Systems Engineering and Electronics ›› 2023, Vol. 45 ›› Issue (12): 3915-3923.doi: 10.12305/j.issn.1001-506X.2023.12.21
• Systems Engineering • Previous Articles
Fine grained cross-modal retrieval algorithm for IETM with attention mechanism fused
Yichen ZHAI, Jiaojiao GU, Fuqiang ZONG, Wenzhi JIANG
- Coastal Defense College, Naval Aviation University, Yantai 264001, China
-
Received:2022-04-11Online:2023-11-25Published:2023-12-05 -
Contact:Jiaojiao GU
CLC Number:
Cite this article
Yichen ZHAI, Jiaojiao GU, Fuqiang ZONG, Wenzhi JIANG. Fine grained cross-modal retrieval algorithm for IETM with attention mechanism fused[J]. Systems Engineering and Electronics, 2023, 45(12): 3915-3923.
share this article
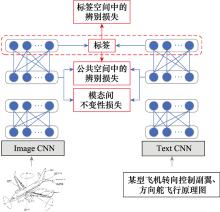
Fig.1
DSCMR network's structure"

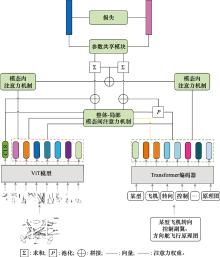
Fig.2
Model's structure"


Fig.3
Some category images and corresponding text examples of the self-built dataset"
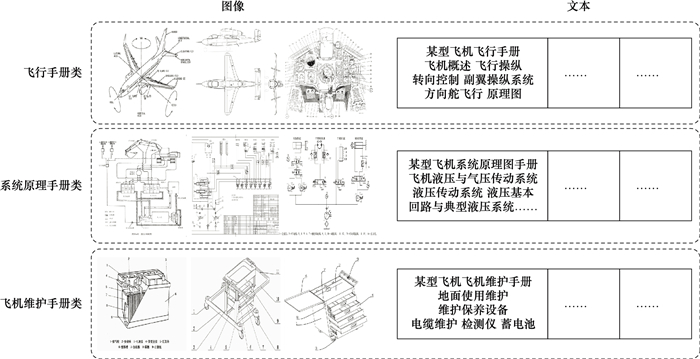
Table 1
Cross-modal retrieval method mAP (with Pascal Sentence dataset)"
| 方法 | mAP | ||
| 图检文 | 文检图 | 平均值 | |
| DCCA[ | 0.678 | 0.677 | 0.678 |
| ACMR[ | 0.671 | 0.676 | 0.673 |
| MAN[ | 0.680 | 0.700 | 0.690 |
| DSCMR[ | 0.722 | 0.710 | 0.716 |
| DSCMR* | 0.936 | 0.928 | 0.932 |
| 文献[ | 0.227 | 0.225 | 0.226 |
| 文献[ | 0.539 | 0.531 | 0.535 |
| 文献[ | 0.623 | 0.702 | 0.662 |
| 本文* | 0.963 | 0.964 | 0.964 |
Table 2
Cross-modal retrieval method mAP (with self-built dataset)"
| 方法 | mAP | ||
| 图检文 | 文检图 | 平均值 | |
| DCCA | 0.482 | 0.444 | 0.463 |
| ACMR | 0.596 | 0.515 | 0.556 |
| MAN | 0.504 | 0.515 | 0.510 |
| DSCMR | 0.721 | 0.770 | 0.745 |
| SDML | 0.793 | 0.785 | 0.789 |
| DSCMR* | 0.835 | 0.869 | 0.852 |
| SDML* | 0.848 | 0.871 | 0.860 |
| 本文* | 0.961 | 0.958 | 0.959 |
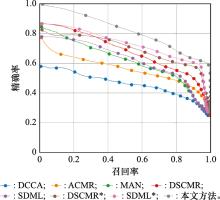
Fig.4
PR curve of image retrieval text"
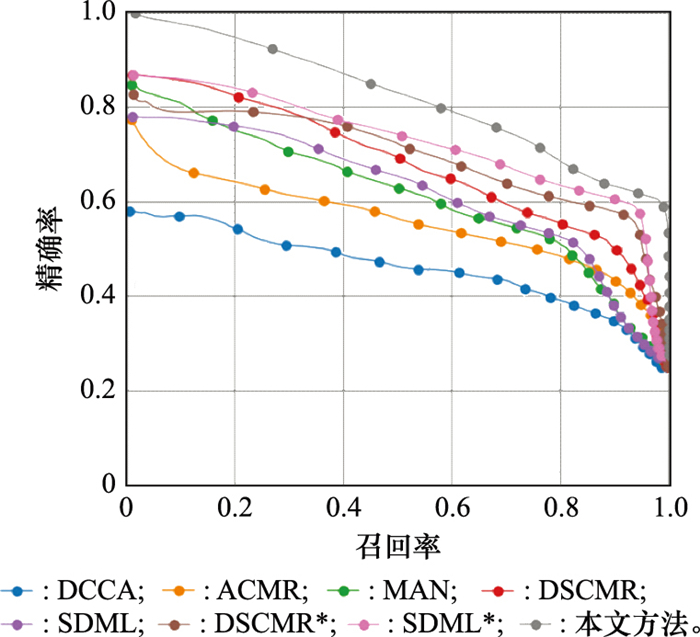
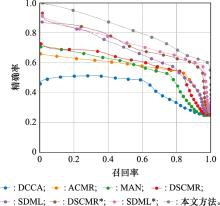
Fig.5
PR curve of text retrieval image"

Table 3
Comparison of mAP results of ablation experiment (with self-built dataset)"
| 方法 | 模块 | mAP | |||||
| 特征提取 | 文本对抗 | 模态间注意力 | 模态内注意力 | 图检文 | 文检图 | 平均值 | |
| 1 | CNN CNN | - | - | - | 0.721 | 0.770 | 0.745 |
| 2 | CNN CNN | √ | - | - | 0.736 | 0.778 | 0.757 |
| 3 | CNN Transformer | √ | - | - | 0.723 | 0.772 | 0.747 |
| 4 | ViT CNN | √ | - | - | 0.864 | 0.878 | 0.871 |
| 5 | VIT Transfomer | √ | - | - | 0.835 | 0.869 | 0.852 |
| 6 | VIT Transfomer | √ | √ | - | 0.937 | 0.929 | 0.933 |
| 7 | VIT Transfomer | √ | √ | √ | 0.961 | 0.958 | 0.959 |
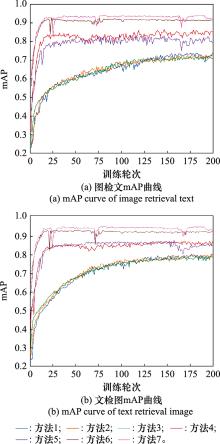
Fig.6
mAP curve of different methods"
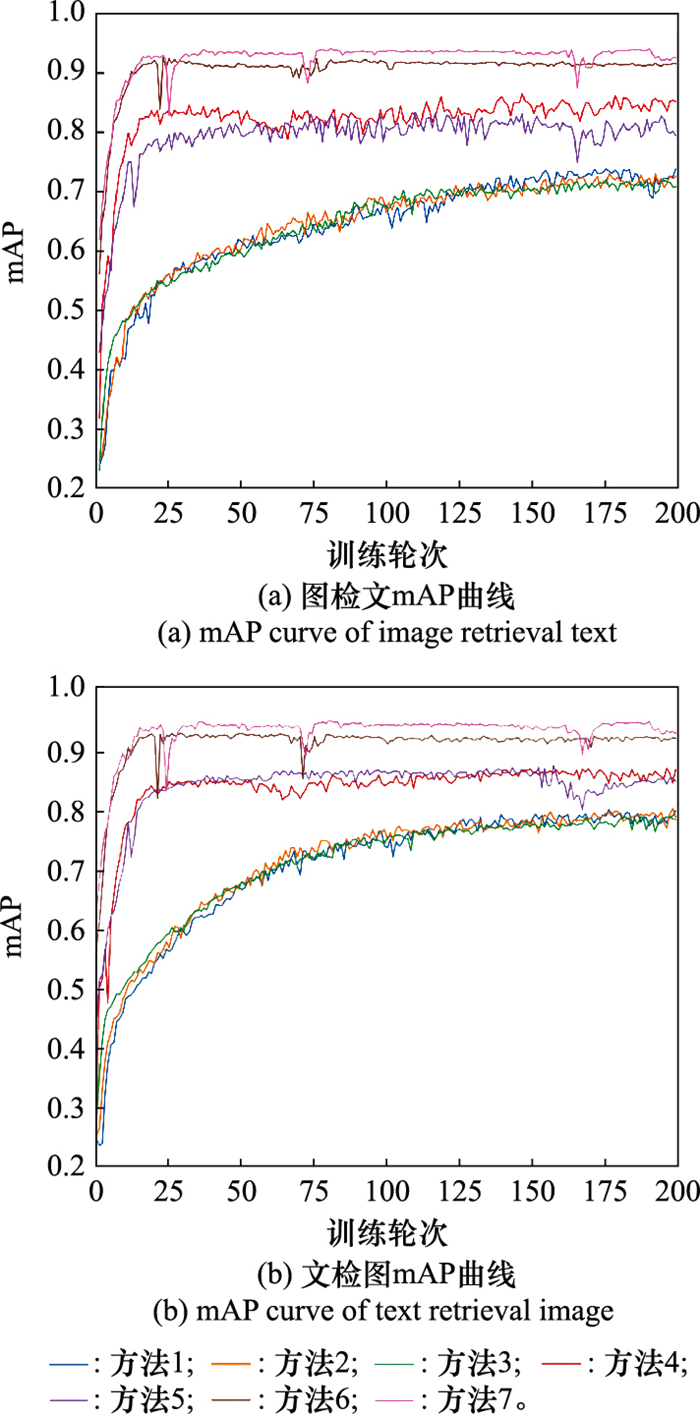
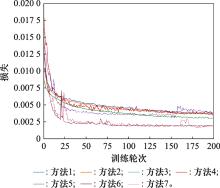
Fig.7
Loss change of verification data set"
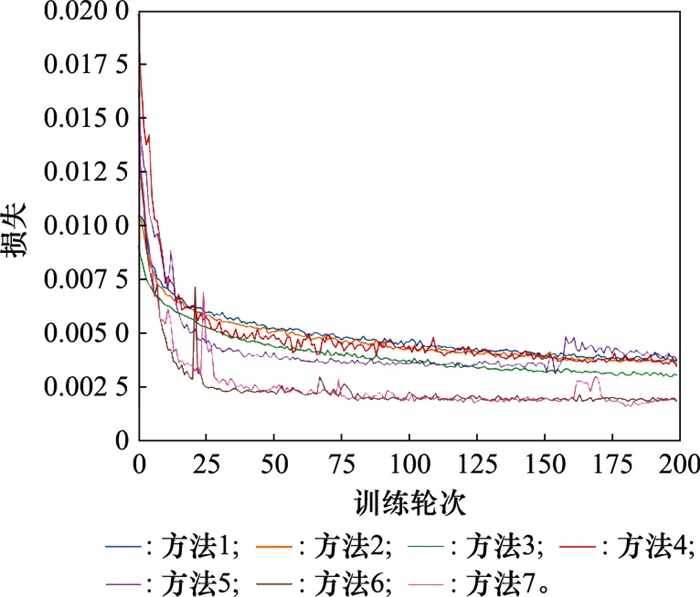
Fig.8
Influence of different parameter values on mAP"
Table 4
mAP results of different mapping feature dimensions"
| 特征维度 | mAP | ||
| 图检文 | 文检图 | 平均值 | |
| 128 | 0.957 | 0.956 | 0.957 |
| 256 | 0.961 | 0.958 | 0.959 |
| 512 | 0.950 | 0.950 | 0.950 |

Fig.9
Visual analysis of attention"

| 1 | 宋鹏. 智能化交互式电子技术手册系统开发研究[D]. 西安: 西安工业大学, 2020. |
| SONG P. Research and development of intelligent interactive electronic technical manual system[D]. Xi'an: Xi'an University of Technology, 2020. | |
| 2 | 刘颖, 郭莹莹, 房杰, 等. 深度学习跨模态图文检索研究综述[J]. 计算机科学与探索, 2022, 16 (3): 489- 511. |
| LIU Y , GUO Y Y , FANG J , et al. A survey of research on deep learning cross-modal image text retrieval[J]. Computer Science and Exploration, 2022, 16 (3): 489- 511. | |
| 3 | PENG Y X , HUANG X , ZHAO Y Z . An overview of cross-media retrieval: concepts, methodologies, benchmarks, and challenges[J]. IEEE Trans.on Circuits and Systems for Video Technology, 2017, 28 (9): 2372- 2385. |
| 4 | 朱路, 田晓梦, 曹赛男, 等. 基于高阶语义相关的子空间跨模态检索方法研究[J]. 数据分析与知识发现, 2020, 4 (5): 84- 91. |
| ZHU L , TIAN X M , CAO S N , et al. Subspace cross-modal retrieval based on high-order semantic correlation[J]. Data Analysis and Knowledge Discovery, 2020, 4 (5): 84- 91. | |
| 5 | RASIWASIA N, COSTA P J. A new approach to cross-modal multimedia retrieval[C]//Proc. of the 18th ACM International Conference on Multimedia, 2010: 251-260. |
| 6 | WANG K Y, YIN Q Y, WANG W, et al. A comprehensive survey on cross-modal retrieval[EB/OL]. [2022-04-05]. https://arxiv.org/abs/1607.06215. |
| 7 | KAUR P , PANNU H S , MALHI A K . Comparative analysis on cross-modal information retrieval: a review[J]. Computer Science Review, 2021, 39 (2): 100336. |
| 8 | BAHDANAU D, CHO K, BENGIO Y. Neural machine translation by jointly learning to align and translate[EB/OL]. [2022-04-05]. https://arxiv.org/abs/1409.0473v5. |
| 9 | 薛静宜. 手绘草图的跨模态检索[D]. 北京: 北京邮电大学, 2020. |
| XUE J Y. Cross-modal retrieval of hand drawn sketches[D]. Beijing: Beijing University of Posts and Telecommunications, 2020. | |
| 10 | HU J, SHEN L, SAMUEL A. Squeeze-and-excitation networks[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2018: 7132-7141. |
| 11 | LEE K H, CHEN X, HUA G, et al. Stacked cross attention for image-text matching[C]//Proc. of the European Conference on Computer Vision, 2018: 201-216. |
| 12 |
REN S Q , HE K M , GIRSHICK R , et al. Faster-RCNN: towards real-time object detection with region proposal networks[J]. IEEE Trans.on Pattern Analysis and Machine Intelligence, 2017, 39 (6): 1137- 1149.
doi: 10.1109/TPAMI.2016.2577031 |
| 13 | ZHANG Q, LEI Z, ZHANG Z X, et al. Context-aware attention network for image-text retrieval[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 3536-3545. |
| 14 | ZENG Y, ZHANG X S, LI H. Multi-grained vision language pre-training: aligning texts with visual concepts[EB/OL]. [2022-04-05]. https://arxiv.org/abs/2111.08276v1. |
| 15 | DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: transformers for image recognition at scale[EB/OL]. [2022-04-05]. https://arxiv.org/abs/2010.11929v1. |
| 16 | RASHTCHIAN C, YOUNG P, HODOSH M, et al. Collecting image annotations using amazon's mechanical turk[C]//Proc. of the Annual Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies HLT 2010 Workshop on Creating Speech and Language Data with Amazon's Mechanical, 2010: 139-147. |
| 17 | ZHEN L L, HU P, WANG X, et al. Deep supervised cross-modal retrieval[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 10394-10403. |
| 18 | VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]//Proc. of the 31st International Conference on Neural Information Processing Systems, 2017: 6000-6010. |
| 19 | MIKOLOV T, CHEN K, CORRADO G, et al. Efficient estimation of word representations in vector space[EB/OL]. [2022-04-05]. https://arxiv.org/abs/1301.3781v1. |
| 20 |
HOIEM D , DIVVALA S K , HAYS J H . Pascal VOC 2008 challenge[J]. International Journal of Computer Vision, 2010, 88 (2): 303- 338.
doi: 10.1007/s11263-009-0275-4 |
| 21 | MIYATO T, DAI A M, GOODFELLOW I. Adversarial training methods for semi-supervised text classification[EB/OL]. [2022-04-05]. https://arxiv.org/abs/1605.07725v2. |
| 22 | WANG K Y, YIN Q Y, WANG W, et al. A comprehensive survey on cross-modal retrieval[EB/OL]. [2022-04-05]. https://arxiv.org/abs/1607.06215. |
| 23 | ANDREW G, ARORA R, BILMES J, et al. Deep canonical correlation analysis[C]//Proc. of the International Conference on Machine Learning, 2013: 1247-1255. |
| 24 | WANG B K, YANG Y, XU X, et al. Adversarial cross-modal retrieval[C]//Proc. of the 25th ACM International Conference on Multimedia, 2017: 154-162. |
| 25 | HU P , PENG D Z , WANG X , et al. Multimodal adversarial network for cross-modal retrieval[J]. Knowledge-Based Systems, 2019, 180 (5): 38- 50. |
| 26 | HU P, ZHEN L L, PENG D Z, et al. Scalable deep multimodal learning for cross-modal retrieval[C]//Proc. of the 42nd ACM International Conference on Research and Development in Information Retrieval, 2019: 635-644. |
| 27 | HE K M, ZHANG X, REN S Q, et al. Deep residual learning for image recognition[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2016: 770-778. |
| 28 | ELIZALDE B, ZARAR S, RAJ B. Cross modal audio search and retrieval with joint embeddings based on text and audio[C]// Proc. of the IEEE International Conference on Acoustics, Speech and Signal Processing, 2019: 4095-4099. |
| 29 |
XU X , HE L M , LU H , et al. Deep adversarial metric learning for cross-modal retrieval[J]. World Wide Web, 2019, 22 (2): 657- 672.
doi: 10.1007/s11280-018-0541-x |
| 30 | CAO W M , LIN Q B , HE Z Q , et al. Hybrid representation learning for cross-modal retrieval[J]. Neurocomputing, 2019, 345 (14): 45- 57. |
| [1] | Xiaofeng ZHAO, Jiahui NIU, Chuntong LIU, Yuting XIA. Hyperspectral image classification based on hybrid convolution with three-dimensional attention mechanism [J]. Systems Engineering and Electronics, 2023, 45(9): 2673-2680. |
| [2] | Haijun LI, Fancheng KONG, Yun LIN. Infrared ship detection algorithm based on improved YOLOv5s [J]. Systems Engineering and Electronics, 2023, 45(8): 2415-2422. |
| [3] | Zhe DENG, Jing LEI, Chengzhe SUN. Semi-supervised interference cancellation method for frequency hopping signal blind detection [J]. Systems Engineering and Electronics, 2023, 45(7): 2236-2248. |
| [4] | Xin GUAN, Jiaen GUO, Xiao YI. Ship target recognition based on low rank bilinear pooling attention network [J]. Systems Engineering and Electronics, 2023, 45(5): 1305-1314. |
| [5] | Qingyuan ZHAO, Zhiqiang ZHAO, Chunmao YE, Yaobing LU. Micro-motion fusion recognition of double band early warning radar based on self-attention mechanism [J]. Systems Engineering and Electronics, 2023, 45(3): 708-716. |
| [6] | Pengyu CAO, Chengzhi YANG, Zesheng CHEN, Lu WANG, Limeng SHI. Radar signal recognition method based on deep residual shrinkage attention network [J]. Systems Engineering and Electronics, 2023, 45(3): 717-725. |
| [7] | Xiaojia YAN, Weige LIANG, Gang ZHANG, Bo SHE, Fuqing TIAN. Prediction method for mechanical equipment based on RCNN-ABiLSTM [J]. Systems Engineering and Electronics, 2023, 45(3): 931-940. |
| [8] | Zhuzhen HE, Min LI, Yao GOU, Aitao YANG. Ship target detection method for synthetic aperture radar images based on improved YOLOv5 [J]. Systems Engineering and Electronics, 2023, 45(12): 3743-3753. |
| [9] | Yanyan HUANG, Shaoyan GAI, Feipeng DA. Image matching algorithm based on attention mechanism of three branch spatial transformation [J]. Systems Engineering and Electronics, 2023, 45(11): 3363-3373. |
| [10] | Chenghui QI, Dengyin ZHANG. Progressive image dehaze based on perceptual fusion [J]. Systems Engineering and Electronics, 2023, 45(11): 3419-3427. |
| [11] | Haoran LI, Wei XIONG, Yaqi CUI. An association method between SAR images and AIS information based on depth feature fusion [J]. Systems Engineering and Electronics, 2023, 45(11): 3491-3497. |
| [12] | Junfeng SUN, Chenghai LI, Bo CAO. Network security situation prediction based on TCN-BiLSTM [J]. Systems Engineering and Electronics, 2023, 45(11): 3671-3679. |
| [13] | Xiao HAN, Shiwen CHEN, Meng CHEN, Jincheng YANG. Open-set recognition of LPI radar signal based on reciprocal point learning [J]. Systems Engineering and Electronics, 2022, 44(9): 2752-2759. |
| [14] | Pingliang XU, Yaqi CUI, Wei XIONG, Zhenyu XIONG, Xiangqi GU. Generative track segment consecutive association method [J]. Systems Engineering and Electronics, 2022, 44(5): 1543-1552. |
| [15] | Tao WU, Lunwen WANG, Jingcheng ZHU. Camouflage image segmentation based on transfer learning and attention mechanism [J]. Systems Engineering and Electronics, 2022, 44(2): 376-384. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||