Systems Engineering and Electronics ›› 2025, Vol. 47 ›› Issue (2): 535-543.doi: 10.12305/j.issn.1001-506X.2025.02.20
• Systems Engineering • Previous Articles
Uncertainty-based Bayesian policy reuse method
Ke FU, Hao CHEN, Yu WANG, Quan LIU, Jian HUANG
- College of Intelligence Science and Technology, National University of Defense Technology, Changsha 410073, China
-
Received:2023-09-05Online:2025-02-25Published:2025-03-18 -
Contact:Jian HUANG
CLC Number:
Cite this article
Ke FU, Hao CHEN, Yu WANG, Quan LIU, Jian HUANG. Uncertainty-based Bayesian policy reuse method[J]. Systems Engineering and Electronics, 2025, 47(2): 535-543.
share this article

Fig.1
Agent's internal architecture"


Fig.2
Framework of Uncertainty-BPR algorithm"


Fig.3
Soccer game"


Fig.4
Predator-prey game"


Fig.5
Performance models and opponent models numerical visualization in soccer game"


Fig.6
Accuracy of opponent actions reconstruction in soccer game"


Fig.7
Accumulated rewards in soccer game"


Fig.8
Episodic rewards in soccer game"


Fig.9
Recognition accuracy in soccer game"

Table 1
Average recognition accuracy of opponents'strategy in each run (mean ±std) %"
| 实验环境 | BPR+ | Beyes-ToMoP | Deep BPR+ | Uncertainty-BPR |
| 足球游戏 | 84.5±0.0 | 81.8±1.6 | 84.1±0.1 | 87.7±0.1 |
| 追捕游戏 | 90.7±0.1 | 89.7±1.1 | 91.6±0.2 | 92.5±0.2 |

Fig.10
Accumulated rewards in predator-prey game"


Fig.11
recognition accuracy in the predator-prey game"


Fig.12
Episodic rewards in predator-prey game"

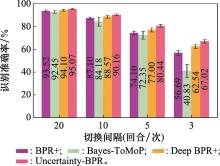
Fig.13
Influence of the opponent policy switching interval on recognition accuracy in soccer game"


Fig.14
Influence of the opponent policy switching interval on recognition accuracy in predator-prey game"

| 1 | ZHOU Z Y, LIU G J, TANG Y. Multi-agent reinforcement learning: methods, applications, visionary prospects, and cha-llenges[EB/OL]. [2023-09-05]. https://doi.org/10.48550/arXiv.2305.10091. |
| 2 | WEN M N , KUBA J , LIN R J , et al. Multi-agent reinforcement learning is a sequence modeling problem[J]. Advances in Neural Information Processing Systems, 2022, 35, 16509- 16521. |
| 3 |
VINYALS O , BABUSCHKIN I , CZARNECKI W M , et al. Grandmaster level in StarCraft Ⅱ using multi-agent reinforcement learning[J]. Nature, 2019, 575 (7782): 350- 354.
doi: 10.1038/s41586-019-1724-z |
| 4 | GAO Y M, LIU F Y, WANG L, et al. Towards effective and interpretable human-agent collaboration in MOBA games: a communication perspective[C]//Proc. of the 11th International Conference on Learning Representations, 2023. |
| 5 | 张磊, 李姜, 侯进永, 等. 基于改进强化学习的多无人机协同对抗算法研究[J]. 兵器装备工程学报, 2023, 44 (5): 230- 238. |
| ZHANG L , LI J , HOU J Y , et al. Research on multi-UAV cooperative confrontation algorithm based on improved reinforcement learning[J]. Journal of Ordnance Equipment Engineering, 2023, 44 (5): 230- 238. | |
| 6 | POPE A P , IDE J S , MICOVIC D , et al. Hierarchical reinforcement learning for air combat at DARPA's Alpha dog fight trials[J]. IEEE Trans.on Artificial Intelligence, 2022, 4 (6): 1371- 1385. |
| 7 | ANDRIES S , HERMAN A E , WILLIE B , et al. Scaling multi-agent reinforcement learning to full 11 versus 11 simulated robotic football[J]. Autonomous Agents and Multi-Agent Systems, 2023, 37 (1): 30. |
| 8 | 孙辉辉, 胡春鹤, 张军国. 基于主动风险防御机制的多机器人强化学习协同对抗策略[J]. 控制与决策, 2023, 38 (5): 1429- 1450. |
| SUN H H , HU C H , ZHANG J G . Cooperative countermeasure strategy based on active risk defense multiagent reinforcement learning[J]. Control and Decision, 2023, 38 (5): 1429- 1450. | |
| 9 | ZHANG T. Opponent modelling in multi-agent systems[D]. London: University College London, 2021. |
| 10 | HU H M, SHI D X, YANG H H, et al. Independent multi-agent reinforcement learning using common knowledge[C]//Proc. of the IEEE International Conference on Systems, Man, and Cybernetics, 2022: 2703-2708. |
| 11 |
ROSMAN B , HAWASLY M , RAMAMOORTHY S . Bayesian policy reuse[J]. Machine Learning, 2016, 104, 99- 127.
doi: 10.1007/s10994-016-5547-y |
| 12 | 何立, 沈亮, 李辉, 等. 强化学习中的策略重用: 研究进展[J]. 系统工程与电子技术, 2022, 44 (3): 884- 899. |
| HE L , SHEN L , LI H , et al. Survey on policy reuse in reinforcement learning[J]. Systems Engineering and Electronics, 2022, 44 (3): 884- 899. | |
| 13 | HERNANDEZ-LEAL P, TAYLOR M E, ROSMAN B, et al. Identifying and tracking switching, non-stationary opponents: a Bayesian approach[C]//Proc. of the 30th Conference on Artificial Intelligence, 2016. |
| 14 | YANG T P, MENG Z P, HAO J Y, et al. Towards efficient detection and optimal response against sophisticated opponents[C]// Proc. of the 28th International Joint Conference on Artificial Intelligence, 2019: 623-629. |
| 15 | WEERD H D , VERBRUFFE R , VERHEIJ B . How much does it help to know what she knows you know? an agent-based simulation study[J]. Artificial Intelligence, 2013, 199, 67- 92. |
| 16 | HERNANDEZ-LEAL P , KARTAL B , TAYLOR M E . A survey and critique of multiagent deep reinforcement learning[J]. Autonomous Agents and Multi-Agent Systems, 2019, 33, 750- 797. |
| 17 | ZHENG Y, MENG Z P, HAO J Y, et al. A deep Bayesian policy reuse approach against non-stationary agents[C]//Proc. of the Advances in Neural Information Processing Systems, 2018. |
| 18 |
BANK D , KOENIGSTEIN N , GIRYES R . Autoencoders[J]. Machine Learning for Data Science Handbook, 2023,
doi: 10.1007/978-3-031-24628-9_16 |
| 19 | ZHAI J H, ZHANG S F, CHEN J F, et al. Autoencoder and its various variants[C]//Proc. of the IEEE International Conference on Systems, Man, and Cybernetics, 2018: 415-419. |
| 20 | LI C J , ZHOU D , GU Q , et al. Learning two-player Markov games: neural function approximation and correlated equilibrium[J]. Advances in Neural Information Processing Systems, 2022, 35, 33262- 33274. |
| 21 | GUO W B, WU X, HUANG S, et al. Adversarial policy learning in two-player competitive games[C]//Proc. of the 38th International Conference on Machine Learning, 2021: 3910-3919. |
| 22 | SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[EB/OL]. [2023-09-05]. https://doi.org/10.48550/arXiv.1707.06347. |
| 23 | VOLODYMYR M, ADRIA P B, MEH D, et al. Asynchronous methods for deep reinforcement learning[C]//Proc. of the 33th International Conference on Machine Learning, 2016. |
| 24 | 姜楠, 王健. 信息论与编码理论[M]. 北京: 清华大学出版社, 2010. |
| JIANG N , WANG J . The theory of information and coding[M]. Beijing: Tsinghua University Press, 2020. | |
| 25 | ZHANG T, YING W G, GONG Z C, et al. A regularized opponent model with maximum entropy objective[C]//Proc. of the 29th International Joint Conference on Artificial Intelligence, 2019. |
| 26 | WIMMER L, SALE Y, HOFMAN P, et al. Quantifying aleatoric and epistemic uncertainty in machine learning: are conditional entropy and mutual information appropriate measures?[C]//Proc. of the 39th Conference on Uncertainty in Artificial Intelligence, 2023: 2282-2292. |
| 27 | MURPHY K P . Probabilistic machine learning: an introduction[M]. Cambridge: Massachusetts Institute of Technology Press, 2022. |
| 28 | CRESCENZO D A , LONGOBARD M . On cumulative entropies[J]. Journal of Statistical Planning and Inference, 2009, 139 (12): 4072- 4087. |
| 29 | PAPOUDAKIS G , CHRISTIANOU F , ALBRECHT S . Agent modelling under partial observability for deep reinforcement learning[J]. Advances in Neural Information Processing Systems, 2021, 34, 19210- 19222. |
| 30 | LOWE R, WU Y I, TAMAR A, et al. Multi-agent actor-critic for mixed cooperative-competitive environments[C]//Proc. of the 31st International Conference on Neural Information Processing Systems, 2017: 6382-6393. |
| [1] | Xunliang YAN, Kuan WANG, Zijian ZHANG, Peichen WANG. Reentry guidance method based on LSTM-DDPG [J]. Systems Engineering and Electronics, 2025, 47(1): 268-279. |
| [2] | Tingyu ZHANG, Ying ZENG, Nan LI, Hongzhong HUANG. Spacecraft power-signal composite network optimization algorithm based on DRL [J]. Systems Engineering and Electronics, 2024, 46(9): 3060-3069. |
| [3] | Yuqi XIA, Yanyan HUANG, Qia CHEN. Path planning for unmanned vehicle reconnaissance based on deep Q-network [J]. Systems Engineering and Electronics, 2024, 46(9): 3070-3081. |
| [4] | Zhipeng YANG, Zihao CHEN, Chang ZENG, Song LIN, Jindi MAO, Kai ZHANG. Online route planning decision-making method of aircraft in complex environment [J]. Systems Engineering and Electronics, 2024, 46(9): 3166-3175. |
| [5] | Lisha PENG, Yuxiang SUN, Yufan XUE, Xianzhong ZHOU. Intelligent decision-making technology for wargame by integrating three-way multiple attribute decision-making and SAC [J]. Systems Engineering and Electronics, 2024, 46(7): 2310-2322. |
| [6] | Hongda GUO, Jingtao LOU, Youchun XU, Peng YE, Yongle LI, Jinsheng CHEN. Event-triggered communication of multiple unmanned ground vehicles collaborative based on MADDPG [J]. Systems Engineering and Electronics, 2024, 46(7): 2525-2533. |
| [7] | Mengyu ZHANG, Yajie DOU, Ziyi CHEN, Jiang JIANG, Kewei YANG, Bingfeng GE. Review of deep reinforcement learning and its applications in military field [J]. Systems Engineering and Electronics, 2024, 46(4): 1297-1308. |
| [8] | Yanling LI, Feizhou LUO, Zhilei GE. Robust observer-based deep reinforcement learning for attitude stabilization of vertical takeoff and landing vehicle [J]. Systems Engineering and Electronics, 2024, 46(3): 1038-1047. |
| [9] | Heng TANG, Wei SUN, Lei LYU, Ruofei HE, Jianjun WU, Changhao SUN, Tianye SUN. UAV formation path planning approach incorporating dynamic reward strategy [J]. Systems Engineering and Electronics, 2024, 46(10): 3506-3518. |
| [10] | Luwei FENG, Songtao LIU, Huazhi XU. Intelligent radar jamming decision-making method based on POMDP model [J]. Systems Engineering and Electronics, 2023, 45(9): 2755-2760. |
| [11] | Yue MA, Lin WU, Xiao XU. Cooperative targets assignment based on multi-agent reinforcement learning [J]. Systems Engineering and Electronics, 2023, 45(9): 2793-2801. |
| [12] | Daozhi WEI, Zhaoyu ZHANG, Jiahao XIE, Ning LI. Multi-sensor cross cueing technique based on improved Actor-Critic algorithm [J]. Systems Engineering and Electronics, 2023, 45(6): 1624-1632. |
| [13] | Fengguo WU, Wei TAO, Hui LI, Jianwei ZHANG, Chengchen ZHENG. UAV intelligent avoidance decisions based on deep reinforcement learning algorithm [J]. Systems Engineering and Electronics, 2023, 45(6): 1702-1711. |
| [14] | Xinzhi LI, Shengbo DONG, Xiangyang CUI. Reinforcement learning technology based on asymmetric unobservable state [J]. Systems Engineering and Electronics, 2023, 45(6): 1755-1761. |
| [15] | Jin TANG, Yangang LIANG, Zhihui BAI, Kebo LI. Landing control algorithm of rotor UAV based on DQN [J]. Systems Engineering and Electronics, 2023, 45(5): 1451-1460. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||