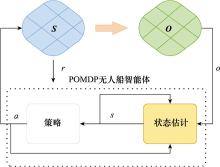
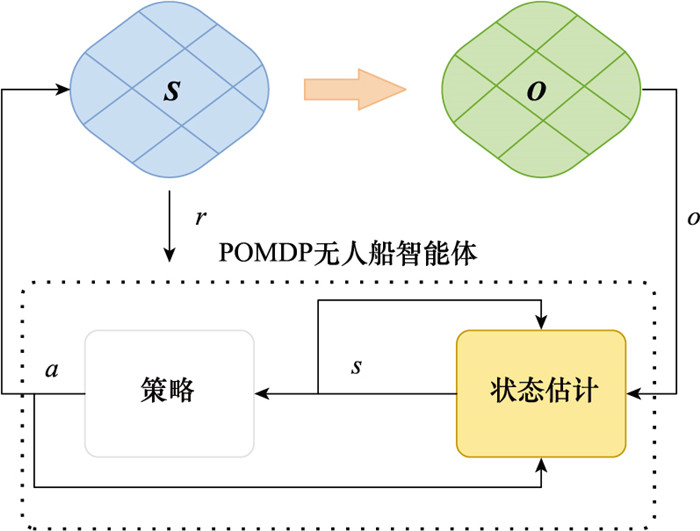
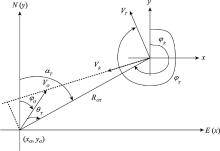
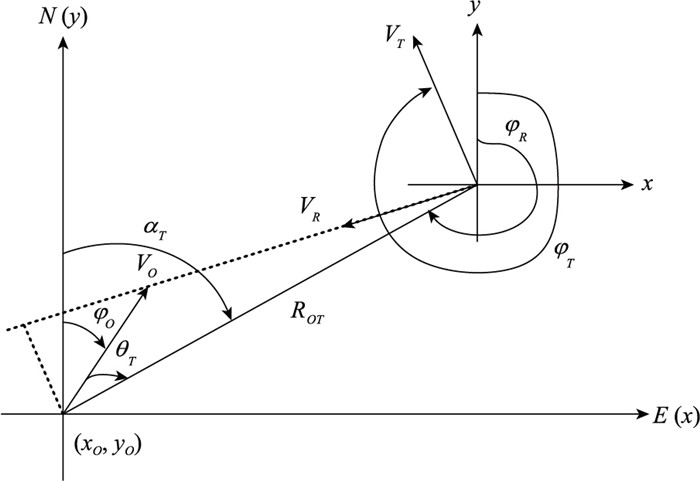
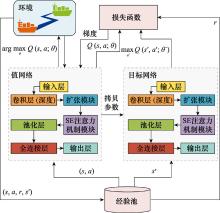
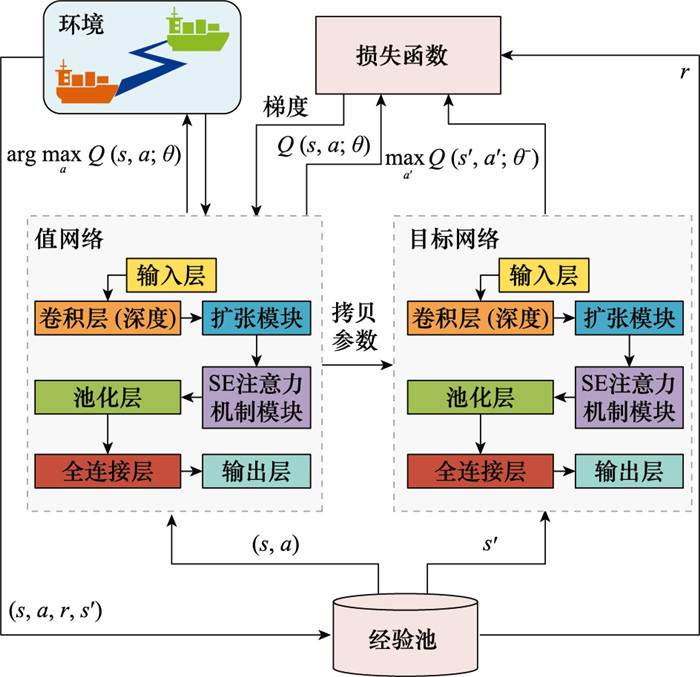
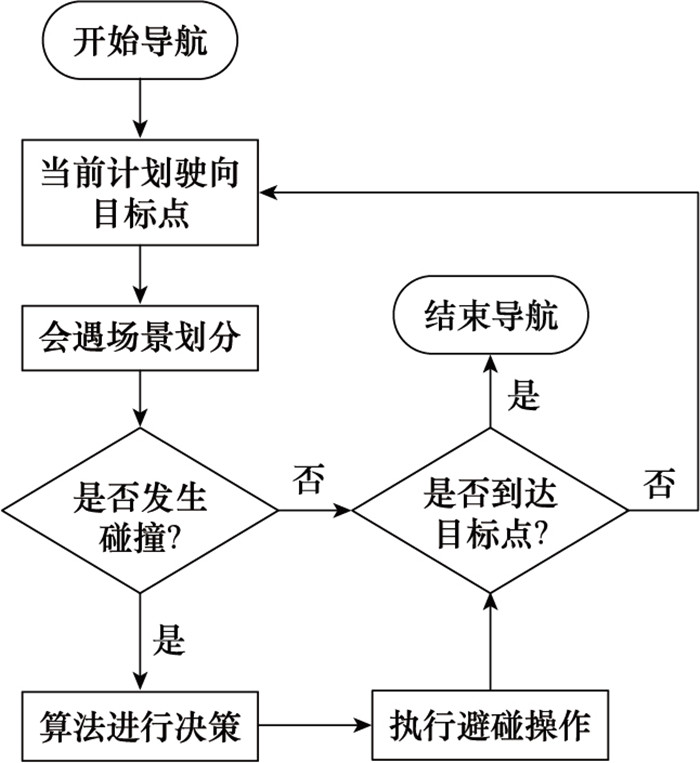
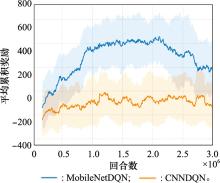
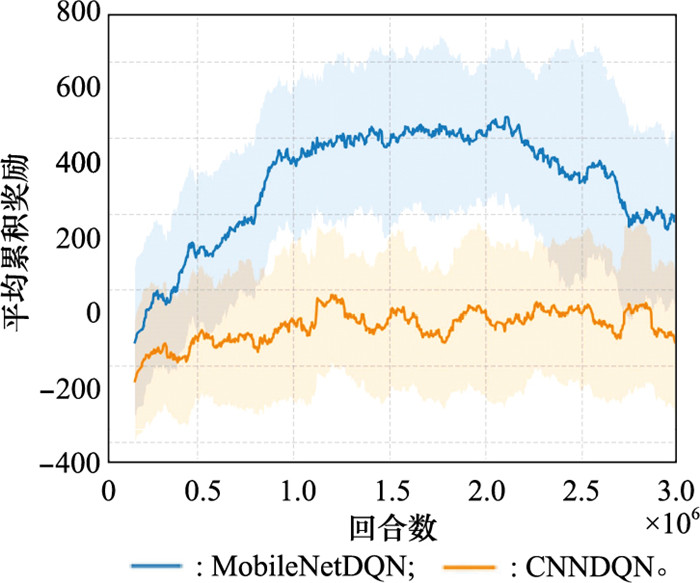
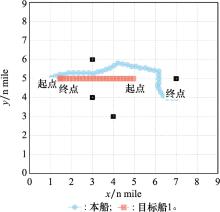
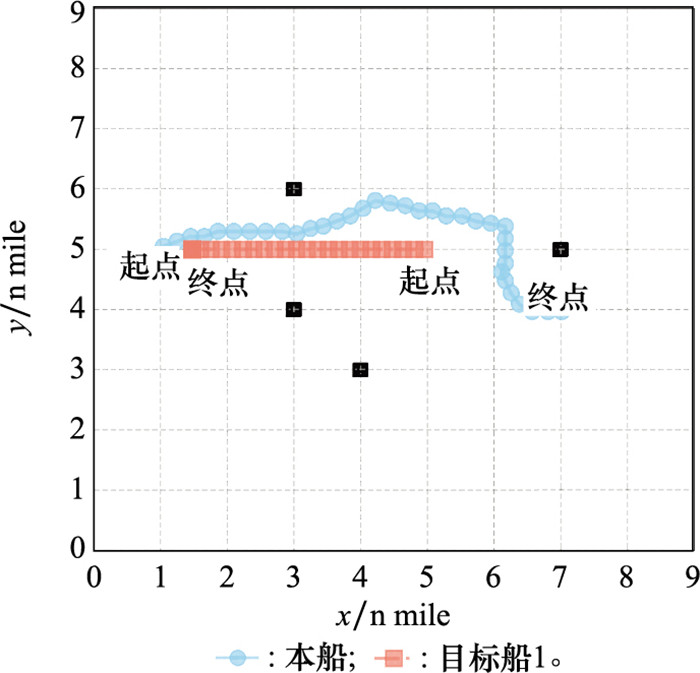
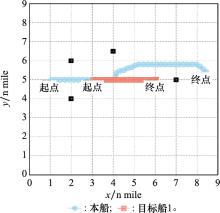
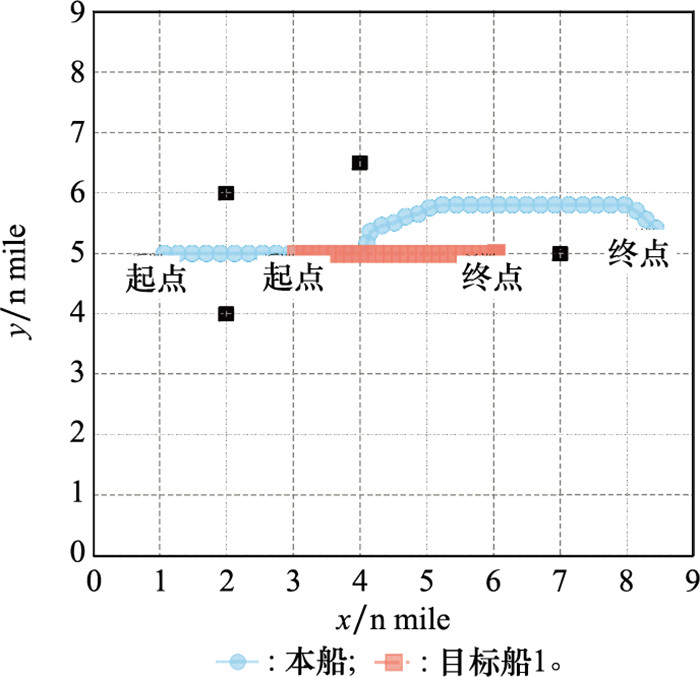
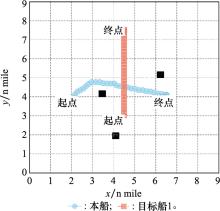
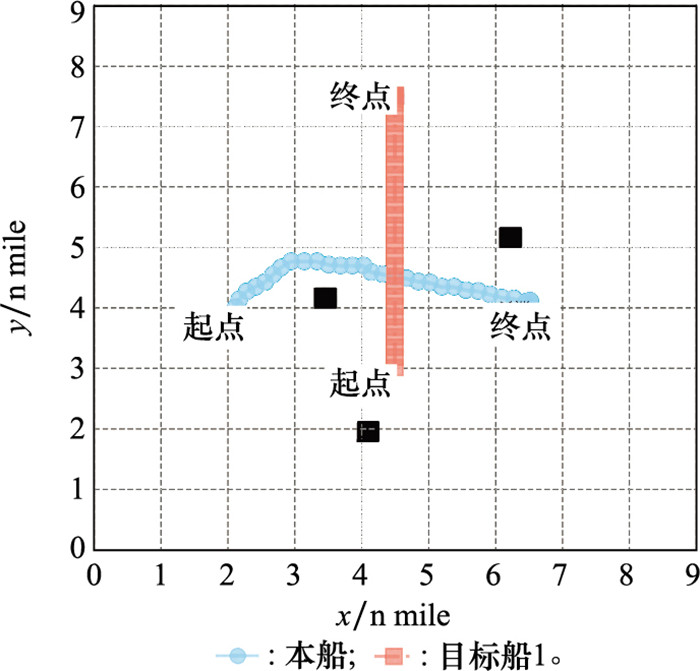
| 1 |
ROBLES A C. The COLREGS, mariners, and states[M]//ALFREDO C, ROBLES Jr. Vessel collisions in the law of the sea: the South China Sea arbitration. Singapore: Springer, 2022: 41-75.
|
| 2 |
王耀南, 安果维, 王传成, 等. 智能无人系统技术应用与发展趋势[J]. 中国舰船研究, 2022, 17 (5): 9- 26.
|
|
WANG Y N , AN G W , WANG C C , et al. Technology application and development trend of intelligent unmanned system[J]. Chinese Journal of Ship Research, 2022, 17 (5): 9- 26.
|
| 3 |
LIU B , SOARES C G . Recent developments in ship collision a nalysis and challenges to an accidental limit state design method[J]. Ocean Engineering, 2023, 270 (1): 113636- 113644.
|
| 4 |
LI B D , LU J , LU H , et al. Predicting maritime accident consequence scenarios for emergency response decisions using optimization-based decision tree approach[J]. Maritime Policy & Management, 2023, 50 (1): 19- 41.
|
| 5 |
GAN L X , YE B Y , HUANG Z Q , et al. Knowledge graph construction based on ship collision accident reports to improve maritime traffic safety[J]. Ocean & Coastal Management, 2023, 240 (2): 106660- 106674.
|
| 6 |
赵燕, 苑茹滨, 刘帅, 等. 基于航行经验的智能船舶自主避碰算法研究[J]. 天津航海, 2023, 251 (2): 68- 74.
|
|
ZHAO Y , YUAN R B , LIU S , et al. Research on intelligent ship autonomous collision avoidance algorithm based on navigation experience[J]. Tianjin Navigation, 2023, 251 (2): 68- 74.
|
| 7 |
YU Q , TEIXEIRA A P , LIU K , et al. Framework and application of multi-criteria ship collision risk assessment[J]. Ocean Engineering, 2022, 250 (4): 111006.
|
| 8 |
HWANG T , YOUN I H . Development of a graph-based collision risk situation model for validation of autonomous ships' collision avoidance systems[J]. Journal of Marine Science and Engineering, 2023, 11 (11): 2037- 2046.
doi: 10.3390/jmse11112037
|
| 9 |
赵贵祥, 王晨旭, 王贺平, 等. 改进速度障碍法的无人艇局部路径规划[J]. 系统工程与电子技术, 2023, 45 (12): 3975- 3983.
doi: 10.12305/j.issn.1001-506X.2023.12.28
|
|
ZHAO G X , WANG C X , WANG H P , et al. Local path planning for unmanned surface vehicle using improved velocity obstacle method[J]. Systems Engineering and Electronics, 2023, 45 (12): 3975- 3983.
doi: 10.12305/j.issn.1001-506X.2023.12.28
|
| 10 |
陈天德, 黄炎焱, 张永亮. 基于碰撞危险度的无陷阱动态航路规划[J]. 系统工程与电子技术, 2019, 41 (11): 2496- 2506.
doi: 10.3969/j.issn.1001-506X.2019.11.13
|
|
CHEN T D , HUANG Y Y , ZHANG Y L . Non-trap dynamic path planning based on collision risk[J]. Systems Engineering and Electronics, 2019, 41 (11): 2496- 2506.
doi: 10.3969/j.issn.1001-506X.2019.11.13
|
| 11 |
丁振国, 张树奎, 胡甚平. 长江水道事故风险预测模型优化[J]. 上海海事大学学报, 2022, 43 (1): 66- 70.
|
|
DING Z G , ZHANG S K , HU S P . Optimization of accident risk prediction model for Yangtze river waterway[J]. Journal of Shanghai Maritime University, 2022, 43 (1): 66- 70.
|
| 12 |
ZHONG S B , WEN Y Q , HUANG Y M , et al. Ontological ship behavior modeling based on COLREGs for knowledge reasoning[J]. Journal of Marine Science and Engineering, 2022, 10 (2): 203- 223.
|
| 13 |
VOLKOVA T A , BALYKINA Y E , BESPALOV A . Predicting ship trajectory based on neural networks using AIS data[J]. Journal of Marine Science and Engineering, 2021, 9 (3): 254- 265.
|
| 14 |
丁志国, 张新宇, 王程博, 等. 基于驾驶实践的无人船智能避碰决策方法[J]. 中国舰船研究, 2021, 16 (1): 96- 104.
|
|
DING Z G , ZHANG X Y , WANG C B , et al. Intelligent collision avoidance decision-making method for unmanned ships based on driving practice[J]. Chinese Journal of Ship Research, 2021, 16 (1): 96- 104.
|
| 15 |
XIE S , GAROFANO V , CHU X M , et al. Model predictive ship collision avoidance based on Q-learning beetle swarm antenna search and neural networks[J]. Ocean Engineering, 2019, 193 (5): 106609- 106633.
|
| 16 |
HU J Y , YAN D W , ZHENG J . Embed behavior decision making into ship collision avoidance path planning based on ant colony and Q-learning algorithm[J]. Industrial Engineering and Innovation Management, 2022, 5 (1): 20- 28.
|
| 17 |
WANG C B , ZHANG X Y , YANG Z L , et al. Collision avoidance for autonomous ship using deep reinforcement learning and prior-knowledge-based approximate representation[J]. Frontiers in Marine Science, 2023, 9 (3): 1084763- 1084777.
|
| 18 |
WANG C B , ZHANG X Y , GAO H B , et al. Optimizing anti-collision strategy for MASS: a safe reinforcement learning approach to improve maritime traffic safety[J]. Ocean & Coastal Management, 2024, 253 (54): 107161- 107186.
|
| 19 |
WANG C B , ZHANG X Y , GAO H B , et al. COLERGs-constrained safe reinforcement learning for realising MASS's risk-informed collision avoidance decision making[J]. Knowledge-Based Systems, 2024, 300 (8): 112205- 112225.
|
| 20 |
WANG C B , WANG N , GAO H B , et al. Knowledge transfer enabled reinforcement learning for efficient and safe autonomous ship collision avoidance[J]. International Journal of Machine Learning and Cybernetics, 2024, 15, 3714- 3731.
|
| 21 |
CUI Z W , GUAN W , ZHANG X K . Collision avoidance decision-making strategy for multiple USVs based on deep reinforcement learning algorithm[J]. Ocean Engineering, 2024, 308 (2): 118323- 118343.
|
| 22 |
ZHANG X Y , ZHENG K J , WANG C B , et al. A novel deep reinforcement learning for POMDP-based autonomous ship collision decision-making[J]. Neural Computing and Applications,
doi: 10.1007/s00521-023-08908-z
|
| 23 |
JIANG L L , AN L X , ZHANG X Y , et al. A human-like collision avoidance method for autonomous ship with attention-based deep reinforcement learning[J]. Ocean Engineering, 2022, 264 (3): 112378- 112390.
|
| 24 |
ZHENG K J , ZHANG X Y , WANG C B , et al. A partially observable multi-ship collision avoidance decision-making model based on deep reinforcement learning[J]. Ocean & Coastal Management, 2023, 242 (3): 106689- 106704.
|
| 25 |
SPAAN M T J. Partially observable Markov decision processes[M]// Reinforcement learning: state-of-the-art. WIERING M, OTTERLO M V. Heidelberg: Springer, 2012: 387-414.
|
| 26 |
RVOLODYMY M , KORAY K , DAVID S , et al. Human-level control through deep reinforcement learning[J]. Nature, 2018, 518 (7540): 529- 533.
|
| 27 |
TESAURO G . A self-teaching backgammon program, achieves master-level play[J]. Neural Computation, 1994, 6 (2): 215- 219.
|
| 28 |
WATTER M , SPRINGENBERG J , BOEDECKER J , et al. Embed to control: a locally linear latent dynamics model for control from raw images[J]. Advances in Neural Information Processing Systems, 2015, 28 (2): 165- 168.
|
| 29 |
HOWARD A G, ZHU M, CHEN B, et al. Mobilenets: efficient convolutional neural networks for mobile vision applications[EB/OL]. [2024-05-11]. https://arxiv.org/abs/1704.04861.
|
| 30 |
HOWARD A, SANDLER M, CHU G, et al. Searching for mobilenetv3[C]//Proc. of the IEEE/CVF International Conference on Computer Vision, 2019: 1314-1324.
|