Systems Engineering and Electronics ›› 2024, Vol. 46 ›› Issue (8): 2641-2649.doi: 10.12305/j.issn.1001-506X.2024.08.12
• Sensors and Signal Processing • Previous Articles
Infrared and visible light image fusion based on convolution and self attention
Xiaoxuan CHEN1, Shuwen XU2, Shaohai HU1,*, Xiaole MA1
- 1. School of Computer and Information Technology, Beijing Jiaotong University, Beijing 100044, China
2. Research Institute of TV and Electro-Acoustics, China Electronics Technology Group Corporation, Beijing 100015, China
-
Received:2023-05-29Online:2024-07-25Published:2024-08-07 -
Contact:Shaohai HU
CLC Number:
Cite this article
Xiaoxuan CHEN, Shuwen XU, Shaohai HU, Xiaole MA. Infrared and visible light image fusion based on convolution and self attention[J]. Systems Engineering and Electronics, 2024, 46(8): 2641-2649.
share this article
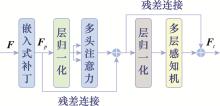
Fig.1
Structure of self attention mechanism"

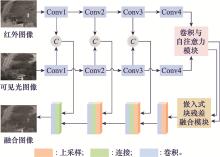
Fig.2
The proposed model"
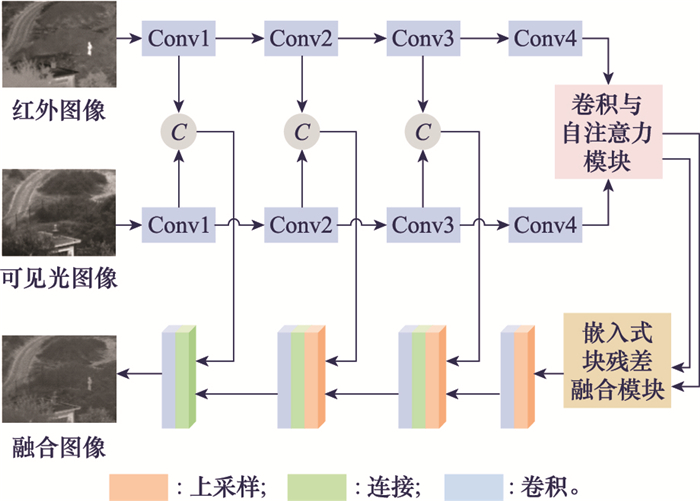
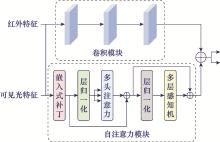
Fig.3
Structure of convolution and self attention module"

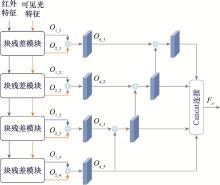
Fig.4
Structure of embedded block residual fusion module"
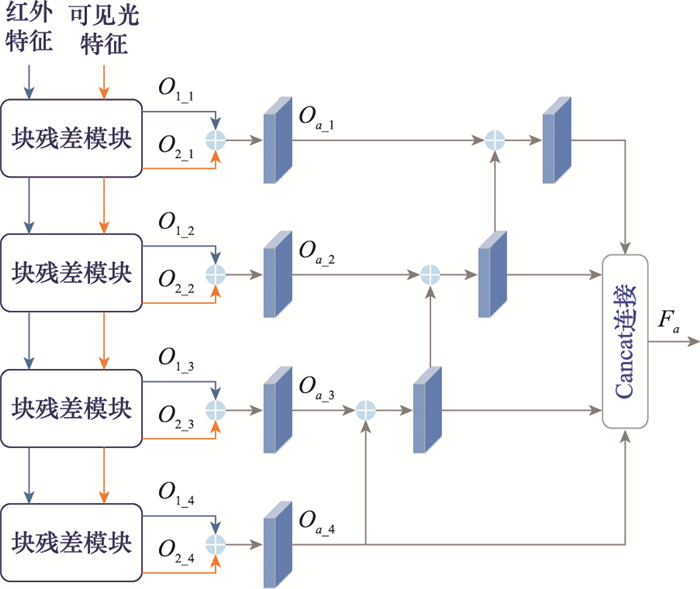
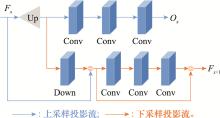
Fig.5
Structure of block residual module"
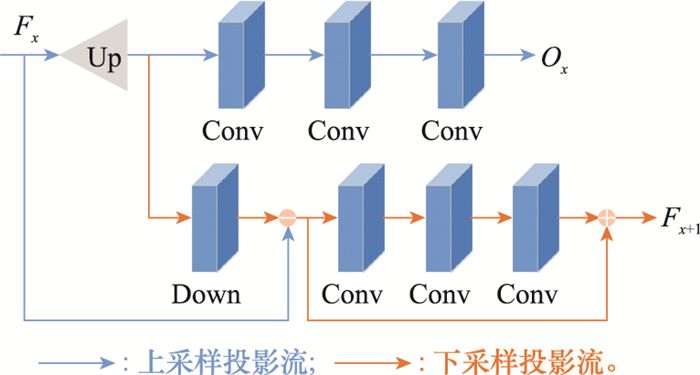

Fig.6
Comparison results of partial fusion images"

Table 1
Comparison of objective metrics of different fused images on TNO dataset"
| 算法 | CC | EN | FMI_w | MI | SD | VIF |
| CVT[ | 0.474 3 | 6.431 4 | 0.433 4 | 1.575 7 | 8.309 2 | 0.599 6 |
| NSCT[ | 0.481 7 | 6.419 2 | 0.448 0 | 1.679 7 | 8.294 3 | 0.688 8 |
| Wavelet[ | 0.487 8 | 6.295 0 | 0.360 0 | 1.774 3 | 8.194 3 | 0.619 6 |
| MSVD[ | 0.493 8 | 6.227 6 | 0.303 5 | 1.877 8 | 8.140 3 | 0.613 5 |
| GTF[ | 0.322 8 | 6.635 3 | 0.436 2 | 2.422 5 | 8.684 0 | 0.565 6 |
| DenseFuse[ | 0.499 4 | 6.174 0 | 0.417 7 | 2.143 4 | 8.100 6 | 0.608 8 |
| DeepFuse[ | 0.498 7 | 6.756 3 | 0.422 2 | 2.226 8 | 8.796 1 | 0.778 2 |
| FusionDN[ | 0.460 2 | 7.395 5 | 0.362 7 | 2.162 2 | 9.537 5 | 0.862 3 |
| U2Fusion[ | 0.501 0 | 6.757 1 | 0.362 0 | 1.804 5 | 9.011 0 | 0.751 4 |
| 本文算法 | 0.478 0 | 6.557 7 | 0.504 1 | 3.592 5 | 9.672 3 | 0.929 7 |
Table 2
Comparison of objective metrics of different fused images on LLVIP dataset"
| 算法 | CC | EN | FMI_w | MI | SD | VIF |
| CVT[ | 0.699 8 | 6.539 9 | 0.361 0 | 2.124 4 | 8.409 2 | 0.778 5 |
| NSCT[ | 0.702 7 | 6.539 3 | 0.393 2 | 2.238 0 | 7.334 6 | 0.891 9 |
| Wavelet[ | 0.709 5 | 6.475 8 | 0.325 0 | 2.421 5 | 8.384 1 | 0.799 0 |
| MSVD[ | 0.646 8 | 6.405 5 | 0.261 3 | 2.604 9 | 8.374 5 | 0.790 1 |
| GTF[ | 0.578 7 | 6.519 0 | 0.343 8 | 3.338 8 | 8.553 3 | 0.764 7 |
| DenseFuse[ | 0.716 0 | 6.377 2 | 0.311 6 | 2.998 3 | 8.398 8 | 0.792 1 |
| DeepFuse[ | 0.700 8 | 6.523 1 | 0.338 3 | 2.789 5 | 8.274 7 | 0.877 1 |
| FusionDN[ | 0.672 4 | 6.198 9 | 0.320 3 | 2.626 1 | 8.550 7 | 0.893 3 |
| U2Fusion[ | 0.696 0 | 5.942 9 | 0.283 5 | 2.351 3 | 8.102 0 | 0.639 4 |
| 本文算法 | 0.698 1 | 6.753 4 | 0.416 3 | 3.7140 | 8.680 1 | 0.894 2 |
Table 3
Comparison of objective metrics of different fused images on M3FD dataset"
| 算法 | CC | EN | FMI_w | MI | SD | VIF |
| CVT[ | 0.577 2 | 6.643 8 | 0.388 4 | 2.155 7 | 8.925 2 | 0.802 4 |
| NSCT[ | 0.583 1 | 6.606 4 | 0.420 6 | 2.477 9 | 8.919 2 | 0.904 8 |
| Wavelet[ | 0.582 7 | 6.531 7 | 0.351 0 | 2.548 2 | 8.879 3 | 0.746 2 |
| MSVD[ | 0.582 0 | 6.444 8 | 0.276 3 | 2.678 5 | 8.805 5 | 0.738 4 |
| GTF[ | 0.455 5 | 7.298 9 | 0.400 9 | 3.860 2 | 9.809 0 | 0.769 6 |
| DenseFuse[ | 0.585 7 | 6.420 4 | 0.384 4 | 2.860 9 | 8.195 1 | 0.733 3 |
| DeepFuse[ | 0.568 0 | 6.592 7 | 0.410 3 | 3.012 1 | 9.394 0 | 0.908 2 |
| FusionDN[ | 0.560 7 | 7.460 6 | 0.342 0 | 3.023 2 | 9.974 6 | 0.934 0 |
| U2Fusion[ | 0.572 4 | 6.926 0 | 0.344 4 | 2.757 4 | 9.479 8 | 0.929 9 |
| 本文算法 | 0.563 9 | 7.626 1 | 0.495 9 | 3.948 3 | 9.506 7 | 0.943 8 |
Table 4
Ablation experiments on TNO dataset"
| 实验类型 | 对照设置 | CC | EN | M3FD | MI | SD | VIF |
| 特征提取模块的消融实验 | 卷积模块 | 0.459 8 | 6.740 4 | 0.451 1 | 2.087 7 | 8.650 2 | 0.762 7 |
| 卷积与自注意力模块 | 0.418 0 | 6.557 7 | 0.504 1 | 3.592 5 | 9.672 3 | 0.929 7 | |
| 融合模块的消融实验 | 相加 | 0.477 6 | 6.695 9 | 0.403 4 | 2.079 8 | 8.526 6 | 0.650 7 |
| 自注意力机制 | 0.476 2 | 6.723 0 | 0.441 1 | 2.387 7 | 8.649 5 | 0.794 3 | |
| 相加式块残差融合模块 | 0.476 2 | 6.857 8 | 0.496 8 | 3.590 4 | 9.669 6 | 0.929 3 | |
| 嵌入式块残差融合模块 | 0.418 | 6.557 7 | 0.504 1 | 3.592 5 | 9.672 3 | 0.929 7 | |
| 损失函数超参数的消融实验 | 600 | 0.459 3 | 6.556 8 | 0.497 1 | 3.585 8 | 9.658 8 | 0.927 9 |
| 500 | 0.473 1 | 6.732 5 | 0.499 7 | 3.580 4 | 9.599 7 | 0.903 2 | |
| 400 | 0.491 7 | 6.551 2 | 0.502 2 | 3.580 2 | 9.532 5 | 0.890 9 | |
| 300本文算法 | 0.41 8 | 6.557 7 | 0.504 1 | 3.592 5 | 9.672 3 | 0.929 7 |

Fig.7
Subjective comparisons of the detection results between source and fused images by five object detection models on "gate""

| 1 | 李舒涵, 许宏科, 武治宇. 基于红外与可见光图像融合的交通标志检测[J]. 现代电子技术, 2020, 43 (3): 45- 49. |
| LI S H , XU H K , WU Z Y . Traffic sign detection based on infrared and visible image fusion[J]. Modern Electronics Technique, 2020, 43 (3): 45- 49. | |
| 2 |
BIKASH M , SANJAY A , RUTUPARNA P , et al. A survey on region based imagefusion methods[J]. Information Fusion, 2019, 48, 119- 132.
doi: 10.1016/j.inffus.2018.07.010 |
| 3 | 李霖, 王红梅, 李辰凯. 红外与可见光图像深度学习融合方法综述[J]. 红外与激光工程, 2022, 51 (12): 337- 356. |
| LI L , WANG H M , LI C K . A review of deep learning fusion methods for infrared and visible images[J]. Infrared and Laser Engineering, 2022, 51 (12): 337- 356. | |
| 4 | 王新赛, 冯小二, 李明明. 基于能量分割的空间域图像融合算法研究[J]. 红外技术, 2022, 44 (7): 726- 731. |
| WANG X S , FENG X E , LI M M . Research on spatial domain image fusion algorithm based on energy segmentation[J]. Infrared Technology, 2022, 44 (7): 726- 731. | |
| 5 |
LIU Y , CHEN X , PENG H , et al. Multi-focus image fusion with a deep convolutional neural network[J]. Information Fusion, 2017, 36, 191- 207.
doi: 10.1016/j.inffus.2016.12.001 |
| 6 | RAM P K, SAI S V, VENKATESH B R. DeepFuse: a deep unsupervised approach for exposure fusion with extreme exposure image pairs[C]//Proc. of the IEEE International Conference on Computer Vision, 2017: 4714-4722. |
| 7 |
MA J Y , YU W , LIANG P W , et al. FusionGAN: a generative adversarial network for infrared and visible image fusion[J]. Information Fusion, 2019, 48, 11- 26.
doi: 10.1016/j.inffus.2018.09.004 |
| 8 | XU H, MA J Y, LE Z L, et al. FusionDN: a unified densely connected network for image fusion[C]//Proc. of the AAAI Conference on Artificial Intelligence, 2020: 12484-12491 |
| 9 |
XIAO B , XU B C , BI X L , et al. Global-feature encoding U-Net (GEU-Net) for multi-focus image fusion[J]. IEEE Trans. on Image Processing, 2021, 30, 163- 175.
doi: 10.1109/TIP.2020.3033158 |
| 10 |
FANG Y M , YAN J B , LI L D , et al. No reference quality assessment for screen content images with both local and global feature representation[J]. IEEE Trans. on Image Processing, 2018, 27 (4): 1600- 1610.
doi: 10.1109/TIP.2017.2781307 |
| 11 | QU L H, LIU S L, WANG M N, et al. TransMEF: a transformer-based multi-exposure image fusion framework using self-supervised multi-task learning[C]//Proc. of the AAAI Conference on Artificial Intelligence, 2022: 2126-2134. |
| 12 |
MA J Y , TANG L F , FAN F , et al. SwinFusion: cross-domain long-range learning for general image fusion via swin transformer[J]. IEEE/CAA Journal of Automatica Sinica, 2022, 9 (7): 1200- 1217.
doi: 10.1109/JAS.2022.105686 |
| 13 |
TANG W , HE F Z , LIU Y , et al. DATFuse: infrared and visible image fusion via dual attention transformer[J]. IEEE Trans. on Circuits and System for Video Technology, 2023, 33 (7): 3159- 3172.
doi: 10.1109/TCSVT.2023.3234340 |
| 14 | PENG Z L, HUANG W, GU S Z, et al. Conformer: local features coupling global representations for visual recognition[C]//Proc. of the IEEE/CVF International Conference on Computer Vision, 2021: 367-376. |
| 15 | WANG J X , XI X L , LI D M , et al. FusionGRAM: an infrared and visible image fusion framework based on gradient residual and attention mechanism[J]. IEEE Trans. on Instrumentation and Measurement, 2023, 72, 5005412. |
| 16 | QIU Y J, WANG R X, TAO D P, et al. Embedded block residual network: a recursive restoration model for single-image super-resolution[C]//Proc. of the IEEE/CVF International Conference on Computer Vision, 2019: 4179-4188. |
| 17 |
TOET A . The TNO multiband image data collection[J]. Data in Brief, 2017, 15, 249- 251.
doi: 10.1016/j.dib.2017.09.038 |
| 18 | JIA X Y, ZHU C, LI M Z, et al. LLVIP: a visible-infrared paired dataset for low-light vision[C]//Proc. of the IEEE International Conference on Computer Vision, 2021: 3496-3504. |
| 19 | LIU J Y, FAN X, HUANG Z B, et al. Target-aware dual adversarial learning and a multi-scenario multi-modality benchmark to fuse infrared and visible for object detection[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022: 5802-5811. |
| 20 | EMADALDEN A, UZAIR A B, HUANG M X, et al. Image fusion based on discrete cosine transform with high compression[C]//Proc. of the 7th International Conference on Signal and Image Processing, 2022: 606-610. |
| 21 |
ZHU Z Q , ZHENG M Y , QI G Q , et al. A phase congruency and local laplacian energy based multi-modality medical image fusion method in NSCT domain[J]. IEEE Access, 2019, 7, 20811- 20824.
doi: 10.1109/ACCESS.2019.2898111 |
| 22 | GUO H, CHEN J Y, YANG X, et al. Visible-infrared image fusion based on double-density wavelet and thermal exchange optimization[C]//Proc. of the IEEE 5th Advanced Information Technology, Electronic and Automation Control Conference, 2021: 2151-2154. |
| 23 |
NAIDU VPS . Image fusion technique using multi-resolution singular value decomposition[J]. Defence Science Journal, 2011, 61, 479- 484.
doi: 10.14429/dsj.61.705 |
| 24 |
MA J Y , CHEN C , LI C , et al. Infrared and visible image fusion via gradient transfer and total variation minimization[J]. Information Fusion, 2016, 31, 100- 109.
doi: 10.1016/j.inffus.2016.02.001 |
| 25 |
LI H , WU X J . DenseFuse: a fusion approach to infrared and visible images[J]. IEEE Trans. on Image Processing, 2019, 28 (5): 2614- 2623.
doi: 10.1109/TIP.2018.2887342 |
| 26 |
XU H , MA J Y , JIANG J J , et al. U2Fusion: a unified unsupervised image fusion network[J]. IEEE Trans. on Pattern Analysis and Machine Intelligence, 2022, 44 (1): 502- 518.
doi: 10.1109/TPAMI.2020.3012548 |
| 27 | LIU W, DRAGOMIR A, DUMITRU E, et al. SSD: single shot multibox detector[C]//Proc. of the European Conference on Computer Vision, 2016: 21-37. |
| 28 |
REN S Q , HE K M , GIRSHICK R , et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE. on Pattern Analysis and Machine Intelligence, 2017, 39 (6): 1137- 1149.
doi: 10.1109/TPAMI.2016.2577031 |
| 29 | REDMON J, FARHAD A. Yolov3: an incremental improvement[EB/OL]. [2023-05-29]. http://arxiv.org/pdf/1804.02767 |
| 30 | ALEXEY B, WANG C Y, LIAO H Y. Yolov4: optimal speed and accuracy of object detection[EB/OL]. [2023-05-29]. https://arxiv.org/abs/2004.10934. |
| 31 | GE Z, LIU S T, WANG F, et al. Yolox: exceeding Yolo series in 2021[EB/OL]. [2023-05-29]. https://arxiv.org/abs/2107.08430. |
| [1] | Qianglong WANG, Xiaoguang GAO, Bicong WU, Zijian HU, Kaifang WAN. Review of research on restricted Boltzmann machine and its variants [J]. Systems Engineering and Electronics, 2024, 46(7): 2323-2345. |
| [2] | Xiantao SUN, Wangyang JIANG, Wenjie CHEN, Weihai CHEN, Yali ZHI. Object grasp pose detection based on the region of interest [J]. Systems Engineering and Electronics, 2024, 46(6): 1867-1877. |
| [3] | Xuemei CHEN, Zhiheng LIU, Suiping ZHOU, Hang YU, Yanming LIU. Road extraction from high-resolution remote sensing images based on HRNet [J]. Systems Engineering and Electronics, 2024, 46(4): 1167-1173. |
| [4] | Tianwen ZHANG, Xiaoling ZHANG, Zikang SHAO, Tianjiao ZENG. Mask attention interaction for SAR ship instance segmentation [J]. Systems Engineering and Electronics, 2024, 46(3): 831-838. |
| [5] | Yali ZHANG, Wei FENG, Yinghui QUAN, Mengdao XING. Ship recognition algorithm based on multi-level collaborative fusion of multi-source remote sensing images [J]. Systems Engineering and Electronics, 2024, 46(2): 407-418. |
| [6] | Duanyang SHI, Qiang LIN, Bing HU, Xiaoshuai DU. Target detection method of primary surveillance radar based on YOLO [J]. Systems Engineering and Electronics, 2024, 46(1): 143-151. |
| [7] | Meng WANG, Bing ZHU. Application of uncertainty modeling in 2D and 3D object detection [J]. Systems Engineering and Electronics, 2023, 45(8): 2370-2376. |
| [8] | Huiying WANG, Chunping WANG, Qiang FU, Zishuo HAN, Dongdong ZHANG. Infrared and low illumination image fusion based on image features [J]. Systems Engineering and Electronics, 2023, 45(8): 2395-2404. |
| [9] | Kai SHAO, Ziqun DU, Guangyu WANG. CSI feedback method for dynamically adjusting compression rate based on model pruning [J]. Systems Engineering and Electronics, 2023, 45(8): 2615-2622. |
| [10] | Tianshu CUI, Dong WANG, Zhen HUANG. Automatic modulation classification based on lightweight network for space cognitive communication [J]. Systems Engineering and Electronics, 2023, 45(7): 2220-2226. |
| [11] | Yu JIANG, Qi YUAN, Zhitao HU, Weiwei WU, Xin GU. Airport arrival and departure delay time prediction based on meteorological factors [J]. Systems Engineering and Electronics, 2023, 45(6): 1722-1731. |
| [12] | Yang CHEN, Canhui LIAO, Kun ZHANG, Jian LIU, Pengju WANG. A signal modulation indentification algorithm based on self-supervised contrast learning [J]. Systems Engineering and Electronics, 2023, 45(4): 1200-1206. |
| [13] | Ye ZHANG, Yi HOU, Kewei OUYANG, Shilin ZHOU. Survey of univariate sequence data classification methods [J]. Systems Engineering and Electronics, 2023, 45(2): 313-335. |
| [14] | Zhengtu SHAO, Dengrong XU, Wenli XU, Hanzhong WANG. Radar active jamming recognition based on LSTM and residual network [J]. Systems Engineering and Electronics, 2023, 45(2): 416-423. |
| [15] | Renfei CHEN, Yong PENG, Zhongwen LI. A novel detector for floating objects based on continual unsupervised domain adaptation strategy [J]. Systems Engineering and Electronics, 2023, 45(11): 3391-3401. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||