Systems Engineering and Electronics ›› 2025, Vol. 47 ›› Issue (10): 3168-3178.doi: 10.12305/j.issn.1001-506X.2025.10.05
• Electronic Technology • Previous Articles
Local feature encode-decoding based 3D target detection of autonomous driving
Kai SHAO1,2,3,*( ), Guang WU1, Yan LIANG1, Xingfa XI1, Linjia GAO1
), Guang WU1, Yan LIANG1, Xingfa XI1, Linjia GAO1
- 1. School of Communication and Information Engineering,Chongqing University of Posts and Telecommunications,Chongqing 400065,China
2. Chongqing Key Laboratory of Mobile Communications Technology,Chongqing University of Posts and Telecommunications,Chongqing 400065,China
3. Engineering Research Center of Mobile Communications of the Ministry of Education,Chongqing University of Posts and Telecommunications,Chongqing 400065,China
-
Received:2024-10-15Online:2025-10-25Published:2025-10-23 -
Contact:Kai SHAO E-mail:shaokai@cqupt.edu.cn
CLC Number:
Cite this article
Kai SHAO, Guang WU, Yan LIANG, Xingfa XI, Linjia GAO. Local feature encode-decoding based 3D target detection of autonomous driving[J]. Systems Engineering and Electronics, 2025, 47(10): 3168-3178.
share this article
Fig.1
LFED-RCNN network structure diagram"
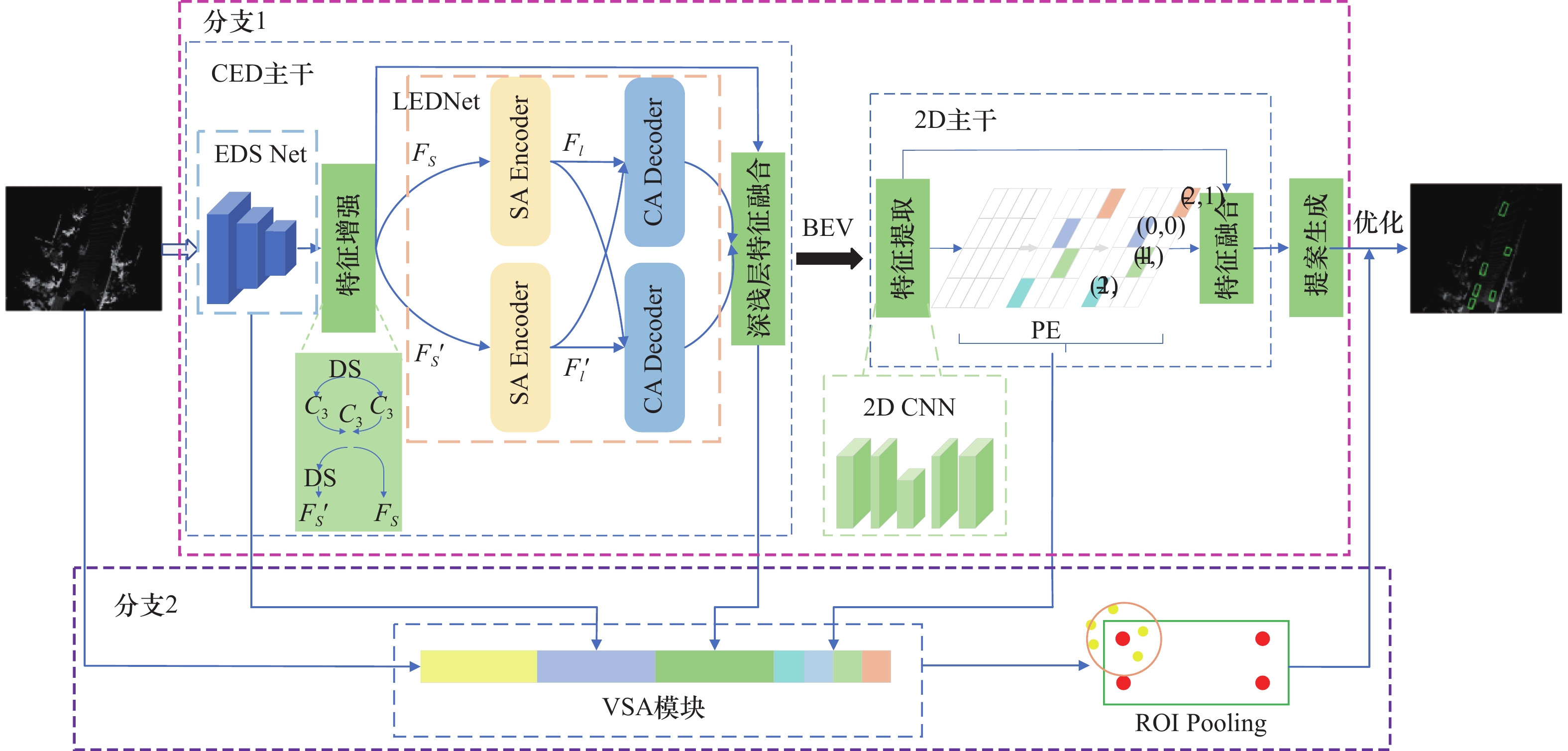

Fig.2
EDSNet structure"
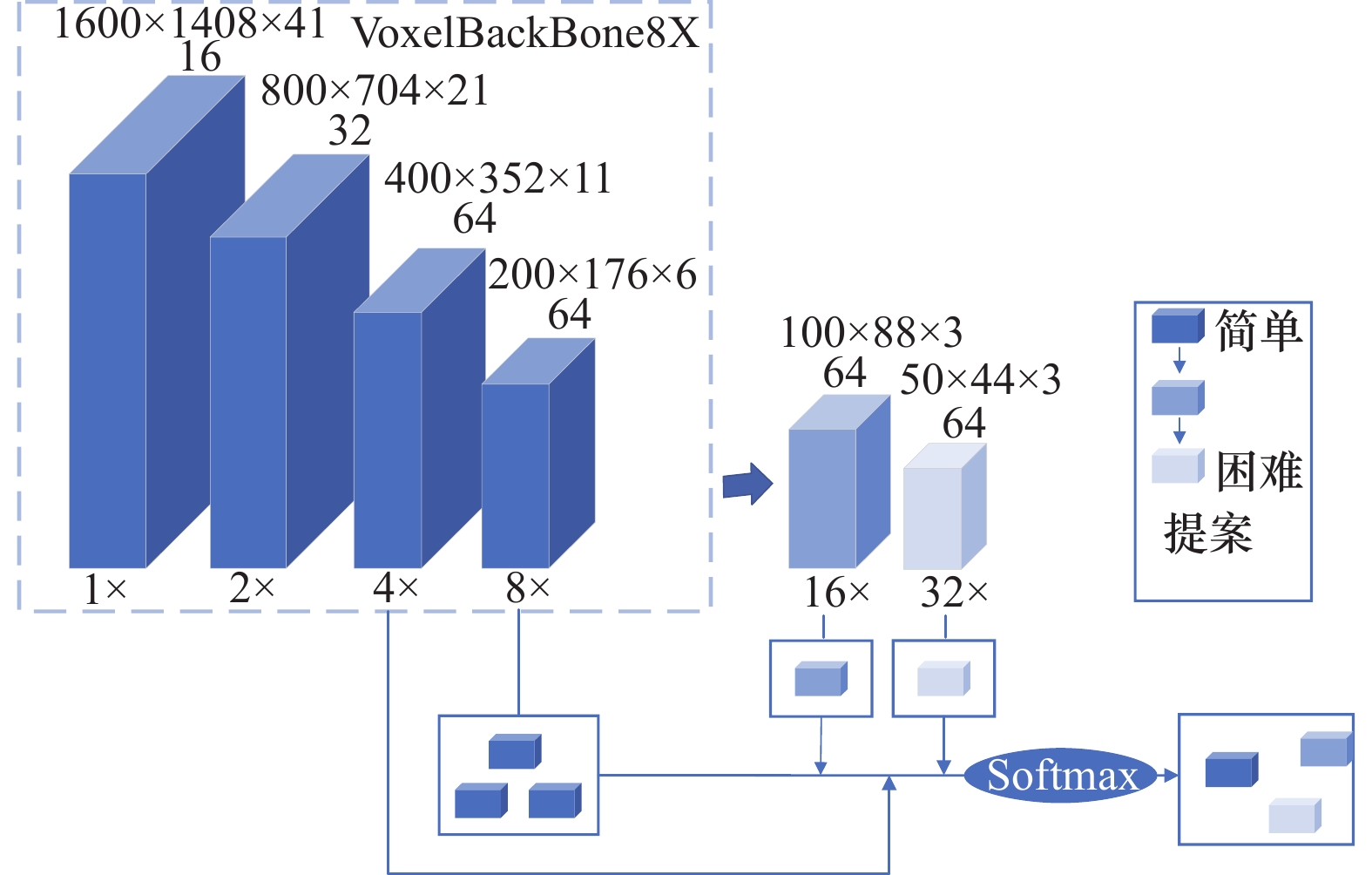
Fig.3
SA Encoder structure"
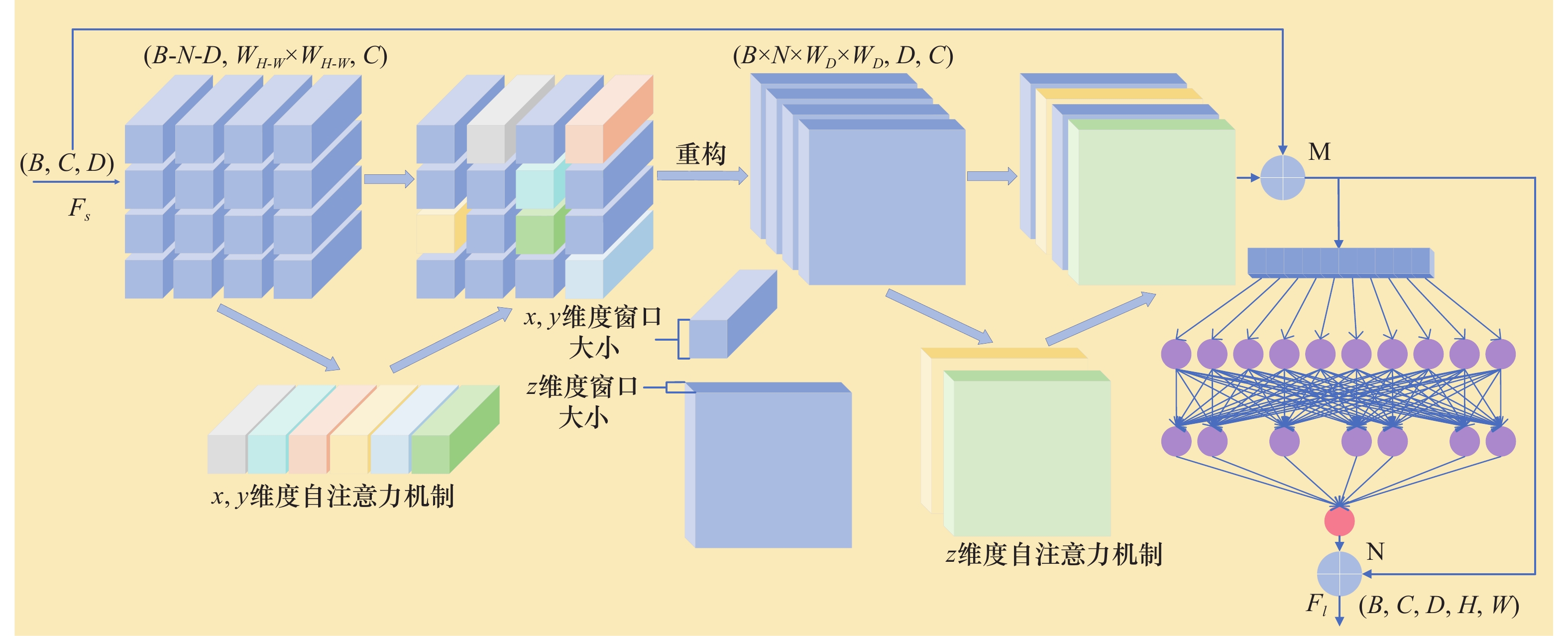
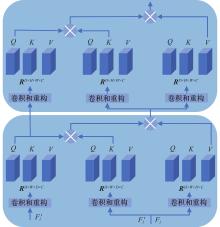
Fig.4
CA Decoder structure"
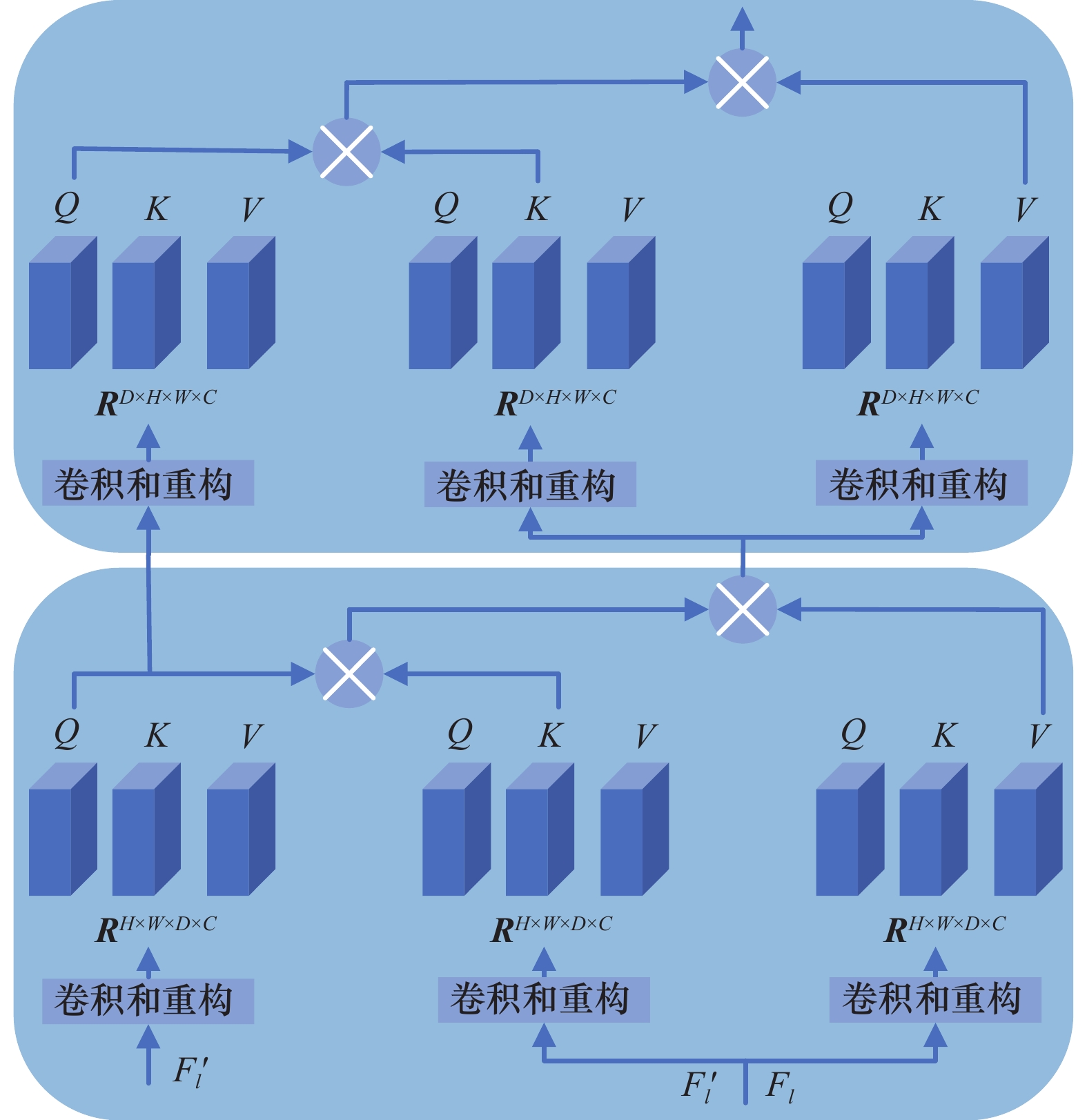
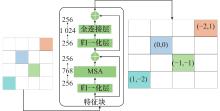
Fig.5
PE module"
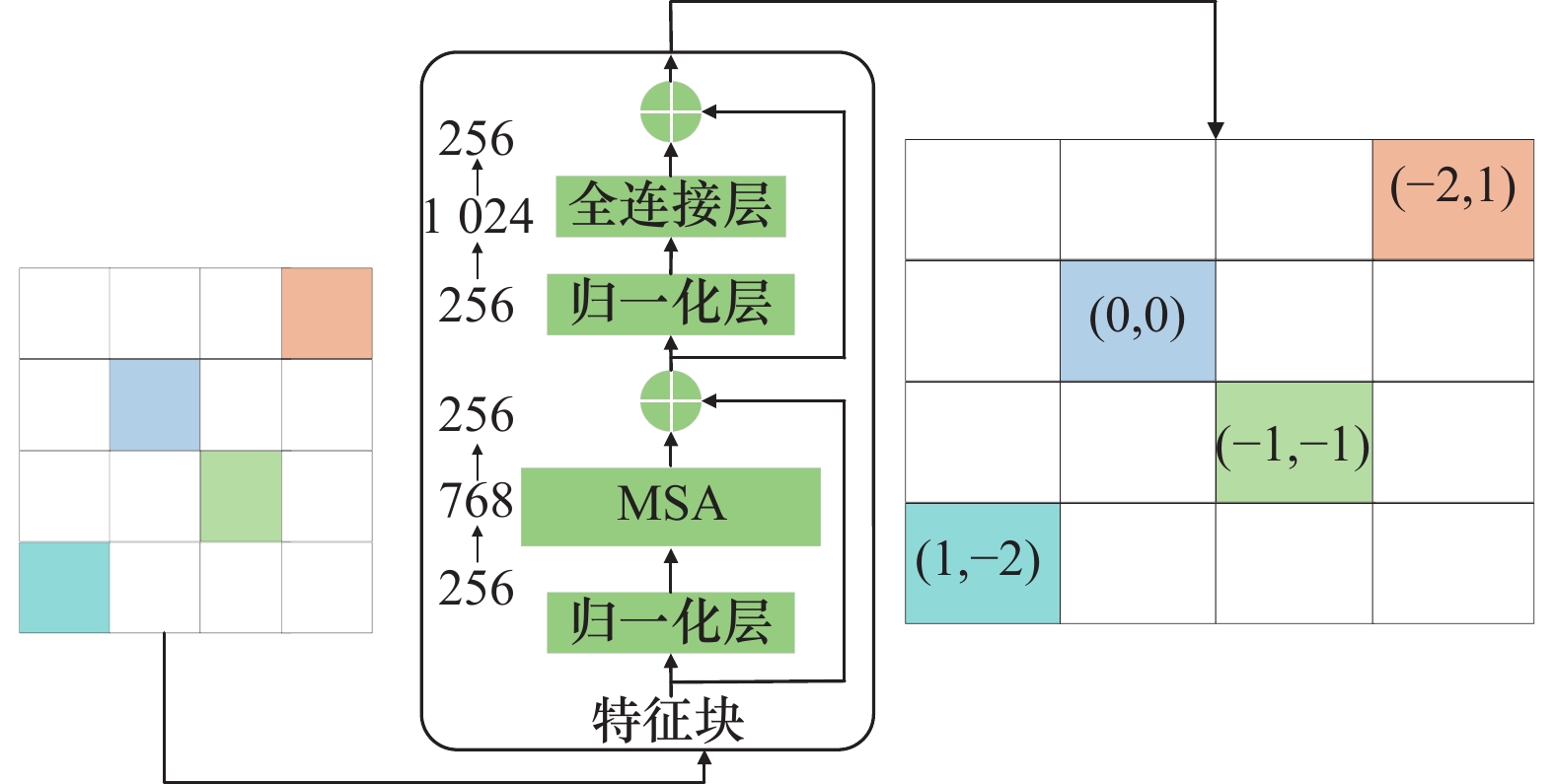
Table 1
Comparative experimental results of various algorithms on the KITTI dataset %"
| 方法 | 阶段 | 车mAP(IoU=0.7) | 行人mAP(IoU=0.5) | 骑行者mAP(IoU=0.5) | ||||||||
| 简单 | 中等 | 困难 | 简单 | 中等 | 困难 | 简单 | 中等 | 困难 | ||||
| MFANet[ | Ⅱ | 91.00 | 82.65 | 81.80 | 64.19 | 57.00 | 51.25 | 93.88 | 74.68 | 70.29 | ||
| SPNet-P[ | Ⅰ | 88.71 | 78.67 | 77.29 | 61.07 | 56.46 | 51.19 | 82.10 | 68.03 | 63.00 | ||
| Voxel-RCNN[ | Ⅱ | 92.38 | 85.29 | 82.86 | — | — | — | — | — | — | ||
| VoTr-SSD[ | Ⅰ | 87.86 | 78.27 | 76.93 | — | — | — | — | — | — | ||
| PointRCNN[ | Ⅰ | 89.43 | 80.50 | 78.15 | — | — | — | — | — | — | ||
| IA-SSD[ | Ⅰ | 89.05 | 79.59 | 77.84 | 60.62 | 54.74 | 50.39 | 84.07 | 68.11 | 65.14 | ||
| CAT-Det[ | Ⅰ | 90.12 | 81.46 | 79.15 | 61.57 | 58.82 | 53.11 | 85.92 | 71.03 | 66.33 | ||
| PFSC[ | Ⅰ | 92.06 | 84.68 | 82.61 | 63.34 | 57.86 | 53.32 | 92.04 | 74.68 | 69.92 | ||
| PV-RCNN[ | Ⅱ | 92.22 | 84.66 | 82.55 | 65.37 | 59.34 | 55.31 | 92.08 | 72.43 | 67.79 | ||
| M3DETR[ | Ⅱ | 89.28 | 84.16 | 79.05 | — | — | — | — | — | — | ||
| PV-RCNN++[ | Ⅱ | 91.06 | 84.07 | 81.64 | 64.50 | 58.48 | 52.60 | 92.61 | 72.71 | 68.04 | ||
| MFT-SSD[ | Ⅱ | 89.35 | 84.46 | 78.55 | — | — | — | — | — | — | ||
| LFED-RCNN | Ⅱ | 92.22 | 85.36 | 82.95 | 70.00 | 62.73 | 57.48 | 93.94 | 73.56 | 72.14 | ||
Table 2
Comparison with mainstream methods on the ONCE dataset %"
| 方法 | 车mAP(IoU=0.7) | 行人mAP(IoU=0.5) | 骑行者mAP(IoU=0.5) | |||||||||||
| 整体 | 0~30 m | 30~50 m | 50 m~∞ | 整体 | 0~30 m | 30~50 m | 50 m~∞ | 整体 | 0~30 m | 30~50 m | 50 m~∞ | |||
| PointRCNN[ | 52.09 | 74.75 | 40.89 | 16.81 | 4.28 | 6.17 | 2.40 | 0.91 | 29.84 | 46.03 | 20.94 | 5.46 | ||
| PointPillars[ | 68.57 | 80.86 | 62.07 | 47.04 | 17.63 | 19.74 | 15.15 | 10.23 | 46.81 | 58.33 | 40.32 | 25.86 | ||
| PV-RCNN[ | 77.77 | 89.39 | 72.55 | 58.64 | 23.50 | 25.61 | 22.84 | 17.27 | 59.37 | 71.66 | 52.58 | 36.17 | ||
| SECOND[ | 71.19 | 84.04 | 63.02 | 47.25 | 26.44 | 29.33 | 24.05 | 18.05 | 58.04 | 69.96 | 52.43 | 34.61 | ||
| CenterPoints[ | 66.79 | 80.10 | 59.55 | 43.39 | 49.90 | 56.24 | 42.61 | 26.27 | 63.45 | 74.28 | 57.94 | 41.48 | ||
| PointPainting[ | 66.17 | 80.31 | 59.80 | 42.26 | 44.84 | 52.63 | 36.63 | 22.47 | 62.34 | 73.55 | 57.20 | 40.39 | ||
| LFED-RCNN | 80.23 | 90.00 | 76.53 | 62.58 | 33.49 | 37.82 | 31.20 | 21.43 | 63.58 | 74.74 | 58.91 | 41.70 | ||
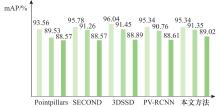
Fig.6
Comparison of detection performance from BEV perspective"
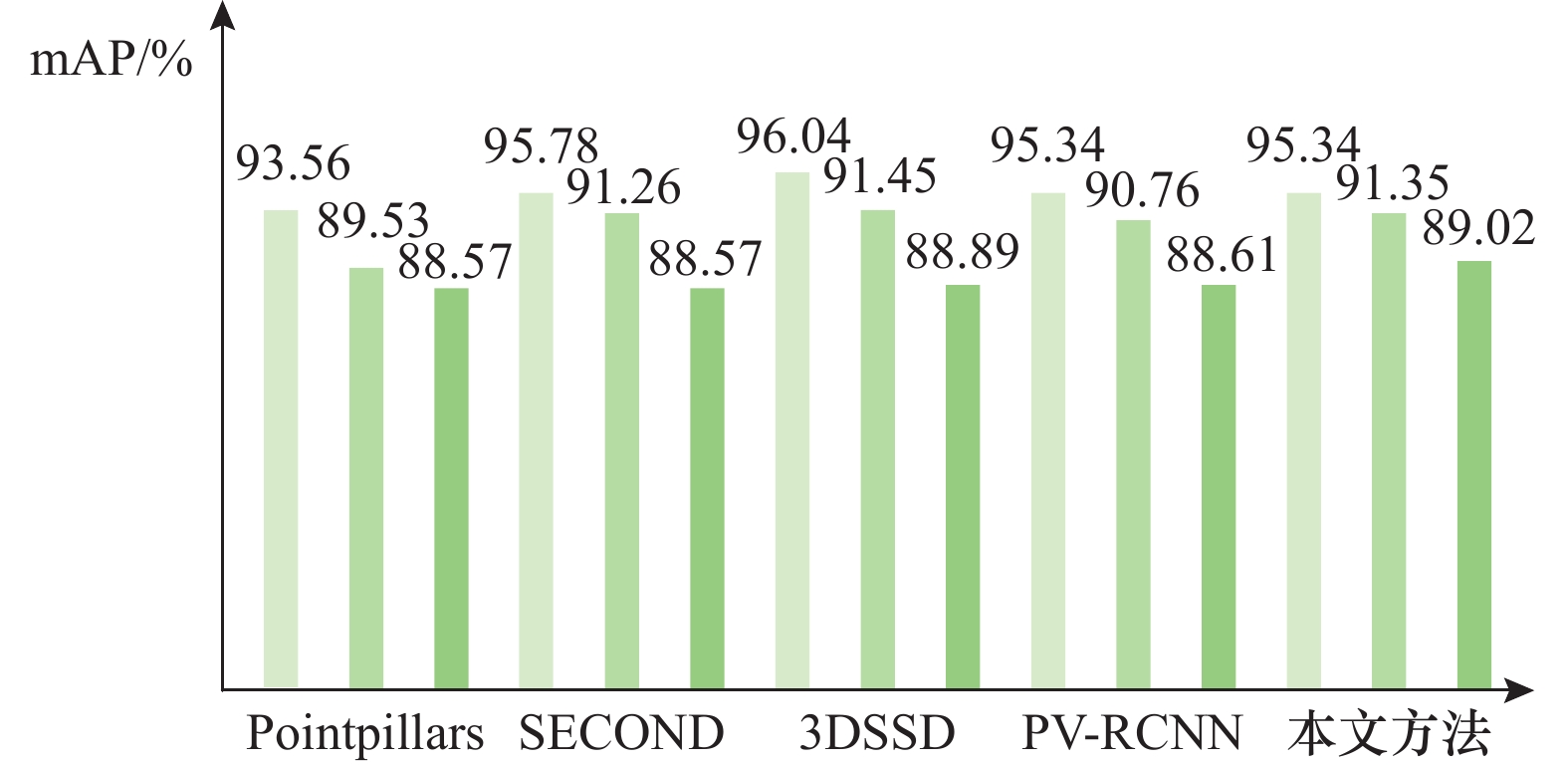
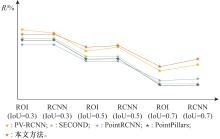
Fig.7
Comparison of R with different conditions"
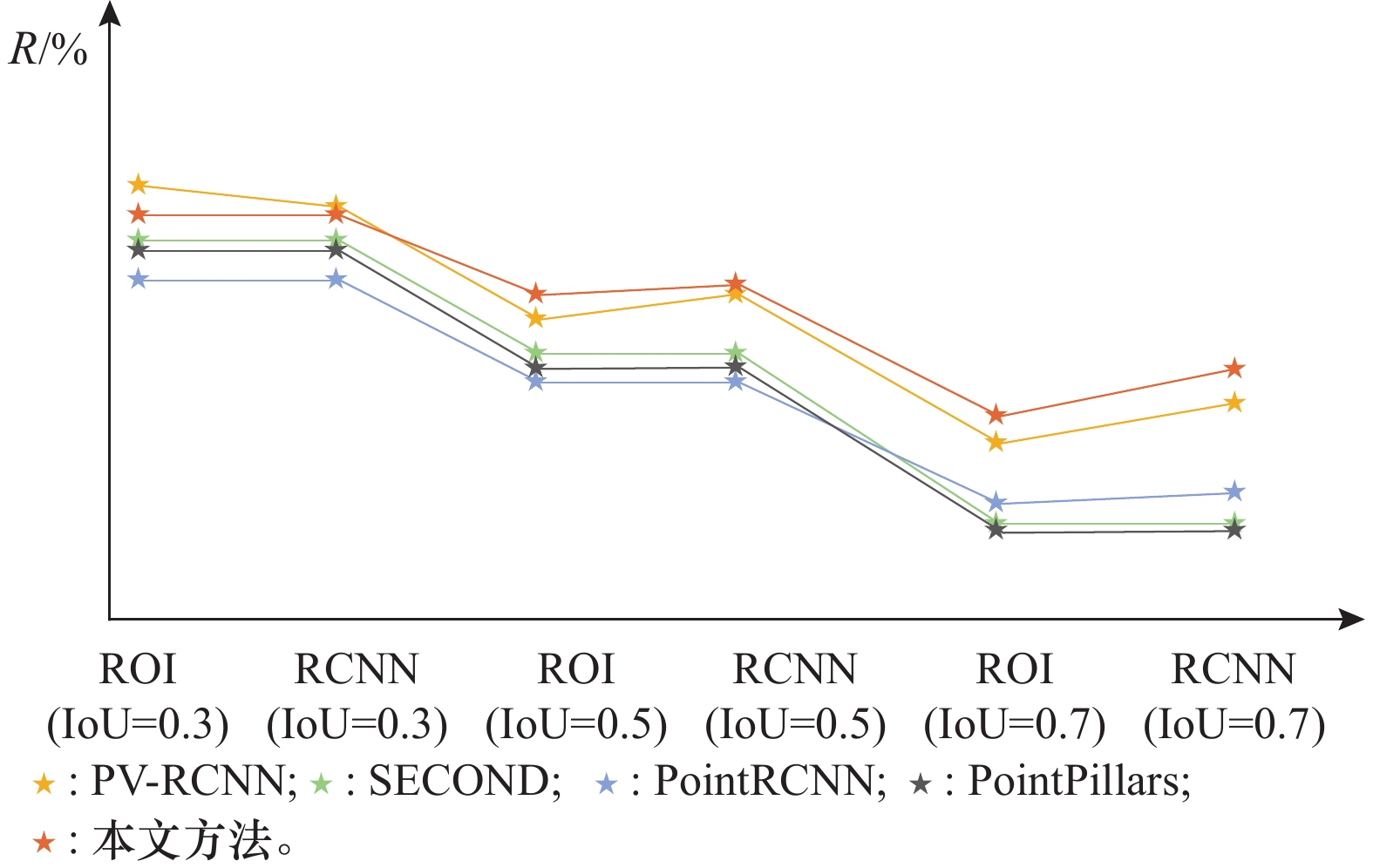
Table 3
Comparison of different algorithms computation and inference latency ms"
| 方法 | PointRCNN[ | PointPillars[ | SECOND[ | PV-RCNN[ | Voxel-RCNN[ | LFED-RCNN |
| 时间 | 92.7 | 57.4 | 224.1 | 353.9 | 245.8 | 391.9 |
Table 4
Impact of downsampling layers on performance in KITTI dataset"
| 下采样层 | 下采样倍数 | mAP/% | 车mAP (IoU=0.7)/% | 行人mAP (IoU=0.5)/% | 骑行者mAP (IoU=0.5)/% |
| D4 | {1,2,4,8} | 72.14 | 84.66 | 59.34 | 72.43 |
| D5 | {1,2,4,8,16} | 72.35 | 84.71 | 59.66 | 72.68 |
| D6 | {1,2,4,8,16,32} | 72.44 | 84.87 | 59.86 | 72.61 |
Table 5
Ablation experiment on KITTI dataset %"
| 下采样网络 | LEDNet | PE模块 | 车mAP(IoU=0.7) | 行人mAP(IoU=0.5) | 骑行者mAP(IoU=0.5) |
| × | × | × | 84.66 | 59.34 | 72.43 |
| √ | × | × | 84.87 | 59.86 | 72.61 |
| √ | × | √ | 84.92 | 61.03 | 72.69 |
| √ | √ | × | 85.10 | 62.12 | 72.81 |
| √ | √ | √ | 85.36 | 62.73 | 73.56 |

Fig.8
Visualized results"

| 1 | ZHOU Y S, HE Y, ZHU H Z, et al. Monocular 3D object detection: an extrinsic parameter free approach[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021: 7556−7566. |
| 2 | DUAN K W, BAI S, XIE L X, et al. Centernet: keypoint triplets for object detection[C]//Proc. of the IEEE/CVF International Conference on Computer Vision, 2019: 6569−6578. |
| 3 | LIAN Q, LI P L, CHEN X Z. MonoJSG: joint semantic and geometric cost volume for monocular 3D object detection[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022: 1070−1079. |
| 4 | SHI S S, WANG X G, LI H S. PointRCNN: 3D object proposal generation and detection from point cloud[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 770−779. |
| 5 | LANG A H, VORA S, CAESAR H, et al. Pointpillars: fast encoders for object detection from point clouds[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 12697−12705. |
| 6 | SHI S S, GUO C Y, JIANG L, et al. PV-RCNN: point-voxel feature set abstraction for 3D object detection[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 10529−10538. |
| 7 | QI C R, SU H, MO K C, et al. PointNet: deep learning on point sets for 3D classification and segmentation[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 652−660. |
| 8 | NABATI R, QI H R. Centerfusion: center-based radar and camera fusion for 3D object detection[C]//Proc. of the IEEE/CVF Winter Conference on Application of Computer Vision, 2021: 1527−1536. |
| 9 | LI Y W, YU A W, MENG T J, et al. Deepfusion: lidar-camera deep fusion for multi-modal 3D object detection[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022: 17182−17191. |
| 10 | BAI X Y, HU Z Y, ZHU X G, et al. Transfusion: robust lidar-camera fusion for 3D object detection with transformers[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022: 1090−1099. |
| 11 | ZHANG Y F, HU Q Y, XU G Q, et al. Not all points are equal: learning highly efficient point-based detectors for 3D lidar point clouds[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022: 18953−18962. |
| 12 | SU Z, LIANG X H, YANG S, et al. PFSC: pyramid R-CNN for point-voxels with focal sparse convolutional networks for 3D object detection[C]//Proc. of the 2024 IEEE International Conference on Mechatronics and Automation, 2024: 1843−1848. |
| 13 | ZHANG Y A, CHEN J X, HUANG D. Cat-det: contrastively augmented transformer for multi-modal 3D object detection[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022: 908−917. |
| 14 |
李娇娇, 孙红岩, 董雨, 等. 基于深度学习的3维点云处理综述[J]. 计算机研究与发展, 2022, 59 (5): 1160- 1179.
doi: 10.7544/issn1000-1239.20210131 |
|
LI J J, SUN H Y, DONG Y, et al. Review of 3D point cloud processing based on deep learning[J]. Journal of Computer Research and Development, 2022, 59 (5): 1160- 1179.
doi: 10.7544/issn1000-1239.20210131 |
|
| 15 | SHI Y S, ZHANG X K, DENG Y L, et al. Multilevel feature aggregation network with efficient voxel-to-keypoint encoding for 3D object detection on point clouds[C]//Proc. of the Chinese Control Conference, 2024: 7866−7872. |
| 16 | HU Y H, DING Z Z, GE R Z, et al. AFDetV2: rethinking the necessity of the second stage for object detection from point clouds[C] //Proc. of the AAAI Conference on Artificial Intelligence, 2022, 36(1): 969−979. |
| 17 | JU B, ZOU Z K, YE X Q, et al. Paint and distill: boosting 3D object detection with semantic passing network[C]//Proc. of the 30th ACM International Conference on Multimedia, 2022: 5639−5648. |
| 18 | WU H, WEN C L, LI W, et al. Transformation-equivariant 3D object detection for autonomous driving[C]//Proc. of the AAAI Conference on Artificial Intelligence, 2023, 37(3): 2795−2802. |
| 19 | CHEN X S, SHI S S, ZHU B J, et al. MPPNet: multi-frame feature intertwining with proxy points for 3D temporal object detection[C] //Proc. of the European Conference on Computer Vision, 2022: 680−697. |
| 20 |
YAN Y, MAO Y X, LI B. Second: sparsely embedded convolutional detection[J]. Sensors, 2018, 18 (10): 3337.
doi: 10.3390/s18103337 |
| 21 | 陆军, 李杨, 鲁林超. 远距离和遮挡下三维目标检测算法研究[J]. 智能系统学报, 2024, 19 (2): 259- 266. |
| LU J, LI Y, LU L C. Research on 3D target detection algorithm under long distance and occlusion[J]. CAAI Transactions on Intelligent Systems, 2024, 19 (2): 259- 266. | |
| 22 | DENG J J, SHI S S, LI P W, et al. Voxel R-CNN: towards high performance voxel-based 3D object detection[C]//Proc. of the AAAI Conference on Artificial Intelligence, 2021, 35(2): 1201−1209. |
| 23 | YIN T W, ZHOU X Y, KRAHENBUHL P. Center-based 3D object detection and tracking[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021: 11784−11793. |
| 24 | SONG Z Y, ZHANG G X, XIE J, et al. Voxelnextfusion: a simple, unified and effective voxel fusion framework for multi-modal 3D object detection[C]//Proc. of the IEEE/CVF International Conference on Computer Vision, 2023, 2181−2191. |
| 25 | ZHENG W, TANG W L, CHEN S J, et al. CIA-SSD: confident IoU-aware single-stage object detector from point cloud[C]//Proc. of the AAAI Conference on Artificial Intelligence, 2021, 35(4): 3555−3562. |
| 26 | LI Y J, YANG S, ZHENG Y C, et al. Improved point-voxel region convolutional neural network: 3D object detectors for autonomous driving[J]. IEEE Trans. on Intelligent Transportation Systems, 2021, 23 (7): 9311- 9317. |
| 27 | 李宇轩, 陈壹华, 温兴, 等. 改进Point-Voxel特征提取的3D小目标检测[J]. 微电子学与计算机, 2023, 40 (2): 50- 58. |
| LI Y X, CHEN Y H, WEN X, et al. 3D small target detection using improved Point-Voxel feature extraction[J]. Microelectronics and Computers, 2023, 40 (2): 50- 58. | |
| 28 | SHI S S, WANG Z, SHI J P, et al. From points to parts: 3D object detection from point cloud with part-aware and part aggregation network[J]. IEEE Trans. on Pattern Analysis and Machine Intelligence, 2020, 43 (8): 2647- 2664. |
| 29 | GUAN T R, WANG J, LAN S Y, et al. M3DETR: multi-representation, multi-scale, mutual-relation 3D object detection with transformers[C]//Proc. of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2022: 772−782. |
| 30 | XIE S Y, KONG L D, ZHANG W W, et al. RoboBEV: towards robust bird’s eye view perception under corruptions[EB/OL]. [2024− 05−10]. https://arxiv.org/abs/2304.06719. |
| 31 | DONG Y P, KANG C X, ZHANG J L, et al. Benchmarking robustness of 3D object detection to common corruptions[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023: 1022−1032. |
| 32 | MAO J G, XUE Y J, NIU M Z, et al. Voxel transformer for 3D object detection[C]//Proc. of the IEEE/CVF International Conference on Computer Vision, 2021: 3164−3173. |
| 33 | SUN P, TAN M X, WANG W Y, et al. Swformer: sparse window transformer for 3D object detection in point clouds[C]//Proc. of the European Conference on Computer Vision, 2022: 426−442. |
| 34 | FENG X Y, DU H M, FAN H H, et al. Seformer: structure embedding transformer for 3D object detection[C]//Proc. of the AAAI Conference on Artificial Intelligence, 2023, 37(1): 632−640. |
| 35 | WANG H Y, SHI C, SHI S S, et al. DSVT: dynamic sparse voxel transformer with rotated sets[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023: 13520−13529. |
| 36 | FAN L, PANG Z Q, ZHANG T Y, et al. Embracing single stride 3D object detector with sparse transformer[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022: 8458−8468. |
| 37 | 宋存利, 柴伟琴, 张雪松. 基于改进YOLO v5算法的道路小目标检测[J]. 系统工程与电子技术, 2024, 46 (10): 3271- 3278. |
| SONG C L, CHAI W Q, ZHANG X S. Road small target detection based on improved YOLOv5 algorithm[J]. Systems Engineering and Electronics, 2024, 46 (10): 3271- 3278. | |
| 38 | 陈晓萱, 徐书文, 胡绍海, 等. 基于卷积与自注意力的红外与可见光图像融合[J]. 系统工程与电子技术, 2024, 46 (8): 2641- 2649. |
| CHEN X X, XU S W, HU S H, et al. Infrared and visible image fusion based on convolution and self-attention[J]. Systems Engineering and Electronics, 2024, 46 (8): 2641- 2649. | |
| 39 | OUYANG D L, HE S, ZHANG G Z, et al. Efficient multi-scale attention module with cross-spatial learning[C]//Proc. of the IEEE International Conference on Acoustics, 2023. |
| 40 | LI X, HU X L, YANG J. Spatial group-wise enhance: improving semantic feature learning in convolutional networks[EB/OL]. [2024−05−10]. https://arxiv.org/abs/1905.09646. |
| 41 | HU J, SHEN L, SUN G. Squeeze-and- excitation networks[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2018: 7132−7141. |
| 42 | 邵凯, 王明政, 王光宇. 基于Transformer的多尺度遥感语义分割网络[J]. 智能系统学报, 2024, 19 (2): 920- 929. |
| SHAO K, WANG M Z, WANG G Y. Transformer-based multiscale remote sensing semantic segmentation network[J]. CAAI Transactions on Intelligent Systems, 2024, 19 (2): 920- 929. | |
| 43 | 梁燕, 易春霞, 王光宇, 等. 基于多尺度语义编解码网络的遥感图像语义分割[J]. 电子学报, 2023, 51 (11): 3199- 3214. |
| LIANG Y, YI C X, WANG G Y, et al. Semantic segmentation of remote sensing images based on multi-scale semantic encoding and decoding network[J]. Acta Electronica Sinica, 2023, 51 (11): 3199- 3214. | |
| 44 |
梁燕, 易春霞, 王光宇. 基于编解码网络UNet3+的遥感影像建筑变化检测[J]. 计算机学报, 2023, 46 (8): 1720- 1733.
doi: 10.11897/SP.J.1016.2023.01720 |
|
LIANG Y, YI C X, WANG G Y. Building change detection in remote sensing images based on encoding and decoding network UNet3+[J]. Journal of Computer Science, 2023, 46 (8): 1720- 1733.
doi: 10.11897/SP.J.1016.2023.01720 |
|
| 45 |
SHI S S, JIANG L, DENG J J, et al. PV-RCNN++: point-voxel feature set abstraction with local vector representation for 3D object detection[J]. International Journal of Computer Vision, 2023, 131 (2): 531- 551.
doi: 10.1007/s11263-022-01710-9 |
| 46 |
TONG G F, LI Z, PENG H, et al. Multi-source features fusion single stage 3D object detection with transformer[J]. IEEE Robotics and Automation Letters, 2023, 8 (4): 2062- 2069.
doi: 10.1109/LRA.2023.3244124 |
| 47 | YIN T W, ZHOU X Y, PHILIPP K. Center-based 3D object detection and tracking[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021: 11779−11788. |
| 48 | VORA S, LANG A H, HELOU B, et al. PointPainting: sequential fusion for 3D object detection[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 4603−4611. |
| [1] | Xiaoyang HE, Xiaolong CHEN, Xiaolin DU, Ningyuan SU, Wang YUAN, Jian GUAN. Classification of maritime micromotion target based on transfer learning in CBAM-Swin-Transformer [J]. Systems Engineering and Electronics, 2025, 47(4): 1155-1167. |
| [2] | Xiarun SHEN, Ruonan LI, Haotian ZHANG. Server KPI anomaly detection based on CVAE-LSTM [J]. Systems Engineering and Electronics, 2025, 47(3): 1019-1027. |
| [3] | Xiaoxuan CHEN, Shuwen XU, Shaohai HU, Xiaole MA. Infrared and visible light image fusion based on convolution and self attention [J]. Systems Engineering and Electronics, 2024, 46(8): 2641-2649. |
| [4] | Caiyun WANG, Huiwen ZHANG, Jianing WANG, Yida WU, Yun CHANG. Ballistic midcourse target RCS recognition based on DTCWT-VAE [J]. Systems Engineering and Electronics, 2024, 46(7): 2269-2275. |
| [5] | Lisha XUE, Ruixing GE, Yuxuan ZHU, Yanfei BAO. Generation and efficiency analysis of communication jamming signal based on SABEGAN [J]. Systems Engineering and Electronics, 2024, 46(6): 2155-2163. |
| [6] | Pengfei YANG, Ling HE, Qian WANG, Ruidi WANG, Mingzhi ZHANG. Interference identification based on mixed signal multidomain feature and Transformer framework [J]. Systems Engineering and Electronics, 2024, 46(6): 2138-2145. |
| [7] | Lan MA, Shijun MENG, Zhijun WU. Intention mining for civil aviation radiotelephony communication based on BERT and generative adversarial [J]. Systems Engineering and Electronics, 2024, 46(2): 740-750. |
| [8] | Jiarong PING, Sai LI, Yunhang LIN. Modulation recognition of unmanned aerial vehicle swarm MIMO signals under Alpha stable distribution noise and multipath interference [J]. Systems Engineering and Electronics, 2024, 46(11): 3920-3929. |
| [9] | Zichang LIU, Yongsheng BAI, Siyu LI, Xisheng JIA. Diesel engine fault diagnosis method based on wavelet time-frequency diagram and Swin Transformer [J]. Systems Engineering and Electronics, 2023, 45(9): 2986-2998. |
| [10] | Jianli DING, Qiqi ZHANG, Jing WANG, Weigang HUO. ADS-B anomaly detection method based on Transformer-VAE [J]. Systems Engineering and Electronics, 2023, 45(11): 3680-3689. |
| [11] | Ruping ZHAI, Shuheng ZHANG, Jiarong PING. Waveform recognition of unmanned aerial vehicle swarm communication in complex multipath environment [J]. Systems Engineering and Electronics, 2023, 45(10): 3312-3320. |
| [12] | Yukun CHEN, Hui YU, Ningyun LU. Fault diagnosis of radar T/R module based on semi-supervised deep learning [J]. Systems Engineering and Electronics, 2023, 45(10): 3329-3337. |
| [13] | Haigang SUI, Jiajie LI, Guohua GOU. Online fast localization method of UAVs based on heterologous image matching [J]. Systems Engineering and Electronics, 2023, 45(10): 3008-3015. |
| [14] | Kun QIAN, Chenxuan LI, Meishan CHEN, Jiwei GUO, Lei PAN. Ship target instance segmentation algorithm based on improved Swin Transformer [J]. Systems Engineering and Electronics, 2023, 45(10): 3049-3057. |
| [15] | Pengyu CAO, Chengzhi YANG, Limeng SHI, Hongchao WU. LPI radar signal enhancement based on DAE-GAN network [J]. Systems Engineering and Electronics, 2021, 43(9): 2493-2500. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||