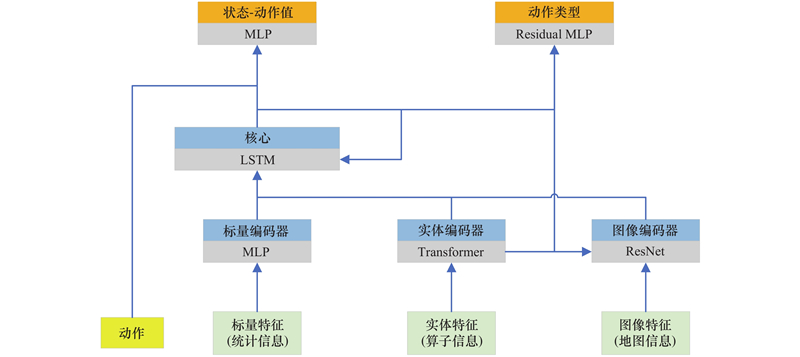
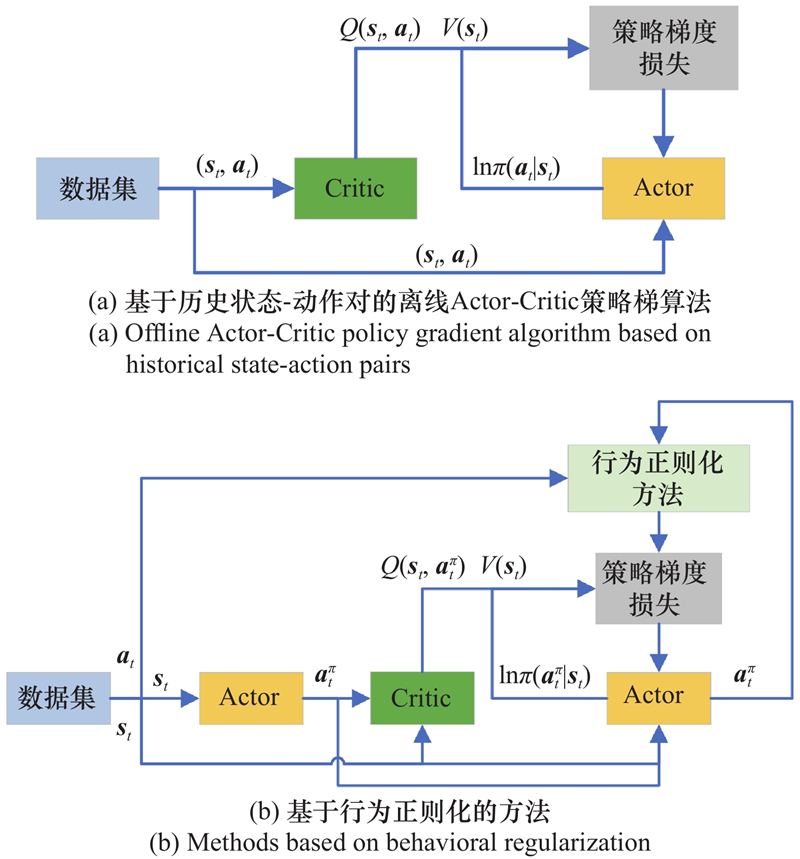
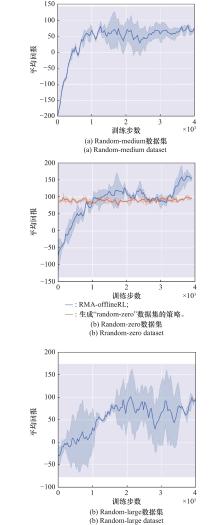
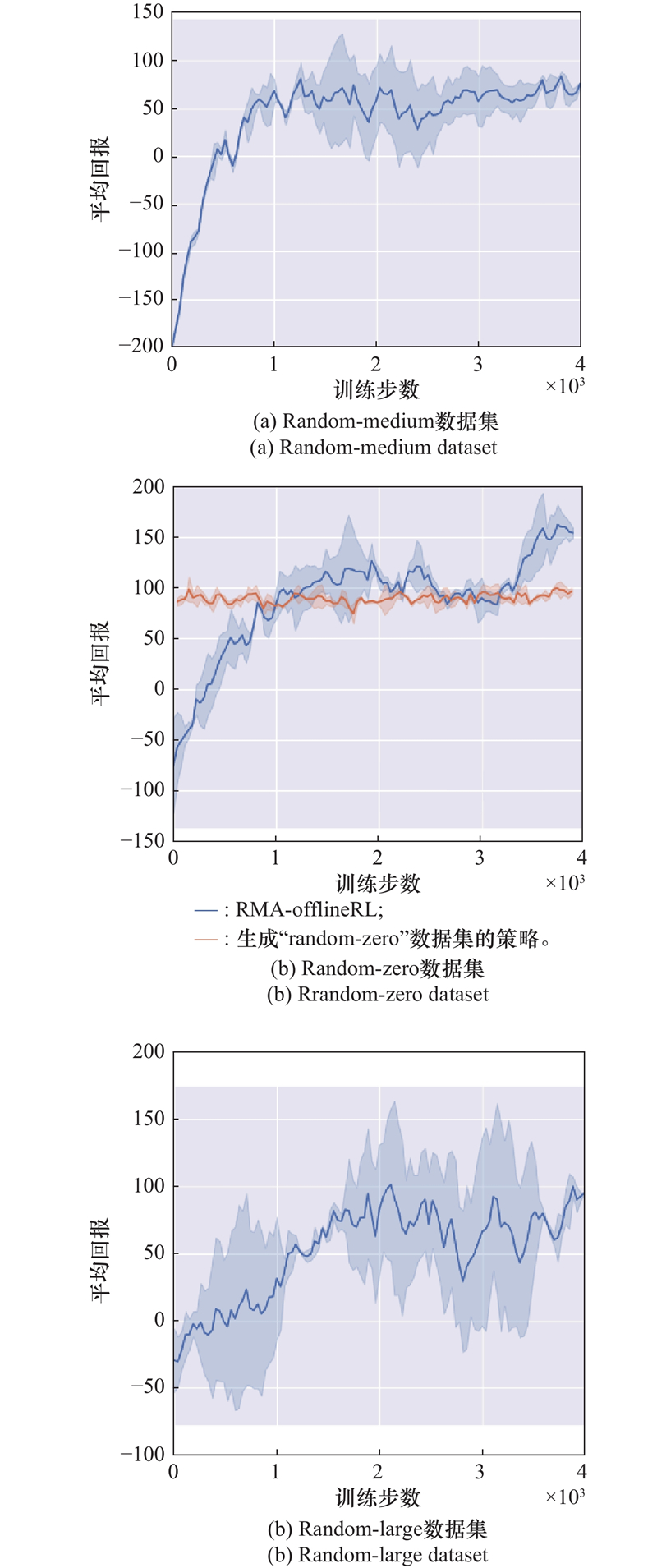
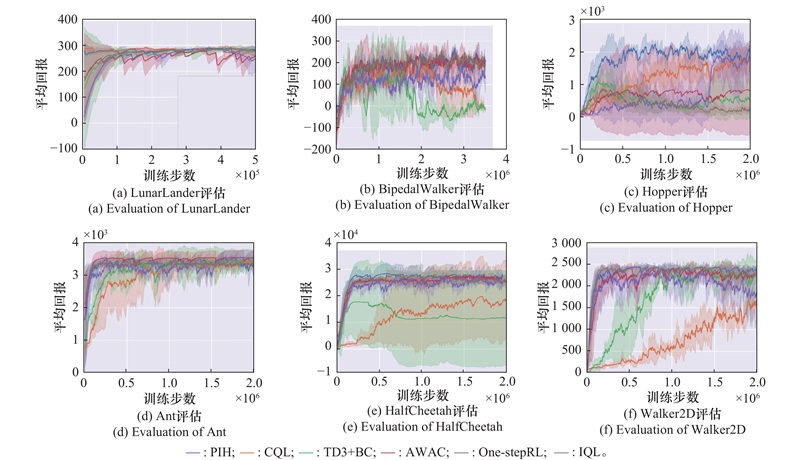
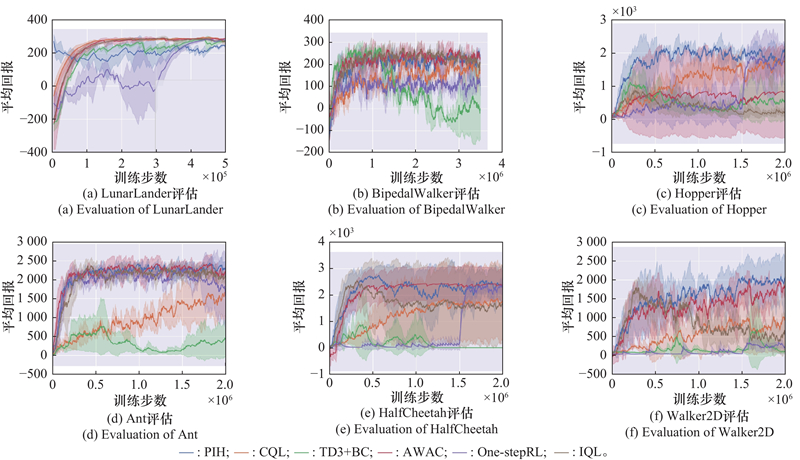
| 1 |
张梦钰, 豆亚杰, 陈子夷, 等. 深度强化学习及其在军事领域中的应用综述[J]. 系统工程与电子技术, 2024, 46(4): 1297−1308.
|
|
ZHANG M Y, DOU Y J, CHEN Z Y, et al. Review of deep reinforcement learning and its applications in military field[J]. Systems Engineering and Electronics, 2024, 46(4): 1297−1308 .
|
| 2 |
周雪, 苘大鹏, 许晨, 等. 无人系统中离线强化学习的隐蔽数据投毒攻击方法[J]. 通信学报, 2024, 45 (12): 16- 27.
doi: 10.11959/j.issn.1000-436x.2024264
|
|
ZHOU X, RUI D P, XU C, et al. Stealthy data poisoning attack method on offline reinforcement learning in unmanned systems[J]. Journal on Communications, 2024, 45 (12): 16- 27.
doi: 10.11959/j.issn.1000-436x.2024264
|
| 3 |
侯永宏, 丁旺, 任懿, 等. 基于优质样本筛选的离线强化学习算法[J]. 模式识别与人工智能, 2024, 37(11): 1022−1032.
|
|
HOU Y H, DING W, REN Y, et al. Offline reinforcement learning algorithm based on selection of high-quality samples[J]. Pattern Recognition and Artificial Intelligence, 2024, 37(11): 1022−1032.
|
| 4 |
彭莉莎, 孙宇祥, 薛宇凡, 等. 融合三支多属性决策与SAC的兵棋推演智能决策技术[J]. 系统工程与电子技术, 2024, 46 (7): 2310- 2322.
|
|
PENG L S, SUN Y X, XUE Y F, et al. Intelligent decision-making technology for wargame by integrating three-way multiple attribute decision-making and SAC[J]. Systems Engineering and Electronics, 2024, 46 (7): 2310- 2322.
|
| 5 |
ARNOB S Y, ISLAM R, PRECUP D. Importance of empirical sample complexity analysis for offline reinforcement learning[EB/OL]. [2024-12-10]. https://doi.org/10.48550/arXiv.2112.15578.
|
| 6 |
KAJETAN S, MARKUS H, MARKUS C D, et al. A dataset perspective on offline reinforcement learning[C]//Proc. of the Conference on Lifelong Learning Agents, 2022: 470−517.
|
| 7 |
AVRIAL K, JUSTING F, MATTHEW S, et al. Stabilizing off-policy Q-learning via bootstrapping error reduction[C]//Proc. of the 33th Neural Information Processing Systems, 2019: 452−461.
|
| 8 |
毛经坤, 李凤熙, 刘春新, 等. 基BCQ离线强化学习的呼吸机动态治疗策略控制[EB/OL]. [2024-12-10]. https://link.cnki.net/urlid/12.1374.N.20241122.0937.008.
|
|
MAO J K, LI F X, LIU C X, et al. Dynamic treatment policy control of ventilator based on BCQ offline deep reinforcement learning[EB/OL]. [2024-12-10]. https://link.cnki.net/urlid/12.1374.N.20241122.0937.008.
|
| 9 |
陈锶奇, 耿婕, 汪云飞, 等. 基于离线强化学习的研究综述[J]. 无线电通信技术, 2024, 50 (5): 831- 842.
|
|
CHEN S Q, GENG J, WANG Y F, et al. Survey of research on offline reinforcement learning[J]. Radio Communications and Technology, 2024, 50 (5): 831- 842.
|
| 10 |
NATASHA J, ASMA G, JUDY H S, et al. Way off-policy batch deep reinforcement learning of implicit human preferences in dialog[EB/OL]. [2024-12-10]. https://doi.org/10.48550/arXiv.1907.00456.
|
| 11 |
HUANG L Y, DONG B T, XIE W, et al. An implicit trust region approach to behavior regularized offine reinforcement learning[C]//Proc. of the 38th AAAI Conference on Artificial Intelligence, 2024, 16944−16952.
|
| 12 |
WU Y F, TUCKER G, NACHUM O. Behavior regularized offline reinforcement learning[EB/OL]. [2024-12-10]. https://doi.org/10.48550/arXiv.1911.11361 .
|
| 13 |
FUJIMOTO S, GU S S. A minimalist approach to offline reinforcement learning[C]//Proc. of the 35th Conference on Neural Information Processing Systems, 2024.
|
| 14 |
PAINE T L, PADURARU C, MICHI A, et al. Hyperparameter selection for offline reinforcement learning[EB/OL]. [2024-12-10]. https://doi.org/10.48550/arXiv.2007.09055.
|
| 15 |
ZHANG S Y, JIANG N. Towards hyperparameter-free policy selection for offline reinforcement learning[C]//Proc. of the 35th Conference on Neural Information Processing Systems, 2021: 12864−12875.
|
| 16 |
JIN Y, YANG Z R, WANG Z R. Is pessimism provably efficient for offline RL?[C]//Proc. of the 38th International Conference on Machine Learning, 2021: 5084−5096.
|
| 17 |
KUMAR A, ZHOU A, TUCKER G, et al. Conservative Q-learning for offline reinforcement learning[C]//Proc. of the 34th Conference on Neural Information Processing Systems, 2020: 1179−1191.
|
| 18 |
KOSTRIKOV I, NAIR A, LEVINE S. Offline reinforcement learning with implicit Q-learning[EB/OL]. [2024-12-10]. https://doi.org/10.48550/arXiv.2110.06169.
|
| 19 |
BRANDFONBRENER D, WHITNEY W, RANGANATH R, et al. Offline RL without off-policy evaluation[C]//Proc. of the 35th Conference on Neural Information Processing Systems, 2021, 34: 4933−4946.
|
| 20 |
NAIR A, GUPTA A, DALAL M, et al. AWAC: accelerating online reinforcement learning with offline datasets[EB/OL]. [2024-12-10]. https://doi.org/10.48550/arXiv.2006.09359.
|
| 21 |
XU J L, HU J, WANG S X, et al. MiaoSuan Wargame: a multi-mode integrated platform for imperfect information game[C]//Proc. of the IEEE Conference on Games, 2022: 457−464.
|
| 22 |
WANG C B, ZHANG X Y, GAO H B, et al. COLERGs-constrained safe reinforcement learning for realising MASS’s risk-informed collision avoidance decision making[J]. Knowledge-Based Systems, 2024, 300, 112205.
doi: 10.1016/j.knosys.2024.112205
|
| 23 |
GAO H B, ZHAO M, ZHENG X, et al. An improved hierarchical deep reinforcement learning algorithm for multi-intelligent vehicle lane change[J]. Neurocomputing, 2024, 609, 128482.
doi: 10.1016/j.neucom.2024.128482
|
| 24 |
SUTTON R S, MCALLESTER D, SINGH S, et al. Policy gradient methods for reinforcement learning with function approximation[C]//Proc. of the Neural Information Processing Systems, 2000: 1057−1063.
|
| 25 |
SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Combustion optimization study of pulverized coal boiler based on proximal policy optimization algorithm[J]. Applied Thermal Engineering, 2024, 254, 1359- 1361.
doi: 10.2139/ssrn.4542814
|
| 26 |
OSBORNE J. Improving your data transformations: applying the Box-Cox transformation[J]. Practical Assessment, Research, and Evaluation, 2010, 15(12). DOI: https://doi.org/10.7275/qbpc-gk17.
|
| 27 |
LIU R Z, WANG W H, SHEN Y J, et al. An introduction of mini-AlphaStar[EB/OL]. [2024-12-10]. https://doi.org/10.48550/arXiv.2104.06890.
|
| 28 |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]//Proc. of the Neural Information Processing Systems, 2017: 5998−6008.
|
| 29 |
HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2016: 770−778.
|
| 30 |
ZHANG H Q, MA H B, YING J. An improved off-policy actor-critic algorithm with historical behaviors reusing for robotic control[C]//Proc. of the 15th International Conference on Intelligent Robots and Applications, 2023: 449−458.
|
| 31 |
ESPEHOLT L, SOYER H, MUNOS R, et al. IMPALA: scalable distributed deep RL with importance weighted actor-learner architectures[C]//Proc. of the 35th International Conference on Machine Learning, 2018: 1407−1416.
|
| 32 |
HU M. Deep RL zoo: a collections of deep RL algorithms implemented with PyTorch[EB/OL]. [2024-12-10]. https://github.com/michaelnny/deep_rl_zoo.
|
| 33 |
BROCKMAN G, CHEUNG V, PETTERSSON L, et al. OpenAI Gym[EB/OL]. [2024-12-10]. https://doi.org/10.48550/arXiv.1606.01540.
|
| 34 |
BERROCAL E, SIERRA B, HERRERO H W. Evaluating PyBullet and Isaac Sim in the scope of robotics and reinforcement learning[C]//Proc. of the 7th Iberian Robotics Conference, 2024.
|