Systems Engineering and Electronics ›› 2022, Vol. 44 ›› Issue (10): 3190-3199.doi: 10.12305/j.issn.1001-506X.2022.10.23
• Guidance, Navigation and Control • Previous Articles Next Articles
Autopilot parameter rapid tuning method based on deep reinforcement learning
Qitian WAN1, Baogang LU2, Yaxin ZHAO3, Qiuqiu WEN1,*
- 1. School of Aerospace Engineering, Beijing Institute of Technology, Beijing 100081, China
2. Beijing Institute of Space Long March Vehicle, Beijing 100076, China
3. China Academy of Launch Vehicle Technology, Beijing 100076, China
-
Received:2021-12-07Online:2022-09-20Published:2022-10-24 -
Contact:Qiuqiu WEN
CLC Number:
Cite this article
Qitian WAN, Baogang LU, Yaxin ZHAO, Qiuqiu WEN. Autopilot parameter rapid tuning method based on deep reinforcement learning[J]. Systems Engineering and Electronics, 2022, 44(10): 3190-3199.
share this article
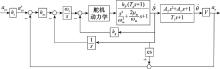
Fig.1
Diagram of autopilot structure"

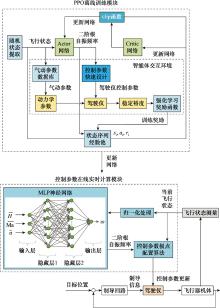
Fig.2
Parameter tuning framework based on deep reinforcement learning"
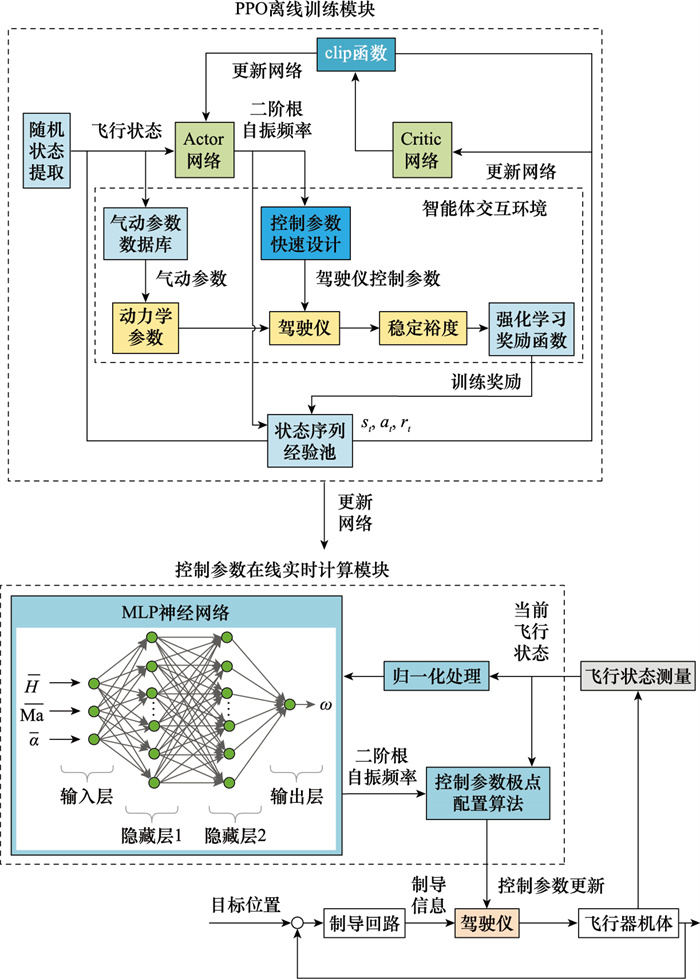

Fig.3
Parameter tuning training framework based on PPO algorithm"

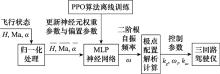
Fig.4
MLP neural network online real-time calculation model"
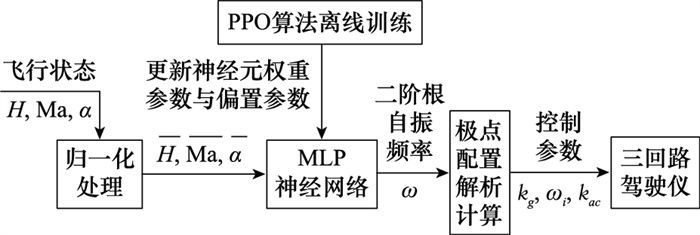
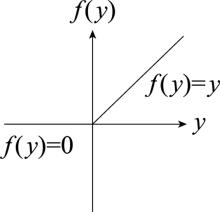
Fig.5
ReLU function"

Fig.6
MLP neural network structure diagram"
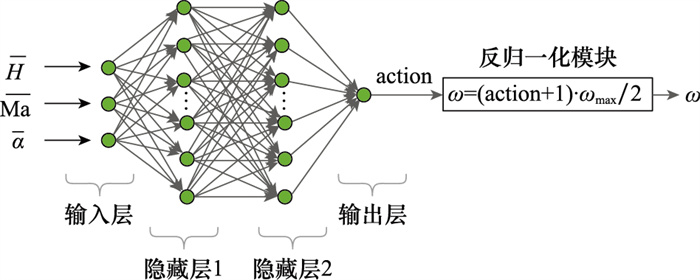
Table 1
Training hyperparameters of PPO algorithm"
| 超参数 | 取值 |
| 学习率 | e-3 |
| 记忆容量 | 224 |
| 折扣因子 | 0.99 |
| 单轮更新的最大采样步数 | 150 000 |
| 批次大小 | 128 |
| 估计优势函数裁剪系数 | 0.2 |
| 泛化优势估计参数 | 0.98 |
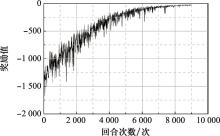
Fig.7
Three-dimensional actions training process reward value curve"
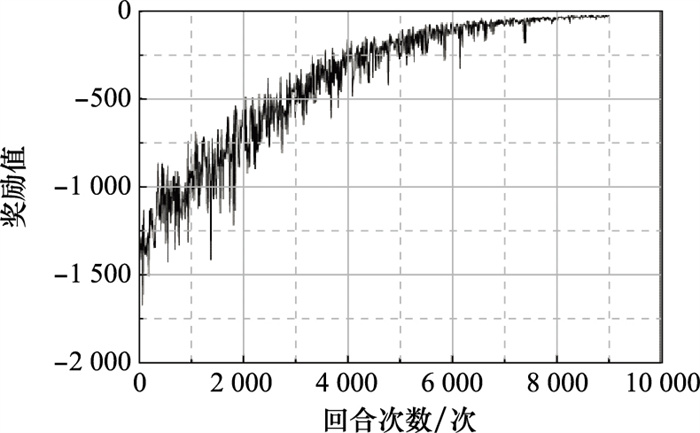

Fig.8
One-dimensional action training process reward value curve"
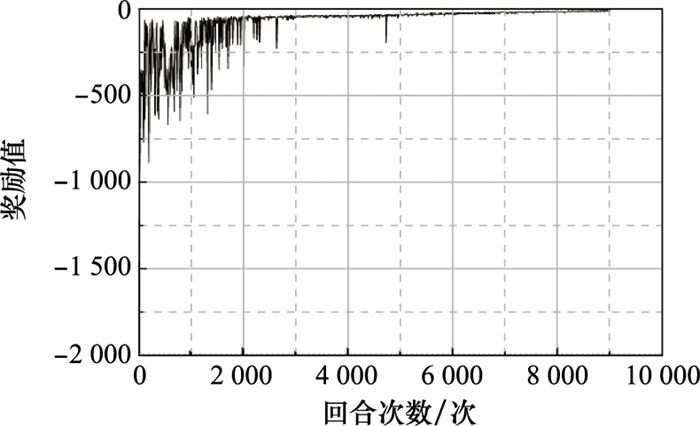
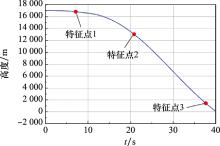
Fig.9
Reentry height curve"

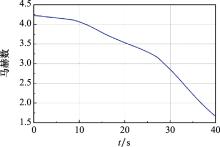
Fig.10
Reentry Mach number curve"
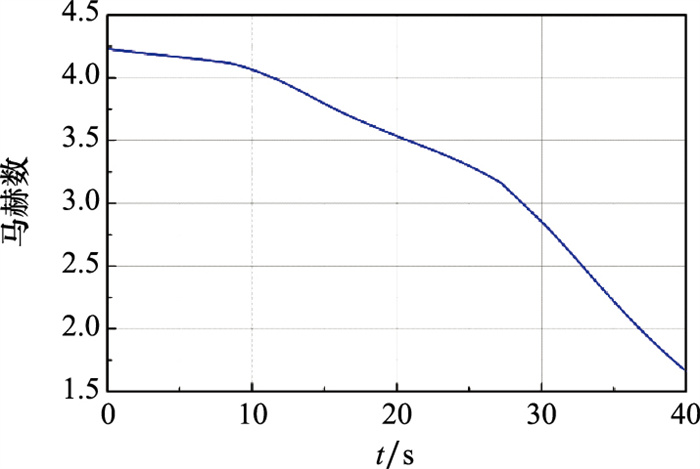
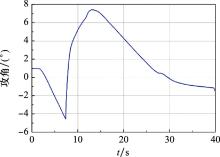
Fig.11
Reentry angle attack curve"
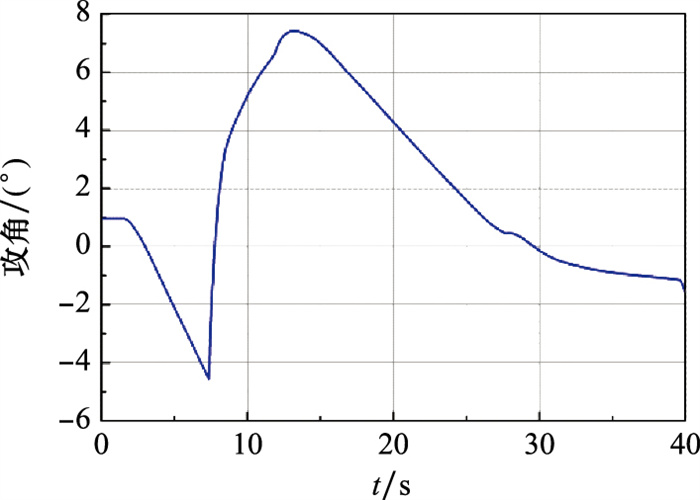
Table 2
Flight status at different feature points"
| 特征点 | H/m | Ma | α/(°) |
| 特征点1 | 16 863 | 4.14 | -3.77 |
| 特征点2 | 13 075 | 3.50 | -3.87 |
| 特征点3 | 1 420 | 1.90 | -1.04 |
Table 3
Design results of different flight states"
| 特征点 | 二阶根自振频率/(rad/s) | 相位裕度/(°) | 幅值裕度/ dB | 上升时间/s | 过渡过程时间/s |
| 特征点1 | 35.15 | 65.17 | 8.54 | 0.71 | 5.84 |
| 特征点2 | 36.22 | 65.18 | 8.53 | 0.71 | 5.84 |
| 特征点3 | 37.56 | 65.10 | 8.51 | 0.71 | 5.84 |
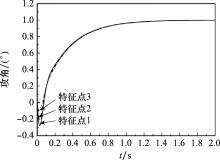
Fig.12
Response curve of autopilot based on deep reinforcement learning parameter tuning"
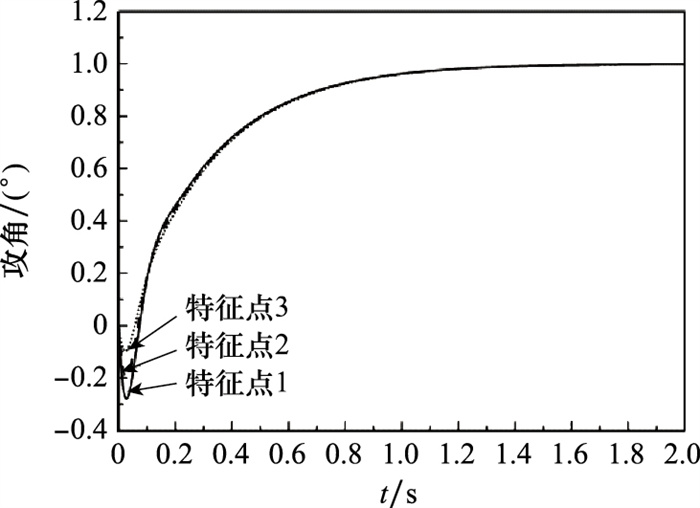
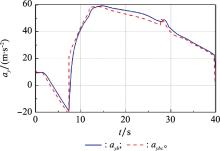
Fig.13
Command tracking curve of pitch channel"
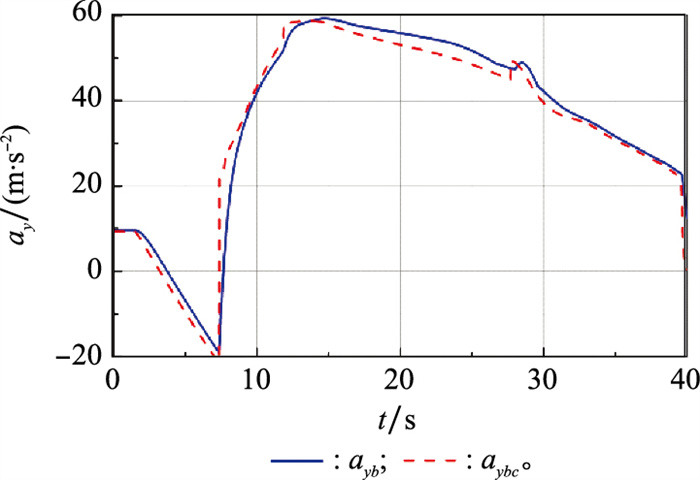
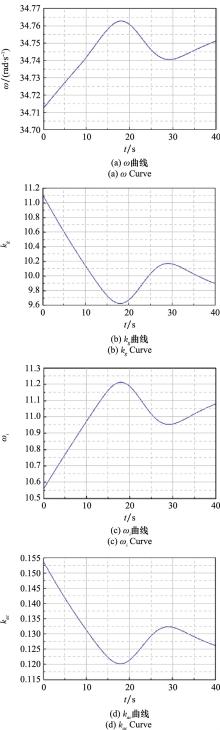
Fig.14
Curves of neural network output and control parameters"

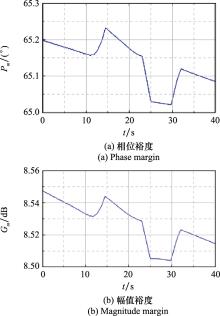
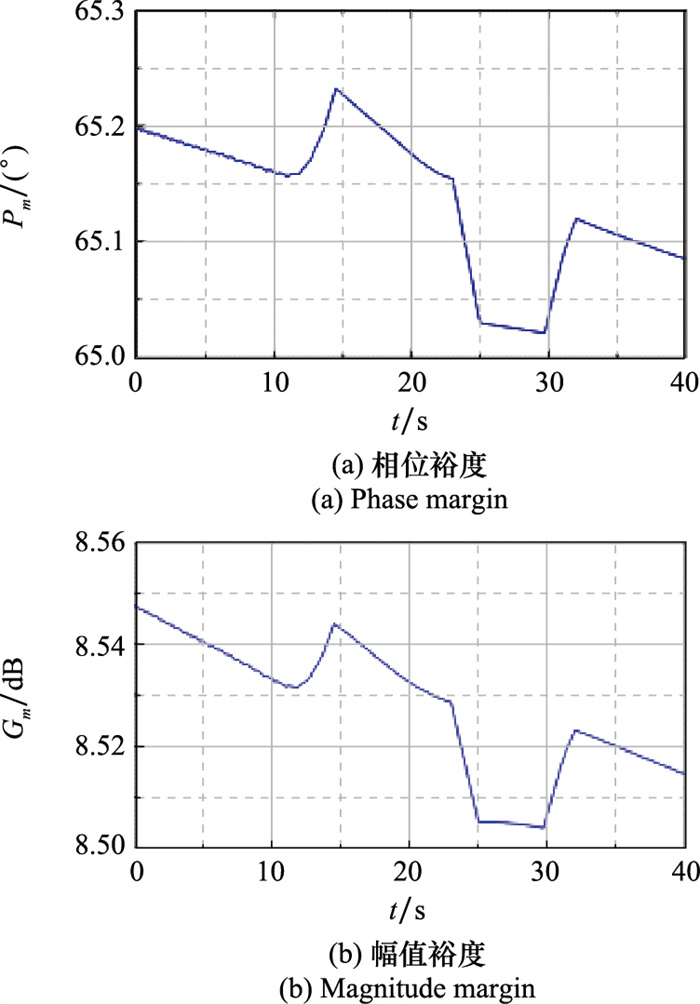
Fig.15
Stability margin curves"
| 1 | GARNELL P . Guided weapon control systems[M]. Oxford: Pergamon Press, 1980. |
| 2 |
温求遒, 夏群力, 祁载康. 三回路驾驶仪开环穿越频率约束极点配置设计[J]. 系统工程与电子技术, 2009, 31 (2): 420- 423.
doi: 10.3321/j.issn:1001-506X.2009.02.039 |
|
WEN Q Q , XIA Q L , QI Z K . Pole placement design with open-loop crossover frequency constraint for three-loop autopilot[J]. Systems Engineering and Electronics, 2009, 31 (2): 420- 423.
doi: 10.3321/j.issn:1001-506X.2009.02.039 |
|
| 3 |
孙宝彩, 祁载康. 带状态反馈约束的驾驶仪极点配置设计方法[J]. 系统仿真学报, 2006, 18, 892- 896.
doi: 10.3969/j.issn.1004-731X.2006.z2.252 |
|
SUN B C , QI Z K . Study of pole placement method for state feedback constrained autopilot design[J]. Journal of System Simulation, 2006, 18, 892- 896.
doi: 10.3969/j.issn.1004-731X.2006.z2.252 |
|
| 4 |
朱敬举, 祁载康, 夏群力. 三回路驾驶仪的极点配置方法设计[J]. 弹箭与制导学报, 2007, 27 (4): 8- 12.
doi: 10.3969/j.issn.1673-9728.2007.04.003 |
|
ZHU J J , QI Z K , XIA Q L . Pole assignment method for three-loop autopilot design[J]. Journal of Projectiles, Rockets, Missiles and Guidance, 2007, 27 (4): 8- 12.
doi: 10.3969/j.issn.1673-9728.2007.04.003 |
|
| 5 | 王辉, 林德福, 祁载康. 导弹伪攻角反馈三回路驾驶仪设计分析[J]. 系统工程与电子技术, 2012, 34 (1): 129- 135. |
| WANG H , LIN D F , QI Z K . Design and analysis of missile three-loop autopilot with pseudo-angle of attack feedback[J]. Systems Engineering and Electronics, 2012, 34 (1): 129- 135. | |
| 6 |
ZENG X , ZHU Y W , YANG L , et al. A guidance method for coplanar orbital interception based on reinforcement learning[J]. Journal of Systems Engineering and Electronics, 2021, 32 (4): 927- 938.
doi: 10.23919/JSEE.2021.000079 |
| 7 |
LI Y , QIU X H , LIU X D , et al. Deep reinforcement learning and its application in autonomous fitting optimization for attack areas of UCAVs[J]. Journal of Systems Engineering and Electronics, 2020, 31 (4): 734- 742.
doi: 10.23919/JSEE.2020.000048 |
| 8 |
MA Y , CHANG T Q , FAN W H . A single-task and multi-decision evolutionary game model based on multi-agent reinforcement learning[J]. Journal of Systems Engineering and Electronics, 2021, 32 (3): 642- 657.
doi: 10.23919/JSEE.2021.000055 |
| 9 |
MIN F , FRANS C G . Collaborative multi-agent reinforcement learning based on experience propagation[J]. Journal of Systems Engineering and Electronics, 2013, 24 (4): 683- 689.
doi: 10.1109/JSEE.2013.00079 |
| 10 | RICHARD S S , ANDREW G B . Reinforcement learning: an introduction[M]. 2nd ed Cambridge, Massachusetts: The MIT Press, 2014. |
| 11 | LAKSHAY A, ATRI D. Reinforcement learning for sequential low-thrust orbit raising problem[C]//Proc. of the AIAA SciTech Forum, 2020. |
| 12 | MARGHERITA P, MICHÈLE L. Deep reinforcement learning approach for small bodies shape reconstruction enhancement[C]//Proc. of the AIAA SciTech Forum, 2020. |
| 13 | CAN B, BURAK Y, GOKHAN I. High fidelity progressive reinforcement learning for agile maneuvering UAVs[C]//Proc. of the AIAA SciTech Forum, 2020. |
| 14 | HANNAH C L, JOHN V. Application of computational intelligence for command & control of unmanned air systems[C]//Proc. of the AIAA SciTech Forum, 2019. |
| 15 |
JACOB G E , ROHAN S . Bridging reinforcement learning and online learning for spacecraft attitude control[J]. Journal of Aerospace Information Systems, 2022, 19 (1): 62- 69.
doi: 10.2514/1.I010958 |
| 16 | SATOSHI S , SATASHI S , AKIRA O , et al. Closed-loop flow separation control using the deep Q network over airfoil[J]. AIAA Journal, 2020, 10 (58): 4260- 4270. |
| 17 | ROBERT C, LIAM F, COLIN G, et al. Closed-loop Q-learning control of a small unmanned aircraft[C]//Proc. of the AIAA SciTech Forum, 2020. |
| 18 | SHANELLE G C, INSEOK H. Deep reinforcement learning control for aerobatic maneuvering of agile fixed-wing aircraft[C]//Proc. of the AIAA SciTech Forum, 2020. |
| 19 | DANIEL M, GERTJAN L. Design and evaluation of advanced intelligent flight controllers[C]//Proc. of the AIAA SciTech Forum, 2020. |
| 20 | KANTA Y, NAOYA O, RYU F. Exploration of long time-of-flight three-body transfers using deep reinforcement learning[C]//Proc. of the AIAA SciTech Forum, 2020. |
| 21 | HIROSHI K, SEIJI T, EIJI S. Feedback control of Karman vortex shedding from a cylinder using deep reinforcement learning[C]//Proc. of the Flow Control Conference, 2018. |
| 22 | SUNGYUNG L, MATTHEW S, BRETT S, et al. Markov neural network for guidance, navigation and control[C]//AIAA SciTech 2020 Forum, 2020. |
| 23 | ANDREW H, HANSPETER S. Spacecraft command and control with safety guarantees using shielded deep reinforcement learning[C]//Proc. of the AIAA SciTech Forum, 2020. |
| 24 |
南杨, 李中键, 叶文伟. 基于强化学习的飞行自动驾驶仪设计[J]. 电子设计工程, 2013, 21 (10): 45- 47.
doi: 10.3969/j.issn.1674-6236.2013.10.014 |
|
NAN Y , LI Z J , YE W W . Design of autopilot for aircraft based on reinforcement learning[J]. Electronic Design Engineering, 2013, 21 (10): 45- 47.
doi: 10.3969/j.issn.1674-6236.2013.10.014 |
|
| 25 | 范军芳, 张鑫. 基于强化学习的微小型弹药两回路驾驶仪设计[J]. 战术导弹技术, 2019, 4, 48- 54. |
| FAN J F , ZHANG X . Design two-loop autopilot based on reinforcement learning for miniature munition[J]. Tactical Missile Technology, 2019, 4, 48- 54. | |
| 26 | 甄岩, 郝明瑞. 基于深度强化学习的智能PID控制方法研究[J]. 战术导弹技术, 2019, 5, 37- 43. |
| ZHEN Y , HAO M R . Research on intelligent PID control method based on deep reinforcement learning[J]. Tactical Missile Technology, 2019, 5, 37- 43. | |
| 27 | ZARCHAN P . Tactical and strategic missile guidance[M]. Washington D C: American Institute of Aeronautics and Astronautics, 1994. |
| 28 | JOHN S, FILIP W, ALEC R, et al. Proximal policy optimization algorithms[EB/OL]. [2021-12-01]. https://arxiv.org/abs/1707.06347. |
| 29 | JOHN S, SERGEY L, PHILIPP M, et al. Trust region policy optimization[C]//Proc. of the 32nd International Conference on Machine Learning, 2015: 1889-1897. |
| 30 | EVAN G , PETER L B , JONATHAN B . Variance reduction techniques for gradient estimates in reinforcement learning[J]. Journal of Machine Learning Research, 2015, 5, 1471- 1530. |
| 31 | JOHN S, PHILIPP M, SERGEY L, et al. High-dimensional continuous control using generalized advantage estimation[C]//Proc. of the International Conference on Learning Representations, 2016. |
| 32 | NICOLAS H, DHRUVA T, SRINIVASAN S, et al. Emergence of locomotion behaviours in rich environments[EB/OL]. [2021-12-01]. https://arxiv.org/abs/1707.02286. |
| [1] | Bakun ZHU, Weigang ZHU, Wei LI, Ying YANG, Tianhao GAO. Research on decision-making modeling of cognitive jamming for multi-functional radar based on Markov [J]. Systems Engineering and Electronics, 2022, 44(8): 2488-2497. |
| [2] | Guan WANG, Haizhong RU, Dali ZHANG, Guangcheng MA, Hongwei XIA. Design of intelligent control system for flexible hypersonic vehicle [J]. Systems Engineering and Electronics, 2022, 44(7): 2276-2285. |
| [3] | Lingyu MENG, Bingli GUO, Wen YANG, Xinwei ZHANG, Zuoqing ZHAO, Shanguo HUANG. Network routing optimization approach based on deep reinforcement learning [J]. Systems Engineering and Electronics, 2022, 44(7): 2311-2318. |
| [4] | Dongzi GUO, Rong HUANG, Hechuan XU, Liwei SUN, Naigang CUI. Research on deep deterministic policy gradient guidance method for reentry vehicle [J]. Systems Engineering and Electronics, 2022, 44(6): 1942-1949. |
| [5] | Mingren HAN, Yufeng WANG. Optimization method for orbit transfer of all-electric propulsion satellite based on reinforcement learning [J]. Systems Engineering and Electronics, 2022, 44(5): 1652-1661. |
| [6] | Li HE, Liang SHEN, Hui LI, Zhuang WANG, Wenquan TANG. Survey on policy reuse in reinforcement learning [J]. Systems Engineering and Electronics, 2022, 44(3): 884-899. |
| [7] | Bakun ZHU, Weigang ZHU, Wei LI, Ying YANG, Tianhao GAO. Multi-function radar intelligent jamming decision method based on prior knowledge [J]. Systems Engineering and Electronics, 2022, 44(12): 3685-3695. |
| [8] | Qingqing YANG, Yingying GAO, Yu GUO, Boyuan XIA, Kewei YANG. Target search path planning for naval battle field based on deep reinforcement learning [J]. Systems Engineering and Electronics, 2022, 44(11): 3486-3495. |
| [9] | Bin ZENG, Hongqiang ZHANG, Houpu LI. Research on anti-submarine strategy for unmanned undersea vehicles [J]. Systems Engineering and Electronics, 2022, 44(10): 3174-3181. |
| [10] | Bin ZENG, Rui WANG, Houpu LI, Xu FAN. Scheduling strategies research based on reinforcement learning for wartime support force [J]. Systems Engineering and Electronics, 2022, 44(1): 199-208. |
| [11] | Linxiao HAN, Jianbo HU, Shiyuan SONG, Yingyang WANG, Zihou HE, Peng ZHANG. Parameter tuning of manipulator motion tracking controller based on Policy Gradient [J]. Systems Engineering and Electronics, 2021, 43(9): 2605-2611. |
| [12] | Zhiwei JIANG, Yang HUANG, Qihui WU. Anti-interference frequency allocation based on kernel reinforcement learning [J]. Systems Engineering and Electronics, 2021, 43(6): 1547-1556. |
| [13] | Jiayi LIU, Shaohua YUE, Gang WANG, Xiaoqiang YAO, Jie ZHANG. Cooperative evolution algorithm of multi-agent system under complex tasks [J]. Systems Engineering and Electronics, 2021, 43(4): 991-1002. |
| [14] | An YAN, Zhang CHEN, Chaoyang DONG, Kanghui HE. Attitude balance control of two-wheeled robot based on fuzzy reinforcement learning [J]. Systems Engineering and Electronics, 2021, 43(4): 1036-1043. |
| [15] | Chen LI, Yanyan HUANG, Yongliang ZHANG, Tiande CHEN. Multi-agent decision-making method based on Actor-Critic framework and its application in wargame [J]. Systems Engineering and Electronics, 2021, 43(3): 755-762. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||