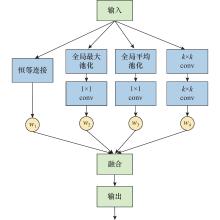
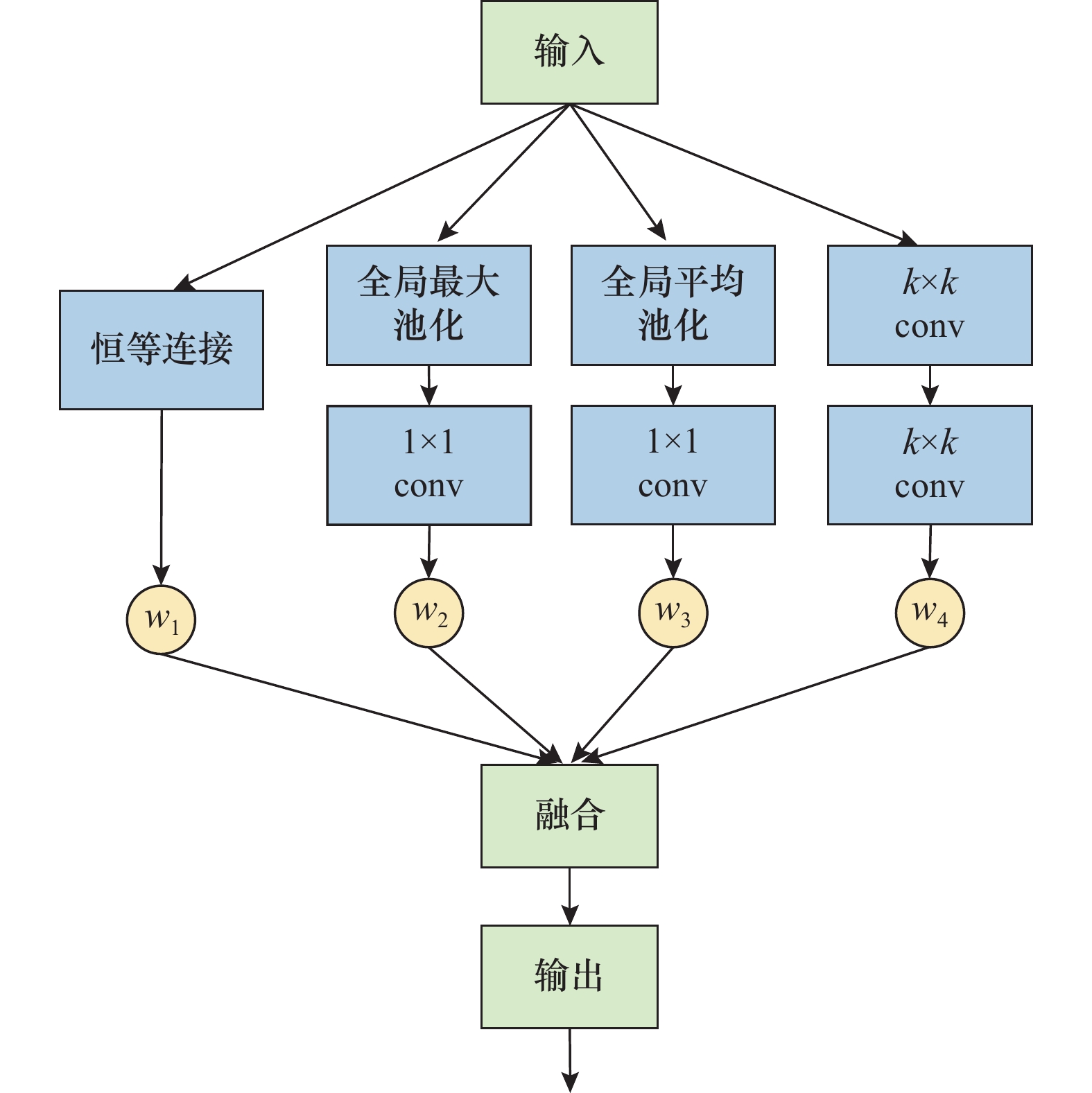
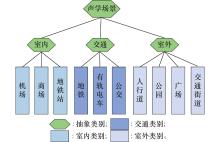
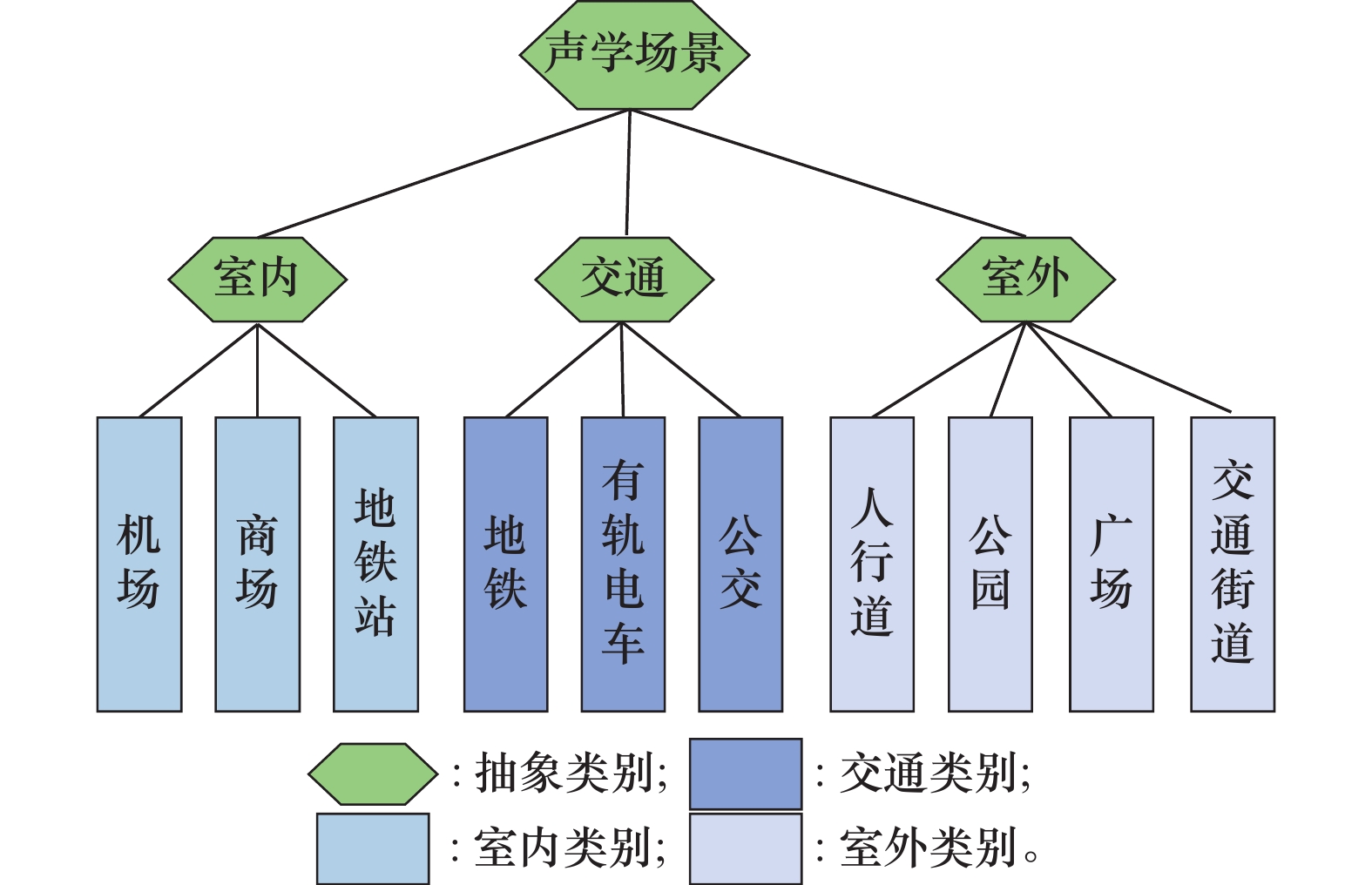
| 1 |
JIANG G, MA Z C, MAO Q R, et al. Multi-level distance embedding learning for robust acoustic scene classification with unseen devices[J]. Pattern Analysis and Applications, 2023, 26 (3): 1089- 1099.
doi: 10.1007/s10044-023-01172-w
|
| 2 |
DING B Y, ZHANG T, WANG C, et al. Acoustic scene classification: a comprehensive survey[J]. Expert Systems with Applications, 2024, 238, 121902.
doi: 10.1016/j.eswa.2023.121902
|
| 3 |
JATI A, NADARAJAN A, PERI R, et al. Temporal dynamics of workplace acoustic scenes: egocentric analysis and prediction[J]. IEEE/ACM Trans. on Audio, Speech, and Language Processing, 2021, 29, 756- 769.
doi: 10.1109/TASLP.2021.3050265
|
| 4 |
刘立芳, 杨海霞, 齐小刚. 基于线性判别分析的时频域特征提取算法[J]. 系统工程与电子技术, 2019, 41 (10): 2184- 2190.
doi: 10.3969/j.issn.1001-506X.2019.10.05
|
|
LIU L F, YANG H X, QI X G. Time-frequency domain feature extraction algorithm based on linear discriminant analysis[J]. Systems Engineering and Electronics, 2019, 41 (10): 2184- 2190.
doi: 10.3969/j.issn.1001-506X.2019.10.05
|
| 5 |
SZEGEDY C, LIU W, JIA Y Q, et al. Going deeper with convolutions[C]// Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2015.
|
| 6 |
LUO W J, LI Y J, URTASUN R, et al. Understanding the effective receptive field in deep convolutional neural networks[J]. Advances in neural information processing systems, 2016, 29, 4905–4913.
|
| 7 |
KOUTINI K, EGHBAL-ZADEH H, DORFER M, et al. The receptive field as a regularizer in deep convolutional neural networks for acoustic scene classification[C]//Proc. of the 27th European Signal Processing Conference, 2019.
|
| 8 |
SZEGEDY C, VANHOUCKE V, IOFFE S, et al. Rethinking the inception architecture for computer vision[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2016: 2818−2826.
|
| 9 |
XIAN Y, SUN Y, WANG W W, et al. A multi-scale feature recalibration network for end-to-end single channel speech enhancement[J]. IEEE Journal of Selected Topics in Signal Processing, 2020, 15 (1): 143- 155.
|
| 10 |
SHIM H J, JUNG J W, KIM J H, et al. Attentive max feature map and joint training for acoustic scene classification[C]//Proc. of the IEEE International Conference on Acoustics, Speech and Signal Processing, 2022: 1036−1040.
|
| 11 |
DONG X Y, YAN Y, TAN M K, et al. Late fusion via subspace search with consistency preservation[J]. IEEE Trans. on Image Processing, 2018, 28 (1): 518- 528.
|
| 12 |
PASEDDULA C, GANGASHETTY S V. Late fusion framework for acoustic scene classification using LPCC, SCMC, and log-Mel band energies with deep neural networks[J]. Applied Acoustics, 2021, 172, 107568.
doi: 10.1016/j.apacoust.2020.107568
|
| 13 |
SUH S, PARK S, JEONG Y, et al. Designing acoustic scene classification models with CNN variants[R]. Tokyo: Detection and Classification of Acoustic Scenes and Events Challenge, 2020.
|
| 14 |
HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2016: 770−778.
|
| 15 |
DING B Y, ZHANG T, LIU G J, et al. Late fusion for acoustic scene classification using swarm intelligence[J]. Applied Acoustics, 2022, 192, 108698.
doi: 10.1016/j.apacoust.2022.108698
|
| 16 |
ALAMIR M A. A novel acoustic scene classification model using the late fusion of convolutional neural networks and different ensemble classifiers[J]. Applied Acoustics, 2021, 175, 107829.
doi: 10.1016/j.apacoust.2020.107829
|
| 17 |
CHEN C, LI B. A transform module to enhance lightweight attention by expanding receptive field[J]. Expert Systems with Applications, 2024, 248 (8): 123359.
doi: 10.1016/j.eswa.2024.123359
|
| 18 |
MOROCUTTI T, SCHMID F, KOUTINI K, et al. Device-robust acoustic scene classification via impulse response augmentation[C]//Proc. of the 31st European Signal Processing Conference, 2023: 176−180.
|
| 19 |
HU H, YANG C H H, XIA X, et al. A two-stage approach to device-robust acoustic scene classification[C]//Proc. of the IEEE International Conference on Acoustics, Speech and Signal Processing, 2021: 845−849.
|
| 20 |
CAI Y Q, LIN M Y, ZHU C Y, et al. DCASE2023 task1 submission: device simulation and time-frequency separable convolution for acoustic scene classification[R]. Tampere: Detection and Classification of Acoustic Scenes and Events Challenge, 2023.
|
| 21 |
PHAYE S S R, BENETOS E, WANG Y. Subspectralnet–using sub-spectrogram based convolutional neural networks for acoustic scene classification[C]//Proc. of the IEEE International Conference on Acoustics, Speech and Signal Processing, 2019: 825−829.
|
| 22 |
费鸿博, 吴伟官, 李平, 等. 基于梅尔频谱分离和LSCNet的声学场景分类方法[J]. 哈尔滨工业大学学报, 2022, 54 (5): 124- 130.
doi: 10.11918/202104081
|
|
FEI H B, WU W G, LI P, et al. Acoustic scene classification method based on Mel-spectrogram separation and LSCNet[J]. Journal of Harbin Institute of Technology, 2022, 54 (5): 124- 130.
doi: 10.11918/202104081
|
| 23 |
ZHANG B X, WANG Z R, LING Y G, et al. ShuffleTrans: patch-wise weight shuffle for transparent object segmentation[J]. Neural Networks, 2023, 167, 199- 212.
doi: 10.1016/j.neunet.2023.08.011
|
| 24 |
SCHMID F, MASOUDIAN S, KOUTINI K, et al. CPJKU submission to DCASE22: distilling knowledge for low complexity convolutional neural networks from a patchout audio transformer[R]. Nancy: Detection and Classification of Acoustic Scenes and Events Challenge, 2022.
|
| 25 |
LOSHCHILOV I, HUTTER F. Decoupled weight decay regularization[C]//Proc. of the International Conference on Learning Representations, 2017.
|
| 26 |
SHAO Y F, MA X X, MA Y, et al. Deep semantic learning for acoustic scene classification[J]. EURASIP Journal on Audio, Speech, and Music Processing, 2024, 2024, 1.
doi: 10.1186/s13636-023-00323-5
|
| 27 |
ZHANG H, CISSE M, DAUPHIN Y N, et al. Mixup: beyond empirical risk minimization[EB/OL].[2024-07-16]. https://arxiv.org/abs/1710.09412.
|
| 28 |
KIM B G, YANG S H, KIM J H, et al. Domain generalization with relaxed instance frequency-wise normalization for multi-device acoustic scene classification[EB/OL].[2024-07-16]. https://arxiv.org/abs/2206.12513.
|
| 29 |
HEITTOLA T, MESAROS A, VIRTANEN T. Acoustic scene classification in DCASE 2020 challenge: generalization across devices and low complexity solutions[EB/OL].[2024-07-16] https://arxiv.org/abs/2005.14623.
|
| 30 |
PHAM L, NGO D, SALOVIC D, et al. Lightweight deep neural networks for acoustic scene classification and an effective visualization for presenting sound scene contexts[J]. Applied Acoustics, 2023, 211, 109489.
doi: 10.1016/j.apacoust.2023.109489
|

 ), 何德华1, 宁方立2
), 何德华1, 宁方立2