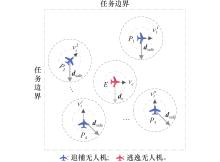
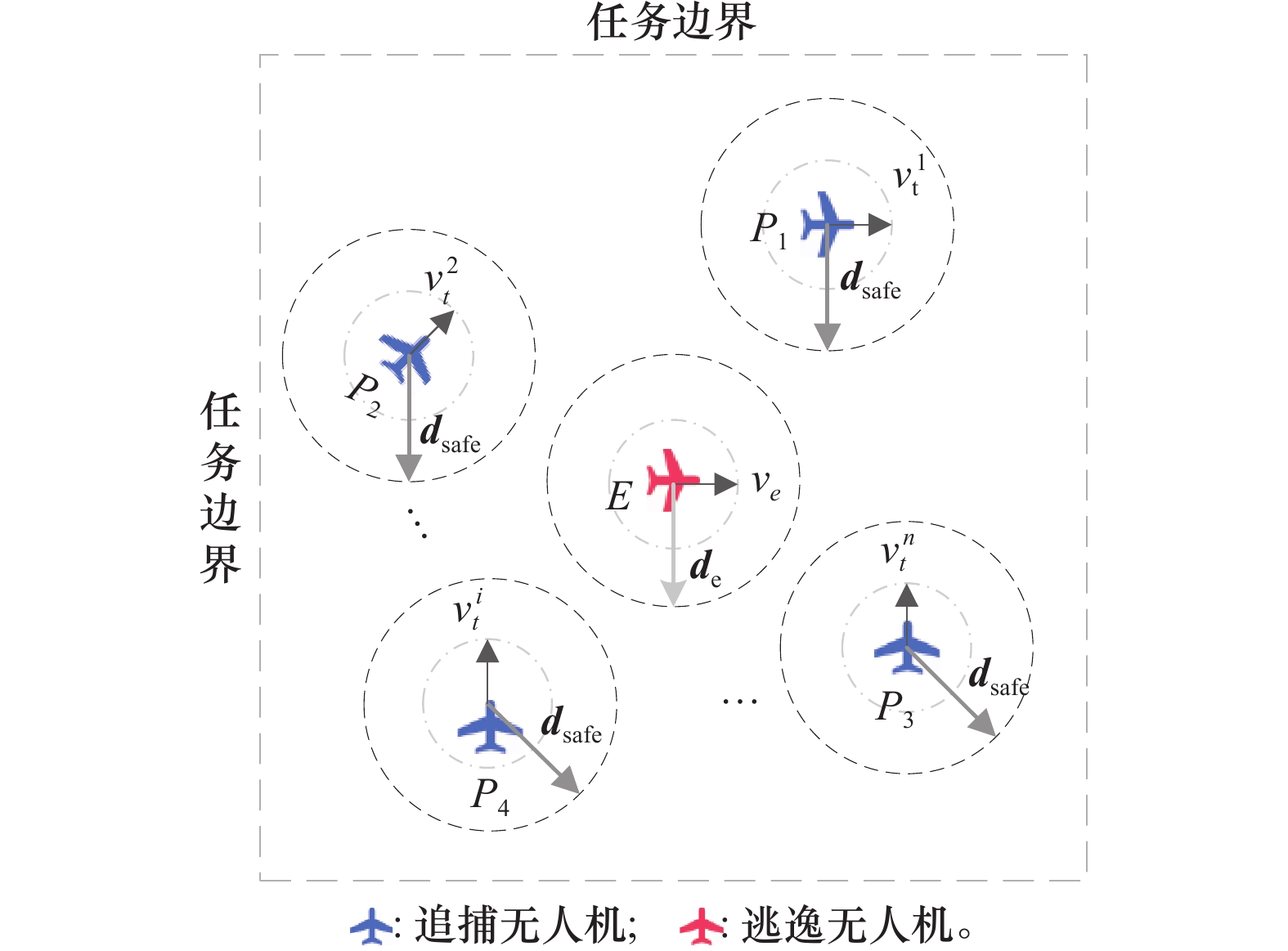
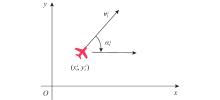
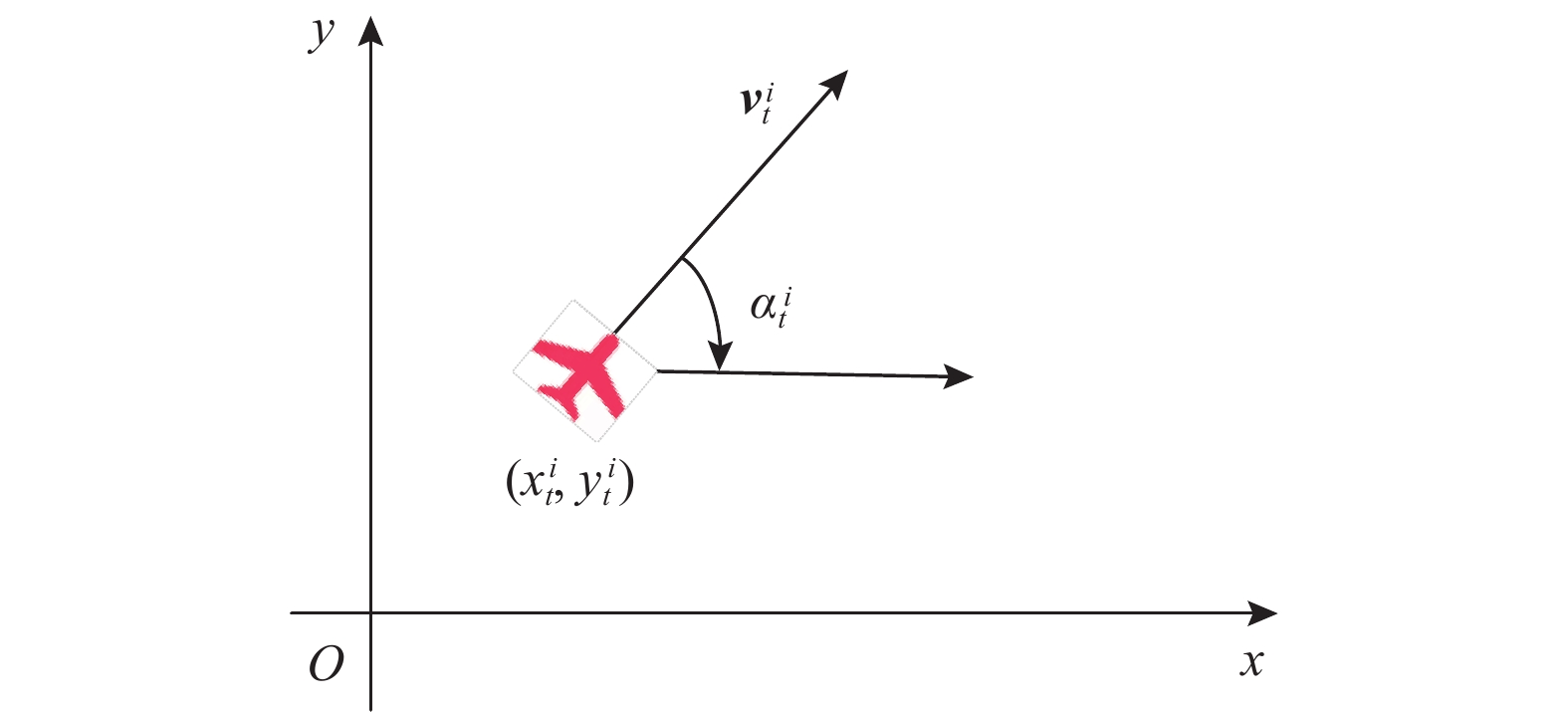
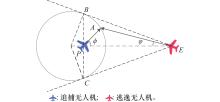
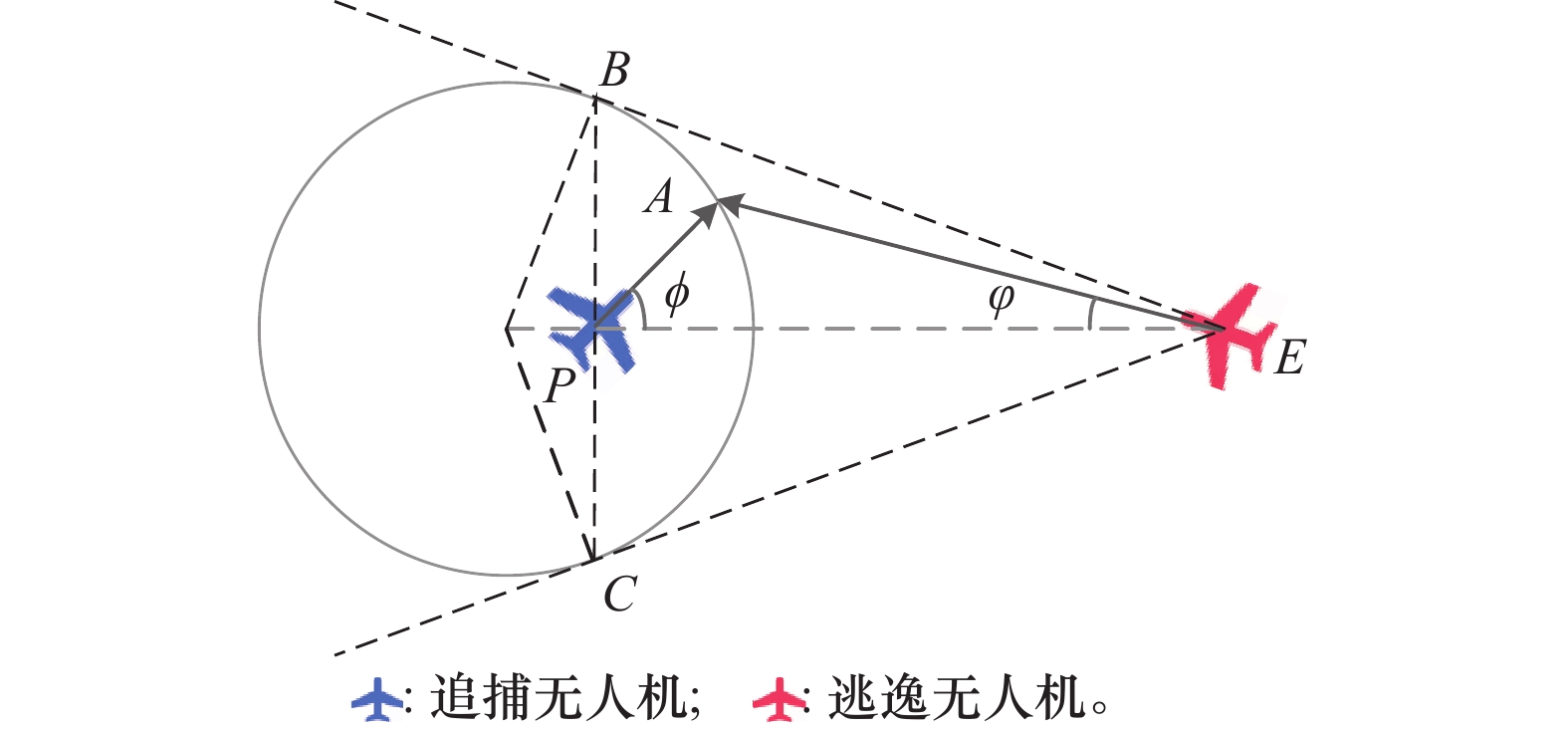
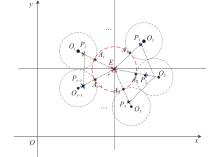
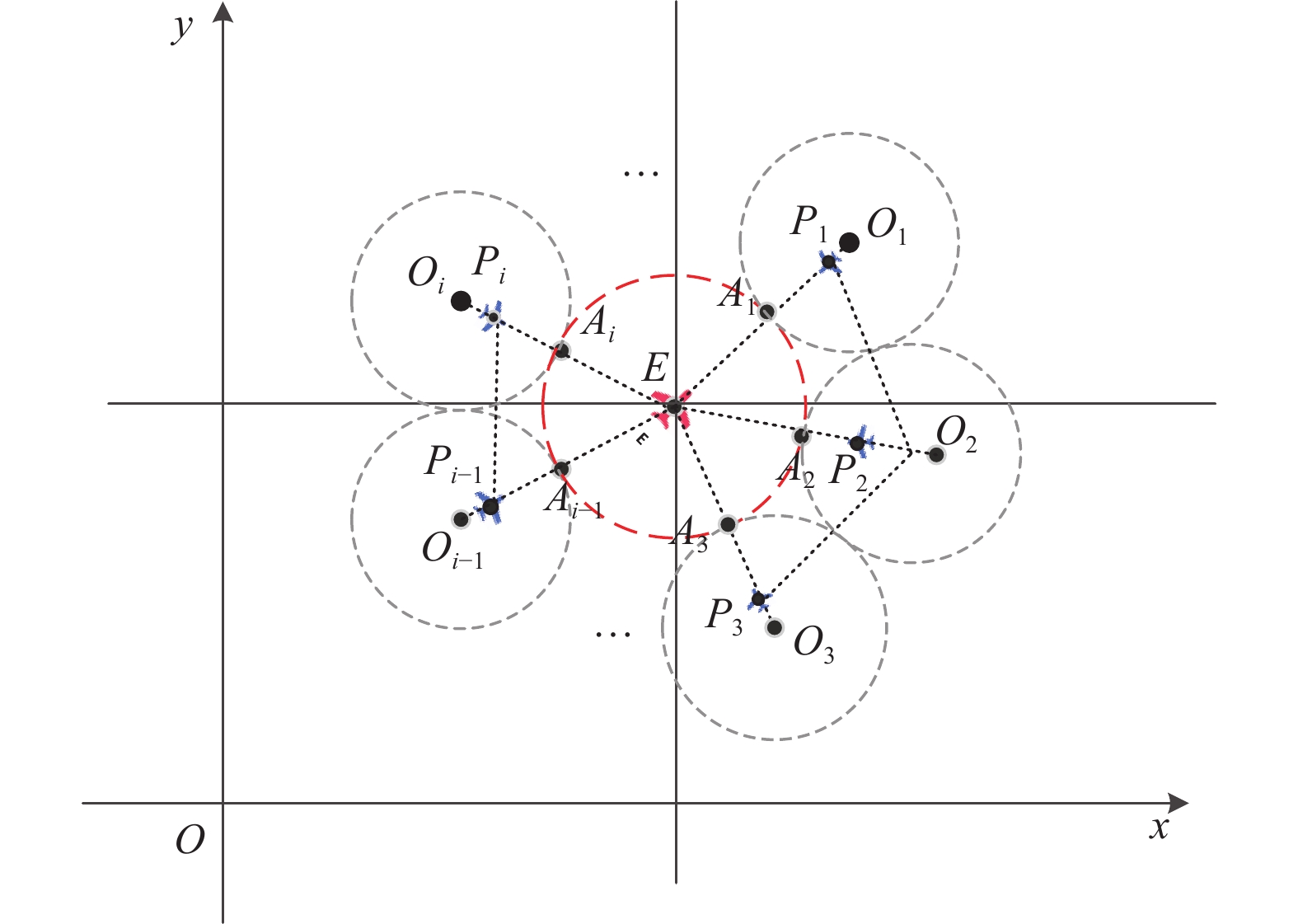
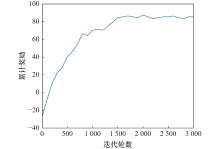
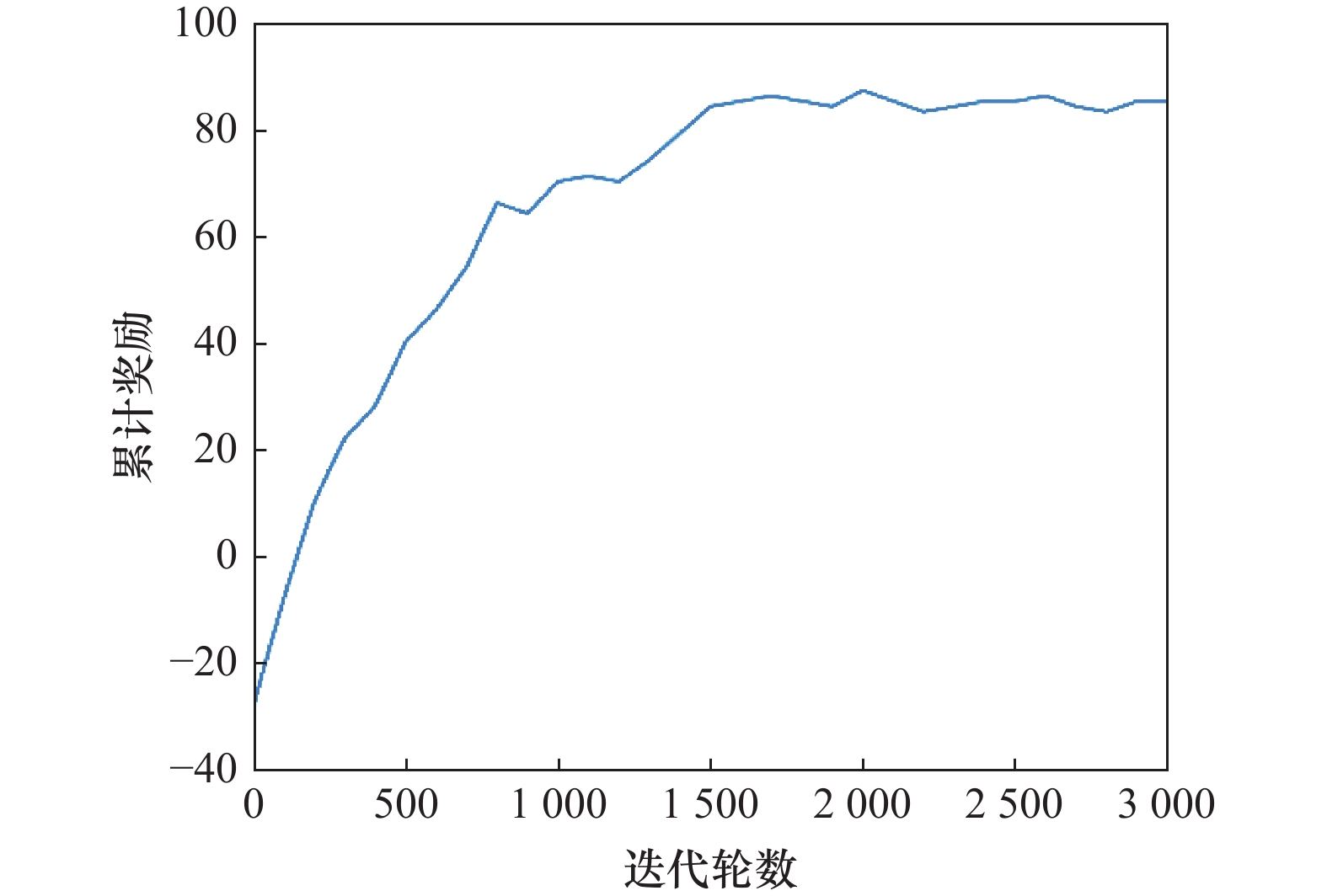
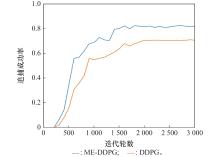
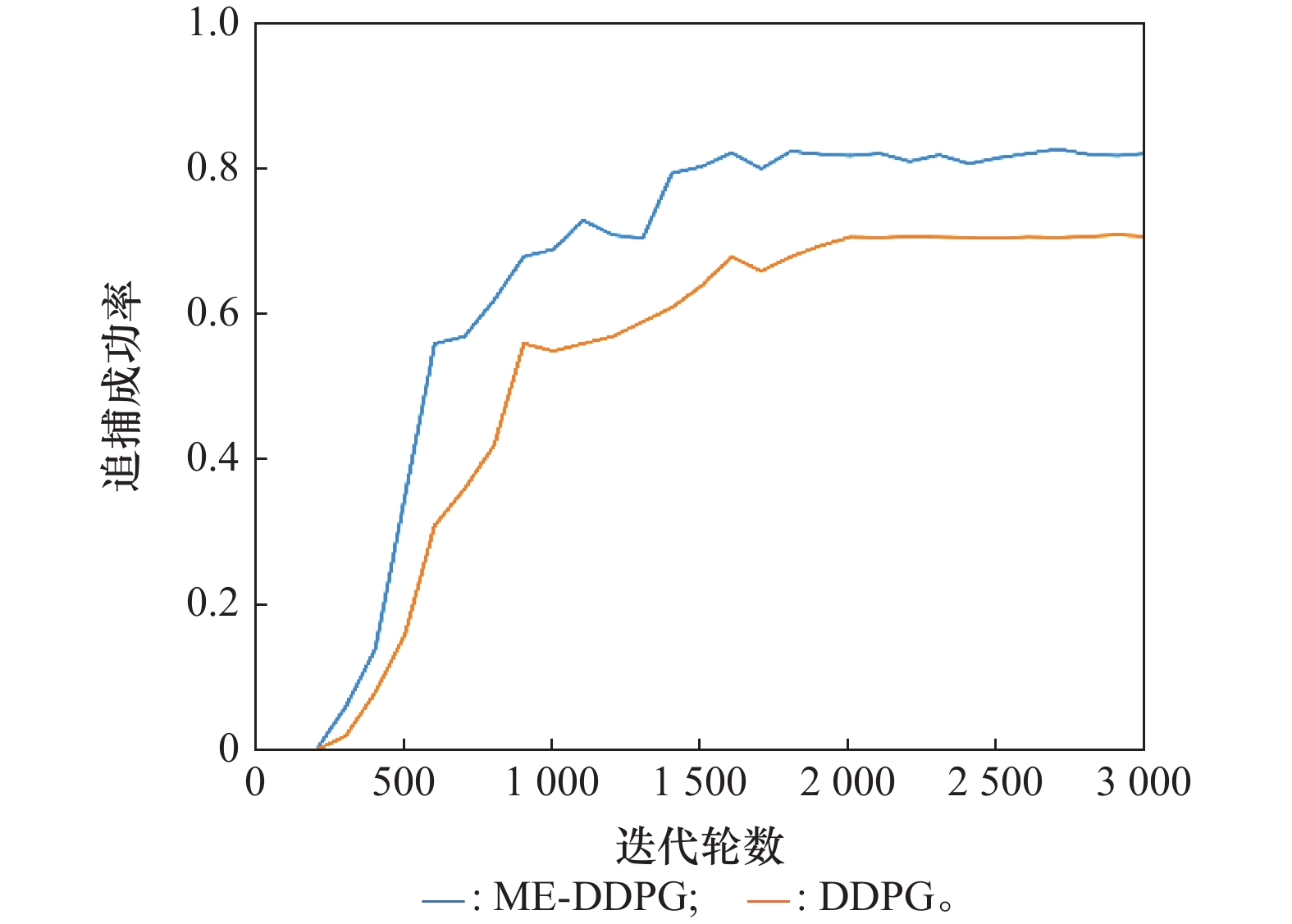
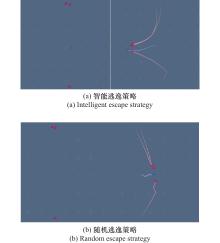
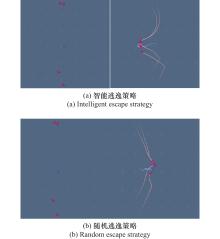
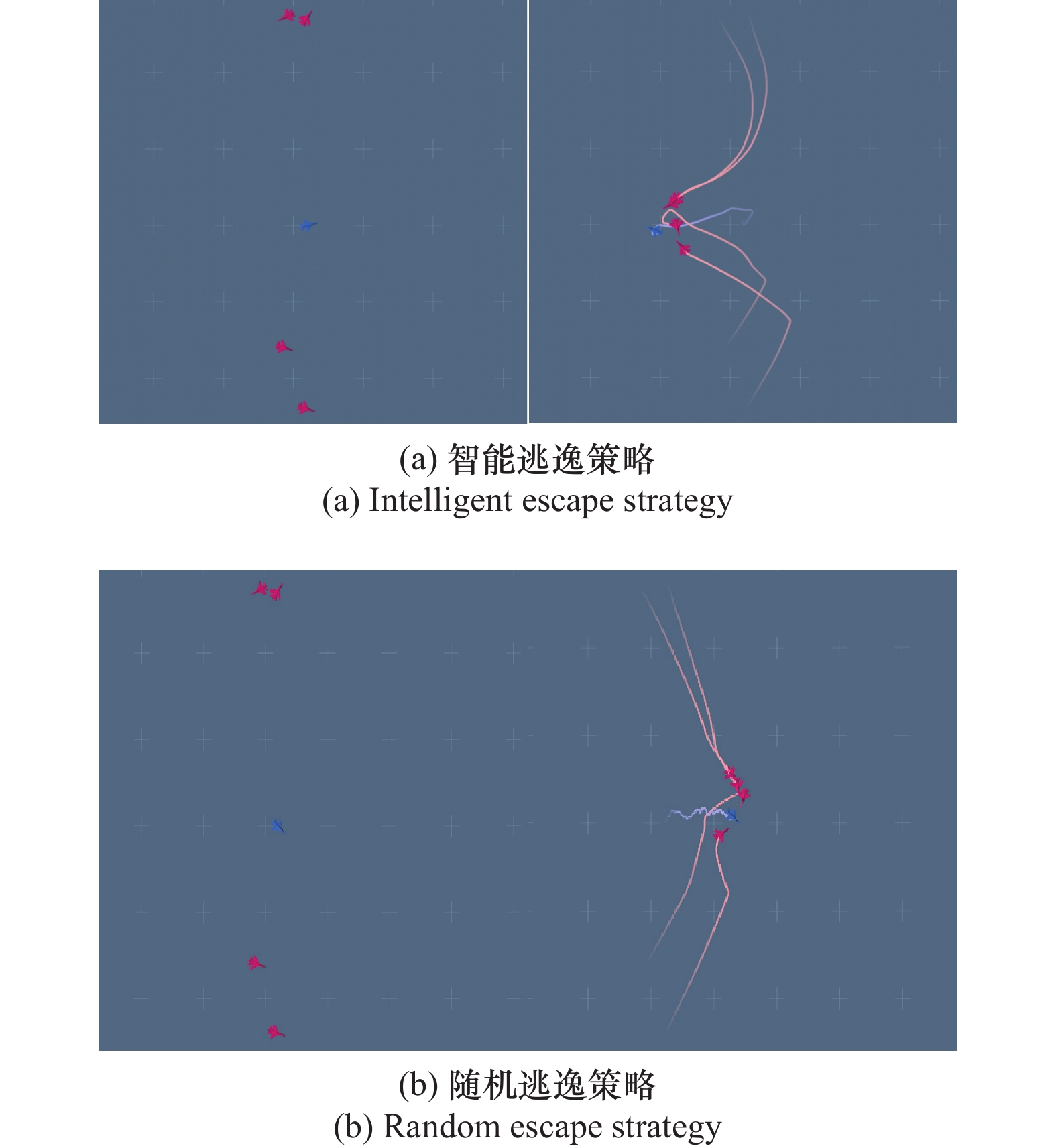
| 29 |
WANG Y Y, WANG X, ZHOU W X, et al. Threat potential field based pursuit-evasion games for under actuated unmanned surface vehicles[J]. Ocean Engineering, 2023, 285(Part 2): 115381.
|
| 30 |
DANKWA S, ZHENG W. Twin-delayed ddpg: a deep reinforcement learning technique to model a continuous movement of an intelligent robot agent[C]//Proc. of the 3rd International Conference on Vision, Image and Signal Processing, 2019.
|
| 31 |
ALACAOGLU A, VIANO L, HE N, et al. A natural actor-critic framework for zero-sum Markov games[C]//Proc. of the 39th International Conference on Machine Learning, 2022: 307−366.
|
| 32 |
DUAN J, GUAN Y, LI S E, et al. Distributional soft actor-critic: off-policy reinforcement learning for addressing value estimation errors[J]. IEEE Trans. on Neural Networks and Learning Systems, 2021, 33 (11): 6584- 6598.
|
| 33 |
HUANG Z Q, HUA G Y, WANG J Y, et al. Exploration strategy improved DDPG for lane keeping tasks in autonomous driving[C]//Proc. of the 2nd International Conference on Artificial Intelligence, Automation and Algorithms, 2022: 012020.
|
| 34 |
ICARTE R T, KLASSEN T Q, VALENZANO R, et al. Reward machines: exploiting reward function structure in reinforcement learning[EB/OL]. [2023-11-11]. https://arxiv.org/abs/2010.03950.
|
| 1 |
EMIMI M, KHALEEL M, ALKRASH A. The current opportunities and challenges in drone technology[J]. International Journal of Electrical Engineering and Sustainability, 2023, 1 (3): 74- 89.
|
| 2 |
ZHANG R L, ZONG Q, ZHANG X Y, et al. Game of drones: multi-UAV pursuit-evasion game with online motion planning by deep reinforcement learning[J]. IEEE Trans. on Neural Networks and Learning Systems, 2023, 34 (10): 7900- 7909.
doi: 10.1109/TNNLS.2022.3146976
|
| 3 |
CHAPPELL A R. Knowledge-based reasoning in the Paladin tactical decision generation system[C]//Proc. of the 11th Digital Avionics Systems Conference, 1992: 155−160.
|
| 4 |
TENG T H, TAN A H, TAN Y S, et al. Self-organizing neural networks for learning air combat maneuvers[C]//Proc. of the International Joint Conference on Neural Networks, 2012.
|
| 5 |
BATHER J A. Differential games: a mathematical theory with applications to warfare and pursuit, control and optimization[J]. Wiley, 1966, 129 (3): 474- 475.
|
| 6 |
左家亮, 杨任农, 张滢, 等. 基于启发式强化学习的空战机动智能决策[J]. 航空学报, 2017, 38 (10): 321168.
|
|
ZUO J L, YANG R N, ZHANG Y, et al. Intelligent decision-making in air combat maneuvering based on heuristic reinforcement learning[J]. Acta Aeronautica et Astronautica Sinica, 2017, 38 (10): 321168.
|
| 7 |
王炫, 王维嘉, 宋科璞, 等. 基于进化式专家系统树的无人机空战决策技术[J]. 兵工自动化, 2019, 38 (1): 48- 53.
|
|
WANG X, WANG W J, SONG K P, et al. UAV air combat decision technology based on evolutionary expert system tree[J]. Ordnance Industry Automation, 2019, 38 (1): 48- 53.
|
| 8 |
张宏鹏, 黄长强, 轩永波, 等. 基于深度神经网络的无人作战飞机自主空战机动决策[J]. 兵工学报, 2020, 41 (8): 1613- 1622.
|
|
ZHANG H P, HUANG C Q, XUAN Y B, et al. Autonomous air combat maneuver decision of unmanned combat aircraft based on deep neural networks[J]. Acta Armamentarii, 2020, 41 (8): 1613- 1622.
|
| 9 |
DONG B, FENG Z A, CUI Y M, et al. Event-triggered adaptive fuzzy optimal control of modular robot manipulators using zero-sum differential game through value iteration[J]. International Journal of Adaptive Control and Signal Processing, 2023, 37 (9): 2364- 2379.
doi: 10.1002/acs.3642
|
| 10 |
ZHANG Y Q, ZHANG P F, WANG X D, et al. An open loop Stackelberg solution to optimal strategy for UAV pursuit-evasion game[J]. Aerospace Science and Technology, 2022, 129, 107840.
doi: 10.1016/j.ast.2022.107840
|
| 11 |
WANG X, WEI Q L, LI T, et al. Optimal strategy for aircraft pursuit-evasion games via self-play iteration[EB/OL]. [2023-11-12]. http://doi.org/10.1007/s11633-022-1413-5.
|
| 12 |
GARCIA E, CASBEER D W, PACHTER M. Active target defence differential game: fast defender case[J]. IET Control Theory & Applications, 2017, 11 (17): 2985- 2993.
|
| 13 |
魏慎娜. 基于新型态势函数的空战微分博弈问题研究[D]. 沈阳: 沈阳航空航天大学, 2018.
|
|
WEI S N. Research on differential game problem of air combat based on new situation function[D]. Shenyang: Shenyang University of Aeronautics and Astronautics, 2018.
|
| 14 |
李守义, 陈谋, 王玉惠, 等. 非完备策略集下人机对抗空战决策方法[J]. 中国科学: 信息科学, 2022, 52 (12): 2239- 2253.
doi: 10.1360/SSI-2022-0222
|
|
LI S Y, CHEN M, WANG Y H, et al. Human-computer gaming decision-making method in air combat under an incomplete strategy set[J]. SCIENTIA SINICA Informationis, 2022, 52 (12): 2239- 2253.
doi: 10.1360/SSI-2022-0222
|
| 15 |
HUA X, LIU J, ZHANG J J, et al. An apollonius circle based game theory and Q-learning for cooperative hunting in unmanned aerial vehicle cluster[J]. Computers and Electrical Engineering, 2023, 110, 108876.
doi: 10.1016/j.compeleceng.2023.108876
|
| 16 |
ZULUAGA J, LEIDIG J P, TREFFTZ C, et al. Deep reinforcement learning for autonomous search and rescue[C]//Proc. of the National Aerospace and Electronics Conference, 2018: 521−525.
|
| 17 |
GONG Z H, XU Y, LUO D L. UAV cooperative air combat maneuvering confrontation based on multi-agent reinforcement learning[J]. Unmanned Systems, 2023, 11 (3): 273- 286.
doi: 10.1142/S2301385023410029
|
| 18 |
KURNIAWAN B, VAMPLEW P, PAPASIMEON M, et al. An empirical study of reward structures for actor-critic reinforcement learning in air combat manoeuvring simulation[J]. Lecture Notes in Computer Science, 2019, 11919, 54- 65.
|
| 19 |
HE G H, KANG M X, JIANG K C. A decision method for simulated confrontation of UAVs based on deep reinforcement learning[C]//Proc. of the 42nd Chinese Control Conference, 2023: 8098−8103.
|
| 20 |
ZHENG J Q, MA Q H, YANG S J, et al. Research on cooperative operation of air combat based on multi-agent[C]//Proc. of the 2nd International Conference on Human Interaction and Emerging Technologies: Future Applications, 2020: 175−179.
|
| 21 |
张建东, 王鼎涵, 杨啟明, 等. 基于分层强化学习的无人机多维空战决策[J]. 兵工学报, 2023, 44 (6): 1547- 1563.
|
|
ZHANG J D, WANG D H, YANG Q M, et al. Multi-dimensional decision-making for UAV air combat based on hierarchical reinforcement learning[J]. Acta Armamentarii, 2023, 44 (6): 1547- 1563.
|
| 22 |
PIPLAI A, ANORUO M, FASAYE K, et al. Knowledge guided two-player reinforcement learning for cyber attacks and defenses[C]//Proc. of the 21st IEEE International Conference on Machine Learning and Applications, 2022: 1342−1349.
|
| 23 |
ZHANG M, LIU T, CHEN Y Y, et al. A h-D3QN-QMIX design for formation decision in air combat[C]//Proc. of the 42nd Chinese Control Conference, 2023: 5577−5582.
|
| 24 |
XIONG H, ZHANG Y. Reinforcement learning-based formation-surrounding control for multiple quadrotor UAVs pursuit-evasion games[J]. ISA Transactions, 2024, 145, 205- 224.
doi: 10.1016/j.isatra.2023.12.006
|
| 25 |
刘冰雁, 叶雄兵, 高勇, 等. 基于分支深度强化学习的非合作目标追逃博弈策略求解[J]. 航空学报, 2020, 41 (10): 348- 358.
|
|
LIU B Y, YE X B, GAO Y, et al. Strategy solving of non-cooperative target pursuit game based on branch deep reinforcement learning[J]. Chinese Journal of Aeronautics, 2020, 41 (10): 348- 358.
|
| 26 |
GARCIA E, CASBEER D W, MOLL A V, et al. Multiple pursuer multiple evader differential games[J]. IEEE Trans. on Automatic Control, 2019, 66 (5): 2345- 2350.
|
| 27 |
LIANG X, ZHOU B R, JIANG L P, et al. Collaborative pursuit-evasion game of multi-UAVs based on Apollonius circle in the environment with obstacle[J]. Connection Science, 2023, 35 (1): 2168253.
doi: 10.1080/09540091.2023.2168253
|
| 28 |
SONG F, QIAN B Y, WANG Y. Collision avoidance method of autonomous vehicle based on improved artificial potential field algorithm[J]. Journal of Automobile Engineering, 2021, 235 (14): 3416- 3430.
doi: 10.1177/09544070211014319
|