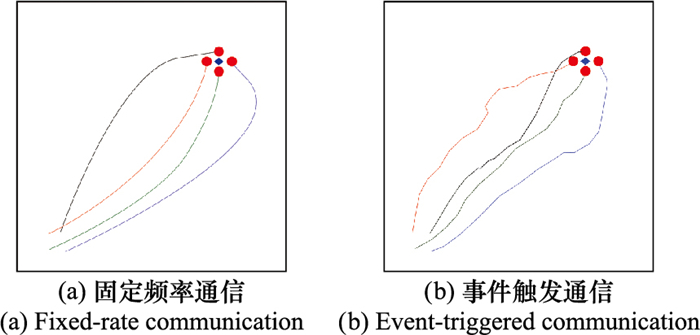
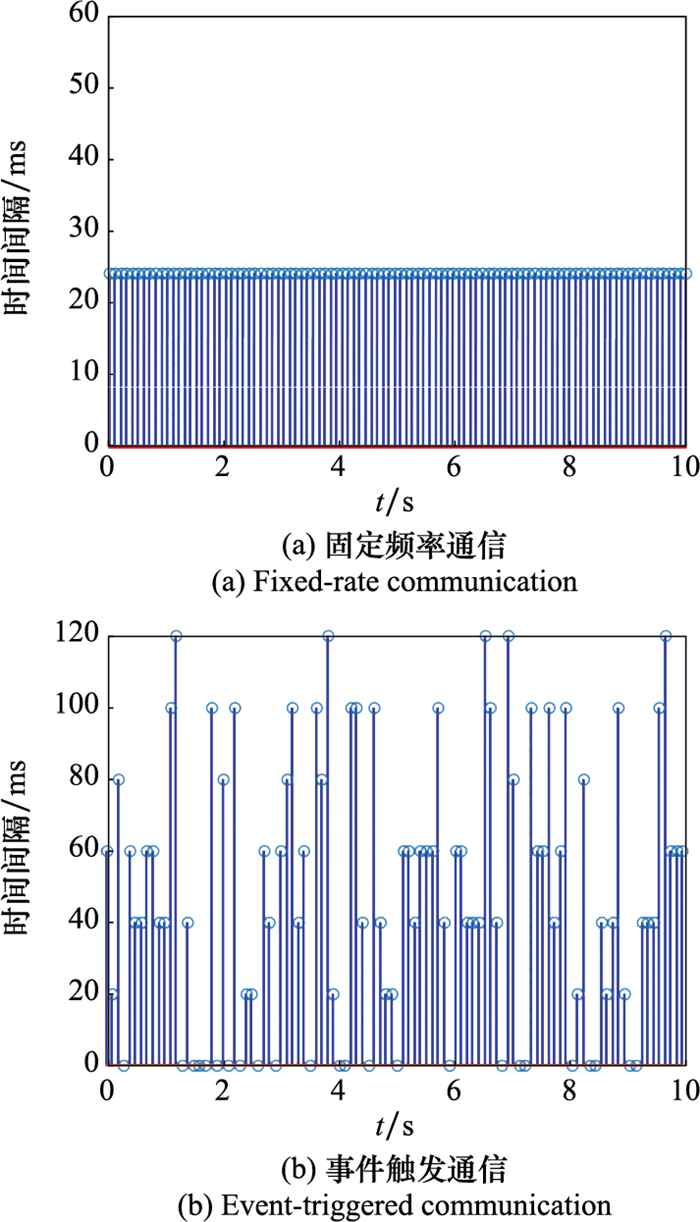
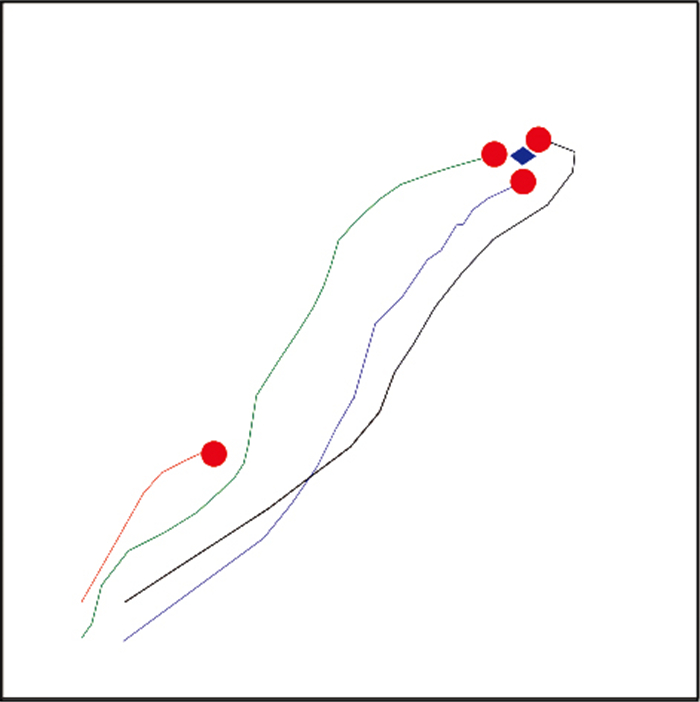
| 14 |
ZHOU T , LIU Q L , WANG D , et al. Leader-following consensus for linear multi-agent systems based on integral-type event-triggered strategy[J]. Control and Decision, 2022, 37 (5): 1258- 1266.
|
| 15 |
王浩亮, 柴亚星, 王丹, 等. 基于事件触发机制的多自主水下航行器协同路径跟踪控制[J]. 自动化学报, 2022, 45 (2): 1001- 1011.
|
|
WANG H L , CHAI Y X , WANG D , et al. Event-triggered cooperative path following of multiple autonomous underwater vehicles[J]. Acta Automatica Sinica, 2022, 45 (2): 1001- 1011.
|
| 16 |
陈世明, 邵赛, 姜根兰. 基于事件触发二阶多智能体系统的固定时间比例一致性[J]. 自动化学报, 2022, 48 (1): 261- 270.
|
|
CHEN S M , SHANG S , JIANG G L . Distributed event-triggered fixed-time scaled consensus control for second-order multi-agent systems[J]. Acta Automatica Sinica, 2022, 48 (1): 261- 270.
|
| 17 |
PENG C , LI F Q . A survey on recent advances in event-triggered communication and control[J]. Information Sciences, 2018, 457 (8): 113- 125.
|
| 18 |
HUTTENRAUCH M , SOSIC A , NEUMANN G . Deep reinforcement learning for swarm systems[J]. Journal of Machine Learning Research, 2019, 20 (54): 1- 31.
|
| 19 |
WANG Z F , GAO Y B , LIU Y F , et al. Distributed dynamic event-triggered communication and control for multi-agent consensus: a hybrid system approach[J]. Information Sciences, 2022, 618 (12): 191- 208.
|
| 20 |
RYU H C, SHIN H Y, PARK J K. Multi-agent actor-critic with hierarchical graph attention network[C]//Proc.of the 34th AAAI Conferenceon Artificial Intelligence, 2020: 7236-7243.
|
| 21 |
ZHU X D , ZHANG F , LI H . Swarm deep reinforcement learning for robotic manipulation[J]. Procedia Computer Science, 2022, 198 (12): 472- 479.
|
| 22 |
LOWE R, WU Y, TAMAR A, et al. Multi-agent actor-critic for mixed cooperative-competitive environments[C]//Proc.of the 31st International Conference on Neural Information Processing Systems, 2017: 6382-6393.
|
| 1 |
张梦钰, 豆亚杰, 陈子夷, 等. 深度强化学习及其在军事领域中的应用综述[J]. 系统工程与电子技术, 2024, 46 (4): 1297- 1308.
doi: 10.12305/j.issn.1001-506X.2024.04.18
|
|
ZHANG M Y , DOU Y J , CHEN Z Y , et al. Deep reinforcement learning and its applications in military field[J]. Systems Engineering and Electronics, 2024, 46 (4): 1297- 1308.
doi: 10.12305/j.issn.1001-506X.2024.04.18
|
| 2 |
费博雯, 包卫东, 刘大千, 等. 面向动态目标搜索与打击的空地协同自主任务分配方法[EB/OL].[2023-05-11].http://kns.cnki.net/kcms/detail/11.2422.TN.20221228.1702.020.html.
|
|
FEI B W, BAO W D, LIU D Q, et al. Air-ground cooperative autonomous task allocation method for dynamic target search and strike[EB/OL].[2023-05-11]. http://kns.cnki.net/kcms/detail/11.2422.TN.20221228.1702.020.html.
|
| 3 |
ZHANG Z, WANG X H, ZHANG Q R, et al. Multi-robot cooperative pursuit via potential field-enhanced reinforcement learning[C]//Proc.of the International Conference on Robotics and Automation, 2022: 8808-8814.
|
| 4 |
OLSEN T, STIFFLER N M, O’KANE J M. Rapid recovery from robot failures in multi-robot visibility-based pursuit-evasion[C]//Proc.of the IEEE/RSJ International Conference on Intelligent Robots and Systems, 2021: 9734-9741.
|
| 5 |
BAUMANN D, ZHU J J, MARTIUS G, et al. Deep reinforcement learning for event-triggered control[C]//Proc.of the IEEE Conference on Decision and Control, 2018: 943-950.
|
| 6 |
HU G Z , ZHU Y H , ZHAO D B , et al. Event-triggered communication network with limited-bandwidth constraint for multi-agent reinforcement learning[J]. IEEE Trans. on Neural Networks and Learning Systems, 2021, 34 (8): 3966- 3978.
|
| 7 |
OTTE M , KUHLMAN M , SOFGE D . Competitive target search with multi-agent teams: symmetric and asymmetric communication constraints[J]. Autonomous Robots, 2018, 42 (6): 1207- 1230.
doi: 10.1007/s10514-017-9687-0
|
| 8 |
DENG C , WEN C Y , WANG W , et al. Distributed adaptive tracking control for high-order nonlinea multiagent systems over event-triggered communication[J]. IEEE Trans. on Automatic Control, 2023, 68 (2): 1176- 1183.
doi: 10.1109/TAC.2022.3148384
|
| 9 |
WANG Z J , YANG G , SU X S , et al. Ouijabots: omnidirectional robots for cooperative object transport with rotation control using no communication[J]. Distributed Autonomous Robotic Systems, 2018, 6, 117- 131.
|
| 23 |
FUNK N , BAUMANN D , BERENZ V , et al. Learning event-triggered control from data through joint optimization[J]. IFAC Journal of Systems and Control, 2021, 16 (6): 100144- 100161.
|
| 24 |
FOERSTER J, FARQUHAR G, AFOURAS T, et al. Counterfactual multi-agent policy gradients[C]//Proc.of the AAAI Conference on Artificial Intelligence, 2018: 2974-2982.
|
| 25 |
MIYAZAKI K, MATSUNAGA N, MURATA K, et al. Formation path learning for cooperative transportation of multiple robots using[C]//Proc.of the 21st International Conference on Control, Automation and Systems, 2021: 1619-1623.
|
| 26 |
GONZÁLEZ-SIERRA J , FLORES-MONTES D , HERNANDEZ-MARTINEZ E G , et al. Robust circumnavigation of a heterogeneous multi-agent system[J]. Autonomous Robots, 2021, 45 (2): 265- 281.
|
| 27 |
CHEN Z Y , NIU B , ZHANG L , et al. Command filtering-based adaptive neural network control for uncertain switched nonlinear systems using event-triggered communication[J]. International Journal Robust Nonlinear Control, 2022, 32 (11): 6507- 6522.
doi: 10.1002/rnc.6154
|
| 28 |
MEISTER D , DVRR F , ALLGOWER F . Shared network effects in time-versus event-triggered consensus of a single-integrator multi-agent system[J]. IFAC-Papers Online, 2023, 56 (2): 5975- 5980.
|
| 29 |
HUA M, ZHANG C F, LI Z, et al. Multi-agent deep reinforcement learning for charge-sustaining control of multi-mode hybrid vehicles[EB/OL].[2023-05-11]. https://arxiv.org/abs/2209.02633.
|
| 30 |
OLFATI-SABER R , FAX J A , MURRAY R M . Consensus and cooperation in networked multi-agent systems[J]. Proceedings of the IEEE, 2007, 95 (1): 215- 233.
|
| 10 |
邓甲, 王付永, 刘忠信, 等. 动态事件触发机制下二阶多智能体系统完全分布式控制[J]. 控制理论与应用, 2023, 41 (1): 11- 20.
|
|
DENG J , WANG F Y , LIU Z X , et al. Fully distributed control for second-order multi-agent systems under dynamic event-triggered mechanism[J]. Control Theory & Applications, 2023, 41 (1): 11- 20.
|
| 11 |
黄兵, 肖云飞, 冯元, 等. 无人艇全分布式动态事件触发编队控制[J]. 控制理论与应用, 2023, 40 (8): 1479- 1487.
|
|
HUANG B , XIAO Y F , FENG Y , et al. Fully distributed dyna-mic event-triggered formation control for multiple unmanned surface vehicles[J]. Control Theory & Applications, 2023, 40 (8): 1479- 1487.
|
| 12 |
ZUO R W , LI Y H , LYU M . Learning-based distributed containment control for hfv swarms under event-triggered communication[J]. IEEE Trans. on Aerospace and Electronic Systems, 2023, 59 (1): 568- 579.
doi: 10.1109/TAES.2022.3185969
|
| 13 |
HIRCHE S . Distributed control for cooperative manipulation with event-triggered communication[J]. IEEE Trans. on Robotics, 2020, 36 (4): 1038- 1052.
doi: 10.1109/TRO.2020.2973096
|
| 14 |
周托, 刘全利, 王东, 等. 积分事件触发策略下的线性多智能体系统领导跟随一致性[J]. 控制与决策, 2022, 37 (5): 1258- 1266.
|