Systems Engineering and Electronics ›› 2025, Vol. 47 ›› Issue (6): 1867-1879.doi: 10.12305/j.issn.1001-506X.2025.06.15
• Systems Engineering • Previous Articles Next Articles
Confront strategy of multi-unmanned aerial vehicle based on ASDDPG algorithm
Xiaowei FU, Xinyi WANG, Zhe QIAO
- School of Electronics and Information, Northwestern Polytechnical University, Xi'an 710129, China
-
Received:2024-03-05Online:2025-06-25Published:2025-07-09 -
Contact:Xiaowei FU
CLC Number:
Cite this article
Xiaowei FU, Xinyi WANG, Zhe QIAO. Confront strategy of multi-unmanned aerial vehicle based on ASDDPG algorithm[J]. Systems Engineering and Electronics, 2025, 47(6): 1867-1879.
share this article
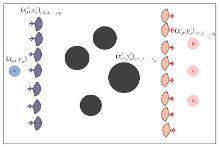
Fig.1
Schematic diagram of the multi-unmanned aerial vehicle confrontation scenario"
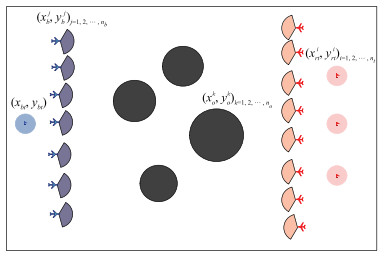
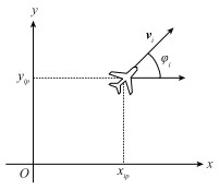
Fig.2
Two dimensional motion model of unmanned aerial vehicle"
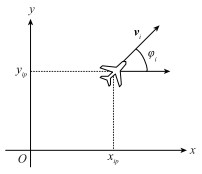
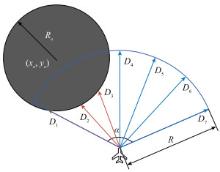
Fig.3
Situation of obstacle detection by unmanned aerial vehicle radar"
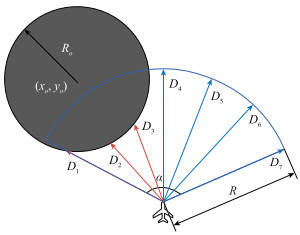
Fig.4
Computation flow of unmanned aerial vehicle radar detection data"
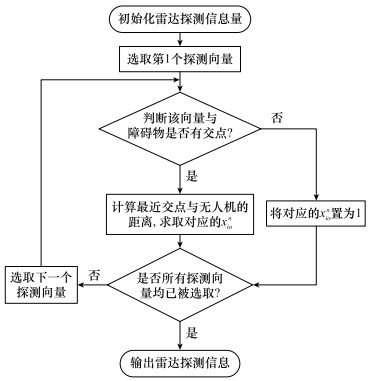
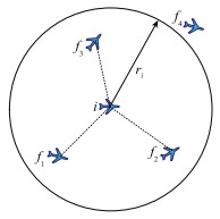
Fig.5
Schematic diagram of unmanned aerial vehicle-to- unmanned aerial vehicle communication"
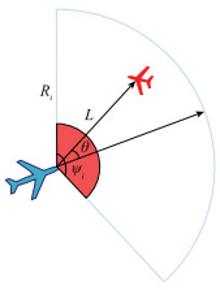
Fig.6
Schematic diagram of damage analysis"
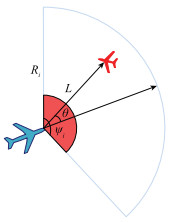
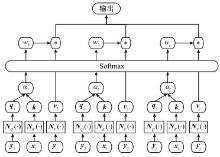
Fig.7
State processing flow based on attention network"
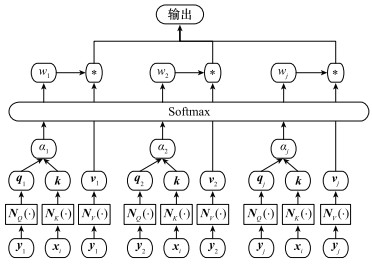
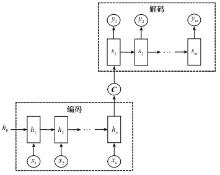
Fig.8
Encoding and decoding model framework"
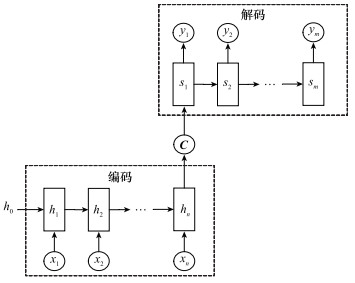
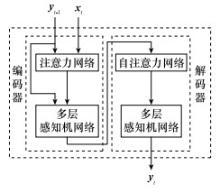
Fig.9
Network of past state information extraction"
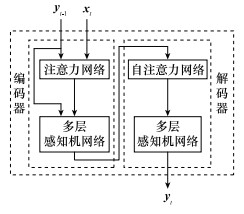
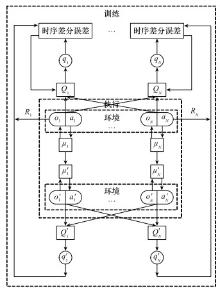
Fig.10
Network structure of MADDPG algorithm"
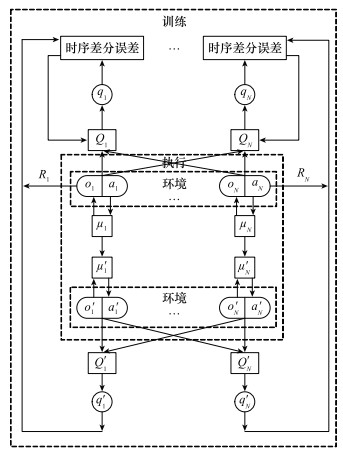
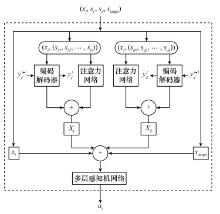
Fig.11
Structure of the Actor network"
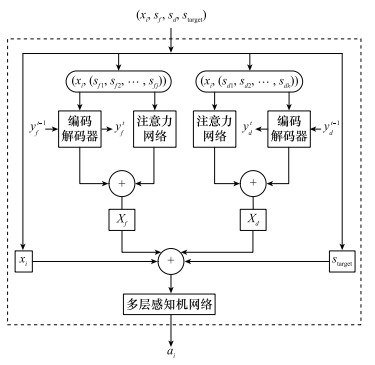
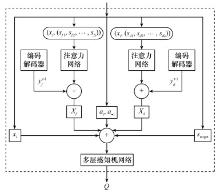
Fig.12
Structure of Critic network"

Table 1
Property parameters of environment and unmanned aerial vehicle"
| 环境和无人机属性 | 参数 |
| 战场范围(xmin, xmax, ymin, ymax)/km | 0, 100, 0, 80 |
| 障碍物数量 | 8 |
| 障碍物区域半径及数量/km | 4(2个), 5(3个), 6(3个) |
| 障碍物随机生成区域/km | [15, 85]×[15, 65] |
| 红蓝两方无人机数量 | 10~10或15~15 |
| 红方无人机雷达探测范围(火力打击范围)半径/km | 6 |
| 红方无人机雷达探测角度范围(火力打击角度范围)/(°) | 120 |
| 蓝方无人机雷达探测范围(火力打击范围)半径/km | 7.5 |
| 蓝方无人机雷达探测角度范围(火力打击角度范围)/(°) | 120 |
| 红方无人机最大速度/(m/s) | 340 |
| 蓝方无人机最大速度/(m/s) | 340 |
| 红方无人机最大角速度/(rad/s) | π/22.6 |
| 蓝方无人机最大角速度/(rad/s) | π/15.7 |
| 红方无人机的位置随机生成区域/km | [90, 100]×[0, 80] |
| 蓝方无人机的位置随机生成区域/km | [0, 10]×[0, 80] |
| 红方无人机初始航向角/rad | π |
| 蓝方无人机初始航向角/rad | 0 |
| 红方无人机阵地中心位置及半径/km | [98, 40], 2 |
| 蓝方无人机阵地中心位置及半径/km | [2, 40], 2 |
| 红方无人机信息交流半径/km | 20 |
| 蓝方无人机信息交流半径/km | 20 |
| 无人机碰撞坠毁距离/km | 0.5 |
| 无人机毁伤概率系数 | 0.2 |
| 目标区域半径/km | 2 |
Table 2
Setting of algorithm hyper parameter"
| 算法超参数 | 数值 |
| 最大回合数 | 1 000 |
| 每回合最大步数 | 1 000 |
| 学习率 | 0.000 1 |
| 初始探索率 | 0.1 |
| 软更新率 | 0.01 |
| 折扣因子 | 0.95 |
| 经验池大小 | 50 000 |
| 批采样数量 | 64 |
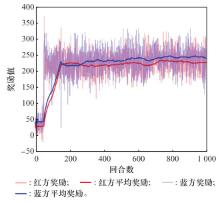
Fig.13
Reward curve of ASDDPG algorithm"
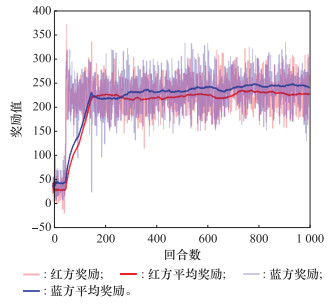
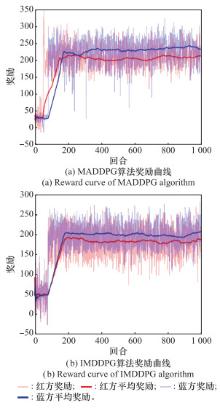
Fig.14
Reward curve of other algorithms"
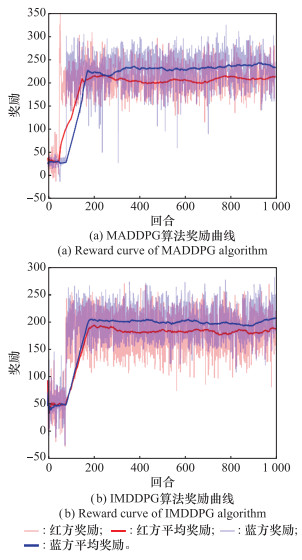
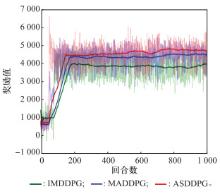
Fig.15
Curve of training rewards for multi-unmanned aerial vehicle attack-defense confrontation"
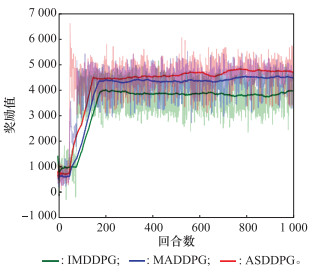
Table 3
Data comparison of training process of three algorithms"
| 算法 | 在300回合时的奖励值 | 300到1 000回合的平均奖励值 | 训练时奖励所达到的平均奖励峰值 |
| IMDDPG | 3 868.36 | 3 815.73 | 3 953.01 |
| MADDPG | 4 291.34 | 4 382.77 | 4 514.79 |
| ASDDPG | 4 454.19 | 4 624.13 | 4 799.81 |
Table 4
Test results of ASDDPG algorithm in red side %"
| 蓝方算法 | 蓝方成功率 | 红方成功率 |
| IMDDPG算法 | 54.1 | 45.9 |
| MADDPG算法 | 57.4 | 42.6 |
| ASDDPG算法 | 60.2 | 39.8 |
Table 5
Test results of ASDDPG algorithm in blue side %"
| 红方算法 | 红方成功率 | 蓝方成功率 |
| IMDDPG算法 | 34.2 | 65.8 |
| MADDPG算法 | 37.3 | 62.7 |
| ASDDPG算法 | 39.8 | 60.2 |
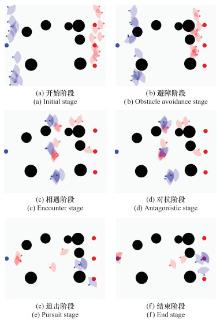
Fig.16
Multi-unmanned aerial vehicle adversarial process of 10v10"
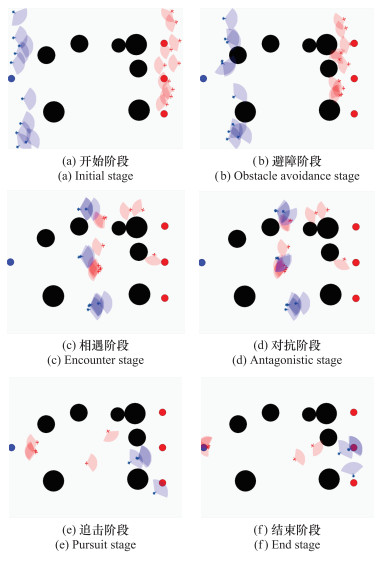

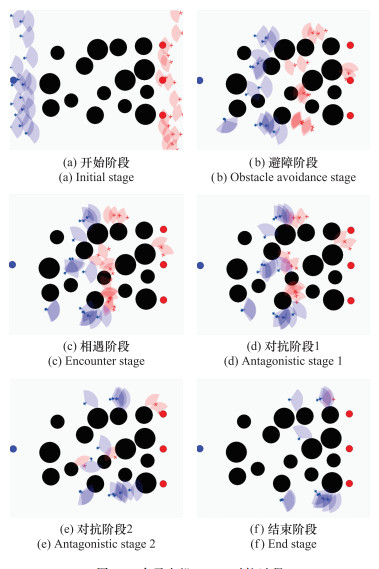
Fig.17
Multi-unmanned aerial vehicle adversarial process of 15v15"
| 1 |
胡延霖, 王翌丞, 于克振. 信息化战争中无人机的作战用途及发展趋势分析[J]. 现代商贸工业, 2010, 22 (2): 242- 243.
doi: 10.3969/j.issn.1672-3198.2010.02.152 |
|
HU Y L , WANG L C , YU K Z . Analysis of operational use and development trend of UAVs in information warfare[J]. Modern Business Trade Industry, 2010, 22 (2): 242- 243.
doi: 10.3969/j.issn.1672-3198.2010.02.152 |
|
| 2 |
CHI P , WEI J H , WU K , et al. A bio-inspired decision-making method of UAV swarm for attack-defense confrontation via multi-agent reinforcement learning[J]. Biomimetics, 2023, 8 (2): 222- 245.
doi: 10.3390/biomimetics8020222 |
| 3 |
SHAHID S , ZHEN Z Y , JAVAID U , et al. Offense-defense distributed decision making for swarm vs. swarm confrontation while attacking the aircraft carriers[J]. Drones, 2022, 6 (10): 271- 291.
doi: 10.3390/drones6100271 |
| 4 | 万华翔, 张雅舰. 蜂群无人机对战场环境的影响及对抗技术研究[J]. 飞航导弹, 2019 (4): 68- 72. |
| WAN H X , ZHANG Y J . Research on the influence of swarm UAV on battlefield environment and countermeasure technology[J]. Aerodynamic Missile Journal, 2019 (4): 68- 72. | |
| 5 | 罗德林, 张海洋, 谢荣增, 等. 基于多agent系统的大规模无人机集群对抗[J]. 控制理论与应用, 2015, 32 (11): 1498- 1504. |
| LUO D L , ZHANG H Y , XIE R Z , et al. Unmanned aerial vehicles swarm conflict based on multi-agent system[J]. Control Theory & Applications, 2015, 32 (11): 1498- 1504. | |
| 6 | DUAN H B , LEI Y Q , XIA J , et al. Autonomous maneuver decision for unmanned aerial vehicle via improved pigeon-inspired optimization[J]. IEEE Trans.on Aerospace and Electronic Systems, 2022, 59 (3): 3156- 3170. |
| 7 |
ZHANG J , XING J H . Cooperative task assignment of multi- UAV system[J]. Chinese Journal of Aeronautics, 2020, 33 (11): 2825- 2827.
doi: 10.1016/j.cja.2020.02.009 |
| 8 |
XU J . Research on key technologies of UAV cluster cooperative system for internet of things applications[J]. Journal of Control and Decision, 2024, 11 (1): 26- 35.
doi: 10.1080/23307706.2022.2089749 |
| 9 | XU J, GUO Q, XIAO L, et al. Autonomous decision-making method for combat mission of UAV based on deep reinforcement learning[C]//Proc. of the IEEE 4th Advanced Information Technology, Electronic and Automation Control Conference, 2019. |
| 10 | DANOY G, BRUST M R, BOUVRY P. Connectivity stability in autonomous multi-level UAV swarms for wide area monitoring[C]//Proc. of the 5th ACM Symposium on Development and Analysis of Intelligent Vehicular Networks and Applications, 2015. |
| 11 |
LIU H Y , WU K , HUANG K H , et al. Optimization of large- scale UAV cluster confrontation game based on integrated evol ution strategy[J]. Cluster Computing, 2024, 27 (1): 515- 529.
doi: 10.1007/s10586-022-03961-0 |
| 12 | WANG B L , LI S G , GAO X Z , et al. Weighted mean field re inforcement learning for large-scale UAV swarm confrontation[J]. Applied Intelligence, 2023, 53 (5): 5274- 5289. |
| 13 |
FU X J , YAN H . Neural network optimal control for tripartite UAV confrontation systems based on fuzzy differential game[J]. Scientific Reports, 2024, 14 (1): 21547- 21571.
doi: 10.1038/s41598-024-71844-y |
| 14 | YANG R C, GAO H B, WU X D, et al. An intention recognition method based on Bayesian network for UAV formation in confrontation[C]//Proc. of the International Conference on Autonomous Unmanned Systems, 2022: 2799-2809. |
| 15 |
JIANG C J , FANG Y , ZHAO P H , et al. Intelligent UAV identity authentication and safety supervision based on behavior modeling and prediction[J]. IEEE Trans.on Industrial Informatics, 2020, 16 (10): 6652- 6662.
doi: 10.1109/TII.2020.2966758 |
| 16 |
LUO D L , FAN Z H , YANG Z Y , et al. Multi-UAV cooperative maneuver decision-making for pursuit-evasion using im proved MADRL[J]. Defence Technology, 2024, 35, 187- 197.
doi: 10.1016/j.dt.2023.11.013 |
| 17 |
YANG M , LIU G J , ZHOU Z Y , et al. Partially observable mean field multi-agent reinforcement learning based on graph attention network for UAV swarms[J]. Drones, 2023, 7 (7): 476- 497.
doi: 10.3390/drones7070476 |
| 18 |
ZHANG T T , CHAI L , WANG S S , et al. Improving autonomous behavior strategy learning in an unmanned swarm system through knowledge enhancement[J]. IEEE Trans.on Reliability, 2022, 71 (2): 763- 774.
doi: 10.1109/TR.2022.3158279 |
| 19 | SHEIKH H U, BOLONI L. Multi-agent reinforcement learn ing for problems with combined individual and team reward[C]// Proc. of the International Joint Conference on Neural Networks, 2020. |
| 20 | VLAHOV B, SQUIRES E, STRICKLAND L, et al. On developing a UAV pursuit-evasion policy using reinforcement learning[C]//Proc. of the 17th IEEE International Conference on Machine Learning and Applications, 2018. |
| 21 | HUO Z X, DAI S L, YUAN M X, et al. A reinforcement learning based multiple strategy framework for tracking a mo-ving target[C]//Proc. of the IEEE/ASME International Conference on Advanced Intelligent Mechatronic, 2020. |
| 22 | ZHU J D , FU X W , QIAO Z . UAVs maneuver decision-ma-king method based on transfer reinforcement learning[J]. Computational Intelligence and Neuroscience, 2022, 2022 (1): 2399796. |
| 23 |
YANG J F , YANG X W , YU T Q . Multi-unmanned aerial ve hicle confrontation in intelligent air combat: a multi-agent deep reinforcement learning approach[J]. Drones, 2024, 8 (8): 382- 399.
doi: 10.3390/drones8080382 |
| 24 |
GONG Z H , XU Y , LUO D L . UAV cooperative air combat maneuvering confrontation based on multi-agent reinforcement learning[J]. Unmanned Systems, 2023, 11 (3): 273- 286.
doi: 10.1142/S2301385023410029 |
| 25 | LIU D , ZONG Q , ZHAGN X Y , et al. Game of drones: intelligent online decision making of multi-UAV confrontation[J]. IEEE Trans.on Emerging Topics in Computational Intelligence, 2024, 8 (2): 2086- 2100. |
| 26 | WANG Z, LIU F, GUO J, et al. UAV swarm confrontation based on multi-agent deep reinforcement learning[C]//Proc. of the 41st Chinese Control Conference, 2022: 4996-5001. |
| 27 | HU S G , RU L , LYU M L , et al. Evolutionary game analysis of behaviour strategy for UAV swarm in communication-constrained environments[J]. IET Control Theory & Applications, 2024, 18 (3): 350- 363. |
| 28 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]//Proc. of the Advances in Neural Information Processing Systems, 2017: 5998-6008. |
| 29 | LOWE R, WU Y I, TAMAR A, et al. Multi-agent actor-critic for mixed cooperative-competitive environments[C]//Proc. of the Advances in Neural Information Processing Systems, 2017: 6379-6390. |
| 30 | RONNEBERGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation[C]//Proc. of the 18th Medical Image Computing and Computer-Assisted Intervention Conference, 2015: 234-241. |
| 31 |
TAMPUU A , MATIISEN T , KODELJA D , et al. Multiagent cooperation and competition with deep reinforcement learning[J]. PloS One, 2017, 12 (4): e0172395.
doi: 10.1371/journal.pone.0172395 |
| [1] | Linzhi MENG, Xiaojuan SUN, Yuxin HU, Bin GAO, Guoqing SUN, Wenhao MU. Reinforcement learning task scheduling algorithm for satellite on-orbit processing [J]. Systems Engineering and Electronics, 2025, 47(6): 1917-1929. |
| [2] | Kangjie ZHENG, Xinyu ZHANG, Weisong WANG, Zhensheng LIU. Intelligent ship dynamic autonomous obstacle avoidance decision based on DQN and rule [J]. Systems Engineering and Electronics, 2025, 47(6): 1994-2001. |
| [3] | Shuhan LIU, Tong LI, Fuqiang LI, Chungang YANG. Intent and situation-dual driven anti-jamming communication mechanism for data link [J]. Systems Engineering and Electronics, 2025, 47(6): 2055-2064. |
| [4] | Zhikang LIN, Longfei SHI, Jialei LIU, Jiazhi MA. Scintillation detection scheduling method of netted radar based on deep Q-learning [J]. Systems Engineering and Electronics, 2025, 47(5): 1443-1452. |
| [5] | Ziyi WANG, Xiongjun FU, Jian DONG, Cheng FENG. Optimization of radar collaborative anti-jamming strategies based on hierarchical multi-agent reinforcement learning [J]. Systems Engineering and Electronics, 2025, 47(4): 1108-1114. |
| [6] | Xiaoyang HE, Xiaolong CHEN, Xiaolin DU, Ningyuan SU, Wang YUAN, Jian GUAN. Classification of maritime micromotion target based on transfer learning in CBAM-Swin-Transformer [J]. Systems Engineering and Electronics, 2025, 47(4): 1155-1167. |
| [7] | Wei XIONG, Dong ZHANG, Zhi REN, Shuheng YANG. Research on intelligent decision-making methods for coordinated attack by manned aerial vehicles and unmanned aerial vehicles [J]. Systems Engineering and Electronics, 2025, 47(4): 1285-1299. |
| [8] | Peng MA, Rui JIANG, Bin WANG, Mengfei XU, Changbo HOU. Strategy reconstruction for resilience against intelligence jamming based on implicit opponent modeling [J]. Systems Engineering and Electronics, 2025, 47(4): 1355-1363. |
| [9] | Jiakuan LI, Bo FENG, Hongliang LIU, Chunmao YE, Jizhou YU. Angle-guided attention-based wideband PD recognition method for aerodynamic targets [J]. Systems Engineering and Electronics, 2025, 47(3): 807-816. |
| [10] | Kaiqiang TANG, Huiqiao FU, Jiasheng LIU, Guizhou DENG, Chunlin CHEN. Hierarchical optimization research of constrained vehicle routing based on deep reinforcement learning [J]. Systems Engineering and Electronics, 2025, 47(3): 827-841. |
| [11] | Xiarong CHEN, Jichao LI, Gang CHEN, Peng LIU, Jiang JIANG. Portfolio of weapon system-of-systems based on heterogeneous information networks [J]. Systems Engineering and Electronics, 2025, 47(3): 855-861. |
| [12] | Ke FU, Hao CHEN, Yu WANG, Quan LIU, Jian HUANG. Uncertainty-based Bayesian policy reuse method [J]. Systems Engineering and Electronics, 2025, 47(2): 535-543. |
| [13] | Xiaolin LIU, Mengjiao GUO, Zhuo LI. Adaptive graph convolutional recurrent network prediction method for flight delay based on Dueling DQN optimization [J]. Systems Engineering and Electronics, 2025, 47(2): 568-579. |
| [14] | Qiang LIU, Haoran SUN, Denghua HU, Shuang ZHANG. Time alignment fusion algorithm based on Vondrak-Cepek combined filtering and attention mechanism weighting [J]. Systems Engineering and Electronics, 2025, 47(2): 673-679. |
| [15] | Xunliang YAN, Kuan WANG, Zijian ZHANG, Peichen WANG. Reentry guidance method based on LSTM-DDPG [J]. Systems Engineering and Electronics, 2025, 47(1): 268-279. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||