
系统工程与电子技术 ›› 2021, Vol. 43 ›› Issue (2): 420-433.doi: 10.12305/j.issn.1001-506X.2021.02.17
高昂1( ), 董志明1,*(), 李亮1(), 宋敬华1(), 段莉2()
), 董志明1,*(), 李亮1(), 宋敬华1(), 段莉2()
收稿日期:2020-03-06
出版日期:2021-02-01
发布日期:2021-03-16
通讯作者:
董志明
E-mail:15689783388@163.com;236211588@qq.com;liliang_zgy@163.com;jhsong@sina.com;E-mail:236211566@qq.com
作者简介:高昂(1988-),男,博士研究生,主要研究方向为装备作战与保障仿真、多智能体深度强化学习。E-mail:基金资助:
Ang GAO1(), Zhiming DONG1,*(), Liang LI1(), Jinghua SONG1(), Li DUAN2()
Received:2020-03-06
Online:2021-02-01
Published:2021-03-16
Contact:
Zhiming DONG
E-mail:15689783388@163.com;236211588@qq.com;liliang_zgy@163.com;jhsong@sina.com;E-mail:236211566@qq.com
摘要:
多智能体深度确定性策略梯度(multi-agent deep deterministic policy gradient, MADDPG)算法是深度强化学习方法在多智能体系统(multi-agent system, MAS)领域的重要运用,为提升算法性能,提出基于并行优先经验回放机制的MADDPG算法。分析算法框架及训练方法,针对算法集中式训练、分布式执行的特点,采用并行方法完成经验回放池数据采样,并在采样过程中引入优先回放机制,实现经验数据并行流动、数据处理模型并行工作、经验数据优先回放。分别在OpenAI多智能体对抗、合作两类典型环境中,从训练轮数、训练时间两个维度对改进算法进行了对比验证,结果表明,并行优先经验回放机制的引入使得算法性能提升明显。
中图分类号:
高昂, 董志明, 李亮, 宋敬华, 段莉. MADDPG算法并行优先经验回放机制[J]. 系统工程与电子技术, 2021, 43(2): 420-433.
Ang GAO, Zhiming DONG, Liang LI, Jinghua SONG, Li DUAN. Parallel priority experience replay mechanism of MADDPG algorithm[J]. Systems Engineering and Electronics, 2021, 43(2): 420-433.

图1
单智能体DRL方法与MADRL方法示意图"


图2
RL算法分类图"

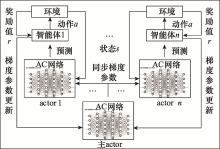
图3
A3C算法示意图"

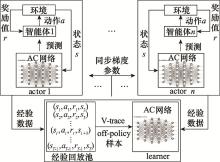
图4
IMPALA框架示意图"

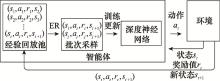
图5
经验回放机制示意图"

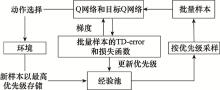
图6
PER原理示意图"


图7
MADDPG算法框架示意图"


图8
PPER-MADDPG算法示意图"


图9
MADDPG并行方法流程图"

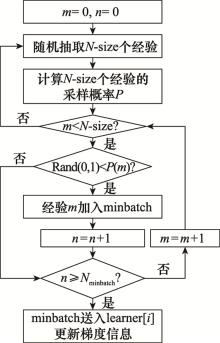
图10
PER机制算法流程图"

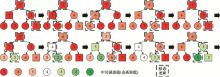
图11
MDP中的Q学习迭代示意图"


图12
Actor、Critic神经网络结构"


图13
“捕食者与猎物”环境示意图"

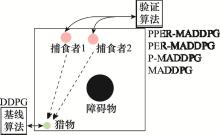
图14
对抗实验设计示意图"

表1
智能体胜率统计表"
| 算法胜率对比 | 训练轮数 | ||||
| 4 501~4 600 | 4 601~4 700 | 4 701~4 800 | 4 801~4 900 | 4 901~5 000 | |
| (PPER-MADDPG, PER-MADDPG) | (0.97, 0.02) | (0.96, 0.03) | (0.94, 0.01) | (0.96, 0.01) | (0.94, 0.02) |
| (PPER-MADDPG, P-MADDPG) | (0.97, 0.00) | (0.96, 0.01) | (0.95, 0.01) | (0.97, 0.00) | (0.96, 0.01) |
| (PPER-MADDPG, MADDPG) | (0.96, 0.01) | (0.97, 0.01) | (0.97, 0.00) | (0.96, 0.00) | (0.94, 0.01) |
| (PPER-MADDPG, DDPG) | (0.96, 0.02) | (0.97, 0.01) | (0.93, 0.04) | (0.95, 0.04) | (0.96, 0.02) |

图15
智能体胜率曲线"
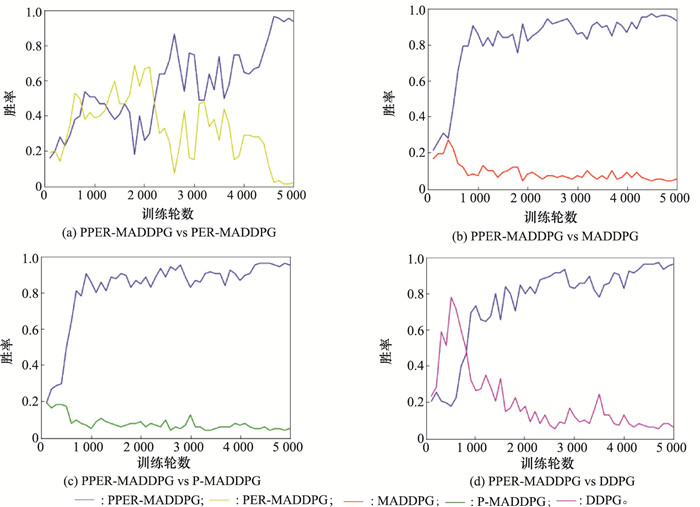
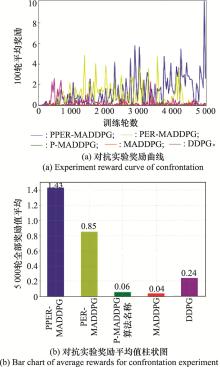
图16
对抗实验数据图(episode维度)"

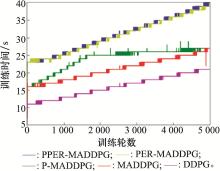
图17
每轮训练所用时间统计图"

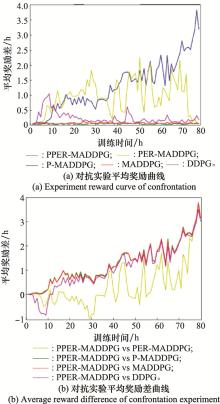
图18
对抗实验数据图(时间维度)"

表2
智能体平均奖励差值统计表"
| 算法奖励差值对比 | 训练时间/h | ||||
| 75~76 | 76~77 | 77~78 | 78~79 | 79~80 | |
| PPER-MADDPG-PER-MADDPG | 2.19 | 2.76 | 2.93 | 3.77 | 3.14 |
| PPER-MADDPG-P-MADDPG | 2.46 | 2.81 | 3.10 | 3.79 | 3.15 |
| PPER-MADDPG-MADDPG | 2.41 | 2.80 | 3.11 | 3.75 | 3.15 |
| PPER-MADDPG-DDPG | 2.38 | 2.69 | 2.98 | 3.51 | 3.01 |

图19
“合作导航”环境示意图"

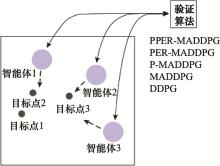
图20
合作实验设计示意图"
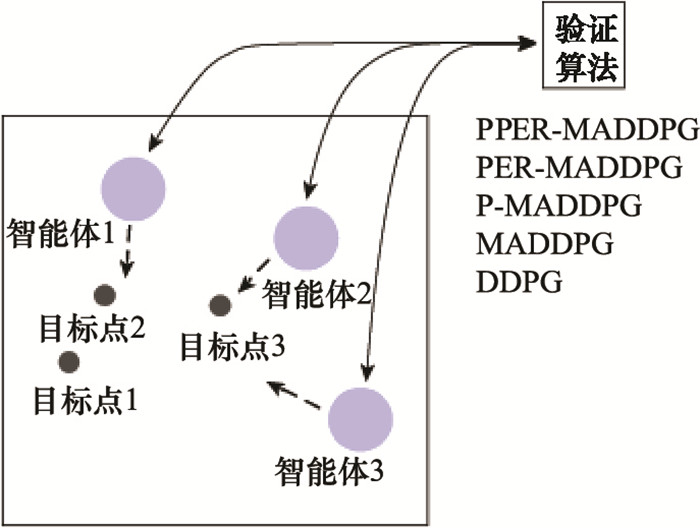

图21
合作实验数据图(episode维度)"

表3
智能体奖励值均值与标准偏差统计表(训练轮数不同)"
| 算法对比 | 训练轮数 | ||||
| 4 501~4 600 | 4 601~4 700 | 4 701~4 800 | 4 801~4 900 | 4 901~5 000 | |
| PPER-MADDPG | (-0.23, 0.16) | (-0.24, 0.07) | (-0.29, 0.16) | (-0.24, 0.07) | (-0.23, 0.05) |
| PER-MADDPG | (-0.29, 0.27) | (-0.25, 0.09) | (-0.24, 0.07) | (-0.24, 0.07) | (-0.27, 0.16) |
| P-MADDPG | (-0.59, 0.73) | (-0.72, 0.73) | (-0.81, 0.78) | (-0.52, 0.50) | (-0.62, 0.70) |
| MADDPG | (-0.63, 0.74) | (-0.76, 0.74) | (-0.85, 0.79) | (-0.56, 0.50) | (-0.66, 0.71) |
| DDPG | (-0.22, 0.07) | (-0.24, 0.09) | (-0.28, 0.14) | (-0.28, 0.09) | (-0.26, 0.07) |
表4
5 000轮智能体奖励值平均"
| 算法 | 奖励值 |
| PPER-MADDPG | -0.38 |
| PER-MADDPG | -0.42 |
| P-MADDPG | -0.95 |
| MADDPG | -1.01 |
| DDPG | -0.69 |

图22
每轮训练所用时间统计图"


图23
合作实验数据图(时间维度)"

表5
智能体奖励值均值与标准偏差统计表(训练时间不同)"
| 算法对比 | 训练时间/h | ||||
| 75~76 | 76~77 | 77~78 | 78~79 | 79~80 | |
| PPER-MADDPG | (-0.29, 0.11) | (-0.26, 0.14) | (-0.24, 0.19) | (-0.22, 0.08) | (-0.24, 0.04) |
| PER-MADDPG | (-0.27, 0.34) | (-0.31, 0.20) | (-0.26, 0.10) | (-0.25, 0.09) | (-0.25, 0.08) |
| P-MADDPG | (-0.98, 0.91) | (-0.55, 0.50) | (-0.59, 0.63) | (-0.69, 0.75) | (-0.41, 0.38) |
| MADDPG | (-0.82, 0.84) | (-0.71, 0.62) | (-0.95, 0.88) | (-0.57, 0.49) | (-0.61, 0.77) |
| DDPG | (-0.25, 0.09) | (-0.25, 0.09) | (-0.41, 0.08) | (-0.61, 0.17) | (-0.26, 0.07) |
表6
80 h累积奖励值平均统计表"
| 算法 | 奖励值 |
| PPER-MADDPG | -0.38 |
| PER-MADDPG | -0.39 |
| P-MADDPG | -0.95 |
| MADDPG | -1.01 |
| DDPG | -0.63 |
| 1 |
ZHANG J , WANG G , YUE S H , et al. Multi-agent system application in accordance with game theory in bi-directional coordination network model[J]. Journal of Systems Engineering and Electronics, 2020, 31 (2): 279- 289.
doi: 10.23919/JSEE.2020.000006 |
| 2 | 孙彧, 曹雷, 陈希亮, 等. 多智能体深度强化学习研究综述[J]. 计算机工程与应用, 2020, 56 (5): 13- 24. |
| SUN Y , CAO L , CHEN X L , et al. Research review on multi-agent deep reinforcement learning[J]. Computer Engineering and Applications, 2020, 56 (5): 13- 24. | |
| 3 |
LECUN Y , BENGIO Y , HINTON G . Deep learning[J]. Nature, 2015, 521 (7553): 436- 444.
doi: 10.1038/nature14539 |
| 4 | MNIH V, KAVUKCUOGLU K, SILVER D, et al. Playing atari with deep reinforcement learning[EB/OL].[2020-02-07].http://arxiv.org/pdf/1312.5602.pdf. |
| 5 | 刘全, 翟建伟, 章宗长, 等. 深度强化学习综述[J]. 计算机学报, 2018, 41 (1): 1- 27. |
| LIU Q , ZHAI J W , ZHANG Z C , et al. Review of deep reinforcement learning[J]. Journal of Computer Science, 2018, 41 (1): 1- 27. | |
| 6 | 谭浪.强化学习在多智能体对抗中的应用研究[D].北京:中国运载火箭技术研究院, 2019. |
| TAN L. Application research of reinforcement learning on multi-agent competition[D]. Beijing: China Academy of Launch Vehicle Technology, 2019. | |
| 7 | HERNANDEZ-LEAL P , KARTAL B , TAYLOR M E . A survey and critique of multiagent deep reinforcement learning[J]. Autonomous Agents and Multi-agent Systems, 2019, 33 (6): 750- 797. |
| 8 | 杜威, 丁世飞. 多智能体强化学习综述[J]. 计算机科学, 2019, 46 (8): 1- 8. |
| DU W , DING S F . A review of multi-agent reinforcement learning[J]. Computer Science, 2019, 46 (8): 1- 8. | |
| 9 | RICHARD S , SUTTON A G . Reinforcement learning:an introduction[M]. Cambridge: MIT Press, 2018. |
| 10 | FOERSTER J, ASSAEL I A, DE F N, et al. Learning to communicate with deep multi-agent reinforcement learning[C]//Proc.of the 30th Annual Conference on Neural Information Processing, 2016: 2137-2145. |
| 11 | LANCTOT M, ZAMBALDI V, GRUSLYS A, et al. A unified game-theoretic approach to multiagent reinforcement learning[C]//Proc.of the Advances in Neural Information Processing Systems, 2017: 4190-4203. |
| 12 | PALMER G, TUYLS K, BLOEMBERGEN D, et al. Lenient multi-agent deep reinforcement learning[C]//Proc.of the 17th International Conference on Autonomous Agents and Multiagent Systems: International Foundation for Autonomous Agents and Multiagent Systems, 2018: 443-451. |
| 13 | OMIDSHAFIEI S, PAZIS J, AMATO C, et al. Deep decentralized multi-task multi-agent reinforcement learning under partial observability[C]//Proc.of the 34th International Conference on Machine Learning, 2017: 2681-2690. |
| 14 | ZHENG Y, HAO J Y, ZHANG Z Z. Weighted double deep multi-agent reinforcement learning in stochastic cooperative environments[C]//Proc.of the Pacific Rim International Confe-rence on Artificial Intelligence, 2018: 421-429. |
| 15 |
JADERBERG M , CZARNECKI W M , DUNNING I , et al. Human-level performance in 3d multiplayer games with population-based reinforcement learning[J]. Science, 2019, 364 (6443): 859- 865.
doi: 10.1126/science.aau6249 |
| 16 | SUNEHAG P, LEVER G, GRUSLYS A, et al. Value-decomposition networks for cooperative multi-agent learning based on team reward[C]//Proc.of the 17th International Conference on Autonomous Agents and MultiAgent Systems, 2018: 2085-2087. |
| 17 | RASHID T, SAMVELYAN M, DE W C S, et al. Qmix: monotonic value function factorisation for deep multi-agent reinforcement learning[EB/OL].[2020-02-07]. http://arxiv.org/pdf/1803.11485.pdf. |
| 18 | FOERSTER J N, FARQUHAR G, AFOURAS T, et al. Counterfactual multi-agent policy gradients[C]//Proc.of the AAAI 32nd Conference on Artificial Intelligence, 2018: 2974-2982. |
| 19 | GUPTA J K, EGOROV M, KOCHENDERFER M. Cooperative multi-agent control using deep reinforcement learning[C]//Proc.of the International Conference on Autonomous Agents and Multiagent Systems, 2017: 66-83. |
| 20 | LOWE R, WU Y, TAMAR A, et al. Multi-agent actor-critic for mixed cooperative-competitive environments[C]//Proc.of the Advances in Neural Information Processing Systems, 2017: 6379-6390. |
| 21 | 何明,张斌,柳强,等. MADDPG算法经验优先抽取机制研究[EB/OL].[2020-02-07]. http://doi.org/10.13195/j.kzyjc.2019.0834. |
| HE M, ZHANG B, LIU Q, et al. Study on the preferential extraction mechanism of MADDPG algorithm experience[EB/OL].[2020-02-07]. http://doi.org/10.13195/j.kzyjc.2019.0834. | |
| 22 | KONDA V R, TSITSIKLIS J N. Actor-critic algorithms[C]//Proc.of the Advances in Neural Information Processing Systems, 2000: 1008-1014. |
| 23 | MNIH V, BADIA A P, MIRZA M, et al. Asynchronous methods for deep reinforcement learning[C]//Proc.of the International Conference on Machine Learning, 2016: 1928-1937. |
| 24 | BABAEIZADEH M, FROSIO I, TYREE S, et al. Reinforcement learning through asynchronous advantage actor-critic on a GPU[EB/OL].[2020-02-07].http://arxiv.org/pdf/1611.06256.pdf. |
| 25 | ESPEHOLT L, SOYER H, MUNOS R, et al. Impala: scalable distributed deep-RL with importance weighted actor-learner architectures[EB/OL].[2020-02-07]. http://arxiv.org/pdf/1802.01561.pdf. |
| 26 | TAI L, PAOLO G, LIU M. Virtual-to-real deep reinforcement learning: continuous control of mobile robots for mapless navigation[C]//Proc.of the IEEE/RSJ International Conference on Intelligent Robots and Systems, 2017: 31-36. |
| 27 | BARTH-MARON G, HOFFMAN M W, BUDDEN D, et al. Distributed distributional deterministic policy gradients[EB/OL].[2020-02-07].http://arxiv.org/pdf/1804.08617.pdf. |
| 28 | HEESS N, SRIRAM S, LEMMON J, et al. Emergence of locomotion behaviours in rich environments[EB/OL].[2020-02-07].http://arxiv.org/pdf/1707.02286.pdf. |
| 29 | LIN L J. Reinforcement learning for robots using neural networks[R].Carnegie Mellon University, 1993: 50-77. |
| 30 | MNIH V, KAVUKCUOGLU K, SILVER D, et al. Playing atari with deep reinforcement learning[EB/OL].[2020-02-07].http://arxiv.org/pdf/1312.5602.pdf. |
| 31 |
MNIH V , KAVUKCUOGLU K , SILVER D , et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518 (7540): 529- 540.
doi: 10.1038/nature14236 |
| 32 | VAN H H, GUEZ A, SILVER D. Deep reinforcement learning with double Q-learning[C]//Proc.of the AAAI 30th Conference on Artificial Intelligence, 2016: 2094-2100. |
| 33 | WANG Z, SCHAUL T, HESSEL M, et al. Dueling network architectures for deep reinforcement learning[EB/OL].[2020-02-07]. http://arxiv.org/pdf/1511.06581.pdf. |
| 34 | HAUSKNECHT M, STONE P. Deep recurrent Q-learning for partially observable MDPS[C]//Proc.of the AAAI Fall Symposium Series, 2015: 29-37. |
| 35 | LILLICRAP T P, HUNT J J, PRITZEL A, et al. Continuous control with deep reinforcement learning[EB/OL].[2020-02-07]. http://arxiv.org/pdf/1509.02971.pdf. |
| 36 | WANG Z, BAPST V, HEESS N, et al. Sample efficient actor-critic with experience replay[2020-02-07].http://arxiv.org/pdf/1611.01224.pdf. |
| 37 | SCHULMAN J, LEVINE S, ABBEEL P, et al. Trust region policy optimization[C]//Proc.of the International Conference on Machine Learning, 2015: 1889-1897. |
| 38 | SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[EB/OL].[2020-02-07].http://arxiv.org/pdf/1707.06347.pdf. |
| 39 | HAARNOJA T, ZHOU A, ABBEEL P, et al. Soft actor-critic: off-policy maximum entropy deep reinforcement learning with a stochastic actor[EB/OL].[2020-02-07].http://arxiv.org/pdf/1801.01290.pdf. |
| 40 | SCHAUL T, QUAN J, ANTONOGLOU I, et al. Prioritized experience replay[EB/OL].[2020-02-07].http://arxiv.org/pdf/1511.05952.pdf. |
| 41 | BRITTAIN M, BERTRAM J, YANG X, et al. Prioritized sequence experience replay[EB/OL].[2020-02-07].http://arxiv.org/pdf/1905.12726.pdf. |
| 42 | ZHANG H, XIONG K, BAI J. Improved deep deterministic policy gradient algorithm based on prioritized sampling[C]//Proc.of the Chinese Intelligent Systems Conference, 2019: 205-215. |
| 43 | KHAN A, ZHANG C, LEE D D, et al. Scalable centralized deep multi-agent reinforcement learning via policy gradients[EB/OL].[2020-02-07].http://arxiv.org/pdf/1805.08776.pdf. |
| 44 | LIU R S, ZOU J. The effects of memory replay in reinforcement learning[C]//Proc.of the 56th Annual Allerton Conference on Communication, Control and Computing, 2019: 478-485. |
| 45 | 陈希亮, 曹雷, 李晨溪, 等. 基于重抽样优选缓存经验回放机制的深度强化学习方法[J]. 控制与决策, 2018, 33 (4): 600- 606. |
| [1] | 马子杰, 谢拥军. 体系作战下巡航导弹的动态隐身[J]. 系统工程与电子技术, 2022, 44(9): 2826-2831. |
| [2] | 王冠, 茹海忠, 张大力, 马广程, 夏红伟. 弹性高超声速飞行器智能控制系统设计[J]. 系统工程与电子技术, 2022, 44(7): 2276-2285. |
| [3] | 孟泠宇, 郭秉礼, 杨雯, 张欣伟, 赵柞青, 黄善国. 基于深度强化学习的网络路由优化方法[J]. 系统工程与电子技术, 2022, 44(7): 2311-2318. |
| [4] | 郭冬子, 黄荣, 许河川, 孙立伟, 崔乃刚. 再入飞行器深度确定性策略梯度制导方法研究[J]. 系统工程与电子技术, 2022, 44(6): 1942-1949. |
| [5] | 张普, 薛惠锋, 高山, 左轩. 具有混合执行器故障的多智能体分布式有限时间自适应协同容错控制[J]. 系统工程与电子技术, 2022, 44(4): 1220-1229. |
| [6] | 杨清清, 高盈盈, 郭玙, 夏博远, 杨克巍. 基于深度强化学习的海战场目标搜寻路径规划[J]. 系统工程与电子技术, 2022, 44(11): 3486-3495. |
| [7] | 罗哲, 权婉珍, 张朴睿, 杨小冈. 单边Lipschitz非线性多智能体系统一致性追踪控制[J]. 系统工程与电子技术, 2022, 44(1): 279-284. |
| [8] | 刘家义, 岳韶华, 王刚, 姚小强, 张杰. 复杂任务下的多智能体协同进化算法[J]. 系统工程与电子技术, 2021, 43(4): 991-1002. |
| [9] | 马文, 李辉, 王壮, 黄志勇, 吴昭欣, 陈希亮. 基于深度随机博弈的近距空战机动决策[J]. 系统工程与电子技术, 2021, 43(2): 443-451. |
| [10] | 张普, 薛惠锋, 高山, 左轩. 具有弱通讯的多智能体分布式自适应协同跟踪控制[J]. 系统工程与电子技术, 2021, 43(2): 487-498. |
| [11] | 高昂, 郭齐胜, 董志明, 杨绍卿. 基于EAS+MADRL的多无人车体系效能评估方法研究[J]. 系统工程与电子技术, 2021, 43(12): 3643-3651. |
| [12] | 张堃, 李珂, 时昊天, 张振冲, 刘泽坤. 基于深度强化学习的UAV航路自主引导机动控制决策算法[J]. 系统工程与电子技术, 2020, 42(7): 1567-1574. |
| [13] | 刘家义, 王刚, 张杰, 王闯, 宋喜团. 基于改进AGD-分布式多智能体系统的目标优化分配模型[J]. 系统工程与电子技术, 2020, 42(4): 863-870. |
| [14] | 谢浩, 郭爱煌, 宋春林, 焦润泽. LTE-V下基于深度强化学习的基站选择算法[J]. 系统工程与电子技术, 2019, 41(7): 1652-1657. |
| [15] | 李晨溪, 曹雷, 张永亮, 陈希亮, 周宇欢, 段理文. 基于知识的深度强化学习研究综述[J]. 系统工程与电子技术, 2017, 39(11): 2603-2613. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||