
系统工程与电子技术 ›› 2025, Vol. 47 ›› Issue (9): 2993-3003.doi: 10.12305/j.issn.1001-506X.2025.09.20
• 系统工程 • 上一篇
魏潇龙1( ), 吴亚荣1(), 姚登凯2,*(), 赵顾颢1()
), 吴亚荣1(), 姚登凯2,*(), 赵顾颢1()
收稿日期:2024-07-23
出版日期:2025-09-25
发布日期:2025-09-16
通讯作者:
姚登凯
E-mail:xiaolong3494@163.com;chumiaoying2023@163.com;yao13321185369@163.com;zghlupin@163.com
作者简介:魏潇龙(1989—),男,讲师,硕士,主要研究方向为无人机运行与管控基金资助:
Xiaolong WEI1(), Yarong WU1(), Dengkai YAO2,*(), Guhao ZHAO1()
Received:2024-07-23
Online:2025-09-25
Published:2025-09-16
Contact:
Dengkai YAO
E-mail:xiaolong3494@163.com;chumiaoying2023@163.com;yao13321185369@163.com;zghlupin@163.com
摘要:
针对无人机(unmanned aerial vehicle,UAV)超视距空战机动决策复杂度高、时效性强的问题,提出基于深度强化学习的分层决策算法。首先,根据超视距空战的战术特点,对UAV的态势判断、状态转移、胜负判定等过程进行建模,搭建空战仿真环境。其次,对深度强化学习网络模型进行构建,引入分层决策机制,使用蚁群算法作为目标网络Q值估计的启发式因子。仿真验证表明,所提算法可以使UAV根据态势变化及时采取机动策略,且策略输出和机动指令输出较为稳定,决策效率较高。所提算法可在拓宽UAV战术样式的基础上降低网络的学习难度,提升决策质量。
中图分类号:
魏潇龙, 吴亚荣, 姚登凯, 赵顾颢. 基于深度强化学习的无人机空战机动分层决策算法[J]. 系统工程与电子技术, 2025, 47(9): 2993-3003.
Xiaolong WEI, Yarong WU, Dengkai YAO, Guhao ZHAO. Hierarchical decision-making algorithm for UAV air combat maneuvering based on deep reinforcement learning[J]. Systems Engineering and Electronics, 2025, 47(9): 2993-3003.
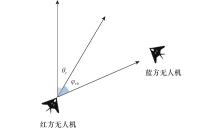
图1
无人机角度关系"
图2
无人机空战机动方法"
表1
无人机机动决策类型"
| 代号 | 机动方式 | 含义 |
| 1 | 减速快速左转 | 无人机在左转的同时减速,但使用的转弯率较大 |
| 2 | 减速慢速左转 | 无人机在左转的同时减速,但使用的转弯率较小 |
| 3 | 减速直飞 | 无人机减速直飞 |
| 4 | 减速慢速右转 | 无人机在右转的同时减速,但使用的转弯率较小 |
| 5 | 减速快速右转 | 无人机在右转的同时减速,但使用的转弯率较大 |
| 6 | 加速快速左转 | 无人机在左转的同时增速,且使用的转弯率较大 |
| 7 | 加速慢速左转 | 无人机在左转的同时增速,且使用的转弯率较小 |
| 8 | 加速直飞 | 无人机加速直飞 |
| 9 | 加速慢速右转 | 无人机在右转的同时增速,且使用的转弯率较小 |
| 10 | 加速快速右转 | 无人机在右转的同时增速,且使用的转弯率较大 |
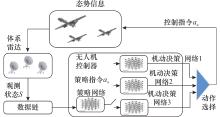
图3
无人机分层网络控制架构"
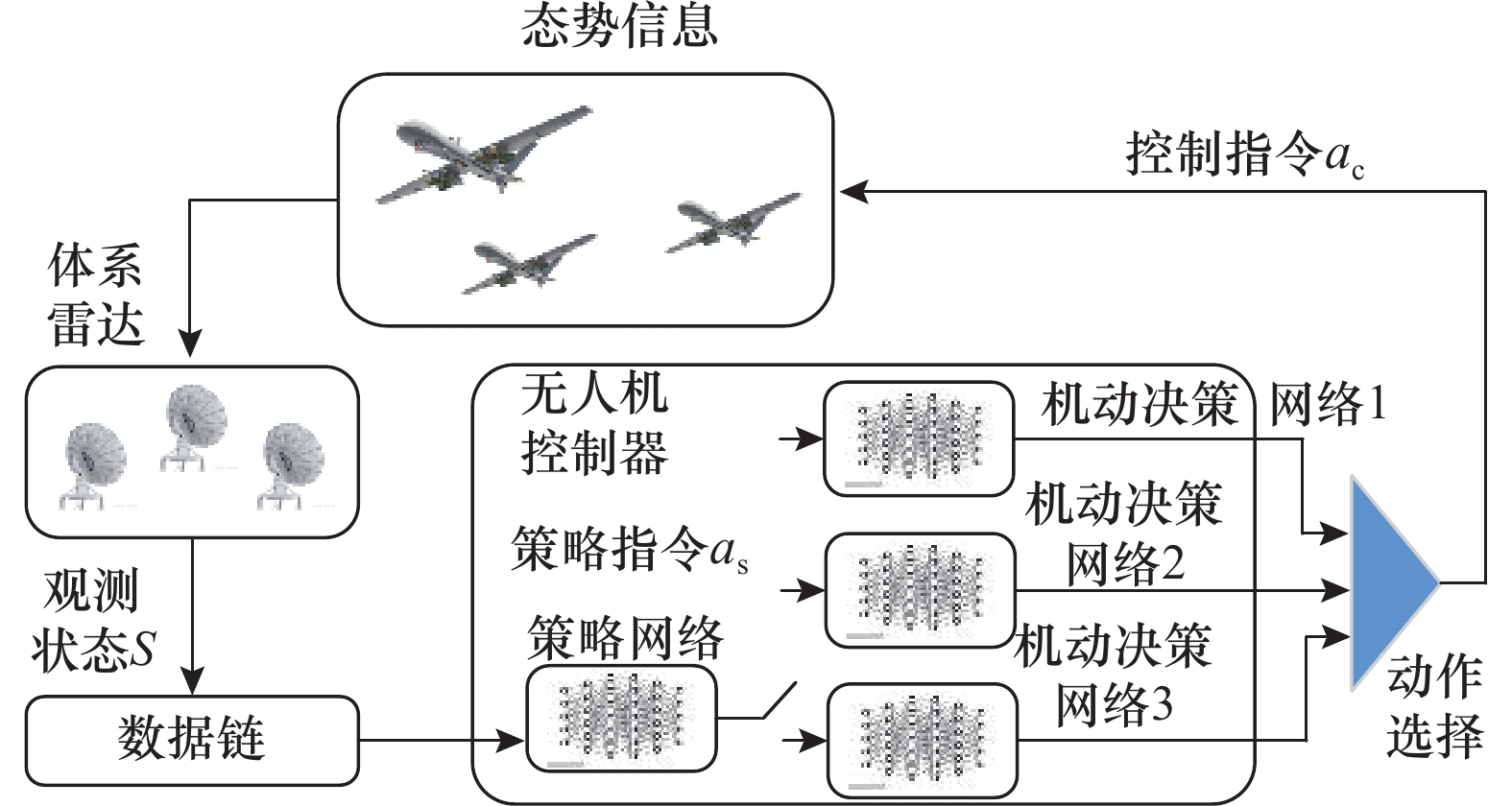
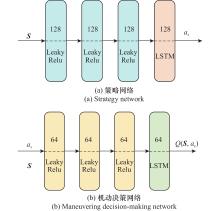
图4
无人机控制器神经网络结构"
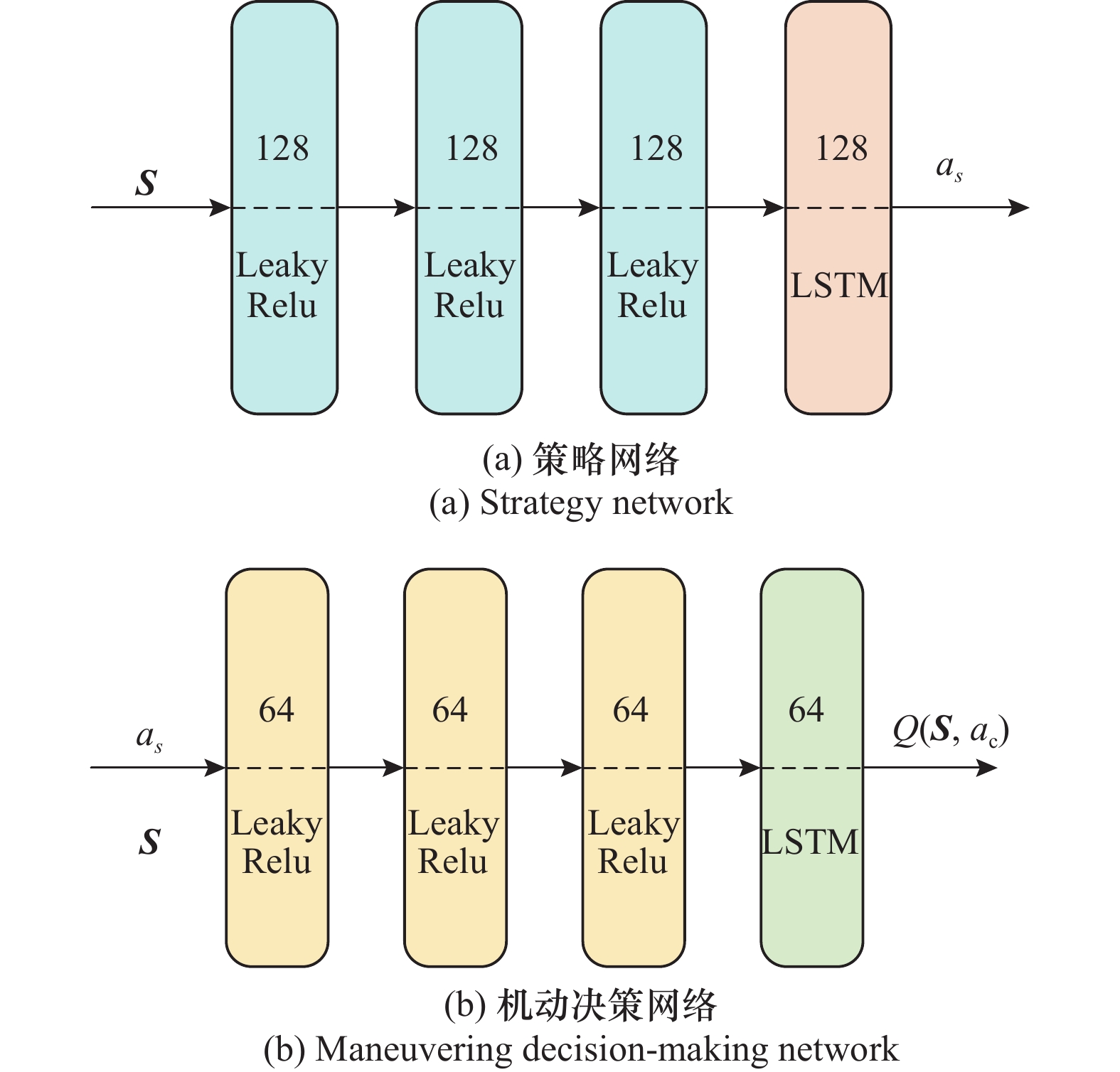
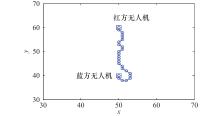
图5
ACO算法生成的Q值估计路径"
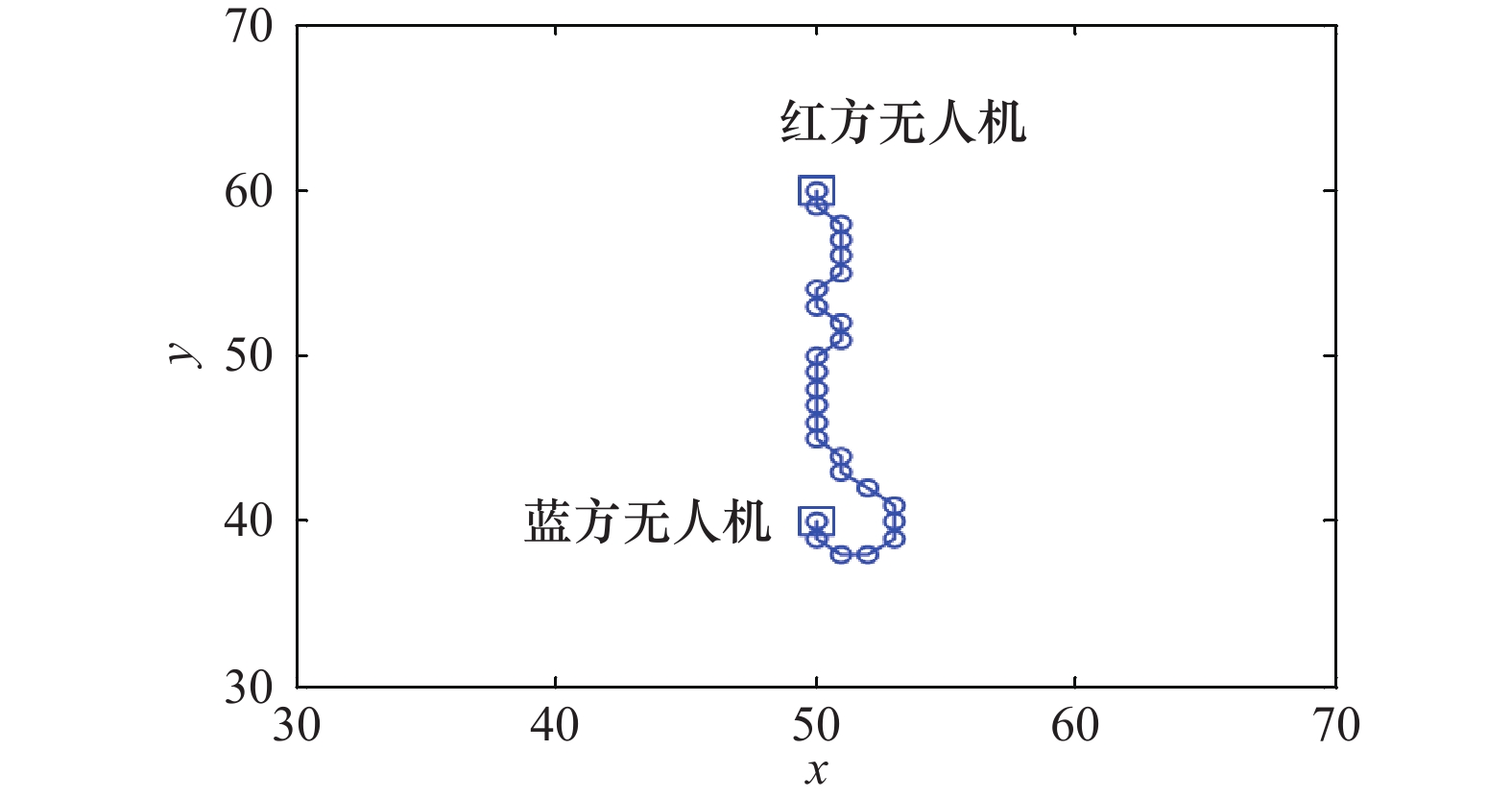
表2
算法参数"
| 参数 | 取值 |
| 80 | |
| 60 | |
| D1 | 16 |
| D2 | 5 |
| D3 | 1 |
| 0.9 | |
| 策略网络学习率 | 10−4 |
| 动作网络学习率 | 10−6 |
图6
策略网络损失值变化曲线"
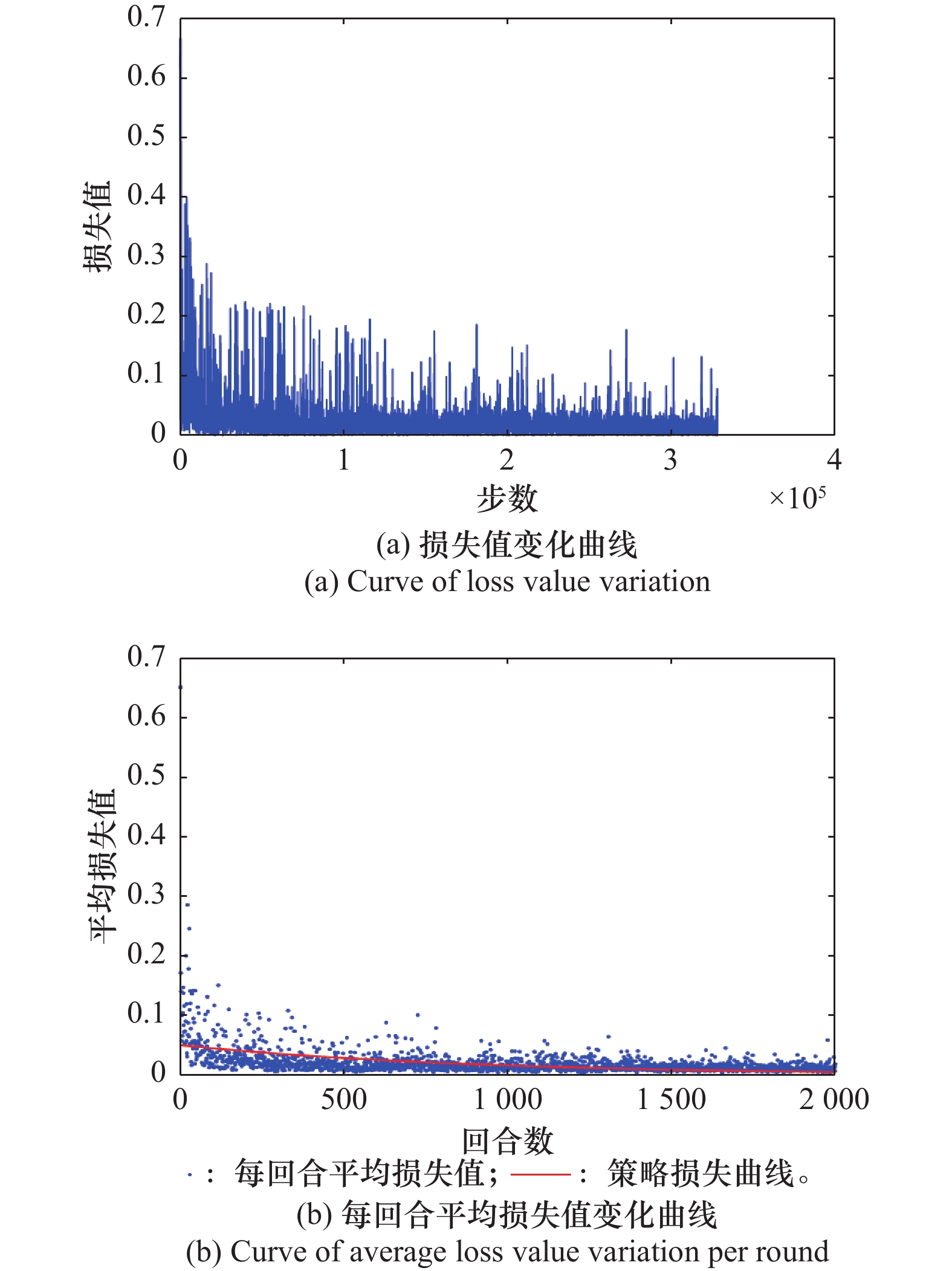
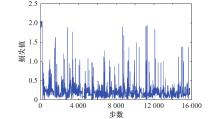
图7
单一深度网络损失函数"
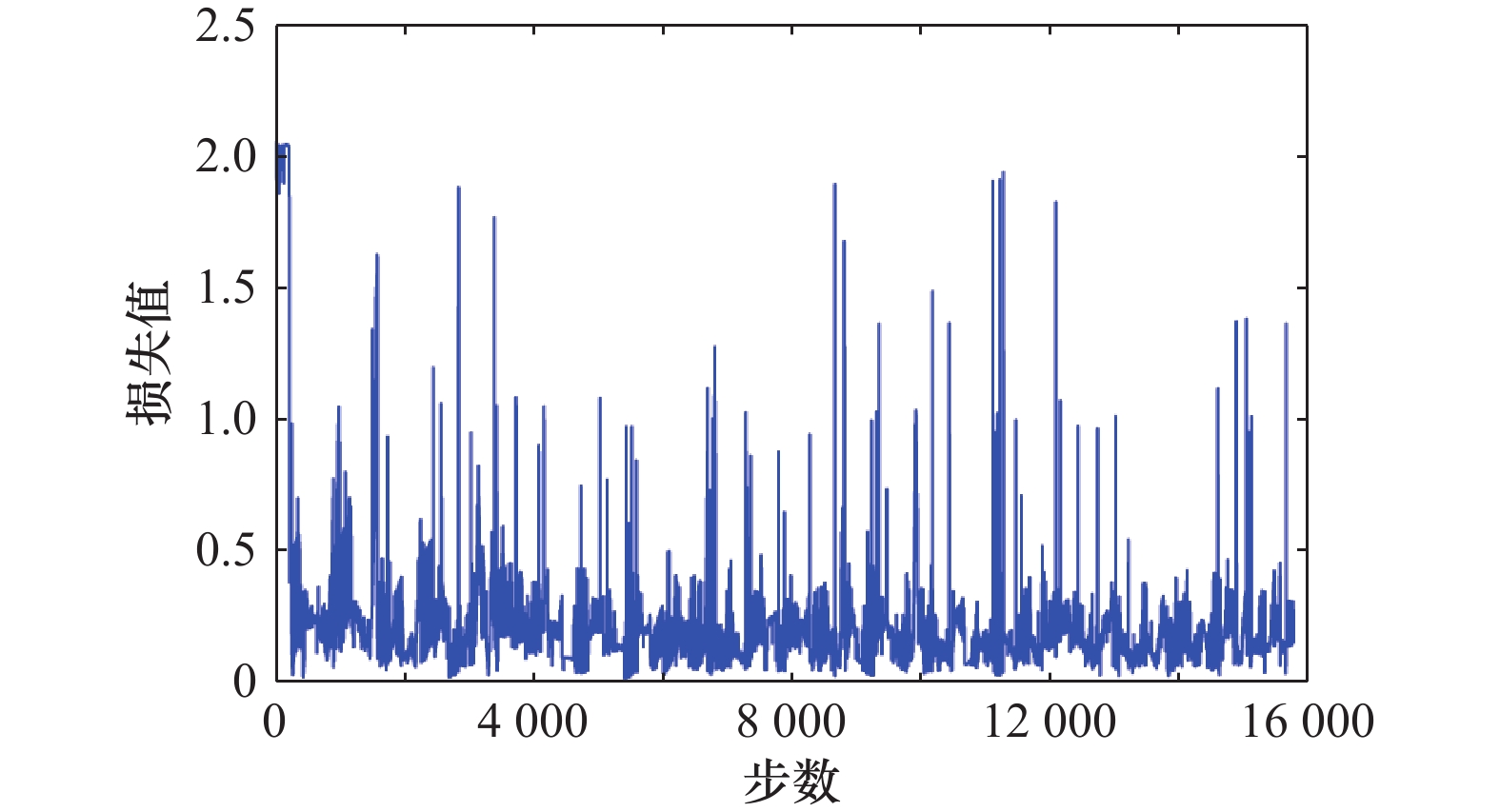
图8
距离机动网络损失值变化曲线"
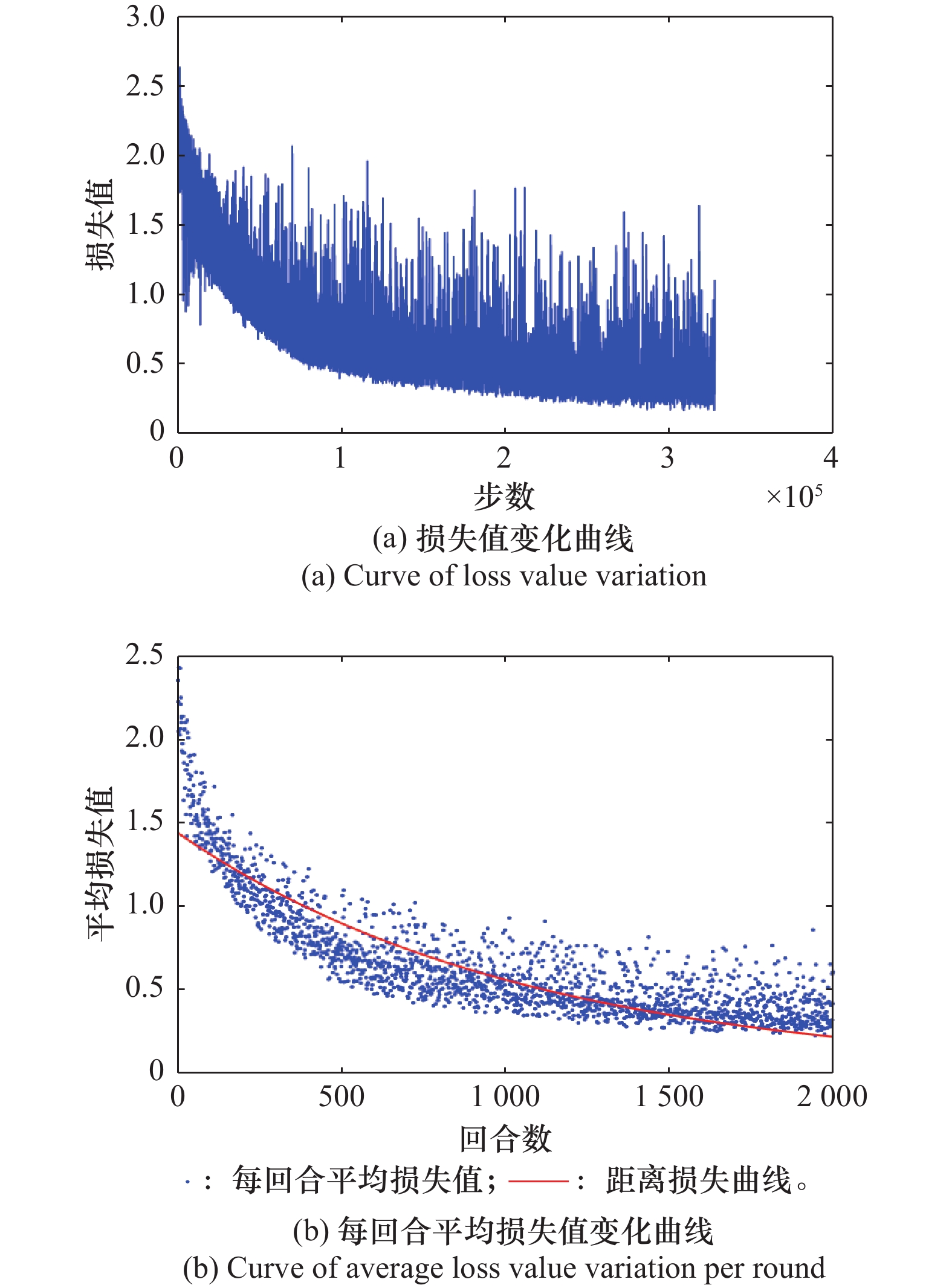
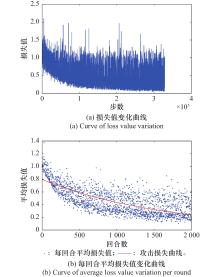
图9
攻击机动网络损失值变化曲线"
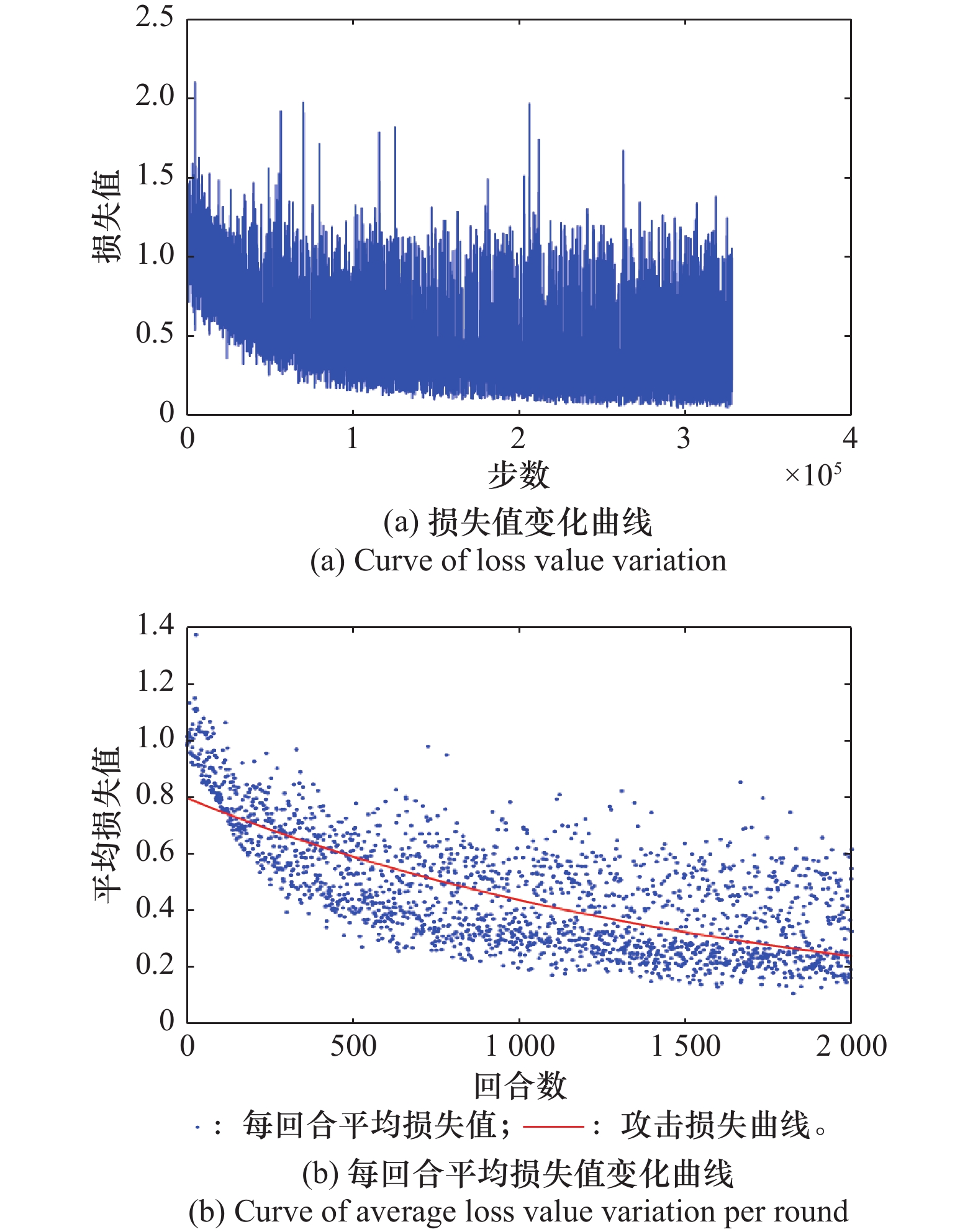
图10
威胁机动网络损失值变化曲线"
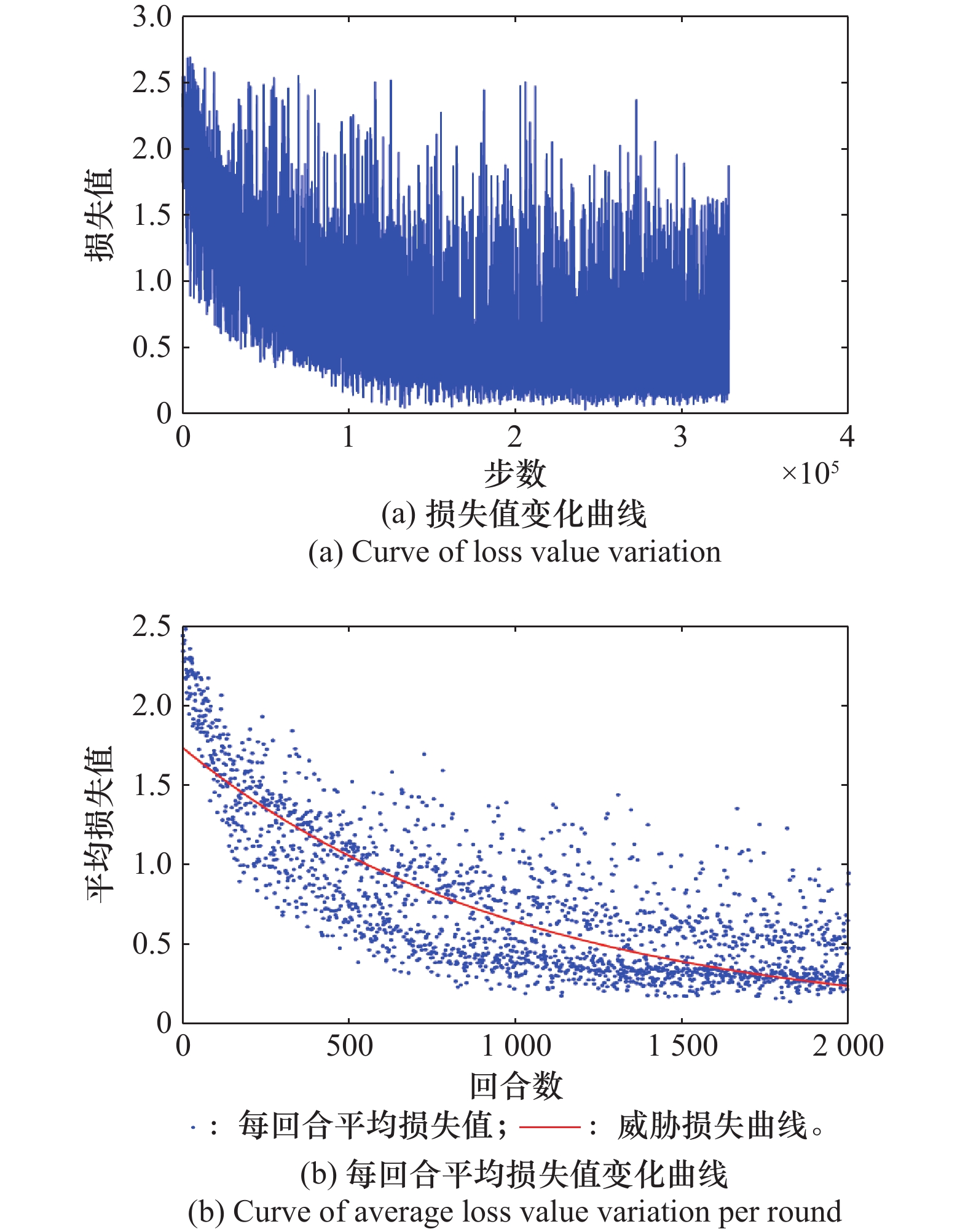
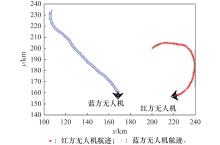
图11
无人机对抗空战过程"
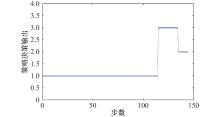
图12
策略网络决策输出"

图13
动作网络决策输出"
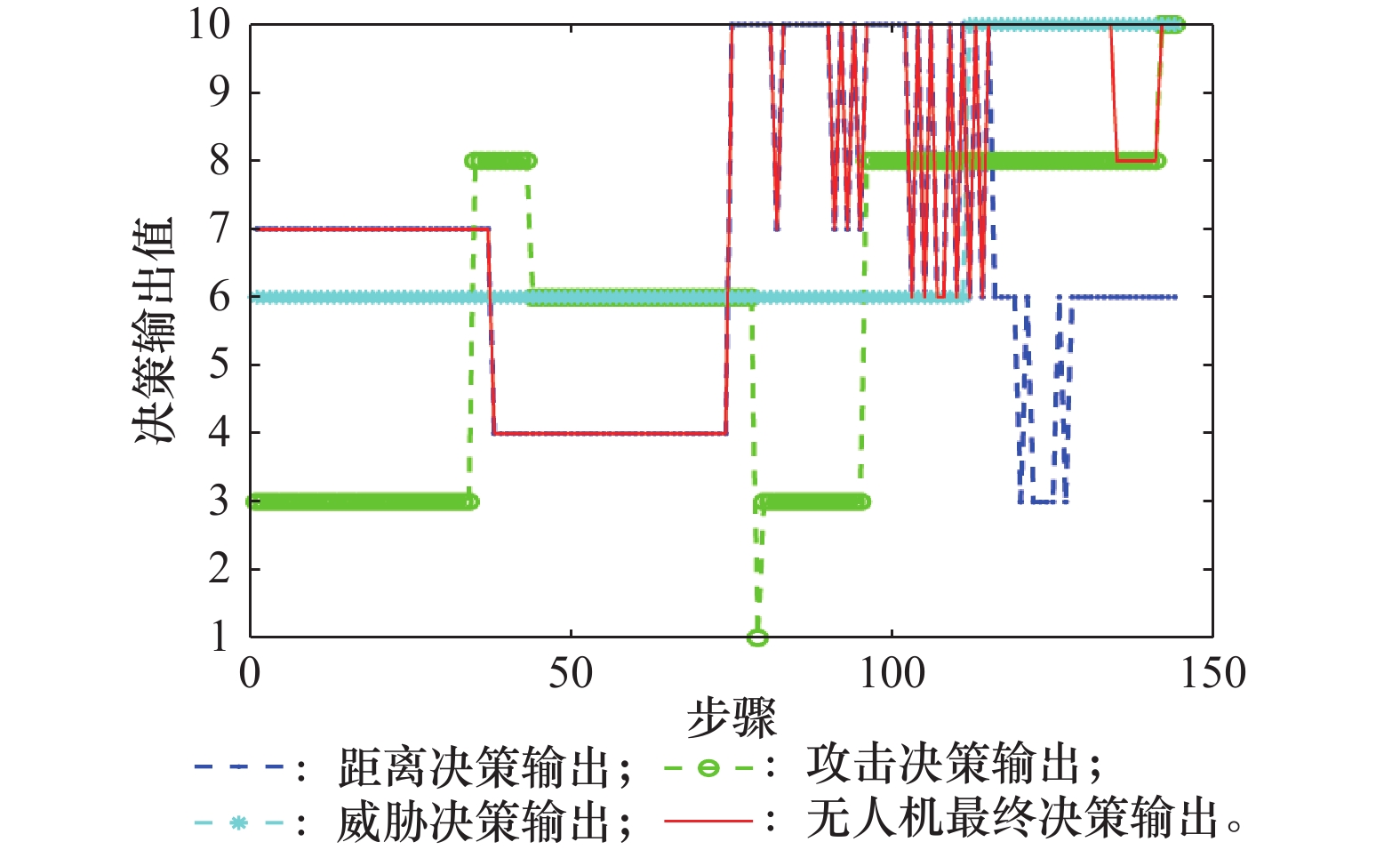
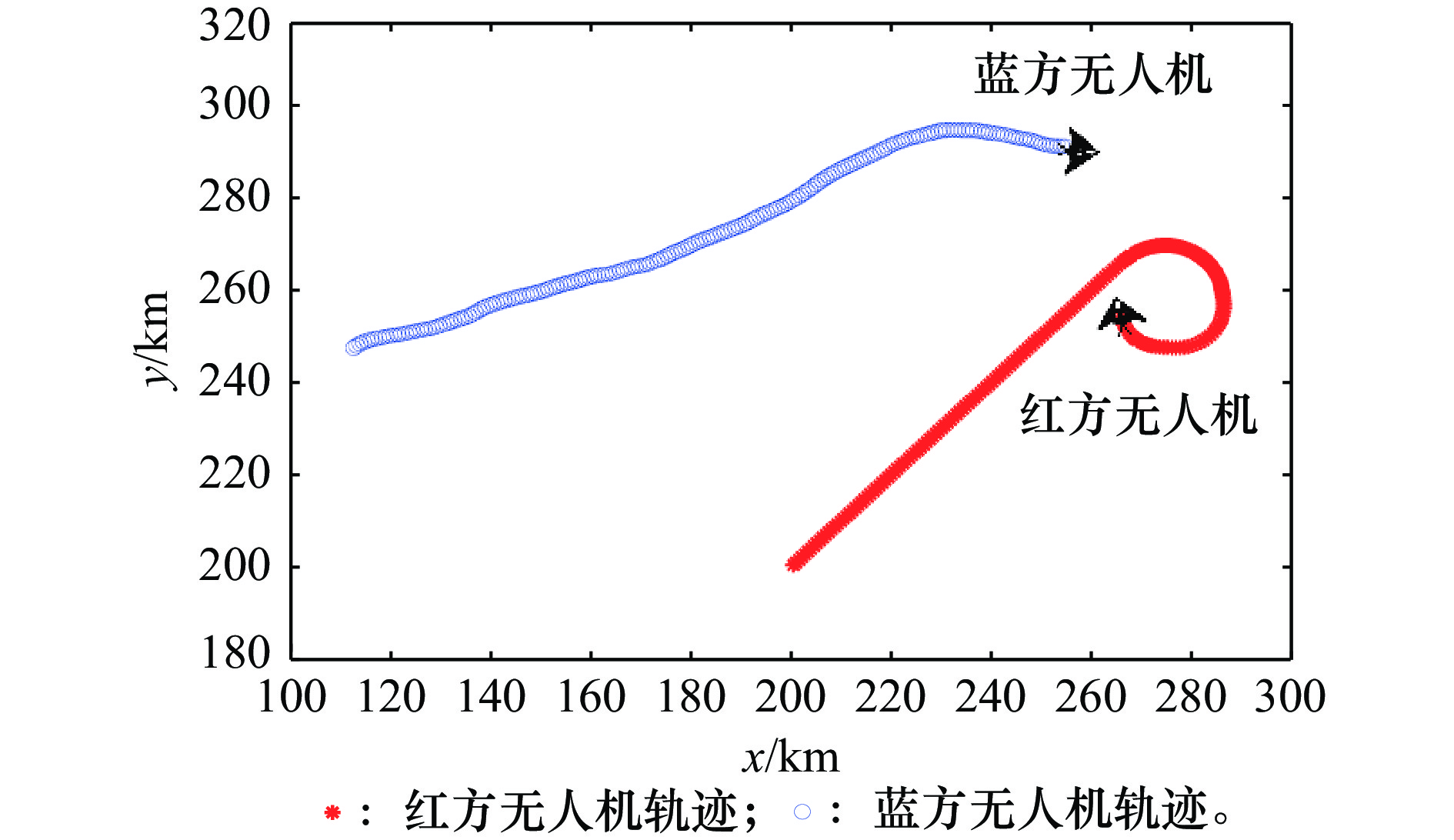
图14
初始态势劣势取胜"
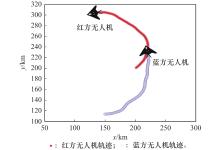
图15
初始态势劣势逃逸"
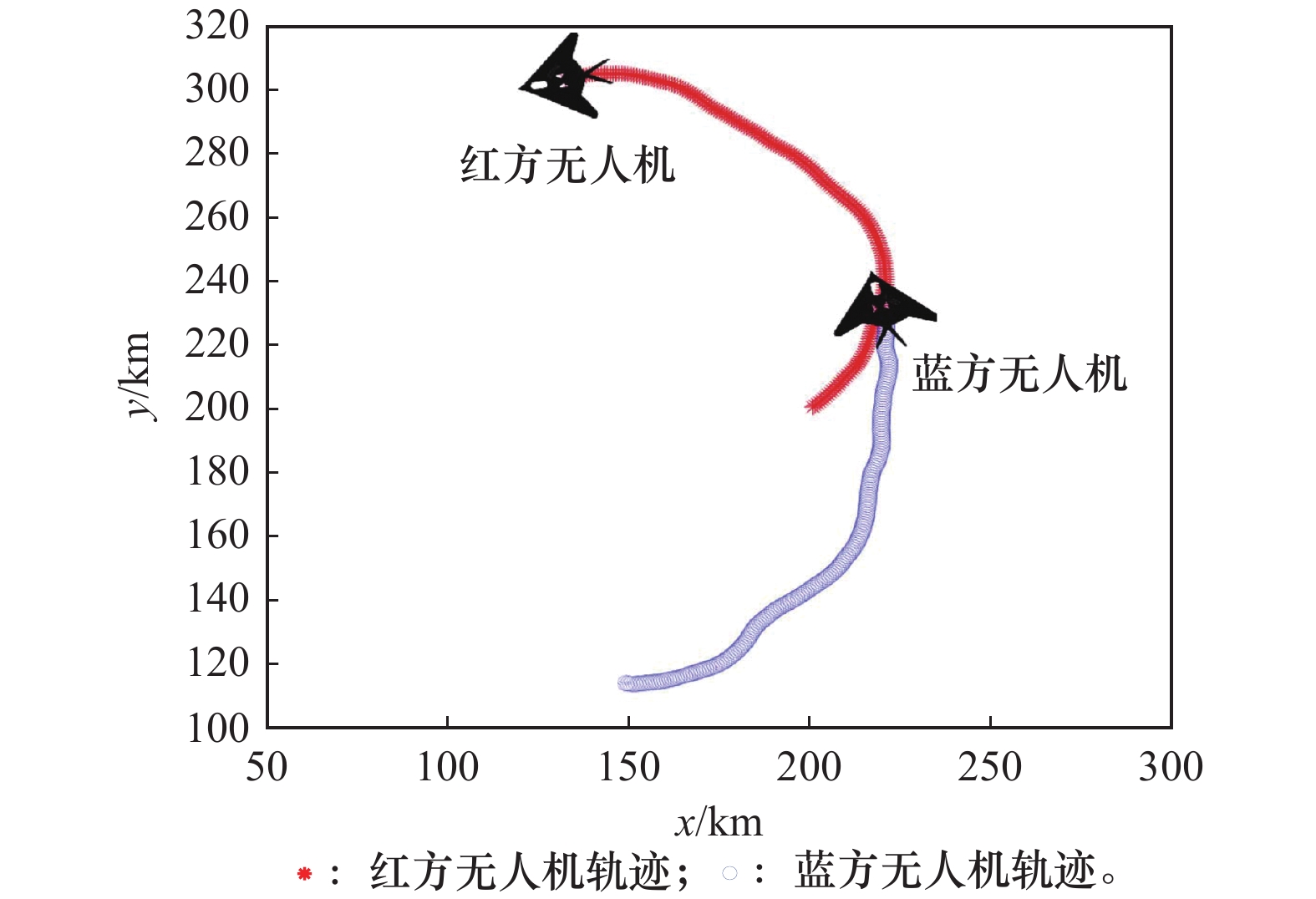
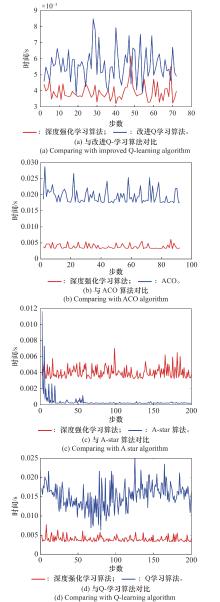
图16
决策时间对比图"

| 1 |
黄长强. 未来空战过程智能化关键技术研究[J]. 航空兵器, 2019, 26 (1): 11- 19.
doi: 10.12132/ISSN.1673-5048.2017.0002 |
|
HUANG C Q. Research on key technology of future air combat process intelligentization[J]. Aero Weaponry, 2019, 26 (1): 11- 19.
doi: 10.12132/ISSN.1673-5048.2017.0002 |
|
| 2 |
谢建峰, 杨啟明, 戴树岭, 等. 基于强化遗传算法的无人机空战机动决策研究[J]. 西北工业大学学报, 2020, 38 (6): 1330- 1338.
doi: 10.3969/j.issn.1000-2758.2020.06.024 |
|
XIE J F, YANG Q M, DAI S L, et al. Air combat maneuver decision based on reinforcement genetic algorithm[J]. Journal of Northwestern Polytechnical University, 2020, 38 (6): 1330- 1338.
doi: 10.3969/j.issn.1000-2758.2020.06.024 |
|
| 3 |
HU D Y, YANG R N, ZUO J L, et al. Application of deep reinforcement learning in maneuver planning of beyond-visual-range air combat[J]. IEEE Access, 2021, 9, 32282- 32297.
doi: 10.1109/ACCESS.2021.3060426 |
| 4 |
韩统, 崔明朗, 张伟, 等. 多无人机协同空战机动决策[J]. 兵器装备工程学报, 2020, 41 (4): 117- 123.
doi: 10.11809/bqzbgcxb2020.04.023 |
|
HAN T, CUI M L, ZHANG W, et al. Multi-UCAV cooperative air combat maneuvering decision[J]. Journal of Ordnance Equipment Engineering, 2020, 41 (4): 117- 123.
doi: 10.11809/bqzbgcxb2020.04.023 |
|
| 5 | 朱星宇, 艾剑良. 多对多无人机空战的智能决策研究[J]. 复旦学报(自然科学版), 2021, 60 (4): 410- 419. |
| ZHU X Y, AI J L. Research on intelligent decision making of many to many unmanned aerial vehicle air combat[J]. Journal of Fudan University (Natural Science), 2021, 60 (4): 410- 419. | |
| 6 | 王宇琨, 王泽, 董力维, 等. 基于分层的智能建模方法的多机空战行为建模[J]. 系统仿真学报, 2023, 35 (10): 2249- 2261. |
| WANG Y K, WANG Z, DONG L W, et al. Research on multi-aircraft air combat behavior modeling based on hierarchical intelligent modeling methods[J]. Journal of System Simulation, 2023, 35 (10): 2249- 2261. | |
| 7 |
牛军锋, 甘旭升, 魏潇龙, 等. 异型无人机空战对抗协同机动决策研究[J]. 指挥与控制学报, 2023, 9 (3): 292- 302.
doi: 10.3969/j.issn.2096-0204.2023.03.0292 |
|
NIU J F, GAN X S, WEI X L, et al. Cooperative maneuver decision-making of antagonistic air combat of special shaped UAV[J]. Journal of Command and Control, 2023, 9 (3): 292- 302.
doi: 10.3969/j.issn.2096-0204.2023.03.0292 |
|
| 8 | 王宏健, 于丹, 徐欣, 等. 非对称博弈下多UUV 基地防卫协同对抗策略[J]. 智能系统学报, 2022, 17 ( 2 ) : 348-359. |
| WANG H J, YU D, XU X, et al. Multi-UUV base defense cooperative countermeasure under the asymmetric game condition[J]. CAAI Transactions on Intelligent Systems, 2022, 17(2): 348–359. | |
| 9 | GREYDANUS S, KOUL A, DODGE J, et al. Visualizing and understanding atari agents[C]//Proc. of the 35th International Conference on Machine Learning, 2018: 1792-1801. |
| 10 | SCHWARZROCK J, ZACARIAS I, BAZZAN A L C, et al. Solving task allocation problem in multi unmanned aerial vehicles systems using swarm intelligence[J]. Engineering Applications of Artificial Intelligence, 2018, 72, 10- 20. |
| 11 | GENG W X, KONG F, MA D Q. Study on tactical decision of UAV medium-range air combat[C]//Proc. of the 26th Chinese Control and Decision Conference, 2014: 135−139. |
| 12 | PIAO H Y, SUN Z X, MENG G L, et al. Beyond-visual range air combat tactics auto-generation by reinforcement learning[C]//Proc. of the International Joint Conference on Neural Networks, 2020. |
| 13 |
ZHANG X B, LIU G Q, YANG C J, et al. Research on air combat maneuver decision-making method based on reinforcement learning[J]. Electronics, 2018, 7 (11): 279.
doi: 10.3390/electronics7110279 |
| 14 | XUAN J Y, LU J, YAN Z, et al. Bayesian deep reinforcement learning via deep kernel learning[J]. International Journal of Computational Intelligence Systems, 2018, 12 (10): 164- 171. |
| 15 | YANG Y O, WANG X Q, HU R Z, et al. APER-DDQN: UAV precise airdrop method based on deep reinforcement learning[J]. IEEE Access, 2022, 10: 50878−50891. |
| 16 | SIHEM O, MILOUD B, JONATHAN P, et al. Deep reinforcement learning based collision avoidance in UAV environment[J]. IEEE Internet of Things Journal, 2022, (9): 4015- 4030. |
| 17 | YANG K, LIU L. An improved deep reinforcement learning algorithm for path planning in unmanned driving[J]. IEEE Access, 2024, 12: 67935−67944. |
| 18 |
HU Z J, GAO X G, WAN K F, et al. Relevant experience learning: a deep reinforcement learning method for UAV autonomous motion planning in complex unknown environments[J]. Chinese Journal of Aeronautics, 2021, 34 (12): 187- 204.
doi: 10.1016/j.cja.2020.12.027 |
| 19 |
ZHAN G, ZHANG K, LI K, et al. UAV maneuvering decision-making algorithm based on deep reinforcement learning under the guidance of expert experience[J]. Journal of Systems Engineering and Electronics, 2024, 35 (3): 644- 665.
doi: 10.23919/JSEE.2024.000022 |
| 20 | 雷毅飞, 王露禾, 贺泊茗, 等. 基于深度强化学习的多无人机空战机动策略研究[J]. 航空科学技术, 2024, 35 (3): 111- 118. |
| LEI Y F, WANG L H, HE B M, et al. Research on multi-UAV air combat maneuver strategy based on deep reinforcement learning[J]. Aeronautical Science & Technology, 2024, 35 (3): 111- 118. | |
| 21 | LI Y, HAN W, WANG Y Q, et al. Deep reinforcement learning with application to air confrontation intelligent decision-making of manned/unmanned aerial vehicle cooperative system[J]. IEEE Access, 2020, 8, 67887- 67898. |
| 22 | LIU X, ZHONG W Z, WANG X, et al. Deep reinforcement learning-based 3D trajectory planning for cellular connected UAV[J]. Drones, 2024, 8(5): 199. |
| 23 | ZHOU K, WEI R X, XU Z F, et al. A brain like air combat learning system inspired by human learning mechanism[C]// Proc. of the IEEE Chinese Guidance, Navigation and Control Conference, 2018. |
| 24 | 王宝来, 高显忠, 谢涛, 等. 基于强化学习与种群博弈的近距空战决策研究[J]. 航空学报, 2024, 45(12): 329446. |
| WANG B L, GAO X Z, XIE T, et al. Research on decision-making in close-range air combat based on reinforcement learning and population game[J]. Acta Aeronautica et Astronautica Sinica: 2024, 45(12): 329446. | |
| 25 | YANG Q M, ZHANG J D, SHI G Q, et al. Maneuver decision of UAV in short-range air combat based on deep reinforcement learning[J]. IEEE Access, 2020, 8, 363- 378. |
| 26 | 吕超, 李慕宸, 欧家骏. 基于分层深度强化学习的无人机混合路径规划[EB/OL]. [2024-06-23]. https://doi.org/10.13700/j.bh.1001-5965.2023.0550. |
| LV C, LI M C, OU J J, UAV hybrid path planning based on hierarchical deep reinforcement learning[EB/OL]. [2024-06-23]. https://doi.org/10.13700/j.bh.1001-5965.2023.0550. | |
| 27 | 唐上钦, 谢磊, 王渊, 等. 无人机自主空战战术决策仿真系统设计与实现[J]. 计算机工程与应用, 2022, 58(21): 272−288. |
| TANG S Q, XIE L, WANG Y, et al. Design and implementation of UAV autonomous air combat tactical decision simulation system[J]. Computer Engineering and Applications, 2022, 58(21): 272−288. | |
| 28 | CHEN X H, QI Y H, YIN Y Z, et al. A multi-stage deep reinforcement learning with search-based optimization for air-ground unmanned system navigation[J]. Applied Sciences, 2023, 13(4): 2244. |
| 29 | WEI Y J, ZHANG H P, WANG Y, et al. Autonomous maneuver decision-making through curriculum learning and reinforcement learning with sparse rewards[J]. IEEE Access, 2023, 11: 73543−73555 . |
| 30 | YUE L F, YANG R N, ZUO J L, et al. Unmanned aerial vehicle swarm cooperative decision-making for SEAD mission: a hierarchical multiagent reinforcement learning approach[J]. IEEE Access, 2022, 10: 92177−92191. |
| 31 | HU J W, WANG L H, HU T M, et al. Autonomous maneuver decision making of dual-UAV cooperative air combat based on deep reinforcement learning[J]. Electronics, 2022, 11(3): 467. |
| 32 | 王晓光, 章卫国, 陈伟. 无人机编队超视距空战决策及作战仿真[J]. 控制与决策, 2015, 30 (2): 328- 334. |
| WANG X G, ZHANG W G, CHEN W. BVR air combat decision making and simulation for UAV formation[J]. Control and Decision, 2015, 30 (2): 328- 334. | |
| 33 |
周攀, 黄江涛, 章胜, 等. 基于深度强化学习的智能空战决策与仿真[J]. 航空学报, 2023, 44 (4): 126731.
doi: 10.7527/S1000-6893.2022.26731. |
|
ZHOU P, HUANG J T, ZHANG S, et al. Research on UAV intelligent air combat decision and simulation based on deep reinforcement learning[J]. Acta Aeronautica et Astronautica Sinica, 2023, 44 (4): 126731.
doi: 10.7527/S1000-6893.2022.26731. |
|
| 34 | 杨书恒, 张栋, 熊威, 等. 基于可解释性强化学习的空战机动决策方法[J]. 航空学报, 2024, 45(18): 329922. |
| YANG S H, ZHANG D, XIONG W, et al. A decision-making method for air combat maneuver based on explainable reinforcement learning[J]. Acta Aeronautica et Astronautica Sinica, 2024, 45(18): 329922. | |
| 35 | 陈蔼祥. 深度学习[M]. 北京: 清华大学出版社, 2020. |
| CHEN A X. Deep learning[M]. Beijing: Tsinghua University Press, 2020. | |
| 36 | WANG L, LUO C M, LI M C, et al. Trajectory planning of an autonomous mobile robot by evolving ant colony system[J]. International Journal of Robotics and Automation, 2017, 32 (4): 112- 121. |
| 37 | MA X X, LIU C. Improved ant colony algorithm for the split delivery vehicle routing problem[J]. Applied Sciences, 2024, 14(12): 5090 . |
| 38 |
姚培源, 魏潇龙, 俞利新, 等. 基于Q-Learning算法的无人机空战机动决策研究[J]. 电光与控制, 2023, 30 (5): 16- 22.
doi: 10.3969/j.issn.1671-637X.2023.05.004 |
|
YAO P Y, WEI X L, YU L X, et al. Research on UAV air combat maneuver decision based on Q-learning algorithm[J]. Electronics Optics & Control, 2023, 30 (5): 16- 22.
doi: 10.3969/j.issn.1671-637X.2023.05.004 |
| [1] | 闻雯, 时晨光, 周建江. 多元威胁环境下无人机集群隐身航迹规划算法[J]. 系统工程与电子技术, 2025, 47(9): 2971-2984. |
| [2] | 张欣悦, 吴晓莉, 王名珺, 晏彪, 武愈涵. 有/无人机协同操作界面的最佳交互方式评估[J]. 系统工程与电子技术, 2025, 47(8): 2600-2611. |
| [3] | 李延通, 李子璠, 周姗姗, 张闯. 无人机光伏电站巡检双目标选址-路径问题研究[J]. 系统工程与电子技术, 2025, 47(8): 2612-2621. |
| [4] | 羊钊, 胡锦标, 王艳, 齐洪彪. 考虑异巢起降的无人机山地巡检覆盖路径规划[J]. 系统工程与电子技术, 2025, 47(8): 2622-2631. |
| [5] | 闫小伟, 凌冲, 石胜斌. 地表未爆子弹药快速检测系统设计与实现[J]. 系统工程与电子技术, 2025, 47(8): 2639-2645. |
| [6] | 张晓璐, 陈亚洲, 赵敏. 无人机数据链带内电磁干扰效应预测模型与验证[J]. 系统工程与电子技术, 2025, 47(8): 2763-2773. |
| [7] | 符小卫, 王辛夷, 乔哲. 基于APIQ算法的多无人机攻防对抗策略[J]. 系统工程与电子技术, 2025, 47(7): 2205-2215. |
| [8] | 朱运豆, 孙海权, 胡笑旋. 基于指针网络架构的多星协同成像任务规划方法[J]. 系统工程与电子技术, 2025, 47(7): 2246-2255. |
| [9] | 郑凯文, 杜承泽, 赵兴芳, 逄晓凡. 融合时空散列的三维RRT*多编队航路规划[J]. 系统工程与电子技术, 2025, 47(7): 2256-2266. |
| [10] | 吴北苹, 何晶, 党慧莹, 岳地久. 基于作战环的反无人机作战体系贡献率评估[J]. 系统工程与电子技术, 2025, 47(7): 2267-2274. |
| [11] | 林思颖, 郁丰, 熊智, 吴方, 周紫君. 基于AHRS的GNSS间断拒止下低成本无人机导航方法[J]. 系统工程与电子技术, 2025, 47(7): 2329-2338. |
| [12] | 唐俊超, 胡春鹤. 三维地形风场环境下无人机全覆盖路径规划[J]. 系统工程与电子技术, 2025, 47(7): 2349-2356. |
| [13] | 何云风, 史贤俊, 卢建华, 赵超轮, 赵国荣. 故障条件下基于同步DMPC的多无人机分组编队控制[J]. 系统工程与电子技术, 2025, 47(7): 2357-2370. |
| [14] | 符小卫, 王辛夷, 乔哲. 基于ASDDPG算法的多无人机对抗策略[J]. 系统工程与电子技术, 2025, 47(6): 1867-1879. |
| [15] | 孟麟芝, 孙小涓, 胡玉新, 高斌, 孙国庆, 牟文浩. 面向卫星在轨处理的强化学习任务调度算法[J]. 系统工程与电子技术, 2025, 47(6): 1917-1929. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||