Systems Engineering and Electronics ›› 2024, Vol. 46 ›› Issue (4): 1174-1184.doi: 10.12305/j.issn.1001-506X.2024.04.05
• Electronic Technology • Previous Articles Next Articles
Multi-teacher joint knowledge distillation based on CenterNet
Shaohua LIU, Kang DU, Chundong SHE, Ao YANG
- School of Electronic Engineering, Beijing University of Posts and Telecommunications, Beijing 100080, China
-
Received:2022-12-05Online:2024-03-25Published:2024-03-25 -
Contact:Chundong SHE
CLC Number:
Cite this article
Shaohua LIU, Kang DU, Chundong SHE, Ao YANG. Multi-teacher joint knowledge distillation based on CenterNet[J]. Systems Engineering and Electronics, 2024, 46(4): 1174-1184.
share this article
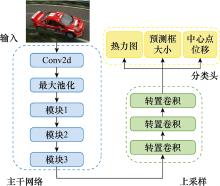
Fig.1
Structure of standard CenterNet"
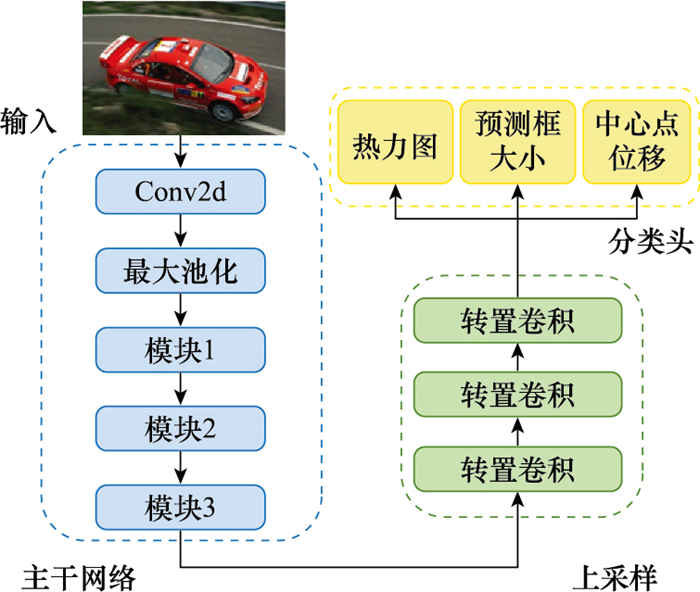
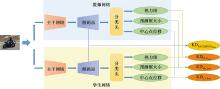
Fig.2
Knowledge distillation module structure based on CenterNet"
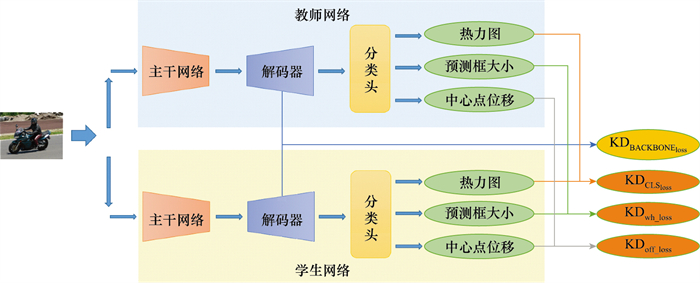
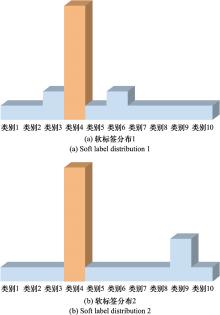
Fig.3
Soft label distribution generated for the same image by different networks"
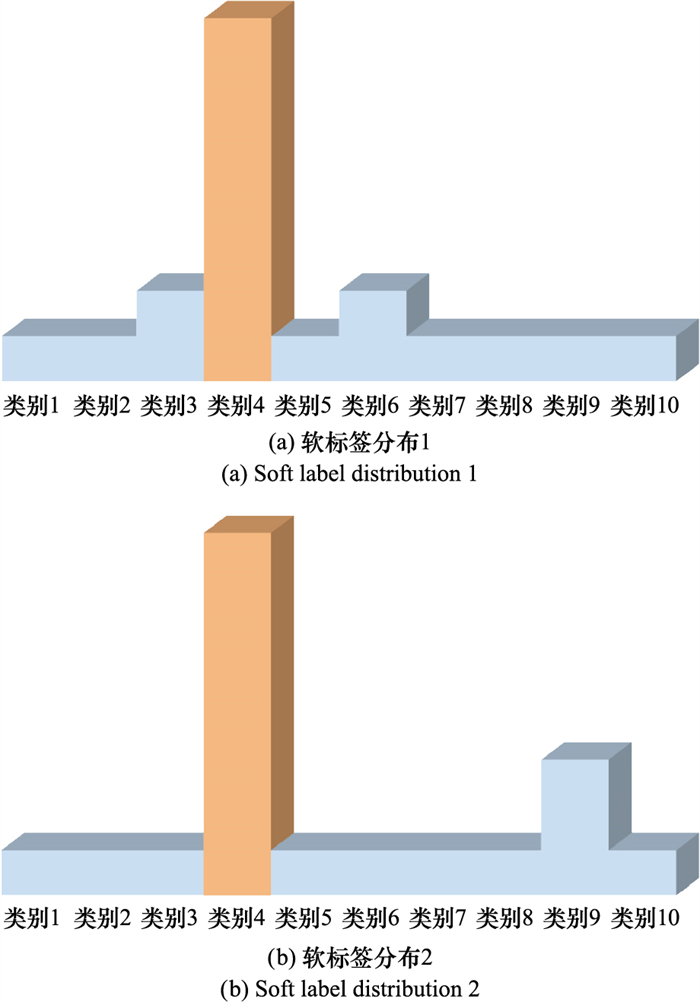
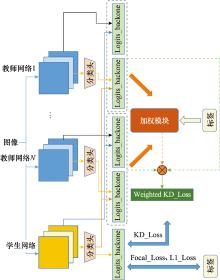
Fig.4
Multi-teacher joint knowledge distillation network"
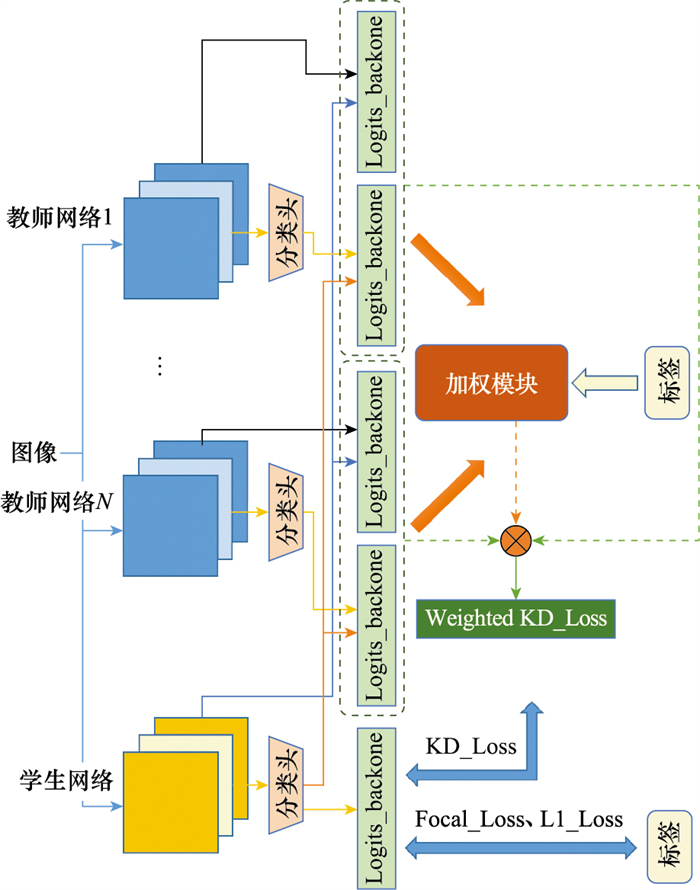
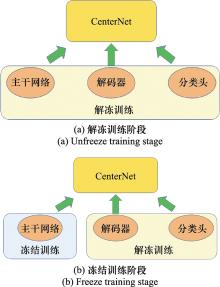
Fig.5
Unfreeze and freeze training"
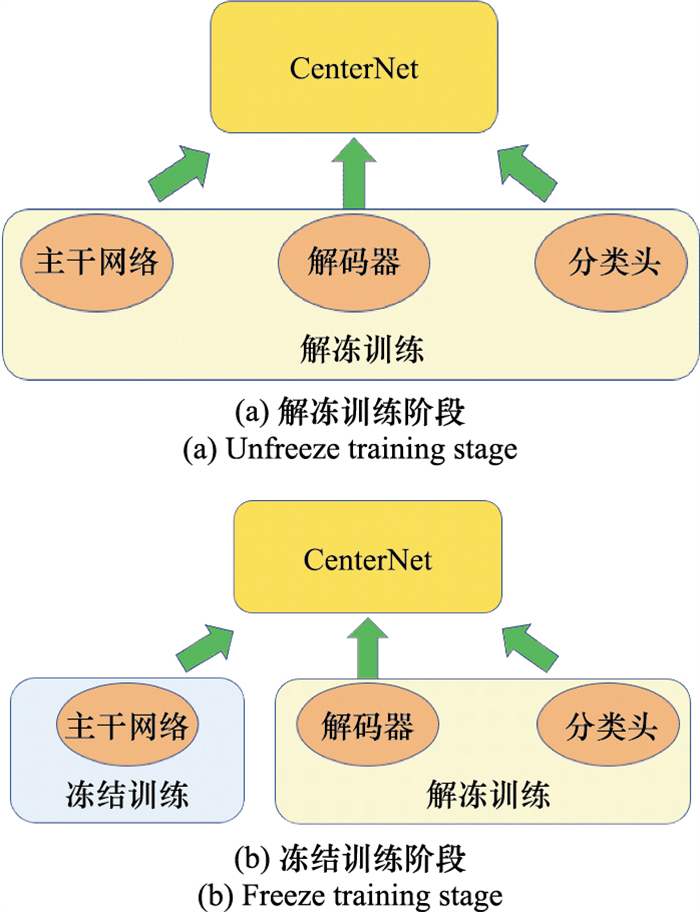
Table 1
Model size, parameter size, FLOPs of different structures of CenterNet"
| 主干网络 | 模型大小/M | 参数量/M | 浮点运算次数/B |
| ResNet50 | 124.94 | 32.67 | 34.99 |
| Hourglass | 730.35 | 182.59 | 125.32 |
| ResNet18 | 53.66 | 17.68 | 15.51 |
| ResNet34 | 92.28 | 23.07 | 21.02 |
| MobileNetV2 | 31.68 | 7.95 | 10.32 |
| EfficientNet-b0 | 43.41 | 10.98 | 12.55 |

Fig.6
AP of different models trained in two ways in car category"
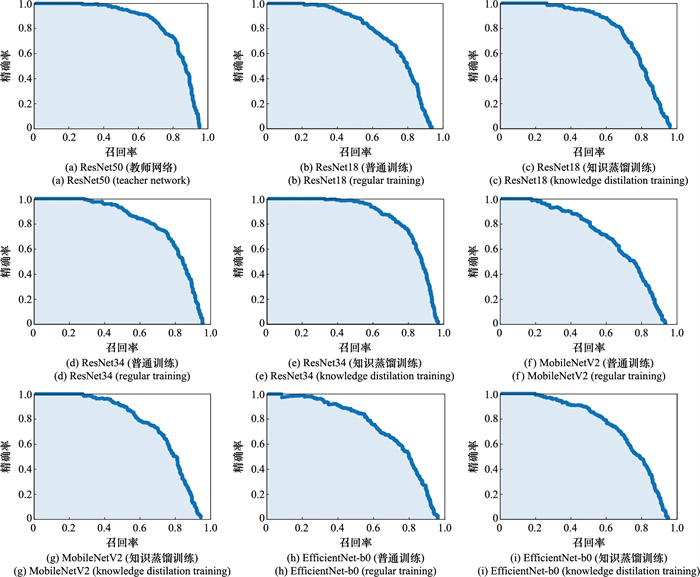
Table 2
mAP, number of training rounds, and loading of pre-trained models in different light-weight structures of CenterNet (with VOC dataset)"
| 主干网络 | mAP | 教师模型 | 训练 轮次 | 学生预 训练模型 |
| ResNet50 | 80.22 | - | 100 | Imagenet |
| ResNet18 | 73.95 | - | 100 | Imagenet |
| ResNet18(KD) | 77.96 | ResNet50 | 100 | Imagenet |
| ResNet34 | 79.83 | - | 100 | Imagenet |
| ResNet34(KD) | 83.01 | ResNet50 | 100 | Imagenet |
| MobileNetV2 | 66.93 | - | 100 | Imagenet |
| MobileNetV2(KD) | 75.96 | ResNet50 | 100 | Imagenet |
| EfficientNet-b0 | 75.27 | - | 100 | Imagenet |
| EfficientNet-b0(KD) | 77.13 | ResNet50 | 100 | Imagenet |

Fig.7
AP of different models trained in two ways in motorbike category"
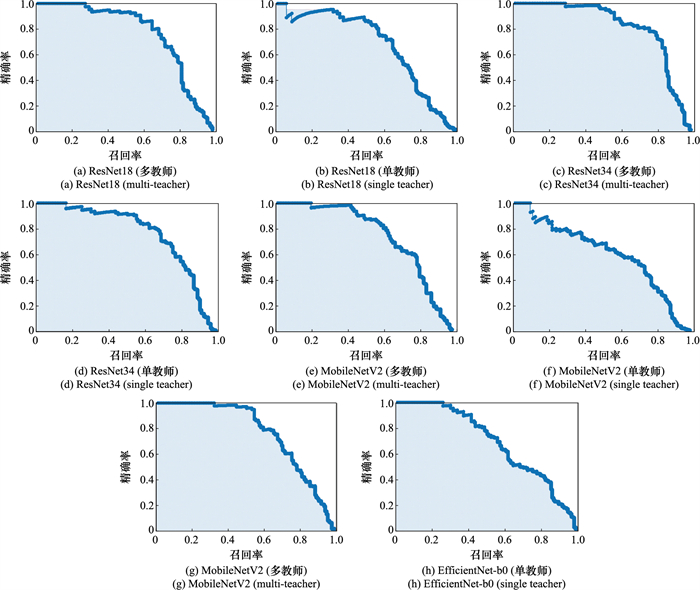
Table 3
Comparison of single teacher knowledge distillation and multi-teacher knowledge distillation"
| 主干网络 | mAP | 教师模型 | 轮次 |
| ResNet18 | 77.96 | ResNet50 | 100 |
| ResNet18 | 79.82 | ResNet50 & Hourglass | 100 |
| ResNet34 | 83.01 | ResNet50 | 100 |
| ResNet34 | 85.32 | ResNet50 & Hourglass | 100 |
| MobileNetV2 | 75.96 | ResNet50 | 100 |
| MobileNetV2 | 78.23 | ResNet50 & Hourglass | 100 |
| EfficientNet-b0 | 77.13 | ResNet50 | 100 |
| EfficientNet-b0 | 78.02 | ResNet50 & Hourglass | 100 |
Table 4
Comparison of CenterNet performance obtained by distillation training with different loss weight parameters W (withResNet18 as backbone)"
| W(w1, w2, w3, w4) | mAP | 轮次 |
| 1 000, 1, 0.1, 100 | 76.36 | 100 |
| 100, 10, 0.1, 100 | 75.39 | 100 |
| 100, 10, 1, 1 | 72.91 | 100 |
| 10, 0.1, 1 000, 10 | 71.36 | 100 |
| 10, 100, 0.1, 100 | 72.23 | 100 |
| 0.1, 10, 1 000, 1 | 69.88 | 100 |

Fig.8
ResNet18-CenterNet object's detection effect"


Fig.9
Detection performance diagram of the regular training(left) and detection performance diagram of the multi-teacher distillation training (right)"

| 1 | HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2016: 770-778. |
| 2 | NEWELL A, YANG K Y, DENG J. Stacked hourglass networks for human pose estimation[C]///Proc. of the 14th European Conference, 2016: 483-499. |
| 3 | DENG J, DONG W, SOCHER R, et al. ImageNet: a large-scale hierarchical image database[C]///Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2009: 248-255. |
| 4 | GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2014: 580-587. |
| 5 | PURKAIT P, ZHAO C, ZACH C. SPP-Net: deep absolute pose regression with synthetic views[EB/OL]. [2023-05-04]. https://arxiv.org/abs/1712.03452. |
| 6 |
REN S , HE K , GIRSHICK R , et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Trans.on Pattern Analysis and Machine Intelligence, 2017, 39 (6): 1137- 1149.
doi: 10.1109/TPAMI.2016.2577031 |
| 7 | REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 6517-6525. |
| 8 | FARHADI A, REDMON J. Yolov3: an incremental improvement[C]//Proc. of the Computer Vision and Pattern Recognition, 2018. |
| 9 |
LAW H , DENG J . CornerNet: detecting objects as paired keypoints[J]. International Journal of Computer Vision, 2020, 128 (3): 642- 656.
doi: 10.1007/s11263-019-01204-1 |
| 10 | ZHOU X Y, WANG D Q, KRAHENBUHL P. Objects as points[EB/OL]. [2023-05-04]. https://arxiv.org/abs/1904.07850. |
| 11 | ZHOU X Y, ZHUO J C, KRAHENBUHL P. Bottom-up object detection by grouping extreme and center points[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 850-859. |
| 12 | ZHANG X Y, ZHOU X Y, LIN M X, et al. ShuffleNet: an extremely efficient convolutional neural network for mobile devices[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2018: 6848-6856. |
| 13 | SANDLER M, HOWARD A, ZHU M L, et al. MobileNetv2: inverted residuals and linear bottlenecks[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2018: 4510-4520. |
| 14 | TAN M X, LE Q. EfficientNet: rethinking model scaling for convolutional neural networks[C]//Proc. of the International Conference on Machine Learning, 2019: 6105-6114. |
| 15 | JIAO X Q, YIN Y C, SHANG L F, et al. Tinybert: distilling BERT for natural language understanding[EB/OL]. [2023-05-04]. https://arxiv.org/abs/1909.10351. |
| 16 | HAN K, WANG Y H, TIAN Q, et al. Ghostnet: more features from cheap operations[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 1580-1589. |
| 17 | SUN Z Q, YU H K, SONG X D, et al. MobileBERT: a compact task-agnostic bert for resource-limited devices[EB/OL]. [2023-05-04]. https://arxiv.org/abs/2004.02984. |
| 18 | ABRAHAMYAN L, ZIATCHIN V, CHEN Y M, et al. Bias loss for mobile neural networks[C]//Proc. of the IEEE/CVF International Conference on Computer Vision, 2021: 6556-6566. |
| 19 | CHEN Y P, DAI X Y, CHEN D D, et al. Mobile-former: bridging mobilenet and transformer[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022: 5270-5279. |
| 20 | 黄震华, 杨顺志, 林威, 等. 知识蒸馏研究综述[J]. 计算机学报, 2022, 45 (3): 624- 653. |
| HUANG Z H , YANG S Z , LIN W , et al. Knowledge distilation: a survey[J]. Chinese Journal of Computers, 2022, 45 (3): 624- 653. | |
| 21 | HINTON G , VINYALS O , DEAN J . Distilling the knowledge in a neural network[J]. Computer Science, 2015, 14 (7): 38- 39. |
| 22 | FURLANELLO T, LIPTON Z, TSCHANNEN M, et al. Born again neural networks[C]//Proc. of the International Conference on Machine Learning, 2018: 1607-1616. |
| 23 | CHO J H, HARIHARAN B. On the efficacy of knowledge distillation[C]//Proc. of the IEEE/CVF International Conference on Computer Vision, 2019: 4794-4802. |
| 24 | URBAN G, GERAS K J, KAHOU S E, et al. Do deep convolutional nets really need to be deep and convolutional?[EB/OL]. [2023-05-04]. https://arxiv.org/abs/1603.05691. |
| 25 | TANG Z Y, WANG D, ZHANG Z Y. Recurrent neural network training with dark knowledge transfer[C]//Proc. of the IEEE International Conference on Acoustics, Speech and Signal Processing, 2016: 5900-5904. |
| 26 | YUAN L, TAY F E H, LI G L, et al. Revisiting knowledge distillation via label smoothing regularization[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 3903-3911. |
| 27 | VAPNIK V , VASHIST A . A new learning paradigm: learning using privileged information[J]. Neural Networks, 2009, 22 (5/6): 544- 557. |
| 28 | PHUONG M, LAMPERT C. Towards understanding know-ledge distillation[C]//Proc. of the International Conference on Machine Learning, 2019: 5142-5151. |
| 29 | CHENG X, RAO Z F, CHEN Y L, et al. Explaining know-ledge distillation by quantifying the knowledge[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 12925-12935. |
| 30 | LIN S H, XIE H W, WANG B, et al. Knowledge distillation via the target-aware transformer[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022: 10915-10924. |
| 31 | YANG Z D, LI Z, JIANG X H, et al. Focal and global know-ledge distillation for detectors[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022: 4643-4652. |
| 32 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[J]. Advances in Neural Information Processing Systems[EB/OL]. [2023-05-04]. https://arxiv.org/abs/1706.03762. |
| [1] | Sijia HUANG, Chunfeng SONG, Xuan LI. Target detection in sonar images based on variable scale prior frame [J]. Systems Engineering and Electronics, 2024, 46(3): 771-778. |
| [2] | Xiaoyu FANG, Lijia HUANG. SAR ship detection algorithm based on global position information and fusion of residual feature [J]. Systems Engineering and Electronics, 2024, 46(3): 839-848. |
| [3] | Chunjie ZHANG, Guanbo WANG, Qi CHEN, Zhi'an DENG. Gesture recognition based on millimeter-wave radar with pure self-attention mechanism [J]. Systems Engineering and Electronics, 2024, 46(3): 859-867. |
| [4] | Xiaofeng ZHAO, Jiahui NIU, Chuntong LIU, Yuting XIA. Hyperspectral image classification based on hybrid convolution with three-dimensional attention mechanism [J]. Systems Engineering and Electronics, 2023, 45(9): 2673-2680. |
| [5] | Haijun LI, Fancheng KONG, Yun LIN. Infrared ship detection algorithm based on improved YOLOv5s [J]. Systems Engineering and Electronics, 2023, 45(8): 2415-2422. |
| [6] | Tianshu CUI, Dong WANG, Zhen HUANG. Automatic modulation classification based on lightweight network for space cognitive communication [J]. Systems Engineering and Electronics, 2023, 45(7): 2220-2226. |
| [7] | Zhe DENG, Jing LEI, Chengzhe SUN. Semi-supervised interference cancellation method for frequency hopping signal blind detection [J]. Systems Engineering and Electronics, 2023, 45(7): 2236-2248. |
| [8] | Qingyuan ZHAO, Zhiqiang ZHAO, Chunmao YE, Yaobing LU. Micro-motion fusion recognition of double band early warning radar based on self-attention mechanism [J]. Systems Engineering and Electronics, 2023, 45(3): 708-716. |
| [9] | Pengyu CAO, Chengzhi YANG, Zesheng CHEN, Lu WANG, Limeng SHI. Radar signal recognition method based on deep residual shrinkage attention network [J]. Systems Engineering and Electronics, 2023, 45(3): 717-725. |
| [10] | Xiaojia YAN, Weige LIANG, Gang ZHANG, Bo SHE, Fuqing TIAN. Prediction method for mechanical equipment based on RCNN-ABiLSTM [J]. Systems Engineering and Electronics, 2023, 45(3): 931-940. |
| [11] | Zhuzhen HE, Min LI, Yao GOU, Aitao YANG. Ship target detection method for synthetic aperture radar images based on improved YOLOv5 [J]. Systems Engineering and Electronics, 2023, 45(12): 3743-3753. |
| [12] | Yichen ZHAI, Jiaojiao GU, Fuqiang ZONG, Wenzhi JIANG. Fine grained cross-modal retrieval algorithm for IETM with attention mechanism fused [J]. Systems Engineering and Electronics, 2023, 45(12): 3915-3923. |
| [13] | Yanyan HUANG, Shaoyan GAI, Feipeng DA. Image matching algorithm based on attention mechanism of three branch spatial transformation [J]. Systems Engineering and Electronics, 2023, 45(11): 3363-3373. |
| [14] | Chenghui QI, Dengyin ZHANG. Progressive image dehaze based on perceptual fusion [J]. Systems Engineering and Electronics, 2023, 45(11): 3419-3427. |
| [15] | Junfeng SUN, Chenghai LI, Bo CAO. Network security situation prediction based on TCN-BiLSTM [J]. Systems Engineering and Electronics, 2023, 45(11): 3671-3679. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||