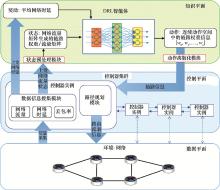
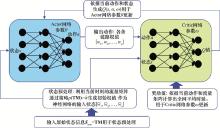
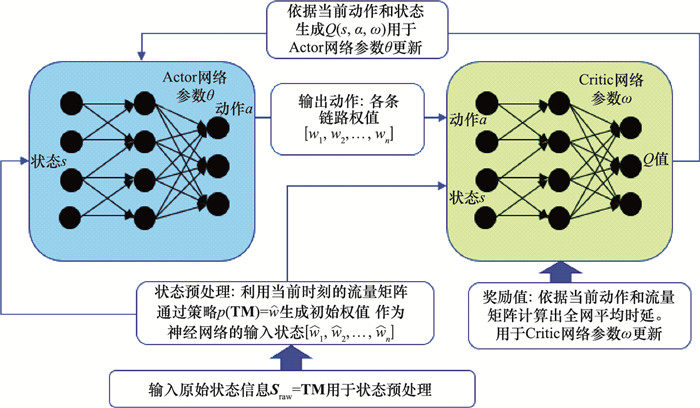
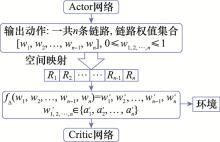
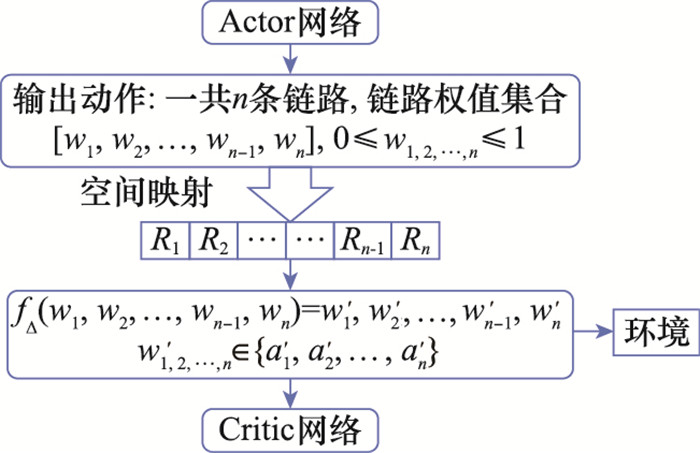
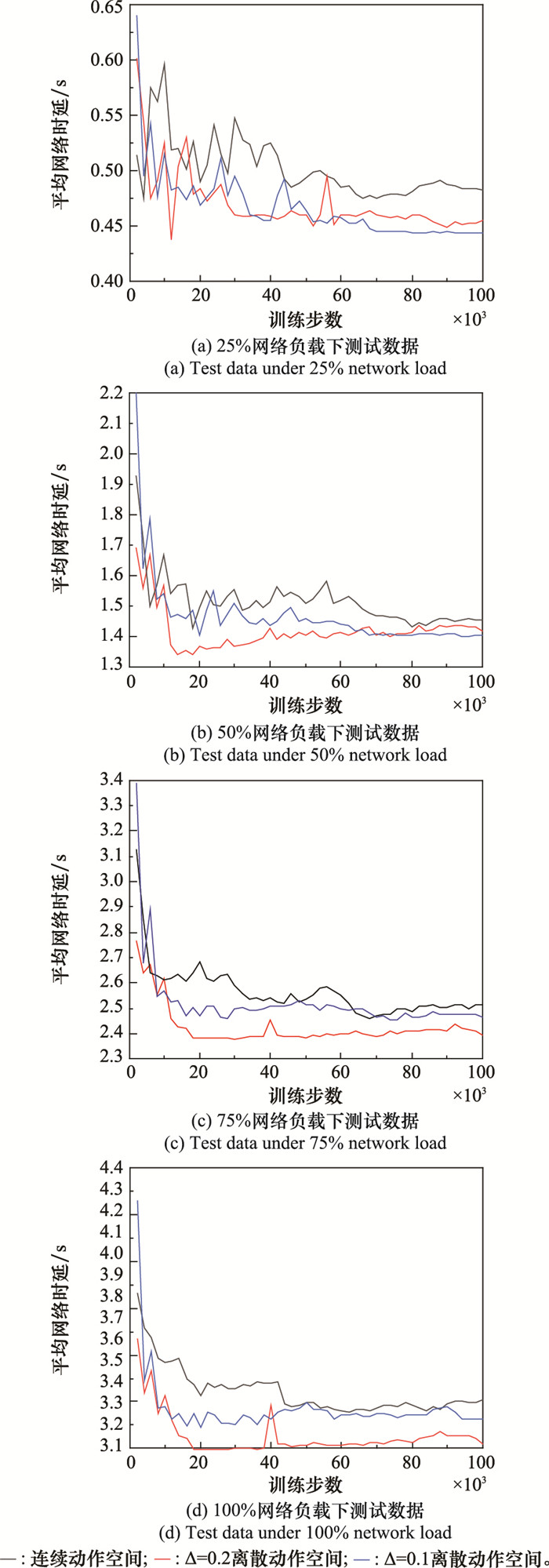
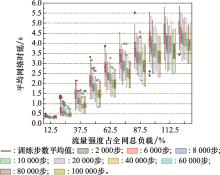
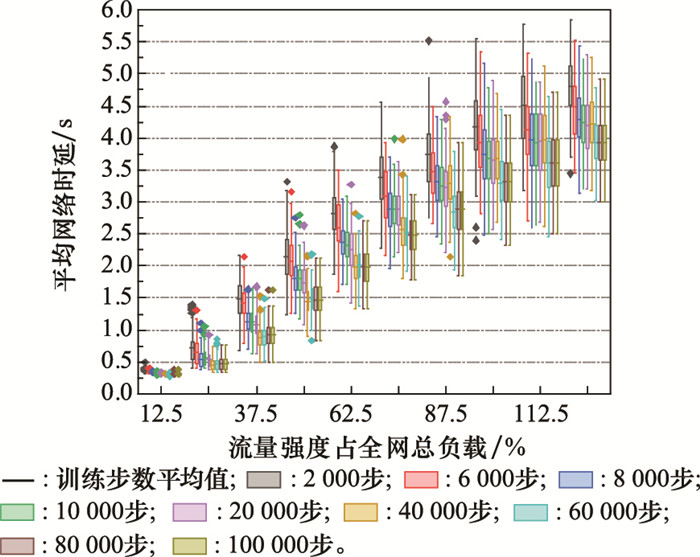
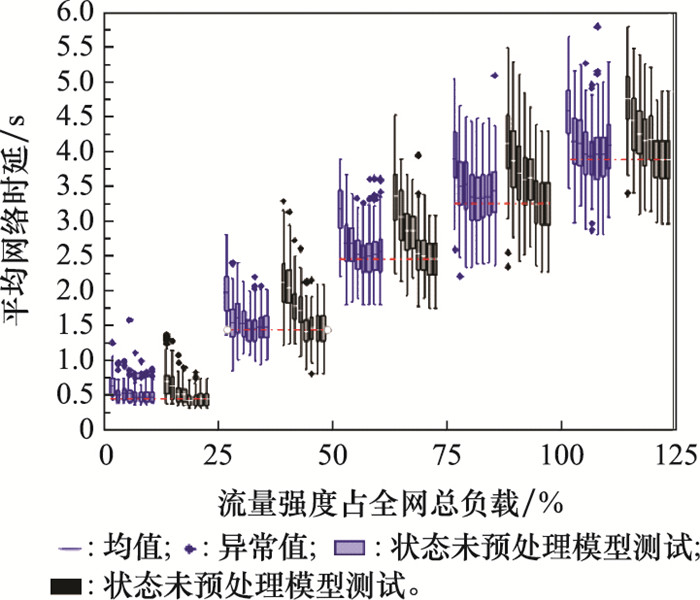
| 1 |
BOUZIDI H, OUTTAGARTS A, LANGAR R. Deep reinforcement learning application for network latency management in software defined networks[C]//Proc. of the IEEE GLOBECOM, 2019.
|
| 2 |
DIEGO K , FERNANDO M R . Paulo estevesverissimo, Christian Esteverothenberg, siamakazodolmolky, andsteveuhlig[J]. Proceedings of the IEEE, 2015, 103 (1): 14- 76.
doi: 10.1109/JPROC.2014.2371999
|
| 3 |
欧阳晔, 王立磊, 杨爱东, 等. 通信人工智能的下一个十年[J]. 电信科学, 2021, 37 (3): 1- 36.
|
|
OUYANG Y , WANG L L , YANG A D . Next decade of telecommunications artificial intelligence[J]. Telecommunications Science, 2021, 37 (3): 1- 36.
|
| 4 |
ALEXANDER C, MOULI C, SAILESH K D: A SDN framework for distributed network analytics[C]//Proc. of the IFIP/IEEE International Symposium on Integrated Network Management, 2015: 9-17.
|
| 5 |
WANG F Y , ZHANG J J , ZHENG X , et al. Where does alpha go go: from church-turning thesis to alpha go thesis and beyond[J]. Acta Automatica Sinica, 2016, 3 (2): 113- 120.
|
| 6 |
CLARK D D, PARTRIDGE C, RAMMING J C, et al. A knowledge plane for the internet[C]//Proc. of the Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications, 2003: 3-10.
|
| 7 |
BOUTABA R , SALAHUDDIN M A , LIMAM N , et al. A comprehensive survey on machine learning for networking: evolution, applications and research opportunities[J]. Journal of Internet Services and Applications, 2018,
doi: 10.1186/s13174-018-0087-2
|
| 8 |
SENDRA S, REGO A, LLORET J, et al. Including artificial intelligence in a routing protocol using software defined networks[C]//Proc. of the IEEE International Conference on Communications Workshops, 2017: 670-674.
|
| 9 |
STAMPA G, ARIAS M, SANCHEZ-CHARLES D, et al. A deep-reinforcement learning approach for software-defined networking routing optimization[EB/OL]. [2021-06-25]. https://arxiv.org/abs/1709.07080.
|
| 10 |
LILLICRAP T P, HUNT J J, PRITZEL A, et al. Continuous control with deep reinforcement learning[EB/OL]. [2021-06-25]. https://arxiv.org/abs/1509.02971.
|
| 11 |
ZOPH B, GHIASI G, LIN T Y, et al. Rethinking pre-training and self-training[EB/OL]. [2021-06-25]. https://arxiv.org/abs/2006.06882v2/
|
| 12 |
王雪松, 张依阳, 程玉虎. 基于高斯过程分类器的连续空间强化学习[J]. 电子学报, 2009, 37 (6): 1153- 1158.
doi: 10.3321/j.issn:0372-2112.2009.06.001
|
|
WANG X S , ZHANG Y Y , CHENG Y H . Reinforcement learning for continuous spaces based on Gaussian process classifier[J]. Acta Electronica Sinica, 2009, 37 (6): 1153- 1158.
doi: 10.3321/j.issn:0372-2112.2009.06.001
|
| 13 |
NGIAM J, KHOSLA A, KIM M, et al. Multimodal deep learning[C]//Proc. of the International Conference on Machine Learning, 2009.
|
| 14 |
SUTTON R S , BARTO A G . Reinforcement learning[J]. A Bradford Book, 1998, 15 (7): 665- 685.
|
| 15 |
LBERT M , ALBERTO R N , JOSEP C . Knowledge-defined networking[J]. ACM SIGCOMM Computer Communication Review, 2017, 47 (3): 2- 10.
doi: 10.1145/3138808.3138810
|
| 16 |
CLARK D. A knowledge plane for the internet[C]//Proc of the ACM Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications, 2003.
|
| 17 |
SUTTON R S , BARTO N G . Reinforcement learning: an introduction[M]. Cambridge: MIT Press, 1998.
|
| 18 |
REIF J H . Depth-first search is inherently sequential[J]. Information Processing Letters, 1985, 20 (5): 229- 234.
doi: 10.1016/0020-0190(85)90024-9
|
| 19 |
YAO Q, FAN Y, HU W, et al. On the training aspects of deep neural network (DNN) for parametric TTS synthesis[C]//Proc. of the IEEE International Conference on Acoustics, 2014.
|
| 20 |
GUO Z T , WEN G . Shortest path algorithm in time-dependent networks[J]. Chinese Journal of Computers, 2002, 2 (2): 165- 172.
|
| 21 |
ROUGHAN M . Simplifying the synthesis of internet traffic matrices[J]. ACM SIGCOMM Computer Communication Review, 2005, 35 (5): 93- 96.
doi: 10.1145/1096536.1096551
|
| 22 |
WASSERSTEI N , RONALD L . Monte Carlo: concepts, algorithms, and applications[J]. Technometrics, 1996, 39 (3): 338- 338.
|