
系统工程与电子技术 ›› 2025, Vol. 47 ›› Issue (3): 827-841.doi: 10.12305/j.issn.1001-506X.2025.03.15
• 系统工程 • 上一篇
唐开强, 傅汇乔, 刘佳生, 邓归洲, 陈春林
收稿日期:2024-03-07
出版日期:2025-03-28
发布日期:2025-04-18
通讯作者:
陈春林
作者简介:唐开强 (1992—), 男, 助理研究员, 博士, 主要研究方向为组合优化、深度强化学习、智能无人系统基金资助:Kaiqiang TANG, Huiqiao FU, Jiasheng LIU, Guizhou DENG, Chunlin CHEN
Received:2024-03-07
Online:2025-03-28
Published:2025-04-18
Contact:
Chunlin CHEN
摘要:
针对带容量约束的车辆路径问题(capacitated vehicle routing problem, CVRP), 提出一种利用层次结构对容量约束进行解耦的方法, 将复杂的CVRP拆分为约束规划和路径规划, 并分别进行深度强化学习(deep reinforcement learning, DRL)优化求解。首先, 上层基于注意力模型和采样机制对配送任务进行分配, 规划出满足容量约束的子回路集。其次, 下层采用预训练的无约束的注意力机制模型, 对子回路集进行路径规划。最后, 通过Reinforce算法反馈训练和迭代优化上层的网络参数。实验结果表明, 该方法对不同规模的CVRP和异构CVRP任务具有泛化性, 性能优于最先进的DRL方法; 并且与其他启发式方法相比, 在批量运算任务中, 求解速度提升10倍以上, 且保持具有竞争力的解。
中图分类号:
唐开强, 傅汇乔, 刘佳生, 邓归洲, 陈春林. 基于深度强化学习的带约束车辆路径分层优化研究[J]. 系统工程与电子技术, 2025, 47(3): 827-841.
Kaiqiang TANG, Huiqiao FU, Jiasheng LIU, Guizhou DENG, Chunlin CHEN. Hierarchical optimization research of constrained vehicle routing based on deep reinforcement learning[J]. Systems Engineering and Electronics, 2025, 47(3): 827-841.

图1
HDRL的整体结构"

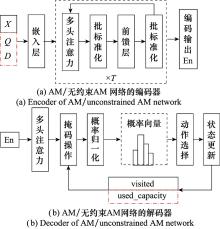
图2
基于AM的HDRL网络结构"
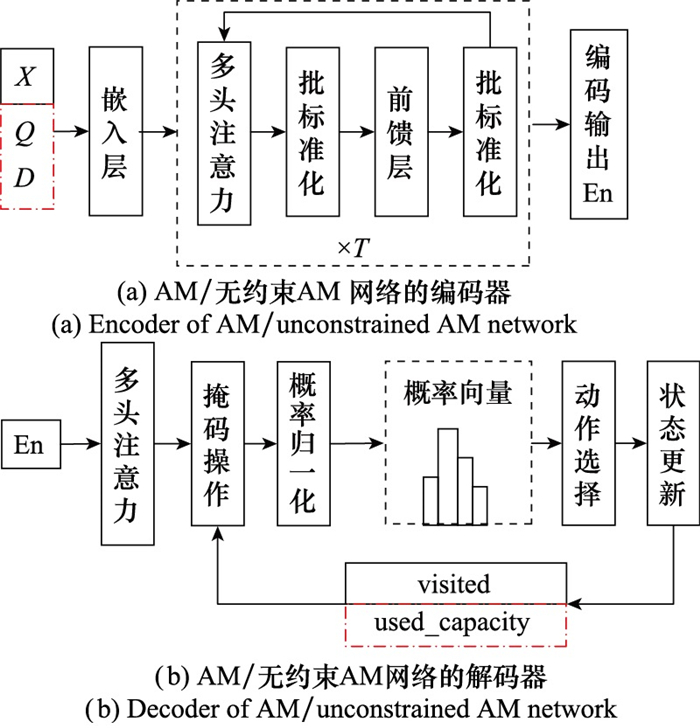
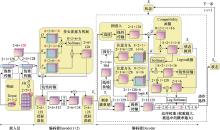
图3
AM网络结构实例分析"


图4
UAMSO前后路径图对比"


图5
UAMSO对子回路优化结果"


图6
子回路优化效果对比"

表1
4种算法的耗时对比"
| 算法 | 优化方式 | 规模 | ||
| 20 | 50 | 100 | ||
| AM | UAMSO | 5 | 8 | 15 |
| 2opt | 19 | 68 | 166 | |
| Swap | 12 | 68 | 170 | |
| Relocation | 19 | 72 | 236 | |
| MDAM | UAMSO | 18 | 29 | 43 |
| 2opt | 19 | 69 | 173 | |
| Swap | 17 | 74 | 175 | |
| Relocation | 20 | 74 | 237 | |

图7
20顾客点路径规划结果"


图8
50顾客点路径规划结果"


图9
100顾客点路径规划结果"

表2
HDRL与CVRP基线比较"
| 算法名称 | 参数 | CVRP20 | CVRP50 | CVRP100 | CVRP400 | |||||||||||
| Obj. | Gap/% | Time/s | Obj. | Gap/% | Time/s | Obj. | Gap/% | Time/s | Obj. | Gap/% | Time/s | |||||
| LKH | — | 6.14 | 0 | 280 | 10.40 | 0 | 1 887 | 15.71 | 0 | 4818 | 24.67 | 0 | 4.1 | |||
| OR-Tools | — | 6.26 | 1.95 | 1 018 | 11.05 | 6.25 | 1 094 | 17.08 | 8.72 | 1381 | 27.01 | 9.49 | 30.4 | |||
| HGPN | greedy | 7.7 | 25.41 | 1.2 | 14.65 | 40.87 | 2.9 | 23.51 | 49.65 | 6.7 | — | — | — | |||
| AM | greedy | 6.43 | 4.72 | 0.8 | 11.06 | 6.35 | 1.6 | 16.80 | 6.94 | 2.6 | 29.33 | 18.89 | 0.2 | |||
| POMO | greedy | 6.35 | 3.42 | 1 | 10.74 | 3.27 | 1 | 16.15 | 2.80 | 3 | — | — | — | |||
| MDAM | greedy | 6.24 | 1.62 | 2 | 10.71 | 2.98 | 15 | 16.52 | 5.16 | 26 | — | — | — | |||
| BS=30 | 6.16 | 0.03 | 33 | 10.56 | 1.54 | 92 | 16.15 | 2.80 | 407 | — | — | — | ||||
| DACT | T=1k | 6.18 | 0.06 | 93 | 10.88 | 4.62 | 255 | 16.62 | 5.79 | 1 061 | — | — | — | |||
| T=5K | 6.15 | 0.02 | 251 | 10.55 | 1.35 | 1 282 | 16.26 | 3.50 | 3 280 | — | — | — | ||||
| TAM-AM | — | — | — | — | — | — | — | 16.19 | 3.06 | 9 | 27.03 | 9.57 | 0.3 | |||
| HDRL (本文) | M=100 | 6.17 | 0.05 | 16 | 10.53 | 1.25 | 31 | 16.02 | 1.97 | 66 | 25.84 | 4.74 | 44 | |||
| M=300 | 6.15 | 0.02 | 29 | 10.49 | 0.87 | 71 | 15.96 | 1.59 | 143 | 25.06 | 1.58 | 168 | ||||
表3
HCVRP的各种基线比较"
| 算法名称 | V3-40 | V3-60 | V3-80 | V3-100 | V3-120 | ||||||||||||||
| Obj. | Gap/% | Time/s | Obj. | Gap/% | Time/s | Obj. | Gap/% | Time/s | Obj. | Gap/% | Time/s | Obj. | Gap/% | Time/s | |||||
| Exact-solver* | 55.43 | 0 | 71 | 78.47 | 0 | 214 | 102.42 | 0 | 793 | 124.61 | 0 | 2 512 | - | - | - | ||||
| SISR | 55.79 | 0.65 | (254) | 79.12 | 0.83 | (478) | 103.41 | 0.97 | (763) | 126.19 | 1.27 | (1 140) | 149.10 | 0 | (1 667) | ||||
| AM (sample12800) | 60.26 | 8.71 | 1.35 | 84.96 | 8.27 | 2.31 | 110.94 | 8.32 | 3.61 | 134.72 | 8.11 | 5.19 | 158.19 | 6.10 | 6.86 | ||||
| Li (sample12800) | 57.07 | 2.54 | 1.65 | 80.53 | 2.37 | 2.99 | 105.43 | 2.69 | 4.63 | 128.60 | 2.87 | 6.74 | 151.10 | 1.09 | 9.11 | ||||
| HDRL (sample12800) | 56.75 | 2.38 | 1.70 | 80.10 | 2.08 | 3.05 | 104.79 | 2.31 | 4.68 | 127.71 | 2.49 | 6.80 | 150.22 | 0.75 | 9.18 | ||||
| 1 |
DANTZIG G , FULKERSON R , JOHNSON S . Solution of a large-scale traveling-salesman problem[J]. Journal of the Operations Research Society of America, 1954, 2 (4): 393- 410.
doi: 10.1287/opre.2.4.393 |
| 2 | TOTH P , VIGO D . The vehicle routing problem[M]. Philadelphia: Society for Industrial and Applied Mathematics, 2002. |
| 3 | 李坚强, 蔡俊创, 孙涛, 等. 面向复杂物流配送场景的车辆路径规划多任务辅助进化算法[J]. 自动化学报, 2024, 50 (3): 544- 559. |
| LI J Q , CAI J C , SUN T , et al. Multitask-based assisted evolutionary algorithm for vehicle routing problems in complex logistics distribution scenarios[J]. Acta Automatica Sinica, 2024, 50 (3): 544- 559. | |
| 4 |
QIN G Y , TAO F M , LI L X . A vehicle routing optimization problem for cold chain logistics considering customer satisfaction and carbon emissions[J]. International Journal of Environmental Research and Public Health, 2019, 16 (4): 576.
doi: 10.3390/ijerph16040576 |
| 5 |
陈春良, 昝翔, 张仕新, 等. 基于改进MMAS的装备维修任务路径规划方法[J]. 系统工程与电子技术, 2017, 39 (12): 2716- 2720.
doi: 10.3969/j.issn.1001-506X.2017.12.13 |
|
CHEN C L , ZAN X , ZHANG S X , et al. Routing plan method for equipment maintenance task based on improved MMAS[J]. Systems Engineering and Electronics, 2017, 39 (12): 2716- 2720.
doi: 10.3969/j.issn.1001-506X.2017.12.13 |
|
| 6 |
LI B J , WU G H , HE Y M , et al. An overview and experimental study of learning-based optimization algorithms for the vehicle routing problem[J]. IEEE/CAA Journal of Automatica Sinica, 2022, 9 (7): 1115- 1138.
doi: 10.1109/JAS.2022.105677 |
| 7 |
KONSTANTAKOPOULOS G D , GAYIALIS S P , KECHAGIAS E P . Vehicle routing problem and related algorithms for logistics distribution: a literature review and classification[J]. Operational Research, 2022, 22 (3): 2033- 2062.
doi: 10.1007/s12351-020-00600-7 |
| 8 |
LIU T , LUO Z X , QIN H , et al. A branch-and-cut algorithm for the two-echelon capacitated vehicle routing problem with grouping constraints[J]. European Journal of Operational Research, 2018, 266 (2): 487- 497.
doi: 10.1016/j.ejor.2017.10.017 |
| 9 |
ZHANG Z , LUO Z X , QIN H , et al. Exact algorithms for the vehicle routing problem with time windows and combinatorial auction[J]. Transportation Science, 2019, 53 (2): 427- 441.
doi: 10.1287/trsc.2018.0835 |
| 10 |
MAHMOUDI M , ZHOU X S . Finding optimal solutions for vehicle routing problem with pickup and delivery services with time windows: a dynamic programming approach based on state-space-time network representations[J]. Transportation Research Part B: Methodological, 2016, 89, 19- 42.
doi: 10.1016/j.trb.2016.03.009 |
| 11 |
TAN S Y , YEH W C . The vehicle routing problem: State-of-the-art classification and review[J]. Applied Sciences, 2021, 11 (21): 10295.
doi: 10.3390/app112110295 |
| 12 |
LAPORTE G . The vehicle routing problem: an overview of exact and approximate algorithms[J]. European journal of operational research, 1992, 59 (3): 345- 358.
doi: 10.1016/0377-2217(92)90192-C |
| 13 |
KAYA E , GORKEMLI B , AKAY B , et al. A review on the studies employing artificial bee colony algorithm to solve combinatorial optimization problems[J]. Engineering Applications of Artificial Intelligence, 2022, 115, 105311.
doi: 10.1016/j.engappai.2022.105311 |
| 14 | ELSHAER R , AWAD H . A taxonomic review of metaheuristic algorithms for solving the vehicle routing problem and its variants[J]. Computers & Industrial Engineering, 2020, 140, 106242. |
| 15 |
吴冯国, 陶伟, 李辉, 等. 基于深度强化学习算法的无人机智能规避决策[J]. 系统工程与电子技术, 2023, 45 (6): 1702- 1711.
doi: 10.12305/j.issn.1001-506X.2023.06.14 |
|
WU F G , TAO W , LI H , et al. Intelligent avoidance decision making for unmanned aerial vehicles based on deep reinforcement learning algorithm[J]. Systems Engineering and Electronics, 2023, 45 (6): 1702- 1711.
doi: 10.12305/j.issn.1001-506X.2023.06.14 |
|
| 16 |
夏雨奇, 黄炎焱, 陈恰. 基于深度Q网络的无人车侦察路径规划[J]. 系统工程与电子技术, 2024, 46 (9): 3070- 3082.
doi: 10.12305/j.issn.1001-506X.2024.09.19 |
|
XIA Y Q , HUANG Y Y , CHEN Q . Path planning for unmanned vehicle reconnaissance mission based on deep Q-Network[J]. Systems Engineering and Electronics, 2024, 46 (9): 3070- 3082.
doi: 10.12305/j.issn.1001-506X.2024.09.19 |
|
| 17 | VINYALS O, FORTUNATO M, JAITLY N. Pointer networks[C]//Proc. of the 28th International Conference on Neural Information Processing Systems, 2015: 2692-2700. |
| 18 | BELLO I, PHAM H, LE Q V, et al. Neural combinatorial optimization with reinforcement learning[EB/OL]. [2024-02-07]. https://arxiv.org/abs/1611.09940. |
| 19 | GOLDEN B , ASSAD A , LEVY L , et al. The fleet size and mix vehicle routing problem[J]. Computers & Operations Research, 1984, 11 (1): 49- 66. |
| 20 | KOOL W, VAN H H, WELLING M. Attention, learn to solve routing problems[C]//Proc. of the 6th International Conference on Learning Representations, 2018. |
| 21 | KWON Y D, CHOO J, KIM B, et al. Pomo: policy optimization with multiple optima for reinforcement learning[C]//Proc. of the Advances in Neural Information Processing Systems, 2020. |
| 22 | MA Y N, LI J W, CAO Z G, et al. Learning to iteratively solve routing problems with dual-aspect collaborative transformer[C]//Proc. of the Advances in Neural Information Processing Systems, 2021. |
| 23 | XIN L, SONG W, CAO Z G, et al. Multi-decoder attention model with embedding glimpse for solving vehicle routing problems[C]//Proc. of the 35th AAAI Conference on Artificial Intelligence, 2021: 12042-12049. |
| 24 | CHEN X Y, TIAN Y D. Learning to perform local rewriting for combinatorial optimization[C]//Proc. of the Advances in Neural Information Processing systems, 2019. |
| 25 | QIN W , ZHUANG Z L , HUANG Z Z , et al. A novel reinforcement learning-based hyper-heuristic for heterogeneous vehicle routing problem[J]. Computers & Industrial Engineering, 2021, 156, 107252. |
| 26 |
LI J W , MA Y N , GAO R Z , et al. Deep reinforcement learning for solving the heterogeneous capacitated vehicle routing problem[J]. IEEE Trans. on Cybernetics, 2022, 52 (12): 13572- 13585.
doi: 10.1109/TCYB.2021.3111082 |
| 27 | MA Q, GE S W, HE D Y, et al. Combinatorial optimization by graph pointer networks and hierarchical reinforcement learning[EB/OL]. [2024-02-07]. https://arxiv.org/abs/1911.04936. |
| 28 | WANG X P , FU H Q , DENG G Z , et al. Hierarchical free gait motion planning for hexapod robots using deep reinforcement learning[J]. IEEE Trans. on Industrial Informatics, 2023, 19 (1): 10901- 10912. |
| 29 | HOU Q C, YANG J W, SU Y Q, et al. Generalize learned heuristics to solve large-scale vehicle routing problems in real-time[C]//Proc. of the 11th International Conference on Learning Representations, 2022. |
| 30 | KINGMA D P. Adam: a method for stochastic optimization[C]// Proc. of the 3rd International Conference on Learning Representation, 2014. |
| 31 | WU Y X , SONG W , CAO Z G , et al. Learning improvement heuristics for solving routing problems[J]. IEEE Trans. on Neural Networks and Learning Systems, 2021, 33 (9): 5057- 5069. |
| 32 | HELSGAUN K . An extension of the Lin-Kernighan-Helsgaun TSP solver for constrained traveling salesman and vehicle routing problems[J]. Roskilde: Roskilde University, 2017, 12, 966- 980. |
| 33 | FURNON V, PERRON L. OR-tools routing library[EB/OL]. [2024-02-07]. https://developers.google.com/optimization/routing/. |
| 34 |
CHRISTIAENS J , VANDEN BERGHE G . Slack induction by string removals for vehicle routing problems[J]. Transportation Science, 2020, 54 (2): 417- 433.
doi: 10.1287/trsc.2019.0914 |
| [1] | 张庭瑜, 曾颖, 李楠, 黄洪钟. 基于深度强化学习的航天器功率-信号复合网络优化算法[J]. 系统工程与电子技术, 2024, 46(9): 3060-3069. |
| [2] | 夏雨奇, 黄炎焱, 陈恰. 基于深度Q网络的无人车侦察路径规划[J]. 系统工程与电子技术, 2024, 46(9): 3070-3081. |
| [3] | 杨志鹏, 陈子浩, 曾长, 林松, 毛金娣, 张凯. 复杂环境下的飞行器在线航路规划决策方法[J]. 系统工程与电子技术, 2024, 46(9): 3166-3175. |
| [4] | 郭宏达, 娄静涛, 徐友春, 叶鹏, 李永乐, 陈晋生. 基于MADDPG的多无人车协同事件触发通信[J]. 系统工程与电子技术, 2024, 46(7): 2525-2533. |
| [5] | 张梦钰, 豆亚杰, 陈子夷, 姜江, 杨克巍, 葛冰峰. 深度强化学习及其在军事领域中的应用综述[J]. 系统工程与电子技术, 2024, 46(4): 1297-1308. |
| [6] | 李彦铃, 罗飞舟, 葛致磊. 基于鲁棒观测器的深度强化学习垂直起降运载器姿态稳定研究[J]. 系统工程与电子技术, 2024, 46(3): 1038-1047. |
| [7] | 吴冯国, 陶伟, 李辉, 张建伟, 郑成辰. 基于深度强化学习算法的无人机智能规避决策[J]. 系统工程与电子技术, 2023, 45(6): 1702-1711. |
| [8] | 唐进, 梁彦刚, 白志会, 黎克波. 基于DQN的旋翼无人机着陆控制算法[J]. 系统工程与电子技术, 2023, 45(5): 1451-1460. |
| [9] | 唐斯琪, 潘志松, 胡谷雨, 吴炀, 李云波. 深度强化学习在天基信息网络中的应用——现状与前景[J]. 系统工程与电子技术, 2023, 45(3): 886-901. |
| [10] | 李信, 李勇军, 赵尚弘. 基于深度强化学习的卫星光网络波长路由算法[J]. 系统工程与电子技术, 2023, 45(1): 264-270. |
| [11] | 王冠, 茹海忠, 张大力, 马广程, 夏红伟. 弹性高超声速飞行器智能控制系统设计[J]. 系统工程与电子技术, 2022, 44(7): 2276-2285. |
| [12] | 孟泠宇, 郭秉礼, 杨雯, 张欣伟, 赵柞青, 黄善国. 基于深度强化学习的网络路由优化方法[J]. 系统工程与电子技术, 2022, 44(7): 2311-2318. |
| [13] | 杨清清, 高盈盈, 郭玙, 夏博远, 杨克巍. 基于深度强化学习的海战场目标搜寻路径规划[J]. 系统工程与电子技术, 2022, 44(11): 3486-3495. |
| [14] | 高昂, 董志明, 李亮, 宋敬华, 段莉. MADDPG算法并行优先经验回放机制[J]. 系统工程与电子技术, 2021, 43(2): 420-433. |
| [15] | 马文, 李辉, 王壮, 黄志勇, 吴昭欣, 陈希亮. 基于深度随机博弈的近距空战机动决策[J]. 系统工程与电子技术, 2021, 43(2): 443-451. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||