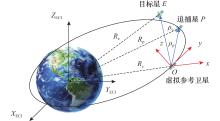
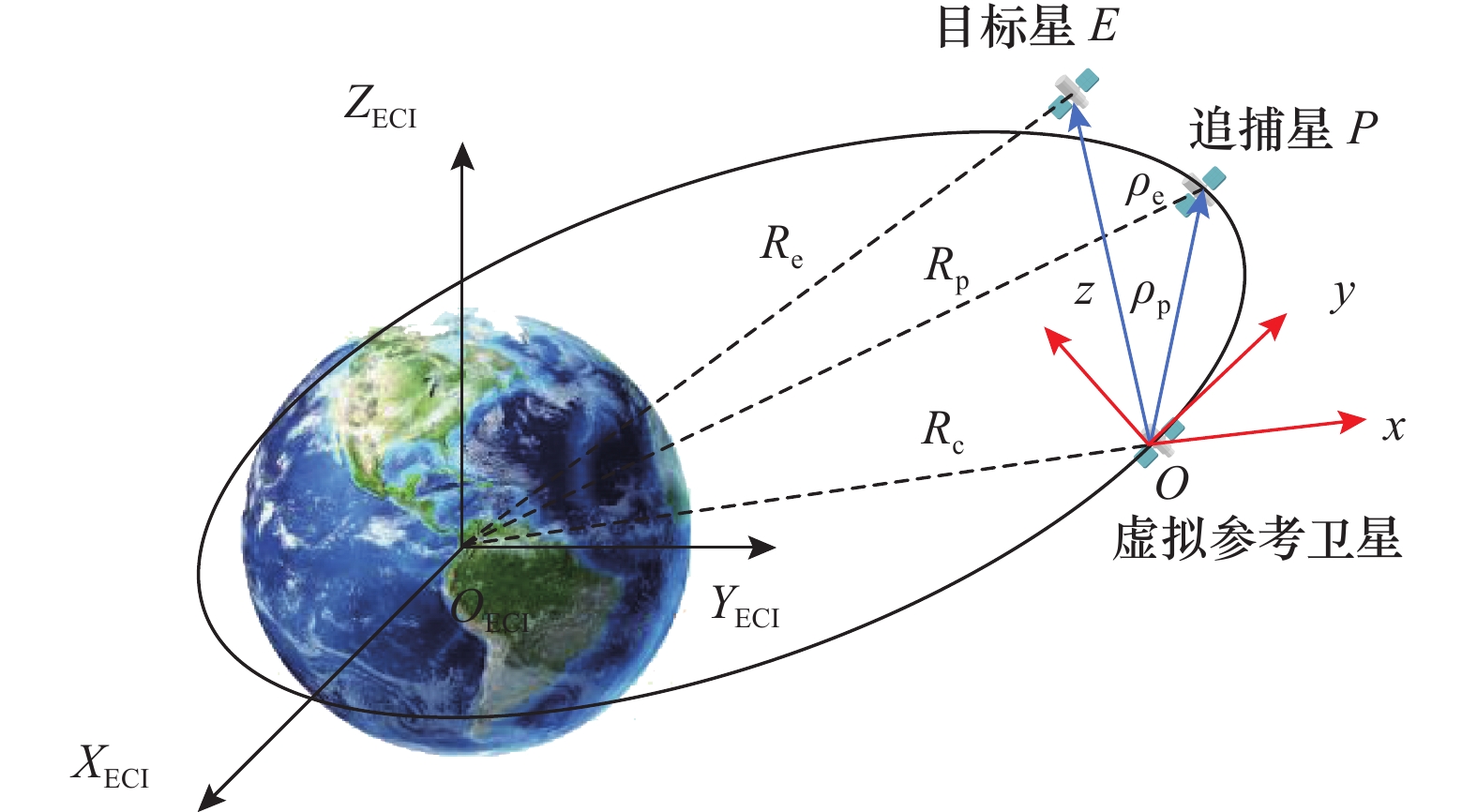
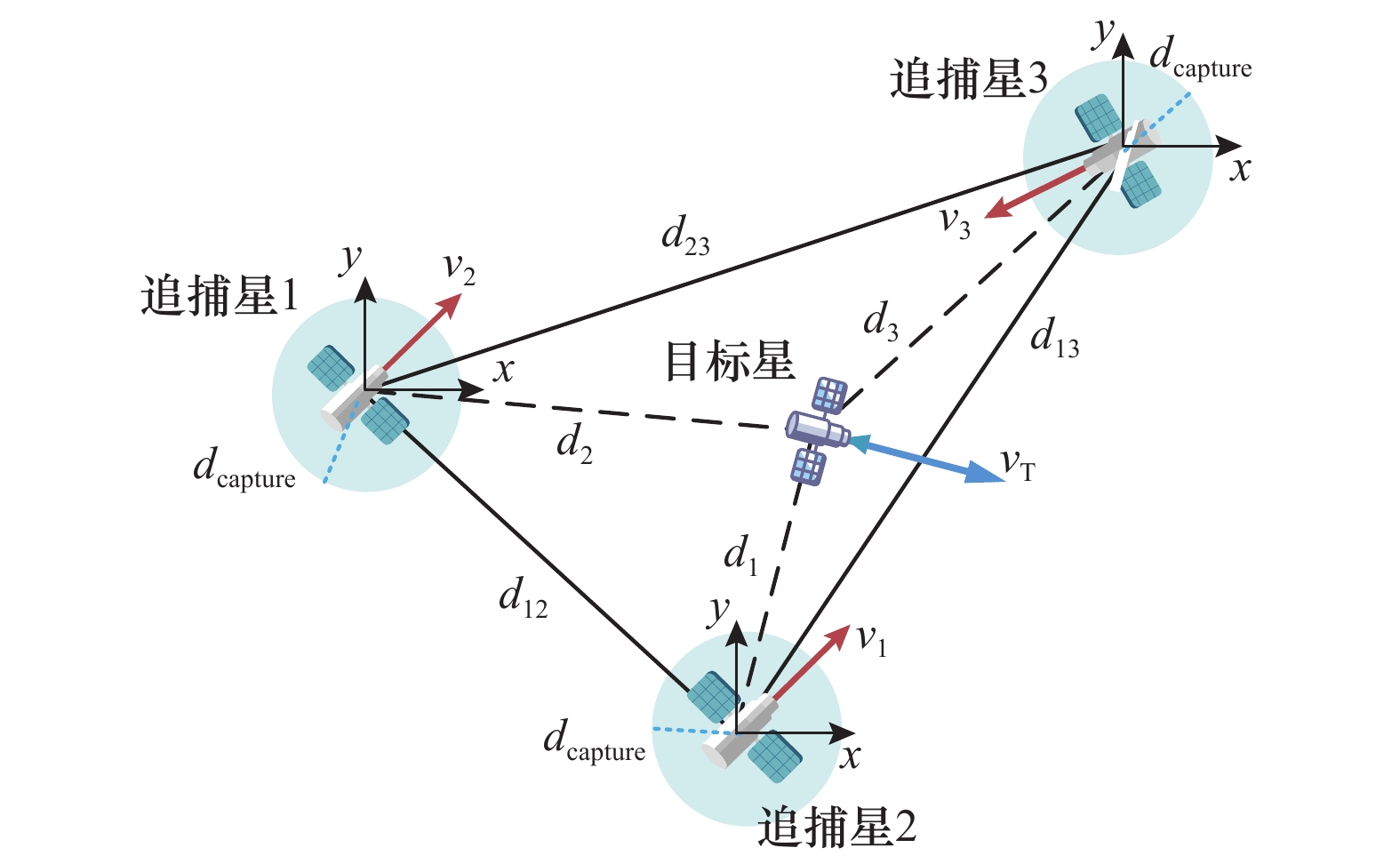
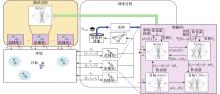
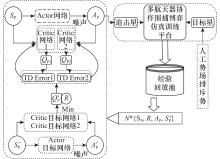
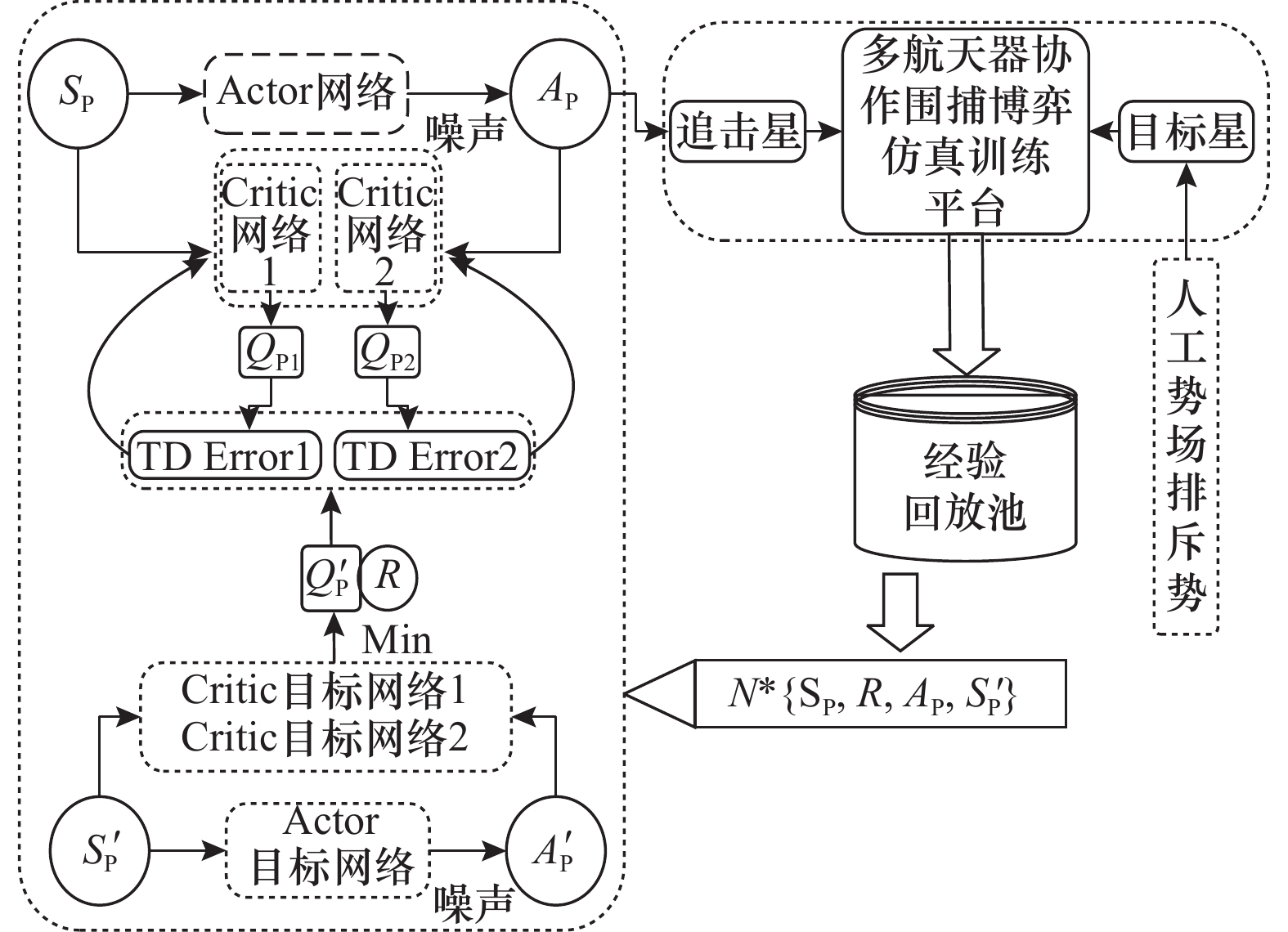
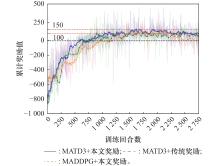
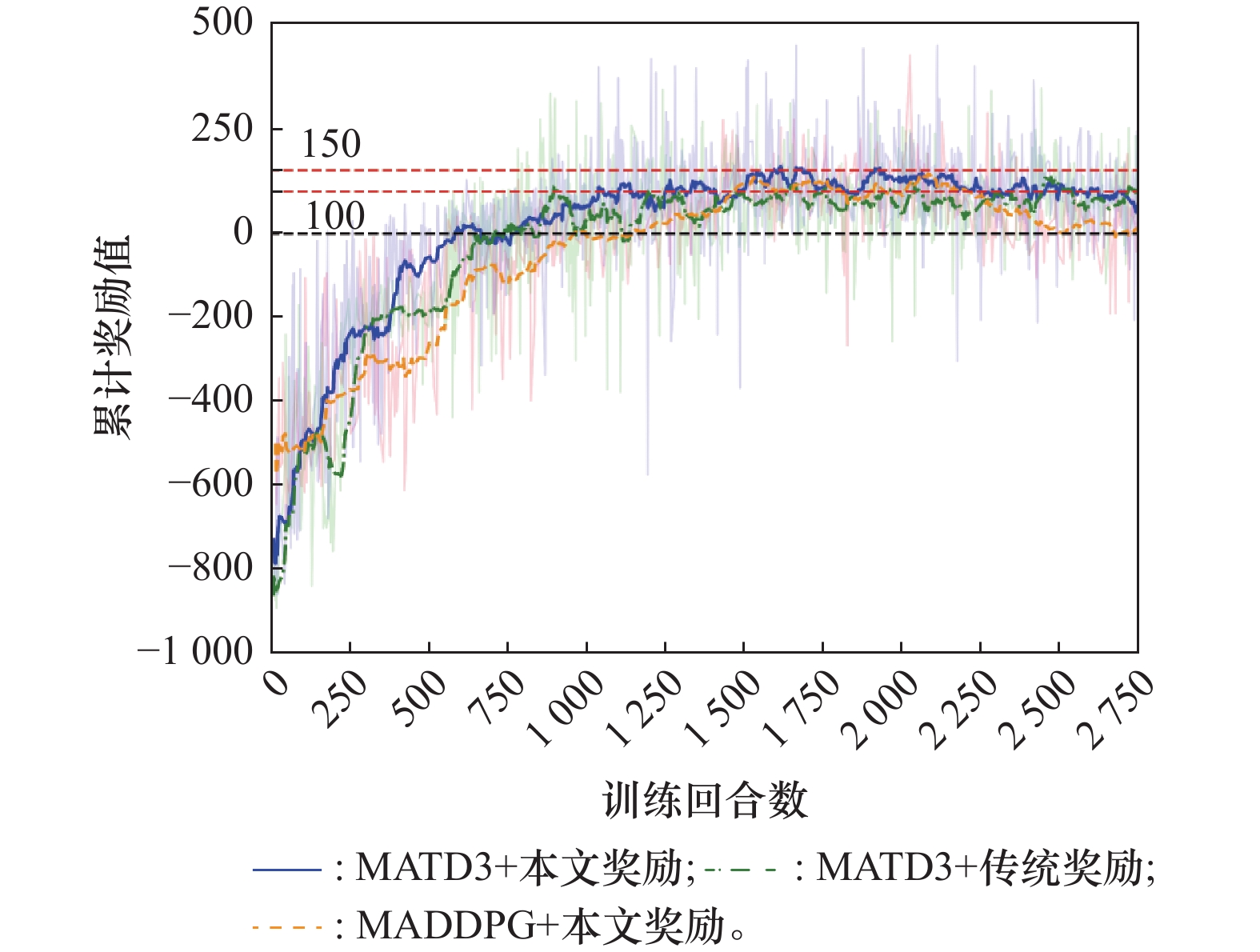
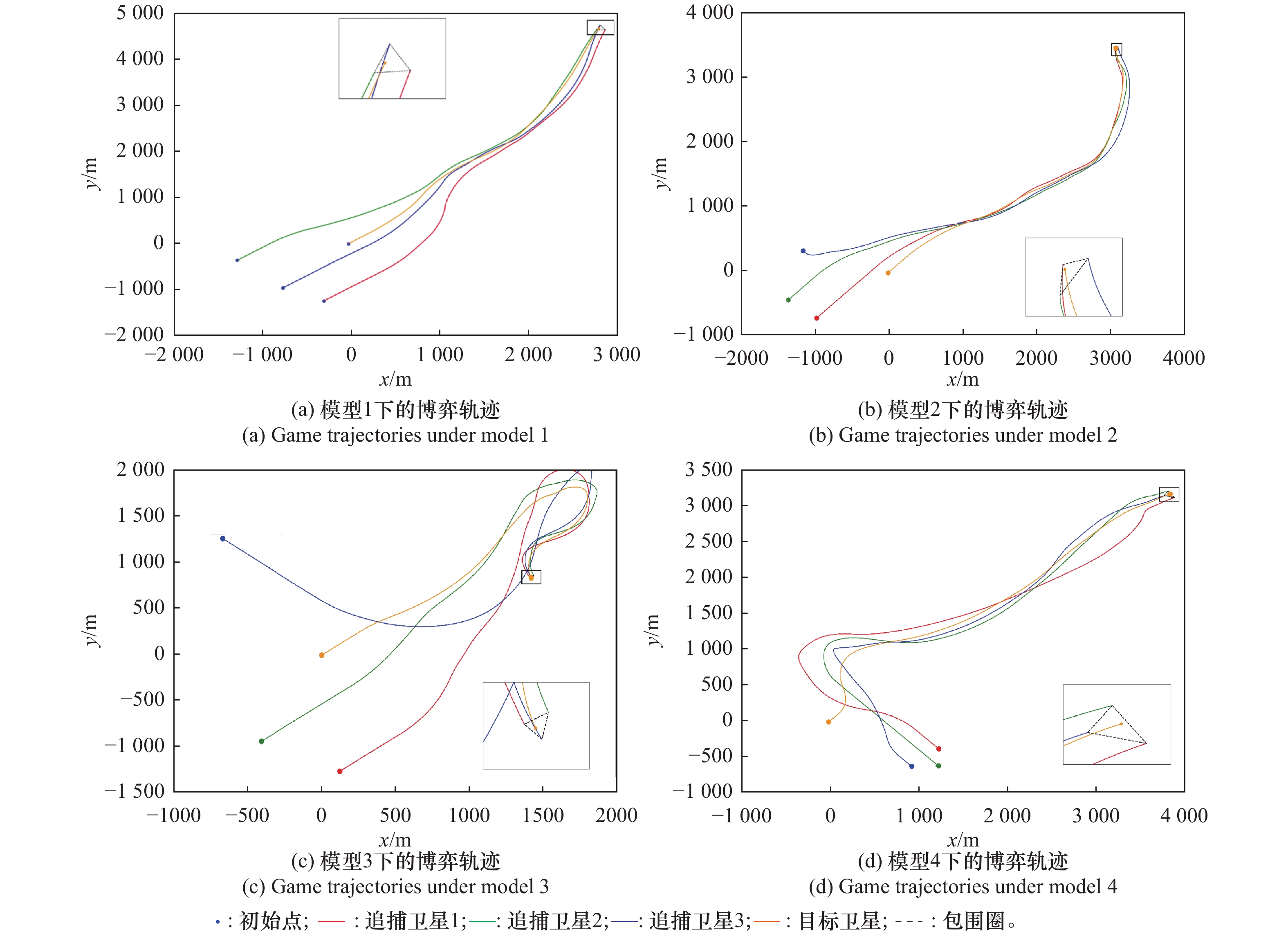
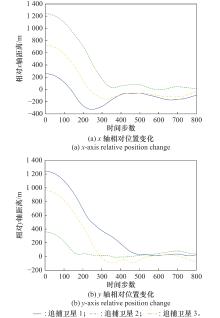
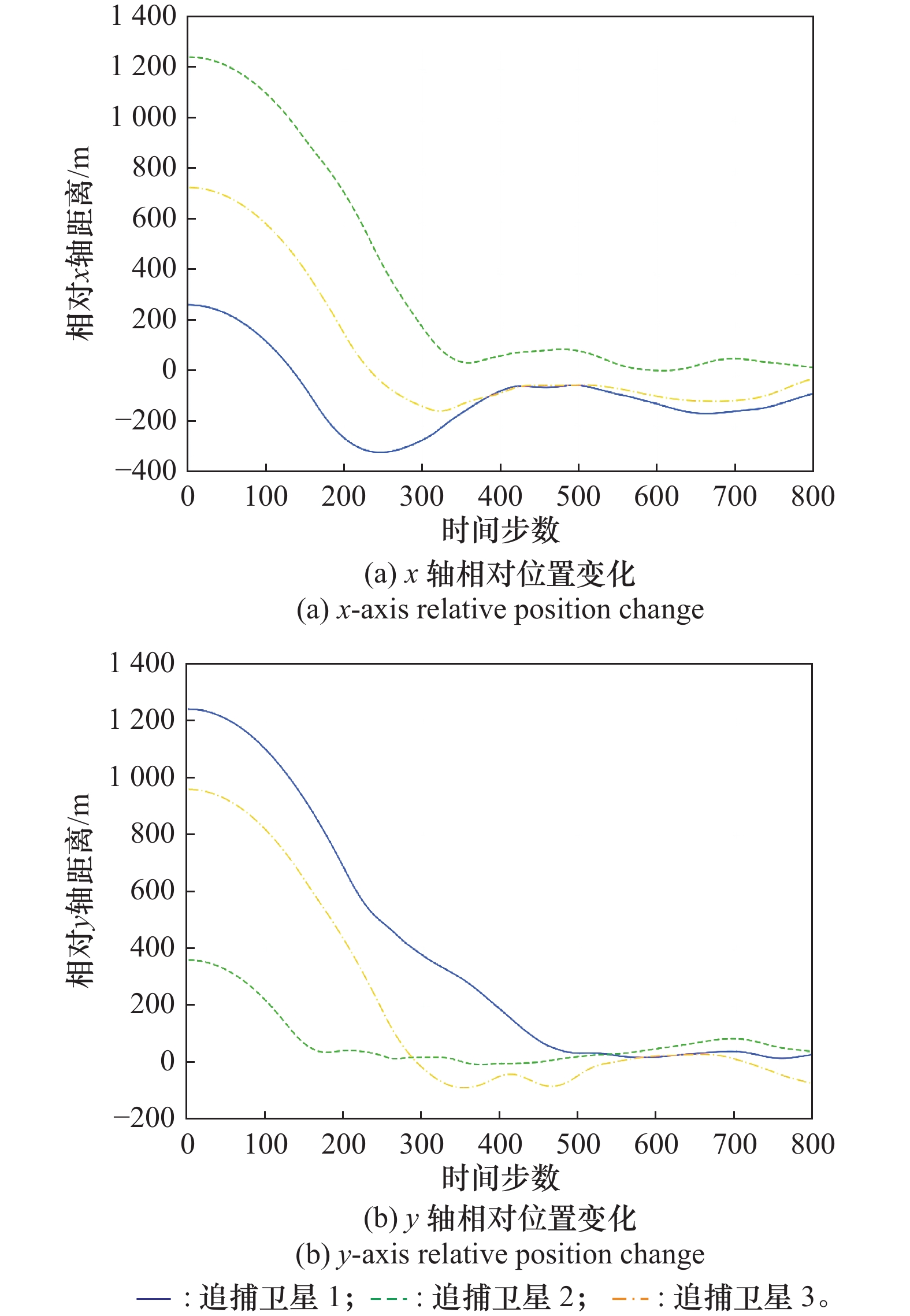
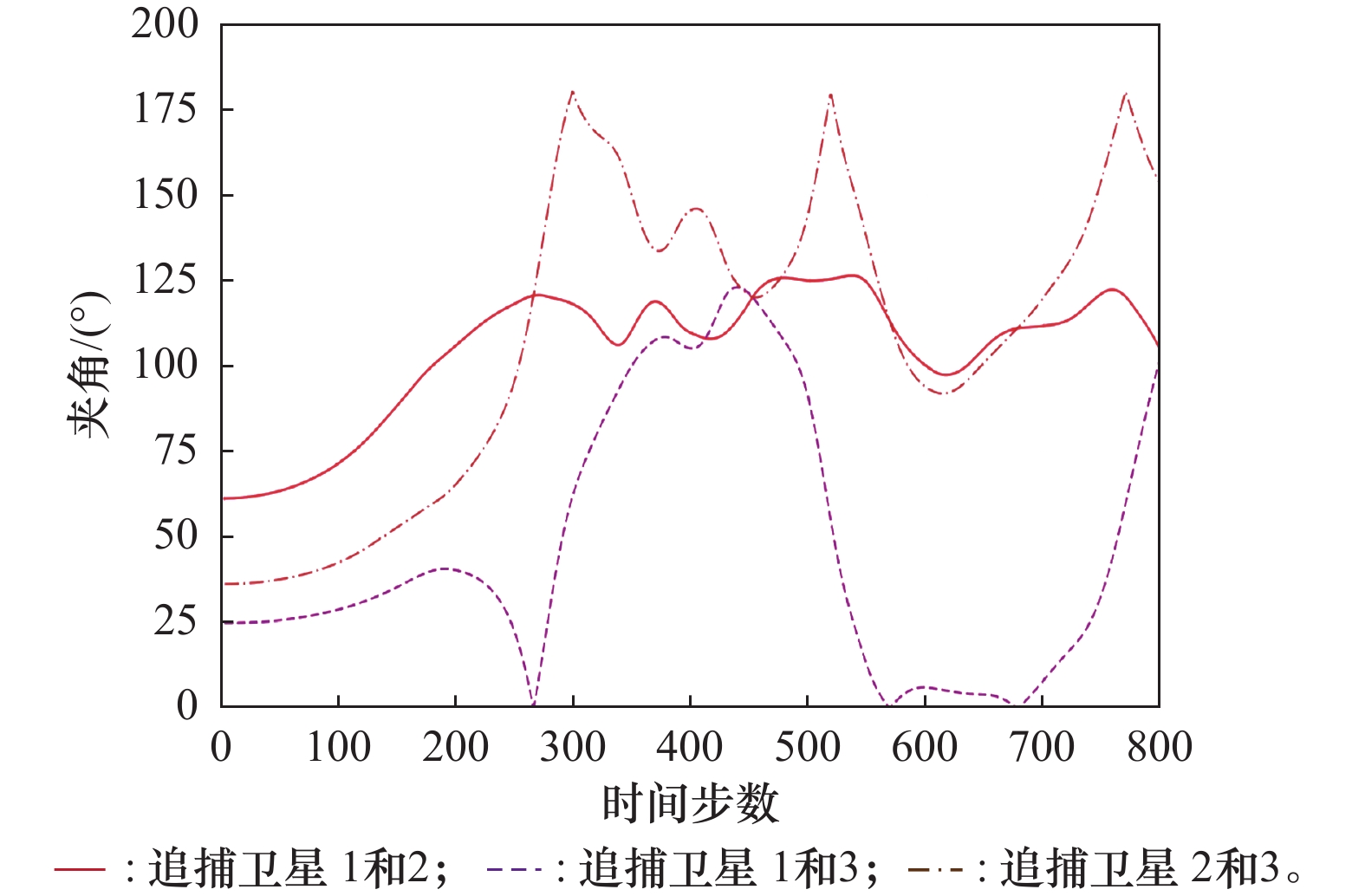
| 1 |
李传江, 闫慧达, 郭延宁, 等. 混合空间目标下的多航天器抵近观测任务规划[J]. 宇航学报, 2023, 44 (12): 1871- 1882.
doi: 10.3873/j.issn.1000-1328.2023.12.009
|
|
LI C J, YAN H D, GUO Y N, et al. Mission planning for multiple spacecraft inspection of mixed space targets in proximity[J]. Journal of Astronautics, 2023, 44 (12): 1871- 1882.
doi: 10.3873/j.issn.1000-1328.2023.12.009
|
| 2 |
BHARDWAJ A, BHATTA S, TSUKAMOTO H. Information optimal multi spacecraft positioning for interstellar object exploration[EB/OL]. [2024−11−14]. https://doi.org/10.48550/arXiv.2411.09110.
|
| 3 |
WU C Y, HAN S, CHEN Q, et al. Enhancing LEO mega-constellations with inter-satellite links: vision and challenges [EB/OL]. [2024−06−07]. https://doi.org/10.48550/arXiv.2406.05078.
|
| 4 |
WANG N, SUN L Y, FANG Y K, et al. Assignment of hybrid laser and microwave inter-satellite links for navigation satellite systems[J]. Scientific Reports, 2025, 15, 11374.
doi: 10.1038/s41598-025-95869-z
|
| 5 |
ASRI E G, ZHU Z H. An introductory review of swarm technology for spacecraft on-orbit servicing[J]. International Journal of Mechanical System Dynamics, 2024, 4 (1): 3- 21.
|
| 6 |
ZHAO Y, WU P L, YU H L, et al. Task allocation for space debris removal based on improved particle swarm optimization algorithm[C]//Proc. of the International Conference on Cyber-Physical Social Intelligence, 2023: 399–404.
|
| 7 |
LIU Z H, LIN C W, CHEN G. Space attack technology overview[J]. Journal of Physics: Conference Series, 2020, 1544 (1): 012178.
doi: 10.1088/1742-6596/1544/1/012178
|
| 8 |
ZHAO Y K, HUANG P F, ZHANG F. Capture dynamic sand net closing control for tethered space net robot[J]. Journal of Guidance, Control, and Dynamics, 2019, 42 (1): 199- 208.
|
| 9 |
JIAO C T J, ZHANG L, SU X J, et al. Predictive motion control for autonomous capture of a tumbling target with a space manipulator[J]. Journal of the Franklin Institute, 2022, 359 (15): 7913- 7935.
doi: 10.1016/j.jfranklin.2022.08.012
|
| 10 |
AGLIETTI G S, TAYLOR B, FELLOWES S. et al. The active space debris removal mission remove debris. Part 2: in orbit operations[J]. Acta Astronautica, 2020, 168, 310- 322.
doi: 10.1016/j.actaastro.2019.09.001
|
| 11 |
HAN H Y, DANG Z H. Optimal delta-V-based strategies inorbital pursuit-evasion games[J]. Advances in Space Research, 2023, 72 (2): 243- 256.
doi: 10.1016/j.asr.2023.03.028
|
| 12 |
ISAACS R. Differential games: a mathematical theory with applications to warfare and pursuit, control and optimization[M]. New York: Wiley, 1965.
|
| 13 |
WEINTRAUB I E, PACHTER M, GARCIA E. An introduction to pursuit-evasion differential games[C]//Proc. of the American Control Conference, 2020: 1049–1066.
|
| 14 |
杨傅云翔, 杨乐平, 朱彦伟, 等. 航天器轨道追逃态势分析的水平集方法[J]. 国防科技大学学报, 2024, 46 (3): 30- 38.
doi: 10.11887/j.cn.202403004
|
|
YANG F Y X, YANG L P, ZHU Y W, et al. Situation analysis method based on level set for spacecraft pursuit-evasion game[J]. Journal of National University of Defense Technology, 2024, 46 (3): 30- 38.
doi: 10.11887/j.cn.202403004
|
| 15 |
张秋华, 孙松涛, 谌颖, 等. 时间固定的两航天器追逃策略及数值求解[J]. 宇航学报, 2014, 35 (5): 537- 544.
|
|
ZHANG Q H, SUN S T, CHEN Y, et al. Strategy and numerical solution of pursuit evasion with fixed duration for two Spacecraft[J]. Journal of astronautics, 2014, 35 (5): 537- 544.
|
| 16 |
赵琳, 周俊峰, 刘源, 等. 三维空间“追-逃-防”三方微分对策方法[J]. 系统工程与电子技术, 2019, 41 (2): 322- 335.
doi: 10.3969/j.issn.1001-506X.2019.02.14
|
|
ZHAO L, ZHOU J F, LIU Y, et al. Three body differential game approach of pursuit evasion defense in three dimensional space[J]. Systems Engineering and Electronics, 2019, 41 (2): 322- 335.
doi: 10.3969/j.issn.1001-506X.2019.02.14
|
| 17 |
GARCIA E, FUCHS Z E, MILUTINOVIC D, et al. A geometric approach for the cooperative two-pursuer one-evader differential game[C]//Proc. of the International Federation of Automatic Control. 2017: 15209–15214.
|
| 18 |
LI Z, ZHU H, YANG Z, et al. A dimension reduction solution of free-time differential games for spacecraft pursuit-evasion[J]. Acta Astronautica, 2019, 163, 201- 210.
doi: 10.1016/j.actaastro.2019.01.011
|
| 19 |
SARGENT L, COVERSTONE V, RODRIGUEZ N, et al. Toward reinforcement learning identification for swarms engaged in cooperative pursuit[C]//Proc. of the AIAA Science and technology Forum and Exposition, 2022: 2501.
|
| 20 |
CHEN V, PHILLIPS S A, COPP D A, Planning autonomous spacecraft rendezvous and docking trajectories via reinforcement learning[C]//Proc. of the AAS Guidance, Navigation and Control Conference, 2023.
|
| 21 |
ZHAO L, ZHANG Y, DANG Z. PRD-MADDPG: an efficient learning-based algorithm for orbital pursuit-evasion game with impulsive maneuvers[J], Advances in Space Research, 2023, 72(2): 211–230.
|
| 22 |
LUO Y L, JIANG X Q, ZHOU C, et al. Swarm-to-swarm orbital pursuit method under delta-v maneuver for space pursuit-evasion[J]. Acta Astronautica, 2024, 223, 702- 722.
doi: 10.1016/j.actaastro.2024.07.048
|
| 23 |
周贞文, 邵将, 徐扬, 等. 针对逃逸目标的多机协同围捕策略研究[J]. 空军工程大学学报(自然科学版), 2021, 22 (3): 2- 8.
|
|
ZHOU Z W, SHAO J, XU Y, et al. Research on multi-UAV cooperative roundup strategy for escape targets[J]. Journal of Aeronautical Engineering University (Natural Science Edition), 2021, 22 (3): 2- 8.
|
| 24 |
LI B, WANG J M, SONG C, et al. Multi-UAV roundup strategy method based on deep reinforcement learning CEL-MADDPG algorithm[J]. Expert Systems with Applications, 2024, 245, 123018.
|
| 25 |
FU X W, WANG H, XU Z. Research on cooperative pursuit strategy for multi-UAVs based on DE-MADDPG algorithm[J]. Acta Aeronautica et Astronautica Sinica, 2021, 42, 325311.
|
| 26 |
许旭升, 党朝辉, 宋斌, 等. 基于多智能体强化学习的轨道追逃博弈方法[J]. 上海航天(中英文), 2022, 39 (2): 24- 31.
|
|
XU X S, DANG Z H, SONG B, et al. Method for cluster satellite orbit pursuit-evasion game based on multi-agent deep deterministic policy gradient algorithm[J]. Aerospace Shanghai (Chinese & English), 2022, 39 (2): 24- 31.
|
| 27 |
耿远卓, 袁利, 黄煌, 等. 基于终端诱导强化学习的航天器轨道追逃博弈[J]. 自动化学报, 2023, 49 (5): 974- 984.
|
|
GENG Y Z, YUAN L, HUANG H, et al. Terminal guidance based reinforcement-learning for orbital pursuit-evasion game of the spacecraft[J]. Acta Automatica Sinica, 2023, 49 (5): 974- 984.
|
| 28 |
迟进梓, 余红英, 张子雄. 一种小推力航天器变轨优化方法[J]. 航天控制, 2021, 39 (2): 3- 10.
|
|
CHI J Z, YU H Y, ZHANG Z X. Research on orbit flight planning method of small thrust spacecraft[J]. Aerospace Control, 2021, 39 (2): 3- 10.
|
| 29 |
FUJIMOTO S, HOOF H V, MEGER D. Addressing function approximation error in actor-critic methods[C]//Proc. of the 35th International Conference on Machine Learning, 2018: 1587–1596.
|
| 30 |
范书珲, 廖文和, 张翔, 等. 基于深度强化学习的双星近距离追逃博弈控制方法[J]. 中国惯性技术学报, 2024, 32(12): 1240–1249.
|
|
FAN S H, LIAO W H, ZHANG X, et al. Close-range pursuit-evasion game control method of dual satellite based on deep reinforcement[J], 2024, 32(12): 1240–1249.
|