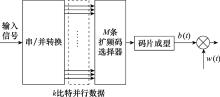
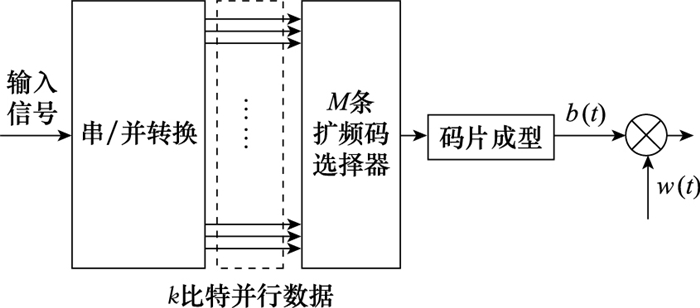
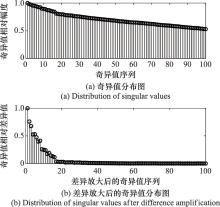
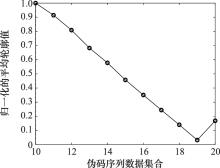
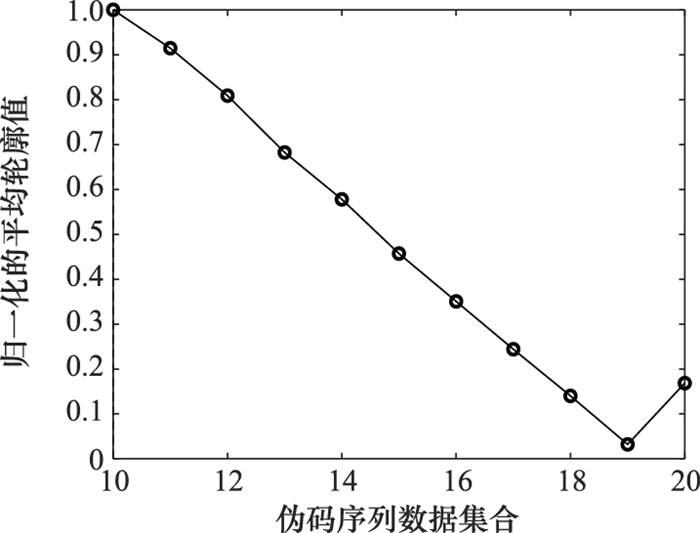
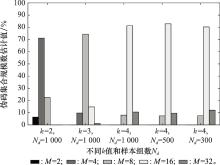
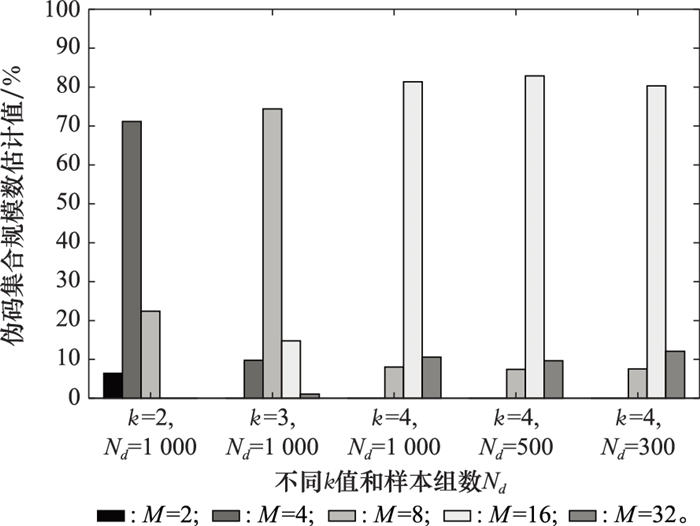
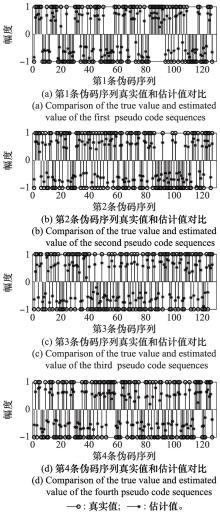
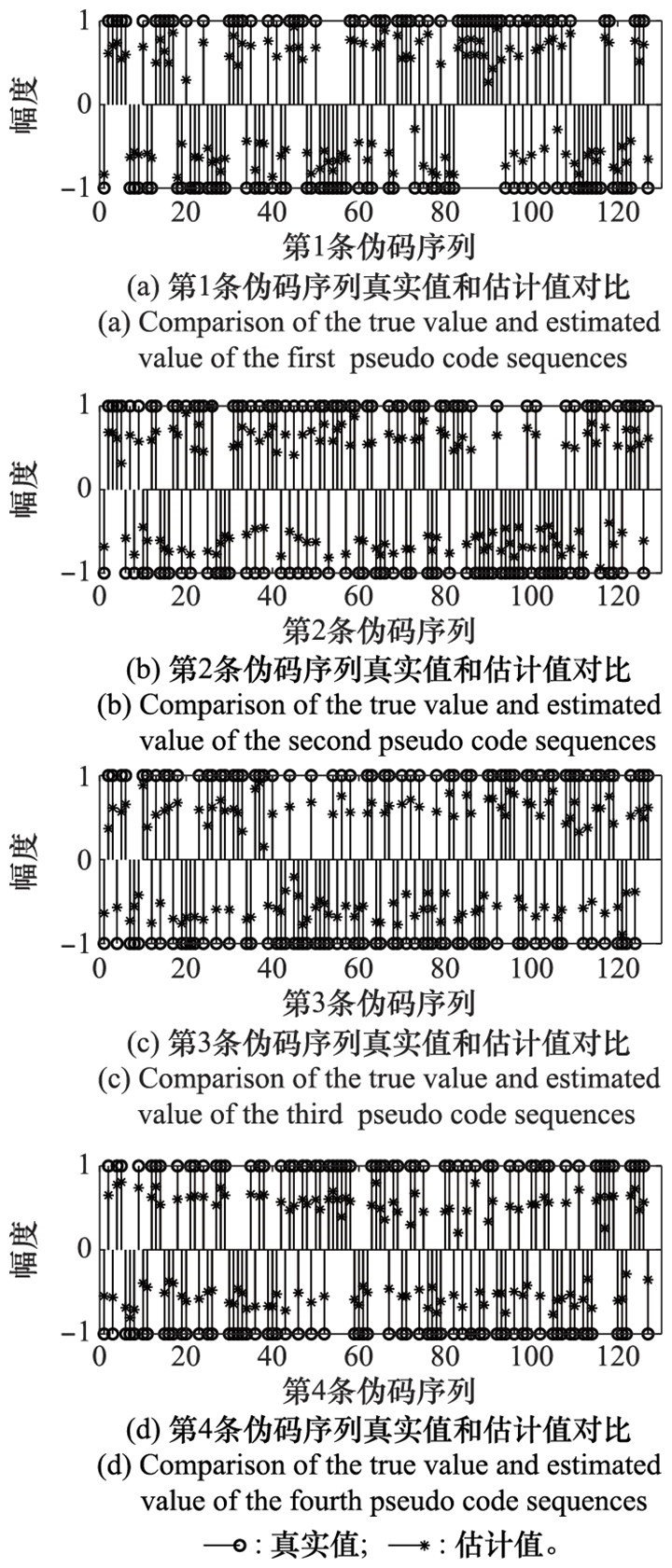
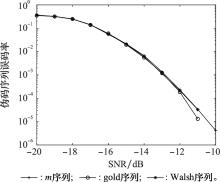
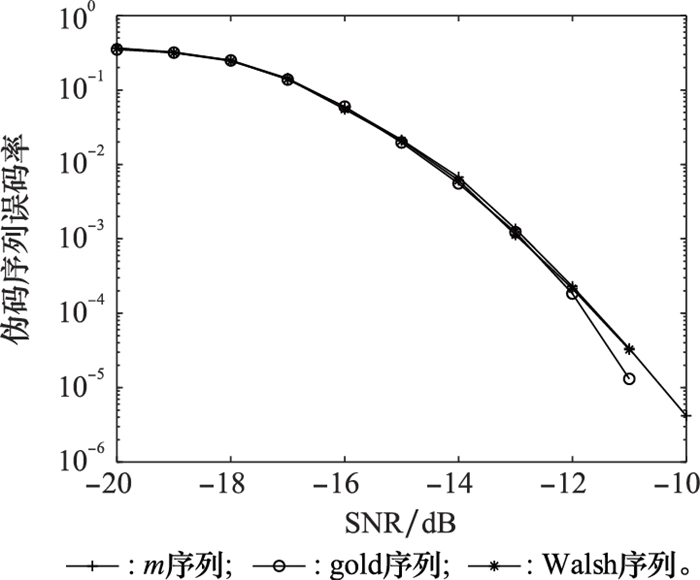
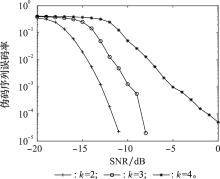
| 1 |
COOK C , MARSH H . An introduction to spread spectrum[J]. IEEE Communications Magazine, 1983, 21 (2): 8- 16.
doi: 10.1109/MCOM.1983.1091346
|
| 2 |
周佳晶, 唐友喜. JTIDS扩频序列的估计[J]. 电子科技大学学报, 2007, 36 (S2): 1054- 1056.
|
|
ZHOU J J , TANG Y X . Spread spectrum sequence estimation for JTIDS[J]. Journal of University of Electronic Science and Technology of China, 2007, 36 (S2): 1054- 1056.
|
| 3 |
PURSLEY M B , ROYSTER T C . High-rate direct-sequence spread spectrum with error control coding[J]. IEEE Trans.on Communications, 2006, 54 (9): 1693- 1702.
doi: 10.1109/TCOMM.2006.881256
|
| 4 |
WANG H, GUO X J, WANG Z J. Cluster-based blind estimation of mary DSSS signals[C]//Proc. of the IEEE International Conference on Communications, 2008: 5053-5057.
|
| 5 |
FUKASAWA A . Wideband CDMA system for personal radio communications[J]. IEEE Journal on Selected Areas in Communications, 1996, 34 (10): 32- 34.
|
| 6 |
QIU Z Y , PENG H , LI T Y . A blind despreading and demodulation method for QPSK-DSSS signal with unknown carrier offset based on matrix subspace analysis[J]. IEEE Access, 2019, 7, 125700- 125710.
doi: 10.1109/ACCESS.2019.2938785
|
| 7 |
QIANG X Z, ZHANG T Q. Estimation of spreading code in non-periodic long-code DSSS signal[C]//Proc. of the 6th International Conference on Wireless Communications, Signal Processing and Networking, 2021: 162-165.
|
| 8 |
LIU Q H, LI T Y, XU M K. Joint blind estimation of PN codes and channels for long-code DSSS signals in multiple paths at low SNR[C]//Proc. of the IEEE 20th International Conference on Communication Technology, 2020: 1266-1270.
|
| 9 |
GU X L , ZHAO Z J , SHEN L . Blind estimation of pseudo-random codes in periodic long code direct sequence spread spectrum signals[J]. IET Communications, 2016, 10 (11): 1273- 1281.
doi: 10.1049/iet-com.2015.0374
|
| 10 |
HUANG N J, GE Y Z, ZHANG X J, et al. Parameters blind estimation for underwater acoustic DSSS signal[C]//Proc. of the IEEE International Conference on Signal Processing, Communications and Computing, 2018.
|
| 11 |
QIU P Y, XU D, HUANG Z T, et al. Blind spreading sequence set estimation of the M-ary direct sequence spread spectrum signals[C]//Proc. of the IEEE International Conference on Wireless Communications, Networking and Information Security, 2010: 188-191.
|
| 12 |
LI J W, ZHANG T Q, YANG C S, et al. Clustering based blind estimation of PN sequences in M-ary spread spectrum system[C]//Proc. of the International Conference on Mechatronic Sciences, Electric Engineering and Computer, 2013: 866-869.
|
| 13 |
张天骐, 杨强, 宋玉龙, 等. 一种K-means改进算法的软扩频信号伪码序列盲估计[J]. 电子与信息学报, 2018, 40 (1): 226- 234.
|
|
ZHANG T Q , YANG Q , SONG Y L , et al. Blind estimation PN sequence in soft spread spectrum signal of improved K-means algorithm[J]. Journal of Electronics & Information Technology, 2018, 40 (1): 226- 234.
|
| 14 |
李丞, 张玉. 基于改进近邻传播算法的Walsh软扩频盲解扩方法[J]. 火力与指挥控制, 2019, 44 (3): 77- 81.
|
|
LI C , ZHANG Y . Blind despread method of walsh soft spread spectrum based on improved affinity propagation algorithm[J]. Fire Control & Command Control, 2019, 44 (3): 77- 81.
|
| 15 |
张丹娜, 杨晓静, 冯辉, 等. 改进Walsh码软扩频盲解扩算法[J]. 系统工程与电子技术, 2019, 41 (10): 2378- 2384.
|
|
ZHAGN D N , YANG X J , FENG H , et al. Improved Walsh code soft spread spectrum blind despreading algorithm[J]. Systems Engineering and Electronics, 2019, 41 (10): 2378- 2384.
|
| 16 |
李军伟, 张天骐, 潘毅, 等. 多进制扩频信号的伪码周期盲估计[J]. 光通信研究, 2013, (5): 53- 56.
|
|
LI J W , ZHANG T Q , PAN Y , et al. Blind period eatimation of PN sequence for M-ary spread spectrum signals[J]. Study on Optical Communications, 2013, (5): 53- 56.
|
| 17 |
戴月明, 王明慧, 张明, 等. SVD优化初始簇中心的K-means中文文本聚类算法[J]. 系统仿真学报, 2018, 30 (10): 3835- 3842.
|
|
DAI Y M , WANG M H , ZHANG M , et al. Optimizing initial cluster centroids by SVD in K-means algorithm for Chinese text clustering[J]. Journal of System Simulation, 2018, 30 (10): 3835- 3842.
|
| 18 |
张天骐, 方竹, 汪锐, 等. 窄带干扰及动态环境BOC调制信号多通道并行捕获[J]. 系统工程与电子技术, 2023, 45 (4): 1222- 1230.
|
|
ZHANG T Q , FANG Z , WANG R , et al. Multi-channel pa-rallel acquisition of BOC modulation signals in narrowband interference and dynamic environment[J]. Systems Engineering and Electronics, 2023, 45 (4): 1222- 1230.
|
| 19 |
王丽敏, 姬强, 韩旭明, 等. 基于奇异值分解的自适应近邻传播聚类算法[J]. 吉林大学学报(理学版), 2014, 52 (4): 753- 757.
|
|
WANG L M , JI Q , HAN X M , et al. Self-adaptive affinity propagation clustering algorithm based on singular value decomposition[J]. Journal of Jilin University (Science Edition), 2014, 52 (4): 753- 757.
|
| 20 |
SAADAT A , HOOSHMAND R A , KIYOUMARSI A , et al. Voltage sag source location in distribution networks with DGs using cosine similarity[J]. IEEE Trans.on Instrumentation and Measurement, 2022, 71, 1- 10.
|