Transformer模型最先在NLP任务中被广泛应用, 在NLP任务中需要编码器抽取很多特征。其中, 首先需要考虑的就是每个词的上下文语义, 因为每个词的具体含义都跟上下文强相关, 而上下文又分为方向和距离两个属性, 传统的循环神经网络(recurrent neural network, RNN)[14 ] 只能对句子进行单向编码, CNN只能对短句进行编码, 而Transformer既可以同时编码双向语义, 又能够抽取长距离特征, 所以在上下文语义抽取方面要优于RNN和CNN。NLP任务需要抽取的第二种特征是序列的顺序, 在这方面Transformer的表现一般介于RNN和CNN之间。NLP任务对计算速度是比较敏感的, 由于RNN无法并行处理序列信息, 因此表现最差, CNN和Transformer都可以进行并行计算, 但Transformer模型结构稍显复杂, 所以在速度方面稍逊CNN。综上, 由于Transformer在效果和速度方面性能表现均衡, 所以在NLP任务中很快便脱颖而出, 之后随着研究的深入, Transformer被引入其他任务中, 均有不俗表现, 已隐隐呈现出成为高效的通用计算架构的趋势。
Transformer模型是一种典型的编码器-解码器结构, 其中最为重要是多头自注意力(multi-head self-attention, MSA), 残差连接和归一化(add & layer normalization, Add & LN)以及前馈网络3个模块。MSA负责将输入投影到不同空间, 得到Q K V Q V [15 ] 作为激活函数, 因为GeLU函数引入了正则思想, 越小的值越有可能被舍弃, 相当于线性修正单元函数(rectified linear units, ReLU)[16 ] 和随机舍弃的综合, 因为ReLU函数的值只有0和1, 所以单纯使用ReLU就缺乏这样的随机性。
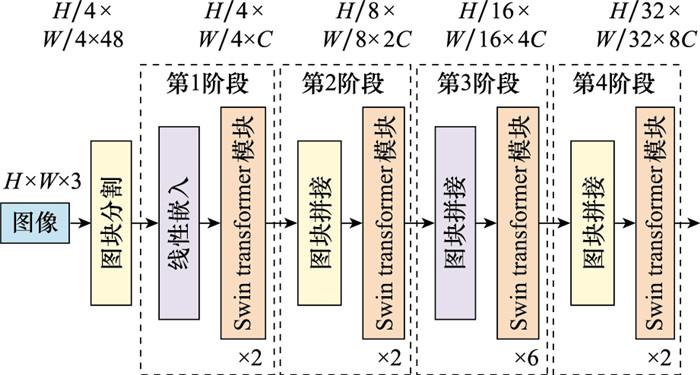
图1
Swin Transformer网络结构
Fig.1
Architecture of Swin Transformer net
图2
Swin Transformer模块结构
Fig.2
Architecture of Swin Transformer blocks
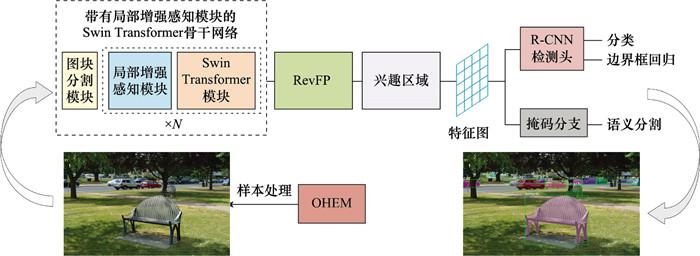
图3
算法框架
Fig.3
Algorithm framework
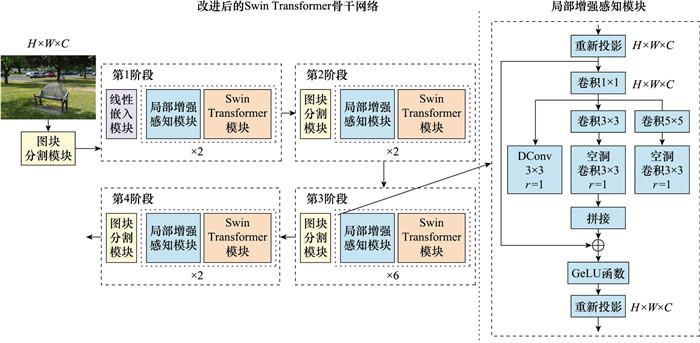
图4
带有LES模块的Swin Transformer骨干网络结构
Fig.4
Swin Transformer backbone network structure with LES block
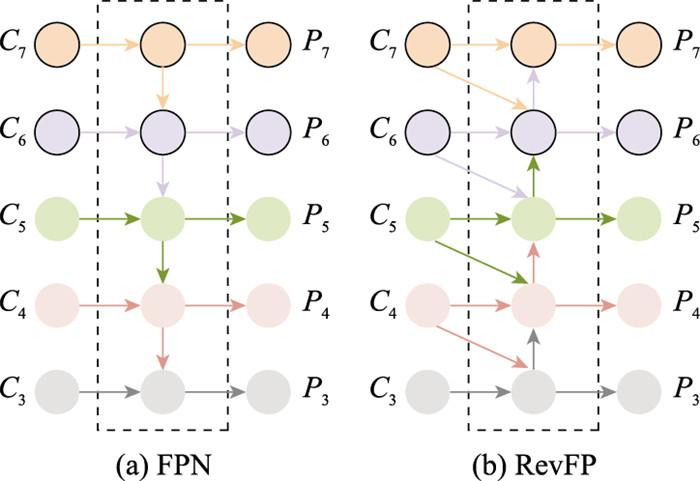
图5
FPN和RevFP特征融合网络结构
Fig.5
FPN and RevFP feature fusion network structure
图7
对比实验结果示例
Fig.7
Examples of comparative experimental results
[1]
苏丽 , 孙雨鑫 , 苑守正 . 基于深度学习的实例分割研究综述
[J]. 智能系统学报 , 2022 , 17 (1 ): 16 - 31 .
URL
[本文引用: 1]
SU L , SUN Y X , YUAN S Z . A survey of instance segmentation research based on deep learning
[J]. CAAI Trans.on Intelligent Systems , 2022 , 17 (1 ): 16 - 31 .
URL
[本文引用: 1]
[2]
HARIHARAN B, ARBELÁEZ P, GIRSHICK R, et al. Simultaneous detection and segmentation[C]//Proc. of the European Conference on Computer Vision, 2014: 297-312.
[本文引用: 1]
[3]
HE K M, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN[C]// Proc. of the IEEE International Conference on Computer Vision, 2017: 2980-2988.
[本文引用: 1]
[4]
HUANG Z J, HUANG L C, GONG Y C, et al. Mask scoring R-CNN[C]//Proc. of the Conference on Computer Vision and Pattern Recognition, 2019: 6402-6411.
[本文引用: 1]
[5]
CHENG T H, WANG X G, HUANG L C, et al. Boundary-preserving mask R-CNN[C]//Proc. of the European Conference on Computer Vision, 2020: 660-676.
[本文引用: 2]
[6]
LONG J , SHELHAMER E , DARRELL T . Fully convolutional networks for semantic segmentation
[J]. IEEE Trans.on Pattern Analysis and Machine Intelligence , 2015 , 39 (4 ): 640 - 651 .
[本文引用: 2]
[7]
BOLYA D, ZHOU C, XIAO F Y, et al. YOLACT: real-time instance segmentation[C]//Proc. of the IEEE/CVF International Conference on computer Vision, 2019.
[本文引用: 1]
[8]
BOLYA D , ZHOU C , XIAO F Y , et al . YOLACT++: better real-time instance segmentation
[J]. IEEE Trans.on Pattern Analysis and Machine Intelligence , 2022 , 44 (2 ): 1108 - 1121 .
DOI:10.1109/TPAMI.2020.3014297
[本文引用: 2]
[9]
ASHISH V, NOAM S, NIKI P, et al. Attention is all you need[EB/OL]. [2022-05-09]. https://arxiv.org/abs/1706.03762v5 .
[本文引用: 1]
[10]
HU J, CAO L J, LU Y, et al. ISTR: end-to-end instance segmentation with Transformers[EB/OL]. [2022-05-09]. https://arxiv.org/abs/2011.14503v4 .
[本文引用: 1]
[11]
GUO R H, NIU D T, QU L, et al. SOTR: segmenting objects with Transformers[C]//Proc. of the Conference on Computer Vision and Pattern Recognition, 2021: 7157-7166.
[本文引用: 1]
[12]
LIU Z, LIN Y T, CAO Y, et al. Swin Transformer: hierarchical vision Transformer using shifted windows[C]//Proc. of the International Conference on Computer Vision, 2021: 10012-10022.
[本文引用: 1]
[13]
霍熠阳, 于涛, 高飞. 基于CenterMask的SAR舰船实例分割[C]// 第十三届全国DSP应用技术学术会议论文集, 2021: 150-155.
[本文引用: 1]
HUO Y Y, YU T, GAO F. SAR ship instance segmentation based on CenterMask[C]//Proc. of the 13th National Confe-rence on DSP Application Technology, 2021: 150-155.
[本文引用: 1]
[14]
ZAREMBA W, SUTSKEVER I, VINYALS O. Recurrent neural network regularization[EB/OL]. [2022-05-09]. https://arxiv.org/abs/1409.2329 .
[本文引用: 1]
[15]
HENDRYCKS D, GIMPEL K. Gaussian error linear units (GELUs)[EB/OL]. [2022-05-09]. https://arxiv.org/abs/1606.08415v4 .
[本文引用: 1]
[16]
GLOROT X, BORDES A, BENGIO Y. Deep sparse rectifier neural networks[C]//Proc. of the 14th International Confe-rence on Artificial Intelligence and Statistics, 2011: 315-323.
[本文引用: 1]
[17]
ZONG Z F, CAO Q G, LENG B. RCNet: reverse feature pyramid and cross-scale shift network for object detection[C]// Proc. of the 29th ACM International Conference on Multimedia, 2021: 5637-5645.
[本文引用: 2]
[18]
SHRIVASTAVA A, GUPTA A, GIRSHICK R. Training region- based object detectors with online hard example mining[C]// Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2016: 761-769.
[本文引用: 1]
[19]
CHEN L C, PAPANDREOU G, KOKKINOS I, et al. Semantic image segmentation with deep convolutional nets and fully connected CRFs[C]//Proc. of the Internation Conference on Learming Representation, 2015.
[本文引用: 1]
[20]
CHEN L C , PAPANDREOU G , KOKKINOS I , et al . DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs
[J]. IEEE Trans.on Pattern Analysis and Machine Intelligence , 2018 , 40 (4 ): 834 - 848 .
DOI:10.1109/TPAMI.2017.2699184
[21]
CHEN L C, PAPANDREOU G, SCHROFF F, et al. Rethinking atrous convolution for semantic image segmentation[EB/OL]. [2022-05-09]. https://arxiv.org/abs/1706.05587v3
[22]
CHEN L C, ZHU Y, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]//Proc. of the European Conference on Computer Vision, 2018: 801-818.
[本文引用: 1]
[23]
YU F, KOLTUN V. Multi-scale context aggregation by dilated convolutions[EB/OL]. [2022-05-09]. https://arxiv.org/abs/1511.07122 .
[本文引用: 1]
[24]
李晨瑄 , 钱坤 , 胥辉旗 . 基于深浅层特征融合的舰船要害关键点检测算法
[J]. 系统工程与电子技术 , 2021 , 43 (11 ): 3239 - 3249 .
URL
[本文引用: 1]
LI C X , QIAN K , XU H Q . Key-points detection algorithm based on fusion of deep and shallow features for warship's vital part
[J]. Systems Engineering and Electronics , 2021 , 43 (11 ): 3239 - 3249 .
URL
[本文引用: 1]
[25]
LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 936-944.
[本文引用: 1]
[26]
LIU S, QI L, QIN H, et al. Path aggregation network for instance segmentation[C]//Proc. of the Conference on Computer Vision and Pattern Recognition, 2018: 8759-8768.
[本文引用: 1]
[27]
TAN M, PANG R, LE Q V. EfficientDet: scalable and efficient object detection[C]//Proc. of the Conference on Computer Vision and Pattern Recognition, 2020: 10778-10787.
[本文引用: 1]
[28]
钱坤 , 李晨瑄 , 陈美杉 , 等 . 基于YOLOv5的舰船目标及关键部位检测算法
[J]. 系统工程与电子技术 , 2022 , 44 (6 ): 1823 - 1832 .
URL
[本文引用: 1]
QIAN K , LI C X , CHEN M S , et al . Ship target and key parts detection algorithm based on YOLOv5
[J]. Systems Engineering and Electronics , 2022 , 44 (6 ): 1823 - 1832 .
URL
[本文引用: 1]
[29]
LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context[C]//Proc. of the European Confe-rence on Computer Vision, 2014: 740-755.
[本文引用: 1]
[30]
CAI Z W, VASCONCELOS N. Cascade R-CNN: delving into high quality object detection[C]//Proc. of the Conference on Computer Vision and Pattern Recognition, 2018: 6154-6162.
[本文引用: 1]
基于深度学习的实例分割研究综述
1
2022
... 近年来, 随着计算机图形算力的爆发式增长和人工智能算法的长足进步, 计算机视觉领域进入了新的技术时代, 图像分割作为计算机视觉的重要分支, 是根据一定的规则将图像中的像素分成不同的部分, 并添加相应标签, 可以视为是图像分类识别向像素级的延伸, 而其中的实例分割兼具了目标检测和语义分割的双重任务, 在实现上更具挑战意义和实用价值.目前, 实例分割已经广泛应用于汽车自动驾驶、智能辅助医疗和遥感影像判读等民用领域.在军事应用上, 实例分割也是精确制导、侦察监视等研究领域的核心问题, 对于推进军事现代化和信息化有着重要意义[1 ] . ...
A survey of instance segmentation research based on deep learning
1
2022
... 近年来, 随着计算机图形算力的爆发式增长和人工智能算法的长足进步, 计算机视觉领域进入了新的技术时代, 图像分割作为计算机视觉的重要分支, 是根据一定的规则将图像中的像素分成不同的部分, 并添加相应标签, 可以视为是图像分类识别向像素级的延伸, 而其中的实例分割兼具了目标检测和语义分割的双重任务, 在实现上更具挑战意义和实用价值.目前, 实例分割已经广泛应用于汽车自动驾驶、智能辅助医疗和遥感影像判读等民用领域.在军事应用上, 实例分割也是精确制导、侦察监视等研究领域的核心问题, 对于推进军事现代化和信息化有着重要意义[1 ] . ...
1
... 早期的实例分割受益于目标检测相关研究成果的延伸, Hariharan等首次使用同时检测和分割算法[2 ] 通过生成建议框、特征提取、区域分类与改良等步骤同时完成了检测和分割操作.He等人提出的掩模区域卷积神经网络(mask region-convolutional neural network, Mask R-CNN)[3 ] 是一种功能强大的基线算法, 通过添加预测兴趣区域的语义分割分支能够高效地完成实例分割任务, 也引领了后续一系列改进算法的产生, 如掩模评分区域卷积神经网络(mask scoring R-CNN, MS R-CNN)[4 ] 、边界保持Mask R-CNN(boundary-preserving Mask R-CNN, BMask R-CNN)[5 ] 等.Long等人提出的全卷积网络(fully convolutional networks, FCN)[6 ] 是一种端到端的图像分割方法, 通过使用全卷积网络、反卷积层和跳跃连接实现了图像分割, 成为该领域的代表性算法.为进一步提升FCN算法的精度, Bolya等人提出了只看系数算法(you only look at coefficients, YOLACT)[7 ] , 该算法通过两个并行的子网络来实现实例分割, 一个用来得到类似FCN的分割原型图, 另一个用来得到检测框, 然后融合原型图和检测框后得到掩码, 其在处理速度上实现了突破, 成为首个能够完成实时实例分割的算法, 随后的YOLACT++算法[8 ] 继续优化了算法结构和执行效率, 进一步提升了算法速度和精度. ...
1
... 早期的实例分割受益于目标检测相关研究成果的延伸, Hariharan等首次使用同时检测和分割算法[2 ] 通过生成建议框、特征提取、区域分类与改良等步骤同时完成了检测和分割操作.He等人提出的掩模区域卷积神经网络(mask region-convolutional neural network, Mask R-CNN)[3 ] 是一种功能强大的基线算法, 通过添加预测兴趣区域的语义分割分支能够高效地完成实例分割任务, 也引领了后续一系列改进算法的产生, 如掩模评分区域卷积神经网络(mask scoring R-CNN, MS R-CNN)[4 ] 、边界保持Mask R-CNN(boundary-preserving Mask R-CNN, BMask R-CNN)[5 ] 等.Long等人提出的全卷积网络(fully convolutional networks, FCN)[6 ] 是一种端到端的图像分割方法, 通过使用全卷积网络、反卷积层和跳跃连接实现了图像分割, 成为该领域的代表性算法.为进一步提升FCN算法的精度, Bolya等人提出了只看系数算法(you only look at coefficients, YOLACT)[7 ] , 该算法通过两个并行的子网络来实现实例分割, 一个用来得到类似FCN的分割原型图, 另一个用来得到检测框, 然后融合原型图和检测框后得到掩码, 其在处理速度上实现了突破, 成为首个能够完成实时实例分割的算法, 随后的YOLACT++算法[8 ] 继续优化了算法结构和执行效率, 进一步提升了算法速度和精度. ...
1
... 早期的实例分割受益于目标检测相关研究成果的延伸, Hariharan等首次使用同时检测和分割算法[2 ] 通过生成建议框、特征提取、区域分类与改良等步骤同时完成了检测和分割操作.He等人提出的掩模区域卷积神经网络(mask region-convolutional neural network, Mask R-CNN)[3 ] 是一种功能强大的基线算法, 通过添加预测兴趣区域的语义分割分支能够高效地完成实例分割任务, 也引领了后续一系列改进算法的产生, 如掩模评分区域卷积神经网络(mask scoring R-CNN, MS R-CNN)[4 ] 、边界保持Mask R-CNN(boundary-preserving Mask R-CNN, BMask R-CNN)[5 ] 等.Long等人提出的全卷积网络(fully convolutional networks, FCN)[6 ] 是一种端到端的图像分割方法, 通过使用全卷积网络、反卷积层和跳跃连接实现了图像分割, 成为该领域的代表性算法.为进一步提升FCN算法的精度, Bolya等人提出了只看系数算法(you only look at coefficients, YOLACT)[7 ] , 该算法通过两个并行的子网络来实现实例分割, 一个用来得到类似FCN的分割原型图, 另一个用来得到检测框, 然后融合原型图和检测框后得到掩码, 其在处理速度上实现了突破, 成为首个能够完成实时实例分割的算法, 随后的YOLACT++算法[8 ] 继续优化了算法结构和执行效率, 进一步提升了算法速度和精度. ...
2
... 早期的实例分割受益于目标检测相关研究成果的延伸, Hariharan等首次使用同时检测和分割算法[2 ] 通过生成建议框、特征提取、区域分类与改良等步骤同时完成了检测和分割操作.He等人提出的掩模区域卷积神经网络(mask region-convolutional neural network, Mask R-CNN)[3 ] 是一种功能强大的基线算法, 通过添加预测兴趣区域的语义分割分支能够高效地完成实例分割任务, 也引领了后续一系列改进算法的产生, 如掩模评分区域卷积神经网络(mask scoring R-CNN, MS R-CNN)[4 ] 、边界保持Mask R-CNN(boundary-preserving Mask R-CNN, BMask R-CNN)[5 ] 等.Long等人提出的全卷积网络(fully convolutional networks, FCN)[6 ] 是一种端到端的图像分割方法, 通过使用全卷积网络、反卷积层和跳跃连接实现了图像分割, 成为该领域的代表性算法.为进一步提升FCN算法的精度, Bolya等人提出了只看系数算法(you only look at coefficients, YOLACT)[7 ] , 该算法通过两个并行的子网络来实现实例分割, 一个用来得到类似FCN的分割原型图, 另一个用来得到检测框, 然后融合原型图和检测框后得到掩码, 其在处理速度上实现了突破, 成为首个能够完成实时实例分割的算法, 随后的YOLACT++算法[8 ] 继续优化了算法结构和执行效率, 进一步提升了算法速度和精度. ...
... Algorithm comparison results
Table 4 算法 主干网络 mAPsegm /% AP50 segm /% AP75 segm /% 参数量/MB FPS FCN[6 ] VGG16 62.2 79.5 69.2 134 13.3 Mask R-CNN[5 ] ResNet-50 69.4 89.6 77.9 110 15.0 Cascade Mask R-CNN[30 ] ResNet-50 68.7 89.4 76.3 82 18.0 YOLACT++[8 ] ResNet-50 66.3 82.3 74.6 129 32.6 基线算法 Swin-Ting 73.9 90.8 87.5 86 15.3 本文算法 改进Swin-Ting 75.4 91.3 89.4 89 15.5
实验将使用原始Swin-Ting作为骨干网络, 用FPN进行特征融合, 不采用在线困难样例挖掘方法辅助训练的算法作为基线算法.实验结果表明, 本文算法对比基线算法, 在不显著增加模型大小的情况下, 分割精度获得了有效提升, 其中在mAPsegm , AP50 segm 和AP75 segm 等指标上分别提高1.5%, 0.5%和1.9%, 证明了对网络的改进能够进一步提升Swin Transformer的实际性能.对比以ResNet-50为骨干网络的3种算法, 在mAP, AP50 和AP75 等指标上至少提升了6.0%, 1.7%和11.5%, 凸显出Swin Transformer网络的优越性; 相较以VGG16为骨干网络的FCN算法优势更为明显.在处理速度上, YOLACT++表现依旧强势, 是唯一能够达到实时实例分割的算法, 而其他算法在图像处理速度上的整体差距不大, 本文算法得益于RevFP融合网络低延迟的特性, 对比以原Swin-Ting为骨干网络的Mask R-CNN算法, 在FPS指标上小幅提升了1.3%. ...
Fully convolutional networks for semantic segmentation
2
2015
... 早期的实例分割受益于目标检测相关研究成果的延伸, Hariharan等首次使用同时检测和分割算法[2 ] 通过生成建议框、特征提取、区域分类与改良等步骤同时完成了检测和分割操作.He等人提出的掩模区域卷积神经网络(mask region-convolutional neural network, Mask R-CNN)[3 ] 是一种功能强大的基线算法, 通过添加预测兴趣区域的语义分割分支能够高效地完成实例分割任务, 也引领了后续一系列改进算法的产生, 如掩模评分区域卷积神经网络(mask scoring R-CNN, MS R-CNN)[4 ] 、边界保持Mask R-CNN(boundary-preserving Mask R-CNN, BMask R-CNN)[5 ] 等.Long等人提出的全卷积网络(fully convolutional networks, FCN)[6 ] 是一种端到端的图像分割方法, 通过使用全卷积网络、反卷积层和跳跃连接实现了图像分割, 成为该领域的代表性算法.为进一步提升FCN算法的精度, Bolya等人提出了只看系数算法(you only look at coefficients, YOLACT)[7 ] , 该算法通过两个并行的子网络来实现实例分割, 一个用来得到类似FCN的分割原型图, 另一个用来得到检测框, 然后融合原型图和检测框后得到掩码, 其在处理速度上实现了突破, 成为首个能够完成实时实例分割的算法, 随后的YOLACT++算法[8 ] 继续优化了算法结构和执行效率, 进一步提升了算法速度和精度. ...
... Algorithm comparison results
Table 4 算法 主干网络 mAPsegm /% AP50 segm /% AP75 segm /% 参数量/MB FPS FCN[6 ] VGG16 62.2 79.5 69.2 134 13.3 Mask R-CNN[5 ] ResNet-50 69.4 89.6 77.9 110 15.0 Cascade Mask R-CNN[30 ] ResNet-50 68.7 89.4 76.3 82 18.0 YOLACT++[8 ] ResNet-50 66.3 82.3 74.6 129 32.6 基线算法 Swin-Ting 73.9 90.8 87.5 86 15.3 本文算法 改进Swin-Ting 75.4 91.3 89.4 89 15.5
实验将使用原始Swin-Ting作为骨干网络, 用FPN进行特征融合, 不采用在线困难样例挖掘方法辅助训练的算法作为基线算法.实验结果表明, 本文算法对比基线算法, 在不显著增加模型大小的情况下, 分割精度获得了有效提升, 其中在mAPsegm , AP50 segm 和AP75 segm 等指标上分别提高1.5%, 0.5%和1.9%, 证明了对网络的改进能够进一步提升Swin Transformer的实际性能.对比以ResNet-50为骨干网络的3种算法, 在mAP, AP50 和AP75 等指标上至少提升了6.0%, 1.7%和11.5%, 凸显出Swin Transformer网络的优越性; 相较以VGG16为骨干网络的FCN算法优势更为明显.在处理速度上, YOLACT++表现依旧强势, 是唯一能够达到实时实例分割的算法, 而其他算法在图像处理速度上的整体差距不大, 本文算法得益于RevFP融合网络低延迟的特性, 对比以原Swin-Ting为骨干网络的Mask R-CNN算法, 在FPS指标上小幅提升了1.3%. ...
1
... 早期的实例分割受益于目标检测相关研究成果的延伸, Hariharan等首次使用同时检测和分割算法[2 ] 通过生成建议框、特征提取、区域分类与改良等步骤同时完成了检测和分割操作.He等人提出的掩模区域卷积神经网络(mask region-convolutional neural network, Mask R-CNN)[3 ] 是一种功能强大的基线算法, 通过添加预测兴趣区域的语义分割分支能够高效地完成实例分割任务, 也引领了后续一系列改进算法的产生, 如掩模评分区域卷积神经网络(mask scoring R-CNN, MS R-CNN)[4 ] 、边界保持Mask R-CNN(boundary-preserving Mask R-CNN, BMask R-CNN)[5 ] 等.Long等人提出的全卷积网络(fully convolutional networks, FCN)[6 ] 是一种端到端的图像分割方法, 通过使用全卷积网络、反卷积层和跳跃连接实现了图像分割, 成为该领域的代表性算法.为进一步提升FCN算法的精度, Bolya等人提出了只看系数算法(you only look at coefficients, YOLACT)[7 ] , 该算法通过两个并行的子网络来实现实例分割, 一个用来得到类似FCN的分割原型图, 另一个用来得到检测框, 然后融合原型图和检测框后得到掩码, 其在处理速度上实现了突破, 成为首个能够完成实时实例分割的算法, 随后的YOLACT++算法[8 ] 继续优化了算法结构和执行效率, 进一步提升了算法速度和精度. ...
YOLACT++: better real-time instance segmentation
2
2022
... 早期的实例分割受益于目标检测相关研究成果的延伸, Hariharan等首次使用同时检测和分割算法[2 ] 通过生成建议框、特征提取、区域分类与改良等步骤同时完成了检测和分割操作.He等人提出的掩模区域卷积神经网络(mask region-convolutional neural network, Mask R-CNN)[3 ] 是一种功能强大的基线算法, 通过添加预测兴趣区域的语义分割分支能够高效地完成实例分割任务, 也引领了后续一系列改进算法的产生, 如掩模评分区域卷积神经网络(mask scoring R-CNN, MS R-CNN)[4 ] 、边界保持Mask R-CNN(boundary-preserving Mask R-CNN, BMask R-CNN)[5 ] 等.Long等人提出的全卷积网络(fully convolutional networks, FCN)[6 ] 是一种端到端的图像分割方法, 通过使用全卷积网络、反卷积层和跳跃连接实现了图像分割, 成为该领域的代表性算法.为进一步提升FCN算法的精度, Bolya等人提出了只看系数算法(you only look at coefficients, YOLACT)[7 ] , 该算法通过两个并行的子网络来实现实例分割, 一个用来得到类似FCN的分割原型图, 另一个用来得到检测框, 然后融合原型图和检测框后得到掩码, 其在处理速度上实现了突破, 成为首个能够完成实时实例分割的算法, 随后的YOLACT++算法[8 ] 继续优化了算法结构和执行效率, 进一步提升了算法速度和精度. ...
... Algorithm comparison results
Table 4 算法 主干网络 mAPsegm /% AP50 segm /% AP75 segm /% 参数量/MB FPS FCN[6 ] VGG16 62.2 79.5 69.2 134 13.3 Mask R-CNN[5 ] ResNet-50 69.4 89.6 77.9 110 15.0 Cascade Mask R-CNN[30 ] ResNet-50 68.7 89.4 76.3 82 18.0 YOLACT++[8 ] ResNet-50 66.3 82.3 74.6 129 32.6 基线算法 Swin-Ting 73.9 90.8 87.5 86 15.3 本文算法 改进Swin-Ting 75.4 91.3 89.4 89 15.5
实验将使用原始Swin-Ting作为骨干网络, 用FPN进行特征融合, 不采用在线困难样例挖掘方法辅助训练的算法作为基线算法.实验结果表明, 本文算法对比基线算法, 在不显著增加模型大小的情况下, 分割精度获得了有效提升, 其中在mAPsegm , AP50 segm 和AP75 segm 等指标上分别提高1.5%, 0.5%和1.9%, 证明了对网络的改进能够进一步提升Swin Transformer的实际性能.对比以ResNet-50为骨干网络的3种算法, 在mAP, AP50 和AP75 等指标上至少提升了6.0%, 1.7%和11.5%, 凸显出Swin Transformer网络的优越性; 相较以VGG16为骨干网络的FCN算法优势更为明显.在处理速度上, YOLACT++表现依旧强势, 是唯一能够达到实时实例分割的算法, 而其他算法在图像处理速度上的整体差距不大, 本文算法得益于RevFP融合网络低延迟的特性, 对比以原Swin-Ting为骨干网络的Mask R-CNN算法, 在FPS指标上小幅提升了1.3%. ...
1
... 近两年来, 发轫于自然语言处理(natural language processing, NLP)的Transformer[9 ] 模型在计算视觉领域大放异彩, 在实例分割研究中相较传统CNN展现出了极强的竞争力.基于Transformer的实例分割算法[10 ] 是首个基于Transformer的实例分割框架, 通过使用循环细化策略进行检测和分割, 为实例分割提供了新角度.随后的基于Transformer的图像分割算法[11 ] , 使用Transformer预测每个实例类别, 并动态生成具有多个分割的掩码级上采样模块, 该算法与原始Transformer相比在运算速度和资源开销上更具优势.基于滑动窗口的Transformer(shifted windows Transformer, Swin Transformer)[12 ] 实例分割算法, 使用滑动窗口策略和层级化设计, 其将注意力计算限制在一个窗口中, 旨在引入与CNN卷积类似的局部性操作, 并显著降低计算量, 进一步提高了实例分割的速度和精度.随着对Swin Transformer模型研究的不断深入, 如何在保持较低运算开销条件下尽量充分地实现上下文信息的交互, 如何理解算法中自注意力机制的作用方式以及如何对其他模块进行优化等问题的提出, 为进一步提升Swin Transformer模型性能提供了可能的方向. ...
1
... 近两年来, 发轫于自然语言处理(natural language processing, NLP)的Transformer[9 ] 模型在计算视觉领域大放异彩, 在实例分割研究中相较传统CNN展现出了极强的竞争力.基于Transformer的实例分割算法[10 ] 是首个基于Transformer的实例分割框架, 通过使用循环细化策略进行检测和分割, 为实例分割提供了新角度.随后的基于Transformer的图像分割算法[11 ] , 使用Transformer预测每个实例类别, 并动态生成具有多个分割的掩码级上采样模块, 该算法与原始Transformer相比在运算速度和资源开销上更具优势.基于滑动窗口的Transformer(shifted windows Transformer, Swin Transformer)[12 ] 实例分割算法, 使用滑动窗口策略和层级化设计, 其将注意力计算限制在一个窗口中, 旨在引入与CNN卷积类似的局部性操作, 并显著降低计算量, 进一步提高了实例分割的速度和精度.随着对Swin Transformer模型研究的不断深入, 如何在保持较低运算开销条件下尽量充分地实现上下文信息的交互, 如何理解算法中自注意力机制的作用方式以及如何对其他模块进行优化等问题的提出, 为进一步提升Swin Transformer模型性能提供了可能的方向. ...
1
... 近两年来, 发轫于自然语言处理(natural language processing, NLP)的Transformer[9 ] 模型在计算视觉领域大放异彩, 在实例分割研究中相较传统CNN展现出了极强的竞争力.基于Transformer的实例分割算法[10 ] 是首个基于Transformer的实例分割框架, 通过使用循环细化策略进行检测和分割, 为实例分割提供了新角度.随后的基于Transformer的图像分割算法[11 ] , 使用Transformer预测每个实例类别, 并动态生成具有多个分割的掩码级上采样模块, 该算法与原始Transformer相比在运算速度和资源开销上更具优势.基于滑动窗口的Transformer(shifted windows Transformer, Swin Transformer)[12 ] 实例分割算法, 使用滑动窗口策略和层级化设计, 其将注意力计算限制在一个窗口中, 旨在引入与CNN卷积类似的局部性操作, 并显著降低计算量, 进一步提高了实例分割的速度和精度.随着对Swin Transformer模型研究的不断深入, 如何在保持较低运算开销条件下尽量充分地实现上下文信息的交互, 如何理解算法中自注意力机制的作用方式以及如何对其他模块进行优化等问题的提出, 为进一步提升Swin Transformer模型性能提供了可能的方向. ...
1
... 近两年来, 发轫于自然语言处理(natural language processing, NLP)的Transformer[9 ] 模型在计算视觉领域大放异彩, 在实例分割研究中相较传统CNN展现出了极强的竞争力.基于Transformer的实例分割算法[10 ] 是首个基于Transformer的实例分割框架, 通过使用循环细化策略进行检测和分割, 为实例分割提供了新角度.随后的基于Transformer的图像分割算法[11 ] , 使用Transformer预测每个实例类别, 并动态生成具有多个分割的掩码级上采样模块, 该算法与原始Transformer相比在运算速度和资源开销上更具优势.基于滑动窗口的Transformer(shifted windows Transformer, Swin Transformer)[12 ] 实例分割算法, 使用滑动窗口策略和层级化设计, 其将注意力计算限制在一个窗口中, 旨在引入与CNN卷积类似的局部性操作, 并显著降低计算量, 进一步提高了实例分割的速度和精度.随着对Swin Transformer模型研究的不断深入, 如何在保持较低运算开销条件下尽量充分地实现上下文信息的交互, 如何理解算法中自注意力机制的作用方式以及如何对其他模块进行优化等问题的提出, 为进一步提升Swin Transformer模型性能提供了可能的方向. ...
1
... 海战场舰船目标精确识别与分割是反舰导弹末段图像制导的核心问题, 对于舰船目标的检测识别算法很多, 但细化至像素级的实例分割研究相对较少, 已有研究也多是针对合成孔径雷达(synthetic aperture radar, SAR)图像进行实例分割[13 ] , 而SAR图像多为高空俯视视角, 从俯视视角得到的舰船轮廓相对单一, 对于数据集的准备和训练也相对容易.目前, 现役主战反舰导弹为保证隐蔽突防的成功率, 多采用低飞掠海攻击模式, 从舰船侧视角接近目标时, 舰船目标的尺度和角度变化更加剧烈, 因此对于算法的要求也更高.为进一步提升海战场目标检测能力, 实现精确化打击, 对于将一般的目标检测识别延伸细化至像素级精度的实例分割, 有着很强的实战意义. ...
1
... 海战场舰船目标精确识别与分割是反舰导弹末段图像制导的核心问题, 对于舰船目标的检测识别算法很多, 但细化至像素级的实例分割研究相对较少, 已有研究也多是针对合成孔径雷达(synthetic aperture radar, SAR)图像进行实例分割[13 ] , 而SAR图像多为高空俯视视角, 从俯视视角得到的舰船轮廓相对单一, 对于数据集的准备和训练也相对容易.目前, 现役主战反舰导弹为保证隐蔽突防的成功率, 多采用低飞掠海攻击模式, 从舰船侧视角接近目标时, 舰船目标的尺度和角度变化更加剧烈, 因此对于算法的要求也更高.为进一步提升海战场目标检测能力, 实现精确化打击, 对于将一般的目标检测识别延伸细化至像素级精度的实例分割, 有着很强的实战意义. ...
1
... Transformer模型最先在NLP任务中被广泛应用, 在NLP任务中需要编码器抽取很多特征.其中, 首先需要考虑的就是每个词的上下文语义, 因为每个词的具体含义都跟上下文强相关, 而上下文又分为方向和距离两个属性, 传统的循环神经网络(recurrent neural network, RNN)[14 ] 只能对句子进行单向编码, CNN只能对短句进行编码, 而Transformer既可以同时编码双向语义, 又能够抽取长距离特征, 所以在上下文语义抽取方面要优于RNN和CNN.NLP任务需要抽取的第二种特征是序列的顺序, 在这方面Transformer的表现一般介于RNN和CNN之间.NLP任务对计算速度是比较敏感的, 由于RNN无法并行处理序列信息, 因此表现最差, CNN和Transformer都可以进行并行计算, 但Transformer模型结构稍显复杂, 所以在速度方面稍逊CNN.综上, 由于Transformer在效果和速度方面性能表现均衡, 所以在NLP任务中很快便脱颖而出, 之后随着研究的深入, Transformer被引入其他任务中, 均有不俗表现, 已隐隐呈现出成为高效的通用计算架构的趋势. ...
1
... Transformer模型是一种典型的编码器-解码器结构, 其中最为重要是多头自注意力(multi-head self-attention, MSA), 残差连接和归一化(add & layer normalization, Add & LN)以及前馈网络3个模块.MSA负责将输入投影到不同空间, 得到Q K V Q V [15 ] 作为激活函数, 因为GeLU函数引入了正则思想, 越小的值越有可能被舍弃, 相当于线性修正单元函数(rectified linear units, ReLU)[16 ] 和随机舍弃的综合, 因为ReLU函数的值只有0和1, 所以单纯使用ReLU就缺乏这样的随机性. ...
1
... Transformer模型是一种典型的编码器-解码器结构, 其中最为重要是多头自注意力(multi-head self-attention, MSA), 残差连接和归一化(add & layer normalization, Add & LN)以及前馈网络3个模块.MSA负责将输入投影到不同空间, 得到Q K V Q V [15 ] 作为激活函数, 因为GeLU函数引入了正则思想, 越小的值越有可能被舍弃, 相当于线性修正单元函数(rectified linear units, ReLU)[16 ] 和随机舍弃的综合, 因为ReLU函数的值只有0和1, 所以单纯使用ReLU就缺乏这样的随机性. ...
2
... 本算法使用Swin Transformer作为骨干网络, 完成特征提取工作, 图像进入图像分割模块后形成序列化小块, 并沿通道方向展平, 通过线性嵌入模块完成线性到非线性再到线性的3次变换; 在进入Swin Transformer块前, 先通过局部增强感知(local enhanced sensing, LES)模块, 旨在进一步抑制无效特征, 增强有效参数, 提高上下文信息之间的交互; 在特征融合阶段使用RevFP网络[17 ] , 在采用局部融合操作的同时, 集成高级与低级特征, 获得更好的融合效果和更低的延迟; 在网络的训练阶段, 使用在线困难样例挖掘(online hard example mining, OHEM)[18 ] 方法, 解决自制数据集难易样本不均衡, 训练效果不理想的问题, 通过设置负样本池反复迭代, 使算法在小样本数据集上获得更好的效果; 最后使用基于Mask R-CNN的检测头, 完成实例分割任务.算法整体框架如图 3 所示. ...
... 在特征融合阶段, 特征金字塔网络[25 ] (feature pyramid networks, FPN)是目前最为常用的选择, 其结构如图 5(a) 所示.后续相关研究提出了多种不同的架构, 如路径聚合网络(path-aggregation network, PANet)[26 ] , 双向FPN(bi-directional FPN, BiFPN)[27 ] 等, 这些方法使用了不同形式的双向特征融合.相关实验表明, 以上改进结构均能有效改善网络性能, 已在目标检测、实例分割领域得到了广泛应用, 但这些网络通常是以固定顺序堆叠特征金字塔, 更长的信息链路, 会降低推理速度.此外, 由于FPN中仅在近邻层级特征进行了局部融合, 这就导致非相邻特征的语义信息会被稀释.文献[17 ]提出了RevFP网络, 这是一种利用局部双向特征融合的简化的双向金字塔推理架构, 相比于其他双向金字塔架构, RevFP具有更好的性能、更小巧的模型和更低的延迟, RevFP结构如图 5(b) 所示. ...
1
... 本算法使用Swin Transformer作为骨干网络, 完成特征提取工作, 图像进入图像分割模块后形成序列化小块, 并沿通道方向展平, 通过线性嵌入模块完成线性到非线性再到线性的3次变换; 在进入Swin Transformer块前, 先通过局部增强感知(local enhanced sensing, LES)模块, 旨在进一步抑制无效特征, 增强有效参数, 提高上下文信息之间的交互; 在特征融合阶段使用RevFP网络[17 ] , 在采用局部融合操作的同时, 集成高级与低级特征, 获得更好的融合效果和更低的延迟; 在网络的训练阶段, 使用在线困难样例挖掘(online hard example mining, OHEM)[18 ] 方法, 解决自制数据集难易样本不均衡, 训练效果不理想的问题, 通过设置负样本池反复迭代, 使算法在小样本数据集上获得更好的效果; 最后使用基于Mask R-CNN的检测头, 完成实例分割任务.算法整体框架如图 3 所示. ...
1
... 在卷积神经网络中, 卷积核大小决定了卷积感受野的尺寸, 而与之对应的是不同尺寸的感受野适合识别分割不同尺寸的目标, 由于反舰导弹在接近舰船目标过程中, 目标变化的过程具有多角度、多尺度特性, 所以设计能够融合多尺度的感受野对于提升识别和分割精度有着重要作用.受“深度实验室”系列算法[19 -22 ] 启发, 设计了包含3条并行支路的局部增强感知模块. ...
DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs
2018
1
... 在卷积神经网络中, 卷积核大小决定了卷积感受野的尺寸, 而与之对应的是不同尺寸的感受野适合识别分割不同尺寸的目标, 由于反舰导弹在接近舰船目标过程中, 目标变化的过程具有多角度、多尺度特性, 所以设计能够融合多尺度的感受野对于提升识别和分割精度有着重要作用.受“深度实验室”系列算法[19 -22 ] 启发, 设计了包含3条并行支路的局部增强感知模块. ...
1
... 在Swin Transformer中数据流由向量构成, 数据首先进行特征向量的重新投影, 形成多维空间特征映射, 然后通过并行的空洞卷积(dilated convolution, DConv)[23 ] 分支, 其中, 每个支路中核大小为1×1的普通卷积旨在降低通道数, 3条分支的空洞卷积扩张率分别为r =1, r =3和r =5, 根据空洞卷积卷积核计算公式K =(r -1)(k -1)+k .其中, K 为空洞卷积卷积核尺寸, r 为扩张率, k 为常规卷积卷积核尺寸, 由此分别获得3×3, 7×7和11×11大小的感受野, 利用DConv来增加感受野尺寸并不以牺牲特征分辨率为代价, 且可以在不同的尺度上对大范围的上下文信息进行良好编码, 使特征图获取更精确的语义与定位信息, 有效增强尺度、角度剧烈变化时的舰船目标识别分割的鲁棒性[24 ] . ...
基于深浅层特征融合的舰船要害关键点检测算法
1
2021
... 在Swin Transformer中数据流由向量构成, 数据首先进行特征向量的重新投影, 形成多维空间特征映射, 然后通过并行的空洞卷积(dilated convolution, DConv)[23 ] 分支, 其中, 每个支路中核大小为1×1的普通卷积旨在降低通道数, 3条分支的空洞卷积扩张率分别为r =1, r =3和r =5, 根据空洞卷积卷积核计算公式K =(r -1)(k -1)+k .其中, K 为空洞卷积卷积核尺寸, r 为扩张率, k 为常规卷积卷积核尺寸, 由此分别获得3×3, 7×7和11×11大小的感受野, 利用DConv来增加感受野尺寸并不以牺牲特征分辨率为代价, 且可以在不同的尺度上对大范围的上下文信息进行良好编码, 使特征图获取更精确的语义与定位信息, 有效增强尺度、角度剧烈变化时的舰船目标识别分割的鲁棒性[24 ] . ...
Key-points detection algorithm based on fusion of deep and shallow features for warship's vital part
1
2021
... 在Swin Transformer中数据流由向量构成, 数据首先进行特征向量的重新投影, 形成多维空间特征映射, 然后通过并行的空洞卷积(dilated convolution, DConv)[23 ] 分支, 其中, 每个支路中核大小为1×1的普通卷积旨在降低通道数, 3条分支的空洞卷积扩张率分别为r =1, r =3和r =5, 根据空洞卷积卷积核计算公式K =(r -1)(k -1)+k .其中, K 为空洞卷积卷积核尺寸, r 为扩张率, k 为常规卷积卷积核尺寸, 由此分别获得3×3, 7×7和11×11大小的感受野, 利用DConv来增加感受野尺寸并不以牺牲特征分辨率为代价, 且可以在不同的尺度上对大范围的上下文信息进行良好编码, 使特征图获取更精确的语义与定位信息, 有效增强尺度、角度剧烈变化时的舰船目标识别分割的鲁棒性[24 ] . ...
1
... 在特征融合阶段, 特征金字塔网络[25 ] (feature pyramid networks, FPN)是目前最为常用的选择, 其结构如图 5(a) 所示.后续相关研究提出了多种不同的架构, 如路径聚合网络(path-aggregation network, PANet)[26 ] , 双向FPN(bi-directional FPN, BiFPN)[27 ] 等, 这些方法使用了不同形式的双向特征融合.相关实验表明, 以上改进结构均能有效改善网络性能, 已在目标检测、实例分割领域得到了广泛应用, 但这些网络通常是以固定顺序堆叠特征金字塔, 更长的信息链路, 会降低推理速度.此外, 由于FPN中仅在近邻层级特征进行了局部融合, 这就导致非相邻特征的语义信息会被稀释.文献[17 ]提出了RevFP网络, 这是一种利用局部双向特征融合的简化的双向金字塔推理架构, 相比于其他双向金字塔架构, RevFP具有更好的性能、更小巧的模型和更低的延迟, RevFP结构如图 5(b) 所示. ...
1
... 在特征融合阶段, 特征金字塔网络[25 ] (feature pyramid networks, FPN)是目前最为常用的选择, 其结构如图 5(a) 所示.后续相关研究提出了多种不同的架构, 如路径聚合网络(path-aggregation network, PANet)[26 ] , 双向FPN(bi-directional FPN, BiFPN)[27 ] 等, 这些方法使用了不同形式的双向特征融合.相关实验表明, 以上改进结构均能有效改善网络性能, 已在目标检测、实例分割领域得到了广泛应用, 但这些网络通常是以固定顺序堆叠特征金字塔, 更长的信息链路, 会降低推理速度.此外, 由于FPN中仅在近邻层级特征进行了局部融合, 这就导致非相邻特征的语义信息会被稀释.文献[17 ]提出了RevFP网络, 这是一种利用局部双向特征融合的简化的双向金字塔推理架构, 相比于其他双向金字塔架构, RevFP具有更好的性能、更小巧的模型和更低的延迟, RevFP结构如图 5(b) 所示. ...
1
... 在特征融合阶段, 特征金字塔网络[25 ] (feature pyramid networks, FPN)是目前最为常用的选择, 其结构如图 5(a) 所示.后续相关研究提出了多种不同的架构, 如路径聚合网络(path-aggregation network, PANet)[26 ] , 双向FPN(bi-directional FPN, BiFPN)[27 ] 等, 这些方法使用了不同形式的双向特征融合.相关实验表明, 以上改进结构均能有效改善网络性能, 已在目标检测、实例分割领域得到了广泛应用, 但这些网络通常是以固定顺序堆叠特征金字塔, 更长的信息链路, 会降低推理速度.此外, 由于FPN中仅在近邻层级特征进行了局部融合, 这就导致非相邻特征的语义信息会被稀释.文献[17 ]提出了RevFP网络, 这是一种利用局部双向特征融合的简化的双向金字塔推理架构, 相比于其他双向金字塔架构, RevFP具有更好的性能、更小巧的模型和更低的延迟, RevFP结构如图 5(b) 所示. ...
基于YOLOv5的舰船目标及关键部位检测算法
1
2022
... 为模拟反舰武器掠海攻击模式末段图像制导呈现的影像, 选用文献[28 ]提出的基于水平或低视角的舰船目标数据集, 数据集共有1 554幅图像, 作战舰艇区分航空母舰和驱逐舰, 分别有636幅和741幅, 民用船只包含渔船、液化天然气船、集装箱船、快艇、帆船等类别, 共558幅, 由于网络支持多分辨率图像训练, 所以没有统一图像大小, 所有图像大小介于500×680至1 280×960之间. ...
Ship target and key parts detection algorithm based on YOLOv5
1
2022
... 为模拟反舰武器掠海攻击模式末段图像制导呈现的影像, 选用文献[28 ]提出的基于水平或低视角的舰船目标数据集, 数据集共有1 554幅图像, 作战舰艇区分航空母舰和驱逐舰, 分别有636幅和741幅, 民用船只包含渔船、液化天然气船、集装箱船、快艇、帆船等类别, 共558幅, 由于网络支持多分辨率图像训练, 所以没有统一图像大小, 所有图像大小介于500×680至1 280×960之间. ...
1
... 经统计, 共标注1 052幅图像, 每图像平均标注1.23个目标.标注使用开源工具labelme, 并将标注后生成的.json格式的文件使用脚本转换成微软通用目标语义(Microsoft common objects in context, MS COCO)数据集[29 ] 标准格式, 并按照MS COCO数据集的目录构成要求进行文件的组织和保存.另外, 在训练前还需要将标注好的数据集按照8 ∶1 ∶1的比例随机划分为训练集、测试集和验证集, 3个子集的数量分别为842幅、106幅和104幅.具体标注情况如表 1 所示. ...
1
... Algorithm comparison results
Table 4 算法 主干网络 mAPsegm /% AP50 segm /% AP75 segm /% 参数量/MB FPS FCN[6 ] VGG16 62.2 79.5 69.2 134 13.3 Mask R-CNN[5 ] ResNet-50 69.4 89.6 77.9 110 15.0 Cascade Mask R-CNN[30 ] ResNet-50 68.7 89.4 76.3 82 18.0 YOLACT++[8 ] ResNet-50 66.3 82.3 74.6 129 32.6 基线算法 Swin-Ting 73.9 90.8 87.5 86 15.3 本文算法 改进Swin-Ting 75.4 91.3 89.4 89 15.5
实验将使用原始Swin-Ting作为骨干网络, 用FPN进行特征融合, 不采用在线困难样例挖掘方法辅助训练的算法作为基线算法.实验结果表明, 本文算法对比基线算法, 在不显著增加模型大小的情况下, 分割精度获得了有效提升, 其中在mAPsegm , AP50 segm 和AP75 segm 等指标上分别提高1.5%, 0.5%和1.9%, 证明了对网络的改进能够进一步提升Swin Transformer的实际性能.对比以ResNet-50为骨干网络的3种算法, 在mAP, AP50 和AP75 等指标上至少提升了6.0%, 1.7%和11.5%, 凸显出Swin Transformer网络的优越性; 相较以VGG16为骨干网络的FCN算法优势更为明显.在处理速度上, YOLACT++表现依旧强势, 是唯一能够达到实时实例分割的算法, 而其他算法在图像处理速度上的整体差距不大, 本文算法得益于RevFP融合网络低延迟的特性, 对比以原Swin-Ting为骨干网络的Mask R-CNN算法, 在FPS指标上小幅提升了1.3%. ...






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}