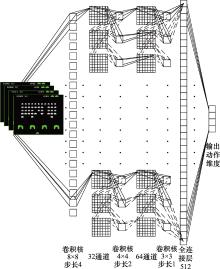
图5
深度Q-网络"
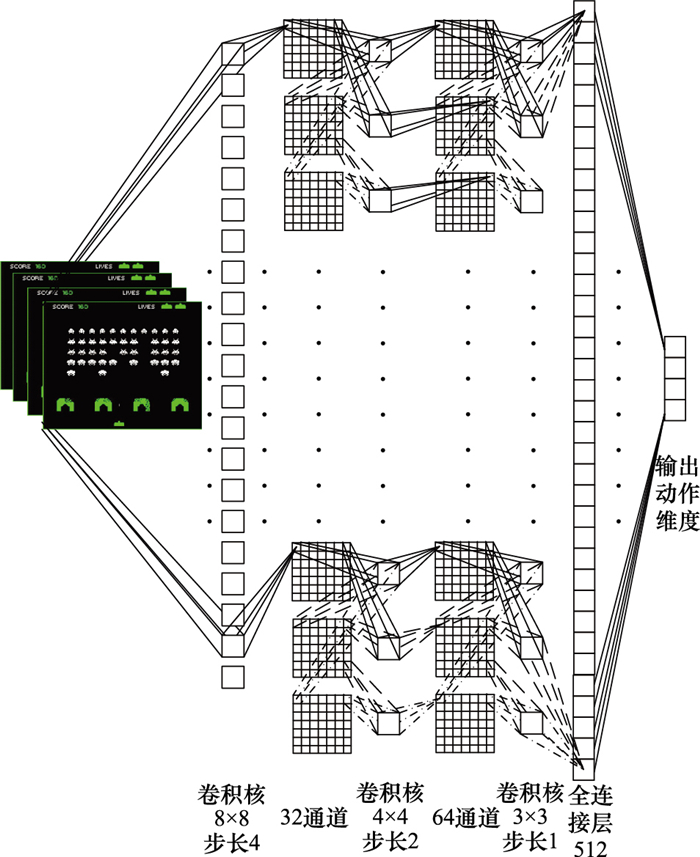
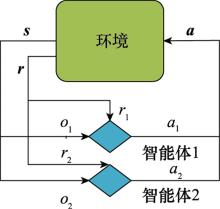
图6
部分可观测MDP"
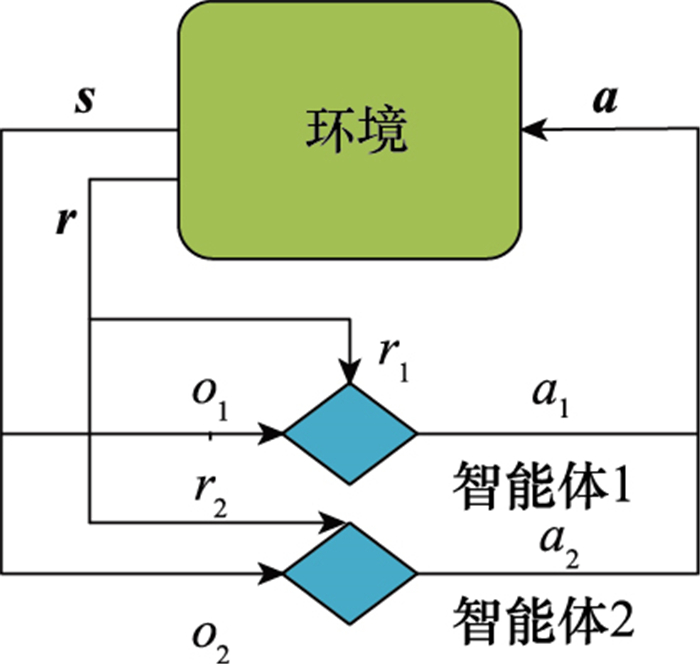
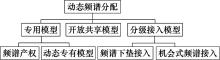
图7
动态频谱分配模型"
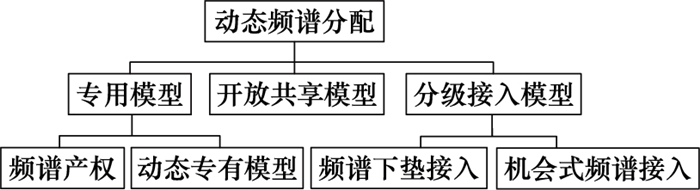
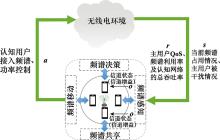
图8
基于Dec-POMDP的动态频谱分配建模"
表1
4种方法特性对比"
| 区别 | 基于IQL的方法 | 基于CQL的方法 | 基于JQL的方法 | 基于MAAC的方法 |
| 是否需要控制中心 | 否 | 否 | 是 | 否 |
| 是否需要用户协作 | 否 | 是 | 是 | 否 |
| 是否需要集中训练 | 否 | 否 | 是 | 是 |
| 适用的用户数量 | 少 | 少 | 较多 | 多 |
| 训练稳定性 | 低 | 中 | 中 | 高 |
| 对用户间信息交互的需求 | 无 | 大 | 大 | 无 |
| 1 |
MITOLA J , MAGUIRE G Q . Cognitive radio: making software radios more personal[J]. IEEE Personal Communications, 1999, 6 (4): 13- 18.
doi: 10.1109/98.788210 |
| 2 |
HAYKIN S . Cognitive radio: brain-empowered wireless communications[J]. IEEE Journal on Selected Areas in Communications, 2005, 23 (2): 201- 220.
doi: 10.1109/JSAC.2004.839380 |
| 3 |
PENG C , ZHENG H , ZHAO B Y . Utilization and fairness in spectrum assignment for opportunistic spectrum access[J]. Mobile Networks and Applications, 2006, 11 (4): 555- 576.
doi: 10.1007/s11036-006-7322-y |
| 4 | 廖楚林, 陈劼, 唐友喜, 等. 认知无线电中的并行频谱分配算法[J]. 电子与信息学报, 2007, 7, 1608- 1611. |
| LIAO C L , CHEN J , TANG Y X , et al. Parallel spectrum allocation algorithm in cognitive radio[J]. Journal of Electronics and Information Technology, 2007, 7, 1608- 1611. | |
| 5 | 郝丹丹, 邹仕洪, 程时端. 开放式频谱系统中启发式动态频谱分配算法[J]. 软件学报, 2008, 2008 (3): 479- 491. |
| HAO D D , ZOU S H , CHENG S R . Heuristic dynamic spectrum allocation algorithm in open spectrum system[J]. Journal of Software, 2008, 2008 (3): 479- 491. | |
| 6 | WANG W, LIU X. List-coloring based channel allocation for open-spectrum wireless networks[C]//Proc. of the IEEE 62nd Vehicular Technology Conference, 2005: 690-694. |
| 7 |
刘鹏, 张国翊, 舒放, 等. 基于图论的认知无线网络频谱动态分配[J]. 电讯技术, 2020, 60 (6): 625- 631.
doi: 10.3969/j.issn.1001-893x.2020.06.002 |
|
LIU P , ZHANG G Y , SHU F , et al. Dynamic spectrum allocation of cognitive wireless network based on graph theory[J]. Telecommunication Engineering, 2020, 60 (6): 625- 631.
doi: 10.3969/j.issn.1001-893x.2020.06.002 |
|
| 8 |
何建强, 滕志军, 刘皎. 一种基于改进颜色敏感图论着色的频谱分配算法[J]. 计算机与数字工程, 2019, 47 (8): 1866- 1868, 1889.
doi: 10.3969/j.issn.1672-9722.2019.08.004 |
|
HE J Q , TENG Z J , LIU J . A spectrum allocation algorithm based on improved color sensitive graph theory coloring[J]. Computer & Digital Engineering, 2019, 47 (8): 1866- 1868, 1889.
doi: 10.3969/j.issn.1672-9722.2019.08.004 |
|
| 9 | NEEL J, REED J H, GILLES R P. The role of game theory in the analysis of software radio networks[C]//Proc. of the SDR Forum Technology Conference, 2002. |
| 10 | NEEL J O, REED J H, GILLES R P. Convergence of cognitive radio networks[C]//Proc. of the IEEE Wireless Communications and Networking Conference, 2004: 2250-2255. |
| 11 |
滕志军, 韩雪, 杨旭. 认知无线电中基于博弈论的频谱分配算法[J]. 计算机应用研究, 2011, 28 (7): 2661- 2663.
doi: 10.3969/j.issn.1001-3695.2011.07.073 |
|
TENG Z J , HAN X , YANG X . Spectrum allocation algorithm based on game theory in cognitive radio[J]. Application Research of Computers, 2011, 28 (7): 2661- 2663.
doi: 10.3969/j.issn.1001-3695.2011.07.073 |
|
| 12 | CAO L, ZHENG H. Distributed spectrum allocation via local bargaining[C]//Proc. of the IEEE International Conference on Sensing, Communication and Networking, 2005: 475-486. |
| 13 |
ETKIN R , PAREKH A , TSE D . Spectrum sharing for unlicensed bands[J]. IEEE Journal on Selected Areas in Communications, 2007, 25 (3): 517- 528.
doi: 10.1109/JSAC.2007.070402 |
| 14 | 徐昌彪, 刘雪亮, 鲜永菊. 基于博弈论的动态频谱分配技术研究[J]. 电子技术应用, 2012, 38 (4): 102- 105, 109. |
| XU C B , LIU X L , XIAN Y J . Research on dynamic spectrum allocation technology based on game theory[J]. Application of Electronic Technique, 2012, 38 (4): 102- 105, 109. | |
| 15 |
刘鑫一, 姜建. 基于拍卖理论的认知物联网频谱分配策略[J]. 中国科技论文, 2016, 11 (19): 2187- 2192.
doi: 10.3969/j.issn.2095-2783.2016.19.008 |
|
LIU X Y , JIANG J . Cognitive IoT spectrum allocation strategy based on auction theory[J]. China Science Paper, 2016, 11 (19): 2187- 2192.
doi: 10.3969/j.issn.2095-2783.2016.19.008 |
|
| 16 |
CHEN J , GAO Y M , KUO Y H . A parallel repeated auction for spectrum allocation in distributed cognitive radio networks[J]. Wireless personal communications, 2014, 77 (4): 2839- 2855.
doi: 10.1007/s11277-014-1671-9 |
| 17 | ZHOU X, ZHENG H. TRUST: a general framework for truthful double spectrum auctions[C]//Proc. of the IEEE International Conference on Computer Communications, 2009: 999-1007. |
| 18 | WANG Q, YE B, XU T, et al. An approximate truthfulness motivated spectrum auction for dynamic spectrum access[C]//Proc. of the IEEE Wireless Communications and Networking Conference, 2011: 257-262. |
| 19 |
MNIH V , KAVUKCUOGLU K , SILV-ER D , et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518 (7540): 529- 533.
doi: 10.1038/nature14236 |
| 20 | HASSELT H . Double Q-learning[J]. Advances in neural information processing systems (NeurIPS), 2010, 23, 2613- 2621. |
| 21 | VAN HASSELT H, GUEZ A, SILVER D. Deep reinforcement learning with double q-learning[C]//Proc. of the AAAI Conference on Artificial Intelligence, 2016. |
| 22 | WANG Z, SCHAUL T, HESSEL M, et al. Dueling network architectures for deep reinforcement learning[C]//Proc. of Machine Learning Research, 2016: 1995-2003. |
| 23 | FORTUNATO M, AZAR M G, PIOT B, et al. Noisy networks for exploration[EB/OL]. [2021-05-08]. https://arxiv.org/abs/1706.10295. |
| 24 | HESSEL M, MODAYIL J, VAN HASSELT H, et al. Rainbow: combining improvements in deep reinforcement learning[C]//Proc. of the AAAI 32nd Conference on Artificial Intelligence, 2018: 3215-3223. |
| 25 | GU S, LILLICRAP T, SUTSKEVER I, et al. Continuous deep Q-learning with model-based acceleration[C]//Proc. of the International Conference on Machine Learning, 2016: 2829-2838. |
| 26 | KONDA V R, TSITSIKLIS J N. Act-or-Critic algorithms[C]//Proc. of the Advances in Neural Information Processing Systems, 2000: 1008-1014. |
| 27 | MNIH V, BADIA A P, MIRZA M, et al. Asynchronous methods for deep reinforcement learning[C]//Proc. of the International conference on Machine Learning, 2016: 1928-1937. |
| 28 | SCHULMAN J, LEVINE S, ABBEEL P, et al. Trust region policy optimization[C]//Proc. of the International Conference on Machine Learning, 2015: 1889-1897. |
| 29 | WU Y, MANSIMOV E, GROSSE R B, et al. Scalable trust-region method for deep reinforcement learning using Kronecker-factored approximation[C]//Proc. of the Advances in Neural Information Processing Systems, 2017: 5279-5288. |
| 30 | SCHULMAN J, WOLSKI F, DHARI-WAL P, et al. Proximal policy optimization algorithms[EB/OL]. [2021-05-08]. https://arxiv.org/abs/1707.06347. |
| 31 | WANG Z, BAPST V, HEESS N, et al. Sample efficient actor-critic with experience replay[EB/OL]. [2021-05-08] https://arxiv.org/abs/1611.01224. |
| 32 | MUNOS R, STEPLETON T, HARUT-YUNYAN A, et al. Safe and efficient off-policy reinforcement learning[EB/OL]. [2021-05-08]. https://arxiv.org/abs/1606.02647. |
| 33 | SILVER D, LEVER G, HEESS N, et al. Deterministic policy gradient algorithms[C]//Proc. of the 31st International Conference on Machine Learning Volume, 2014: I-387-I-395. |
| 34 | FUJIMOTO S, VAN HOOF H, MEG-ER D. Addressing function approximation error in actor-critic methods[C]//Proc. of the Machine Learning Research, 2018. |
| 35 | HAARNOJA T, ZHOU A, ABBEEL P, et al. Soft actor-critic: off-policy maximum entropy deep reinforcement learning with a stochastic actor[C]//Proc. of the International Confe-rence on Machine Learning, 2018: 1861-1870. |
| 36 | SUTTON R S , BARTO A G . Reinforcement learning: an introduction[M]. Cambridge: MIT Press, 2018. |
| 37 | SILVER D, SUTTON R S, MVLLERM. Sample-based learning and search with permanent and transient memories[C]//Proc. of the International Conference on Machine Learning, 2008: 968-975. |
| 38 | COULOM R. Efficient selectivity and backup operators in Monte-Carlo tree search[C]//Proc. of the International Conference on Computers and Games, 2006: 72-83. |
| 39 |
SILVER D , HUANG A , MADDISON C J , et al. Mastering the game of go with deep neural networks and tree search[J]. Nature, 2016, 529 (7587): 484- 489.
doi: 10.1038/nature16961 |
| 40 |
SILVER D , SCHRITTWIESER J , SI-MONYAN K , et al. Mastering the game of go without human knowledge[J]. Nature, 2017, 550 (7676): 354- 359.
doi: 10.1038/nature24270 |
| 41 |
SCHRITTWIESER J , ANTONOGLOU I , HUBERT T , et al. Mastering Atari, go, chess and shogi by planning with a learned model[J]. Nature, 2020, 588 (7839): 604- 609.
doi: 10.1038/s41586-020-03051-4 |
| 42 |
GOODFELLOW I , POUGET-ABADIE J , MIRZA M , et al. Generative adversarial networks[J]. Communications of the ACM, 2020, 63 (11): 139- 144.
doi: 10.1145/3422622 |
| 43 | HO J, ERMON S. Generative adversarial imitation learning[C]//Proc. of the Advances in Neural Information Processing Systems, 2016, 29: 4565-4573. |
| 44 | LEVINE S, KUMAR A, TUCKER G, et al. Offline reinforcement learning: tutorial, review, and perspectives on open problems[EB/OL]. [2021-05-08]. https://arxiv.org/abs/2005.01643. |
| 45 | 殷昌盛, 杨若鹏, 朱巍, 等. 多智能体分层强化学习综述[J]. 智能系统学报, 2020, 15 (4): 646- 655. |
| YIN C S , YANG R P , ZHU W , et al. A survey on multi-agent hierarchical reinforcement learning[J]. CAAI Transactions on Intelligent Systems, 2020, 15 (4): 646- 655. | |
| 46 | BUȘONIU L , BABUŠKA R , SCHUTTER B D . Innovations in multi-agent systems and applications[M]. Heidelberg: Springer, 2010: 183- 221. |
| 47 |
LITTMAN M L . Value-function reinforcement learning in Markov games[J]. Cognitive Systems Research, 2001, 2 (1): 55- 66.
doi: 10.1016/S1389-0417(01)00015-8 |
| 48 | LAUER M, RIEDMILLER M. An algorithm for distributed reinforcement learning in cooperative multi-agent systems[C]//Proc. of the 17th International Conference on Machine Learning, 2000: 535-542. |
| 49 | LITTMAN M L . Machine learning proceedings[M]. Amsterdam: Elsevier Inc., 1994: 157- 163. |
| 50 | HU J, WELLMAN M P. Multiagent reinforcement learning: theoretical framework and an algorithm[C]//Proc. of the International Conference on Machine Learning, 1998: 242-250. |
| 51 | GREENWALD A, HALL K, SERRA-NO R. Correlated Q-learning[C]//Proc. of the International Conference on Machine Learning, 2003: 242. |
| 52 | 梁星星, 冯旸赫, 马扬, 等. 多Agent深度强化学习综述[EB/OL]. [2020-11-30]. https://doi.org/10.16383/j.aas.c180372. |
| LIANG X X, FENG Y H, MA Y, et al. Re-view of multi-Agent deep reinforcement learning[EB/OL]. [2020-11-30]. https://doi.org/10.16383/j.aas.c180372. | |
| 53 | SUKHBAATAR S, FERGUS R. Learning multiagent communication with backpropagation[C]//Proc. of the Advances in Neural Information Processing Systems, 2016: 2244-2252. |
| 54 | PENG P, YUAN Q, WEN Y, et al. Multi-agent bidirectionally-coordinated nets for learning to play starcraft combat games[EB/OL]. [2021-05-08]. https://arxiv.org/abs/1703.10069. |
| 55 | TAN M. Multi-agent reinforcement learning: independent vs. cooperative agents[C]//Proc. of the 10th International Conference on Machine Learning, 1993: 330-337. |
| 56 | MATIGNON L, LAURENT G J, LE FORT-PIAT N. Hysteretic Q-learning: an algorithm for decentralized reinforcement learning in cooperative multi-agent teams[C]//Proc. of the IEEE/RSJ International Conference on Intelligent Robots and Systems, 2007: 64-69. |
| 57 | OMIDSHAFIEI S, PAZIS J, AMATO C, et al. Deep decentralized multi-task multi-agent reinforcement learning under partial observability[C]//Proc. of the International Conference on Machine Learning, 2017: 2681-2690. |
| 58 | PEROLAT J, PIOT B, PIETQUIN O. Actor-critic fictitious play in simultaneous move multistage games[C]//Proc. of the International Conference on Artificial Intelligence and Statistics, 2018: 919-928. |
| 59 | FOERSTER J, ASSAEL Y, DEFREI-TAS N, et al. Learning to communicate with deep multi-agent reinforcement learning[C]//Proc. of the Advances in Neural Information Processing Systems, 2016: 2137-2145. |
| 60 | MAO H, GONG Z, NI Y, et al. ACCNet: actor-coordinator-critic net for "learning-to-communicate" with deep multi-agent reinforcement learning[EB/OL]. [2021-05-08]. https://arxiv.org/abs/1706.03235. |
| 61 | LOWE R, WU Y I, TAMAR A, et al. Multi-agent actor-critic for mixed cooperative-competitive environments[C]//Proc. of the Advances in Neural Information Processing Systems, 2017: 6379-6390. |
| 62 | FOERSTER J, FARQUHAR G, AFO-URAS T, et al. Counterfactual multi-agent policy gradients[J]. arXiv preprint arXiv: 1705.08926, 2017. |
| 63 | SUNEHAG P, LEVER G, GRUSLYS A, et al. Value-decomposition networks for cooperative multi-agent learning based on team reward[C]//Proc. of the 17th International Conference on Autonomous Agents and Multi-Agent Systems, 2018: 2085-2087. |
| 64 | RASHID T, SAMVELYAN M, SCHROEDER C, et al. Qmix: monotonic value function factorisation for deep multi-agent reinforcement learning[C]//Proc. of the International Conference on Machine Learning, 2018: 4295-4304. |
| 65 | VASWANI A, SHAZEER N, PARMA-R N, et al. Attention is all you need[C]//Proc. of the Advances in Neural Information Processing Systems, 2017: 5998-6008. |
| 66 | YANG Y, HAO J, LIAO B, et al. Q-atten: a general framework for cooperative multiagent reinforcement learning[EB/OL]. [2021-05-08]. https://arxiv.org/abs/2002.03939. |
| 67 | SHALEV-SHWARTZ S, SHAMMAH S, SHASHUA A. Safe, multi-agent, reinforcement learning for autonomous driving[J]. arXiv preprint arXiv: 1610.03295, 2016. |
| 68 | AYDIN M E, FELLOWS R. A reinforcement learning algorithm for building collaboration in multi-agent systems[EB/OL]. [2021-05-08]. https://arxiv.org/abs/1711.10574. |
| 69 | LUO Y, SHI Z P, ZHOU X, et al. Dynamic resource allocations based on Q-learning for D2D communication in cellular networks[C]//Proc. of the IEEE 11th International Computer Conference on Wavelet Active Media Technology and Information Processing, 2014: 385-388. |
| 70 |
ZHAO Q , SADLER B M . A survey of dynamic spectrum access[J]. IEEE Signal Processing Magazine, 2007, 24 (3): 79- 89.
doi: 10.1109/MSP.2007.361604 |
| 71 | KOLODZY P. Spectrum policy task force: findings and recommendations[C]//Proc. of the International Symposium on Advanced Radio Technologies, 2003: 459-465. |
| 72 |
CHEN Y X , ZHAO Q , SWAMI A . Joint design and separation principle for opportunistic spectrum access in the presence of sensing errors[J]. IEEE Trans. on Information Theory, 2008, 54 (5): 2053- 2071.
doi: 10.1109/TIT.2008.920248 |
| 73 | 夏婷婷. 基于部分可观测马尔可夫决策过程的机会频谱接入方案设计[D]. 南京: 南京邮电大学, 2014. |
| XIA T T. Project design of the opportunistic spectrum access based on POMDP[D]. Nanjing: Nanjing University of Posts and Telecommunications, 2014. | |
| 74 | 郭冰洁. 认知无线电系统中多信道动态频谱接入算法研究[D]. 成都: 电子科技大学, 2013. |
| GUO B J. Research on multi-channel dynamic spectrum access algorithms in cognitive radio systems[D]. Chengdu: University of Electronic Science and Technology of China, 2013. | |
| 75 | 何浩. 认知无线电动态频谱接入关键技术研究[D]. 成都: 电子科技大学, 2014. |
| HE H. Research on key technologies of dynamic spectrum access in cognitive radio[D]. Chengdu: University of Electronic Science and Technology of China, 2014. | |
| 76 | 叶梓峰. 基于深度强化学习的动态频谱分配方法研究[D]. 广州: 广东工业大学, 2019. |
| YE Z F. Research of dynamic spectrum allocation methods based on deep reinforcement learning[D]. Guangzhou: Guangdong University of Technology, 2019. | |
| 77 | LI H. Multi-agent Q-learning of channel selection in multi-user cognitive radio systems: a two by two case[C]//Proc. of the IEEE International Conference on Systems, Man and Cybernetics, 2009: 1893-1898. |
| 78 | TENG Y L, ZHANG Y, NIU F, et al. Reinforcement learning based auction algorithm for dynamic spectrum aces-s in cognitive radio networks[C]//Proc. of the IEEE 72nd Vehicular Technology Conference-Fall, 2010. |
| 79 | WU C, CHOWDHURY K, FELICE M D, et al. Spectrum management of cognitive radio using multi-agent reinforcement learning[C]//Proc. of the 9th International Conference on Autonomous Agents and Multi-Agent Systems: Industry Track, 2010: 1705-1712. |
| 80 | 伍春, 江虹, 易克初. 聚类多Agent强化学习认知无线电资源分配[J]. 北京邮电大学学报, 2014, 37 (1): 80- 84. |
| WU C , JIANG H , YI K C . Clustering multi-Agent reinforcement learning cognitive radio resource allocation[J]. Journal of Beijing University of Posts and Telecommunications, 2014, 37 (1): 80- 84. | |
| 81 |
ZIA K , JAVED N , SIAL M N , et al. A distributed multi-agent RL-based autonomous spectrum allocation scheme in D2D enabled multi-tier HetNets[J]. IEEE Access, 2019, 7, 6733- 6745.
doi: 10.1109/ACCESS.2018.2890210 |
| 82 | ASHERALIEVA A, MIYANAGA Y. Multi-agent Q-learning for autonomous D2D communication[C]//Proc. of the IEEE International Symposium on Intelligent Signal Processing and Communication Systems, 2016. |
| 83 | NAPARSTEK O , COHEN K . Deep multi-user reinforcement learning for distributed dynamic spectrum access[J]. IEEE Trans. on Wireless Communications, 2018, 18 (1): 310- 323. |
| 84 |
ZHAO J H , ZHANG Y , NIE Y W , et al. Intelligent resource allocation for train-to-train communication: a multi-agent deep reinforcement learning approach[J]. IEEE Access, 2020, 8, 8032- 8040.
doi: 10.1109/ACCESS.2019.2963751 |
| 85 |
NASIR Y S , GUO D . Multi-agent deep reinforcement learning for dynamic power allocation in wireless networks[J]. IEEE Journal on Selected Areas in Communications, 2019, 37 (10): 2239- 2250.
doi: 10.1109/JSAC.2019.2933973 |
| 86 | YAU K L A, KOMISARCZUK P, PAUL D T. Enhancing network performance in distributed cognitive radio networks using single-agent and multi-agent reinforcement learning[C]//Proc. of the IEEE Local Computer Network Conference, 2010: 152-159. |
| 87 | LALL S, SADHU A K, KONAR A, et al. Multi-agent reinforcement learning for stochastic power management in cognitive radio network[C]//Proc. of the IEEE International Conference on Microelectronics, Computing and Communications, 2016. |
| 88 | WANG S , LIU H , GOMES P H , et al. Deep reinforcement learning for dynamic multichannel access in wireless networks[J]. IEEE Trans. on Cognitive Communications and Networking, 2018, 4 (2): 257- 265. |
| 89 | LI Z , GUO C L . Multi-agent deep reinforcement learning based spectrum allocation for D2D underlay communications[J]. IEEE Trans. on Vehicular Technology, 2019, 69 (2): 1828- 1840. |
| [1] | 朱霸坤, 朱卫纲, 李伟, 杨莹, 高天昊. 基于马尔可夫的多功能雷达认知干扰决策建模研究[J]. 系统工程与电子技术, 2022, 44(8): 2488-2497. |
| [2] | 王冠, 茹海忠, 张大力, 马广程, 夏红伟. 弹性高超声速飞行器智能控制系统设计[J]. 系统工程与电子技术, 2022, 44(7): 2276-2285. |
| [3] | 孟泠宇, 郭秉礼, 杨雯, 张欣伟, 赵柞青, 黄善国. 基于深度强化学习的网络路由优化方法[J]. 系统工程与电子技术, 2022, 44(7): 2311-2318. |
| [4] | 郭冬子, 黄荣, 许河川, 孙立伟, 崔乃刚. 再入飞行器深度确定性策略梯度制导方法研究[J]. 系统工程与电子技术, 2022, 44(6): 1942-1949. |
| [5] | 韩明仁, 王玉峰. 基于强化学习的全电推进卫星变轨优化方法[J]. 系统工程与电子技术, 2022, 44(5): 1652-1661. |
| [6] | 王春政, 胡明华, 杨磊, 赵征. 空中交通延误预测研究综述[J]. 系统工程与电子技术, 2022, 44(3): 863-874. |
| [7] | 何立, 沈亮, 李辉, 王壮, 唐文泉. 强化学习中的策略重用: 研究进展[J]. 系统工程与电子技术, 2022, 44(3): 884-899. |
| [8] | 张心宇, 刘源, 宋佳凝. 基于LSTM神经网络的短期轨道预报[J]. 系统工程与电子技术, 2022, 44(3): 939-947. |
| [9] | 朱霸坤, 朱卫纲, 李伟, 杨莹, 高天昊. 基于先验知识的多功能雷达智能干扰决策方法[J]. 系统工程与电子技术, 2022, 44(12): 3685-3695. |
| [10] | 杨清清, 高盈盈, 郭玙, 夏博远, 杨克巍. 基于深度强化学习的海战场目标搜寻路径规划[J]. 系统工程与电子技术, 2022, 44(11): 3486-3495. |
| [11] | 曾斌, 张鸿强, 李厚朴. 针对无人潜航器的反潜策略研究[J]. 系统工程与电子技术, 2022, 44(10): 3174-3181. |
| [12] | 万齐天, 卢宝刚, 赵雅心, 温求遒. 基于深度强化学习的驾驶仪参数快速整定方法[J]. 系统工程与电子技术, 2022, 44(10): 3190-3199. |
| [13] | 李贺, 赵文静, 金明录. 基于特征值高阶矩的频谱感知增强技术[J]. 系统工程与电子技术, 2022, 44(10): 3243-3248. |
| [14] | 曾斌, 王睿, 李厚朴, 樊旭. 基于强化学习的战时保障力量调度策略研究[J]. 系统工程与电子技术, 2022, 44(1): 199-208. |
| [15] | 江志炜, 黄洋, 吴启晖. 基于核函数强化学习的抗干扰频点分配[J]. 系统工程与电子技术, 2021, 43(6): 1547-1556. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||