
系统工程与电子技术 ›› 2025, Vol. 47 ›› Issue (1): 268-279.doi: 10.12305/j.issn.1001-506X.2025.01.27
闫循良1,*, 王宽1, 张子剑2, 王培臣1
收稿日期:2024-03-05
出版日期:2025-01-21
发布日期:2025-01-25
通讯作者:
闫循良
作者简介:闫循良(1984—), 男, 副研究员, 博士, 主要研究方向为高超声速飞行器弹道设计与制导、攻防对抗建模与仿真评估基金资助:Xunliang YAN1,*, Kuan WANG1, Zijian ZHANG2, Peichen WANG1
Received:2024-03-05
Online:2025-01-21
Published:2025-01-25
Contact:
Xunliang YAN
摘要:
针对现有基于深度确定性策略梯度(deep deterministic policy gradient, DDPG)算法的再入制导方法计算精度较差, 对强扰动条件适应性不足等问题, 在DDPG算法训练框架的基础上, 提出一种基于长短期记忆-DDPG(long short term memory-DDPG, LSTM-DDPG)的再入制导方法。该方法采用纵、侧向制导解耦设计思想, 在纵向制导方面, 首先针对再入制导问题构建强化学习所需的状态、动作空间; 其次, 确定决策点和制导周期内的指令计算策略, 并设计考虑综合性能的奖励函数; 然后, 引入LSTM网络构建强化学习训练网络, 进而通过在线更新策略提升算法的多任务适用性; 侧向制导则采用基于横程误差的动态倾侧反转方法, 获得倾侧角符号。以美国超音速通用飞行器(common aero vehicle-hypersonic, CAV-H)再入滑翔为例进行仿真, 结果表明: 与传统数值预测-校正方法相比, 所提制导方法具有相当的终端精度和更高的计算效率优势; 与现有基于DDPG算法的再入制导方法相比, 所提制导方法具有相当的计算效率以及更高的终端精度和鲁棒性。
中图分类号:
闫循良, 王宽, 张子剑, 王培臣. 基于LSTM-DDPG的再入制导方法[J]. 系统工程与电子技术, 2025, 47(1): 268-279.
Xunliang YAN, Kuan WANG, Zijian ZHANG, Peichen WANG. Reentry guidance method based on LSTM-DDPG[J]. Systems Engineering and Electronics, 2025, 47(1): 268-279.

图1
LSTM模型示意图"


图2
LSTM遗忘门"


图3
LSTM输入门"


图4
LSTM输出门"


图5
LSTM-DDPG算法流程图"


图6
Actor网络"


图7
Critic网络"


图8
基于LSTM-DDPG的再入制导算法流程图"
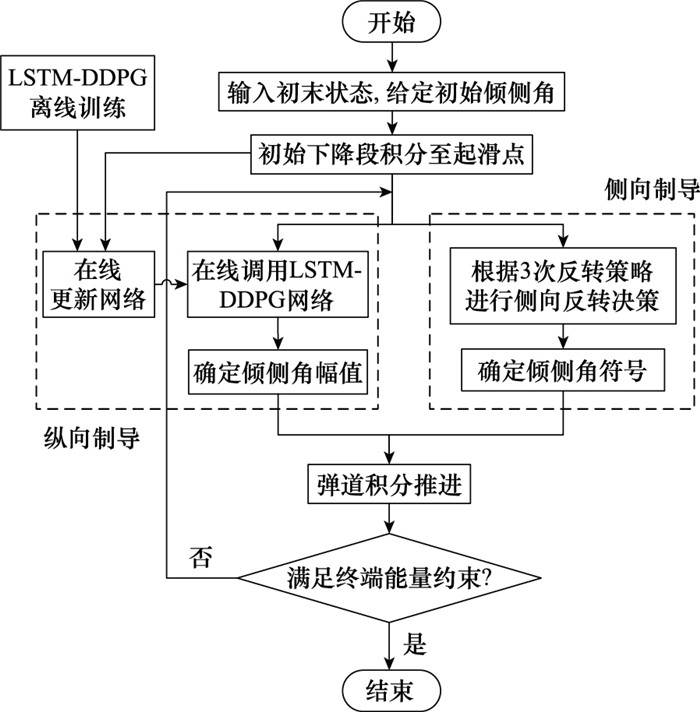
表1
强化学习网络超参数"
| 参数 | 数值 |
| 最大训练次数M | 3 000 |
| 样本池容量 | 105 |
| 每次训练抽取样本数N | 256 |
| Target网络更新率τ | 0.001 |
| Actor网络学习率ημ | 10-5 |
| Critic网络学习率ηQ | 10-4 |
表2
离线训练结果"
| 算法 | 平均累计奖励 |
| LSTM-DDPG | -6.01 |
| DDPG | -6.28 |

图9
离线训练过程"


图10
3种方法的仿真结果曲线"

表3
3种算法的终端偏差结果"
| 算法 | |Δhf|/km | |ΔVf|/(m/s) | |Δstogof|/km | 制导指令更新平均耗时/ms |
| 1 | 0.445 | 1.36 | 0.50 | 15.5 |
| 2 | 0.556 | 1.52 | 3.61 | 1.3 |
| 3 | 0.434 | 1.56 | 0.53 | 1.4 |
表4
适用性仿真条件"
| 算法 | θ0/(°) | ϕ0/(°) | ψ0/(°) | θf*/(°) | ϕf*/(°) | s0/km |
| 1 | 30 | 30 | 340 | -40 | 70 | 6 134.6 |
| 2 | -30 | 10 | 0 | -40 | 70 | 6 709.3 |
| 3 | -130 | 60 | 70 | -40 | 70 | 3 950.9 |
| 4 | 60 | 70 | 280 | -40 | 70 | 3 377.9 |
表5
适用性仿真终端偏差"
| 算法 | |Δhf|/km | |ΔVf|/(m/s) | |Δstogof|/km |
| 1 | 0.434 | 1.56 | 0.53 |
| 2 | 0.575 | 1.78 | 0.48 |
| 3 | 0.675 | 2.14 | 0.69 |
| 4 | 0.632 | 2.41 | 0.67 |

图11
适用性仿真曲线"

表6
参数拉偏设置"
| 不确定参数 | 3σ |
| ρ/% | 10 |
| CL/% | 10 |
| CD/% | 10 |
| h0/km | 3 |
| V0/(m/s) | 100 |
| θ0/(°) | 0.5 |
| ϕ0/(°) | 0.5 |
| γ0/(°) | 0.5 |
| ψ0/(°) | 0.5 |

图12
打靶结果"

表7
打靶终端参数"
| 终端参数 | 均值 | 标准差 |
| hf/km | 25.76 | 0.15 |
| θf/(°) | -38.73 | 0.021 9 |
| ϕf/(°) | 69.84 | 0.014 6 |
| Vf/(m/s) | 1 998.4 | 0.48 |
表8
不同方法打靶数据"
| 算法 | 参数 | hf/km | θf/(°) | ϕf/(°) | Vf/(m/s) |
| 1 | 均值 | 25.40 | -38.74 | 69.84 | 1 998.5 |
| 标准差 | 0.05 | 0.016 5 | 0.015 4 | 0.35 | |
| 2 | 均值 | 25.90 | -38.69 | 69.85 | 1 993.3 |
| 标准差 | 0.11 | 0.047 6 | 0.035 1 | 0.82 | |
| 3 | 均值 | 25.76 | -38.73 | 69.84 | 1 998.4 |
| 标准差 | 0.10 | 0.021 9 | 0.014 6 | 0.48 |
| 1 | 张远龙, 谢愈. 滑翔飞行器弹道规划与制导方法综述[J]. 航空学报, 2020, 41 (1): 023377. |
| ZHANG Y L , XIE Y . Review of trajectory planning and gui-dance methods for gliding vehicles[J]. Acta Aeronautica et Astro- nautica Sinica, 2020, 41 (1): 023377. | |
| 2 | ZHAO S , ZHU J W , BAO W M , et al. High-dynamic intelligent maneuvering guidance strategy via deep reinforcement learning[J]. Proceedings of the Institution of Mechanical Engineers, Part G: Journal of Aerospace Engineering, 2023, 237 (11): 154- 165. |
| 3 |
LEAVITTE J A , MEASE K D . Feasible trajectory generation for atmospheric entry guidance[J]. Journal of Guidance, Control and Dynamics, 2007, 30 (2): 473- 481.
doi: 10.2514/1.23034 |
| 4 |
XUE S B , LU P . Constrained predictor-corrector entry guidance[J]. Journal of Guidance, Control, and Dynamics, 2010, 33 (4): 1273- 1281.
doi: 10.2514/1.49557 |
| 5 |
郭冬子, 黄荣, 许河川, 等. 再入飞行器深度确定性策略梯度制导方法研究[J]. 系统工程与电子技术, 2022, 44 (6): 1942- 1949.
doi: 10.12305/j.issn.1001-506X.2022.06.21 |
|
GUO D Z , HUANG R , XU H C , et al. Research on gradient guidance method for depth deterministic strategy of reentry aircraft[J]. Systems Engineering and Electronics, 2022, 44 (6): 1942- 1949.
doi: 10.12305/j.issn.1001-506X.2022.06.21 |
|
| 6 | LUO X L , CHEN C , ZENG C N , et al. Deep reinforcement learning for joint trajectory planning, transmission scheduling, and access control in UAV-assisted wireless sensor networks[J]. Sensors(Basel, Switzerland), 2023, 23 (10): 423- 434. |
| 7 |
LEE G T , KIM K J , JANG J . Real-time path planning of controllable UAV by subgoals using goal-conditioned reinforcement learning[J]. Applied Soft Computing, 2023, 146, 110660.
doi: 10.1016/j.asoc.2023.110660 |
| 8 |
GUO Y F , LIU Z P . UAV path planning based on deep reinforcement learning[J]. International Journal of Advanced Network, Monitoring and Controls, 2023, 8 (3): 81- 88.
doi: 10.2478/ijanmc-2023-0068 |
| 9 |
LI H T , LV X , ZHANG S . Multi-objective deep reinforcement learning based joint beamforming and power allocation in UAV assisted cellular communication[J]. Wireless Personal Communications, 2024, 134 (2): 809- 829.
doi: 10.1007/s11277-024-10927-5 |
| 10 |
YANG L B , CAI Y Q , WEI H . Unmanned aerial vehicle-assisted wideband cognitive radio network based on DDQN-SAC[J]. EURASIP Journal on Advances in Signal Processing, 2024, 2024, 43.
doi: 10.1186/s13634-024-01141-3 |
| 11 | LI J , CAO S , LIU X J , et al. Trans-UTPA: PSO and MADDPG based multi-UAVs trajectory planning algorithm for emergency communication[J]. Frontiers in Neurorobotics, 2023, 16 (1): 432- 440. |
| 12 | XUE J J , ZHU J , DU J T , et al. Dynamic path planning for multiple UAVs with incomplete information[J]. Electronics, 2023, 12 (4): 123- 132. |
| 13 |
ZHAO Z X , CHEN J , XIN B , et al. Learning scalable task assignment with imperative-priori conflict resolution in multi-UAV adversarial swarm defense problem[J]. Journal of Systems Science and Complexity, 2024, 37 (1): 369- 388.
doi: 10.1007/s11424-024-4029-8 |
| 14 |
ZHU J Y , KUANG M C , ZHOU W Q , et al. Mastering air combat game with deep reinforcement learning[J]. Defence Technology, 2024, 34, 295- 312.
doi: 10.1016/j.dt.2023.08.019 |
| 15 |
DAS P P , WANG P , NIU C X . Reentry trajectory design of a hypersonic vehicle based on reinforcement learning[J]. Journal of Physics: Conference Series, 2023, 2633 (1): 012005.
doi: 10.1088/1742-6596/2633/1/012005 |
| 16 | WU T C , WANG H L , LIU Y H , et al. Learning-based interfered fluid avoidance guidance for hypersonic reentry vehicles with multiple constraints[J]. ISA Transactions, 2023, 39 (1): 139- 150. |
| 17 | 惠俊鹏, 汪韧, 郭继峰. 基于强化学习的禁飞区绕飞智能制导技术[J]. 航空学报, 2023, 44 (11): 240- 252. |
| HUI J P , WANG R , GUO J F . Intelligent guidance technology for no fly zone detour based on reinforcement learning[J]. Acta Aeronautica et Astronautica Sinica, 2023, 44 (11): 240- 252. | |
| 18 | 方科, 张庆振, 倪昆, 等. 飞行时间约束下的再入制导律[J]. 哈尔滨工业大学学报, 2019, 51 (10): 90- 97. |
| FANG K , ZHANG Q Z , NI K , et al. Reentry guidance law under flight time constraints[J]. Journal of Harbin Institute of Technology, 2019, 51 (10): 90- 97. | |
| 19 | 张晚晴, 余文斌, 李静琳, 等. 基于纵程解析解的飞行器智能横程机动再入协同制导[J]. 兵工学报, 2021, 42 (7): 1400- 1411. |
| ZHANG W Q , YU W B , LI J L , et al. Intelligent lateral maneuvering and re-entry coordinated guidance for aircraft based on longitudinal analytical solutions[J]. Acta Armamentarii, 2021, 42 (7): 1400- 1411. | |
| 20 | ZHU J W , ZHANG H , ZHAO S , et al. Multi-constrained intelligent gliding guidance via optimal control and DQN[J]. SCIENCE CHINA Information Sciences, 2023, 66 (3): 214- 229. |
| 21 | 高嘉时. 升力式再入飞行器轨迹优化与制导方法研究[D]. 武汉: 华中科技大学, 2019. |
| GAO J S. Research on trajectory optimization and guidance methods for lift type re-entry vehicles[D]. Wuhan: Huazhong University of Science and Technology, 2019. | |
| 22 | CHENG Y, SHUI Z S, XU C, et al. Cross-cycle iterative unmanned aerial vehicle reentry guidance based on reinforcement learning[C]//Proc. of the IEEE International Conference on Unmanned Systems, 2019: 587-592. |
| 23 | 武天才, 王宏伦, 刘一恒, 等. 基于深度强化学习与高度速率反馈的再入制导方法[J]. 无人系统技术, 2022, 5 (4): 1- 13. |
| WU T C , WANG H L , LIU Y H , et al. Reentry guidance method based on deep reinforcement learning and high rate feedback[J]. Unmanned Systems Technology, 2022, 5 (4): 1- 13. | |
| 24 | 汪韧, 惠俊鹏, 俞启东, 等. 基于LSTM模型的飞行器智能制导技术研究[J]. 力学学报, 2021, 53 (7): 2047- 2057. |
| WANG R , HUI J P , YU Q D , et al. Research on intelligent guidance technology for aircraft based on LSTM model[J]. Chinese Journal of Theoretical and Applied Mechanics, 2021, 53 (7): 2047- 2057. | |
| 25 |
彭余萧, 何真, 仇靖雯. 基于LSTM-DDPG算法的四翼变掠角飞行器主动变形决策[J]. 北京航空航天大学学报,
doi: 10.13700/j.bh.1001-5965.2023.0513 |
|
PENG Y X , HE Z , QIU J W . Active deformation decision-making of four wing variable sweep angle aircraft based on LSTM-DDPG algorithm[J]. Journal of Beijing University of Aeronautics and Astronautics,
doi: 10.13700/j.bh.1001-5965.2023.0513 |
|
| 26 | XIE Y , LIU L H , TANG G J , et al. Highly constrained entry trajectory generation[J]. Acta Astronautica, 2013, 88, 44- 60. |
| 27 | LU P . Entry guidance: a unified method[J]. Journal of Gui-dance, Control, and Dynamics, 2014, 37 (3): 713- 728. |
| 28 | KRIZHEVSKY A, SUTSKEVER I, HINTON G E. Imagenet classification with deep convolutional neural networks[C]//Proc. of the Advances in Neural Information Processing Systems, 2012: 1097-1105. |
| 29 | LIANG S Y, SRIKANT R. Why deep neural networks for function approximation?[EB/OL].[2024-02-05]. https://arxiv.org/abs/1610.04161. |
| 30 | SHEN Z J , LU P . Dynamic lateral entry guidance logic[J]. Journal of Guidance, Control, and Dynamics, 2004, 27 (6): 949- 959. |
| [1] | 张庭瑜, 曾颖, 李楠, 黄洪钟. 基于深度强化学习的航天器功率-信号复合网络优化算法[J]. 系统工程与电子技术, 2024, 46(9): 3060-3069. |
| [2] | 夏雨奇, 黄炎焱, 陈恰. 基于深度Q网络的无人车侦察路径规划[J]. 系统工程与电子技术, 2024, 46(9): 3070-3081. |
| [3] | 杨志鹏, 陈子浩, 曾长, 林松, 毛金娣, 张凯. 复杂环境下的飞行器在线航路规划决策方法[J]. 系统工程与电子技术, 2024, 46(9): 3166-3175. |
| [4] | 彭莉莎, 孙宇祥, 薛宇凡, 周献中. 融合三支多属性决策与SAC的兵棋推演智能决策技术[J]. 系统工程与电子技术, 2024, 46(7): 2310-2322. |
| [5] | 郭宏达, 娄静涛, 徐友春, 叶鹏, 李永乐, 陈晋生. 基于MADDPG的多无人车协同事件触发通信[J]. 系统工程与电子技术, 2024, 46(7): 2525-2533. |
| [6] | 吴嘉俊, 苏春, 张玉茹. 基于双重自注意力机制和长短时记忆网络的剩余寿命预测[J]. 系统工程与电子技术, 2024, 46(6): 1986-1994. |
| [7] | 张梦钰, 豆亚杰, 陈子夷, 姜江, 杨克巍, 葛冰峰. 深度强化学习及其在军事领域中的应用综述[J]. 系统工程与电子技术, 2024, 46(4): 1297-1308. |
| [8] | 李彦铃, 罗飞舟, 葛致磊. 基于鲁棒观测器的深度强化学习垂直起降运载器姿态稳定研究[J]. 系统工程与电子技术, 2024, 46(3): 1038-1047. |
| [9] | 秦湖程, 黄炎焱, 陈天德, 张寒. 基于PPO算法的集群多目标火力规划方法[J]. 系统工程与电子技术, 2024, 46(11): 3764-3773. |
| [10] | 唐恒, 孙伟, 吕磊, 贺若飞, 吴建军, 孙昌浩, 孙田野. 融合动态奖励策略的无人机编队路径规划方法[J]. 系统工程与电子技术, 2024, 46(10): 3506-3518. |
| [11] | 冯路为, 刘松涛, 徐华志. 基于POMDP模型的智能雷达干扰决策方法[J]. 系统工程与电子技术, 2023, 45(9): 2755-2760. |
| [12] | 马悦, 吴琳, 许霄. 基于多智能体强化学习的协同目标分配[J]. 系统工程与电子技术, 2023, 45(9): 2793-2801. |
| [13] | 韦道知, 张曌宇, 谢家豪, 李宁. 基于改进Actor-Critic算法的多传感器交叉提示技术[J]. 系统工程与电子技术, 2023, 45(6): 1624-1632. |
| [14] | 吴冯国, 陶伟, 李辉, 张建伟, 郑成辰. 基于深度强化学习算法的无人机智能规避决策[J]. 系统工程与电子技术, 2023, 45(6): 1702-1711. |
| [15] | 李欣致, 董胜波, 崔向阳. 基于非对称不可观测状态的强化学习技术[J]. 系统工程与电子技术, 2023, 45(6): 1755-1761. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||