
系统工程与电子技术 ›› 2024, Vol. 46 ›› Issue (5): 1628-1655.doi: 10.12305/j.issn.1001-506X.2024.05.17
• 系统工程 • 上一篇
罗俊仁, 张万鹏, 苏炯铭, 袁唯淋, 陈璟
收稿日期:2022-01-29
出版日期:2024-04-30
发布日期:2024-04-30
通讯作者:
陈璟
作者简介:罗俊仁(1989—), 男, 博士研究生, 主要研究方向为多智能体学习、智能博弈基金资助:Junren LUO, Wanpeng ZHANG, Jiongming SU, Weilin YUAN, Jing CHEN
Received:2022-01-29
Online:2024-04-30
Published:2024-04-30
Contact:
Jing CHEN
摘要:
随着深度学习和强化学习而来的人工智能新浪潮, 为智能体从感知输入到行动决策输出提供了“端到端”解决方案。多智能体学习是研究智能博弈对抗的前沿课题, 面临着对抗性环境、非平稳对手、不完全信息和不确定行动等诸多难题与挑战。本文从博弈论视角入手, 首先给出了多智能体学习系统组成,进行了多智能体学习概述, 简要介绍了各类多智能体学习研究方法。其次, 围绕多智能体博弈学习框架, 介绍了多智能体博弈基础模型及元博弈模型, 均衡解概念和博弈动力学, 学习目标多样、环境(对手)非平稳、均衡难解且易变等挑战。再次, 全面梳理了多智能体博弈策略学习方法, 离线博弈策略学习方法, 在线博弈策略学习方法。最后,从智能体认知行为建模与协同、通用博弈策略学习方法和分布式博弈策略学习框架共3个方面探讨了多智能体学习的前沿研究方向。
中图分类号:
罗俊仁, 张万鹏, 苏炯铭, 袁唯淋, 陈璟. 多智能体博弈学习研究进展[J]. 系统工程与电子技术, 2024, 46(5): 1628-1655.
Junren LUO, Wanpeng ZHANG, Jiongming SU, Weilin YUAN, Jing CHEN. Research progress of multi-agent learning in games[J]. Systems Engineering and Electronics, 2024, 46(5): 1628-1655.

图1
本文整体架构"


图2
多智能体学习在机器博弈领域的典型研究"


图3
多智能体学习系统组成"


图4
多智能体学习主要学习方法"


图5
多智能体博弈模型"


图6
多智能体学习基础模型"
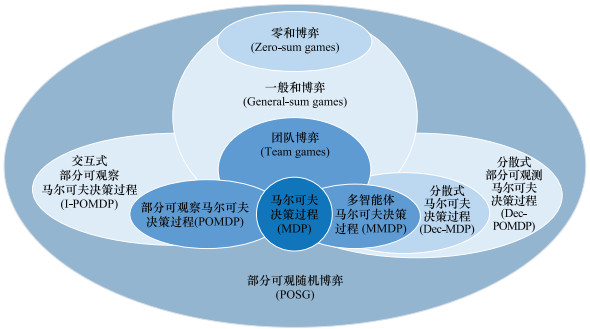
表1
博弈论与元博弈对比"
| 博弈论 | 元博弈 |
| 博弈 | 博弈 |
| 参与方 | 种群 |
| 行动 | 类型 |
| 策略 | 分布 |
| 收益 | 适应度 |

图7
评估矩阵及二维嵌入"


图8
博弈策略几何体"


图9
博弈均衡概念"

表2
多智能体学习的目标"
| 稳定性 | 适应性 |
| 均衡学习[ | 最佳响应[ |
| 收敛性[ | 理性[ |
| 可预测[ | 无悔[ |
| 对手无关[ | 对手察觉[ |
| 总体 | 目标最优、相容性与帕累托有效性、安全性[ |

图10
面向非平稳对手的5种方法"


图11
柠檬水站位博弈[119]"

表3
随机博弈均衡学习方法"
| 博弈类型 | 方法示例 | 特点 |
| 合作博弈 | Team Q[ | 采用团队联合值函数学习 |
| Distributed Q[ | 采用分布式值函数学习 | |
| JAL[ | 采用联合行动学习 | |
| OAL[ | 采用最优自适应学习 | |
| Decentralized Q[ | 采用分散式值函数学习 | |
| 零和博弈 | Minimax Q[ | 采用极小极大式值函数学习 |
| 一般和博弈 | Nash Q[ | 基于纳什均衡的值函数学习 |
| CE Q[ | 基于相关均衡的值函数学习 | |
| Asymmetric Q[ | 基于非对称值函数学习 | |
| FFQ[ | 采用区分敌和友的值函数学习 | |
| WoLF[ | 采用快赢或快学式变学习率学习 | |
| IGA[ | 采用无穷小梯度上升方式学习 | |
| GIGA[ | 采用广义无穷小梯度上升方式学习 | |
| AWESOME[ | 应对平稳对手的最佳响应学习 |
表4
多智能体强化学习方法"
| 学习范式 | 方法示例 | 特点 |
| 完全分散式 | Independent Q[ | 独立计算值函数学习 |
| Distributed Q[ | 分布式计算值函数学习 | |
| Hysteretic Q[ | 区分“奖励”和“惩罚”的变学习率学习 | |
| FMQ[ | 奖励频率最大化值函数学习 | |
| Lenient MARL[ | 忽略低回报行为的宽容式学习 | |
| Distributed Lenient Q[ | 分布式宽容式学习 | |
| 完全集中式 | CommNet[ | 利用通信网络的集中式学习 |
| BiCNet[ | 双向通信协调学习 | |
| 集中式训练分散式执行 | COMA[ | 利用反事实的信度分配 |
| MADDPG[ | 利用深度确定性策略与正则化 | |
| MASQL[ | 利用软值函数 | |
| VDN[ | 利用值函数分解网络 | |
| QMIX[ | 利用值函数与非线性映射 | |
| MAVEN[ | 利用变分探索控制策略隐层空间 | |
| QTRAN[ | 利用变换分解值函数 | |
| Q-DPP[ | 行列式多样性值函数 | |
| MAPPO[ | 利用多个PPO | |
| Shapley Q[ | 利用Shapley值分解值函数 | |
| 联网分散式训练[ | FQI[ | 神经拟合值迭代 |
| DIGing[ | 时变图上的分布式优化 | |
| MAAC[ | 联网的去中心化AC方法 | |
| SAC[ | 利用联网系统平均回报的大规模AC方法 | |
| NeurComm[ | 利用可微通信协议约减联网系统间信息损失与非平稳性 | |
| AMAFQI[ | 利用批强化学习近似拟合值迭代 |
表5
博弈均衡求解方法"
| 博弈类型 | 优化 | 特点 | 后悔值 | 特点 |
| 两人零和博弈 | LP (NE, CE, CCE)[ | 规划方式求解 | 后悔值匹配(NE, CCE)[ | 后悔值匹配 |
| EGT (NE)[ | 过大间隙技术 | CFR(NE)[ | 最小化反事实后悔值 | |
| MP (NE)[ | 镜像梯度优化 | Hedge (NE)[ | 波尔兹曼式策略更新 | |
| PSD (NE)[ | 投影次梯度下降优化 | MWU (CE)[ | 乘性权重更新 | |
| ED (NE)[ | 可利用度下降优化 | Hart后悔值匹配(CE)[ | Hart后悔值匹配 | |
| 两人一般和博弈 | Lemke-Howson (NE)[ | 互补转轴算法 | SERM (扩展式CE)[ | 放缩延拓后悔值小最小化 |
| SEMILP (NE)[ | 支撑集枚举混合整数线性规划 | |||
| 混合方法(NE)[ | 混合方法 | |||
| CG (CCE)[ | 列生成 | |||
| LP (扩展式CE)[ | 线性规划 | |||
| 多人一般和博弈 | CG (CCE)[ | 列生成 | 后悔值测试(NE)[ | 后悔值测试方法 |
| EAH (CE, 扩展式CE)[ | 利用线性规划对偶的椭球算法 | CFR-S(CCE)[ | 基于采样最小化反事实后悔值 | |
| CFR-Jr(CCE)[ | 基于联合重构最小化反事实后悔值 |
表6
非完美信息博弈求解方法"
| 方法类型 | 方法示例 | 特点 |
| 表格式CFR | CFR[ | 最小化反事实后悔值 |
| CFR+[ | 后悔值计算时只取正值 | |
| 线性CFR[ | 后悔值线性累加 | |
| 折扣CFR[ | 后悔值呈指数因子累加 | |
| 指数CFR[ | 指数式反事实后悔值最小值 | |
| 采样类CFR | 蒙特卡罗CFR[ | 基于蒙特卡罗采样 最小化反事实后悔值 |
| 外采样MCCFR[ | 基于外部节点的蒙特卡罗采样 最小化反事实后悔值 | |
| 结果采样MCCFR[ | 基于结果节点的蒙特卡罗采样 最小化反事实后悔值 | |
| 蒙特卡罗CFR+[ | 基于正后悔值的蒙特卡罗采样 最小化反事实后悔值 | |
| 小批次蒙特卡罗CFR[ | 小批量采样的蒙特卡罗采样 最小化反事实后悔值 | |
| 目标CFR[ | 基于目标采样 最小化反事实后悔值 | |
| 方差约减 蒙特卡罗CFR[ | 方差约减蒙特卡罗采样 最小化反事实后悔值 | |
| CFR-S[ | 基于采样最小化 反事实后悔值 | |
| CFR-Jr[ | 基于联合重构最小化 反事实后悔值 | |
| 懒CFR[ | 懒采样最小化反事实后悔值 | |
| 函数近似CFR | 回归CFR[ | 利用函数近似估计后悔值 |
| f回归CFR[ | 利用函数Φ-f近似估计后悔值匹配 | |
| Φ后悔值[ | 利用函数Φ估计后悔值 | |
| 神经网络CFR | 深度CFR[ | 基于深度神经网络最小化 反事实后悔值 |
| 单深度CFR[ | 基于单个深度神经网络最小化 反事实后悔值 | |
| 反事实后悔值网络[ | 设计基于反事实后悔值的网络 | |
| 双CFR[ | 基于双神经网络最小化 反事实后悔值 | |
| 神经网络CFR[ | 基于神经网络最小化 反事实后悔值 | |
| 强化学习CFR[ | 基于强化学习最小化 反事实后悔值 | |
| 递归CFR[ | 利用递归替代值和自举学习方法最小化 反事实后悔值 | |
| 生成树CFR[ | 基于生成树最小化 反事实后悔值 | |
| 优化方法 | 一阶方法[ | 利用一阶优化 |
| 通用的弱化虚拟对弈[ | 弱化虚拟对弈方式形成通用范式 | |
| 熵距离生成函数[ | 基于熵的距离生成函数 | |
| 扩张距离生成函数[ | 扩张的距离生成函数 | |
| 跟随正则化领先者[ | 利用正则化技术/依赖未来自适应变化的跟随正则化领先者 | |
| 在线镜像下降[ | 利用在线镜像下降/依赖未来自适应变化的在线镜像下降 | |
| 跟随正则化领先者[ | 采用跟随正则化领先者策略 | |
| 应对进步对手的镜像提升[ | 面向策略提升型对手的镜像上升优化 | |
| 强化学习方法 | 神经虚拟自对弈[ | 采用基于神经网络的虚拟自对弈方式 |
| 神经虚拟自对弈[ | 采用蒙特采样/异步采样的神经虚拟自对弈 | |
| 后悔值策略梯度[ | 基于后悔值的策略梯度优化 | |
| 后悔值匹配策略梯度[ | 基于后悔值匹配的策略梯度优化 | |
| 优势基线免模型学习深度后悔最小化[ | 利用优势基函数的免模型强化学习方法 | |
| 递归信念学习[ | 结合深度强化学习与在线搜索方法 | |
| 优势值后悔匹配行动-评估[ | 基于优势值函数的后悔值匹配行动-评估方法 | |
| 基于优势后悔匹配的神经虚拟自对弈[ | 融合优势函数后悔值匹配与神经虚拟自对弈 |

图12
采样类CFR方法"

表7
对抗团队博弈"
| 博弈 | 通信 | 解概念 | 求解方法 |
| 正则式博弈 | 无通信 | TME | 增量策略生成(incremental strategy generation, ISG)[ |
| 有通信 | CTME | 逃逸阻断博弈求解器(escape interdiction game solver, EIGS)[ | |
| 序贯式博弈 | 无通信 | TME | 关联递归异步多参数解聚技术(associated recursive asynchronous multiparametric disaggregation technique,ARAMDT)[ |
| 有事先通信 | TMECor | 关联表示技术(associated representation technique, ART)[ | |
| 有事先和事中通信 | TMECom | 迭代生成可达状态(iteratively generated reachable states, IGRS)[ |

图13
博弈策略学习框架"

表8
策略评估方法"
| 博弈类型 | 策略评估方法 | 特点 |
| 传递性压制博弈 | Elo[ | 仅根据智能体的赢(输)率来评定等级 |
| Glicko[ | 根据智能体的赢(输)率和评定方差来确认等级 | |
| 真实技能[ | 基于高斯因子图和贝叶斯方法估计平均技能水平及不确定 | |
| 循环性压制博弈 | mElo2k[ | 利用Shur和组合Hodge分解构造评定矩阵的低秩近似 |
| 纳什平均[ | 利用原博弈的最大熵纳什均衡(一般为均匀分布)构建纳什平均, 可用于智能体之间的能力对比评估、智能体完成任务能力评估、任务难度评估 | |
| α-排名[ | 利用对战结果构造响应图转换矩阵, 通过计算平稳分布得出策略评定等级 | |
| αα-排名[ | 利用随机优化方法计算平稳分布得出策略评定等级 | |
| RG-UCB[ | 非完全信息条件下, 采用基于响应图的自适变采样方法得出策略评定等级 | |
| IGα-rank[ | 利用信息增益的方式估计平稳分析得出策略评定等级 | |
| OptEval[ | 利用低秩矩阵补全的方式估计平稳分析得出策略评定等级 |

图14
策略提升方法"

表9
策略提升方法"
| 方法类型 | 方法 | 特点 | 方法 | 特点 |
| 自对弈 | 朴素SP[ | 朴素自对弈 | δ均匀采样SP[ | δ均匀采样自对弈 |
| 非对称SP[ | 非对称自对弈 | DO | 双重预言机迭代 | |
| 极小化后悔约束组合[ | 极小极大后悔鲁棒预言机 | 无偏SP[ | 基于无偏估计的自对弈 | |
| 虚拟对弈 | 虚拟对弈[ | 维持对手历史动作的信念,学习应对经验分布的最佳响应 | 虚拟SP[ | 虚拟自对弈 |
| 通用的弱化虚拟对弈[ | 弱化虚拟对弈方式形成通用范式 | 扩展式虚拟对弈[ | 针对扩展式博弈的虚拟对弈 | |
| 平滑虚拟对弈[ | 虚拟对弈策略计算时采用平滑技术 | 随机虚拟对弈[ | 虚拟对弈时考虑随机响应 | |
| 团队虚拟对弈[ | 面向团队对抗的虚拟对弈 | 神经网络对弈[ | 虚拟对弈时策略采样神经网络表示 | |
| 神经虚拟自对弈[ | 采用蒙特采样/异步采样的神经虚拟自对弈 | 多样性虚拟对弈[ | 虚拟对弈时考虑多样性 | |
| 优先级虚拟自对弈[ | 基于优先级的虚拟自对弈 | — | — | |
| 协同对弈 | 协同演化[ | 基于协同的演化计算 | 协同学习[ | 基于协同关系的学习 |
| 种群对弈 | 种群训练自对弈 | 基于种群训练的自对弈 | DO经验博弈理论分析[ | 采用基于双重预言机的经验博弈理论分析方法 |
| 混合预言机/混合对手[ | 利用预言机/对手的混合分布 | 深度认知层次[ | 将深度学习得到的策略划分认知层次 | |
| PSRO[ | 围绕策略空间求解响应预言机 | PSRON[ | 响应纳什均衡的策略空间响应预言机 | |
| PSROrN[ | 响应带修正纳什均衡的策略空间响应预言机 | α-PSRO[ | 加入比例的策略空间响应预言机 | |
| 联合PSRO[ | 面向相关均衡的联合策略空间响应预言机 | 行列式点过程PSRO[ | 基于行列式多样性的策略空间响应预言机 | |
| 管线PSRO[ | 基于并行管线的策略空间响应预言机 | 在线PSRO[ | 面向在线决策的策略空间响应预言机 | |
| 自主PSRO[ | 基于自主元学习的策略空间响应预言机 | 任意时间最优PSRO[ | 基于元策略分布的任意时间最优策略空间响应预言机 | |
| 高效PSRO[ | 基于非约束-约束博弈最小最大优化的探索高效策略空间响应预言机 | 神经种群学习[ | 基于自适变交互图元图求解器的神经种群学习 |
表10
多样性度量"
| 分类 | 度量方法 | 特点 |
| 行为多样性 | 期望基数[ | 利用期望基数 |
| 有质量多样性[ | 设计有质量的多样性 | |
| 期望动作变化[ | 计算动作行为的期望 | |
| 占据测度[ | 基于占据的测度 | |
| 策略多样性 | 有效多样性[ | 针对种群的有效多样性 |
| 极大平均差异[ | 计算平均差异极大值 | |
| 响应多样性[ | 度量最佳响应策略的多样性 | |
| 交互图[ | 构建策略之间的交互图 | |
| 环境多样性 | 泛化界[ | 度量泛化能力 |
| 295 | TIAN Z. Opponent modelling in multi-agent systems[D]. London: University College London, 2021. |
| 296 | WANG T H, DONG H, LESSER V, et al. ROMA: multi-agent reinforcement learning with emergent roles[C]//Proc. of the International Conference on Machine Learning, 2020: 9876-9886. |
| 297 | GONG L X, FENG X C, YE D Z, et al, OptMatch: optimized matchmaking via modeling the high-order interactions on the arena[C]//Proc. of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2020: 2300-2310. |
| 298 | HU H Y, LERER A, PEYSAKHOVICH A, et al. "Other-play" for zero-shot coordination[C]//Proc. of the International Conference on Machine Learning, 2020: 4399-4410. |
| 299 | TREUTLEIN J, DENNIS M, OESTERHELD C, et al. A new formalism, method and open issues for zero-shot coordination[C]//Proc. of the International Conference on Machine Learning, 2021: 10413-10423. |
| 300 | LUCERO C, IZUMIGAWA C, FREDERIKSEN K, et al. Human-autonomy teaming and explainable AI capabilities in RTS games[C]//Proc. of the International Conference on Human-Computer Interaction, 2020: 161-171. |
| 301 | WAYTOWICH N , BARTON S L , LAWHERN V , et al. Grounding natural language commands to StarCraft Ⅱ game states for narration-guided reinforcement learning[J]. Artificial Intelligence and Machine Learning for Multi-Domain Ope-rations Applications, 2019, 11006, 267- 276. |
| 302 | SIU H C, PENA J D, CHANG K C, et al. Evaluation of human-AI teams for learned and rule-based agents in Hanabi[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2107.07630. |
| 303 |
KOTSERUBA I , TSOTSOS J K . 40 years of cognitive architectures: core cognitive abilities and practical applications[J]. Artificial Intelligence Review, 2020, 53 (1): 17- 94.
doi: 10.1007/s10462-018-9646-y |
| 304 | ALEXANDER K . Adversarial reasoning: computational approaches to reading the opponent's mind[M]. Boca Raton: Chapman & Hall/CRC, 2006. |
| 305 | KULKARNI A. Synthesis of interpretable and obfuscatory behaviors in human-aware AI systems[D]. Arizona: Arizona State University, 2020. |
| 306 |
ZHENG Y , HAO J Y , ZHANG Z Z , et al. Efficient policy detecting and reusing for non-stationarity in Markov games[J]. Autonomous Agents and Multi-Agent Systems, 2021, 35 (1): 1- 29.
doi: 10.1007/s10458-020-09478-3 |
| 307 | SHEN M, HOW J P. Safe adaptation in multiagent competition[EB/OL]. [2022-03-12]. http://arxiv.org/abs/2203.07562. |
| 308 | HAWKIN J. Automated abstraction of large action spaces in imperfect information extensive-form games[D]. Edmonton: University of Alberta, 2014. |
| 309 | ABEL D. A theory of abstraction in reinforcement learning[D]. Providence: Brown University, 2020. |
| 310 | YANG Y D, RUI L, LI M N, et al. Mean field multi-agent reinforcement learning[C]//Proc. of the International Conference on Machine Learning, 2018: 5571-5580. |
| 311 | JI K Y. Bilevel optimization for machine learning: algorithm design and convergence analysis[D]. Columbus: Ohio State University, 2020. |
| 312 | BOSSENS D M, TARAPORE D. Quality-diversity meta-evolution: customising behaviour spaces to a meta-objective[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2109.03918v1. |
| 313 | MAJID A Y, SAAYBI S, RIETBERGEN T, et al. Deep reinforcement learning versus evolution strategies: a comparative survey[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2110.01411. |
| 314 | RAMPONI G. Challegens and opportunities in multi-agent reinforcement learnings[D]. Milano: Politecnico Di Milano, 2021. |
| 315 | KHETARPAL K, RIEMER M, RISH I, et al. Towards continual reinforcement learning: a review and perspectives[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2012.13490. |
| 316 |
MENG D Y , ZHAO Q , JIANG L . A theoretical understanding of self-paced learning[J]. Information Sciences, 2017, 414, 319- 328.
doi: 10.1016/j.ins.2017.05.043 |
| 317 | 尹奇跃, 赵美静, 倪晚成, 等. 兵棋推演的智能决策技术与挑战[J]. 自动化学报, 2021, 47 (5): 913- 928. |
| YIN Q Y , ZHAO M J , NI W C , et al. Intelligent decision making technology and challenge of wargame[J]. Acta Automatica Sinica, 2021, 47 (5): 913- 928. | |
| 1 | 黄凯奇, 兴军亮, 张俊格, 等. 人机对抗智能技术[J]. 中国科学: 信息科学, 2020, 50 (4): 540- 550. |
| HUANG K Q , XING J L , ZHANG J G , et al. Intelligent technologies of human-computer gaming[J]. Scientia Sinica Informationics, 2020, 50 (4): 540- 550. | |
| 2 | 谭铁牛. 人工智能: 用AI技术打造智能化未来[M]. 北京: 中国科学技术出版社, 2019. |
| TAN T N . Artificial intelligence: building an intelligent future with AI technologies[M]. Beijing: China Science and Technology Press, 2019. | |
| 3 | WOOLDRIDGE M . An introduction to multiagent systems[M]. Florida: John Wiley & Sons, 2009. |
| 4 | SHOHAM Y , LEYTON-BROWN K . Multiagent systems-algorithmic, game-theoretic, and logical foundations[M]. New York: Cambridge University Press, 2009. |
| 5 | MULLER J P, FISCHER K. Application impact of multi-agent systems and technologies: a survey[M]. SHEHORY O, STURM A. Agent-oriented software engineering. Heidelberg: Springer, 2014: 27-53. |
| 6 | TURING A M . Computing machinery and intelligence[M]. Berlin: Springer, 2009. |
| 7 |
OMIDSHAFIEI S , TUYLS K , CZARNECKI W M , et al. Navigating the landscape of multiplayer games[J]. Nature Communications, 2020, 11 (1): 5603.
doi: 10.1038/s41467-020-19244-4 |
| 8 | TUYLS K, STONE P. Multiagent learning paradigms[C]//Proc. of the European Conference on Multi-Agent Systems and Agreement Technologies, 2017: 3-21. |
| 9 |
SILVER D , SCHRITTWIESER J , SIMONYAN K , et al. Mastering the game of Go without human knowledge[J]. Nature, 2017, 550 (7676): 354- 359.
doi: 10.1038/nature24270 |
| 318 | 程恺, 陈刚, 余晓晗, 等. 知识牵引与数据驱动的兵棋AI设计及关键技术[J]. 系统工程与电子技术, 2021, 43 (10): 2911- 2917. |
| CHENG K , CHEN G , YU X H , et al. Knowledge traction and data-driven wargame AI design and key technologies[J]. Systems Engineering and Electronics, 2021, 43 (10): 2911- 2917. | |
| 319 | 蒲志强, 易建强, 刘振, 等. 知识和数据协同驱动的群体智能决策方法研究综述[J]. 自动化学报, 2022, 48 (3): 627- 643. |
| PU Z Q , YI J Q , LIU Z , et al. Knowledge-based and data-driven integrating methodologies for collective intelligence decision making: a survey[J]. Acta Automatica Sinica, 2022, 48 (3): 627- 643. | |
| 320 | 张驭龙, 范长俊, 冯旸赫, 等. 任务级兵棋智能决策技术框架设计与关键问题分析[J]. 指挥与控制学报, 2024, 10 (1): 19- 25. |
| ZHANG Y L , FAN C J , FENG Y H , et al. Technical framework design and key issues analysis in task-level wargame intelligent decision making[J]. Journal of Command and Control, 2024, 10 (1): 19- 25. | |
| 321 | CHEN L L, LU K, RAJESWARAN A, et al. Decision transformer: reinforcement learning via sequence modeling[C]//Proc. of the 35th Conference on Neural Information Processing Systems, 2021: 15084-15097. |
| 322 | MENG L H, WEN M N, YANG Y D, et al. Offline pre-trained multi-agent decision transformer: one big sequence model conquers all StarCraft Ⅱ tasks[EB/OL]. [2022-01-01]. http://arxiv.org/abs/2112.02845. |
| 323 | ZHENG Q Q, ZHANG A, GROVER A. Online decision transformer[EB/OL]. [2022-03-01]. http://arxiv.org/abs/2202.05607. |
| 324 | MATHIEU M, OZAIR S, SRINIVASAN S, et al. StarCraft Ⅱ unplugged: large scale offline reinforcement learning[C]//Proc. of the Deep RL Workshop NeurIPS 2021, 2021. |
| 325 | SAMVELYAN M, RASHID T, SCHROEDER D W C, et al. The StarCraft multi-agent challenge[C]//Proc. of the 18th International Conference on Autonomous Agents and Multi-agent Systems, 2019: 2186-2188. |
| 10 |
SCHRITTWIESER J , ANTONOGLOU I , HUBERT T , et al. Mastering Atari, Go, Chess and Shogi by planning with a learned model[J]. Nature, 2020, 588 (7839): 604- 609.
doi: 10.1038/s41586-020-03051-4 |
| 11 |
MORAVCIK M , SCHMID M , BURCH N , et al. DeepStack: expert-level artificial intelligence in heads-up no-limit poker[J]. Science, 2017, 356 (6337): 508- 513.
doi: 10.1126/science.aam6960 |
| 12 |
BROWN N , SANDHOLM T . Superhuman AI for multiplayer poker[J]. Science, 2019, 365 (6456): 885- 890.
doi: 10.1126/science.aay2400 |
| 13 | JIANG Q Q, LI K Z, DU B Y, et al. DeltaDou: expert-level Doudizhu AI through self-play[C]//Proc. of the 28th International Joint Conference on Artificial Intelligence, 2019: 1265-1271. |
| 14 | ZHAO D C, XIE J R, MA W Y, et al. DouZero: mastering Doudizhu with self-play deep reinforcement learning[C]//Proc. of the 38th International Conference on Machine Learning, 2021: 12333-12344. |
| 15 | LI J J, KOYAMADA S, YE Q W, et al. Suphx: mastering mahjong with deep reinforcement learning[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2003.13590. |
| 16 |
VINYALS O , BABUSCHKIN I , CZARNECKI W M , et al. Grandmaster level in StarCraft Ⅱ using multi-agent reinforcement learning[J]. Nature, 2019, 575 (7782): 350- 354.
doi: 10.1038/s41586-019-1724-z |
| 17 | WANG X J, SONG J X, QI P H, et al. SCC: an efficient deep reinforcement learning agent mastering the game of StarCraft Ⅱ[C]// Proc. of the 38th International Conference on Machine Learning, 2021, 139: 10905-10915. |
| 18 | BERNER C, BROCKMAN G, CHAN B, et al. Dota 2 with large scale deep reinforcement learning[EB/OL]. [2021-08-01]. http://arxiv.org/abs/1912.06680. |
| 19 |
YE D H , CHEN G B , ZHAO P L , et al. Supervised learning achieves human-level performance in MOBA games: a case study of honor of kings[J]. IEEE Trans.on Neural Networks and Learning Systems, 2022, 33 (3): 908- 918.
doi: 10.1109/TNNLS.2020.3029475 |
| 20 | 中国科学院自动化研究所. 人机对抗智能技术[EB/OL]. [2021-08-01]. http://turingai.ia.ac.cn/. |
| Institute of Automation, Chinese Academy of Science. Intelligent technologies of human-computer gaming[EB/OL]. [2021-08-01]. http://turingai.ia.ac.cn/. | |
| 21 | 凡宁, 朱梦莹, 张强. 远超阿尔法狗?"战颅"成战场辅助决策"最强大脑"[EB/OL]. [2021-08-01]. http://digitalpaper.stdaily.com/http_www.kjrb.com/kjrb/html/2021-04/19/content_466128.htm?div=-1. |
| FAN N, ZHU M Y, ZHANG Q. Way ahead of Alpha Go? "War brain" becomes the "strongest brain" for battlefield decision-making[EB/OL]. [2021-08-01]. http://digitalpaper.stdaily.com/http_www.kjrb.com/kjrb/html/2021-04/19/content_466128.htm?div=-1. | |
| 22 | ERNEST N. Genetic fuzzy trees for intelligent control of unmanned combat aerial vehicles[D]. Cincinnati: University of Cincinnati, 2015. |
| 23 | CLIFF D . Collaborative air combat autonomy program makes strides[J]. Microwave Journal, 2021, 64 (5): 43- 44. |
| 24 |
STONE P , VELOSO M . Multiagent systems: a survey from a machine learning perspective[J]. Autonomous Robots, 2000, 8 (3): 345- 383.
doi: 10.1023/A:1008942012299 |
| 25 |
GORDON G J . Agendas for multi-agent learning[J]. Artificial Intelligence, 2007, 171 (7): 392- 401.
doi: 10.1016/j.artint.2006.12.006 |
| 26 | SHOHAM Y, POWERS R, GRENAGER T. Multi-agent reinforcement learning: a critical survey[R]. San Francisco: Stanford University, 2003. |
| 27 | SHOHAM Y , POWERS R , GRENAGER T . If multi-agent learning is the answer, what is the question?[J]. Artificial Intelligence, 2006, 171 (7): 365- 377. |
| 28 |
STONE P . Multiagent learning is not the answer. It is the question[J]. Artificial Intelligence, 2007, 171 (7): 402- 405.
doi: 10.1016/j.artint.2006.12.005 |
| 29 |
TOSIC P , VILALTA R . A unified framework for reinforcement learning, co-learning and meta-learning how to coordinate in collaborative multi-agent systems[J]. Procedia Computer Science, 2010, 1 (1): 2217- 2226.
doi: 10.1016/j.procs.2010.04.248 |
| 30 |
TUYLS K , WEISS G . Multiagent learning: basics, challenges, and prospects[J]. AI Magazine, 2012, 33 (3): 41- 52.
doi: 10.1609/aimag.v33i3.2426 |
| 31 | KENNEDY J. Swarm intelligence[M]. Handbook of nature-inspired and innovative computing. Bostonm: Springer, 2006: 187-219. |
| 32 |
TUYLS K , PARSONS S . What evolutionary game theory tells us about multiagent learning[J]. Artificial Intelligence, 2007, 171 (7): 406- 416.
doi: 10.1016/j.artint.2007.01.004 |
| 33 | SILVA F, COSTA A. Transfer learning for multiagent reinforcement learning systems[C]//Proc. of the 25th International Joint Conference on Artificial Intelligence, 2016: 3982-3983. |
| 34 | HERNANDEZ-LEAL P, KAISERS M, BAARSLAG T, et al. A survey of learning in multiagent environments: dealing with non-stationarity[EB/OL]. [2021-08-01]. http://arxiv.org/abs/1707.09183v1. |
| 35 |
ALBRECHT S V , STONE P . Autonomous agents modelling other agents: a comprehensive survey and open problems[J]. Artificial Intelligence, 2018, 258, 66- 95.
doi: 10.1016/j.artint.2018.01.002 |
| 36 | JANT H P, TUYLS K, PANAIT L, et al. An overview of cooperative and competitive multiagent learning[C]//Proc. of the International Workshop on Learning and Adaption in Multi-Agent Systems, 2005. |
| 37 |
PANAIT L , LUKE S . Cooperative multi-agent learning: the state of the art[J]. Autonomous Agents and Multi-Agent Systems, 2005, 11 (3): 387- 434.
doi: 10.1007/s10458-005-2631-2 |
| 38 | BUSONIU L , BABUSKA R , SCHUTTER B D . A comprehensive survey of multiagent reinforcement learning[J]. IEEE Trans.on Systems, Man & Cybernetics: Part C, 2008, 38 (2): 156- 172. |
| 39 |
HERNANDEZ-LEAL P , KARTAL B , TAYLOR M E . A survey and critique of multiagent deep reinforcement learning[J]. Autonomous Agents and Multi-Agent Systems, 2019, 33 (6): 750- 797.
doi: 10.1007/s10458-019-09421-1 |
| 40 | OROOJLOOY A, HAJINEZHAD D. A review of cooperative multi-agent deep reinforcement learning[EB/OL]. [2021-08-01]. http://arxiv.org/abs/1908.03963. |
| 41 | ZHANG K Q, YANG Z R, BAAR T. Multi-agent reinforcement learning: a selective overview of theories and algorithms[EB/OL]. [2021-08-01]. http://arxiv.org/abs/1911.10635. |
| 42 |
GRONAUER S , DIEPOLD K . Multi-agent deep reinforcement learning: a survey[J]. Artificial Intelligence Review, 2022, 55 (2): 895- 943.
doi: 10.1007/s10462-021-09996-w |
| 43 |
DU W , DING S F . A survey on multi-agent deep reinforcement learning: from the perspective of challenges and applications[J]. Artificial Intelligence Review, 2021, 54 (5): 3215- 3238.
doi: 10.1007/s10462-020-09938-y |
| 44 | 吴军, 徐昕, 王健, 等. 面向多机器人系统的增强学习研究进展综述[J]. 控制与决策, 2011, 26 (11): 1601- 1610. |
| WU J , XU X , WANG J , et al. Recent advances of reinforcement learning in multi-robot systems: a survey[J]. Control and Decision, 2011, 26 (11): 1601- 1610. | |
| 45 | 杜威, 丁世飞. 多智能体强化学习综述[J]. 计算机科学, 2019, 46 (8): 1- 8. |
| DU W , DING S F . Overview on multi-agent reinforcement learning[J]. Computer Science, 2019, 46 (8): 1- 8. | |
| 46 | 殷昌盛, 杨若鹏, 朱巍, 等. 多智能体分层强化学习综述[J]. 智能系统学报, 2020, 15 (4): 646- 655. |
| YIN C S , YANG R P , ZHU W , et al. A survey on multi-agent hierarchical reinforcement learning[J]. CAAI Transactions on Intelligent Systems, 2020, 15 (4): 646- 655. | |
| 47 | 梁星星, 冯旸赫, 马扬, 等. 多Agent深度强化学习综述[J]. 自动化学报, 2020, 46 (12): 2537- 2557. |
| LIANG X X , FENG Y H , MA Y , et al. Deep multi-agent reinforcement learning: a survey[J]. Acta Automatica Sinica, 2020, 46 (12): 2537- 2557. | |
| 48 | 孙长银, 穆朝絮. 多智能体深度强化学习的若干关键科学问题[J]. 自动化学报, 2020, 46 (7): 1301- 1312. |
| SUN C Y , MU C X . Important scientific problems of multi-agent deep reinforcement learning[J]. Acta Automatica Sinica, 2020, 46 (7): 1301- 1312. | |
| 49 |
MATIGNON L , LAURENT G J , LE F P . Independent reinforcement learners in cooperative Markov games: a survey regarding coordination problems[J]. The Knowledge Engineering Review, 2012, 27 (1): 1- 31.
doi: 10.1017/S0269888912000057 |
| 50 | NOWE A , VRANCX P , HAUWERE Y M D . Game theory and multi-agent reinforcement learning[M]. Berlin: Springer, 2012. |
| 51 | LU Y L, YAN K. Algorithms in multi-agent systems: a holistic perspective from reinforcement learning and game theory[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2001.06487. |
| 52 | YANG Y D, WANG J. An overview of multi-agent reinforcement learning from game theoretical perspective[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2011.00583v3s. |
| 53 | BLOEMBERGEN D , TUYLS K , HENNES D , et al. Evolutionary dynamics of multi-agent learning: a survey[J]. Artificial Intelligence, 2015, 53 (1): 659- 697. |
| 54 | WONG A, BACK T, ANNA V, et al. Multiagent deep reinforcement learning: challenges and directions towards human-like approaches[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2106.15691. |
| 55 | OLIEHOEK F A , AMATO C . A concise introduction to decentralized POMDPs[M]. Berlin: Springer, 2016. |
| 56 |
DOSHI P , ZENG Y F , CHEN Q Y . Graphical models for interactive POMDPs: representations and solutions[J]. Autonomous Agents and Multi-Agent Systems, 2009, 18 (3): 376- 386.
doi: 10.1007/s10458-008-9064-7 |
| 57 |
SHAPLEY L S . Stochastic games[J]. National Academy of Sciences of the United States of America, 1953, 39 (10): 1095- 1100.
doi: 10.1073/pnas.39.10.1095 |
| 58 | LITTMAN M L. Markov games as a framework for multi-agent reinforcement learning[C]//Proc. of the 11th International Conference on International Conference on Machine Learning, 1994: 157-163. |
| 59 |
KOVAIK V , SCHMID M , BURCH N , et al. Rethinking formal models of partially observable multiagent decision making[J]. Artificial Intelligence, 2022, 303, 103645.
doi: 10.1016/j.artint.2021.103645 |
| 60 | LOCKHART E, LANCTOT M, PEROLAT J, et al. Computing approximate equilibria in sequential adversarial games by exploitability descent[EB/OL]. [2021-08-01]. http://arxiv.org/abs/1903.05614. |
| 61 | CUI Q, YANG L F. Minimax sample complexity for turn-based stochastic game[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2011.14267. |
| 62 | HERNANDEZ D, GBADAMOSI C, GOODMAN J, et al. Metagame autobalancing for competitive multiplayer games[C]// Proc. of the IEEE Conference on Games, 2020: 275-282. |
| 63 | WELLMAN M P. Methods for empirical game-theoretic analysis[C]//Proc. of the 21st National Conference on Artificial Intelligence, 2006: 1552-1555. |
| 64 |
JIANG X , LIM L H , YAO Y , et al. Statistical ranking and combinatorial Hodge theory[J]. Mathematical Programming, 2011, 127 (1): 203- 244.
doi: 10.1007/s10107-010-0419-x |
| 65 |
CANDOGAN O , MENACHE I , OZDAGLAR A , et al. Flows and decompositions of games: harmonic and potential games[J]. Mathematics of Operations Research, 2011, 36 (3): 474- 503.
doi: 10.1287/moor.1110.0500 |
| 66 |
HWANG S H , REY-BELLET L . Strategic decompositions of normal form games: zero-sum games and potential games[J]. Games and Economic Behavior, 2020, 122, 370- 390.
doi: 10.1016/j.geb.2020.05.003 |
| 67 | BALDUZZI D, GARNELO M, BACHRACH Y, et al. Open-ended learning in symmetric zero-sum games[C]//Proc. of the International Conference on Machine Learning, 2019: 434-443. |
| 68 | CZARNECKI W M, GIDEL G, TRACEY B, et al. Real world games look like spinning tops[C]//Proc. of the 34th International Conference on Neural Information Processing Systems, 2020: 17443-17454. |
| 69 | SANJAYA R, WANG J, YANG Y D. Measuring the non-transitivity in chess[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2110.11737. |
| 70 |
TUYLS K , PEROLAT J , LANCTOT M , et al. Bounds and dynamics for empirical game theoretic analysis[J]. Autonomous Agents and Multi-Agent Systems, 2020, 34 (1): 7.
doi: 10.1007/s10458-019-09432-y |
| 71 | VIQUEIRA E A, GREENWALD A, COUSINS C, et al. Learning simulation-based games from data[C]//Proc. of the 18th International Conference on Autonomous Agents and Multi Agent Systems, 2019: 1778-1780. |
| 72 | ROUGHGARDEN T . Twenty lectures on algorithmic game theory[M]. New York: Cambridge University Press, 2016. |
| 73 | BLUM A, HAGHTALAB N, HAJIAGHAYI M T, et al. Computing Stackelberg equilibria of large general-sum games[C]// Proc. of the International Symposium on Algorithmic Game Theory, 2019: 168-182. |
| 74 | MILEC D, CERNY J, LISY V, et al. Complexity and algorithms for exploiting quantal opponents in large two-player games[C]//Proc. of the AAAI Conference on Artificial Intelligence, 2021: 5575-5583. |
| 75 | BALDUZZI D, TUYLS K, PEROLAT J, et al. Re-evaluating evaluation[C]//Proc. of the 32nd International Conference on Neural Information Processing Systems, 2018: 3272-3283. |
| 76 | LI S H, WU Y, CUI X Y, et al. Robust multi-agent reinforcement learning via minimax deep deterministic policy gradient[C]// Proc. of the AAAI Conference on Artificial Intelligence, 2019: 4213-4220. |
| 77 | YABU Y, YOKOO M, IWASAKI A. Multiagent planning with trembling-hand perfect equilibrium in multiagent POMDPs[C]// Proc. of the Pacific Rim International Conference on Multi-Agents, 2017: 13-24. |
| 78 | GHOROGHI A. Multi-games and Bayesian Nash equilibriums[D]. London: University of London, 2015. |
| 79 |
XU X , ZHAO Q . Distributed no-regret learning in multi-agent systems: challenges and recent developments[J]. IEEE Signal Processing Magazine, 2020, 37 (3): 84- 91.
doi: 10.1109/MSP.2020.2973963 |
| 80 | SUN Y , WEI X , YAO Z H , et al. Analysis of network attack and defense strategies based on Pareto optimum[J]. Electro-nics, 2018, 7 (3): 36. |
| 81 | DENG X T, LI N Y, MGUNI D, et al. On the complexity of computing Markov perfect equilibrium in general-sum stochastic games[EB/OL]. [2021-11-01]. http://arxiv.org/abs/2109.01795. |
| 82 |
BASILICO N , CELLI A , GATTI N , et al. Computing the team-maxmin equilibrium in single-team single-adversary team games[J]. Intelligenza Artificiale, 2017, 11 (1): 67- 79.
doi: 10.3233/IA-170107 |
| 83 | CELLI A, GATTI N. Computational results for extensive-form adversarial team games[EB/OL]. [2021-08-01]. http://arxiv.org/abs/1711.06930. |
| 84 | ZHANG Y Z, AN B. Computing team-maxmin equilibria in zero-sum multiplayer extensive-form games[C]//Proc. of the AAAI Conference on Artificial Intelligence, 2020: 2318-2325. |
| 85 | LI S X, ZHANG Y Z, WANG X R, et al. CFR-MIX: solving imperfect information extensive-form games with combinatorial action space[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2105.08440. |
| 86 | PROBO G. Multi-team games in adversarial settings: ex-ante coordination and independent team members algorithms[D]. Milano: Politecnico Di Milano, 2019. |
| 87 | ORTIZ L E, SCHAPIRE R E, KAKADE S M. Maximum entropy correlated equilibria[C]//Proc. of the 11th International Conference on Artificial Intelligence and Statistics, 2007: 347-354. |
| 88 | GEMP I, SAVANI R, LANCTOT M, et al. Sample-based approximation of Nash in large many-player games via gradient descent[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2106.01285. |
| 89 | FARINA G, BIANCHI T, SANDHOLM T. Coarse correlation in extensive-form games[C]//Proc. of the AAAI Conference on Artificial Intelligence, 2020: 1934-1941. |
| 90 | FARINA G, CELLI A, MARCHESI A, et al. Simple uncoupled no-regret learning dynamics for extensive-form correlated equilibrium[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2104.01520. |
| 91 | XIE Q M, CHEN Y D, WANG Z R, et al. Learning zero-sum simultaneous-move Markov games using function approximation and correlated equilibrium[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2002.07066. |
| 92 |
HUANG S J , YI P . Distributed best response dynamics for Nash equilibrium seeking in potential games[J]. Control Theory and Technology, 2020, 18 (3): 324- 332.
doi: 10.1007/s11768-020-9204-4 |
| 93 | BOSANSKY B , KIEKINTVELD C , LISY V , et al. An exact double-oracle algorithm for zero-sum extensive-form games with imperfect information[J]. Journal of Artificial Intelligence Research, 2014, 51 (1): 829- 866. |
| 94 |
HEINRICH T , JANG Y J , MUNGO C . Best-response dyna-mics, playing sequences, and convergence to equilibrium in random games[J]. International Journal of Game Theory, 2023, 52, 703- 735.
doi: 10.1007/s00182-023-00837-4 |
| 95 | FARINA G, CELLI A, MARCHESI A, et al. Simple uncoupled no-regret learning dynamics for extensive-form correlated equilibrium[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2104.01520. |
| 96 | HU S Y, LEUNG C W, LEUNG H F, et al. The evolutionary dynamics of independent learning agents in population games[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2006.16068. |
| 97 | LEONARDOS S, PILIOURAS G. Exploration-exploitation in multi-agent learning: catastrophe theory meets game theory[C]// Proc. of the AAAI Conference on Artificial Intelligence, 2021: 11263-11271. |
| 98 | POWERS R, SHOHAM Y. New criteria and a new algorithm for learning in multi-agent systems[C]//Proc. of the 17th International Conference on Neural Information Processing Systems, 2004: 1089-1096. |
| 99 | DIGIOVANNI A, ZELL E C. Survey of self-play in reinforcement learning[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2107.02850. |
| 100 | BOWLING M. Multiagent learning in the presence of agents with limitations[D]. Pittsburgh: Carnegie Mellon University, 2003. |
| 101 |
BOWLING M H , VELOSO M M . Multi-agent learning using a variable learning rate[J]. Artificial Intelligence, 2002, 136 (2): 215- 250.
doi: 10.1016/S0004-3702(02)00121-2 |
| 102 | BOWLING M. Convergence and no-regret in multiagent learning[C]//Proc. of the 17th International Conference on Neural Information Processing Systems, 2004: 209-216. |
| 103 | KAPETANAKIS S, KUDENKO D. Reinforcement learning of coordination in heterogeneous cooperative multi-agent systems[C]//Proc. of the 3rd International Joint Conference on Autonomous Agents and Multiagent Systems, 2004: 1258-1259. |
| 104 | DAI Z X, CHEN Y Z, LOW K H, et al. R2-B2: recursive reasoning-based Bayesian optimization for no-regret learning in games[C]//Proc. of the International Conference on Machine Learning, 2020: 2291-2301. |
| 105 | FREEMAN R, PENNOCK D M, PODIMATA C, et al. No-regret and incentive-compatible online learning[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2002.08837. |
| 106 |
LITTMAN M L . Value-function reinforcement learning in Markov games[J]. Journal of Cognitive Systems Research, 2001, 2 (1): 55- 66.
doi: 10.1016/S1389-0417(01)00015-8 |
| 107 | FOERSTER J N, CHEN R Y, AL-SHEDIVAT M, et al. Learning with opponent-learning awareness[EB/OL]. [2021-08-01]. http://arxiv.org/abs/1709.04326. |
| 108 | RDULESCU R, VERSTRAETEN T, ZHANG Y, et al. Opponent learning awareness and modelling in multi-objective normal form games[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2011.07290. |
| 109 | RONEN I B , MOSHE T . R-MAX: a general polynomial time algorithm for near-optimal reinforcement learning[J]. Journal of Machine Learning Research, 2002, 3 (10): 213- 231. |
| 110 | HIMABINDU L, ECE K, RICH C, et al. Identifying unknown unknowns in the open world: representations and policies for guided exploration[C]//Proc. of the 31st AAAI Conference on Artificial Intelligence, 2017: 2124-2132. |
| 111 | PABLO H, MICHAEL K. Learning against sequential opponents in repeated stochastic games[C]//Proc. of the 3rd Multi-Disciplinary Conference on Reinforcement Learning and Decision Making, 2017. |
| 112 |
PABLO H , YUSEN Z , MATTHEW E , et al. Efficiently detecting switches against non-stationary opponents[J]. Auto- nomous Agents and Multi-Agent Systems, 2017, 31 (4): 767- 789.
doi: 10.1007/s10458-016-9352-6 |
| 113 | FRIEDRICH V D O, MICHAEL K, TIM M. The minds of many: opponent modelling in a stochastic game[C]//Proc. of the 26th International Joint Conference on Artificial Intelligence, 2017: 3845-3851. |
| 114 | BAKKES S , SPRONCK P , HERIK H . Opponent modelling for case-based adaptive game AI[J]. Entertainment Computing, 2010, 1 (1): 27- 37. |
| 115 | PAPOUDAKIS G, CHRISTIANOS F, RAHMAN A, et al. Dealing with non-stationarity in multi-agent deep reinforcement learning[EB/OL]. [2021-08-01]. http://arxiv.org/abs/1906.04737. |
| 116 |
DASKALAKIS C , GOLDBERG P W , PAPADIMITRIOU C H . The complexity of computing a Nash equilibrium[J]. SIAM Journal on Computing, 2009, 39 (1): 195- 259.
doi: 10.1137/070699652 |
| 117 | CONITZER V, SANDHOLM T. Complexity results about Nash equilibria[EB/OL]. [2021-08-01]. http://arxiv.org/abs/0205074. |
| 118 |
CONITZER V , SANDHOLM T . New complexity results about Nash equilibria[J]. Games and Economic Behavior, 2008, 63 (2): 621- 641.
doi: 10.1016/j.geb.2008.02.015 |
| 119 | ZHANG Y Z. Computing team-maxmin equilibria in zero-sum multiplayer games[D]. Singapore: Nanyang Technological University, 2020. |
| 120 | LAUER M, RIEDMILLER M. An algorithm for distributed reinforcement learning in cooperative multi-agent systems[C]// Proc. of the 17th International Conference on Machine Learning, 2000: 535-542. |
| 121 | CLAUS C, BOUTILIER C. The dynamics of reinforcement learning in cooperative multiagent system[C]//Proc. of the 15th National/10th Conference on Artificial Intelligence/Innovative Applications of Artificial Intelligence, 1998: 746-752. |
| 122 | WANG X F, SANDHOLM T. Reinforcement learning to play an optimal Nash equilibrium in team Markov games[C]//Proc. of the 15th International Conference on Neural Information Processing Systems, 2002: 1603-1610. |
| 123 | ARSLAN G , YUKSEL S . Decentralized q-learning for stochastic teams and games[J]. IEEE Trans.on Automatic Control, 2016, 62 (4): 1545- 1558. |
| 124 | HU J L , WELLMAN M P . Nash Q-learning for general-sum stochastic games[J]. Journal of Machine Learning Research, 2003, 4 (11): 1039- 1069. |
| 125 | GREENWALD A, HALL L, SERRANO R. Correlated-q learning[C]//Proc. of the 20th International Conference on Machine Learning, 2003: 242-249. |
| 126 | KONONEN V . Asymmetric multi-agent reinforcement learning[J]. Web Intelligence and Agent Systems, 2004, 2 (2): 105- 121. |
| 127 | LITTMAN M L. Friend-or-foe q-learning in general-sum games[C]//Proc. of the 18th International Conference on Machine Learning, 2001: 322-328. |
| 128 | SINGH S, KEARNS M, MANSOUR Y. Nash convergence of gradient dynamics in iterated general-sum games[EB/OL]. [2021-08-01]. http://arxiv.org/abs/1301.3892. |
| 129 | ZINKEVICH M. Online convex programming and generalized infinitesimal gradient ascent[C]//Proc. of the 20th International Conference on Machine Learning, 2003: 928-935. |
| 130 |
CONITZER V , SANDHOLM T . AWESOME: a general multiagent learning algorithm that converges in self-play and learns a best response against stationary opponents[J]. Machine Learning, 2007, 67, 23- 43.
doi: 10.1007/s10994-006-0143-1 |
| 131 | TAN M. Multi-agent reinforcement learning: independent vs. cooperative agents[C]//Proc. of the 10th International Conference on Machine Learning, 1993: 330-337. |
| 132 | LAETITIA M, GUILLAUME L, NADINE L F. Hysteretic Q learning: an algorithm for decentralized reinforcement learning in cooperative multi-agent teams[C]//Proc. of the IEEE/RSJ International Conference on Intelligent Robots and Systems, 2007: 64-69. |
| 133 | MATIGNON L, LAURENT G, LE F P N. A study of FMQ heuristic in cooperative multi-agent games[C]//Proc. of the 7th International Conference on Autonomous Agents and Multiagent Systems, 2008: 77-91. |
| 134 | WEI E , LUKE S . Lenient learning in independent-learner stochastic cooperative games[J]. Journal Machine Learning Research, 2016, 17 (1): 2914- 2955. |
| 135 | PALMER G. Independent learning approaches: overcoming multi-agent learning pathologies in team-games[D]. Liverpool: University of Liverpool, 2020. |
| 136 | SUKHBAATAR S, FERGUS R. Learning multiagent communication with backpropagation[C]//Proc. of the 30th International Conference on Neural Information Processing Systems, 2016: 2244-2252. |
| 137 | PENG P, WEN Y, YANG Y D, et al. Multiagent bidirectionally-coordinated nets: emergence of human-level coordination in learning to play StarCraft combat games[EB/OL]. [2021-08-01]. http://arxiv.org/abs/1703.10069. |
| 138 | JAKOB N F, GREGORY F, TRIANTAFYLLOS A, et al, Counterfactual multi-agent policy gradients[C]//Proc. of the AAAI Conference on Artificial Intelligence, 2018: 2974-2982. |
| 139 | LOWE R, WU Y, TAMAR A, et al. Multi-agent actor-critic for mixed cooperative-competitive environments[C]//Proc. of the 31st International Conference on Neural Information Processing Systems, 2017: 6382-6393. |
| 140 | WEI E, WICKE D, FREELAN D, et al, Multiagent soft q-learning[EB/OL]. [2021-08-01]. http://arxiv.org/abs/1804.09817. |
| 141 | SUNEHAG P, LEVER G, GRUSLYS A, et al. Value-decomposition networks for cooperative multi-agent learning based on team reward[C]//Proc. of the 17th International Conference on Autonomous Agents and Multi-Agent Systems, 2018: 2085-2087. |
| 142 | RASHID T, SAMVELYAN M, WITT C S, et al. Qmix: monotonic value function factorisation for deep multi-agent reinforcement learning[C]//Proc. of the International Conference on Machine Learning, 2018: 4292-4301. |
| 143 | MAHAJAN A, RASHID T, SAMVELYAN M, et al. MAVEN: multi-agent variational exploration[EB/OL]. [2021-08-01]. http://arxiv.org/abs/1910.07483. |
| 144 | SON K, KIM D, KANG W J, et al. Qtran: learning to factorize with transformation for cooperative multi-agent reinforcement learning[C]//Proc. of the International Conference on Machine Learning, 2019: 5887-5896. |
| 145 | YANG Y D, WEN Y, CHEN L H, et al. Multi-agent determinantal q-learning[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2006.01482. |
| 146 | YU C, VELU A, VINITSKY E, et al. The surprising effectiveness of MAPPO in cooperative, multi-agent games[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2103.01955. |
| 147 | WANG J H, ZHANG Y, KIM T K, et al. Shapley q-value: a local reward approach to solve global reward games[C]//Proc. of the AAAI Conference on Artificial Intelligence, 2020: 7285-7292. |
| 148 | RIEDMILLER M. Neural fitted Q iteration-first experiences with a data efficient neural reinforcement learning method[C]// Proc. of the European Conference on Machine Learning, 2005: 317-328. |
| 149 |
NEDIC A , OLSHEVSKY A , SHI W . Achieving geometric convergence for distributed optimization over time-varying graphs[J]. SIAM Journal on Optimization, 2017, 27 (4): 2597- 2633.
doi: 10.1137/16M1084316 |
| 150 | ZHANG K Q, YANG Z R, LIU H, et al. Fully decentralized multi-agent reinforcement learning with networked agents[EB/OL]. [2021-08-01]. http://arxiv.org/abs/1802.08757. |
| 151 | QU G N, LIN Y H, WIERMAN A, et al. Scalable multi-agent reinforcement learning for networked systems with ave-rage reward[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2006.06626. |
| 152 | CHU T, CHINCHALI S, KATTI S. Multi-agent reinforcement learning for networked system control[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2004.01339. |
| 153 | LESAGE-LANDRY A, CALLAWAY D S. Approximate multi-agent fitted q iteration[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2104.09343. |
| 154 |
ZHANG K Q , YANG Z R , LIU H , et al. Finite-sample analysis for decentralized batch multi-agent reinforcement learning with networked agents[J]. IEEE Trans.on Automatic Control, 2021, 66 (12): 5925- 5940.
doi: 10.1109/TAC.2021.3049345 |
| 155 | SANDHOLM T, GILPIN A, CONITZER V. Mixed-integer programming methods for finding Nash equilibria[C]//Proc. of the 20th National Conference on Artificial Intelligence, 2005: 495-501. |
| 156 |
YU N . Excessive gap technique in nonsmooth convex minimization[J]. SIAM Journal on Optimization, 2005, 16 (1): 235- 249.
doi: 10.1137/S1052623403422285 |
| 157 | SUN Z F, NAKHAI M R. An online mirror-prox optimization approach to proactive resource allocation in MEC[C]//Proc. of the IEEE International Conference on Communications, 2020. |
| 158 |
AMIR B , MARC T . Mirror descent and nonlinear projected subgradient methods for convex optimization[J]. Operations Research Letters, 2003, 31 (3): 167- 175.
doi: 10.1016/S0167-6377(02)00231-6 |
| 159 | LOCKHART E, LANCTOT M, PEROLAT J, et al. Computing approximate equilibria in sequential adversarial games by exploitability descent[EB/OL]. [2021-08-01]. http://arxiv.org/abs/1903.05614. |
| 160 |
LAN S . Geometrical regret matching: a new dynamics to Nash equilibrium[J]. AIP Advances, 2020, 10 (6): 065033.
doi: 10.1063/5.0012735 |
| 161 |
VON S B , FORGES F . Extensive-form correlated equilibrium: definition and computational complexity[J]. Mathematics of Operations Research, 2008, 33 (4): 1002- 1022.
doi: 10.1287/moor.1080.0340 |
| 326 | LANCTOT M, LOCKHART E, LESPIAU J B, et al. OpenSpiel: a framework for reinforcement learning in games[EB/OL]. [2022-03-01]. http://arxiv.org/abs/1908.09453. |
| 327 | TERRY J K, BLACK B, GRAMMEL N, et al. PettingZoo: gym for multi-agent reinforcement learning[EB/OL]. [2022-03-01]. http://arxiv.org/abs/2009.14471. |
| 328 | PRETORIUS A, TESSERA K, SMIT A P, et al. MAVA: a research framework for distributed multi-agent reinforcement learning[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2107.01460. |
| 329 | YAO M, YIN Q Y, YANG J, et al. The partially observable asynchronous multi-agent cooperation challenge[EB/OL]. [2022-03-01]. http://arxiv.org/abs/2112.03809. |
| 330 | MORITZ P, NISHIHARA R, WANG S, et al. Ray: a distributed framework for emerging AI applications[C]//Proc. of the 13th USENIX Symposium on Operating Systems Design and Implementation, 2018: 561-577. |
| 331 | ESPEHOLT L, MARINIER R, STANCZYK P, et al. SEED RL: scalable and efficient deep-RL with accelerated central inference[EB/OL]. [2022-03-01]. http://arxiv.org/abs/1910.06591. |
| 332 | MOHANTY S, NYGREN E, LAURENT F, et al. Flatland-RL: multi-agent reinforcement learning on trains[EB/OL]. [2022-03-01]. http://arxiv.org/abs/2012.05893. |
| 333 | SUN P, XIONG J C, HAN L, et al. Tleague: a framework for competitive self-play based distributed multi-agent reinforcement learning[EB/OL]. [2022-03-01]. http://arxiv.org/abs/2011.12895. |
| 334 | ZHOU M, WAN Z Y, WANG H J, et al. MALib: a parallel framework for population-based multi-agent reinforcement learning[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2106.07551. |
| 162 | CESA-BIANCHI N , LUGOSI G . Prediction, learning, and games[M]. Cambridge: Cambridge University Press, 2006. |
| 163 | FREUND Y , SCHAPIRE R E . Adaptive game playing using multiplicative weights[J]. Games and Economic Behavior, 1999, 29 (1/2): 79- 103. |
| 164 |
HART S , MAS-COLELL A . A general class of adaptive strategies[J]. Journal of Economic Theory, 2001, 98 (1): 26- 54.
doi: 10.1006/jeth.2000.2746 |
| 165 |
LEMKE C E , HOWSON J T . Equilibrium points of bimatrix games[J]. Journal of the Society for Industrial and Applied Mathematics, 1964, 12 (2): 413- 423.
doi: 10.1137/0112033 |
| 166 |
PORTER R , NUDELMAN E , SHOHAM Y . Simple search methods for finding a Nash equilibrium[J]. Games and Economic Behavior, 2008, 63 (2): 642- 662.
doi: 10.1016/j.geb.2006.03.015 |
| 167 | CEPPI S, GATTI N, PATRINI G, et al. Local search techniques for computing equilibria in two-player general-sum strategic form games[C]//Proc. of the 9th International Conference on Autonomous Agents and Multiagent Systems, 2010: 1469-1470. |
| 168 | CELLI A, CONIGLIO S, GATTI N. Computing optimal ex ante correlated equilibria in two-player sequential games[C]//Proc. of the 18th International Conference on Autonomous Agents and Multiagent Systems, 2019: 909-917. |
| 169 |
VON S B , FORGES F . Extensive-form correlated equilibrium: definition and computational complexity[J]. Mathematics of Operations Research, 2008, 33 (4): 1002- 1022.
doi: 10.1287/moor.1080.0340 |
| 170 | FARINA G, LING C K, FANG F, et al. Efficient regret minimization algorithm for extensive-form correlated equilibrium[C]//Proc. of the 33rd International Conference on Neural Information Processing Systems, 2019: 5186-5196. |
| 171 | PAPADIMITRIOU C H , ROUGHGARDEN T . Computing correlated equilibria in multi-player games[J]. Journal of the ACM, 2008, 55 (3): 14. |
| 172 | CELLI A, MARCHESI A, BIANCHI T, et al. Learning to correlate in multi-player general-sum sequential games[C]//Proc. of the 33rd International Conference on Neural Information Processing Systems, 2019: 13076-13086. |
| 173 | JIANG A X , KEVIN L B . Polynomial-time computation of exact correlated equilibrium in compact games[J]. Games and Economic Behavior, 2015, 100 (91): 119- 126. |
| 174 | FOSTER D P , YOUNG H P . Regret testing: learning to play Nash equilibrium without knowing you have an opponent[J]. Theoretical Economics, 2006, 1 (3): 341- 367. |
| 175 | ABERNETHY J, BARTLETT P L, HAZAN E. Blackwell approachability and no-regret learning are equivalent[C]//Proc. of the 24th Annual Conference on Learning Theory, 2011: 27-46. |
| 176 | FARINA G, KROER C, SANDHOLM T. Faster game solving via predictive Blackwell approachability: connecting regret matching and mirror descent[C]//Proc. of the AAAI Conference on Artificial Intelligence, 2021: 5363-5371. |
| 177 | SRINIVASAN S, LANCTOT M, ZAMBALDI V, et al. Actor-critic policy optimization in partially observable multiagent environments[C]//Proc. of the 32nd International Conference on Neural Information Processing Systems, 2018: 3426-3439. |
| 178 | ZINKEVICH M, JOHANSON M, BOWLING M, et al, Regret minimization in games with incomplete information[C]//Proc. of the 20th International Conference on Neural Information Processing Systems, 2007: 1729-1736. |
| 179 |
BOWLING M , BURCH N , JOHANSON M , et al. Heads-up limit hold'em poker is solved[J]. Science, 2015, 347 (6218): 145- 149.
doi: 10.1126/science.1259433 |
| 180 | BROWN N, LERER A, GROSS S, et al. Deep counterfactual regret minimization[C]//Proc. of the International Conference on Machine Learning, 2019: 793-802. |
| 181 | BROWN N, SANDHOLM T. Solving imperfect-information games via discounted regret minimization[C]//Proc. of the AAAI Conference on Artificial Intelligence, 2019: 1829-1836. |
| 182 | LI H L, WANG X, QI S H, et al. Solving imperfect-information games via exponential counterfactual regret minimization[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2008.02679. |
| 183 | LANCTOT M, WAUGH K, ZINKEVICH M, et al. Monte Carlo sampling for regret minimization in extensive games[C]// Proc. of the 22nd International Conference on Neural Information Processing Systems, 2009: 1078-1086. |
| 184 | LI H, HU K L, ZHANG S H, et al. Double neural counterfactual regret minimization[EB/OL]. [2021-08-01]. http://arxiv.org/abs/1812.10607. |
| 185 | JACKSON E G. Targeted CFR[C]//Proc. of the 31st AAAI Conference on Artificial Intelligence, 2017. |
| 186 | SCHMID M, BURCH N, LANCTOT M, et al. Variance reduction in Monte Carlo counterfactual regret minimization (VR-MCCFR) for extensive form games using baselines[C]//Proc. of the AAAI Conference on Artificial Intelligence, 2019: 2157-2164. |
| 187 | ZHOU Y C, REN T Z, LI J L, et al. Lazy-CFR: a fast regret minimization algorithm for extensive games with imperfect information[EB/OL]. [2021-08-01]. http://arxiv.org/abs/1810.04433. |
| 188 | WAUGH K, MORRILL D, BAGNELL J A, et al. Solving games with functional regret estimation[C]//Proc. of the AAAI Conference on Artificial Intelligence, 2015: 2138-2144. |
| 189 | D'ORAZIO R, MORRILL D, WRIGHT J R, et al. Alternative function approximation parameterizations for solving games: an analysis of f -regression counterfactual regret minimization[C]//Proc. of the 19th International Conference on Autonomous Agents and Multiagent Systems, 2020: 339-347. |
| 190 | PILIOURAS G, ROWLAND M, OMIDSHAFIEI S, et al. Evolutionary dynamics and Φ-regret minimization in games[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2106.14668v1. |
| 191 | STEINBERGER E. Single deep counterfactual regret minimization[EB/OL]. [2021-08-01]. http://arxiv.org/abs/1901.07621. |
| 192 | LI H L, WANG X, GUO Z Y, et al. RLCFR: minimize counterfactual regret with neural networks[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2105.12328. |
| 193 | LI H L, WANG X, JIA F W, et al. RLCFR: minimize counterfactual regret by deep reinforcement learning[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2009.06373. |
| 194 | LIU W M, LI B, TOGELIUS J. Model-free neural counterfactual regret minimization with bootstrap learning[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2012.01870. |
| 195 | SCHMID M, MORAVCIK M, BURCH N, et al. Player of games[EB/OL]. [2021-12-30]. http://arxiv.org/abs/2112.03178. |
| 196 | CHRISTIAN K, KEVIN W, FATMA K K, et al. Faster first-order methods for extensive-form game solving[C]//Proc. of the 16th ACM Conference on Economics and Computation, 2015: 817-834. |
| 197 |
LESLIE D S , COLLINS E J . Generalised weakened fictitious play[J]. Games and Economic Behavior, 2006, 56 (2): 285- 298.
doi: 10.1016/j.geb.2005.08.005 |
| 198 | KROER C , WAUGH K , KLN-KARZAN F , et al. Faster algorithms for extensive-form game solving via improved smoo-thing functions[J]. Mathematical Programming, 2020, 179 (1): 385- 417. |
| 199 | FARINA G, KROER C, SANDHOLM T. Optimistic regret minimization for extensive-form games via dilated distance-generating functions[C]//Proc. of the 33rd International Conference on Neural Information Processing Systems, 2019: 5221-5231. |
| 200 | LIU W M, JIANG H C, LI B, et al. Equivalence analysis between counterfactual regret minimization and online mirror descent[EB/OL]. [2021-12-11]. http://arxiv.org/abs/2110.04961. |
| 201 | PEROLAT J, MUNOS R, LESPIAU J B, et al. From Poincaré recurrence to convergence in imperfect information games: finding equilibrium via regularization[C]//Proc. of the International Conference on Machine Learning, 2021: 8525-8535. |
| 202 | MUNOS R, PEROLAT J, LESPIAU J B, et al. Fast computation of Nash equilibria in imperfect information games[C]//Proc. of the International Conference on Machine Learning, 2020: 7119-7129. |
| 203 | KAWAMURA K, MIZUKAMI N, TSURUOKA Y. Neural fictitious self-play in imperfect information games with many players[C]//Proc. of the Workshop on Computer Games, 2017: 61-74. |
| 204 |
ZHANG L , CHEN Y X , WANG W , et al. A Monte Carlo neural fictitious self-play approach to approximate Nash equilibrium in imperfect-information dynamic games[J]. Frontiers of Computer Science, 2021, 15 (5): 155334.
doi: 10.1007/s11704-020-9307-6 |
| 205 | STEINBERGER E, LERER A, BROWN N. DREAM: deep regret minimization with advantage baselines and model-free learning[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2006.10410. |
| 206 | BROWN N, BAKHTIN A, LERER A, et al. Combining deep reinforcement learning and search for imperfect-information games[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2007.13544. |
| 207 | GRUSLYS A, LANCTOT M, MUNOS R, et al. The advantage regret-matching actor-critic[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2008.12234. |
| 208 | CHEN Y X, ZHANG L, LI S J, et al. Optimize neural fictitious self-play in regret minimization thinking[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2104.10845. |
| 209 | SONZOGNI S. Depth-limited approaches in adversarial team games[D]. Milano: Politecnico Di Milano, 2019. |
| 210 | ZHANG Y Z, AN B. Converging to team maxmin equilibria in zero-sum multiplayer games[C]//Proc. of the International Conference on Machine Learning, 2020: 11033-11043. |
| 211 | ZHANG Y Z, AN B, LONG T T, et al. Optimal escape interdiction on transportation networks[C]//Proc. of the 26th International Joint Conference on Artificial Intelligence, 2017: 3936-3944. |
| 212 | ZHANG Y Z, AN B. Computing ex ante coordinated team-maxmin equilibria in zero-sum multiplayer extensive-form games[C]//Proc. of the AAAI Conference on Artificial Intelligence, 2021: 5813-5821. |
| 213 | ZHANG Y Z, GUO Q Y, AN B, et al. Optimal interdiction of urban criminals with the aid of real-time information[C]//Proc. of the AAAI Conference on Artificial Intelligence, 2019: 1262-1269. |
| 214 |
BOTVINICK M , RITTER S , WANG J X , et al. Reinforcement learning, fast and slow[J]. Trends in Cognitive Sciences, 2019, 23 (5): 408- 422.
doi: 10.1016/j.tics.2019.02.006 |
| 215 | LANCTOT M, ZAMBALDI V, GRUSLYS A, et al. A unified game-theoretic approach to multiagent reinforcement learning[C]//Proc. of the 31st International Conference on Neural Information Processing Systems, 2017: 4193-4206. |
| 216 | MULLER P, OMIDSHAFIEI S, ROWLAND M, et al. A generalized training approach for multiagent learning[C]//Proc. of the 8th International Conference on Learning Representations, 2020. |
| 217 | SUN P, XIONG J C, HAN L, et al. TLeague: a framework for competitive self-play based distributed multi-agent reinforcement learning[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2011.12895. |
| 218 | ZHOU M, WAN Z Y, WANG H J, et al. MALib: a parallel framework for population-based multi-agent reinforcement learning[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2106.07551. |
| 219 | LISY V, BOWLING M. Eqilibrium approximation quality of current no-limit poker bots[C]//Proc. of the 31st AAAI Conference on Artificial Intelligence, 2017. |
| 220 | CLOUD A, LABER E. Variance decompositions for extensive-form games[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2009.04834. |
| 221 | SUSTR M, SCHMID M, MORAVCK M. Sound algorithms in imperfect information games[C]//Proc. of the 20th International Conference on Autonomous Agents and Multiagent Systems, 2021: 1674-1676. |
| 222 | BREANNA M, COMPARING E, GLICKO I. Bayesian IRT statistical models for educational and gaming data[D]. Fayetteville: University of Arkansas, 2019. |
| 223 |
PANKIEWICZ M , BATOR M . Elo rating algorithm for the purpose of measuring task difficulty in online learning environments[J]. E-Mentor, 2019, 82 (5): 43- 51.
doi: 10.15219/em82.1444 |
| 224 | GLICKMAN M E . The glicko system[M]. Boston: Boston University, 1995. |
| 225 | HERBRICH R, MINKA T, GRAEPEL T. TrueskillTM: a Bayesian skill rating system[C]//Proc. of the 19th International Conference on Neural Information Processing Systems, 2006: 569-576. |
| 226 |
OMIDSHAFIEI S , PAPADIMITRIOU C , PILIOURAS G , et al. α-Rank: multi-agent evaluation by evolution[J]. Scientific Reports, 2019, 9 (1): 9937.
doi: 10.1038/s41598-019-45619-9 |
| 227 | YANG Y D, TUTUNOV R, SAKULWONGTANA P, et al. αα-Rank: practically scaling α-rank through stochastic optimisation[C]//Proc. of the 19th International Conference on Autonomous Agents and Multiagent Systems, 2020: 1575-1583. |
| 228 | ROWLAND M, OMIDSHAFIEI S, TUYLS K, et al. Multiagent evaluation under incomplete information[C]//Proc. of the 33rd International Conference on Neural Information Processing Systems, 2019: 12291-12303. |
| 229 | RASHID T, ZHANG C, CIOSEK K, et al. Estimating α-rank by maximizing information gain[C]//Proc. of the AAAI Conference on Artificial Intelligence, 2021: 5673-5681. |
| 230 | DU Y L, YAN X, CHEN X, et al. Estimating α-rank from a few entries with low rank matrix completion[C]//Proc. of the International Conference on Machine Learning, 2021: 2870-2879. |
| 231 | ROOHI S, GUCKELSBERGER C, RELAS A, et al. Predicting game engagement and difficulty using AI players[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2107.12061. |
| 232 | OBRIEN J D, GLEESON J P. A complex networks approach to ranking professional Snooker players[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2010.08395. |
| 233 | JORDAN S M, CHANDAK Y, COHEN D, et al. Evaluating the performance of reinforcement learning algorithms[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2006.16958. |
| 234 | DEHPANAH A, GHORI M F, GEMMELL J, et al. The evaluation of rating systems in online free-for-all games[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2006.16958. |
| 235 | LEIBO J Z, DUEEZ-GUZMAN E, VEZHNEVETS A S, et al. Scalable evaluation of multi-agent reinforcement learning with melting pot[C]//Proc. of the International Conference on Machine Learning, 2021: 6187-6199. |
| 236 | EBTEKAR A, LIU P. Elo-MMR: a rating system for massive multiplayer competitions[C]//Proc. of the Web Conference, 2021: 1772-1784. |
| 237 | DEHPANAH A, GHORI M F, GEMMELL J, et al. Evaluating team skill aggregation in online competitive games[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2106.11397. |
| 238 | HERNANDEZ D , DENAMGANAI K , DEVLIN S , et al. A comparison of self-play algorithms under a generalized framework[J]. IEEE Trans.on Games, 2021, 14 (2): 221- 231. |
| 239 | LEIGH R, SCHONFELD J, LOUIS S J. Using coevolution to understand and validate game balance in continuous games[C]// Proc. of the 10th Annual Conference on Genetic and Evolutionary Computation, 2008: 1563-1570. |
| 240 | SAYIN M O, PARISE F, OZDAGLAR A. Fictitious play in zero-sum stochastic games[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2010.04223. |
| 241 |
JADERBERG M , CZARNECKI W M , DUNNING I , et al. Human-level performance in 3D multiplayer games with population- based reinforcement learning[J]. Science, 2019, 364 (6443): 859- 865.
doi: 10.1126/science.aau6249 |
| 242 | SAMUEL A L . Some studies in machine learning using the game of checkers[J]. IBM Journal of Research and Development, 2000, 44 (1/2): 206- 226. |
| 243 | BANSAL T, PACHOCKI J, SIDOR S, et al. Emergent complexity via multi-agent competition[EB/OL]. [2021-08-01]. http://arxiv.org/abs/1710.03748. |
| 244 | SUKHBAATAR S, LIN Z, KOSTRIKOV I, et al. Intrinsic motivation and automatic curricula via asymmetric self-play[EB/OL]. [2021-08-01]. http://arxiv.org/abs/1703.05407. |
| 245 | ADAM L, HORCIK R, KASL T, et al. Double oracle algorithm for computing equilibria in continuous games[C]//Proc. of the AAAI Conference on Artificial Intelligence, 2021: 5070-5077. |
| 246 | WANG Y Z, MA Q R, WELLMAN M P. Evaluating strategy exploration in empirical game-theoretic analysis[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2105.10423. |
| 247 | SHOHEI O. Unbiased self-play[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2106.03007. |
| 248 |
HENDON E , JACOBSEN H J , SLOTH B . Fictitious play in extensive form games[J]. Games and Economic Behavior, 1996, 15 (2): 177- 202.
doi: 10.1006/game.1996.0065 |
| 249 | HEINRICH J, LANCTOT M, SILVER D. Fictitious self-play in extensive-form games[C]//Proc. of the International Conference on Machine Learning, 2015: 805-813. |
| 250 | LIU B Y, YANG Z R, WANG Z R. Policy optimization in zero-sum Markov games: fictitious self-play provably attains Nash equilibria[EB/OL]. [2021-08-01]. https://openreview.net/forum?id=c3MWGN_cTf. |
| 251 |
HOFBAUER J , SANDHOLM W H . On the global convergence of stochastic fictitious play[J]. Econometrica, 2002, 70 (6): 2265- 2294.
doi: 10.1111/1468-0262.00376 |
| 252 | FARINA G, CELLI A, GATTI N, et al. Ex ante coordination and collusion in zero-sum multi-player extensive-form games[C]//Proc. of the 32nd International Conference on Neural Information Processing Systems, 2018: 9661-9671. |
| 253 | HEINRICH J. Deep reinforcement learning from self-play in imperfect-information games[D]. London: University College London, 2016. |
| 254 | NIEVES N P, YANG Y, SLUMBERS O, et al. Modelling behavioural diversity for learning in open-ended games[C]//Proc. of the International Conference on Machine Learning, 2021: 8514-8524. |
| 255 | KLIJN D, EIBEN A E. A coevolutionary approach to deep multi-agent reinforcement learning[C]//Proc. of the Genetic and Evolutionary Computation Conference, 2021. |
| 256 | WRIGHT M, WANG Y, WELLMAN M P. Iterated deep reinforcement learning in games: history-aware training for improved stability[C]//Proc. of the ACM Conference on Economics and Computation, 2019: 617-636. |
| 257 | SMITH M O, ANTHONY T, WANG Y, et al. Learning to play against any mixture of opponents[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2009.14180. |
| 258 | SMITH M O, ANTHONY T, WELLMAN M P. Iterative empirical game solving via single policy best response[C]//Proc. of the International Conference on Learning Representations, 2020. |
| 259 | MARRIS L, MULLER P, LANCTOT M, et al. Multi-agent training beyond zero-sum with correlated equilibrium meta-solvers[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2106.09435. |
| 260 | MCALEER S, LANIER J, FOX R, et al. Pipeline PSRO: a scalable approach for finding approximate Nash equilibria in large games[C]//Proc. of the 34th International Conference on Neural Information Processing Systems, 2020, 33: 20238-20248. |
| 261 | DINH L C, YANG Y, TIAN Z, et al. Online double oracle[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2103.07780. |
| 262 | FENG X D, SLUMBERS O, YANG Y D, et al. Discovering multi-agent auto-curricula in two-player zero-sum games[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2106.02745. |
| 263 | MCALEER S, WANG K, LANCTOT M, et al. Anytime optimal PSRO for two-player zero-sum games[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2201.07700. |
| 264 | ZHOU M, CHEN J X, WEN Y, et al. Efficient policy space response oracles[EB/OL]. [2022-03-01]. http://arxiv.org/abs/2202.00633. |
| 265 | LIU S Q, MARRIS L, HENNES D, et al. NeuPL: neural population learning[EB/OL]. [2022-03-01]. http://arxiv.org/abs/2202.07415. |
| 266 | YANG Y D, LUO J, WEN Y, et al. Diverse auto-curriculum is critical for successful real-world multiagent learning systems[C]// Proc. of the 20th International Conference on Autonomous Agents and Multiagent Systems, 2021: 51-56. |
| 267 | WU Z, LI K, ZHAO E M, et al. L2E: learning to exploit your opponent[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2102.09381. |
| 268 | LEIBO J Z, HUGHES E, LANCTOT M, et al. Autocurricula and the emergence of innovation from social interaction: a manifesto for multi-agent intelligence research[EB/OL]. [2021-08-01]. http://arxiv.org/abs/1903.00742. |
| 269 | LIU X Y, JIA H T, WEN Y, et al. Unifying behavioral and response diversity for open-ended learning in zero-sum games[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2106.04958. |
| 270 |
MOURET J B . Evolving the behavior of machines: from micro to macroevolution[J]. Iscience, 2020, 23 (11): 101731.
doi: 10.1016/j.isci.2020.101731 |
| 271 | MCKEE K R, LEIBO J Z, BEATTIE C, et al. Quantifying environment and population diversity in multi-agent reinforcement learning[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2102.08370. |
| 272 | PACCHIANO A, HOLDER J P, CHOROMANSKI K M, et al. Effective diversity in population-based reinforcement learning[C]// Proc. of the 34th International Conference on Neural Information Processing Systems, 2020: 18050-18062. |
| 273 | MASOOD M A, FINALE D V. Diversity-inducing policy gradient: using maximum mean discrepancy to find a set of diverse policies[C]//Proc. of the 28th International Joint Conference on Artificial Intelligence, 2019: 5923-5929. |
| 274 | GARNELO M, CZARNECKI W M, LIU S, et al. Pick your battles: interaction graphs as population-level objectives for strategic diversity[C]//Proc. of the 20th International Conference on Autonomous Agents and Multi-Agent Systems, 2021: 1501-1503. |
| 275 | TAVARES A, AZPURUA H, SANTOS A, et al. Rock, paper, StarCraft: strategy selection in real-time strategy games[C]// Proc. of the 12th AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, 2016: 93-99. |
| 276 |
PABLO H L , ENRIQUE M C , SUCAR L E . A framework for learning and planning against switching strategies in repeated games[J]. Connection Science, 2014, 26 (2): 103- 122.
doi: 10.1080/09540091.2014.885294 |
| 277 | FEI Y J, YANG Z R, WANG Z R, et al. Dynamic regret of policy optimization in non-stationary environments[C]//Proc. of the 31st International Conference on Neural Information Processing Systems, 2020: 6743-6754. |
| 278 | WRIGHT M, VOROBEYCHIK Y. Mechanism design for team formation[C]//Proc. of the AAAI 29th AAAI Conference on Artificial Intelligence, 2015: 1050-1056. |
| 279 | AUER P, JAKSCH T, ORTNER R, et al. Near-optimal regret bounds for reinforcement learning[C]//Proc. of the 21st International Conference on Neural Information Processing Systems, 2008: 89-96. |
| 280 | HE J F, ZHOU D R, GU Q Q, et al. Nearly optimal regret for learning adversarial MDPs with linear function approximation[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2102.08940. |
| 281 | MEHDI J J, RAHUL J, ASHUTOSH N. Online learning for unknown partially observable MDPs[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2102.12661. |
| 282 | TIAN Y, WANG Y H, YU T C, et al. Online learning in unknown Markov games[C]//Proc. of the International Conference on Machine Learning, 2021: 10279-10288. |
| 283 | KASH I A, SULLINS M, HOFMANN K. Combining no-regret and q-learning[C]//Proc. of the 19th International Conference on Autonomous Agents and Multi-Agent Systems, 2020: 593-601. |
| 284 | LIN T Y, ZHOU Z Y, MERTIKOPOULOS P, et al. Finite-time last-iterate convergence for multi-agent learning in games[C]// Proc. of the International Conference on Machine Learning, 2020: 6161-6171. |
| 285 | LEE C W, KROER C, LUO H P. Last-iterate convergence in extensive-form games[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2106.14326. |
| 286 | DASKALAKIS C, FISHELSON M, GOLOWICH N. Near-optimal no-regret learning in general games[EB/OL]. [2021-08-01]. http://arxiv.org/abs/2108.06924. |
| 287 | MORRILL D, D'ORAZIO R, SARFATI R, et al. Hindsight and sequential rationality of correlated play[C]//Proc. of the AAAI Conference on Artificial Intelligence, 2021: 5584-5594. |
| 288 | LI X. Opponent modeling and exploitation in poker using evolved recurrent neural networks[D]. Austin: University of Texas at Austin, 2018. |
| 289 | GANZFRIED S. Computing strong game-theoretic strategies and exploiting suboptimal opponents in large games[D]. Pittsburgh: Carnegie Mellon University, 2015. |
| 290 | DAVIS T, WAUGH K, BOWLING M. Solving large extensive-form games with strategy constraints[C]//Proc. of the AAAI Conference on Artificial Intelligence, 2019: 1861-1868. |
| 291 | KIM D K, LIU M, RIEMER M, et al. A policy gradient algorithm for learning to learn in multiagent reinforcement learning[C]//Proc. of the International Conference on Machine Learning, 2021: 5541-5550. |
| 292 | SILVA F, COSTA A, STONE P. Building self-play curricula online by playing with expert agents in adversarial games[C]// Proc. of the 8th Brazilian Conference on Intelligent Systems, 2019: 479-484. |
| 293 | SUSTR M, KOVARK V, LISY V. Monte Carlo continual resolving for online strategy computation in imperfect information games[C]//Proc. of the 18th International Conference on Autonomous Agents and Multi-Agent Systems, 2019: 224-232. |
| 294 | BROWN N, SANDHOLM T. Safe and nested subgame solving for imperfect-information games[C]//Proc. of the 31st International Conference on Neural Information Processing Systems, 2017: 689-699. |
| [1] | 吴钇达, 王彩云, 王佳宁, 李晓飞. 基于ISVM-DS的红外多传感器融合识别方法[J]. 系统工程与电子技术, 2024, 46(5): 1555-1560. |
| [2] | 黄思佳, 宋纯锋, 李璇. 基于可变尺度先验框的声呐图像目标检测[J]. 系统工程与电子技术, 2024, 46(3): 771-778. |
| [3] | 马兰, 孟诗君, 吴志军. 基于BERT与生成对抗的民航陆空通话意图挖掘[J]. 系统工程与电子技术, 2024, 46(2): 740-750. |
| [4] | 胡涛, 申立群, 朱镜达, 孙成会, 董伟锋. 基于FAST和Sobol指数法的雷达系统效能敏感性分析[J]. 系统工程与电子技术, 2024, 46(2): 561-569. |
| [5] | 曲熠, 陈莹. 基于边缘强化的无监督单目深度估计[J]. 系统工程与电子技术, 2024, 46(1): 71-79. |
| [6] | 颜骥, 刘丙杰, 陈建华. 基于电子商务竞标结构的分布式作战资源调度[J]. 系统工程与电子技术, 2024, 46(1): 227-236. |
| [7] | 张宝琛, 惠建江, 张琦, 刘正雄, 黄攀峰. 面向冗余机械臂避障运动规划的触控交互技术[J]. 系统工程与电子技术, 2024, 46(1): 254-260. |
| [8] | 黄万炎, 杜万和, 杨淑珍, 俞涛. 改进的多项式曲线拟合轨迹预测算法[J]. 系统工程与电子技术, 2024, 46(1): 280-289. |
| [9] | 贺翥祯, 李敏, 苟瑶, 杨爱涛. 改进YOLOv5的合成孔径雷达图像舰船目标检测方法[J]. 系统工程与电子技术, 2023, 45(12): 3743-3753. |
| [10] | 胡涛, 申立群, 田宇阳, 董伟锋. 航天复杂系统测发控流程仿真引擎设计与评价[J]. 系统工程与电子技术, 2023, 45(12): 3866-3874. |
| [11] | 翟一琛, 顾佼佼, 宗富强, 姜文志. 融合注意力机制的IETM细粒度跨模态检索算法[J]. 系统工程与电子技术, 2023, 45(12): 3915-3923. |
| [12] | 陈维义, 何凡, 刘国强, 毛伟伟. 变结构交互式多模型滤波和平滑算法[J]. 系统工程与电子技术, 2023, 45(12): 4005-4012. |
| [13] | 陈任飞, 彭勇, 李忠文. 基于持续无监督域适应策略的水面漂浮物目标检测方法[J]. 系统工程与电子技术, 2023, 45(11): 3391-3401. |
| [14] | 眭海刚, 李嘉杰, 苟国华. 基于异源影像匹配的无人机在线快速定位方法[J]. 系统工程与电子技术, 2023, 45(10): 3008-3015. |
| [15] | 钱坤, 李晨瑄, 陈美杉, 郭继伟, 潘磊. 基于改进Swin Transformer的舰船目标实例分割算法[J]. 系统工程与电子技术, 2023, 45(10): 3049-3057. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||