
系统工程与电子技术 ›› 2026, Vol. 48 ›› Issue (1): 1-11.doi: 10.12305/j.issn.1001-506X.2026.01.01
林志康( ), 刘甲磊, 马佳智, 施龙飞, 徐进宝
), 刘甲磊, 马佳智, 施龙飞, 徐进宝
收稿日期:2024-11-13
出版日期:2026-01-25
发布日期:2026-02-11
通讯作者:
刘甲磊
E-mail:z_k.kang@nudt.edu.cn
作者简介:林志康(1997—),男,博士研究生,主要研究方向为雷达电子防御、强化学习基金资助:
Zhikang LIN(), Jialei LIU, Jiazhi MA, Longfei SHI, Jinbao XU
Received:2024-11-13
Online:2026-01-25
Published:2026-02-11
Contact:
Jialei LIU
E-mail:z_k.kang@nudt.edu.cn
摘要:
针对多个反辐射无人机(anti-radiation unmanned aerial vehicle, ARUAV)同时来袭时如何通过分布式辐射源协同实现有效诱偏以保护地面雷达的问题,提出一种面向双架ARUAV打击的分布式辐射源闪烁诱偏方法,旨在以大距离的分布式布站方式对辐射源进行闪烁辐射控制来影响ARUAV被动测角,进而改变其运行轨迹,最终在末端诱偏使其落点位于雷达辐射源安全半径之外。该方法首先分析信号延时控制形成脉内组合信号对ARUAV的测角诱偏原理并设计ARUAV运动模型,然后建立四维Q表深度Q学习框架,根据雷达安全距离条件建立奖励函数,以一定空域的ARUAV位置和速度作为输入,进行强化学习模型训练。仿真结果表明,所提方法诱偏距离至少为515.91 m,优于传统固定辐射诱偏方法,且较同等布站条件固定辐射的末端诱偏方法诱偏距离至少提升68.59%。
中图分类号:
林志康, 刘甲磊, 马佳智, 施龙飞, 徐进宝. 利用分布式辐射源闪烁诱偏的抗反辐射方法[J]. 系统工程与电子技术, 2026, 48(1): 1-11.
Zhikang LIN, Jialei LIU, Jiazhi MA, Longfei SHI, Jinbao XU. Counter-anti-radiation method method using distributed radiation source blinking decoy[J]. Systems Engineering and Electronics, 2026, 48(1): 1-11.
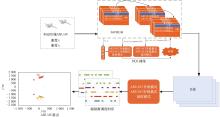
图1
所提方法整体流程图"
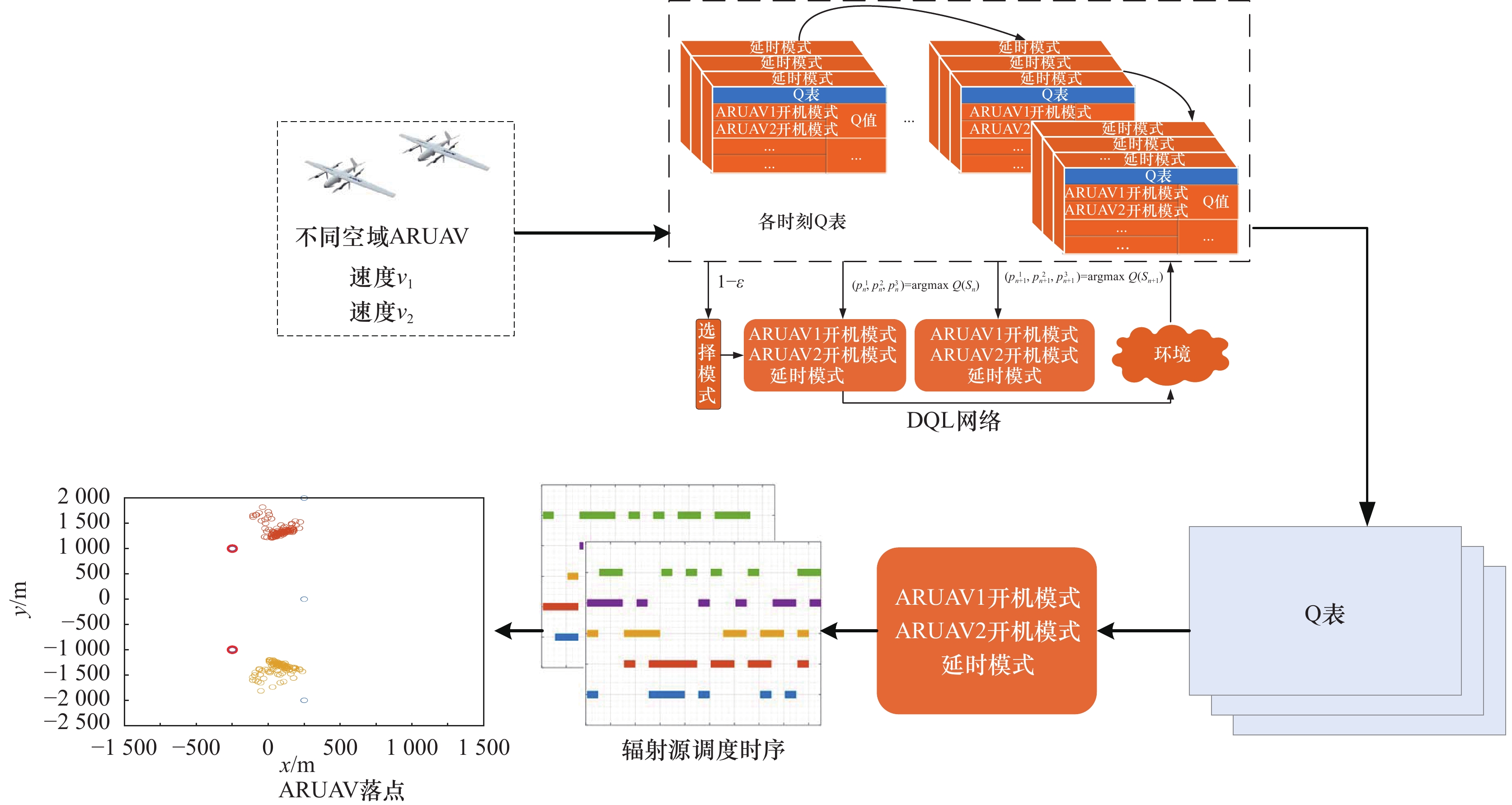
图2
十字交叉长短基线干涉仪测角示意图"
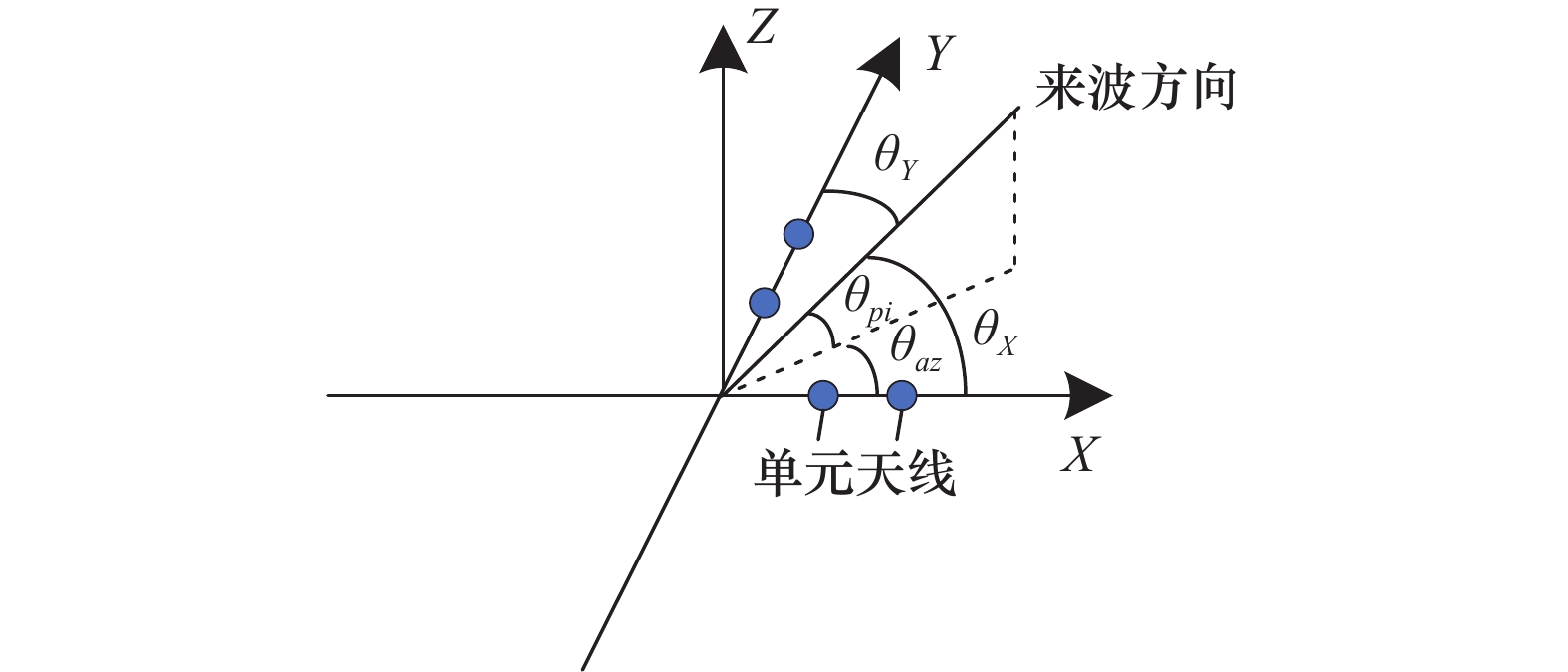
表1
辐射源开机模式表"
| 模式 | 辐射源1 | 辐射源2 | 辐射源3 | 辐射源4 | 辐射源5 |
| 1 | 1 | 1 | 0 | 0 | 0 |
| 2 | 1 | 0 | 0 | 1 | 0 |
| 3 | 0 | 1 | 1 | 0 | 0 |
| 4 | 0 | 1 | 0 | 0 | 1 |
| 5 | 0 | 0 | 1 | 1 | 0 |
| 6 | 0 | 0 | 0 | 1 | 1 |
| 7 | 0 | 0 | 1 | 1 | 1 |
| 8 | 0 | 1 | 1 | 0 | 1 |
| 9 | 1 | 0 | 0 | 1 | 1 |
| 10 | 1 | 0 | 1 | 1 | 0 |
| 11 | 1 | 1 | 0 | 0 | 1 |
| 12 | 1 | 1 | 1 | 0 | 0 |
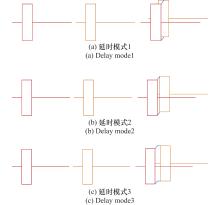
图3
不同延时模式下的脉内组合信号"
表2
不同延时模式干涉仪测角结果"
| 模式 | 辐射源编号 | 方位角/(°) | 俯仰角/(°) |
| — | 1 | 42.709 4 | 21.586 9 |
| — | 2 | 42.878 9 | 20.122 7 |
| 延时模式1 | 1, 2 | 44.972 9 | 37.701 0 |
| 延时模式2 | 1, 2 | 44.429 8 | 24.643 8 |
| 延时模式3 | 1, 2 | 44.886 0 | 47.835 1 |
表3
延时分析参数设置"
| 参数 | 数值 |
| 采样频率/MHz | 150 |
| 脉宽/μs | 100 |
| 载频/GHz | 3 |
| 辐射源1坐标/m | [1 000, 2 000, 0] |
| 辐射源2坐标/m | [0, 1 000, 0] |
| ARUAV位置点/×103m | [14, 14, 7] |
图4
ARUAV运动调整图"
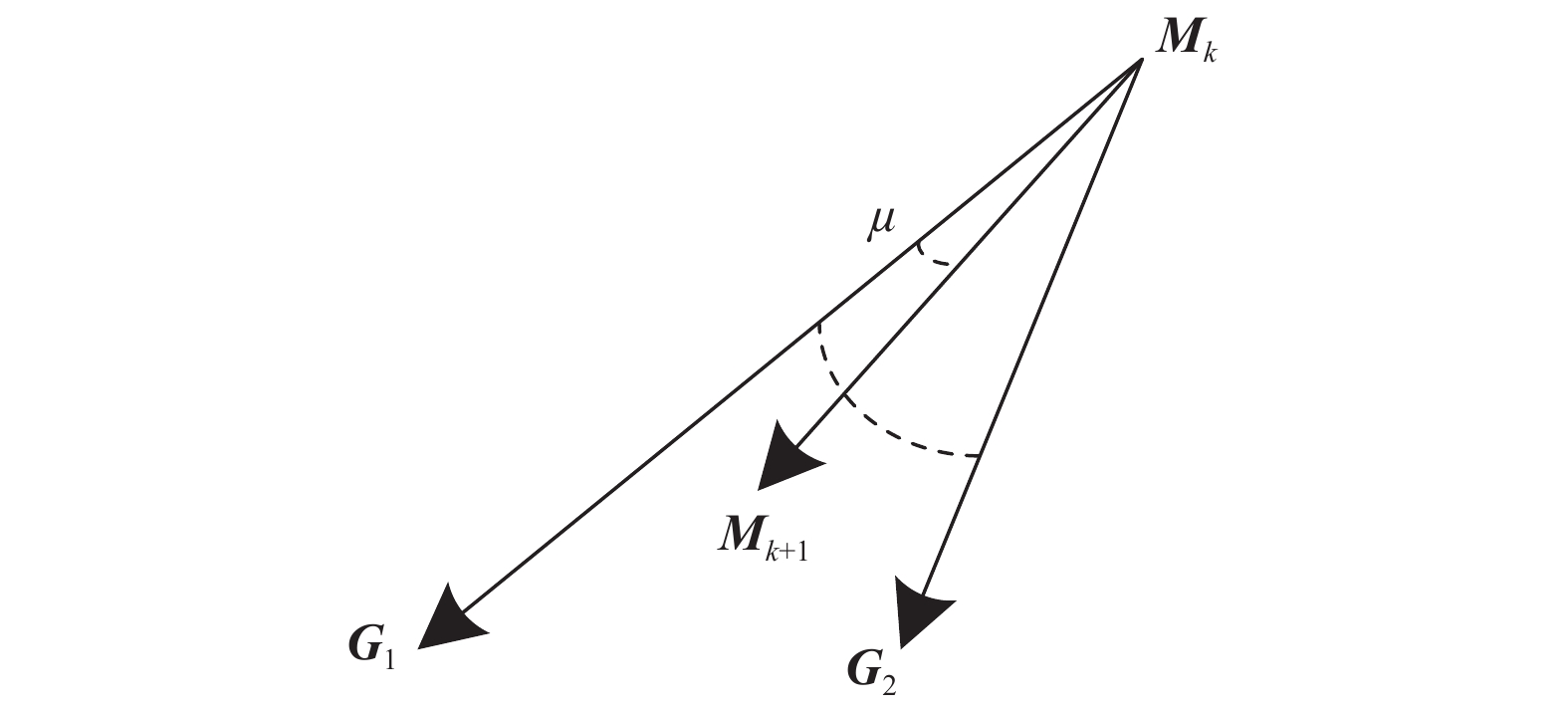
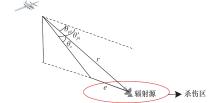
图5
ARUAV攻击目标示意图"
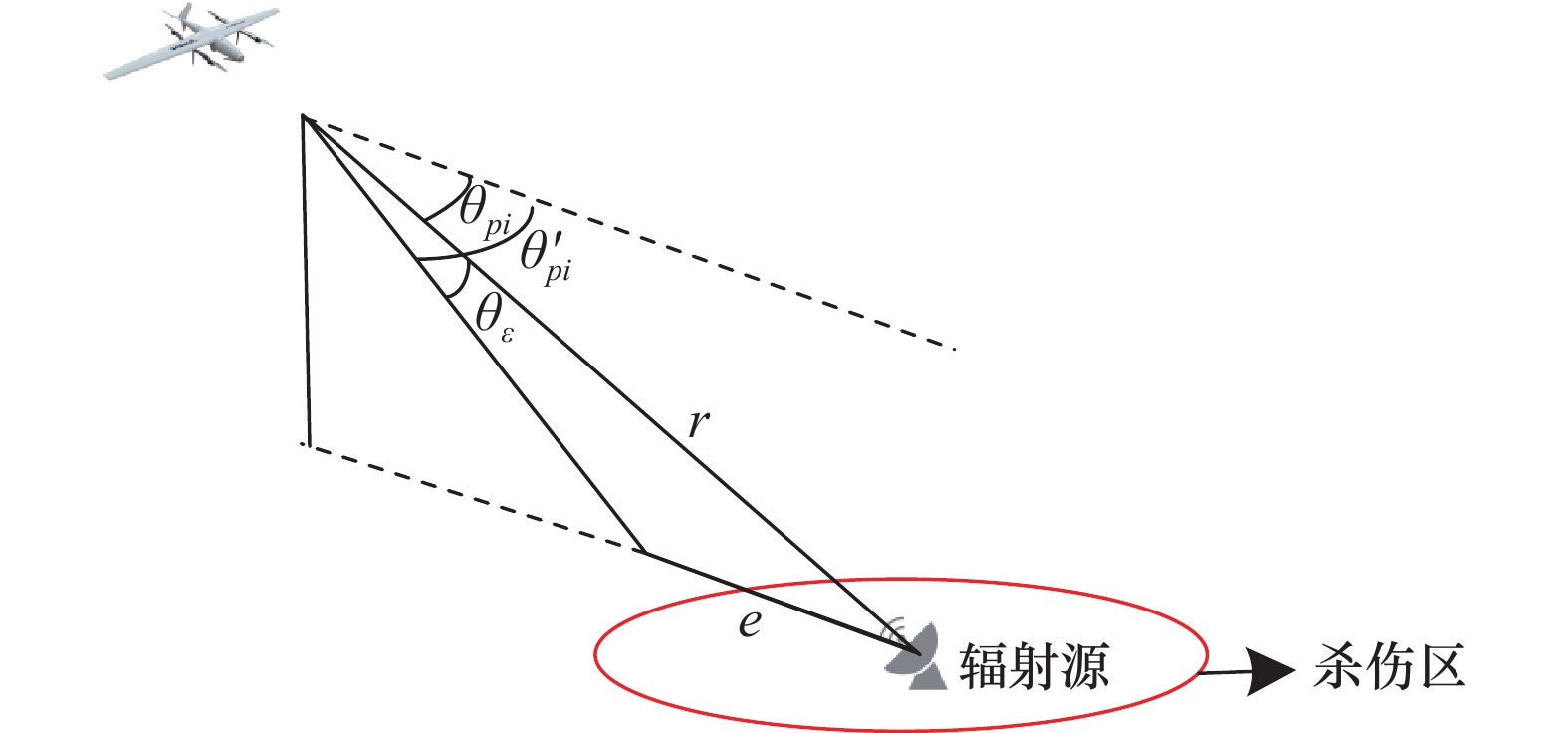
表4
开机模式转移判别矩阵"
| 模式 | |||||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | ||
| 模式 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | |
| 3 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | |
| 4 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | |
| 5 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | |
| 6 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | |
| 7 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 8 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 9 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 10 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 11 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 12 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | |
图6
DQL算法流程图"
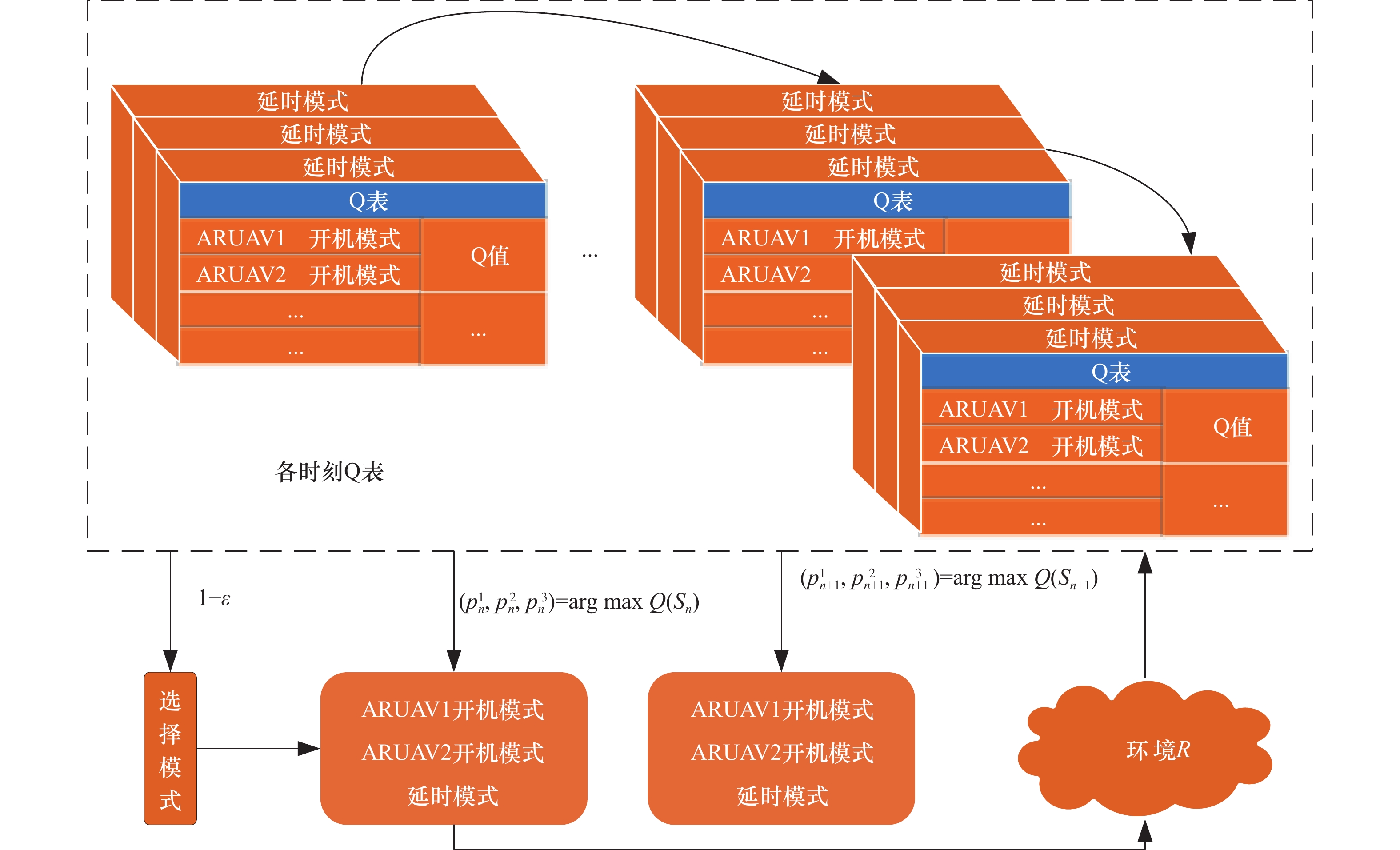
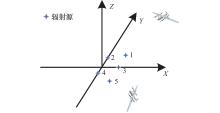
图7
仿真场景"
表5
ARUAV参数"
| 参数 | 数值 |
| 干涉仪短基线长度 | |
| 干涉仪长基线长度 | |
| 采样门限 | |
| 采样频率/MHz | 150 |
| ARUAV1发射空域/×103 m | [13,15], [13,15],[6,8] |
| ARUAV2发射空域/×103 m | [13,15],−[13,15],[6,8] |
| ARUAV速度/马赫 | 3~4 |
表6
辐射源参数"
| 参数 | 数值 |
| 脉宽/μs | 100 |
| 占空比/% | 20, 10 |
| 载频/GHz | 3 |
| 辐射源1坐标/m | [ |
| 辐射源2坐标/m | [0, |
| 辐射源3坐标/m | [ |
| 辐射源4坐标/m | [0, − |
| 辐射源5坐标/m | [ |
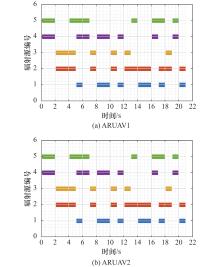
图8
不同ARUAV的辐射源调度时序图"

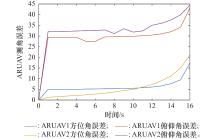
图9
ARUAV测角误差变化曲线"
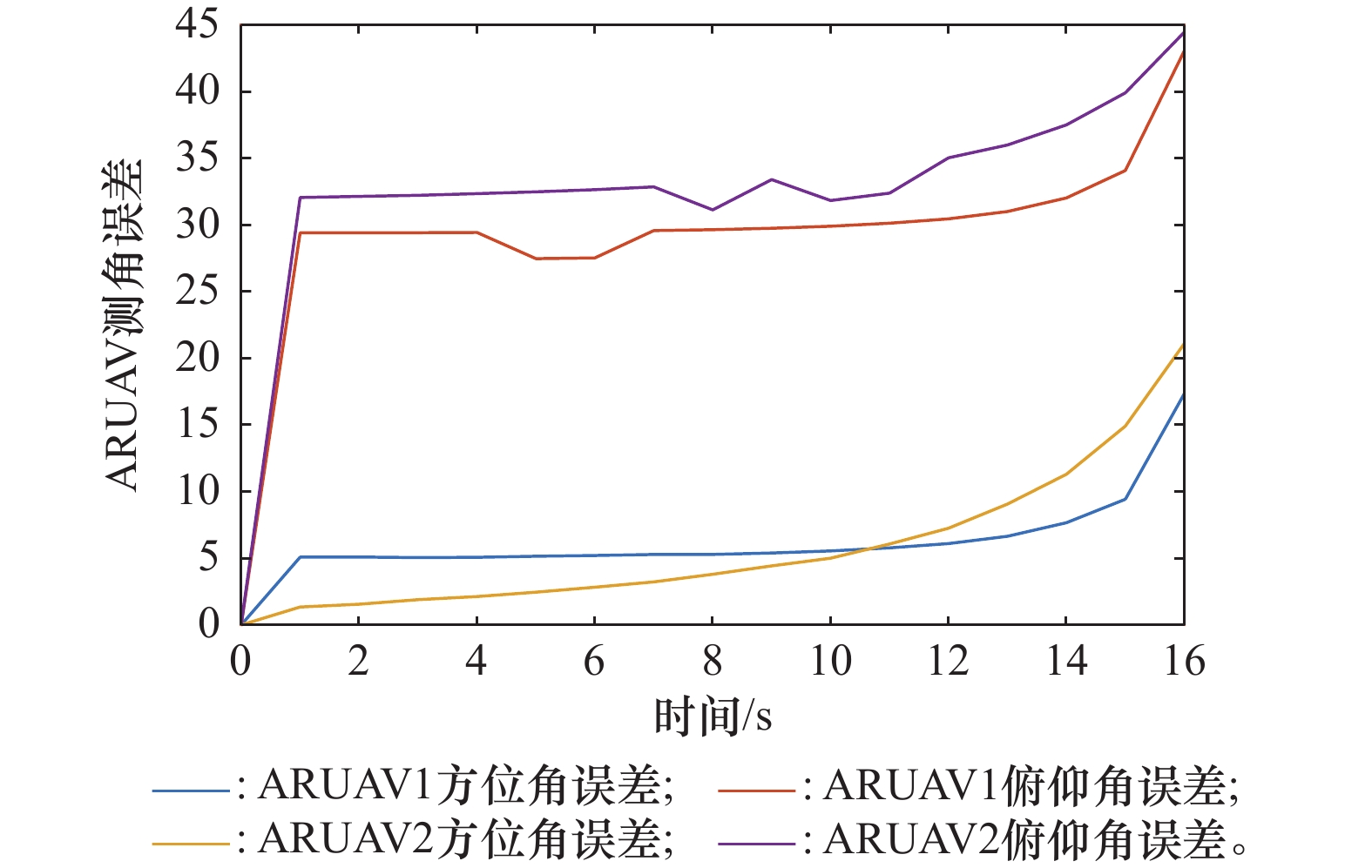
表7
延时辐射时序调度"
| 序号 | 辐射源1 | 辐射源2 | 辐射源3 | 辐射源4 | 辐射源5 |
| 1 | 关机 | 开机② | 延时 | 开机① | 延时 |
| 2 | 开机② | 延时 | 关机 | 开机① | 延时 |
| 3 | 关机 | 开机① | 延时 | 开机② | 延时 |
| 4 | 开机② | 开机① | 延时 | 延时 | 关机 |
| 5 | 开机② | 开机① | 延时 | 延时 | 延时 |
| 6 | 开机① | 开机② | 延时 | 延时 | 延时 |
| 7 | 开机② | 延时 | 关机 | 开机① | 延时 |
| 8 | 开机② | 开机① | 延时 | 延时 | 延时 |
| 9 | 开机① | 开机② | 关机 | 延时 | 延时 |
| 10 | 开机① | 开机② | 延时 | 延时 | 延时 |
| 11 | 开机② | 开机① | 延时 | 延时 | 延时 |
| 12 | 开机① | 开机② | 延时 | 延时 | 关机 |
| 13 | 关机 | 开机① | 延时 | 开机② | 延时 |
| 14 | 关机 | 开机① | 开机② | 延时 | 延时 |
| 15 | 开机① | 延时 | 开机② | 延时 | 关机 |
| 16 | 开机① | 延时 | 开机② | 延时 | 关机 |
| 17 | 关机 | 开机② | 延时 | 开机① | 延时 |
| 18 | 开机① | 延时 | 开机② | 延时 | 延时 |
| 19 | 开机② | 开机① | 延时 | 延时 | 关机 |
| 20 | 关机 | 开机② | 延时 | 开机① | 延时 |
| 21 | 开机① | 延时 | 开机② | 延时 | 关机 |
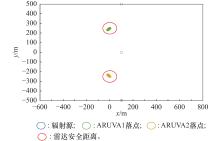
图10
无诱偏落点图"
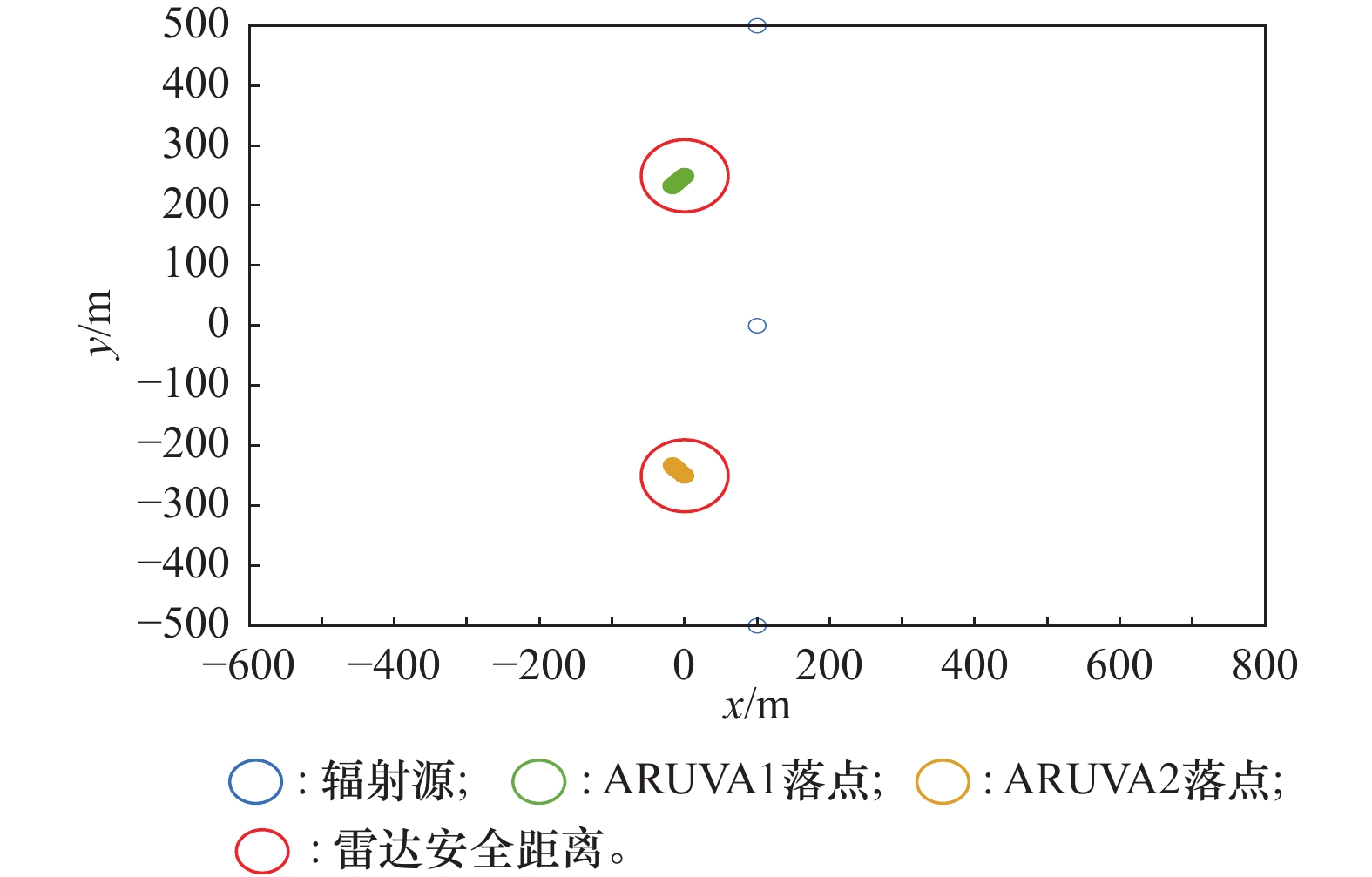
图11
传统布站诱偏落点图"
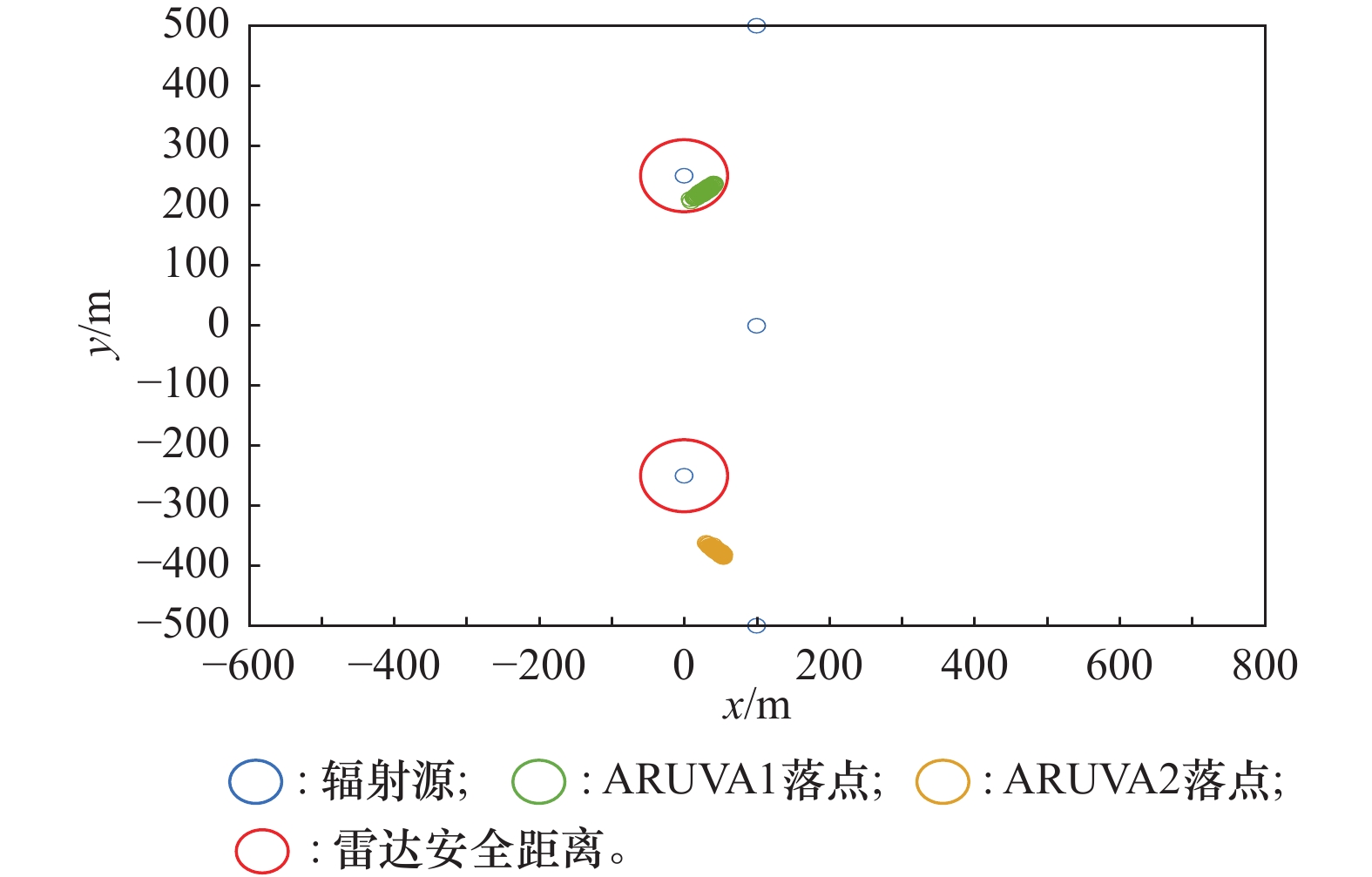
图12
本文布站诱偏落点图"
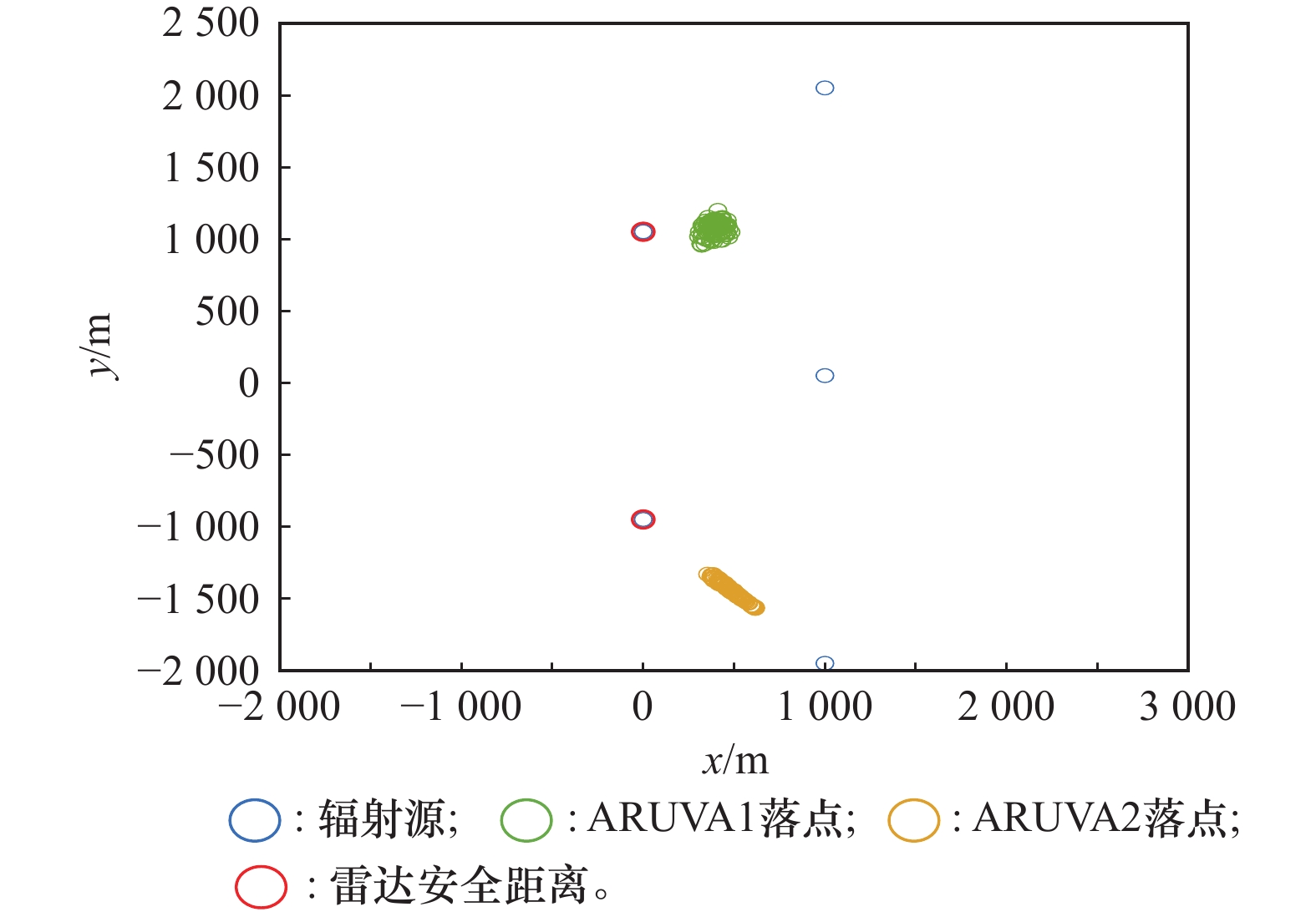
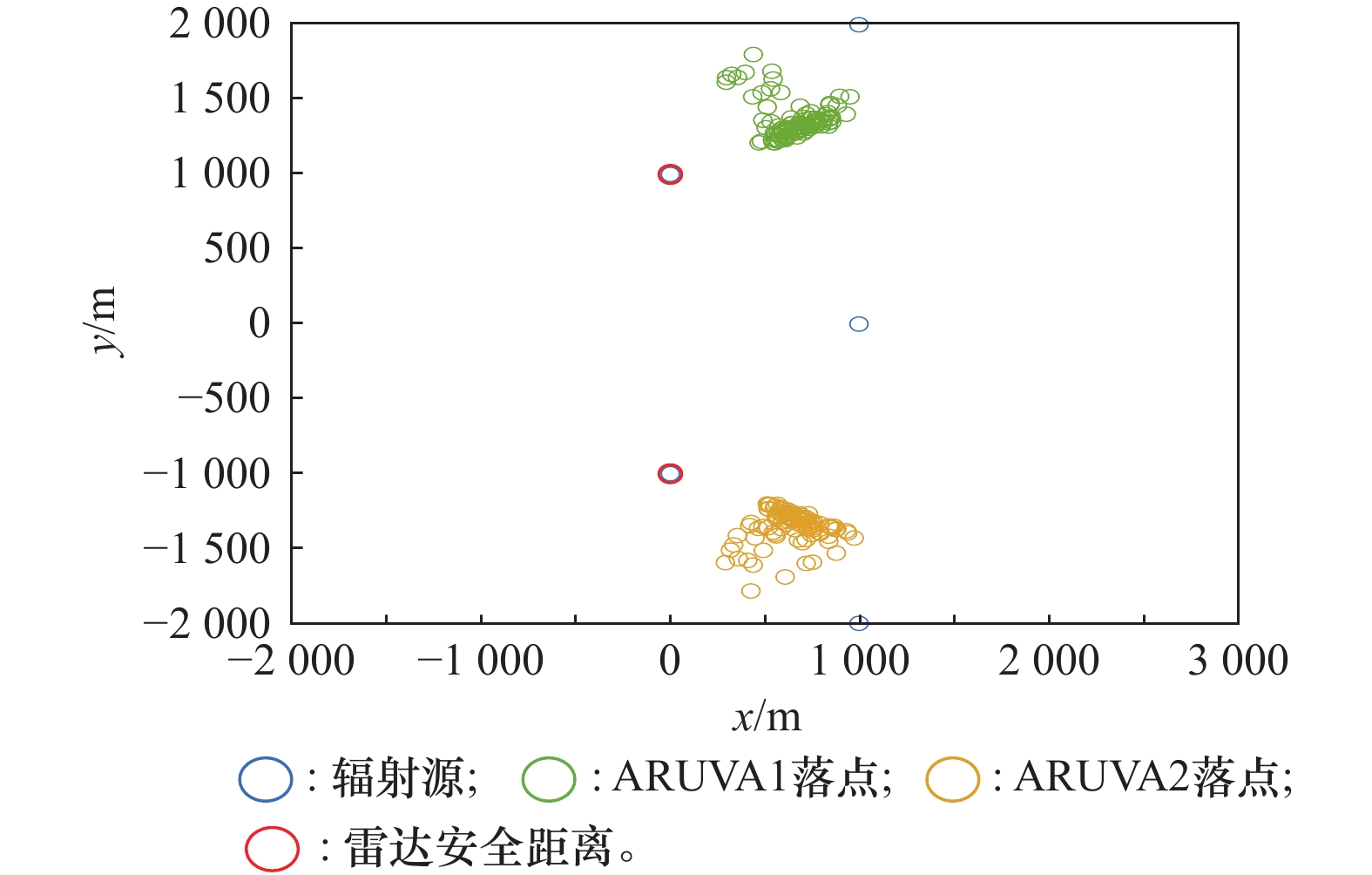
图13
所提方法诱偏落点图"
| 1 |
FONTANA S, DI LAURO F. An overview of sensors for long range missile defense[J]. Sensors, 2022, 22 (24): 9871.
doi: 10.3390/s22249871 |
| 2 | 易伟, 袁野, 刘光宏, 等. 多雷达协同探测技术研究进展: 认知跟踪与资源调度算法[J]. 雷达学报, 2023, 12 (3): 471- 499. |
| YI W, YUAN Y, LIU G H, et al. Recent advances in multi-radar collaborative surveillance: cognitive tracking and resource scheduling algorithms[J]. Journal of Radars, 2023, 12 (3): 471- 499. | |
| 3 | 齐铖, 谢军伟, 张浩为, 等. 基于防空目标探测与跟踪的雷达资源管理技术研究综述[J]. 信号处理, 2024, 40 (11): 1972- 1989. |
| QI C, XIE J W, ZHANG H W, et al. Review of radar resource management technology for air defense target detection and tracking[J]. Journal of Signal Processing, 2024, 40 (11): 1972- 1989. | |
| 4 | ZOU J B, GAO K, ZHANG E Y. Research on electromagnetic scattering characteristics of anti-radiation missile[C]//Proc. of the 3rd International Conference on Communication Software and Networks, 2011: 470−473. |
| 5 | NERI F. Introduction to electronic defense systems[M]. 3 ed. Norwood: Artech House, 2018. |
| 6 | 李玮, 程磊, 逯怀刚, 等. 俄乌冲突中反辐射导弹的作战运用与启示[J]. 航天电子对抗, 2023, 39 (3): 5- 9. |
| LI W, CHENG L, LU H G, et al. Combat use and enlightenment for anti-radiation missile in the Russia-Ukraine conflict[J]. Aerospace Electronic Warfare, 2023, 39 (3): 5- 9. | |
| 7 | 周伟光, 罗积润, 贾玉贵, 等. 雷达配置诱饵对抗反辐射导弹的仿真[J]. 电子与信息学报, 2010, 32 (6): 1370- 1376. |
| ZHOU W G, LUO J R, JIA Y G, et al. Simulation of radar equipped with decoys for counteracting anti-radiation missile[J]. Journal of Electronics & Information Technology, 2010, 32 (6): 1370- 1376. | |
| 8 | ZOU J B, GAO K, ZHANG E Y. Using radar echo to confront anti-radiation missiles[J]. Electronics Letters, 2011, 47(5): 340−341. |
| 9 | ZOU J B, GAO K, LU S J, et al. Coherent decoys jamming anti-radiation missiles[C]//Proc. of the Jordan Conference on Applied Electrical Engineering and Computing Technologies, 2013. |
| 10 | EMADI M, JAFARGHOLI A, MOGHADAM H S, et al. New anti-ARM technique by using random phase and amplitude active decoys[J]. Progress in Electromagnetics Research, 2008, 87 (92): 297- 311. |
| 11 | DONG W F, LIU Q, CHENG Z K, et al. The deceptive effect of blinking decoys on ARMs[C]//Proc. of the Applied Informatics and Communication: International Conference, 2011: 338−347. |
| 12 | RUTKOWSKI A K, CŻYZEWSKI M, WITCZAK A, et al. Protection of radar against anti-radiation missile using single electromagnetic decoy[C]// Proc. of the 16th International Radar Symposium, 2015: 973−978. |
| 13 | 汤建龙, 郭立博, 董阳阳. 基于到达时间和到达方向联合定位的机动有源诱偏方法[J]. 兵工学报, 2020, 41 (10): 2088- 2095. |
| TANG J L, GUO L B, DONG Y Y. Maneuvering active decoying method based on joint TOA-DOA localization[J]. Acta Armamentarii, 2020, 41 (10): 2088- 2095. | |
| 14 | YANG J, XU J H. Analysis of three-point source decoy against anti-radiation missile[C]//Proc. of the 5th International Conference on Artificial Intelligence and Pattern Recognition, 2022: 1159−1163. |
| 15 |
LESICKA A, SLESICKI B. The concept of disrupting anti-radiation missiles in a radar decoy system[J]. Aviation and Security Issues, 2023, 3 (1): 167- 181.
doi: 10.55676/asi.v3i1.52 |
| 16 | 徐宏, 尚朝轩, 韩壮志, 等. 组网火控雷达抗反辐射导弹的闪烁诱偏方法[J]. 系统工程与电子技术, 2011, 33 (5): 1146- 1150. |
| XU H, SHANG C X, HAN Z Z, et al. Blinking decoying method for countering anti-radiation missiles in fire-control radar network[J]. Systems Engineering and Electronic Technology, 2011, 33 (5): 1146- 1150. | |
| 17 | LAKSHMI E V, SASTRY N N, RAO B P. Optimum active decoy deployment for effective deception of missile radars[C]//Proc. of the CIE International Conference on Radar, 2011: 234−237. |
| 18 | VIJAYALAKSHMI E A. Analysis of active decoy deployment against anti-radiation missiles[J]. International Journal of Engineering & Technology, 2018, 7(4): 4814−4818. |
| 19 | MATTILA V, VIRTANEN K, MUTTILAINEN L, et al. Optimizing locations of decoys for protecting surface-based radar against anti-radiation missile with multi-objective ranking and selection[C]//Proc. of the Winter Simulation Conference, 2014: 2319−2330. |
| 20 | ŁUSZCZYK M. Wybrane problemy ochrony radarów przed rakietami antyradiolokacyjnymi[J]. Problemy Mechatroniki: Uzbrojenie, Lotnictwo, Inżynieria Bezpieczeństwa, 2014, 5 (2): 115- 122. |
| 21 |
KAWALEC A, DUDCZYK J. Identification of emitter sources in the aspect of their fractal features[J]. Bulletin of the Polish Academy of Sciences-Technical Sciences, 2013, 61 (3): 623- 628.
doi: 10.2478/bpasts-2013-0065 |
| 22 | RUTKOWSKI A, KAWALEC A. A concept of a microwave seeker designed for ananti-radiation missile[C]//Proc. of the 12th Conference on Reconnaissance and Electronic Warfare System, 2019, 11055: 210−215. |
| 23 | KHMARSKIY P A, MUXAMMEDOV B M, JURAEV D A. Radar protection system against anti-radar missiles with integrated detection channel[J]. Advanced Engineering Days, 2023, 7, 142- 144. |
| 24 | 王跃东, 顾以静, 梁彦, 等. 伴随压制干扰与组网雷达功率分配的深度博弈研究[J]. 雷达学报, 2023, 12 (3): 642- 656. |
| WANG Y D, GU Y J, LIANG Y, et al. Deep game of escorting suppressive jamming and networked radar power allocation[J]. Journal of Radars, 2023, 12 (3): 642- 656. | |
| 25 | 解烽, 刘环宇, 胡锡坤, 等. 基于复数域深度强化学习的多干扰场景雷达抗干扰方法[J]. 雷达学报, 2023, 12 (6): 1290- 1304. |
| XIE F, LIU H Y, HU X K, et al. A radar anti-jamming method under multi jamming scenarios based on deep reinforcement learning in complex domains[J]. Journal of Radars, 2023, 12 (6): 1290- 1304. | |
| 26 | 石荣著. 干涉仪测向原理、方法与应用[M]. 北京: 电子工业出版社, 2023. |
| SHI R Z. Principle, method and application for direction finding by interferometer[M]. Beijing: Publishing House of Electronics Industry, 2023. | |
| 27 | JANG B, KIM M, HARERIMANA G, et al. Q-learning algorithms: a comprehensive classification and applications[J]. IEEE Access, 2019, 7 (1): 133653- 133667. |
| 28 | 林志康, 施龙飞, 刘甲磊, 等. 基于深度Q学习的组网雷达闪烁探测调度方法[J]. 系统工程与电子技术, 2025, 47 (5): 1443- 1452. |
| LIN Z K, SHI L F, LIU J L, et al. Scintillation scheduling method of netted radar based on deep Q learning[J]. Systems Engineering and Electronics, 2025, 47 (5): 1443- 1452. |
| [1] | 薛锦妍, 张雅声, 陶雪峰, 杨茗棋, 赵帅龙. GEO航天器轨道机动控制研究进展[J]. 系统工程与电子技术, 2026, 48(1): 290-300. |
| [2] | 宋传龙, 张倩武, 何健, 周文骏, 王辉, 孔巍巍, 田文波. 基于MADDPG算法的星地协同边缘计算任务卸载方法[J]. 系统工程与电子技术, 2026, 48(1): 350-360. |
| [3] | 姚鹏, 韩美玉, 王德川, 高志诚. 基于对抗进化强化学习的多无人艇追捕方法[J]. 系统工程与电子技术, 2025, 47(9): 2960-2970. |
| [4] | 魏潇龙, 吴亚荣, 姚登凯, 赵顾颢. 基于深度强化学习的无人机空战机动分层决策算法[J]. 系统工程与电子技术, 2025, 47(9): 2993-3003. |
| [5] | 杨大鹏, 龚资浩, 王小也, 郭正玉, 罗德林. 基于多智能体强化学习的无人机协同截击机动决策研究[J]. 系统工程与电子技术, 2025, 47(9): 3076-3085. |
| [6] | 符小卫, 王辛夷, 乔哲. 基于APIQ算法的多无人机攻防对抗策略[J]. 系统工程与电子技术, 2025, 47(7): 2205-2215. |
| [7] | 柳佳豪, 徐任杰, 孙茂桐, 姜九瑶, 李际超, 杨克巍. 基于强化学习的装备体系韧性优化方法[J]. 系统工程与电子技术, 2025, 47(7): 2216-2223. |
| [8] | 朱运豆, 孙海权, 胡笑旋. 基于指针网络架构的多星协同成像任务规划方法[J]. 系统工程与电子技术, 2025, 47(7): 2246-2255. |
| [9] | 符小卫, 王辛夷, 乔哲. 基于ASDDPG算法的多无人机对抗策略[J]. 系统工程与电子技术, 2025, 47(6): 1867-1879. |
| [10] | 孟麟芝, 孙小涓, 胡玉新, 高斌, 孙国庆, 牟文浩. 面向卫星在轨处理的强化学习任务调度算法[J]. 系统工程与电子技术, 2025, 47(6): 1917-1929. |
| [11] | 郑康洁, 张新宇, 王伟菘, 刘震生. DQN与规则结合的智能船舶动态自主避障决策[J]. 系统工程与电子技术, 2025, 47(6): 1994-2001. |
| [12] | 刘书含, 李彤, 李富强, 杨春刚. 意图态势双驱动的数据链抗干扰通信机制[J]. 系统工程与电子技术, 2025, 47(6): 2055-2064. |
| [13] | 林志康, 施龙飞, 刘甲磊, 马佳智. 基于深度Q学习的组网雷达闪烁探测调度方法[J]. 系统工程与电子技术, 2025, 47(5): 1443-1452. |
| [14] | 王子怡, 傅雄军, 董健, 冯程. 基于分层多智能体强化学习的雷达协同抗干扰策略优化[J]. 系统工程与电子技术, 2025, 47(4): 1108-1114. |
| [15] | 熊威, 张栋, 任智, 杨书恒. 面向有人/无人机协同打击的智能决策方法研究[J]. 系统工程与电子技术, 2025, 47(4): 1285-1299. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||