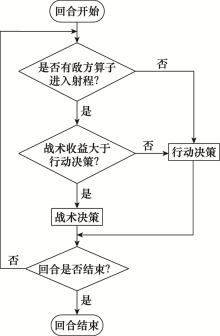
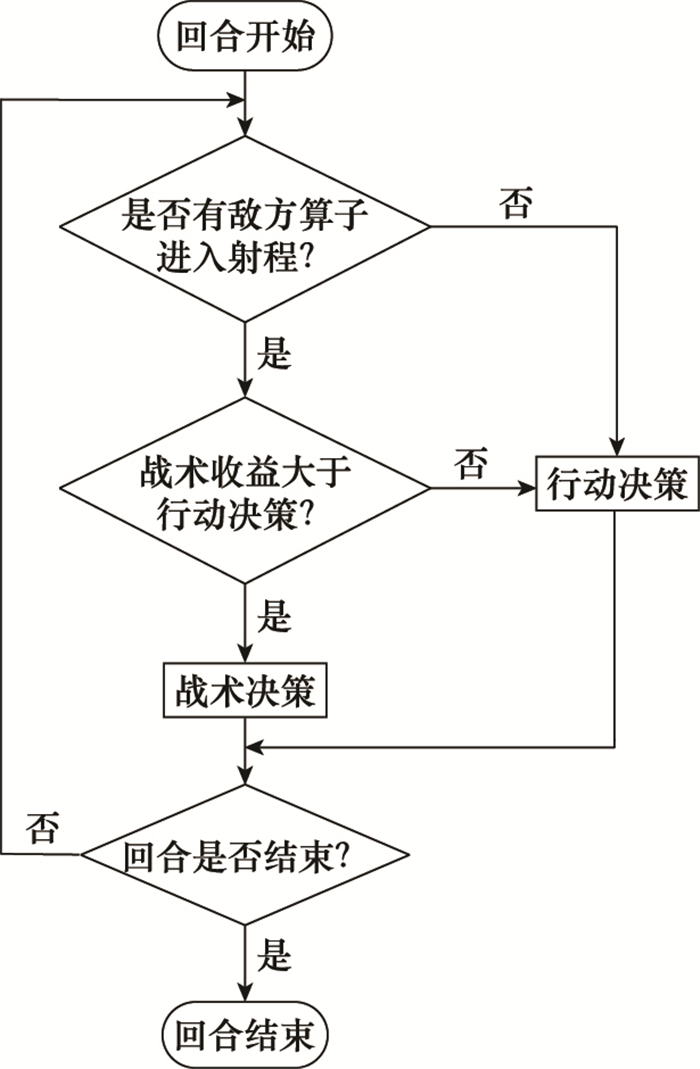
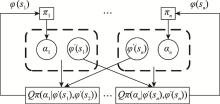
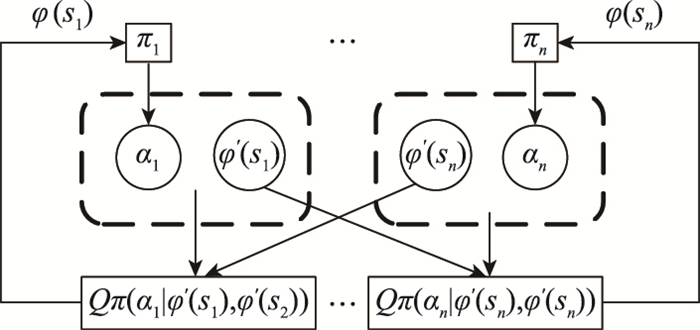
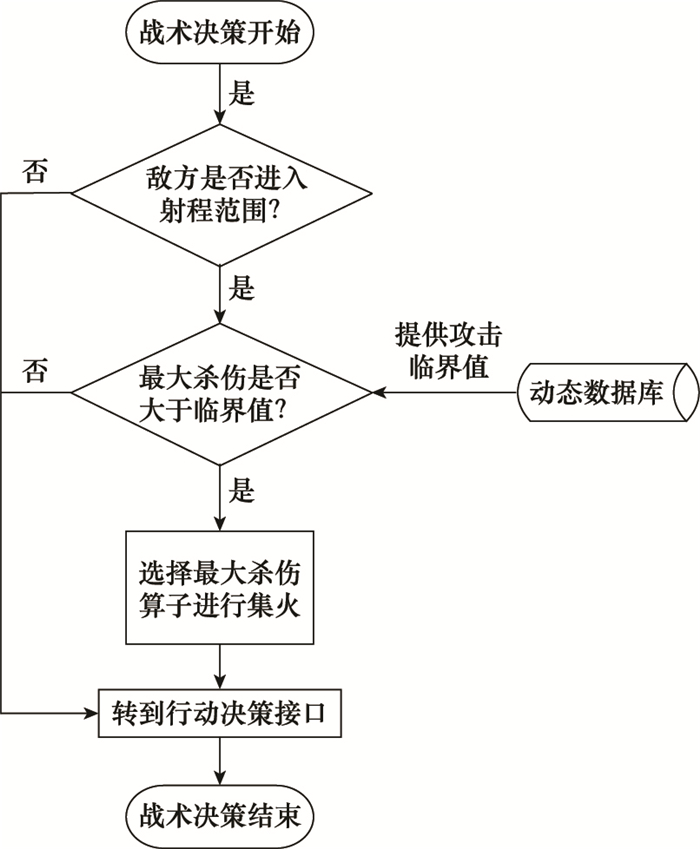
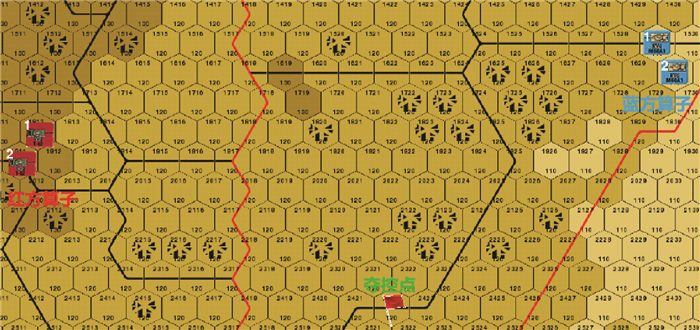
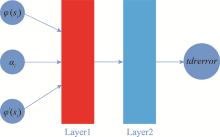
| 1 |
SILVER D , HUBERT T , SCHRITTWIESER J , et al. A gene-ral reinforcement learning algorithm that masters chess, shogi, and Go through self-play[J]. Science, 2018, 362 (6419): 1140- 1144.
doi: 10.1126/science.aar6404
|
| 2 |
SILVER D , HUANG A , MADDISON C , et al. Mastering the game of Go with deep neural networks and tree search[J]. Nature, 2016, 529 (7589): 484- 489.
|
| 3 |
LEVINE S , FINN C , DARRELL T , et al. End-to-end training of deep visuomotor policies[J]. Machine Learning Research, 2015, 17 (1): 1334- 1373.
|
| 4 |
ZHANG H D, LI D C, HE Y Q. Multi-robot cooperation strategy in game environment using deep reinforcement learning[C]//Proc.of the IEEE International Conference on Robotics and Biomime-tics (ROBIO), 2018: 886-891.
|
| 5 |
HISHMEH L, AWAD F. Deer in the headlights: short term planning via reinforcement learning algorithms for autonomous vehicles[C]//Proc.of the 11th International Conference on Information and Communication Systems, 2020: 255-260.
|
| 6 |
KONSTANTINOS M , MARIA K , IOANNIS N . Deep reinforcement-learning-based driving policy for autonomous road vehicles[J]. IET Intelligent Transport Systems, 2020, 14 (1): 13- 24.
doi: 10.1049/iet-its.2019.0249
|
| 7 |
MAKANTASIS K , KONTORINAKI M , NIKOLOS I . Deep reinforcement-learning-based driving policy for autonomous road vehicles[J]. IET Intelligence Transport Systems, 2020, 14 (1): 13- 24.
doi: 10.1049/iet-its.2019.0249
|
| 8 |
VINYALS O , BABUSCHKIN I , CZARNECKI W M , et al. Grandmaster level in starcraft Ⅱ using multi-agent reinforcement learning[J]. Nature, 2019, 575 (7782): 350- 369.
doi: 10.1038/s41586-019-1724-z
|
| 9 |
LAMPLE G, CHAPLOT D S. Playing FPS games with deep reinforcement learning[C]//Proc.of the Workshops at the AAAI Conference on Artificial Intelligence, 2017: 2140-2146.
|
| 10 |
FAN J S, REN H, TIAN C X. An analysis of wargame rules simulation based on stochastic lanchester models[C]//Proc.of the 6th International Conference on Network, Communication and Computing, Association for Computing Machinery, 2017: 135-139.
|
| 11 |
MOY G, SHEKH S. The application of alphazero to wargaming[C]//Proc.of the 32nd Australasian Joint Conference on Artificial Intelligence, 2019.
|
| 12 |
SHANG T F, DONG H Y, HAN K, et al. Research on evaluation method of wargame strategy based on fuzzy Petri net[C]//Proc.of the 2nd International Conference on Information Systems and Computer Aided Education, 2019: 626-629.
|
| 13 |
石崇林.基于数据挖掘的兵棋推演数据分析方法研究[D].长沙: 国防科学技术大学, 2012.
|
|
SHI C L. Research of wargaming data analysis methods based on data mining[D]. Changsha: National University of Defense Technology, 2012.
|
| 14 |
秦园丽, 张训立, 高桂清, 等. 基于兵棋推演系统的作战方案评估方法研究[J]. 兵器装备工程学报, 2019, 40 (6): 92- 95.
|
|
QIN Y L , ZHANG X L , GAO G Q , et al. Research on evaluation method of operational plan based on tactical missile chess deduction system[J]. Journal of Ordnance Equipment Engineering, 2019, 40 (6): 92- 95.
|
| 15 |
SHALABH B , RICHARD S S , MOHAMMAD G , et al. Na-tural actor-critic algorithms[J]. Automatica, 2009, 45 (11): 2471- 2482.
doi: 10.1016/j.automatica.2009.07.008
|
| 16 |
GRZES M. Reward shaping in episodic reinforcement leaning[C]//Proc.of the 16th International Conference on Autonomous Agents and Multiagent Systems, International Foundation for Autonomous Agents and Multiagent Systems, 2017: 565-573.
|
| 17 |
ZHONG S , TAN J , DONG H , et al. Modeling-learning-based actor-critic algorithm with gaussian process approximator[J]. Grid Computing, 2020, 18, 181- 195.
doi: 10.1007/s10723-020-09512-4
|
| 18 |
WATKINS C , DAYAN P . Q-learning[J]. Machine Learning, 1992, 8 (3/4): 279- 292.
doi: 10.1023/A:1022676722315
|
| 19 |
LITTMAN M L . Reinforcement learning improves behaviour from evaluative feedback[J]. Nature, 2015, 521 (7553): 445- 451.
doi: 10.1038/nature14540
|
| 20 |
SUTTON R S , BARTO A G . Reinforcement learning: an introduction[M]. 2nd ed U.K.: MIT Press, 2018.
|
| 21 |
LITTMAN M L . Markov games as a framework for multi-agent reinforcement learning[M]. New Brunswick: Machine Learning Proceedings, 1994: 157- 163.
|
| 22 |
PAULO C H , MOU S S . Distributed multi-agent reinforcement learning by actor-critic method[J]. IFAC Papers On Line, 2019, 52 (20): 363- 368.
doi: 10.1016/j.ifacol.2019.12.182
|
| 23 |
LIU Y X, TAN Y. Learning distributed coordinated policy in catching game with multi-agent reinforcement learning[C]//Proc.of the International Joint Conference on Neural Networks, 2019.
|
| 24 |
LECUN Y , BENGIO Y , HINTON G . Deep learning[J]. Nature, 2015, 521 (7533): 436- 444.
|
| 25 |
MNIH V , KAVUKCUOGLU K , SILVER D , et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518 (7540): 529- 533.
doi: 10.1038/nature14236
|
| 26 |
ETHAN D , GANGER M , HU W . Exploring deep reinforcement learning with multi-Q-learning[J]. Intelligent Control and Automation, 2016, 7 (4): 129- 144.
doi: 10.4236/ica.2016.74012
|
| 27 |
SILVER D , HUANG A , MADDISON C , et al. Mastering the game of Go with deep neural networks and tree search[J]. Nature, 2016, 529 (7587): 484- 489.
doi: 10.1038/nature16961
|
| 28 |
周志华. 机器学习[M]. 北京: 清华大学出版社, 2016: 347- 350.
|
|
ZHOU Z H . Machine learning[M]. Beijing: Tsinghua University Press, 2016: 347- 350.
|
| 29 |
闫科, 张永亮, 陶伟. 突破·铁甲指挥官[M]. 北京: 电子工业出版社, 2018.
|
|
YAN K , ZHANG Y L , TAO W . Breakthrough commander of iron armor[M]. Beijing: Electronic Industry Press, 2018.
|
| 30 |
LI L , LI D , SONG T , et al. Actor-Critic learning control based on regularized temporal-difference prediction with gra-dient correction[J]. IEEE Trans.on Neural Networks and Learning Systems, 2018, 29 (12): 5899- 5909.
doi: 10.1109/TNNLS.2018.2808203
|

 ), 黄炎焱1,*(
), 黄炎焱1,*(