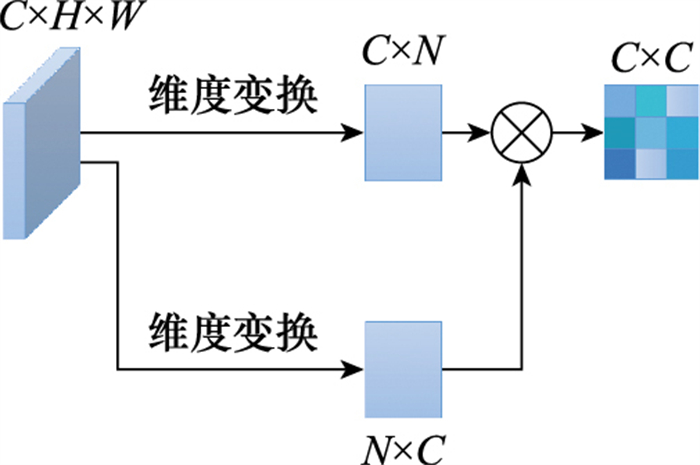
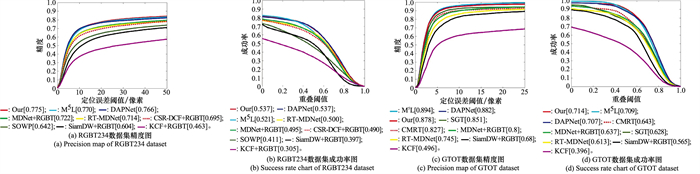
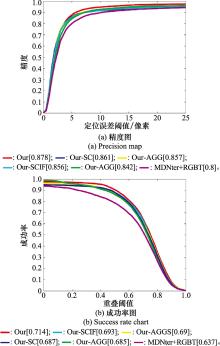
| 1 |
谢瑜, 陈莹. 通道裁剪下的多特征组合目标跟踪算法[J]. 系统工程与电子技术, 2020, 42 (4): 764- 772.
|
|
XIE Y , CHEN Y . Multi-feature combined target tracking algorithm based on channel clipping[J]. Systems Engineering and Electronics, 2020, 42 (4): 764- 772.
|
| 2 |
ZHU Y, MOTTAGHI R, KOLVE E, et al. Target-driven visual navigation in indoor scenes using deep reinforcement learning[C]// Proc. of the IEEE International Conference on Robotics and Automation, 2017: 3357-3364.
|
| 3 |
YU H F , LI G , ZHANG W Z , et al. The unmanned aerial vehicle benchmark: object detection, tracking and baseline[J]. International Journal of Computer Vision, 2020, 128 (5): 1141- 1159.
doi: 10.1007/s11263-019-01266-1
|
| 4 |
DUAN X, XIE S S, MENG Y Z, et al. Brain computer integration controlled unmanned vehicle for target reconnaissance[C]//Proc. of the IEEE International Conference on Unmanned Systems, 2019: 35-39.
|
| 5 |
张开华, 樊佳庆, 刘青山. 视觉目标跟踪十年研究进展[J]. 计算机科学, 2021, 48 (3): 40- 49.
|
|
ZHANG K H , FAN J Q , LIU Q S . Advances on visual object tracking in past decade[J]. Computer Science, 2021, 48 (3): 40- 49.
|
| 6 |
黄月平, 李小锋, 杨小冈, 等. 基于相关滤波的视觉目标跟踪算法新进展[J]. 系统工程与电子技术, 2021, 43 (8): 2051- 2065.
|
|
HUANG Y P , LI X F , YANG X G , et al. New development of visual object tracking algorithm based on correlation filtering[J]. Systems Engineering and Electronics, 2021, 43 (8): 2051- 2065.
|
| 7 |
CHEN Z C, ZHONG B H, LI G, et al. Siamese box adaptive network for visual tracking[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 6668-6677.
|
| 8 |
WU Y H, BLASCH E, CHEN G, et al. Multiple source data fusion via sparse representation for robust visual tracking[C]//Proc. of the 14th International Conference on Information Fusion, 2011.
|
| 9 |
LIU H Y , SUN F F . Fusion tracking in color and infrared images using joint sparse representation[J]. Science China Information Sciences, 2012, 55 (3): 590- 599.
doi: 10.1007/s11432-011-4536-9
|
| 10 |
LI C, ZHAO N N, LU Y F, et al. Weighted sparse representation regularized graph learning for RGB-T object tracking[C]// Proc. of the 25th ACM International Conference on Multimedia, 2017: 1856-1864.
|
| 11 |
LI C, ZHU C, HUANG Y P, et al. Cross-modal ranking with soft consistency and noisy labels for robust RGB-T tracking[C]// Proc. of the European Conference on Computer Vision, 2018: 808-823.
|
| 12 |
ZHANG X H, ZHANG X F, DU X, et al. Learning multi-domain convolutional network for RGB-T visual tracking[C]//Proc. of the 11th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics, 2018.
|
| 13 |
NAM H, HAN B B. Learning multi-domain convolutional neural networks for visual tracking[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2016: 4293-4302.
|
| 14 |
LI C , CHENG H Y , HU S , et al. Learning collaborative sparse representation for grayscale-thermal tracking[J]. IEEE Trans.on Image Processing, 2016, 25 (12): 5743- 5756.
doi: 10.1109/TIP.2016.2614135
|
| 15 |
LAN X X, YE M, ZHANG S H, et al. Robust collaborative discriminative learning for RGB-infrared tracking[C]//Proc. of the AAAI Conference on Artificial Intelligence New Orleans, 2018.
|
| 16 |
ZHU Y F , LI C D , TANG J , et al. Quality-aware feature aggregation network for robust RGB-T tracking[J]. IEEE Trans.on Intelligent Vehicles, 2020, 6 (1): 121- 130.
|
| 17 |
LI C P , LIANG X , LU Y H , et al. RGB-T object tracking: benchmark and baseline[J]. Pattern Recognition, 2019, 96, 106977.
doi: 10.1016/j.patcog.2019.106977
|
| 18 |
SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[C]//Proc. of the 3rd International Conference on Learning Representations, 2015.
|
| 19 |
LI C P , WU X , ZHAO N S , et al. Fusing two-stream convolutional neural networks for RGB-T object tracking[J]. Neurocomputing, 2018, 281, 78- 85.
doi: 10.1016/j.neucom.2017.11.068
|
| 20 |
ZHENG Q , CHEN Y S . Feature pyramid of bi-directional stepped concatenation for small object detection[J]. Multimedia Tools and Applications, 2021, 38 (4): 314- 322.
doi: 10.1007/s11042-021-10718-1?utm_source=xmol
|
| 21 |
CHEN L C , PAPANDREOU G , KOKKINOS I , et al. Deeplab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs[J]. IEEE Trans.on Pattern Analysis and Machine Intelligence, 2017, 40 (4): 834- 848.
|
| 22 |
HE K, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN[C]//Proc. of the IEEE International Conference on Computer Vision, 2017: 2961-2969.
|
| 23 |
FU J, LIU J, TIAN H F, et al. Dual attention network for scene segmentation[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2019: 3146-3154.
|
| 24 |
JUNG I, SON J, BAEK M, et al. Real-time mdnet[C]//Proc. of the European Conference on Computer Vision, 2018: 83-98.
|
| 25 |
GIRSHICK R. Fast R-CNN[C]//Proc. of the IEEE International Conference on Computer Vision, 2015: 1440-1448.
|
| 26 |
LUKEZIC A, VOJIR T, CEHOVIN Z L, et al. Discriminative correlation filter with channel and spatial reliability[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 6309-6318.
|
| 27 |
HENRIQUES J F , CASEIRO R , MARTINS P , et al. High-speed tracking with kernelized correlation filters[J]. IEEE Trans.on Pattern Analysis and Machine Intelligence, 2014, 37 (3): 583- 596.
|
| 28 |
ZHU Y Y, LI C, LUO B F, et al. Dense feature aggregation and pruning for RGB-T tracking[C]//Proc. of the 27th ACM International Conference on Multimedia, 2019: 465-472.
|
| 29 |
ZHANG Z, PENG H. Deeper and wider siamese networks for real-time visual tracking[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2019: 4591-4600.
|
| 30 |
TU Z, LIN C, LI C, et al. M5L: multi-modal multi-margin metric learning for RGB-T tracking[EB/OL]. [2021-03-24]. https://arxiv.org/abs/2003.07650v1,2003.07650,2020.
|