
系统工程与电子技术 ›› 2023, Vol. 45 ›› Issue (3): 886-901.doi: 10.12305/j.issn.1001-506X.2023.03.31
唐斯琪1, 潘志松1,*, 胡谷雨1, 吴炀2, 李云波1
收稿日期:2021-09-23
出版日期:2023-02-25
发布日期:2023-03-09
通讯作者:
潘志松
作者简介:唐斯琪(1993—), 女, 博士研究生, 主要研究方向为卫星网络资源分配、智能卫星网络基金资助:Siqi TANG1, Zhisong PAN1,*, Guyu HU1, Yang WU2, Yunbo LI1
Received:2021-09-23
Online:2023-02-25
Published:2023-03-09
Contact:
Zhisong PAN
摘要:
未来天基信息网络(space information network, SIN)领域将面临由结构复杂、环境动态、业务多样等发展趋势带来的挑战。数据驱动的深度强化学习(deep reinforcement learning, DRL)作为一种应对上述挑战的可行思路被引入SIN领域。首先简要介绍了DRL的基本方法, 并全面回顾了其在SIN领域的研究进展。随后, 以星地网络场景的中继选择为例, 针对大规模节点问题提出了基于平均场的DRL算法, 并提出一种基于微调的模型迁移机制, 用以解决仿真环境与真实环境之间的数据差异问题。仿真证明了其对网络性能优化的效果, 且计算复杂度和时间效率均具有可行性。在此基础上归纳和总结了DRL方法在SIN领域的局限性与面临的挑战。最后,结合强化学习前沿进展, 讨论了此领域未来的努力方向。
中图分类号:
唐斯琪, 潘志松, 胡谷雨, 吴炀, 李云波. 深度强化学习在天基信息网络中的应用——现状与前景[J]. 系统工程与电子技术, 2023, 45(3): 886-901.
Siqi TANG, Zhisong PAN, Guyu HU, Yang WU, Yunbo LI. Application of deep reinforcement learning in space information network——status quo and prospects[J]. Systems Engineering and Electronics, 2023, 45(3): 886-901.
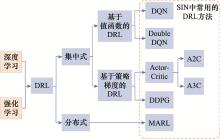
图1
SIN中常用的DRL方法分类"
图2
基于DRL的SIN方法框架图"
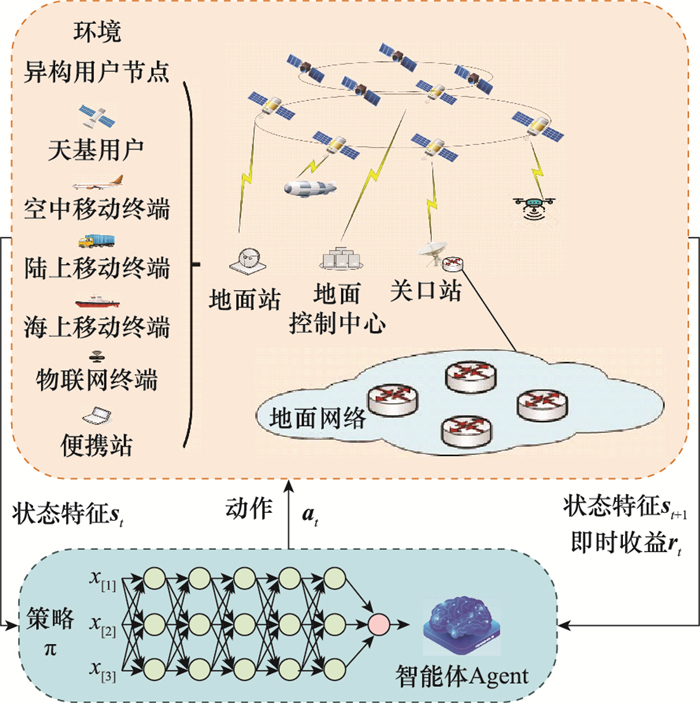

图3
卫星跳波束效果图"
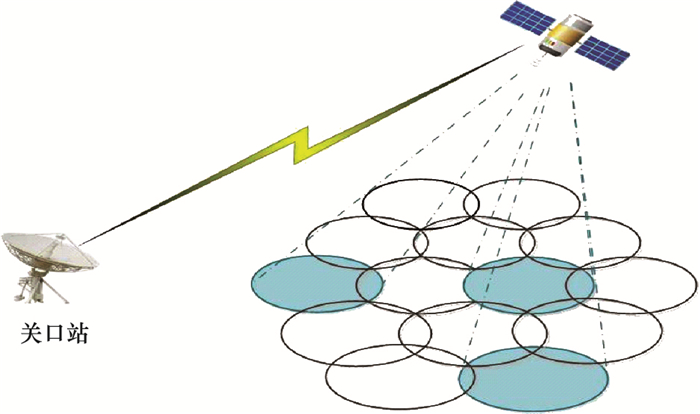
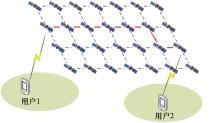
图4
卫星路由问题示意图"
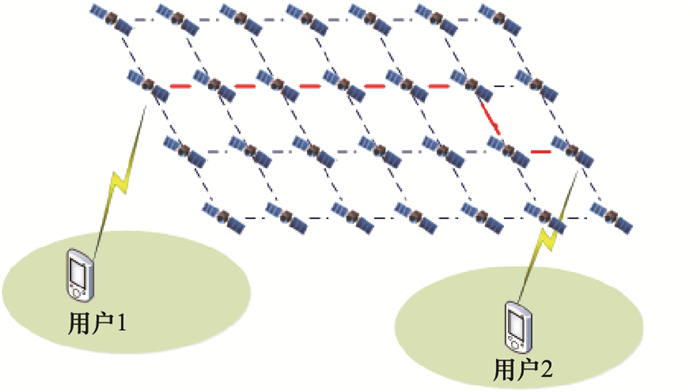
图5
卫星切换问题示意图"

表1
接入选择与卫星切换问题的区别"
| 问题 | 时机 | 目标 |
| 卫星切换 | 当前卫星无法继续服务 | 保持连续服务 |
| 接入选择 | 每一时刻 | 优化网络效能 |
表2
SIN中应用DRL可行研究方向的实用性分析"
| 研究方向 | 计算能力 | 实时性要求 | 算法效果 | 综合收益 | 进展 |
| 资源分配 | 有限, 星上计算 | 较低, 可根据算法速度设定动态调整资源的时隙 | 较好, 可大幅提高资源利用率 | 较高, 资源紧缺是SIN面临的重要问题 | NASA已进行星上验证[ |
| 跳波束 | 有限, 星上计算 | 较低, 可根据算法速度设定跳波束时隙 | 基于MADRL的方法效果较好, DRL方法面临维度灾难 | 较高, 解决了流量空间分布不均匀对资源的浪费 | 理论研究 |
| 接入网络选择 | 终端分布式决策, 不需星上计算 | 较低, 可根据算法速度设定接入调整频率 | 较好, 但需要收集多层异构网络的信息 | 较高, 优化了空天地一体化网络中的接入决策 | 理论研究 |
| 拥塞控制[ | 终端分布式决策, 不需星上计算 | 较低, 可根据算法速度设定窗口调整频率 | 较好, 问题简单直接, 且决策空间有限 | 较高, 但需要考虑网络设备更换的代价 | 理论研究 |
| 计算卸载 | 较高, 终端分布式决策, 不需星上计算 | 高, 但对卫星无要求, 对终端能力和算法时效性有要求 | 有待提高, 其与通信过程的资源分配问题耦合, 考虑因素多, 决策维度高, DRL训练难度大 | 目前有限, 但在计算任务日益增加、边缘能力日益增强的未来场景[ | 理论研究 |
| 卫星切换 | 终端分布式决策, 不需星上计算 | 较低, LEO卫星过顶时间为分钟级, DRL算法使用阶段的决策时间为毫秒级 | 有待提高, 现有方法没能与资源分配结合, 因此效果有待优化 | 现阶段收益有限, 对未来超大规模星座[ | 理论研究 |
| 路由选择 | 有限, 星上计算 | 高, 数据包转发对时效性要求高 | 在拥塞或者受干扰的网络中性能优于其他方法 | 较低, 路由决策无法牺牲时间代价 | 理论研究 |
| 接入协议优化[ | 终端分布式决策, 不需星上计算 | 高, 数据包流量大 | MARL效果较好, 而DRL在节点规模增大时, 收敛效果变差 | 较低, 每个发送数据包需要承受DRL决策的时间代价 | 理论研究 |
| 缓存 | 有限, 星上计算 | 高, 内容访问请求流量大 | 有待提高, 内容数量多, 缓存决策动作空间大 | 较低, 卫星缓存资源有限, 优化缓存策略取得的收益有限 | 理论研究 |
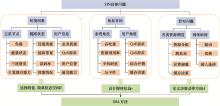
图6
基于DRL的SIN方法设计示意图"
表3
基于DRL的SIN现有研究总结"
| 领域 | 文献 | 场景 | 针对问题 | 优化目标 | DRL方法 |
| 资源分配 | [ | 多波束GEO卫星网络 | 用户时隙分配 | 用户满意度、能量和频谱利用率 | DQN |
| [ | 多波束GEO卫星网络 | 用户信道分配 | 呼通率 | DQN | |
| [ | LEO卫星物联网 | 用户信道分配 | 能量利用率 | DQN | |
| [ | 多波束GEO卫星网络 | 波束带宽分配 | 公平性、流量满足程度 | MARL | |
| [ | 多波束GEO卫星网络 | 波束功率分配 | 功率消耗、流量满足程度 | DDPG | |
| [ | GEO卫星网络 | 配置链路参数 | 吞吐量、误码率、功耗、带宽稳定 | DQN | |
| 跳波束 | [ | 多波束GEO卫星 | 波束点亮方案 | 传输时延 | DQN |
| [ | 多波束GEO卫星 | 波束点亮方案 | 实时服务时延, 非实时服务吞吐量, 公平性 | 双环DQN | |
| 计算卸载与缓存 | [ | 空天地一体化网络 | 任务卸载位置决策 | 平均处理时延 | DQN |
| [ | GEO卫星辅助车联网 | 任务卸载、计算和通信资源联合分配 | 时延 | 优化、DQN | |
| [ | 天地一体化网络 | 通信、缓存和计算资源联合分配 | 通信、缓存和计算开销 | DQN | |
| [ | 多层卫星网络 | 缓存策略、计算卸载、接入选择联合决策 | 缓存和计算开销 | A3C | |
| 路由选择 | [ | LEO卫星星座 | 下一跳路由选择 | 跳数、丢包率、拥塞避免 | Double DQN |
| [ | 天地一体化网络 | 下一跳路由选择 | 时延、丢包率、吞吐量 | DDPG | |
| [ | LEO卫星星座 | 下一跳路由选择 | 时延、卫星电池能量寿命 | DQN | |
| [ | LEO卫星星座 | 抗干扰路径集合计算 | 集合中链路不受干扰 | 近似策略优化 | |
| 卫星切换 | [ | LEO卫星星座 | 切换选择 | QoE | DQN |
| [ | LEO卫星星座 | 切换选择 | 切换次数 | MARL | |
| 接入选择 | [ | 空天地一体化网络 | 接入选择 | 吞吐量 | DQN |
| [ | 空天地一体化网络 | 接入选择与航迹调整 | 吞吐量 | DQN |
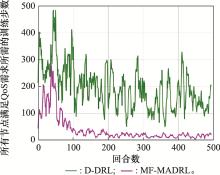
图7
两种DRL方法满足所有终端速率要求所需的训练步数"
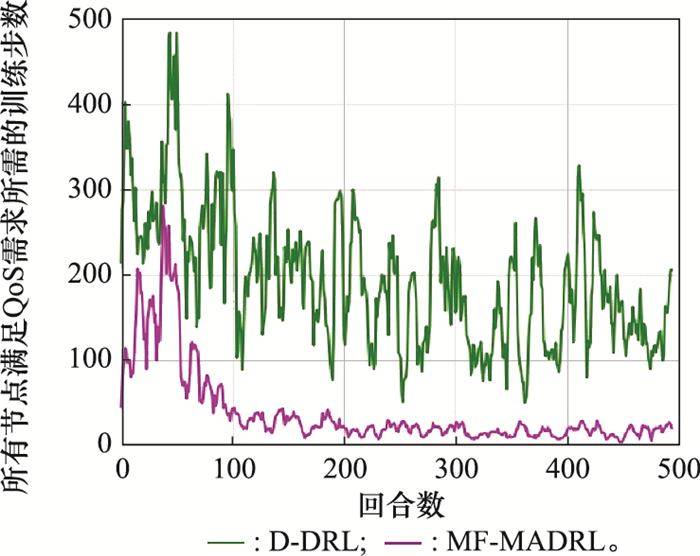
表4
各方法性能和可行性对比"
| 方法 | 吞吐量/Mbps | 运算时间/min | |||
| N=30 | N=120 | N=30 | N=120 | ||
| GA | 19.8 | — | 375.3 | — | |
| MRP | 16.3 | 36.8 | — | — | |
| D-DRL | 18.4 | 40.5 | 11.41 | 55.67 | |
| MF-MADRL | 20.1 | 46.7 | 4.15 | 8.27 | |
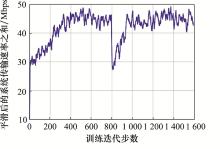
图8
迁移机制MF-MADRL算法收敛效果的提升"
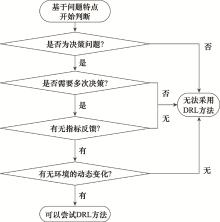
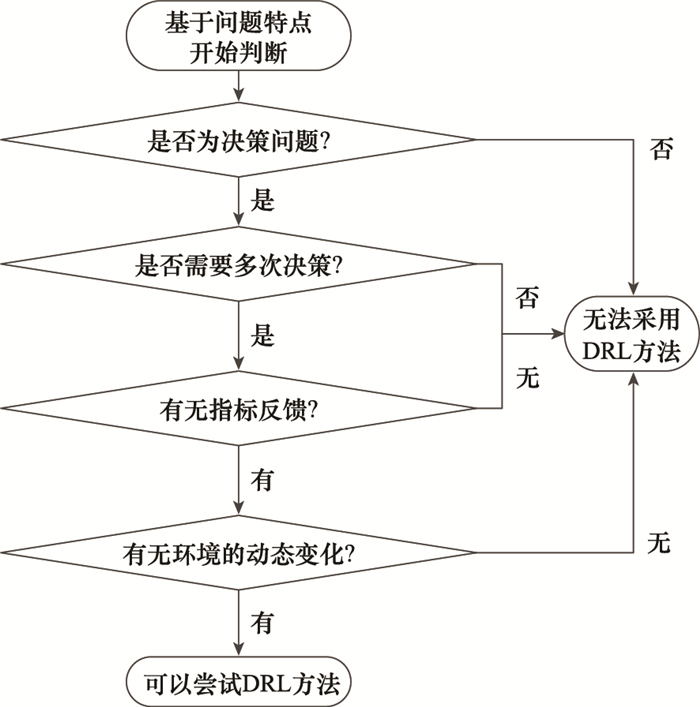
图9
DRL步骤是否可在SIN中应用的判断流程"
| 1 | LIU J J , SHI Y P , FADLULLAH Z M , et al. Space-air-ground integrated network: a survey[J]. IEEE Communications Surveys & Tutorials, 2018, 20 (4): 2714- 2741. |
| 2 |
ARULKUMARAN K , DEISENROTH M P , BRUNDAGE M , et al. A brief survey of deep reinforcement learning[J]. IEEE Signal Processing Magazine, 2017, 34 (6): 26- 38.
doi: 10.1109/MSP.2017.2743240 |
| 3 | 张沛, 刘帅军, 马治国, 等. 基于深度增强学习和多目标优化改进的卫星资源分配算法[J]. 通信学报, 2020, 41 (6): 51- 60. |
| ZHANG P , LIU S J , MA Z G , et al. Improved satellite resource allocation algorithm based on DRL and MOP[J]. Journal on Communications, 2020, 41 (6): 51- 60. | |
| 4 |
LIU S J , HU X , WANG W D . Deep reinforcement learning based dynamic channel allocation algorithm in multibeam satellite systems[J]. IEEE Access, 2018, 6, 15733- 15742.
doi: 10.1109/ACCESS.2018.2809581 |
| 5 |
刘建业, 王华, 周晚萌. 基于GA-SA的低轨星座传感器资源调度算法[J]. 系统工程与电子技术, 2018, 40 (11): 2476- 2481.
doi: 10.3969/j.issn.1001-506X.2018.11.13 |
|
LIU J Y , WANG H , ZHOU W M . LEO constellation sensor resources scheduling algorithm based on genetic and simulated annealing[J]. Systems Engineering and Electronics, 2018, 40 (11): 2476- 2481.
doi: 10.3969/j.issn.1001-506X.2018.11.13 |
|
| 6 |
ZHAO B K , LIU J H , WEI Z L , et al. A deep reinforcement learning based approach for energy-efficient channel allocation in satellite Internet of things[J]. IEEE Access, 2020, 8, 62197- 62206.
doi: 10.1109/ACCESS.2020.2983437 |
| 7 |
HU X , LIAO X L , LIU Z J , et al. Multi-agent deep reinforcement learning-based flexible satellite payload for mobile terminals[J]. IEEE Trans.on Vehicular Technology, 2020, 69 (9): 9849- 9865.
doi: 10.1109/TVT.2020.3002983 |
| 8 | LUIS J J G, GUERSTER M, DEL PORTILLO I, et al. Deep reinforcement learning for continuous power allocation in flexible high throughput satellites[C]//Proc. of the 2nd IEEE Cognitive Communications for Aerospace Applications Workshop, 2019. |
| 9 | LUIS J J G, PACHLER N, GUERSTER M, et al. Artificial intelligence algorithms for power allocation in high throughput sate- llites: a comparison[C]//Proc. of the IEEE Aerospace Conference, 2020. |
| 10 |
FERREIRA P V R , PAFFENROTH R , WYGLINSKI A M , et al. Multi-objective reinforcement learning for cognitive sate-llite communications using deep neural network ensembles[J]. IEEE Journal on Selected Areas in Communications, 2018, 36 (5): 1030- 1041.
doi: 10.1109/JSAC.2018.2832820 |
| 11 |
HU X , LIU S J , WANG Y P , et al. Deep reinforcement learning-based beam Hopping algorithm in multibeam satellite systems[J]. IET Communications, 2019, 13 (16): 2485- 2491.
doi: 10.1049/iet-com.2018.5774 |
| 12 |
HU X , ZHANG Y C , LIAO X L , et al. Dynamic beam hopping method based on multi-objective deep reinforcement learning for next generation satellite broadband systems[J]. IEEE Trans.on Broadcasting, 2020, 66 (3): 630- 646.
doi: 10.1109/TBC.2019.2960940 |
| 13 |
TANG Q Q , FEI Z S , LI B , et al. Computation offloading in LEO satellite networks with hybrid cloud and edge computing[J]. IEEE Internet of Things Journal, 2021, 8 (11): 9164- 9176.
doi: 10.1109/JIOT.2021.3056569 |
| 14 | ZHOU C H , WU W , HE H L , et al. Deep reinforcement learning for delay-oriented IoT task scheduling in space-air-ground integrated network[J]. IEEE Trans.on Wireless Communications, 2020, 20 (2): 911- 925. |
| 15 | CUI G F , LONG Y T , XU L X , et al. Joint offloading and resource allocation for satellite assisted vehicle-to-vehicle communication[J]. IEEE Systems Journal, 2020, 15 (3): 3958- 3969. |
| 16 |
QIU C , YAO H P , YU F R , et al. Deep Q-learning aided networking, caching, and computing resources allocation in software-defined satellite-terrestrial networks[J]. IEEE Trans.on Vehicular Technology, 2019, 68 (6): 5871- 5883.
doi: 10.1109/TVT.2019.2907682 |
| 17 |
MENG X L , WU L D , YU S B . Research on resource allocation method of space information networks based on deep reinforcement learning[J]. Remote Sensing, 2019, 11 (4): 448.
doi: 10.3390/rs11040448 |
| 18 | 朱立东, 张勇, 贾高一. 卫星互联网路由技术现状及展望[J]. 通信学报, 2021, 42 (8): 33- 42. |
| ZHU L D , ZHANG Y , JIA G Y . Current status and future prospects of routing technologies for satellite Internet[J]. Journal on Communications, 2021, 42 (8): 33- 42. | |
| 19 |
WANG C , WANG H W , WANG W D . A two-hops state-aware routing strategy based on deep reinforcement learning for LEO satellite networks[J]. Electronics, 2019, 8 (9): 920.
doi: 10.3390/electronics8090920 |
| 20 | TU Z, ZHOU H C, LI K, et al. A routing optimization method for software-defined SGIN based on deep reinforcement learning[C]//Proc. of the IEEE Global Communications Conference Workshops, 2019. |
| 21 | LIU J H , ZHAO B K , XIN Q , et al. DRL-ER: an intelligent energy-aware routing protocol with guaranteed delay bounds in satellite mega-constellations[J]. IEEE Trans.on Network Science and Engineering, 2020, 8 (4): 2872- 2884. |
| 22 |
HAN C , HUO L Y , TONG X H , et al. Spatial anti-jamming scheme for internet of satellites based on the deep reinforcement learning and stackelberg game[J]. IEEE Trans.on Vehi-cular Technology, 2020, 69 (5): 5331- 5342.
doi: 10.1109/TVT.2020.2982672 |
| 23 | 杨斌, 何锋, 靳瑾, 等. LEO卫星通信系统覆盖时间和切换次数分析[J]. 电子与信息学报, 2014, 36 (4): 804- 809. |
| YANG B , HE F , JIN J , et al. Analysis of coverage time and handoff number on LEO satellite communication systems[J]. Journal of Electronics & Information Technology, 2014, 36 (4): 804- 809. | |
| 24 |
XU H H , LI D S , LIU M L , et al. QoE-driven intelligent hand- over for user-centric mobile satellite networks[J]. IEEE Trans.on Vehicular Technology, 2020, 69 (9): 10127- 10139.
doi: 10.1109/TVT.2020.3000908 |
| 25 | HE S X, WANG T Y, WANG S W. Load-aware satellite handover strategy based on multi-agent reinforcement learning[C]//Proc. of the IEEE Global Communications Conference, 2020. |
| 26 | CAO Y , LIEN S Y , LIANG Y C . Deep reinforcement learning for multi-user access control in non-terrestrial networks[J]. IEEE Trans.on Communications, 2020, 69 (3): 1605- 1619. |
| 27 | LEE J H, PARK J, BENNIS M, et al. Integrating LEO sate-llite and UAV relaying via reinforcement learning for non-terrestrial networks[C]//Proc. of the IEEE Global Communications Conference, 2020. |
| 28 | LI X N, ZHANG H J, LI W, et al. Multi-agent DRL for user association and power control in terrestrial-satellite network[C]//Proc. of the IEEE Global Communications Conference, 2021. |
| 29 | FERIANI A , HOSSAIN E . Single and multi-agent deep reinforcement learning for AI-enabled wireless networks: a tutorial[J]. IEEE Communications Surveys & Tutorials, 2021, 23 (2): 1226- 1252. |
| 30 | FERREIRA P V R , PAFFENROTH R , WYGLINSKI A M , et al. Reinforcement learning for satellite communications: From LEO to deep space operations[J]. IEEE Communications Magazine, 2019, 57 (5): 70- 75. |
| 31 | MAI T, YAO H P, JING Y Q, et al. Self-learning congestion control of MPTCP in satellites communications[C]//Proc. of the 15th International Wireless Communications & Mobile Computing Conference, 2019: 775-780. |
| 32 | XIE R C , TANG Q Q , WANG Q N , et al. Satellite-terrestrial integrated edge computing networks: architecture, challenges, and open issues[J]. IEEE Network, 2020, 34 (3): 224- 231. |
| 33 | HASSAN N U L , HUANG C W , YUEN C , et al. Dense small satellite networks for modern terrestrial communication systems: benefits, infrastructure, and technologies[J]. IEEE Wireless Communications, 2020, 27 (5): 96- 103. |
| 34 | ZHAO B , REN G L , DONG X D , et al. Distributed Q-learning based joint relay selection and access control scheme for IoT-oriented satellite terrestrial relay networks[J]. IEEE Communications Letters, 2021, 25 (6): 1901- 1905. |
| 35 | MNIH V , KAVUKCUOGLU K , SILVER D , et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518 (7540): 529- 533. |
| 36 | YANG Y D, LUO R, LI M N, et al. Mean field multi-agent reinforcement learning[C]//Proc. of the 35th International Conference on Machine Learning, 2018: 5571-5580. |
| 37 | ARTI M K . Channel estimation and detection in satellite communication systems[J]. IEEE Trans.on Vehicular Technology, 2016, 65 (12): 10173- 10179. |
| 38 | BANKEY V , UPADHYAY P K , DA COSTA D B , et al. Performance analysis of multi-antenna multiuser hybrid satellite-terrestrial relay systems for mobile services delivery[J]. IEEE Access, 2018, 6, 24729- 24745. |
| 39 | PACHECO F , EXPOSITO E , GINESTE M . A framework to classify heterogeneous Internet traffic with machine learning and deep learning techniques for satellite communications[J]. Computer Networks, 2020, 173, 107213. |
| 40 | RAO S K . Advanced antenna technologies for satellite communications payloads[J]. IEEE Trans.on Antennas and Propagation, 2015, 63 (4): 1205- 1217. |
| 41 | 万里鹏, 兰旭光, 张翰博, 等. 深度强化学习理论及其应用综述[J]. 模式识别与人工能, 2019, 32 (1): 67- 81. |
| WAN L P , LAN X G , ZHANG H B , et al. A review of deep reinforcement learning theory and application[J]. Pattern Re-cognition and Artificial Intelligence, 2019, 32 (1): 67- 81. | |
| 42 | ARULKUMARAN K , DEISENROTH M P , BRUNDAGE M , et al. Deep reinforcement learning: a brief survey[J]. IEEE Signal Processing Magazine, 2017, 34 (6): 26- 38. |
| 43 | NG A Y, RUSSELL S J. Algorithms for inverse reinforcement learning[C]//Proc. of the 17th International Conference on Machine Learning, 2000: 663-670. |
| 44 | ZHU Z D, LIN K X, ZHOU J Y. Transfer learning in deep reinforcement learning: a survey[EB/OL]. [2021-08-23]. https://arxiv.org/abs/2009.07888. |
| 45 | 谭晓阳, 张哲. 元强化学习综述[J]. 南京航空航天大学学报, 2021, 53 (5): 653- 663. |
| TAN X Y , ZHANG Z . Review on meta reinforcement learning[J]. Journal of Nanjing University of Aeromautics and Astronautics, 2021, 53 (5): 653- 663. | |
| 46 | 周文吉, 俞扬. 分层强化学习综述[J]. 智能系统学报, 2017, 12 (5): 590- 594. |
| ZHOU W J , YU Y . Summarize of hierarchical reinforcement learning[J]. CAAI Transactions on Intelligent Systems, 2017, 12 (5): 590- 594. | |
| 47 | GENG Y Z , LIU E W , WANG R , et al. Hierarchical reinforcement learning for relay selection and power optimization in two-hop cooperative relay network[J]. IEEE Trans.on Communications, 2021, 70 (1): 171- 184. |
| 48 | YANG R, SUN X, NARASIMHAN K. A generalized algorithm for multi-objective reinforcement learning and policy ada-ptation[C]//Proc. of the Conference and Workshop on Neural Information Processing Systems, 2019. |
| 49 | HOCHREITER S , SCHMIDHUBER J . Long short-term memory[J]. Neural Computation, 1997, 9 (8): 1735- 1780. |
| 50 | GOODFELLOW I , POUGET-ABADIE J , MIRZA M , et al. Generative adversarial nets[J]. Advances in Neural Information Processing Systems, 2014, 27, 1- 9. |
| 51 | YAN S, XIONG Y, LIN D. Spatial temporal graph convolutional networks for skeleton-based action recognition[C]//Proc. of the 32ed Association for the Advance of Artificial Intelligence, 2018. |
| 52 | NURVITADHI E, SIM J, SHEFFIELD D, et al. Accelerating recurrent neural networks in analytics servers: Comparison of FPGA, CPU, GPU, and ASIC[C]// Proc. of the IEEE 26th International Conference on Field Programmable Logic and App- lications, 2016. |
| 53 | 李德仁, 沈欣, 李迪龙, 等. 论军民融合的卫星通信、遥感、导航一体天基信息实时服务系统[J]. 武汉大学学报(信息科学版), 2017, 42 (11): 1501- 1505. |
| LI D R , SHEN X , LI D L , et al. On civil-military integrated space-based real-time information service system[J]. Geomatics and Information Science of Wuhan University, 2017, 42 (11): 1501- 1505. | |
| 54 | HINTON G, VINYALS O, DEAN J. Distilling the knowledge in a neural network[EB/OL]. [2021-08-23]. https://arxiv.org/abs/1503.02531. |
| 55 | LIU Z, LI J, SHEN Z, et al. Learning efficient convolutional networks through network slimming[C]//Proc. of the IEEE International Conference on Computer Vision, 2017: 2736-2744. |
| [1] | 张广大, 任清华, 樊志凯. 基于能量采集的友好干扰机辅助下多中继系统安全传输方案[J]. 系统工程与电子技术, 2023, 45(3): 876-885. |
| [2] | 李信, 李勇军, 赵尚弘. 基于深度强化学习的卫星光网络波长路由算法[J]. 系统工程与电子技术, 2023, 45(1): 264-270. |
| [3] | 王冠, 茹海忠, 张大力, 马广程, 夏红伟. 弹性高超声速飞行器智能控制系统设计[J]. 系统工程与电子技术, 2022, 44(7): 2276-2285. |
| [4] | 孟泠宇, 郭秉礼, 杨雯, 张欣伟, 赵柞青, 黄善国. 基于深度强化学习的网络路由优化方法[J]. 系统工程与电子技术, 2022, 44(7): 2311-2318. |
| [5] | 杨清清, 高盈盈, 郭玙, 夏博远, 杨克巍. 基于深度强化学习的海战场目标搜寻路径规划[J]. 系统工程与电子技术, 2022, 44(11): 3486-3495. |
| [6] | 陆音, 汪高瑜, 杨楚瀛, 杨凌青, 赵坤, 朱洪波. 基于单源最优路径的NOMA中继选择与协作传输[J]. 系统工程与电子技术, 2022, 44(1): 292-298. |
| [7] | 高昂, 董志明, 李亮, 宋敬华, 段莉. MADDPG算法并行优先经验回放机制[J]. 系统工程与电子技术, 2021, 43(2): 420-433. |
| [8] | 马文, 李辉, 王壮, 黄志勇, 吴昭欣, 陈希亮. 基于深度随机博弈的近距空战机动决策[J]. 系统工程与电子技术, 2021, 43(2): 443-451. |
| [9] | 高昂, 郭齐胜, 董志明, 杨绍卿. 基于EAS+MADRL的多无人车体系效能评估方法研究[J]. 系统工程与电子技术, 2021, 43(12): 3643-3651. |
| [10] | 张堃, 李珂, 时昊天, 张振冲, 刘泽坤. 基于深度强化学习的UAV航路自主引导机动控制决策算法[J]. 系统工程与电子技术, 2020, 42(7): 1567-1574. |
| [11] | 邹虹, 万彬, 吴大鹏. 带有协作意愿感知的边缘协作中继机制[J]. 系统工程与电子技术, 2020, 42(5): 1173-1181. |
| [12] | 孔槐聪, 林敏, 刘笑宇, 吴雪雯, 王金元. 基于中继选择的星地协作传输系统性能分析[J]. 系统工程与电子技术, 2020, 42(1): 198-205. |
| [13] | 谢浩, 郭爱煌, 宋春林, 焦润泽. LTE-V下基于深度强化学习的基站选择算法[J]. 系统工程与电子技术, 2019, 41(7): 1652-1657. |
| [14] | 李敏, 王平山, 王凯莉. 多源多目标网络下基于包聚合的选择协作方法[J]. 系统工程与电子技术, 2019, 41(5): 1149-1155. |
| [15] | 王恒, 魏欣羽, 李敏. 面向多源多目标协作网络的中继选择方法[J]. 系统工程与电子技术, 2017, 39(6): 1358-1365. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||