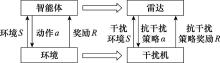
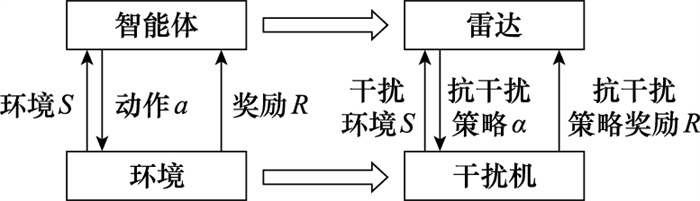
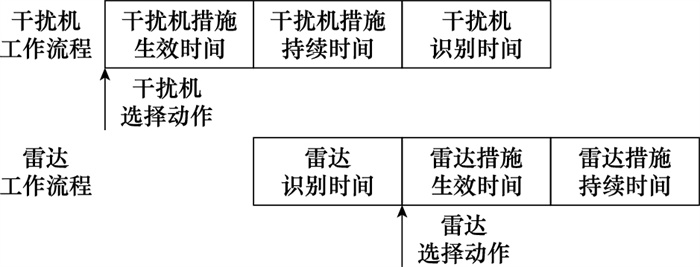
| 1 |
HUANGJ S,CAOG D.Joint transmitting subarray partition and beamforming for active jamming suppression in phased-MIMO radar[J].Radio Science,2022,57(1):1-18.
|
| 2 |
JOHNSON N, CIVEROLO M, LUMSDEN N. Techniques and methods for adaptive single antenna radar system polarization optimization for anti-jam and anti-clutter applications[C]//Proc. of the IEEE National Radar Conference, 2015: 210-213.
|
| 3 |
LIY C,WANGJ D,WANGY,et al.Random frequency coded waveform optimization and signal coherent accumulation against compound deception jamming[J].IEEE Trans.on Aerospace and Electronic Systems,2023,59(4):4434-4449.
doi: 10.1109/TAES.2023.3243884
|
| 4 |
CHENG G J, FU X J, MA S S, et al. Anti-jamming technology of dense co-frequency synchronous range false targets[C]//Proc. of the IEEE International Radar Conference, 2016.
|
| 5 |
SUTTONR S,BARTOA G.Reinforcement learning: an introduction[J].Robotica,1999,17(2):229-235.
|
| 6 |
FANGY Y,ZHANGL,WEIS P,et al.Online frequency-agile strategy for radar detection based on constrained combinatorial non-stationary bandit[J].IEEE Trans.on Aerospace and Electronic Systems,2022,59(2):1693-1706.
|
| 7 |
LI K, JIU B, LIU H W, et al. Reinforcement learning based anti-jamming frequency hopping strategies design for cognitive radar[C]// Proc. of the IEEE International Conference on Signal Processing, Communications and Computing, 2018.
|
| 8 |
AI L Y, WEI Y, YE Y. Reinforcement learning-based joint adaptive frequency hopping and pulse-width allocation for radar anti-jamming[C]//Proc. of the IEEE Radar Conference, 2020.
|
| 9 |
WEI J J, YU L, XU R Q. Intelligent decision method of slope perturbing based on Q-learning for anti-deception jamming[C]//Proc. of the 6th International Conference on Imaging, Signal Processing and Communications, 2022: 71-76.
|
| 10 |
LEI A F, FAN W W, ZHOU F. A cognitive radar anti-jamming strategy generation algorithm based on dueling double DQN[C]//Proc. of the IEEE International Radar Conference, 2023.
|
| 11 |
LI H Y, HAN Z W, PU W Q, et al. Counterfactual regret minimization for anti-jamming game of frequency agile radar[C]// Proc. of the IEEE 12th Sensor Array and Multichannel Signal Processing Workshop, 2022: 111-115.
|
| 12 |
AIL Y,YIW,VARSHNEYP K.Adaptation of frequency hopping interval for radar anti-jamming based on reinforcement learning[J].IEEE Trans.on Vehicular Technology,2022,71(12):12434-12449.
doi: 10.1109/TVT.2022.3197425
|
| 13 |
JIANG X F, ZHOU F, JIAN Y, et al. An optimal POMDP-based anti-jamming policy for cognitive radar[C]//Proc. of the 13th IEEE Conference on Automation Science and Engineering, 2017: 938-943.
|
| 14 |
YANG T, YUAN Y, YI W. Multi-domain resource scheduling for surveillance radar anti-jamming based on Q-learning[C]//Proc. of the IEEE Radar Conference, 2023.
|
| 15 |
AZIZ M M, MAUD A R M, HABIB A. Reinforcement learning based techniques for radar anti-jamming[C]//Proc. of the International Bhurban Conference on Applied Sciences and Technologies, 2021: 1021-1025.
|
| 16 |
汪浩,王峰.强化学习算法在雷达智能抗干扰中的应用[J].现代雷达,2020,42(3):40-44, 48.
|
|
WANGH,WANGF.Application of reinforcement learning algorithm in radar intelligent anti-jamming[J].Modern Radar,2020,42(3):40-44, 48.
|
| 17 |
袁泉. 智能雷达网络抗有源干扰方法[D]. 哈尔滨: 哈尔滨工业大学, 2020.
|
|
YUAN Q. Anti-active jamming method of intelligent radar network[D]. Harbin: Harbin Institute of Technology, 2020.
|
| 18 |
JIANG W, WANG Y P, LI Y, et al. An intelligent anti-jamming decision-making method based on deep reinforcement learning for cognitive radar[C]//Proc. of the 26th International Conference on Computer Supported Cooperative Work in Design, 2023: 1662-1666.
|
| 19 |
FENGC,FUX J,LANGP,et al.A radar anti-jamming strategy based on game theory with temporal constraints[J].IEEE Access,2022,10,97429-97438.
doi: 10.1109/ACCESS.2022.3200761
|
| 20 |
LIK,LIUH W,JIUB,et al.Knowledge aided model-based reinforcement learning for anti-jamming strategy learning[J].IEEE Trans.on Aerospace and Electronic System,2024,60(3):2976-2994.
doi: 10.1109/TAES.2024.3358779
|
| 21 |
LOWE R, WU Y I, TAMAR A, et al. Multi-agent actor-critic for mixed cooperative-competitive environments[C]//Proc. of the 31st International Conference on Neural Information Processing Systems, 2017: 6382-6393.
|
| 22 |
RASHIDT,SAMVELYANM,DE-WITTC S,et al.Monotonic value function factorisation for deep multi-agent reinforcement learning[J].The Journal of Machine Learning Research,2020,21(1):7234-7284.
|
| 23 |
FENGC,FUX J,WANGZ,et al.An optimization method for collaborative radar antijamming based on multi-agent reinforcement learning[J].Remote Sensing,2023,15(11):2893.
|
| 24 |
RIEDMILLER M, HAFNER R, LAMPE T, et al. Learning by playing solving sparse reward tasks from scratch[C]//Proc. of the International Conference on Machine Learning, 2018: 4344-4353.
|
| 25 |
RAFATI J, NOELLE D C. Learning representations in model-free hierarchical reinforcement learning[C]//Proc. of the AAAI Conference on Artificial Intelligence, 2019: 10009-10010.
|