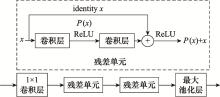
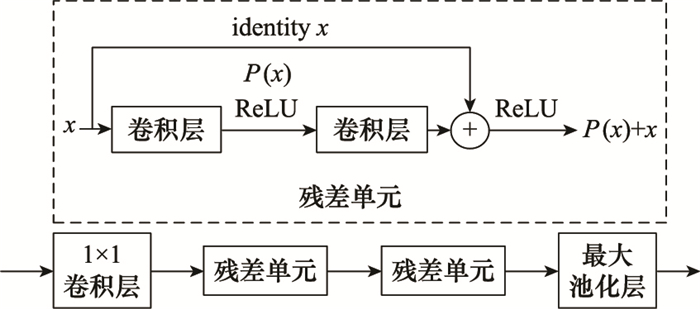
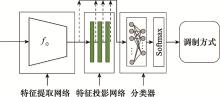
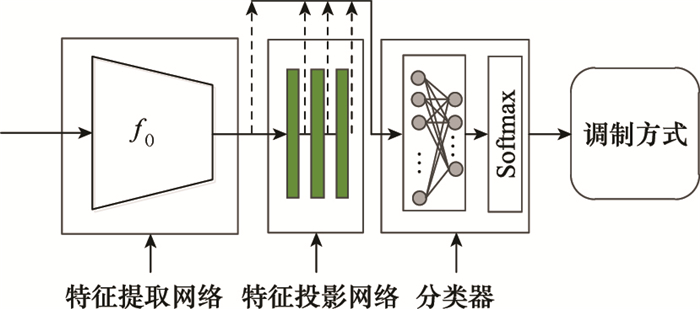
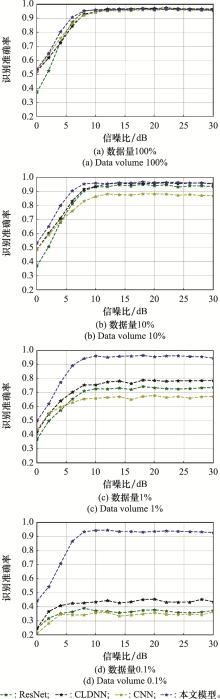
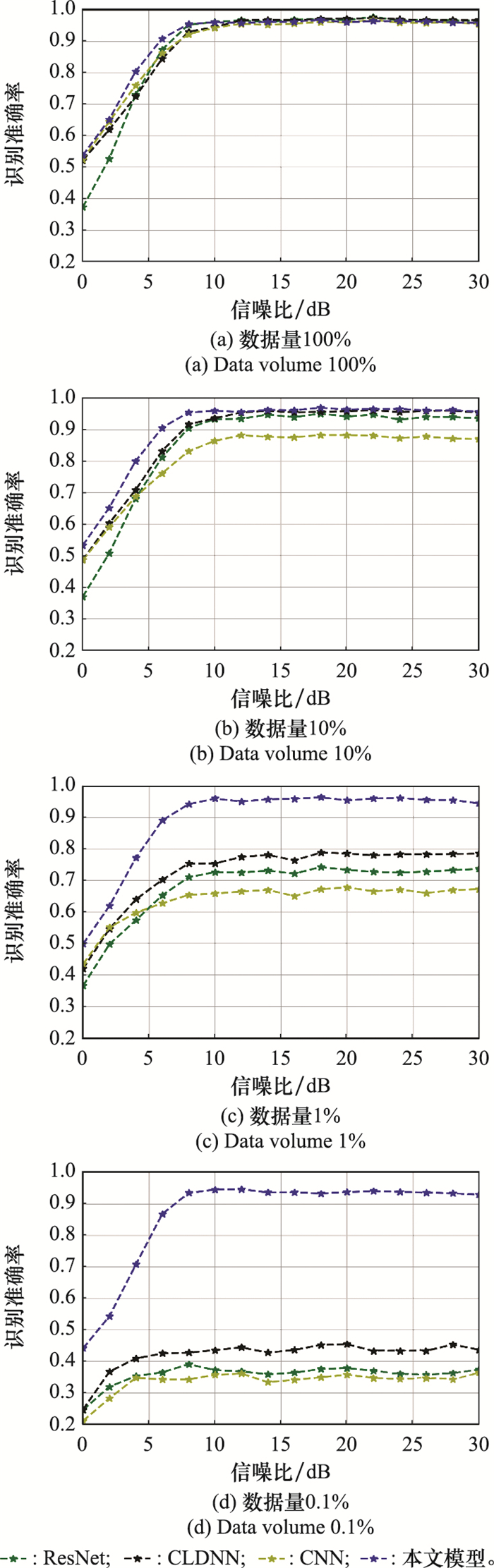
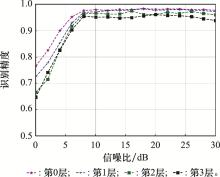
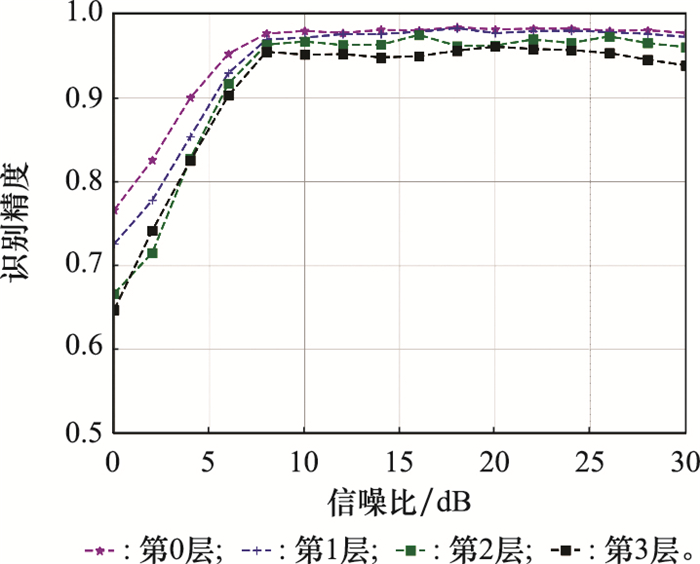
| 20 |
邵凯, 朱苗苗, 王光宇. 基于生成对抗与卷积神经网络的调制识别方法[J]. 系统工程与电子技术, 2022, 44 (3): 1036- 1043.
|
|
SHAO K , ZHU M M , WANG G Y . Modulation recognition method based on generative adversarial network[J]. Systems Engineering and Electronics, 2022, 44 (3): 1036- 1043.
|
| 21 |
OORD A, LI Y, VINYALS O. Representation learning with contrastive predictive coding[EB/OJ]. [2021-10-10]. https://arxiv.org/abs/1807.03748.
|
| 22 |
HE K M, FAN H Q, WU Y X, et al. Momentum contrast for unsupervised visual representation learning[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 9729-9738.
|
| 23 |
CHEN X L, FAN H Q, GIRSHICK R, et al. Improved baselines with momentum contrastive learning[EB/OJ]. [2021-10-10]. https://arxiv.org/abs/2003.04297.
|
| 24 |
CHEN X L, XIE S N, HE K. An empirical study of training self-supervised visual transformers[C]//Proc. of the IEEE/CVF Conference on Computer Vision, 2021: 9640-9649.
|
| 25 |
CHEN T, KORNBLITH S, NOROUZI M, et al. A simple framework for contrastive learning of visual representations[C]//Proc. of the 37th IEEE International Conference on Machine Learning, 2020: 1597-1607.
|
| 26 |
CHEN T , KORNBLITH S , SWERSKY K , et al. Big self-supervised models are strong semi-supervised learners[J]. Advances in neural information processing systems, 2020, 33, 22243- 22255.
|
| 27 |
NAIR V, HINTON G E. Rectified linear units improve restricted Boltzmann machines[C]//Proc. of the 27th IEEE International Conference on Machine Learning, 2010: 807-814.
|
| 28 |
LIN M, CHEN Q, YAN S C. Network in network[C]//Proc. of the International Conference on Learning Representations, 2014.
|
| 29 |
HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2016: 770-778.
|
| 30 |
SZEGEDY C, WEI L, JIA Y, et al. Going deeper with convolutions[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2015.
|
| 1 |
NANDI A K , AZZOUZ E E . Algorithms for automatic modulation recognition of communication signals[J]. IEEE Trans.on Communications, 1998, 46 (4): 431- 436.
doi: 10.1109/26.664294
|
| 2 |
AZZOUZ E E , NANDI A K . Automatic identification of digital modulation types[J]. Signal Processing, 1995, 47 (1): 55- 69.
doi: 10.1016/0165-1684(95)00099-2
|
| 3 |
HO K C , PROKOPIW W , CHAN Y T . Modulation identification of digital signals by the wavelet transform[J]. IEE Proceedings-Radar, Sonar and Navigation, 2002, 147 (4): 169- 176.
|
| 4 |
SWAMI A , SADLER B M . Hierarchical digital modulation classification using cumulants[J]. IEEE Trans.on Communications, 2000, 48 (3): 416- 429.
doi: 10.1109/26.837045
|
| 5 |
SHERME A E . A novel method for automatic modulation recognition[J]. Applied Soft Computing, 2012, 12 (1): 453- 461.
doi: 10.1016/j.asoc.2011.08.025
|
| 6 |
GARDNER W A. Cyclostationarity in communications and signal processing[R]. Yountville CA: Statistical Signal Processing Inc, 1994.
|
| 7 |
FEHSKE A, GAEDDERT J D, REED J H. A new approach to signal classification using spectral correlation and neural networks[C]//Proc. of the IEEE International Symposium on New Frontiers in Dynamic Spectrum Access Networks, 2005: 144-150.
|
| 8 |
BOUTTE D , SANTHANAM B . A hybrid ICA-SVM approach to continuous phase modulation recognition[J]. IEEE Signal Processing Letters, 2009, 16 (5): 402- 405.
doi: 10.1109/LSP.2009.2016444
|
| 9 |
王建新, 宋辉. 基于星座图的数字调制方式识别[J]. 通信学报, 2004, 25 (6): 166- 173.
|
|
WANG J X , SONG H . Digital modulation recognition based on constellation diagram[J]. Journal of Communications, 2004, 25 (6): 166- 173.
|
| 10 |
QUINLAN J R . Induction of decision trees[J]. Machine Learning, 1986, 1 (1): 81- 106.
|
| 11 |
CORTES C , VAPNIK V . Support-vector networks[J]. Machine Learning, 1995, 20 (3): 273- 297.
|
| 12 |
HEARST M A , DUMAIS S T , OSUNA E , et al. Support vector machines[J]. IEEE Intelligent Systems and their applications, 1998, 13 (4): 18- 28.
doi: 10.1109/5254.708428
|
| 13 |
LIPPMANN R . An introduction to computing with neural nets[J]. IEEE ASSP Magazine, 1987, 4 (2): 4- 22.
doi: 10.1109/MASSP.1987.1165576
|
| 14 |
O'SHEA T J, CORGAN J, CLANCY T C. Convolutional radio modulation recognition networks[C]//Proc. of the International Conference on Engineering Applications of Neural Networks, 2016: 213-226.
|
| 15 |
WEST N E, O'SHEA T. Deep architectures for modulation recognition[C]//Proc. of the IEEE International Symposium on Dynamic Spectrum Access Networks, 2017.
|
| 16 |
O'SHEA T J , ROY T , CLANCY T C . Over-the-air deep learning based radio signal classification[J]. IEEE Journal of Selected Topics in Signal Processing, 2018, 12 (1): 168- 179.
doi: 10.1109/JSTSP.2018.2797022
|
| 17 |
查雄, 彭华, 秦鑫, 等. 基于多端卷积神经网络的调制识别方法[J]. 通信学报, 2019, 40 (11): 30- 37.
|
|
ZHA X , PENG H , QIN X , et al. Modulation recognition method based on multi-inputs convolution neural network[J]. Journal of Communications, 2019, 40 (11): 30- 37.
|
| 18 |
查雄, 彭华, 秦鑫, 等. 基于循环神经网络的卫星幅相信号调制识别与解调算法[J]. 电子学报, 2019, 47 (11): 2443- 2448.
|
|
ZHA X , PENG H , QIN X , et al. Satellite amplitude-phase signals modulation identification and demodulation algorithm based on the cyclic neural network[J]. Acta Electronica Sinica, 2019, 47 (11): 2443- 2448.
|
| 19 |
周鑫, 何晓新, 郑文昌. 基于图像深度学习的无线电信号识别[J]. 通信学报, 2019, 40 (7): 114- 125.
|
|
ZHOU X , HE X X , ZHENG W C . Radio signal recognition based on image deep learning[J]. Journal of Communications, 2019, 40 (7): 114- 125.
|