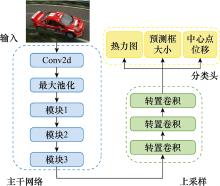
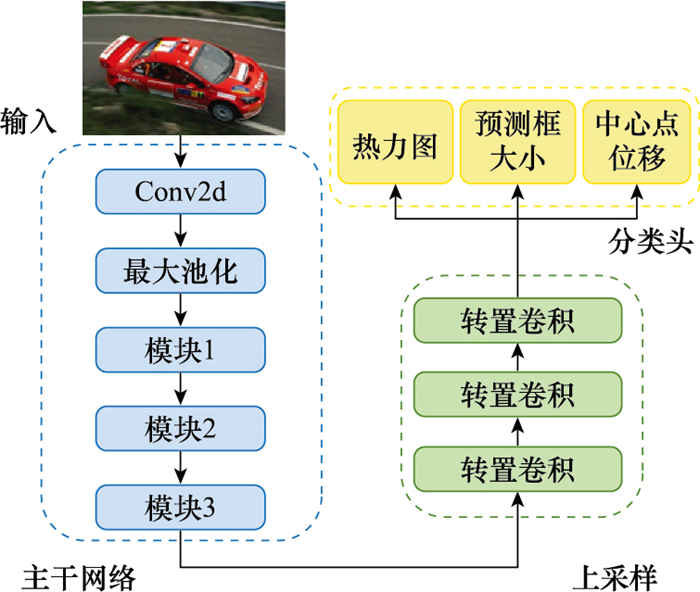
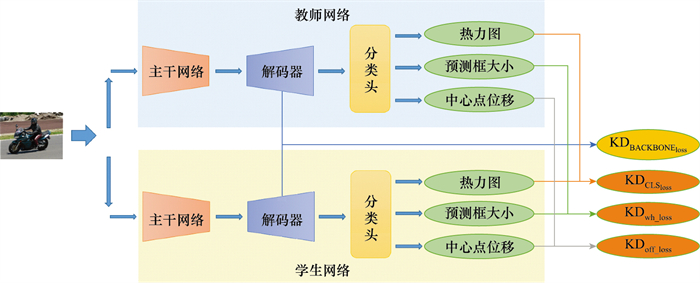
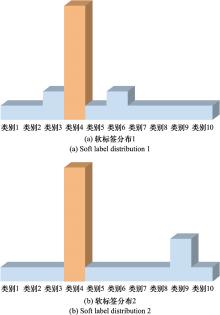
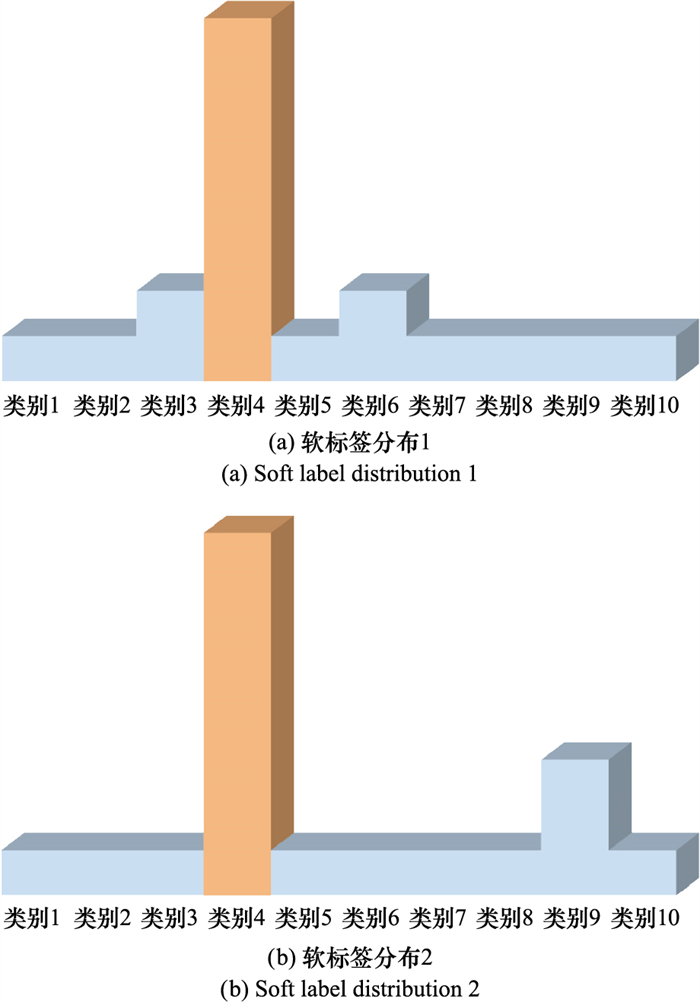
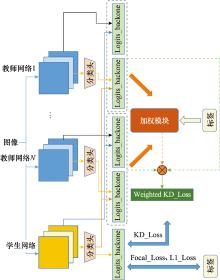
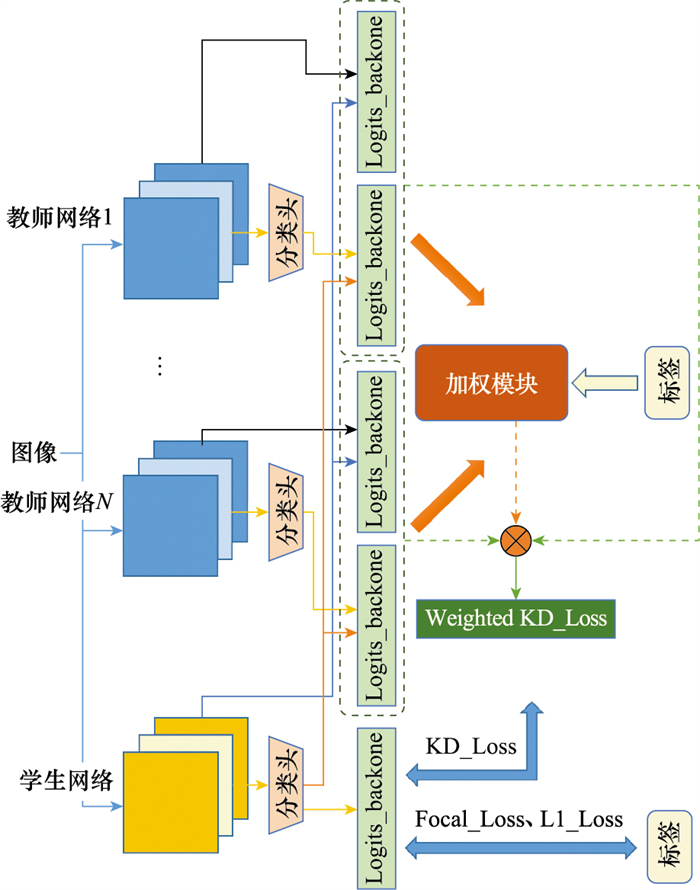
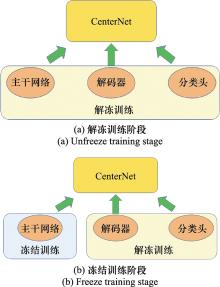
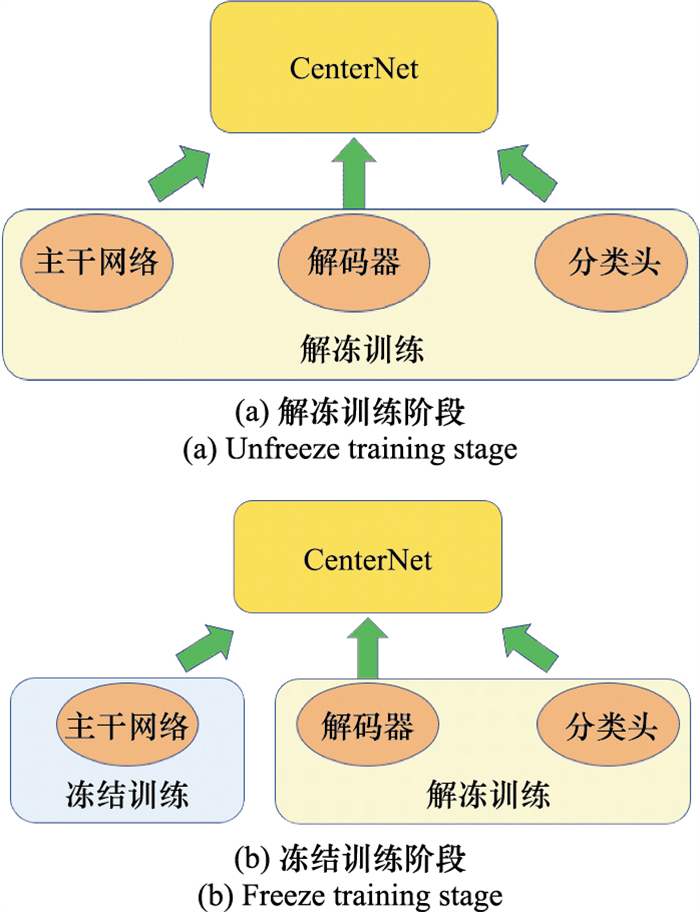
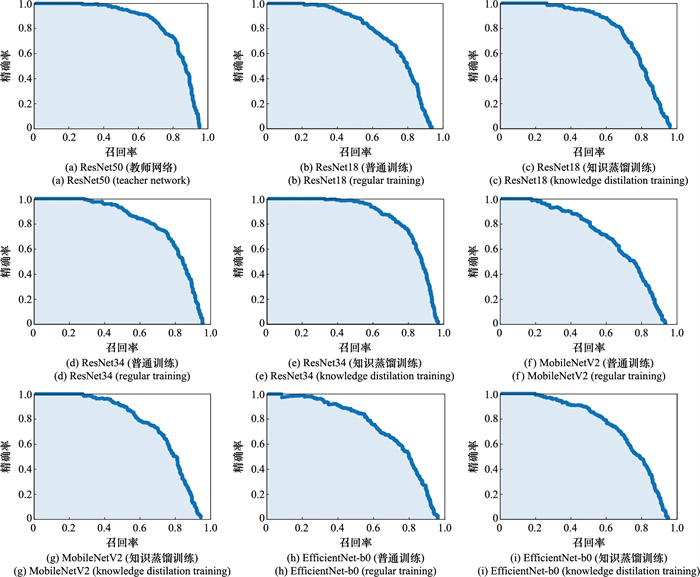
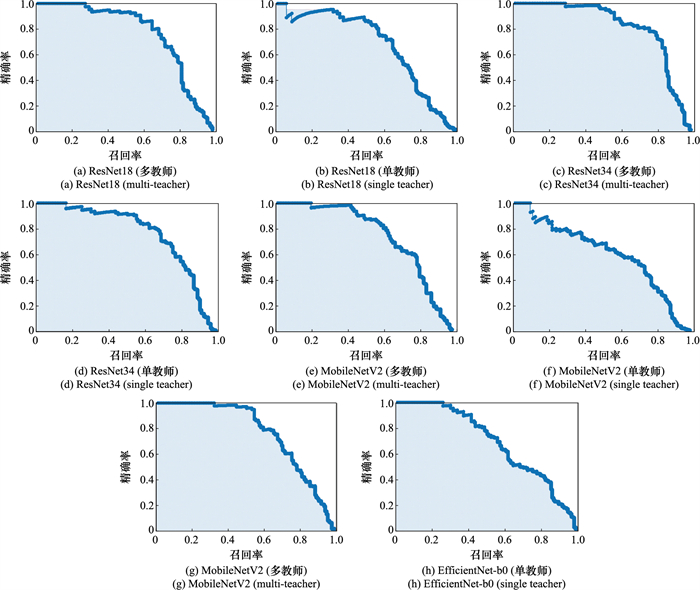
| 1 |
HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2016: 770-778.
|
| 2 |
NEWELL A, YANG K Y, DENG J. Stacked hourglass networks for human pose estimation[C]///Proc. of the 14th European Conference, 2016: 483-499.
|
| 3 |
DENG J, DONG W, SOCHER R, et al. ImageNet: a large-scale hierarchical image database[C]///Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2009: 248-255.
|
| 4 |
GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2014: 580-587.
|
| 5 |
PURKAIT P, ZHAO C, ZACH C. SPP-Net: deep absolute pose regression with synthetic views[EB/OL]. [2023-05-04]. https://arxiv.org/abs/1712.03452.
|
| 6 |
REN S , HE K , GIRSHICK R , et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Trans.on Pattern Analysis and Machine Intelligence, 2017, 39 (6): 1137- 1149.
doi: 10.1109/TPAMI.2016.2577031
|
| 7 |
REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 6517-6525.
|
| 8 |
FARHADI A, REDMON J. Yolov3: an incremental improvement[C]//Proc. of the Computer Vision and Pattern Recognition, 2018.
|
| 9 |
LAW H , DENG J . CornerNet: detecting objects as paired keypoints[J]. International Journal of Computer Vision, 2020, 128 (3): 642- 656.
doi: 10.1007/s11263-019-01204-1
|
| 10 |
ZHOU X Y, WANG D Q, KRAHENBUHL P. Objects as points[EB/OL]. [2023-05-04]. https://arxiv.org/abs/1904.07850.
|
| 11 |
ZHOU X Y, ZHUO J C, KRAHENBUHL P. Bottom-up object detection by grouping extreme and center points[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 850-859.
|
| 12 |
ZHANG X Y, ZHOU X Y, LIN M X, et al. ShuffleNet: an extremely efficient convolutional neural network for mobile devices[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2018: 6848-6856.
|
| 13 |
SANDLER M, HOWARD A, ZHU M L, et al. MobileNetv2: inverted residuals and linear bottlenecks[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2018: 4510-4520.
|
| 14 |
TAN M X, LE Q. EfficientNet: rethinking model scaling for convolutional neural networks[C]//Proc. of the International Conference on Machine Learning, 2019: 6105-6114.
|
| 15 |
JIAO X Q, YIN Y C, SHANG L F, et al. Tinybert: distilling BERT for natural language understanding[EB/OL]. [2023-05-04]. https://arxiv.org/abs/1909.10351.
|
| 16 |
HAN K, WANG Y H, TIAN Q, et al. Ghostnet: more features from cheap operations[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 1580-1589.
|
| 17 |
SUN Z Q, YU H K, SONG X D, et al. MobileBERT: a compact task-agnostic bert for resource-limited devices[EB/OL]. [2023-05-04]. https://arxiv.org/abs/2004.02984.
|
| 18 |
ABRAHAMYAN L, ZIATCHIN V, CHEN Y M, et al. Bias loss for mobile neural networks[C]//Proc. of the IEEE/CVF International Conference on Computer Vision, 2021: 6556-6566.
|
| 19 |
CHEN Y P, DAI X Y, CHEN D D, et al. Mobile-former: bridging mobilenet and transformer[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022: 5270-5279.
|
| 20 |
黄震华, 杨顺志, 林威, 等. 知识蒸馏研究综述[J]. 计算机学报, 2022, 45 (3): 624- 653.
|
|
HUANG Z H , YANG S Z , LIN W , et al. Knowledge distilation: a survey[J]. Chinese Journal of Computers, 2022, 45 (3): 624- 653.
|
| 21 |
HINTON G , VINYALS O , DEAN J . Distilling the knowledge in a neural network[J]. Computer Science, 2015, 14 (7): 38- 39.
|
| 22 |
FURLANELLO T, LIPTON Z, TSCHANNEN M, et al. Born again neural networks[C]//Proc. of the International Conference on Machine Learning, 2018: 1607-1616.
|
| 23 |
CHO J H, HARIHARAN B. On the efficacy of knowledge distillation[C]//Proc. of the IEEE/CVF International Conference on Computer Vision, 2019: 4794-4802.
|
| 24 |
URBAN G, GERAS K J, KAHOU S E, et al. Do deep convolutional nets really need to be deep and convolutional?[EB/OL]. [2023-05-04]. https://arxiv.org/abs/1603.05691.
|
| 25 |
TANG Z Y, WANG D, ZHANG Z Y. Recurrent neural network training with dark knowledge transfer[C]//Proc. of the IEEE International Conference on Acoustics, Speech and Signal Processing, 2016: 5900-5904.
|
| 26 |
YUAN L, TAY F E H, LI G L, et al. Revisiting knowledge distillation via label smoothing regularization[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 3903-3911.
|
| 27 |
VAPNIK V , VASHIST A . A new learning paradigm: learning using privileged information[J]. Neural Networks, 2009, 22 (5/6): 544- 557.
|
| 28 |
PHUONG M, LAMPERT C. Towards understanding know-ledge distillation[C]//Proc. of the International Conference on Machine Learning, 2019: 5142-5151.
|
| 29 |
CHENG X, RAO Z F, CHEN Y L, et al. Explaining know-ledge distillation by quantifying the knowledge[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 12925-12935.
|
| 30 |
LIN S H, XIE H W, WANG B, et al. Knowledge distillation via the target-aware transformer[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022: 10915-10924.
|
| 31 |
YANG Z D, LI Z, JIANG X H, et al. Focal and global know-ledge distillation for detectors[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022: 4643-4652.
|
| 32 |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[J]. Advances in Neural Information Processing Systems[EB/OL]. [2023-05-04]. https://arxiv.org/abs/1706.03762.
|