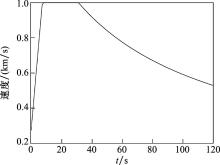
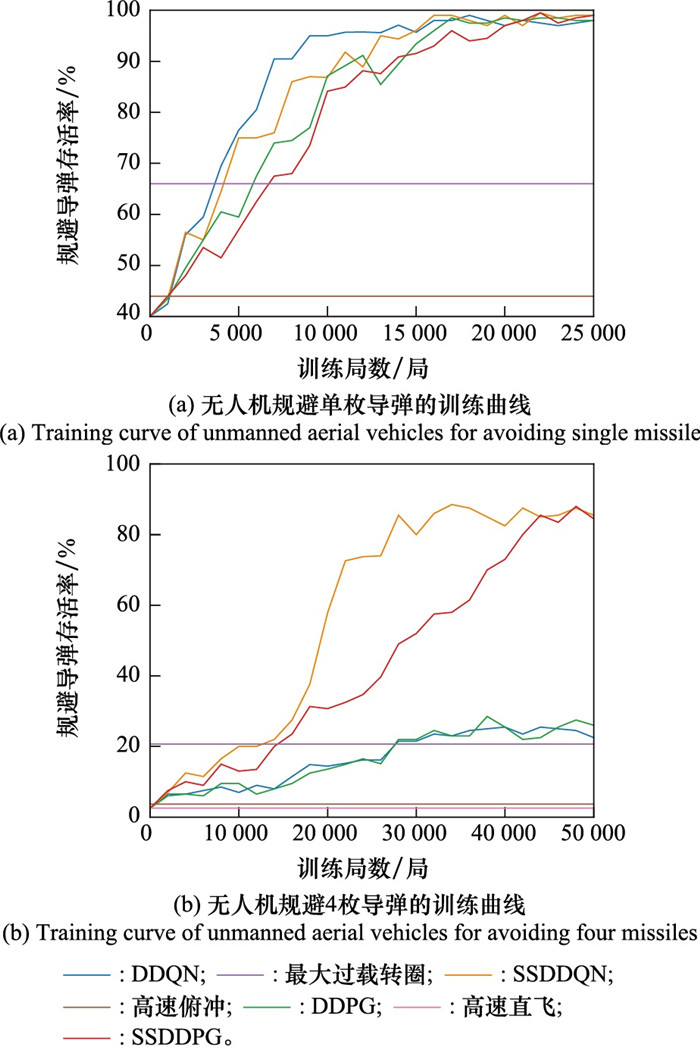
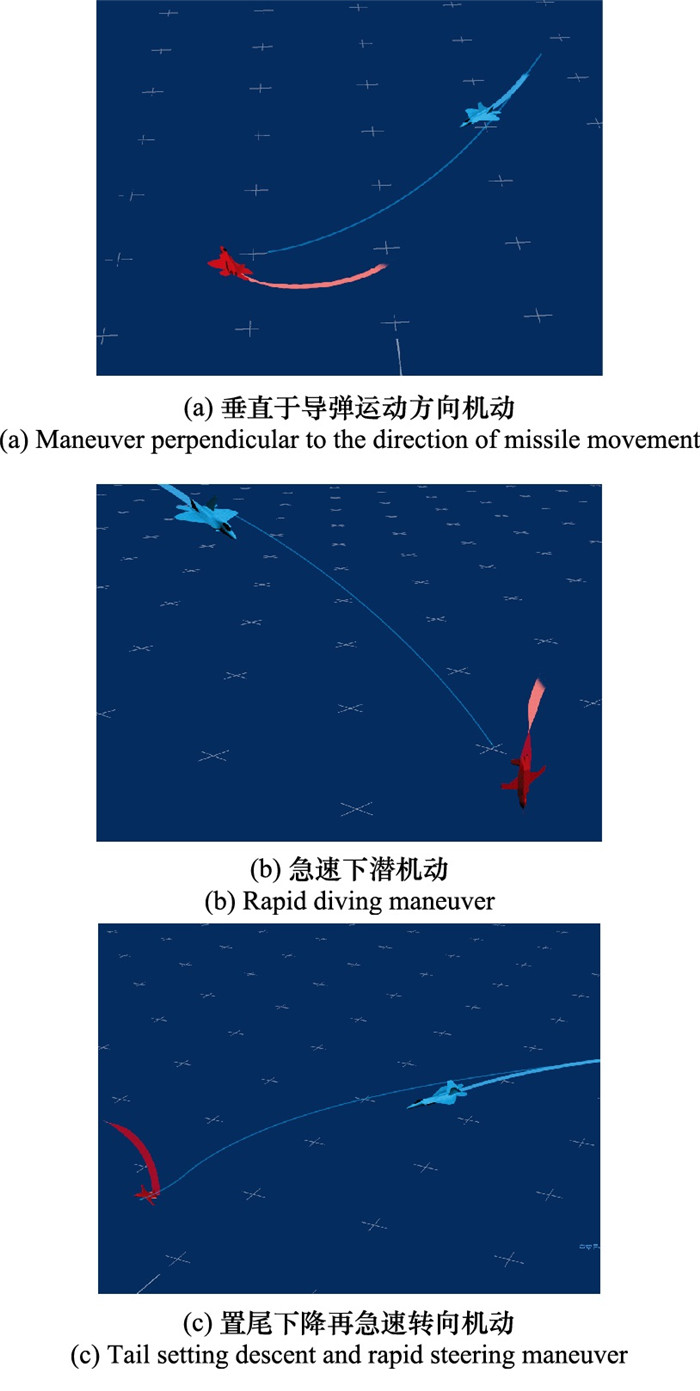
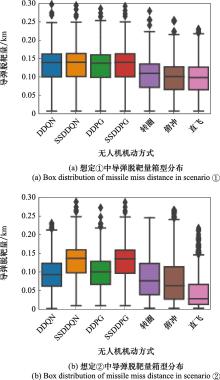
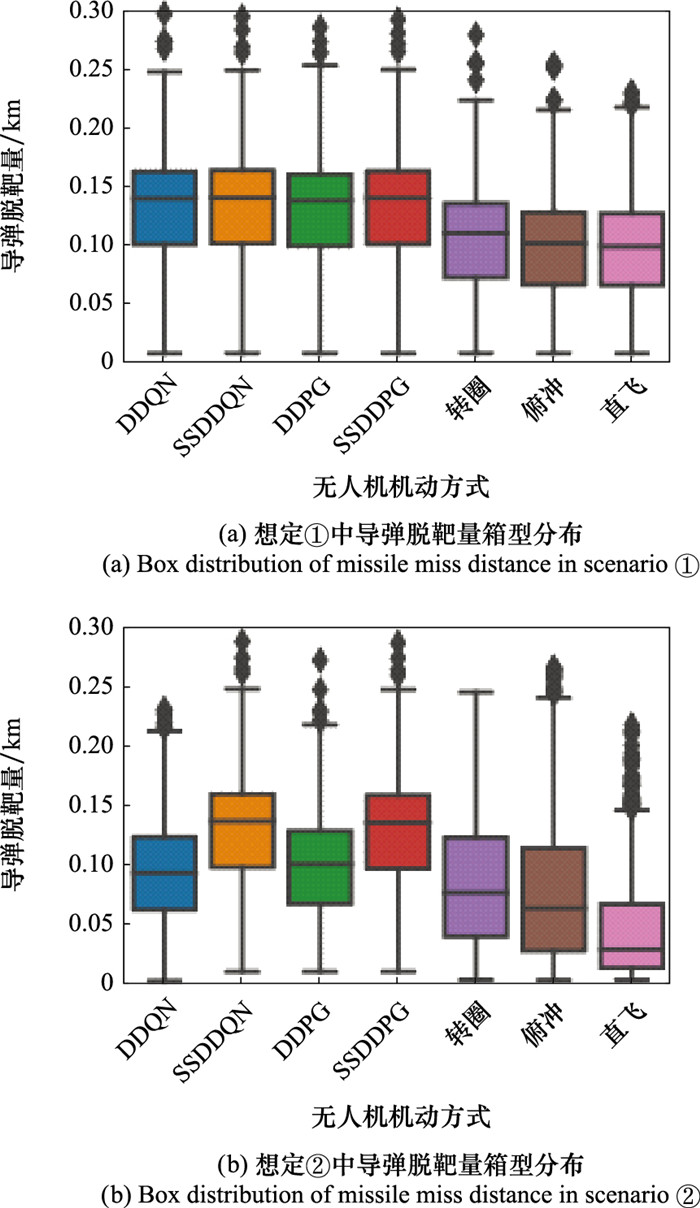
| 1 |
牛绿伟, 高晓光, 张坤, 等. 划分超视距、近距的多机协同作战战术决策[J]. 西北工业大学学报, 2011, 29 (6): 971- 977.
doi: 10.3969/j.issn.1000-2758.2011.06.026
|
|
NIU L W , GAO X G , ZHANG K , et al. Making decisions on proper cooperation tactics for multiple fighters to combat from beyond visual range (BVR) to within visual range (WVR)[J]. Journal of Northwestern Polytechnic University, 2011, 29 (6): 971- 977.
doi: 10.3969/j.issn.1000-2758.2011.06.026
|
| 2 |
LIU C , SUN S S , TAO C G , et al. Sliding mode control of multi-agent system with application to UAV air combat[J]. Computers & Electrical Engineering, 2021, 96 (A): 107491.
|
| 3 |
YAN C , XIANG X J , WANG C . Towards real-time path planning through deep reinforcement learning for a UAV in dynamic environments[J]. Journal of Intelligent & Robotic Systems, 2020, 98 (2): 297- 309.
doi: 10.1007/s10846-019-01073-3
|
| 4 |
王怀威, 李曙林, 陈宁, 等. 战术机动对飞机作战生存力的影响研究[J]. 飞行力学, 2011, 29 (3): 88- 91.
|
|
WANG H W , LI S L , CHEN N , et al. Research on the influence of tactic maneuver on aircraft combat survivability[J]. Flight Dynamics, 2011, 29 (3): 88- 91.
|
| 5 |
IMADO F , KURODA T . Family of local solutions in a missile-aircraft differential game[J]. Journal of Guidance, Control, and Dynamics, 2011, 34 (2): 583- 591.
doi: 10.2514/1.48345
|
| 6 |
YOMCHINDA T. A study of autonomous evasive planar-maneuver against proportional-navigation guidance missiles for unmanned aircraft[C]//Proc. of the Asian Conference on Defence Technology, 2015: 210-214.
|
| 7 |
GIRARD A R , KABAMBA P T . Proportional navigation: optimal homing and optimal evasion[J]. SIAM Review, 2015, 57 (4): 611- 624.
doi: 10.1137/130947301
|
| 8 |
FONOD R , SHIMA T . Multiple model adaptive evasion against a homing missile[J]. Journal of Guidance, Control, and Dyna-mics, 2016, 39 (7): 1578- 1592.
doi: 10.2514/1.G000404
|
| 9 |
CARR R W, COBB R. An energy based objective for solving an optimal missile evasion problem[C]//Proc. of the AIAA Gui-dance, Navigation, and Control Conference, 2017: 1016-1033.
|
| 10 |
邵彦昊, 朱荣刚, 贺建良, 等. 中远程空空雷达导弹的新机动规避方式的探索[J]. 弹箭与制导学报, 2020, 40 (4): 75- 84.
|
|
SHAO Y H , ZHU R G , HE J L , et al. Exploration of a new evasive maneuver mode for medium and long range air-to-air radar missile[J]. Journal of Projectiles, Rockets, Missiles and Guidance, 2020, 40 (4): 75- 84.
|
| 11 |
袁坤刚, 刘登第, 张志伟, 等. 空空导弹末端毁伤效能的仿真评估[C]//第13届中国系统仿真技术及其应用学术年会论文集, 2011: 679-682.
|
|
YUAN K G, LIU D D, ZHANG Z W, et al. Simulation evaluation of air-to-air missile terminal kill efficiency[C]//Proc. of the 13th Chinese Conference on System Simulation Technology and its Application, 2011: 679-682.
|
| 12 |
王光辉, 吕超, 谢宇鹏, 等. 歼击机规避空空导弹的评价算法[J]. 系统工程与电子技术, 2016, 38 (11): 2561- 2566.
|
|
WANG G H , LYU C , XIE Y P , et al. Evasive maneuver model of a fighter against air-to-air missiles[J]. Systems Engineering and Electronics, 2016, 38 (11): 2561- 2566.
|
| 13 |
WANG L G, YU C Q, ZHAO J, et al. Flight vehicle penetration probability evaluation against the missile intercepting[C]//Proc. of the International Conference on Intelligent Transportation, Big Data & Smart City, 2021: 13-16.
|
| 14 |
ONG S Y, PIERSON B L. Optimal evasive aircraft maneuvers against a surface-to-air missile[C]//Proc. of the IEEE Regional Conference on Aerospace Control Systems, 1993: 475-482.
|
| 15 |
SINGH L. Autonomous missile avoidance using nonlinear model predictive control[C]//Proc. of the AIAA Guidance, Navigation, and Control Conference and Exhibit, 2012: 4910-4924.
|
| 16 |
IMADO F , KURODA T . Engagement tactics for two missiles against an optimally maneuvering aircraft[J]. Journal of Gui-dance, Control, and Dynamics, 2011, 34 (2): 574- 582.
doi: 10.2514/1.49079
|
| 17 |
张斌, 何明, 陈希亮, 等. 改进DDPG算法在自动驾驶中的应用[J]. 计算机工程与应用, 2019, 55 (10): 264- 270.
doi: 10.3778/j.issn.1002-8331.1806-0324
|
|
ZHANG B , HE M , CHEN X L , et al. Self-driving via improved DDPG Algorithm[J]. Computer Engineering and Applications, 2019, 55 (10): 264- 270.
doi: 10.3778/j.issn.1002-8331.1806-0324
|
| 18 |
WU C X , JU B B , WU Y , et al. UAV autonomous target search based on deep reinforcement learning in complex disaster scene[J]. IEEE Access, 2019, 7, 117227- 117245.
doi: 10.1109/ACCESS.2019.2933002
|
| 19 |
HAN X, WANG J, XUE J Y, et al. Intelligent decision-making for 3-dimensional dynamic obstacle avoidance of uav based on deep reinforcement learning[C]//Proc. of the International Conference on Wireless Communications and Signal Processing, 2019.
|
| 20 |
SINGLE A , PADAKANDLA S , BHATNAGAR S . Memory-based deep reinforcement learning for obstacle avoidance in UAV with limited environment knowledge[J]. IEEE Trans.on Intelligent Transportation Systems, 2019, 22 (1): 107- 118.
|
| 21 |
YANG Q M , ZHANG J D , SHI G Q , et al. Maneuver decision of UAV in short-range air combat based on deep reinforcement learning[J]. IEEE Access, 2019, 8, 363- 378.
|
| 22 |
ZHANG Y S, ZU W, GAO Y, et al. Research on autonomous maneuvering decision of UCAV based on deep reinforcement learning[C]//Proc. of the Chinese Control and Decision Conference, 2018: 230-235.
|
| 23 |
范鑫磊, 李栋, 张尉, 等. 基于深度强化学习的导弹规避决策训练研究[J]. 电光与控制, 2021, 28 (1): 81- 85.
doi: 10.3969/j.issn.1671-637X.2021.01.018
|
|
FAN X L , LI D , ZHANG W , et al. Missile evasion decision training based on deep reinforcement learning[J]. Electronics Optics & Control, 2021, 28 (1): 81- 85.
doi: 10.3969/j.issn.1671-637X.2021.01.018
|
| 24 |
LILLICRAP T P, HUNT J J, PRITZEL A, et al. Continuous control with deep reinforcement learning[EB/OL]. [2022-04-30]. https://arxiv.org/abs/1509.02971.
|
| 25 |
宋宏川, 詹浩, 夏露, 等. 基于深度确定性策略梯度算法的战机规避中距空空导弹研究[J]. 航空工程进展, 2021, 12 (3): 85- 94.
|
|
SONG H C , ZHAN H , XIA L , et al. The study on a fighter against a medium-range air-to-air missile based on deep deterministic policy gradient algorithm[J]. Advances in Aeronautical Science and Engineering, 2021, 12 (3): 85- 94.
|
| 26 |
VAN H H, GUEZ A, SILVER D. Deep reinforcement learning with double Q-learning[C]//Proc. of the 30th AAAI Conference on Artificial Intelligence, 2016: 2094-2100.
|
| 27 |
肖扬, 吴家威, 李鉴学, 等. 一种基于深度强化学习的动态路由算法[J]. 信息通信技术与政策, 2020, 46 (9): 48- 54.
|
|
XIAO Y , WU J W , LI J X , et al. A dynamic routing algorithm based on deep reinforcement learning[J]. Information and Communications Technology and Policy, 2020, 46 (9): 48- 54.
|
| 28 |
卜令正. 基于深度强化学习的机械臂控制研究[D]. 北京: 中国矿业大学, 2019.
|
|
BU L Z. Study of robot arm control based on deep reinforcement learning[D]. Beijing: China University of Mining and Technology, 2019.
|
| 29 |
MNIH V , KAVUKCUOGLA K , SILVER D , et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518 (7540): 529- 533.
doi: 10.1038/nature14236
|
| 30 |
SILVER D, LEVER G, HEESS N, et al. Deterministic policy gradient algorithms[C]//Proc. of the 31st International Conference on Machine Learning, 2014, 32: 387-395.
|
| 31 |
KOSANOGLU F , ATMIS M , TURAN H H . A deep reinforcement learning assisted simulated annealing algorithm for a maintenance planning problem[J]. Annals of Operations Research, 2022,
doi: 10.1007/s10479-022-04612-8
|
| 32 |
LIU P F, QIU X P, HUANG X J. Recurrent neural network for text classification with multi-task learning[EB/OL]. [2022- 04-30]. https://arxiv.org/abs/1605.05101.
|
| 33 |
KYUNGHYUN C, BARTVAN M, CAGLAR G, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation[EB/OL]. [2022-04-30]. https://arxiv.org/abs/1406.1078.
|
| 34 |
WANG X F , ZHAO H , HAN T , et al. A Gaussian estimation of distribution algorithm with random walk strategies and its application in optimal missile guidance handover for multi-UCAV in over-the-horizon air combat[J]. IEEE Access, 2019, 7, 43298- 43317.
|
| 35 |
LI Q N, CHEN Y, HUANG Z Y, et al. An algorithm of air combat maneuver strategy based on two layer game decision-making and distributed MCTS method with double game trees under uncertain interval information conditions[C]//Proc. of the Chinese Control and Decision Conference, 2021: 6875-6880.
|
| 36 |
LIU Y P, GAO X, SHI J X, et al. Research on decision-making method of air combat embedded training based on extended influence diagram[C]//Proc. of the International Conference on Guidance, Navigation and Control, 2022: 4529-4541.
|
| 37 |
WANG Z , LI H , WU H L , et al. Improving maneuver strategy in air combat by alternate freeze games with a deep reinforcement learning algorithm[J]. Mathematical Problems in Engineering, 2020, 7180639.
|
| 38 |
YANG Z , ZHOU D , KONG W R , et al. Nondominated maneuver strategy set with tactical requirements for a fighter against missiles in a dogfight[J]. IEEE Access, 2020, 8, 117298- 117312.
|