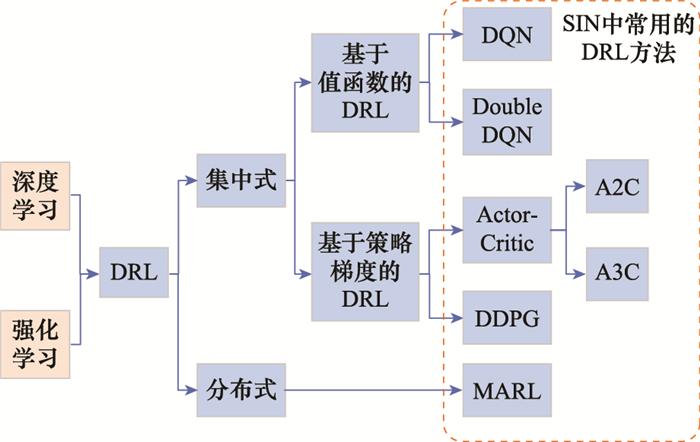
本节梳理了SIN领域常用的DRL方法, 并简要介绍了其特点。SIN中常用的DRL方法及其分类如图 1 所示。其中, 深度Q网络(deep Q network, DQN)是一种经典的基于值函数的DRL方法, 在SIN现有研究中应用最为广泛。但其局限性在于仅支持离散的动作空间, 无法处理功率控制等连续动作空间问题。深度确定性梯度(deep deterministic policy gradient, DDPG)算法是一种常见的基于策略梯度的DRL方法, 其优势在于具备处理连续决策变量的能力, 且针对SIN中的高维动作空间问题, 可将高维离散动作转化为连续变量, 并利用DDPG方法进行决策。上述两种常用的DRL方法都属于集中式方法, 而多智能体强化学习(multi-agent reinforcement learning, MARL),特别是多智能体深度强化学习(multi-agent deep reinforcement learning, MADRL), 是一种分布式方法, 可令大规模SIN的边缘节点具备智能决策能力, 避免集中式控制带来的通信和时延代价。但此类方法收敛稳定性相对较差, 保证收敛效果的关键在于合理设计各智能体之间的通信和协作机制。
图1
SIN中常用的DRL方法分类
Fig.1
Taxonomy of common DRL methods in SIN
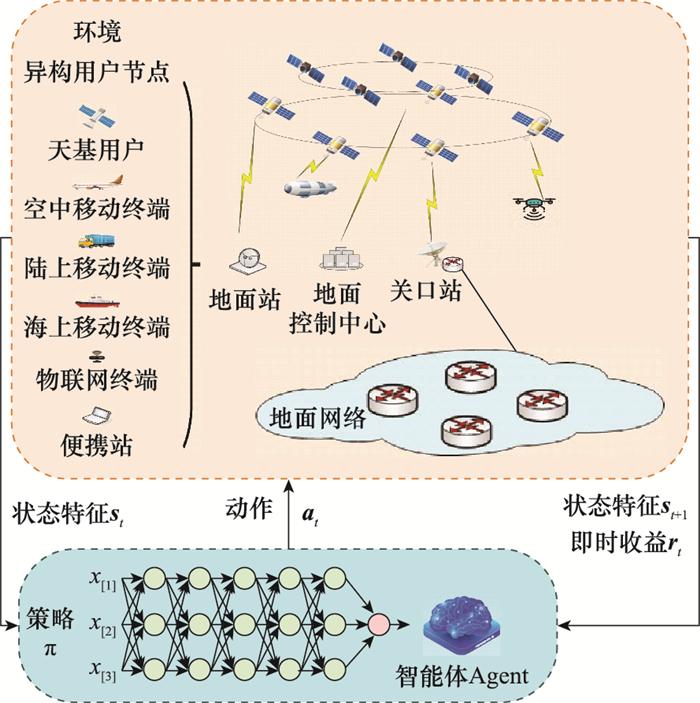
图2
基于DRL的SIN方法框架图
Fig.2
Framework of DRL-based SIN methods
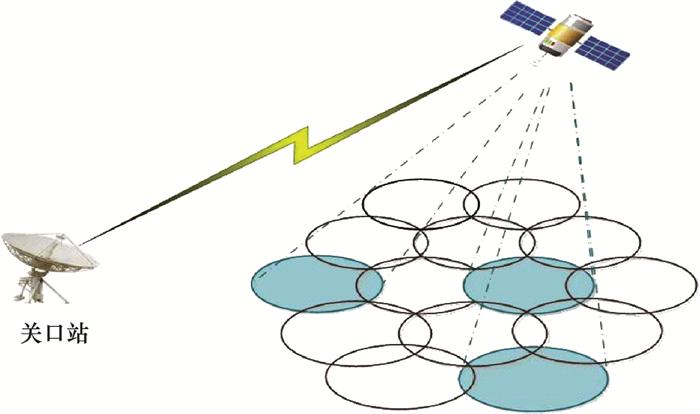
图3
卫星跳波束效果图
Fig.3
Effect of satellite beam hopping
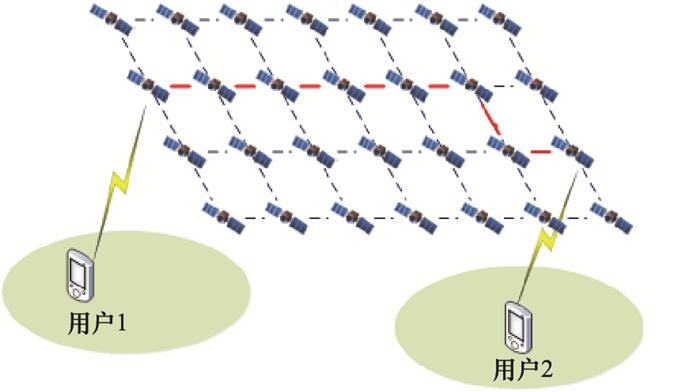
图4
卫星路由问题示意图
Fig.4
Demonstration of satellite routing
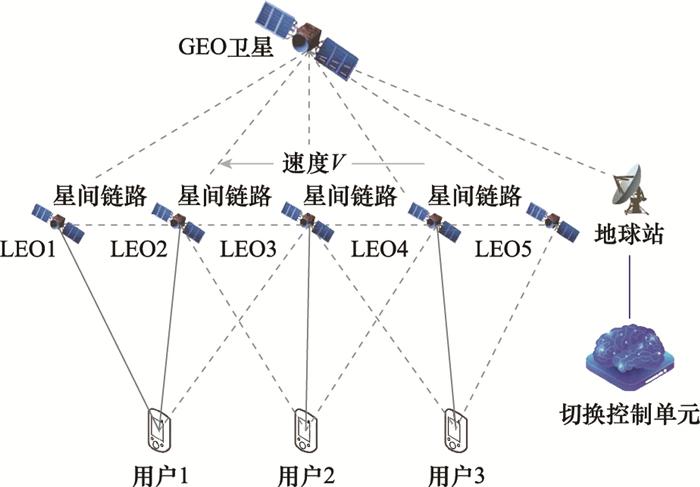
图5
卫星切换问题示意图
Fig.5
Demonstration of satellite handover
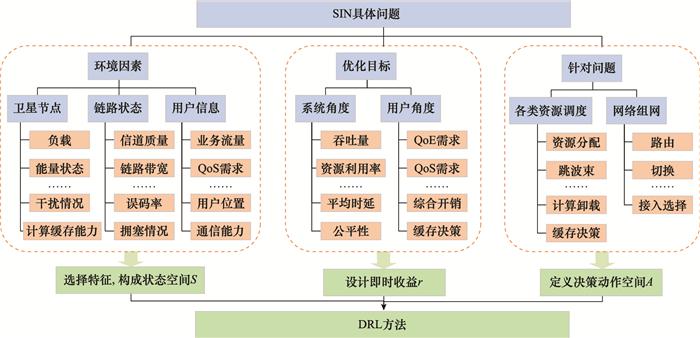
图6
基于DRL的SIN方法设计示意图
Fig.6
Design demonstration of DRL-based SIN methods
将卫星、中继节点、用户之间的通信链路分别表示为$\left\lceil L_{S, n}, L_{S, m}, L_{m, n}\right\rceil$ $\left\lceil d_{S, n}, d_{S, m}, d_{m, n}\right\rceil$ $\left\lceil g_{S, n}, g_{S, m}, g_{m, n}\right\rceil$
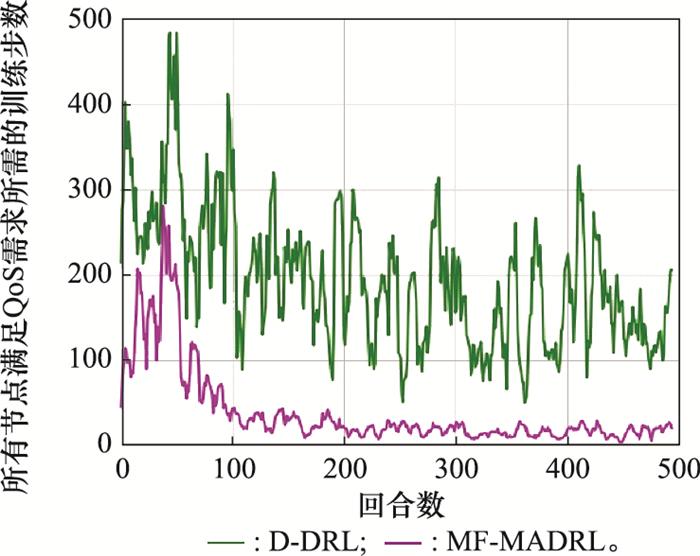
图7
两种DRL方法满足所有终端速率要求所需的训练步数
Fig.7
Number of iterations needed by two DRL methods for satisfying terminal's requirements
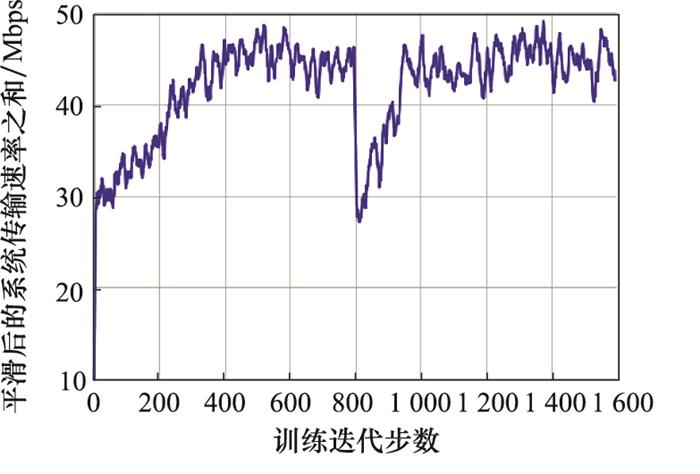
图8
迁移机制MF-MADRL算法收敛效果的提升
Fig.8
Improvement of convergence efficiency by transfer mechanism MF-MADRL algorithm
图9
DRL步骤是否可在SIN中应用的判断流程
Fig.9
Flowchart to decide whether DRL procedure can be applied in SIN research fields
[1]
LIU J J , SHI Y P , FADLULLAH Z M , et al . Space-air-ground integrated network: a survey
[J]. IEEE Communications Surveys & Tutorials , 2018 , 20 (4 ): 2714 - 2741 .
[本文引用: 1]
[2]
ARULKUMARAN K , DEISENROTH M P , BRUNDAGE M , et al . A brief survey of deep reinforcement learning
[J]. IEEE Signal Processing Magazine , 2017 , 34 (6 ): 26 - 38 .
DOI:10.1109/MSP.2017.2743240
[本文引用: 1]
[3]
张沛 , 刘帅军 , 马治国 , 等 . 基于深度增强学习和多目标优化改进的卫星资源分配算法
[J]. 通信学报 , 2020 , 41 (6 ): 51 - 60 .
URL
[本文引用: 2]
ZHANG P , LIU S J , MA Z G , et al . Improved satellite resource allocation algorithm based on DRL and MOP
[J]. Journal on Communications , 2020 , 41 (6 ): 51 - 60 .
URL
[本文引用: 2]
[4]
LIU S J , HU X , WANG W D . Deep reinforcement learning based dynamic channel allocation algorithm in multibeam satellite systems
[J]. IEEE Access , 2018 , 6 , 15733 - 15742 .
DOI:10.1109/ACCESS.2018.2809581
[本文引用: 5]
[6]
ZHAO B K , LIU J H , WEI Z L , et al . A deep reinforcement learning based approach for energy-efficient channel allocation in satellite Internet of things
[J]. IEEE Access , 2020 , 8 , 62197 - 62206 .
DOI:10.1109/ACCESS.2020.2983437
[本文引用: 3]
[7]
HU X , LIAO X L , LIU Z J , et al . Multi-agent deep reinforcement learning-based flexible satellite payload for mobile terminals
[J]. IEEE Trans.on Vehicular Technology , 2020 , 69 (9 ): 9849 - 9865 .
DOI:10.1109/TVT.2020.3002983
[本文引用: 2]
[8]
LUIS J J G, GUERSTER M, DEL PORTILLO I, et al. Deep reinforcement learning for continuous power allocation in flexible high throughput satellites[C]//Proc. of the 2nd IEEE Cognitive Communications for Aerospace Applications Workshop, 2019.
[本文引用: 2]
[9]
LUIS J J G, PACHLER N, GUERSTER M, et al. Artificial intelligence algorithms for power allocation in high throughput sate- llites: a comparison[C]//Proc. of the IEEE Aerospace Conference, 2020.
[本文引用: 1]
[10]
FERREIRA P V R , PAFFENROTH R , WYGLINSKI A M , et al . Multi-objective reinforcement learning for cognitive sate-llite communications using deep neural network ensembles
[J]. IEEE Journal on Selected Areas in Communications , 2018 , 36 (5 ): 1030 - 1041 .
DOI:10.1109/JSAC.2018.2832820
[本文引用: 2]
[11]
HU X , LIU S J , WANG Y P , et al . Deep reinforcement learning-based beam Hopping algorithm in multibeam satellite systems
[J]. IET Communications , 2019 , 13 (16 ): 2485 - 2491 .
DOI:10.1049/iet-com.2018.5774
[本文引用: 3]
[12]
HU X , ZHANG Y C , LIAO X L , et al . Dynamic beam hopping method based on multi-objective deep reinforcement learning for next generation satellite broadband systems
[J]. IEEE Trans.on Broadcasting , 2020 , 66 (3 ): 630 - 646 .
DOI:10.1109/TBC.2019.2960940
[本文引用: 3]
[13]
TANG Q Q , FEI Z S , LI B , et al . Computation offloading in LEO satellite networks with hybrid cloud and edge computing
[J]. IEEE Internet of Things Journal , 2021 , 8 (11 ): 9164 - 9176 .
DOI:10.1109/JIOT.2021.3056569
[本文引用: 1]
[14]
ZHOU C H , WU W , HE H L , et al . Deep reinforcement learning for delay-oriented IoT task scheduling in space-air-ground integrated network
[J]. IEEE Trans.on Wireless Communications , 2020 , 20 (2 ): 911 - 925 .
[本文引用: 3]
[15]
CUI G F , LONG Y T , XU L X , et al . Joint offloading and resource allocation for satellite assisted vehicle-to-vehicle communication
[J]. IEEE Systems Journal , 2020 , 15 (3 ): 3958 - 3969 .
[本文引用: 2]
[16]
QIU C , YAO H P , YU F R , et al . Deep Q-learning aided networking, caching, and computing resources allocation in software-defined satellite-terrestrial networks
[J]. IEEE Trans.on Vehicular Technology , 2019 , 68 (6 ): 5871 - 5883 .
DOI:10.1109/TVT.2019.2907682
[本文引用: 3]
[17]
MENG X L , WU L D , YU S B . Research on resource allocation method of space information networks based on deep reinforcement learning
[J]. Remote Sensing , 2019 , 11 (4 ): 448 .
DOI:10.3390/rs11040448
[本文引用: 3]
[18]
朱立东 , 张勇 , 贾高一 . 卫星互联网路由技术现状及展望
[J]. 通信学报 , 2021 , 42 (8 ): 33 - 42 .
URL
[本文引用: 1]
ZHU L D , ZHANG Y , JIA G Y . Current status and future prospects of routing technologies for satellite Internet
[J]. Journal on Communications , 2021 , 42 (8 ): 33 - 42 .
URL
[本文引用: 1]
[19]
WANG C , WANG H W , WANG W D . A two-hops state-aware routing strategy based on deep reinforcement learning for LEO satellite networks
[J]. Electronics , 2019 , 8 (9 ): 920 .
DOI:10.3390/electronics8090920
[本文引用: 2]
[20]
TU Z, ZHOU H C, LI K, et al. A routing optimization method for software-defined SGIN based on deep reinforcement learning[C]//Proc. of the IEEE Global Communications Conference Workshops, 2019.
[本文引用: 3]
[21]
LIU J H , ZHAO B K , XIN Q , et al . DRL-ER: an intelligent energy-aware routing protocol with guaranteed delay bounds in satellite mega-constellations
[J]. IEEE Trans.on Network Science and Engineering , 2020 , 8 (4 ): 2872 - 2884 .
[本文引用: 3]
[22]
HAN C , HUO L Y , TONG X H , et al . Spatial anti-jamming scheme for internet of satellites based on the deep reinforcement learning and stackelberg game
[J]. IEEE Trans.on Vehi-cular Technology , 2020 , 69 (5 ): 5331 - 5342 .
DOI:10.1109/TVT.2020.2982672
[本文引用: 3]
[23]
杨斌 , 何锋 , 靳瑾 , 等 . LEO卫星通信系统覆盖时间和切换次数分析
[J]. 电子与信息学报 , 2014 , 36 (4 ): 804 - 809 .
URL
[本文引用: 2]
YANG B , HE F , JIN J , et al . Analysis of coverage time and handoff number on LEO satellite communication systems
[J]. Journal of Electronics & Information Technology , 2014 , 36 (4 ): 804 - 809 .
URL
[本文引用: 2]
[24]
XU H H , LI D S , LIU M L , et al . QoE-driven intelligent hand- over for user-centric mobile satellite networks
[J]. IEEE Trans.on Vehicular Technology , 2020 , 69 (9 ): 10127 - 10139 .
DOI:10.1109/TVT.2020.3000908
[本文引用: 2]
[25]
HE S X, WANG T Y, WANG S W. Load-aware satellite handover strategy based on multi-agent reinforcement learning[C]//Proc. of the IEEE Global Communications Conference, 2020.
[本文引用: 2]
[26]
CAO Y , LIEN S Y , LIANG Y C . Deep reinforcement learning for multi-user access control in non-terrestrial networks
[J]. IEEE Trans.on Communications , 2020 , 69 (3 ): 1605 - 1619 .
[本文引用: 2]
[27]
LEE J H, PARK J, BENNIS M, et al. Integrating LEO sate-llite and UAV relaying via reinforcement learning for non-terrestrial networks[C]//Proc. of the IEEE Global Communications Conference, 2020.
[本文引用: 3]
[28]
LI X N, ZHANG H J, LI W, et al. Multi-agent DRL for user association and power control in terrestrial-satellite network[C]//Proc. of the IEEE Global Communications Conference, 2021.
[29]
FERIANI A , HOSSAIN E . Single and multi-agent deep reinforcement learning for AI-enabled wireless networks: a tutorial
[J]. IEEE Communications Surveys & Tutorials , 2021 , 23 (2 ): 1226 - 1252 .
[本文引用: 1]
[30]
FERREIRA P V R , PAFFENROTH R , WYGLINSKI A M , et al . Reinforcement learning for satellite communications: From LEO to deep space operations
[J]. IEEE Communications Magazine , 2019 , 57 (5 ): 70 - 75 .
[本文引用: 1]
[31]
MAI T, YAO H P, JING Y Q, et al. Self-learning congestion control of MPTCP in satellites communications[C]//Proc. of the 15th International Wireless Communications & Mobile Computing Conference, 2019: 775-780.
[本文引用: 1]
[32]
XIE R C , TANG Q Q , WANG Q N , et al . Satellite-terrestrial integrated edge computing networks: architecture, challenges, and open issues
[J]. IEEE Network , 2020 , 34 (3 ): 224 - 231 .
[本文引用: 1]
[33]
HASSAN N U L , HUANG C W , YUEN C , et al . Dense small satellite networks for modern terrestrial communication systems: benefits, infrastructure, and technologies
[J]. IEEE Wireless Communications , 2020 , 27 (5 ): 96 - 103 .
[本文引用: 1]
[34]
ZHAO B , REN G L , DONG X D , et al . Distributed Q-learning based joint relay selection and access control scheme for IoT-oriented satellite terrestrial relay networks
[J]. IEEE Communications Letters , 2021 , 25 (6 ): 1901 - 1905 .
[本文引用: 2]
[35]
MNIH V , KAVUKCUOGLU K , SILVER D , et al . Human-level control through deep reinforcement learning
[J]. Nature , 2015 , 518 (7540 ): 529 - 533 .
[本文引用: 2]
[36]
YANG Y D, LUO R, LI M N, et al. Mean field multi-agent reinforcement learning[C]//Proc. of the 35th International Conference on Machine Learning, 2018: 5571-5580.
[本文引用: 1]
[37]
ARTI M K . Channel estimation and detection in satellite communication systems
[J]. IEEE Trans.on Vehicular Technology , 2016 , 65 (12 ): 10173 - 10179 .
[本文引用: 1]
[38]
BANKEY V , UPADHYAY P K , DA COSTA D B , et al . Performance analysis of multi-antenna multiuser hybrid satellite-terrestrial relay systems for mobile services delivery
[J]. IEEE Access , 2018 , 6 , 24729 - 24745 .
[本文引用: 1]
[39]
PACHECO F , EXPOSITO E , GINESTE M . A framework to classify heterogeneous Internet traffic with machine learning and deep learning techniques for satellite communications
[J]. Computer Networks , 2020 , 173 , 107213 .
[本文引用: 1]
[40]
RAO S K . Advanced antenna technologies for satellite communications payloads
[J]. IEEE Trans.on Antennas and Propagation , 2015 , 63 (4 ): 1205 - 1217 .
[本文引用: 1]
[41]
万里鹏 , 兰旭光 , 张翰博 , 等 . 深度强化学习理论及其应用综述
[J]. 模式识别与人工能 , 2019 , 32 (1 ): 67 - 81 .
URL
[本文引用: 1]
WAN L P , LAN X G , ZHANG H B , et al . A review of deep reinforcement learning theory and application
[J]. Pattern Re-cognition and Artificial Intelligence , 2019 , 32 (1 ): 67 - 81 .
URL
[本文引用: 1]
[42]
ARULKUMARAN K , DEISENROTH M P , BRUNDAGE M , et al . Deep reinforcement learning: a brief survey
[J]. IEEE Signal Processing Magazine , 2017 , 34 (6 ): 26 - 38 .
[本文引用: 1]
[43]
NG A Y, RUSSELL S J. Algorithms for inverse reinforcement learning[C]//Proc. of the 17th International Conference on Machine Learning, 2000: 663-670.
[本文引用: 1]
[44]
ZHU Z D, LIN K X, ZHOU J Y. Transfer learning in deep reinforcement learning: a survey[EB/OL]. [2021-08-23]. https://arxiv.org/abs/2009.07888.
[本文引用: 1]
[45]
谭晓阳 , 张哲 . 元强化学习综述
[J]. 南京航空航天大学学报 , 2021 , 53 (5 ): 653 - 663 .
URL
[本文引用: 1]
TAN X Y , ZHANG Z . Review on meta reinforcement learning
[J]. Journal of Nanjing University of Aeromautics and Astronautics , 2021 , 53 (5 ): 653 - 663 .
URL
[本文引用: 1]
[46]
周文吉 , 俞扬 . 分层强化学习综述
[J]. 智能系统学报 , 2017 , 12 (5 ): 590 - 594 .
URL
[本文引用: 1]
ZHOU W J , YU Y . Summarize of hierarchical reinforcement learning
[J]. CAAI Transactions on Intelligent Systems , 2017 , 12 (5 ): 590 - 594 .
URL
[本文引用: 1]
[47]
GENG Y Z , LIU E W , WANG R , et al . Hierarchical reinforcement learning for relay selection and power optimization in two-hop cooperative relay network
[J]. IEEE Trans.on Communications , 2021 , 70 (1 ): 171 - 184 .
[本文引用: 1]
[48]
YANG R, SUN X, NARASIMHAN K. A generalized algorithm for multi-objective reinforcement learning and policy ada-ptation[C]//Proc. of the Conference and Workshop on Neural Information Processing Systems, 2019.
[本文引用: 1]
[49]
HOCHREITER S , SCHMIDHUBER J . Long short-term memory
[J]. Neural Computation , 1997 , 9 (8 ): 1735 - 1780 .
[本文引用: 1]
[50]
GOODFELLOW I , POUGET-ABADIE J , MIRZA M , et al . Generative adversarial nets
[J]. Advances in Neural Information Processing Systems , 2014 , 27 , 1 - 9 .
[本文引用: 1]
[51]
YAN S, XIONG Y, LIN D. Spatial temporal graph convolutional networks for skeleton-based action recognition[C]//Proc. of the 32ed Association for the Advance of Artificial Intelligence, 2018.
[本文引用: 1]
[52]
NURVITADHI E, SIM J, SHEFFIELD D, et al. Accelerating recurrent neural networks in analytics servers: Comparison of FPGA, CPU, GPU, and ASIC[C]// Proc. of the IEEE 26th International Conference on Field Programmable Logic and App- lications, 2016.
[本文引用: 1]
[53]
李德仁 , 沈欣 , 李迪龙 , 等 . 论军民融合的卫星通信、遥感、导航一体天基信息实时服务系统
[J]. 武汉大学学报(信息科学版) , 2017 , 42 (11 ): 1501 - 1505 .
URL
[本文引用: 1]
LI D R , SHEN X , LI D L , et al . On civil-military integrated space-based real-time information service system
[J]. Geomatics and Information Science of Wuhan University , 2017 , 42 (11 ): 1501 - 1505 .
URL
[本文引用: 1]
[54]
HINTON G, VINYALS O, DEAN J. Distilling the knowledge in a neural network[EB/OL]. [2021-08-23]. https://arxiv.org/abs/1503.02531.
[本文引用: 1]
[55]
LIU Z, LI J, SHEN Z, et al. Learning efficient convolutional networks through network slimming[C]//Proc. of the IEEE International Conference on Computer Vision, 2017: 2736-2744.
[本文引用: 1]
Space-air-ground integrated network: a survey
1
2018
... 天基信息网络(space information network, SIN)是全覆盖、高速率、高可靠的未来6G网络的重要组成部分.未来SIN的特点可归纳为[1 ] : ①网络规模日趋庞大, 包含大规模多层卫星节点和异构终端; ②环境动态多变, 信道条件、网络拓扑和天基节点状态等因素动态变化; ③业务需求多样.随着天基物联网的发展, SIN业务日益多样化, 这意味着业务需求、优先级、用户偏好的多样化. ...
A brief survey of deep reinforcement learning
1
2017
... 上述难点使研究者将目光投向数据驱动的深度强化学习(deep reinforcement learning, DRL)方法[2 ] .在SIN领域中应用DRL具有以下优势: ①不需已知准确定义的SIN模型, 而是能通过与环境的交互优化控制策略; ②不局限于静态的某一时刻, 而是能够优化序列决策的长期收益, 更适合卫星生命周期内的在线决策问题; ③基于神经网络实现从环境特征到策略的映射, 相比需迭代求解的优化方法更具实时性; ④可通过反馈感知环境变化, 并随之调整策略, 更适合动态变化的SIN环境. ...
基于深度增强学习和多目标优化改进的卫星资源分配算法
2
2020
... 时隙分配在已有研究中通常被建模为整数规划并转化为装包问题进行求解.文献[3 ]指出, 此类整数规划求解思路难以在复杂动态环境中调整决策并优化长期收益, 因此提出一种基于DQN的多目标时隙分配方法.以频谱效率、能量效率和用户业务满意度指数的加权作为即时收益r , 提高了系统的综合性能.但此方法仅能为用户分配单个时隙, 而难以进行多时隙聚合分配. ...
... A summary of existing research related to DRL in SIN
Table 3 领域 文献 场景 针对问题 优化目标 DRL方法 资源分配 [3 ] 多波束GEO卫星网络 用户时隙分配 用户满意度、能量和频谱利用率 DQN [4 ] 多波束GEO卫星网络 用户信道分配 呼通率 DQN [6 ] LEO卫星物联网 用户信道分配 能量利用率 DQN [7 ] 多波束GEO卫星网络 波束带宽分配 公平性、流量满足程度 MARL [8 ] 多波束GEO卫星网络 波束功率分配 功率消耗、流量满足程度 DDPG [10 ] GEO卫星网络 配置链路参数 吞吐量、误码率、功耗、带宽稳定 DQN 跳波束 [11 ] 多波束GEO卫星 波束点亮方案 传输时延 DQN [12 ] 多波束GEO卫星 波束点亮方案 实时服务时延, 非实时服务吞吐量, 公平性 双环DQN 计算卸载与缓存 [14 ] 空天地一体化网络 任务卸载位置决策 平均处理时延 DQN [15 ] GEO卫星辅助车联网 任务卸载、计算和通信资源联合分配 时延 优化、DQN [16 ] 天地一体化网络 通信、缓存和计算资源联合分配 通信、缓存和计算开销 DQN [17 ] 多层卫星网络 缓存策略、计算卸载、接入选择联合决策 缓存和计算开销 A3C 路由选择 [19 ] LEO卫星星座 下一跳路由选择 跳数、丢包率、拥塞避免 Double DQN [20 ] 天地一体化网络 下一跳路由选择 时延、丢包率、吞吐量 DDPG [21 ] LEO卫星星座 下一跳路由选择 时延、卫星电池能量寿命 DQN [22 ] LEO卫星星座 抗干扰路径集合计算 集合中链路不受干扰 近似策略优化 卫星切换 [24 ] LEO卫星星座 切换选择 QoE DQN [25 ] LEO卫星星座 切换选择 切换次数 MARL 接入选择 [26 ] 空天地一体化网络 接入选择 吞吐量 DQN [27 ] 空天地一体化网络 接入选择与航迹调整 吞吐量 DQN
3 基于DRL的星地网络中继选择算法 对于星地网络中继节点选择的已有研究, 大多集中于信号强度、地理空间距离、信道质量、负载等因素, 将中继节点选择问题建模为针对传输速率、系统吞吐量、中断概率、能量利用率等指标的优化问题, 并利用优化、博弈论等方法进行求解.通过分析已有研究工作, 可以发现已有的星地网络中继选择算法面临的挑战主要包括以下几点[34 ] : ...
Improved satellite resource allocation algorithm based on DRL and MOP
2
2020
... 时隙分配在已有研究中通常被建模为整数规划并转化为装包问题进行求解.文献[3 ]指出, 此类整数规划求解思路难以在复杂动态环境中调整决策并优化长期收益, 因此提出一种基于DQN的多目标时隙分配方法.以频谱效率、能量效率和用户业务满意度指数的加权作为即时收益r , 提高了系统的综合性能.但此方法仅能为用户分配单个时隙, 而难以进行多时隙聚合分配. ...
... A summary of existing research related to DRL in SIN
Table 3 领域 文献 场景 针对问题 优化目标 DRL方法 资源分配 [3 ] 多波束GEO卫星网络 用户时隙分配 用户满意度、能量和频谱利用率 DQN [4 ] 多波束GEO卫星网络 用户信道分配 呼通率 DQN [6 ] LEO卫星物联网 用户信道分配 能量利用率 DQN [7 ] 多波束GEO卫星网络 波束带宽分配 公平性、流量满足程度 MARL [8 ] 多波束GEO卫星网络 波束功率分配 功率消耗、流量满足程度 DDPG [10 ] GEO卫星网络 配置链路参数 吞吐量、误码率、功耗、带宽稳定 DQN 跳波束 [11 ] 多波束GEO卫星 波束点亮方案 传输时延 DQN [12 ] 多波束GEO卫星 波束点亮方案 实时服务时延, 非实时服务吞吐量, 公平性 双环DQN 计算卸载与缓存 [14 ] 空天地一体化网络 任务卸载位置决策 平均处理时延 DQN [15 ] GEO卫星辅助车联网 任务卸载、计算和通信资源联合分配 时延 优化、DQN [16 ] 天地一体化网络 通信、缓存和计算资源联合分配 通信、缓存和计算开销 DQN [17 ] 多层卫星网络 缓存策略、计算卸载、接入选择联合决策 缓存和计算开销 A3C 路由选择 [19 ] LEO卫星星座 下一跳路由选择 跳数、丢包率、拥塞避免 Double DQN [20 ] 天地一体化网络 下一跳路由选择 时延、丢包率、吞吐量 DDPG [21 ] LEO卫星星座 下一跳路由选择 时延、卫星电池能量寿命 DQN [22 ] LEO卫星星座 抗干扰路径集合计算 集合中链路不受干扰 近似策略优化 卫星切换 [24 ] LEO卫星星座 切换选择 QoE DQN [25 ] LEO卫星星座 切换选择 切换次数 MARL 接入选择 [26 ] 空天地一体化网络 接入选择 吞吐量 DQN [27 ] 空天地一体化网络 接入选择与航迹调整 吞吐量 DQN
3 基于DRL的星地网络中继选择算法 对于星地网络中继节点选择的已有研究, 大多集中于信号强度、地理空间距离、信道质量、负载等因素, 将中继节点选择问题建模为针对传输速率、系统吞吐量、中断概率、能量利用率等指标的优化问题, 并利用优化、博弈论等方法进行求解.通过分析已有研究工作, 可以发现已有的星地网络中继选择算法面临的挑战主要包括以下几点[34 ] : ...
Deep reinforcement learning based dynamic channel allocation algorithm in multibeam satellite systems
5
2018
... 针对频分复用体制中的信道分配问题, 文献[4 ]采用已经分配的信道与其对应地理位置为状态s , 将各个信道作为动作空间A , 并通过求解Q网络得到最优策略π.文献[4 ]指出, 迭代的元启发式资源分配算法[5 ] 因计算复杂度高而难以保证实时性, 且忽略了在线信道分配问题的序列性, 因此提出了基于DQN的多波束地球静止轨道(geostationary orbit, GEO)卫星信道在线分配方法.在此基础上, 文献[6 ]提出了低轨道(low earth orbit, LEO)卫星物联网场景下的信道资源分配方法.首先, 提出了一种基于滑动块的感知方法, 以应对LEO星座的移动性; 其次, 针对LEO卫星能量受限问题, 提出了考虑能量利用率的信道分配方法, 采用与文献[4 ]类似的状态表示方法和网络结构, 利用能量利用率改进DQN的即时收益r , 将能耗降低了65%以上.但此方法并未考虑LEO卫星切换对用户信道分配方案的影响. ...
... , 并通过求解Q网络得到最优策略π.文献[4 ]指出, 迭代的元启发式资源分配算法[5 ] 因计算复杂度高而难以保证实时性, 且忽略了在线信道分配问题的序列性, 因此提出了基于DQN的多波束地球静止轨道(geostationary orbit, GEO)卫星信道在线分配方法.在此基础上, 文献[6 ]提出了低轨道(low earth orbit, LEO)卫星物联网场景下的信道资源分配方法.首先, 提出了一种基于滑动块的感知方法, 以应对LEO星座的移动性; 其次, 针对LEO卫星能量受限问题, 提出了考虑能量利用率的信道分配方法, 采用与文献[4 ]类似的状态表示方法和网络结构, 利用能量利用率改进DQN的即时收益r , 将能耗降低了65%以上.但此方法并未考虑LEO卫星切换对用户信道分配方案的影响. ...
... ]提出了低轨道(low earth orbit, LEO)卫星物联网场景下的信道资源分配方法.首先, 提出了一种基于滑动块的感知方法, 以应对LEO星座的移动性; 其次, 针对LEO卫星能量受限问题, 提出了考虑能量利用率的信道分配方法, 采用与文献[4 ]类似的状态表示方法和网络结构, 利用能量利用率改进DQN的即时收益r , 将能耗降低了65%以上.但此方法并未考虑LEO卫星切换对用户信道分配方案的影响. ...
... 不同于文献[4 , 6 ]主要研究用户的信道分配问题, 文献[7 ]关注各波束带宽分配问题, 考虑到多波束GEO卫星的各个波束传输需求不均衡且存在动态变化的问题, 提出了一种基于MARL的带宽分配算法.将每个波束视为一个智能体, 感知本波束的传输需求,并将其作为状态s , 并通过各智能体间的协作学习到各波束协同频谱分配策略π.仿真实验表明, 此方法能使波束数据传输能力更符合动态流量需求, 且时间复杂度更低. ...
... A summary of existing research related to DRL in SIN
Table 3 领域 文献 场景 针对问题 优化目标 DRL方法 资源分配 [3 ] 多波束GEO卫星网络 用户时隙分配 用户满意度、能量和频谱利用率 DQN [4 ] 多波束GEO卫星网络 用户信道分配 呼通率 DQN [6 ] LEO卫星物联网 用户信道分配 能量利用率 DQN [7 ] 多波束GEO卫星网络 波束带宽分配 公平性、流量满足程度 MARL [8 ] 多波束GEO卫星网络 波束功率分配 功率消耗、流量满足程度 DDPG [10 ] GEO卫星网络 配置链路参数 吞吐量、误码率、功耗、带宽稳定 DQN 跳波束 [11 ] 多波束GEO卫星 波束点亮方案 传输时延 DQN [12 ] 多波束GEO卫星 波束点亮方案 实时服务时延, 非实时服务吞吐量, 公平性 双环DQN 计算卸载与缓存 [14 ] 空天地一体化网络 任务卸载位置决策 平均处理时延 DQN [15 ] GEO卫星辅助车联网 任务卸载、计算和通信资源联合分配 时延 优化、DQN [16 ] 天地一体化网络 通信、缓存和计算资源联合分配 通信、缓存和计算开销 DQN [17 ] 多层卫星网络 缓存策略、计算卸载、接入选择联合决策 缓存和计算开销 A3C 路由选择 [19 ] LEO卫星星座 下一跳路由选择 跳数、丢包率、拥塞避免 Double DQN [20 ] 天地一体化网络 下一跳路由选择 时延、丢包率、吞吐量 DDPG [21 ] LEO卫星星座 下一跳路由选择 时延、卫星电池能量寿命 DQN [22 ] LEO卫星星座 抗干扰路径集合计算 集合中链路不受干扰 近似策略优化 卫星切换 [24 ] LEO卫星星座 切换选择 QoE DQN [25 ] LEO卫星星座 切换选择 切换次数 MARL 接入选择 [26 ] 空天地一体化网络 接入选择 吞吐量 DQN [27 ] 空天地一体化网络 接入选择与航迹调整 吞吐量 DQN
3 基于DRL的星地网络中继选择算法 对于星地网络中继节点选择的已有研究, 大多集中于信号强度、地理空间距离、信道质量、负载等因素, 将中继节点选择问题建模为针对传输速率、系统吞吐量、中断概率、能量利用率等指标的优化问题, 并利用优化、博弈论等方法进行求解.通过分析已有研究工作, 可以发现已有的星地网络中继选择算法面临的挑战主要包括以下几点[34 ] : ...
基于GA-SA的低轨星座传感器资源调度算法
1
2018
... 针对频分复用体制中的信道分配问题, 文献[4 ]采用已经分配的信道与其对应地理位置为状态s , 将各个信道作为动作空间A , 并通过求解Q网络得到最优策略π.文献[4 ]指出, 迭代的元启发式资源分配算法[5 ] 因计算复杂度高而难以保证实时性, 且忽略了在线信道分配问题的序列性, 因此提出了基于DQN的多波束地球静止轨道(geostationary orbit, GEO)卫星信道在线分配方法.在此基础上, 文献[6 ]提出了低轨道(low earth orbit, LEO)卫星物联网场景下的信道资源分配方法.首先, 提出了一种基于滑动块的感知方法, 以应对LEO星座的移动性; 其次, 针对LEO卫星能量受限问题, 提出了考虑能量利用率的信道分配方法, 采用与文献[4 ]类似的状态表示方法和网络结构, 利用能量利用率改进DQN的即时收益r , 将能耗降低了65%以上.但此方法并未考虑LEO卫星切换对用户信道分配方案的影响. ...
LEO constellation sensor resources scheduling algorithm based on genetic and simulated annealing
1
2018
... 针对频分复用体制中的信道分配问题, 文献[4 ]采用已经分配的信道与其对应地理位置为状态s , 将各个信道作为动作空间A , 并通过求解Q网络得到最优策略π.文献[4 ]指出, 迭代的元启发式资源分配算法[5 ] 因计算复杂度高而难以保证实时性, 且忽略了在线信道分配问题的序列性, 因此提出了基于DQN的多波束地球静止轨道(geostationary orbit, GEO)卫星信道在线分配方法.在此基础上, 文献[6 ]提出了低轨道(low earth orbit, LEO)卫星物联网场景下的信道资源分配方法.首先, 提出了一种基于滑动块的感知方法, 以应对LEO星座的移动性; 其次, 针对LEO卫星能量受限问题, 提出了考虑能量利用率的信道分配方法, 采用与文献[4 ]类似的状态表示方法和网络结构, 利用能量利用率改进DQN的即时收益r , 将能耗降低了65%以上.但此方法并未考虑LEO卫星切换对用户信道分配方案的影响. ...
A deep reinforcement learning based approach for energy-efficient channel allocation in satellite Internet of things
3
2020
... 针对频分复用体制中的信道分配问题, 文献[4 ]采用已经分配的信道与其对应地理位置为状态s , 将各个信道作为动作空间A , 并通过求解Q网络得到最优策略π.文献[4 ]指出, 迭代的元启发式资源分配算法[5 ] 因计算复杂度高而难以保证实时性, 且忽略了在线信道分配问题的序列性, 因此提出了基于DQN的多波束地球静止轨道(geostationary orbit, GEO)卫星信道在线分配方法.在此基础上, 文献[6 ]提出了低轨道(low earth orbit, LEO)卫星物联网场景下的信道资源分配方法.首先, 提出了一种基于滑动块的感知方法, 以应对LEO星座的移动性; 其次, 针对LEO卫星能量受限问题, 提出了考虑能量利用率的信道分配方法, 采用与文献[4 ]类似的状态表示方法和网络结构, 利用能量利用率改进DQN的即时收益r , 将能耗降低了65%以上.但此方法并未考虑LEO卫星切换对用户信道分配方案的影响. ...
... 不同于文献[4 , 6 ]主要研究用户的信道分配问题, 文献[7 ]关注各波束带宽分配问题, 考虑到多波束GEO卫星的各个波束传输需求不均衡且存在动态变化的问题, 提出了一种基于MARL的带宽分配算法.将每个波束视为一个智能体, 感知本波束的传输需求,并将其作为状态s , 并通过各智能体间的协作学习到各波束协同频谱分配策略π.仿真实验表明, 此方法能使波束数据传输能力更符合动态流量需求, 且时间复杂度更低. ...
... A summary of existing research related to DRL in SIN
Table 3 领域 文献 场景 针对问题 优化目标 DRL方法 资源分配 [3 ] 多波束GEO卫星网络 用户时隙分配 用户满意度、能量和频谱利用率 DQN [4 ] 多波束GEO卫星网络 用户信道分配 呼通率 DQN [6 ] LEO卫星物联网 用户信道分配 能量利用率 DQN [7 ] 多波束GEO卫星网络 波束带宽分配 公平性、流量满足程度 MARL [8 ] 多波束GEO卫星网络 波束功率分配 功率消耗、流量满足程度 DDPG [10 ] GEO卫星网络 配置链路参数 吞吐量、误码率、功耗、带宽稳定 DQN 跳波束 [11 ] 多波束GEO卫星 波束点亮方案 传输时延 DQN [12 ] 多波束GEO卫星 波束点亮方案 实时服务时延, 非实时服务吞吐量, 公平性 双环DQN 计算卸载与缓存 [14 ] 空天地一体化网络 任务卸载位置决策 平均处理时延 DQN [15 ] GEO卫星辅助车联网 任务卸载、计算和通信资源联合分配 时延 优化、DQN [16 ] 天地一体化网络 通信、缓存和计算资源联合分配 通信、缓存和计算开销 DQN [17 ] 多层卫星网络 缓存策略、计算卸载、接入选择联合决策 缓存和计算开销 A3C 路由选择 [19 ] LEO卫星星座 下一跳路由选择 跳数、丢包率、拥塞避免 Double DQN [20 ] 天地一体化网络 下一跳路由选择 时延、丢包率、吞吐量 DDPG [21 ] LEO卫星星座 下一跳路由选择 时延、卫星电池能量寿命 DQN [22 ] LEO卫星星座 抗干扰路径集合计算 集合中链路不受干扰 近似策略优化 卫星切换 [24 ] LEO卫星星座 切换选择 QoE DQN [25 ] LEO卫星星座 切换选择 切换次数 MARL 接入选择 [26 ] 空天地一体化网络 接入选择 吞吐量 DQN [27 ] 空天地一体化网络 接入选择与航迹调整 吞吐量 DQN
3 基于DRL的星地网络中继选择算法 对于星地网络中继节点选择的已有研究, 大多集中于信号强度、地理空间距离、信道质量、负载等因素, 将中继节点选择问题建模为针对传输速率、系统吞吐量、中断概率、能量利用率等指标的优化问题, 并利用优化、博弈论等方法进行求解.通过分析已有研究工作, 可以发现已有的星地网络中继选择算法面临的挑战主要包括以下几点[34 ] : ...
Multi-agent deep reinforcement learning-based flexible satellite payload for mobile terminals
2
2020
... 不同于文献[4 , 6 ]主要研究用户的信道分配问题, 文献[7 ]关注各波束带宽分配问题, 考虑到多波束GEO卫星的各个波束传输需求不均衡且存在动态变化的问题, 提出了一种基于MARL的带宽分配算法.将每个波束视为一个智能体, 感知本波束的传输需求,并将其作为状态s , 并通过各智能体间的协作学习到各波束协同频谱分配策略π.仿真实验表明, 此方法能使波束数据传输能力更符合动态流量需求, 且时间复杂度更低. ...
... A summary of existing research related to DRL in SIN
Table 3 领域 文献 场景 针对问题 优化目标 DRL方法 资源分配 [3 ] 多波束GEO卫星网络 用户时隙分配 用户满意度、能量和频谱利用率 DQN [4 ] 多波束GEO卫星网络 用户信道分配 呼通率 DQN [6 ] LEO卫星物联网 用户信道分配 能量利用率 DQN [7 ] 多波束GEO卫星网络 波束带宽分配 公平性、流量满足程度 MARL [8 ] 多波束GEO卫星网络 波束功率分配 功率消耗、流量满足程度 DDPG [10 ] GEO卫星网络 配置链路参数 吞吐量、误码率、功耗、带宽稳定 DQN 跳波束 [11 ] 多波束GEO卫星 波束点亮方案 传输时延 DQN [12 ] 多波束GEO卫星 波束点亮方案 实时服务时延, 非实时服务吞吐量, 公平性 双环DQN 计算卸载与缓存 [14 ] 空天地一体化网络 任务卸载位置决策 平均处理时延 DQN [15 ] GEO卫星辅助车联网 任务卸载、计算和通信资源联合分配 时延 优化、DQN [16 ] 天地一体化网络 通信、缓存和计算资源联合分配 通信、缓存和计算开销 DQN [17 ] 多层卫星网络 缓存策略、计算卸载、接入选择联合决策 缓存和计算开销 A3C 路由选择 [19 ] LEO卫星星座 下一跳路由选择 跳数、丢包率、拥塞避免 Double DQN [20 ] 天地一体化网络 下一跳路由选择 时延、丢包率、吞吐量 DDPG [21 ] LEO卫星星座 下一跳路由选择 时延、卫星电池能量寿命 DQN [22 ] LEO卫星星座 抗干扰路径集合计算 集合中链路不受干扰 近似策略优化 卫星切换 [24 ] LEO卫星星座 切换选择 QoE DQN [25 ] LEO卫星星座 切换选择 切换次数 MARL 接入选择 [26 ] 空天地一体化网络 接入选择 吞吐量 DQN [27 ] 空天地一体化网络 接入选择与航迹调整 吞吐量 DQN
3 基于DRL的星地网络中继选择算法 对于星地网络中继节点选择的已有研究, 大多集中于信号强度、地理空间距离、信道质量、负载等因素, 将中继节点选择问题建模为针对传输速率、系统吞吐量、中断概率、能量利用率等指标的优化问题, 并利用优化、博弈论等方法进行求解.通过分析已有研究工作, 可以发现已有的星地网络中继选择算法面临的挑战主要包括以下几点[34 ] : ...
2
... 星上功率资源受限于卫星太阳能电池板的容量, 因此如何高效利用有限功率是SIN中的关键问题.基于DRL的功率分配方法往往通过感知链路状态、干扰情况、用户流量需求, 为各波束和用户确定恰当的发送功率.文献[8 ]利用DDPG方法感知各个波束缓冲区内的数据量, 并将其作为状态s , 将发送功率作为动作a , 在满足用户需求的条件下有效降低了功耗.然而, 此方法的DRL动作空间与波束个数成正比, 因此为保障DRL收敛, 较适合于小规模波束的卫星场景.文献[9 ]比较了基于遗传算法、模拟退火、粒子群、粒子群-遗传混合方法和DRL的GEO卫星动态功率分配方法在时间收敛性、连续可操作性、可扩展性和鲁棒性等方面的性能. ...
... A summary of existing research related to DRL in SIN
Table 3 领域 文献 场景 针对问题 优化目标 DRL方法 资源分配 [3 ] 多波束GEO卫星网络 用户时隙分配 用户满意度、能量和频谱利用率 DQN [4 ] 多波束GEO卫星网络 用户信道分配 呼通率 DQN [6 ] LEO卫星物联网 用户信道分配 能量利用率 DQN [7 ] 多波束GEO卫星网络 波束带宽分配 公平性、流量满足程度 MARL [8 ] 多波束GEO卫星网络 波束功率分配 功率消耗、流量满足程度 DDPG [10 ] GEO卫星网络 配置链路参数 吞吐量、误码率、功耗、带宽稳定 DQN 跳波束 [11 ] 多波束GEO卫星 波束点亮方案 传输时延 DQN [12 ] 多波束GEO卫星 波束点亮方案 实时服务时延, 非实时服务吞吐量, 公平性 双环DQN 计算卸载与缓存 [14 ] 空天地一体化网络 任务卸载位置决策 平均处理时延 DQN [15 ] GEO卫星辅助车联网 任务卸载、计算和通信资源联合分配 时延 优化、DQN [16 ] 天地一体化网络 通信、缓存和计算资源联合分配 通信、缓存和计算开销 DQN [17 ] 多层卫星网络 缓存策略、计算卸载、接入选择联合决策 缓存和计算开销 A3C 路由选择 [19 ] LEO卫星星座 下一跳路由选择 跳数、丢包率、拥塞避免 Double DQN [20 ] 天地一体化网络 下一跳路由选择 时延、丢包率、吞吐量 DDPG [21 ] LEO卫星星座 下一跳路由选择 时延、卫星电池能量寿命 DQN [22 ] LEO卫星星座 抗干扰路径集合计算 集合中链路不受干扰 近似策略优化 卫星切换 [24 ] LEO卫星星座 切换选择 QoE DQN [25 ] LEO卫星星座 切换选择 切换次数 MARL 接入选择 [26 ] 空天地一体化网络 接入选择 吞吐量 DQN [27 ] 空天地一体化网络 接入选择与航迹调整 吞吐量 DQN
3 基于DRL的星地网络中继选择算法 对于星地网络中继节点选择的已有研究, 大多集中于信号强度、地理空间距离、信道质量、负载等因素, 将中继节点选择问题建模为针对传输速率、系统吞吐量、中断概率、能量利用率等指标的优化问题, 并利用优化、博弈论等方法进行求解.通过分析已有研究工作, 可以发现已有的星地网络中继选择算法面临的挑战主要包括以下几点[34 ] : ...
1
... 星上功率资源受限于卫星太阳能电池板的容量, 因此如何高效利用有限功率是SIN中的关键问题.基于DRL的功率分配方法往往通过感知链路状态、干扰情况、用户流量需求, 为各波束和用户确定恰当的发送功率.文献[8 ]利用DDPG方法感知各个波束缓冲区内的数据量, 并将其作为状态s , 将发送功率作为动作a , 在满足用户需求的条件下有效降低了功耗.然而, 此方法的DRL动作空间与波束个数成正比, 因此为保障DRL收敛, 较适合于小规模波束的卫星场景.文献[9 ]比较了基于遗传算法、模拟退火、粒子群、粒子群-遗传混合方法和DRL的GEO卫星动态功率分配方法在时间收敛性、连续可操作性、可扩展性和鲁棒性等方面的性能. ...
Multi-objective reinforcement learning for cognitive sate-llite communications using deep neural network ensembles
2
2018
... 为解决卫星的链路配置问题, 通常将用户流量需求和信道环境作为状态空间S , 将需配置的传输链路的通信参数, 包括调制方案、编码速率、带宽等, 作为动作空间A .传统方法通常基于经验规则或建模优化得到固定配置, 难以应对动态变化的复杂SIN环境.针对此问题, 文献[10 ]提出基于集成DQN的多目标链路资源配置认知模块, 将最大化吞吐量、最小化误码率和功耗、保持带宽稳定等多个优化目标对应的指标加权作为即时收益r , 优化链路资源参数配置策略π, 并进一步将此认知模块部署于实际GEO卫星进行测试, 实测结果表明其有效提高了GEO卫星系统在不同天气状态下的传输性能. ...
... A summary of existing research related to DRL in SIN
Table 3 领域 文献 场景 针对问题 优化目标 DRL方法 资源分配 [3 ] 多波束GEO卫星网络 用户时隙分配 用户满意度、能量和频谱利用率 DQN [4 ] 多波束GEO卫星网络 用户信道分配 呼通率 DQN [6 ] LEO卫星物联网 用户信道分配 能量利用率 DQN [7 ] 多波束GEO卫星网络 波束带宽分配 公平性、流量满足程度 MARL [8 ] 多波束GEO卫星网络 波束功率分配 功率消耗、流量满足程度 DDPG [10 ] GEO卫星网络 配置链路参数 吞吐量、误码率、功耗、带宽稳定 DQN 跳波束 [11 ] 多波束GEO卫星 波束点亮方案 传输时延 DQN [12 ] 多波束GEO卫星 波束点亮方案 实时服务时延, 非实时服务吞吐量, 公平性 双环DQN 计算卸载与缓存 [14 ] 空天地一体化网络 任务卸载位置决策 平均处理时延 DQN [15 ] GEO卫星辅助车联网 任务卸载、计算和通信资源联合分配 时延 优化、DQN [16 ] 天地一体化网络 通信、缓存和计算资源联合分配 通信、缓存和计算开销 DQN [17 ] 多层卫星网络 缓存策略、计算卸载、接入选择联合决策 缓存和计算开销 A3C 路由选择 [19 ] LEO卫星星座 下一跳路由选择 跳数、丢包率、拥塞避免 Double DQN [20 ] 天地一体化网络 下一跳路由选择 时延、丢包率、吞吐量 DDPG [21 ] LEO卫星星座 下一跳路由选择 时延、卫星电池能量寿命 DQN [22 ] LEO卫星星座 抗干扰路径集合计算 集合中链路不受干扰 近似策略优化 卫星切换 [24 ] LEO卫星星座 切换选择 QoE DQN [25 ] LEO卫星星座 切换选择 切换次数 MARL 接入选择 [26 ] 空天地一体化网络 接入选择 吞吐量 DQN [27 ] 空天地一体化网络 接入选择与航迹调整 吞吐量 DQN
3 基于DRL的星地网络中继选择算法 对于星地网络中继节点选择的已有研究, 大多集中于信号强度、地理空间距离、信道质量、负载等因素, 将中继节点选择问题建模为针对传输速率、系统吞吐量、中断概率、能量利用率等指标的优化问题, 并利用优化、博弈论等方法进行求解.通过分析已有研究工作, 可以发现已有的星地网络中继选择算法面临的挑战主要包括以下几点[34 ] : ...
Deep reinforcement learning-based beam Hopping algorithm in multibeam satellite systems
3
2019
... 文献[11 ]利用DQN方法进行波束跳变决策, 根据各波束缓冲区队列长度和链路质量决定每一波束是否点亮.文献[12 ]考虑到实时服务需要降低时延, 而非实时服务需要提高传输速率, 在文献[11 ]的基础上改进了即时收益r .并针对由动作空间大而导致的维度灾难问题, 提出基于双环学习的多行动决策方法.相比最大化最小速率和遗传算法, 基于DRL的跳波束策略使平均传输时延分别降低了42.12%和21.4%. ...
... ]考虑到实时服务需要降低时延, 而非实时服务需要提高传输速率, 在文献[11 ]的基础上改进了即时收益r .并针对由动作空间大而导致的维度灾难问题, 提出基于双环学习的多行动决策方法.相比最大化最小速率和遗传算法, 基于DRL的跳波束策略使平均传输时延分别降低了42.12%和21.4%. ...
... A summary of existing research related to DRL in SIN
Table 3 领域 文献 场景 针对问题 优化目标 DRL方法 资源分配 [3 ] 多波束GEO卫星网络 用户时隙分配 用户满意度、能量和频谱利用率 DQN [4 ] 多波束GEO卫星网络 用户信道分配 呼通率 DQN [6 ] LEO卫星物联网 用户信道分配 能量利用率 DQN [7 ] 多波束GEO卫星网络 波束带宽分配 公平性、流量满足程度 MARL [8 ] 多波束GEO卫星网络 波束功率分配 功率消耗、流量满足程度 DDPG [10 ] GEO卫星网络 配置链路参数 吞吐量、误码率、功耗、带宽稳定 DQN 跳波束 [11 ] 多波束GEO卫星 波束点亮方案 传输时延 DQN [12 ] 多波束GEO卫星 波束点亮方案 实时服务时延, 非实时服务吞吐量, 公平性 双环DQN 计算卸载与缓存 [14 ] 空天地一体化网络 任务卸载位置决策 平均处理时延 DQN [15 ] GEO卫星辅助车联网 任务卸载、计算和通信资源联合分配 时延 优化、DQN [16 ] 天地一体化网络 通信、缓存和计算资源联合分配 通信、缓存和计算开销 DQN [17 ] 多层卫星网络 缓存策略、计算卸载、接入选择联合决策 缓存和计算开销 A3C 路由选择 [19 ] LEO卫星星座 下一跳路由选择 跳数、丢包率、拥塞避免 Double DQN [20 ] 天地一体化网络 下一跳路由选择 时延、丢包率、吞吐量 DDPG [21 ] LEO卫星星座 下一跳路由选择 时延、卫星电池能量寿命 DQN [22 ] LEO卫星星座 抗干扰路径集合计算 集合中链路不受干扰 近似策略优化 卫星切换 [24 ] LEO卫星星座 切换选择 QoE DQN [25 ] LEO卫星星座 切换选择 切换次数 MARL 接入选择 [26 ] 空天地一体化网络 接入选择 吞吐量 DQN [27 ] 空天地一体化网络 接入选择与航迹调整 吞吐量 DQN
3 基于DRL的星地网络中继选择算法 对于星地网络中继节点选择的已有研究, 大多集中于信号强度、地理空间距离、信道质量、负载等因素, 将中继节点选择问题建模为针对传输速率、系统吞吐量、中断概率、能量利用率等指标的优化问题, 并利用优化、博弈论等方法进行求解.通过分析已有研究工作, 可以发现已有的星地网络中继选择算法面临的挑战主要包括以下几点[34 ] : ...
Dynamic beam hopping method based on multi-objective deep reinforcement learning for next generation satellite broadband systems
3
2020
... 文献[11 ]利用DQN方法进行波束跳变决策, 根据各波束缓冲区队列长度和链路质量决定每一波束是否点亮.文献[12 ]考虑到实时服务需要降低时延, 而非实时服务需要提高传输速率, 在文献[11 ]的基础上改进了即时收益r .并针对由动作空间大而导致的维度灾难问题, 提出基于双环学习的多行动决策方法.相比最大化最小速率和遗传算法, 基于DRL的跳波束策略使平均传输时延分别降低了42.12%和21.4%. ...
... 综上所述, 智能波束调度方法的优势在于可根据动态时变的业务需求和信道质量进行决策, 使波束点亮方案所提供的传输速率与流量需求更趋一致.其面临的主要问题在于随着波束数量的增加, 决策动作空间A 成倍增加, 对此文献[12 ]提供了一种解决思路, 但此问题尚未解决. ...
... A summary of existing research related to DRL in SIN
Table 3 领域 文献 场景 针对问题 优化目标 DRL方法 资源分配 [3 ] 多波束GEO卫星网络 用户时隙分配 用户满意度、能量和频谱利用率 DQN [4 ] 多波束GEO卫星网络 用户信道分配 呼通率 DQN [6 ] LEO卫星物联网 用户信道分配 能量利用率 DQN [7 ] 多波束GEO卫星网络 波束带宽分配 公平性、流量满足程度 MARL [8 ] 多波束GEO卫星网络 波束功率分配 功率消耗、流量满足程度 DDPG [10 ] GEO卫星网络 配置链路参数 吞吐量、误码率、功耗、带宽稳定 DQN 跳波束 [11 ] 多波束GEO卫星 波束点亮方案 传输时延 DQN [12 ] 多波束GEO卫星 波束点亮方案 实时服务时延, 非实时服务吞吐量, 公平性 双环DQN 计算卸载与缓存 [14 ] 空天地一体化网络 任务卸载位置决策 平均处理时延 DQN [15 ] GEO卫星辅助车联网 任务卸载、计算和通信资源联合分配 时延 优化、DQN [16 ] 天地一体化网络 通信、缓存和计算资源联合分配 通信、缓存和计算开销 DQN [17 ] 多层卫星网络 缓存策略、计算卸载、接入选择联合决策 缓存和计算开销 A3C 路由选择 [19 ] LEO卫星星座 下一跳路由选择 跳数、丢包率、拥塞避免 Double DQN [20 ] 天地一体化网络 下一跳路由选择 时延、丢包率、吞吐量 DDPG [21 ] LEO卫星星座 下一跳路由选择 时延、卫星电池能量寿命 DQN [22 ] LEO卫星星座 抗干扰路径集合计算 集合中链路不受干扰 近似策略优化 卫星切换 [24 ] LEO卫星星座 切换选择 QoE DQN [25 ] LEO卫星星座 切换选择 切换次数 MARL 接入选择 [26 ] 空天地一体化网络 接入选择 吞吐量 DQN [27 ] 空天地一体化网络 接入选择与航迹调整 吞吐量 DQN
3 基于DRL的星地网络中继选择算法 对于星地网络中继节点选择的已有研究, 大多集中于信号强度、地理空间距离、信道质量、负载等因素, 将中继节点选择问题建模为针对传输速率、系统吞吐量、中断概率、能量利用率等指标的优化问题, 并利用优化、博弈论等方法进行求解.通过分析已有研究工作, 可以发现已有的星地网络中继选择算法面临的挑战主要包括以下几点[34 ] : ...
Computation offloading in LEO satellite networks with hybrid cloud and edge computing
1
2021
... 随着计算任务在业务中占比的日益增加, 计算卸载已成为地面网络的研究热点.随着星上处理能力的日趋提高, 卫星不仅可以作为计算卸载的中继传输节点, 也可部署边缘计算服务器提供计算能力[13 ] .基于DRL的计算卸载问题通常将任务的所有备选计算位置作为动作空间A , 以任务处理时延(包括通信时延和计算时延)为即时收益r , 用于优化决策策略π.通常组成状态空间A 的信息包括: 任务的计算量、数据通信量、信道质量和各网络节点的通信与计算能力. ...
Deep reinforcement learning for delay-oriented IoT task scheduling in space-air-ground integrated network
3
2020
... 文献[14 ]将空天地一体化的物联网场景中的任务卸载问题建模为受限的MDP, 利用风险敏感的DQN,以当前无人机位置和任务队列作为状态s , 在能量受限条件下, 决定此计算任务的处理位置.动作空间A 包括在无人机本地处理、卸载到基站或是卫星处理.利用同等能耗, 将平均时延降低了35%.针对卫星辅助车对车场景下的计算卸载、计算和通信资源分配问题, 文献[15 ]将其分解为两个子问题: 一是固定卸载决策下的计算与通信资源分配, 采用拉格朗日乘子法求解; 二是确定资源分配条件下的任务卸载, 建模为MDP后采用DRL决定卸载位置, 从而有效降低了平均时延. ...
... A summary of existing research related to DRL in SIN
Table 3 领域 文献 场景 针对问题 优化目标 DRL方法 资源分配 [3 ] 多波束GEO卫星网络 用户时隙分配 用户满意度、能量和频谱利用率 DQN [4 ] 多波束GEO卫星网络 用户信道分配 呼通率 DQN [6 ] LEO卫星物联网 用户信道分配 能量利用率 DQN [7 ] 多波束GEO卫星网络 波束带宽分配 公平性、流量满足程度 MARL [8 ] 多波束GEO卫星网络 波束功率分配 功率消耗、流量满足程度 DDPG [10 ] GEO卫星网络 配置链路参数 吞吐量、误码率、功耗、带宽稳定 DQN 跳波束 [11 ] 多波束GEO卫星 波束点亮方案 传输时延 DQN [12 ] 多波束GEO卫星 波束点亮方案 实时服务时延, 非实时服务吞吐量, 公平性 双环DQN 计算卸载与缓存 [14 ] 空天地一体化网络 任务卸载位置决策 平均处理时延 DQN [15 ] GEO卫星辅助车联网 任务卸载、计算和通信资源联合分配 时延 优化、DQN [16 ] 天地一体化网络 通信、缓存和计算资源联合分配 通信、缓存和计算开销 DQN [17 ] 多层卫星网络 缓存策略、计算卸载、接入选择联合决策 缓存和计算开销 A3C 路由选择 [19 ] LEO卫星星座 下一跳路由选择 跳数、丢包率、拥塞避免 Double DQN [20 ] 天地一体化网络 下一跳路由选择 时延、丢包率、吞吐量 DDPG [21 ] LEO卫星星座 下一跳路由选择 时延、卫星电池能量寿命 DQN [22 ] LEO卫星星座 抗干扰路径集合计算 集合中链路不受干扰 近似策略优化 卫星切换 [24 ] LEO卫星星座 切换选择 QoE DQN [25 ] LEO卫星星座 切换选择 切换次数 MARL 接入选择 [26 ] 空天地一体化网络 接入选择 吞吐量 DQN [27 ] 空天地一体化网络 接入选择与航迹调整 吞吐量 DQN
3 基于DRL的星地网络中继选择算法 对于星地网络中继节点选择的已有研究, 大多集中于信号强度、地理空间距离、信道质量、负载等因素, 将中继节点选择问题建模为针对传输速率、系统吞吐量、中断概率、能量利用率等指标的优化问题, 并利用优化、博弈论等方法进行求解.通过分析已有研究工作, 可以发现已有的星地网络中继选择算法面临的挑战主要包括以下几点[34 ] : ...
... 经典的DRL方法大多适用于相对简单直接的计算机领域问题, 将其应用于SIN实际问题中, 面临高维决策空间、复杂约束和互相矛盾的多个优化目标等难点, 需要在DRL方法的改进上进行研究, 使其适应SIN实际问题.文献[14 ]采用风险敏感的DRL方法处理时延约束, 对改进约束处理方式进行了初步探索, 但此问题还有待深入研究. ...
Joint offloading and resource allocation for satellite assisted vehicle-to-vehicle communication
2
2020
... 文献[14 ]将空天地一体化的物联网场景中的任务卸载问题建模为受限的MDP, 利用风险敏感的DQN,以当前无人机位置和任务队列作为状态s , 在能量受限条件下, 决定此计算任务的处理位置.动作空间A 包括在无人机本地处理、卸载到基站或是卫星处理.利用同等能耗, 将平均时延降低了35%.针对卫星辅助车对车场景下的计算卸载、计算和通信资源分配问题, 文献[15 ]将其分解为两个子问题: 一是固定卸载决策下的计算与通信资源分配, 采用拉格朗日乘子法求解; 二是确定资源分配条件下的任务卸载, 建模为MDP后采用DRL决定卸载位置, 从而有效降低了平均时延. ...
... A summary of existing research related to DRL in SIN
Table 3 领域 文献 场景 针对问题 优化目标 DRL方法 资源分配 [3 ] 多波束GEO卫星网络 用户时隙分配 用户满意度、能量和频谱利用率 DQN [4 ] 多波束GEO卫星网络 用户信道分配 呼通率 DQN [6 ] LEO卫星物联网 用户信道分配 能量利用率 DQN [7 ] 多波束GEO卫星网络 波束带宽分配 公平性、流量满足程度 MARL [8 ] 多波束GEO卫星网络 波束功率分配 功率消耗、流量满足程度 DDPG [10 ] GEO卫星网络 配置链路参数 吞吐量、误码率、功耗、带宽稳定 DQN 跳波束 [11 ] 多波束GEO卫星 波束点亮方案 传输时延 DQN [12 ] 多波束GEO卫星 波束点亮方案 实时服务时延, 非实时服务吞吐量, 公平性 双环DQN 计算卸载与缓存 [14 ] 空天地一体化网络 任务卸载位置决策 平均处理时延 DQN [15 ] GEO卫星辅助车联网 任务卸载、计算和通信资源联合分配 时延 优化、DQN [16 ] 天地一体化网络 通信、缓存和计算资源联合分配 通信、缓存和计算开销 DQN [17 ] 多层卫星网络 缓存策略、计算卸载、接入选择联合决策 缓存和计算开销 A3C 路由选择 [19 ] LEO卫星星座 下一跳路由选择 跳数、丢包率、拥塞避免 Double DQN [20 ] 天地一体化网络 下一跳路由选择 时延、丢包率、吞吐量 DDPG [21 ] LEO卫星星座 下一跳路由选择 时延、卫星电池能量寿命 DQN [22 ] LEO卫星星座 抗干扰路径集合计算 集合中链路不受干扰 近似策略优化 卫星切换 [24 ] LEO卫星星座 切换选择 QoE DQN [25 ] LEO卫星星座 切换选择 切换次数 MARL 接入选择 [26 ] 空天地一体化网络 接入选择 吞吐量 DQN [27 ] 空天地一体化网络 接入选择与航迹调整 吞吐量 DQN
3 基于DRL的星地网络中继选择算法 对于星地网络中继节点选择的已有研究, 大多集中于信号强度、地理空间距离、信道质量、负载等因素, 将中继节点选择问题建模为针对传输速率、系统吞吐量、中断概率、能量利用率等指标的优化问题, 并利用优化、博弈论等方法进行求解.通过分析已有研究工作, 可以发现已有的星地网络中继选择算法面临的挑战主要包括以下几点[34 ] : ...
Deep Q-learning aided networking, caching, and computing resources allocation in software-defined satellite-terrestrial networks
3
2019
... 缓存策略影响计算卸载效果, 因此常对两个问题进行联合优化, 文献[16 -17 ]关注计算卸载与缓存的联合决策问题.文献[16 ]提出了一种基于DRL的通信、缓存和计算资源联合分配方法.仿真结果表明, 在不同的用户卫星夹角、内容大小、通信与缓存费用条件下, 所提方法均能达到更优性能.文献[17 ]采用DRL中的异步优势动作评论家(asynchronous advantage actor-critic, A3C)算法, 通过观察用户与各卫星相对位置、GEO数据中继卫星状态、通信链路质量、缓存状态和各边缘服务器的可用计算能力等信息作为状态s , 将接入的LEO卫星、任务卸载的服务器、是否通过GEO卫星中继以及当前请求内容是否被缓存这4个问题的联合决策作为动作a .此方案能有效提高单位资源的收益. ...
... ]关注计算卸载与缓存的联合决策问题.文献[16 ]提出了一种基于DRL的通信、缓存和计算资源联合分配方法.仿真结果表明, 在不同的用户卫星夹角、内容大小、通信与缓存费用条件下, 所提方法均能达到更优性能.文献[17 ]采用DRL中的异步优势动作评论家(asynchronous advantage actor-critic, A3C)算法, 通过观察用户与各卫星相对位置、GEO数据中继卫星状态、通信链路质量、缓存状态和各边缘服务器的可用计算能力等信息作为状态s , 将接入的LEO卫星、任务卸载的服务器、是否通过GEO卫星中继以及当前请求内容是否被缓存这4个问题的联合决策作为动作a .此方案能有效提高单位资源的收益. ...
... A summary of existing research related to DRL in SIN
Table 3 领域 文献 场景 针对问题 优化目标 DRL方法 资源分配 [3 ] 多波束GEO卫星网络 用户时隙分配 用户满意度、能量和频谱利用率 DQN [4 ] 多波束GEO卫星网络 用户信道分配 呼通率 DQN [6 ] LEO卫星物联网 用户信道分配 能量利用率 DQN [7 ] 多波束GEO卫星网络 波束带宽分配 公平性、流量满足程度 MARL [8 ] 多波束GEO卫星网络 波束功率分配 功率消耗、流量满足程度 DDPG [10 ] GEO卫星网络 配置链路参数 吞吐量、误码率、功耗、带宽稳定 DQN 跳波束 [11 ] 多波束GEO卫星 波束点亮方案 传输时延 DQN [12 ] 多波束GEO卫星 波束点亮方案 实时服务时延, 非实时服务吞吐量, 公平性 双环DQN 计算卸载与缓存 [14 ] 空天地一体化网络 任务卸载位置决策 平均处理时延 DQN [15 ] GEO卫星辅助车联网 任务卸载、计算和通信资源联合分配 时延 优化、DQN [16 ] 天地一体化网络 通信、缓存和计算资源联合分配 通信、缓存和计算开销 DQN [17 ] 多层卫星网络 缓存策略、计算卸载、接入选择联合决策 缓存和计算开销 A3C 路由选择 [19 ] LEO卫星星座 下一跳路由选择 跳数、丢包率、拥塞避免 Double DQN [20 ] 天地一体化网络 下一跳路由选择 时延、丢包率、吞吐量 DDPG [21 ] LEO卫星星座 下一跳路由选择 时延、卫星电池能量寿命 DQN [22 ] LEO卫星星座 抗干扰路径集合计算 集合中链路不受干扰 近似策略优化 卫星切换 [24 ] LEO卫星星座 切换选择 QoE DQN [25 ] LEO卫星星座 切换选择 切换次数 MARL 接入选择 [26 ] 空天地一体化网络 接入选择 吞吐量 DQN [27 ] 空天地一体化网络 接入选择与航迹调整 吞吐量 DQN
3 基于DRL的星地网络中继选择算法 对于星地网络中继节点选择的已有研究, 大多集中于信号强度、地理空间距离、信道质量、负载等因素, 将中继节点选择问题建模为针对传输速率、系统吞吐量、中断概率、能量利用率等指标的优化问题, 并利用优化、博弈论等方法进行求解.通过分析已有研究工作, 可以发现已有的星地网络中继选择算法面临的挑战主要包括以下几点[34 ] : ...
Research on resource allocation method of space information networks based on deep reinforcement learning
3
2019
... 缓存策略影响计算卸载效果, 因此常对两个问题进行联合优化, 文献[16 -17 ]关注计算卸载与缓存的联合决策问题.文献[16 ]提出了一种基于DRL的通信、缓存和计算资源联合分配方法.仿真结果表明, 在不同的用户卫星夹角、内容大小、通信与缓存费用条件下, 所提方法均能达到更优性能.文献[17 ]采用DRL中的异步优势动作评论家(asynchronous advantage actor-critic, A3C)算法, 通过观察用户与各卫星相对位置、GEO数据中继卫星状态、通信链路质量、缓存状态和各边缘服务器的可用计算能力等信息作为状态s , 将接入的LEO卫星、任务卸载的服务器、是否通过GEO卫星中继以及当前请求内容是否被缓存这4个问题的联合决策作为动作a .此方案能有效提高单位资源的收益. ...
... ]提出了一种基于DRL的通信、缓存和计算资源联合分配方法.仿真结果表明, 在不同的用户卫星夹角、内容大小、通信与缓存费用条件下, 所提方法均能达到更优性能.文献[17 ]采用DRL中的异步优势动作评论家(asynchronous advantage actor-critic, A3C)算法, 通过观察用户与各卫星相对位置、GEO数据中继卫星状态、通信链路质量、缓存状态和各边缘服务器的可用计算能力等信息作为状态s , 将接入的LEO卫星、任务卸载的服务器、是否通过GEO卫星中继以及当前请求内容是否被缓存这4个问题的联合决策作为动作a .此方案能有效提高单位资源的收益. ...
... A summary of existing research related to DRL in SIN
Table 3 领域 文献 场景 针对问题 优化目标 DRL方法 资源分配 [3 ] 多波束GEO卫星网络 用户时隙分配 用户满意度、能量和频谱利用率 DQN [4 ] 多波束GEO卫星网络 用户信道分配 呼通率 DQN [6 ] LEO卫星物联网 用户信道分配 能量利用率 DQN [7 ] 多波束GEO卫星网络 波束带宽分配 公平性、流量满足程度 MARL [8 ] 多波束GEO卫星网络 波束功率分配 功率消耗、流量满足程度 DDPG [10 ] GEO卫星网络 配置链路参数 吞吐量、误码率、功耗、带宽稳定 DQN 跳波束 [11 ] 多波束GEO卫星 波束点亮方案 传输时延 DQN [12 ] 多波束GEO卫星 波束点亮方案 实时服务时延, 非实时服务吞吐量, 公平性 双环DQN 计算卸载与缓存 [14 ] 空天地一体化网络 任务卸载位置决策 平均处理时延 DQN [15 ] GEO卫星辅助车联网 任务卸载、计算和通信资源联合分配 时延 优化、DQN [16 ] 天地一体化网络 通信、缓存和计算资源联合分配 通信、缓存和计算开销 DQN [17 ] 多层卫星网络 缓存策略、计算卸载、接入选择联合决策 缓存和计算开销 A3C 路由选择 [19 ] LEO卫星星座 下一跳路由选择 跳数、丢包率、拥塞避免 Double DQN [20 ] 天地一体化网络 下一跳路由选择 时延、丢包率、吞吐量 DDPG [21 ] LEO卫星星座 下一跳路由选择 时延、卫星电池能量寿命 DQN [22 ] LEO卫星星座 抗干扰路径集合计算 集合中链路不受干扰 近似策略优化 卫星切换 [24 ] LEO卫星星座 切换选择 QoE DQN [25 ] LEO卫星星座 切换选择 切换次数 MARL 接入选择 [26 ] 空天地一体化网络 接入选择 吞吐量 DQN [27 ] 空天地一体化网络 接入选择与航迹调整 吞吐量 DQN
3 基于DRL的星地网络中继选择算法 对于星地网络中继节点选择的已有研究, 大多集中于信号强度、地理空间距离、信道质量、负载等因素, 将中继节点选择问题建模为针对传输速率、系统吞吐量、中断概率、能量利用率等指标的优化问题, 并利用优化、博弈论等方法进行求解.通过分析已有研究工作, 可以发现已有的星地网络中继选择算法面临的挑战主要包括以下几点[34 ] : ...
卫星互联网路由技术现状及展望
1
2021
... 传统路由方法存在以下两点不足: 一方面, 随着星座规模的增加, 优化问题的解空间急剧增加, 且多个目标使优化问题更加复杂; 另一方面, 传统方法对时变流量的处理分为割裂的两步: 流量预测与后续的路由算法, 由于预测本身存在误差, 分段式框架易导致误差累积放大[18 ] . ...
Current status and future prospects of routing technologies for satellite Internet
1
2021
... 传统路由方法存在以下两点不足: 一方面, 随着星座规模的增加, 优化问题的解空间急剧增加, 且多个目标使优化问题更加复杂; 另一方面, 传统方法对时变流量的处理分为割裂的两步: 流量预测与后续的路由算法, 由于预测本身存在误差, 分段式框架易导致误差累积放大[18 ] . ...
A two-hops state-aware routing strategy based on deep reinforcement learning for LEO satellite networks
2
2019
... 在基于DRL的路由方法中, 智能体通过观察包含链路质量的状态空间S , 将下一跳备选传输节点作为动作空间A , 可以学习到能自适应感知链路状态并动态调整的路由策略π.文献[20 -21 ]主要利用DRL感知动态变化的链路带宽、丢包率、拥塞情况等信息和时变的不均匀业务流量.文献[19 ]提出了一种基于Double DQN的LEO卫星网络路由算法, 在每个卫星节点智能体感知两跳邻居范围内的链路状态, 并决定下一跳路由.更进一步, 文献[20 ]利用长短期记忆(long short-term memory, LSTM)网络对流量和链路质量的时序预测能力, 提出了一种基于DDPG的软件定义空天地一体化网络路由算法.仿真结果表明, 对比传统方法, 其能达到更低网络时延和更高的吞吐量. ...
... A summary of existing research related to DRL in SIN
Table 3 领域 文献 场景 针对问题 优化目标 DRL方法 资源分配 [3 ] 多波束GEO卫星网络 用户时隙分配 用户满意度、能量和频谱利用率 DQN [4 ] 多波束GEO卫星网络 用户信道分配 呼通率 DQN [6 ] LEO卫星物联网 用户信道分配 能量利用率 DQN [7 ] 多波束GEO卫星网络 波束带宽分配 公平性、流量满足程度 MARL [8 ] 多波束GEO卫星网络 波束功率分配 功率消耗、流量满足程度 DDPG [10 ] GEO卫星网络 配置链路参数 吞吐量、误码率、功耗、带宽稳定 DQN 跳波束 [11 ] 多波束GEO卫星 波束点亮方案 传输时延 DQN [12 ] 多波束GEO卫星 波束点亮方案 实时服务时延, 非实时服务吞吐量, 公平性 双环DQN 计算卸载与缓存 [14 ] 空天地一体化网络 任务卸载位置决策 平均处理时延 DQN [15 ] GEO卫星辅助车联网 任务卸载、计算和通信资源联合分配 时延 优化、DQN [16 ] 天地一体化网络 通信、缓存和计算资源联合分配 通信、缓存和计算开销 DQN [17 ] 多层卫星网络 缓存策略、计算卸载、接入选择联合决策 缓存和计算开销 A3C 路由选择 [19 ] LEO卫星星座 下一跳路由选择 跳数、丢包率、拥塞避免 Double DQN [20 ] 天地一体化网络 下一跳路由选择 时延、丢包率、吞吐量 DDPG [21 ] LEO卫星星座 下一跳路由选择 时延、卫星电池能量寿命 DQN [22 ] LEO卫星星座 抗干扰路径集合计算 集合中链路不受干扰 近似策略优化 卫星切换 [24 ] LEO卫星星座 切换选择 QoE DQN [25 ] LEO卫星星座 切换选择 切换次数 MARL 接入选择 [26 ] 空天地一体化网络 接入选择 吞吐量 DQN [27 ] 空天地一体化网络 接入选择与航迹调整 吞吐量 DQN
3 基于DRL的星地网络中继选择算法 对于星地网络中继节点选择的已有研究, 大多集中于信号强度、地理空间距离、信道质量、负载等因素, 将中继节点选择问题建模为针对传输速率、系统吞吐量、中断概率、能量利用率等指标的优化问题, 并利用优化、博弈论等方法进行求解.通过分析已有研究工作, 可以发现已有的星地网络中继选择算法面临的挑战主要包括以下几点[34 ] : ...
3
... 在基于DRL的路由方法中, 智能体通过观察包含链路质量的状态空间S , 将下一跳备选传输节点作为动作空间A , 可以学习到能自适应感知链路状态并动态调整的路由策略π.文献[20 -21 ]主要利用DRL感知动态变化的链路带宽、丢包率、拥塞情况等信息和时变的不均匀业务流量.文献[19 ]提出了一种基于Double DQN的LEO卫星网络路由算法, 在每个卫星节点智能体感知两跳邻居范围内的链路状态, 并决定下一跳路由.更进一步, 文献[20 ]利用长短期记忆(long short-term memory, LSTM)网络对流量和链路质量的时序预测能力, 提出了一种基于DDPG的软件定义空天地一体化网络路由算法.仿真结果表明, 对比传统方法, 其能达到更低网络时延和更高的吞吐量. ...
... ]提出了一种基于Double DQN的LEO卫星网络路由算法, 在每个卫星节点智能体感知两跳邻居范围内的链路状态, 并决定下一跳路由.更进一步, 文献[20 ]利用长短期记忆(long short-term memory, LSTM)网络对流量和链路质量的时序预测能力, 提出了一种基于DDPG的软件定义空天地一体化网络路由算法.仿真结果表明, 对比传统方法, 其能达到更低网络时延和更高的吞吐量. ...
... A summary of existing research related to DRL in SIN
Table 3 领域 文献 场景 针对问题 优化目标 DRL方法 资源分配 [3 ] 多波束GEO卫星网络 用户时隙分配 用户满意度、能量和频谱利用率 DQN [4 ] 多波束GEO卫星网络 用户信道分配 呼通率 DQN [6 ] LEO卫星物联网 用户信道分配 能量利用率 DQN [7 ] 多波束GEO卫星网络 波束带宽分配 公平性、流量满足程度 MARL [8 ] 多波束GEO卫星网络 波束功率分配 功率消耗、流量满足程度 DDPG [10 ] GEO卫星网络 配置链路参数 吞吐量、误码率、功耗、带宽稳定 DQN 跳波束 [11 ] 多波束GEO卫星 波束点亮方案 传输时延 DQN [12 ] 多波束GEO卫星 波束点亮方案 实时服务时延, 非实时服务吞吐量, 公平性 双环DQN 计算卸载与缓存 [14 ] 空天地一体化网络 任务卸载位置决策 平均处理时延 DQN [15 ] GEO卫星辅助车联网 任务卸载、计算和通信资源联合分配 时延 优化、DQN [16 ] 天地一体化网络 通信、缓存和计算资源联合分配 通信、缓存和计算开销 DQN [17 ] 多层卫星网络 缓存策略、计算卸载、接入选择联合决策 缓存和计算开销 A3C 路由选择 [19 ] LEO卫星星座 下一跳路由选择 跳数、丢包率、拥塞避免 Double DQN [20 ] 天地一体化网络 下一跳路由选择 时延、丢包率、吞吐量 DDPG [21 ] LEO卫星星座 下一跳路由选择 时延、卫星电池能量寿命 DQN [22 ] LEO卫星星座 抗干扰路径集合计算 集合中链路不受干扰 近似策略优化 卫星切换 [24 ] LEO卫星星座 切换选择 QoE DQN [25 ] LEO卫星星座 切换选择 切换次数 MARL 接入选择 [26 ] 空天地一体化网络 接入选择 吞吐量 DQN [27 ] 空天地一体化网络 接入选择与航迹调整 吞吐量 DQN
3 基于DRL的星地网络中继选择算法 对于星地网络中继节点选择的已有研究, 大多集中于信号强度、地理空间距离、信道质量、负载等因素, 将中继节点选择问题建模为针对传输速率、系统吞吐量、中断概率、能量利用率等指标的优化问题, 并利用优化、博弈论等方法进行求解.通过分析已有研究工作, 可以发现已有的星地网络中继选择算法面临的挑战主要包括以下几点[34 ] : ...
DRL-ER: an intelligent energy-aware routing protocol with guaranteed delay bounds in satellite mega-constellations
3
2020
... 在基于DRL的路由方法中, 智能体通过观察包含链路质量的状态空间S , 将下一跳备选传输节点作为动作空间A , 可以学习到能自适应感知链路状态并动态调整的路由策略π.文献[20 -21 ]主要利用DRL感知动态变化的链路带宽、丢包率、拥塞情况等信息和时变的不均匀业务流量.文献[19 ]提出了一种基于Double DQN的LEO卫星网络路由算法, 在每个卫星节点智能体感知两跳邻居范围内的链路状态, 并决定下一跳路由.更进一步, 文献[20 ]利用长短期记忆(long short-term memory, LSTM)网络对流量和链路质量的时序预测能力, 提出了一种基于DDPG的软件定义空天地一体化网络路由算法.仿真结果表明, 对比传统方法, 其能达到更低网络时延和更高的吞吐量. ...
... 文献[22 -23 ]则将卫星节点的运行状况加入状态空间S , 具体包括能量状况和受干扰情况.针对巨型星座不考虑卫星电池状态的路由策略会集中消耗某些卫星能量因而导致其电池寿命过早耗尽的问题, 文献[21 ]提出了一种基于DRL的能耗均匀路由算法.智能体感知由各节点能量状况、当前剩余时延等信息构成的状态s , 并将下一跳路由作为动作a .仿真结果表明, 所提算法能将端到端时延限制在所需范围内, 并有效延长了卫星寿命.文献[22 ]则利用DRL感知各卫星节点的受干扰情况, 提出了一种大规模异构卫星网络中的智能抗干扰的路由算法.智能体通过学习历史信息构成的状态s , 感知受到干扰的卫星节点, 从而获取可选的路由路径集合.仿真结果表明, 相比传统抗干扰路由算法, 所提算法的路由代价更低, 收敛速度更快. ...
... A summary of existing research related to DRL in SIN
Table 3 领域 文献 场景 针对问题 优化目标 DRL方法 资源分配 [3 ] 多波束GEO卫星网络 用户时隙分配 用户满意度、能量和频谱利用率 DQN [4 ] 多波束GEO卫星网络 用户信道分配 呼通率 DQN [6 ] LEO卫星物联网 用户信道分配 能量利用率 DQN [7 ] 多波束GEO卫星网络 波束带宽分配 公平性、流量满足程度 MARL [8 ] 多波束GEO卫星网络 波束功率分配 功率消耗、流量满足程度 DDPG [10 ] GEO卫星网络 配置链路参数 吞吐量、误码率、功耗、带宽稳定 DQN 跳波束 [11 ] 多波束GEO卫星 波束点亮方案 传输时延 DQN [12 ] 多波束GEO卫星 波束点亮方案 实时服务时延, 非实时服务吞吐量, 公平性 双环DQN 计算卸载与缓存 [14 ] 空天地一体化网络 任务卸载位置决策 平均处理时延 DQN [15 ] GEO卫星辅助车联网 任务卸载、计算和通信资源联合分配 时延 优化、DQN [16 ] 天地一体化网络 通信、缓存和计算资源联合分配 通信、缓存和计算开销 DQN [17 ] 多层卫星网络 缓存策略、计算卸载、接入选择联合决策 缓存和计算开销 A3C 路由选择 [19 ] LEO卫星星座 下一跳路由选择 跳数、丢包率、拥塞避免 Double DQN [20 ] 天地一体化网络 下一跳路由选择 时延、丢包率、吞吐量 DDPG [21 ] LEO卫星星座 下一跳路由选择 时延、卫星电池能量寿命 DQN [22 ] LEO卫星星座 抗干扰路径集合计算 集合中链路不受干扰 近似策略优化 卫星切换 [24 ] LEO卫星星座 切换选择 QoE DQN [25 ] LEO卫星星座 切换选择 切换次数 MARL 接入选择 [26 ] 空天地一体化网络 接入选择 吞吐量 DQN [27 ] 空天地一体化网络 接入选择与航迹调整 吞吐量 DQN
3 基于DRL的星地网络中继选择算法 对于星地网络中继节点选择的已有研究, 大多集中于信号强度、地理空间距离、信道质量、负载等因素, 将中继节点选择问题建模为针对传输速率、系统吞吐量、中断概率、能量利用率等指标的优化问题, 并利用优化、博弈论等方法进行求解.通过分析已有研究工作, 可以发现已有的星地网络中继选择算法面临的挑战主要包括以下几点[34 ] : ...
Spatial anti-jamming scheme for internet of satellites based on the deep reinforcement learning and stackelberg game
3
2020
... 文献[22 -23 ]则将卫星节点的运行状况加入状态空间S , 具体包括能量状况和受干扰情况.针对巨型星座不考虑卫星电池状态的路由策略会集中消耗某些卫星能量因而导致其电池寿命过早耗尽的问题, 文献[21 ]提出了一种基于DRL的能耗均匀路由算法.智能体感知由各节点能量状况、当前剩余时延等信息构成的状态s , 并将下一跳路由作为动作a .仿真结果表明, 所提算法能将端到端时延限制在所需范围内, 并有效延长了卫星寿命.文献[22 ]则利用DRL感知各卫星节点的受干扰情况, 提出了一种大规模异构卫星网络中的智能抗干扰的路由算法.智能体通过学习历史信息构成的状态s , 感知受到干扰的卫星节点, 从而获取可选的路由路径集合.仿真结果表明, 相比传统抗干扰路由算法, 所提算法的路由代价更低, 收敛速度更快. ...
... .仿真结果表明, 所提算法能将端到端时延限制在所需范围内, 并有效延长了卫星寿命.文献[22 ]则利用DRL感知各卫星节点的受干扰情况, 提出了一种大规模异构卫星网络中的智能抗干扰的路由算法.智能体通过学习历史信息构成的状态s , 感知受到干扰的卫星节点, 从而获取可选的路由路径集合.仿真结果表明, 相比传统抗干扰路由算法, 所提算法的路由代价更低, 收敛速度更快. ...
... A summary of existing research related to DRL in SIN
Table 3 领域 文献 场景 针对问题 优化目标 DRL方法 资源分配 [3 ] 多波束GEO卫星网络 用户时隙分配 用户满意度、能量和频谱利用率 DQN [4 ] 多波束GEO卫星网络 用户信道分配 呼通率 DQN [6 ] LEO卫星物联网 用户信道分配 能量利用率 DQN [7 ] 多波束GEO卫星网络 波束带宽分配 公平性、流量满足程度 MARL [8 ] 多波束GEO卫星网络 波束功率分配 功率消耗、流量满足程度 DDPG [10 ] GEO卫星网络 配置链路参数 吞吐量、误码率、功耗、带宽稳定 DQN 跳波束 [11 ] 多波束GEO卫星 波束点亮方案 传输时延 DQN [12 ] 多波束GEO卫星 波束点亮方案 实时服务时延, 非实时服务吞吐量, 公平性 双环DQN 计算卸载与缓存 [14 ] 空天地一体化网络 任务卸载位置决策 平均处理时延 DQN [15 ] GEO卫星辅助车联网 任务卸载、计算和通信资源联合分配 时延 优化、DQN [16 ] 天地一体化网络 通信、缓存和计算资源联合分配 通信、缓存和计算开销 DQN [17 ] 多层卫星网络 缓存策略、计算卸载、接入选择联合决策 缓存和计算开销 A3C 路由选择 [19 ] LEO卫星星座 下一跳路由选择 跳数、丢包率、拥塞避免 Double DQN [20 ] 天地一体化网络 下一跳路由选择 时延、丢包率、吞吐量 DDPG [21 ] LEO卫星星座 下一跳路由选择 时延、卫星电池能量寿命 DQN [22 ] LEO卫星星座 抗干扰路径集合计算 集合中链路不受干扰 近似策略优化 卫星切换 [24 ] LEO卫星星座 切换选择 QoE DQN [25 ] LEO卫星星座 切换选择 切换次数 MARL 接入选择 [26 ] 空天地一体化网络 接入选择 吞吐量 DQN [27 ] 空天地一体化网络 接入选择与航迹调整 吞吐量 DQN
3 基于DRL的星地网络中继选择算法 对于星地网络中继节点选择的已有研究, 大多集中于信号强度、地理空间距离、信道质量、负载等因素, 将中继节点选择问题建模为针对传输速率、系统吞吐量、中断概率、能量利用率等指标的优化问题, 并利用优化、博弈论等方法进行求解.通过分析已有研究工作, 可以发现已有的星地网络中继选择算法面临的挑战主要包括以下几点[34 ] : ...
LEO卫星通信系统覆盖时间和切换次数分析
2
2014
... 文献[22 -23 ]则将卫星节点的运行状况加入状态空间S , 具体包括能量状况和受干扰情况.针对巨型星座不考虑卫星电池状态的路由策略会集中消耗某些卫星能量因而导致其电池寿命过早耗尽的问题, 文献[21 ]提出了一种基于DRL的能耗均匀路由算法.智能体感知由各节点能量状况、当前剩余时延等信息构成的状态s , 并将下一跳路由作为动作a .仿真结果表明, 所提算法能将端到端时延限制在所需范围内, 并有效延长了卫星寿命.文献[22 ]则利用DRL感知各卫星节点的受干扰情况, 提出了一种大规模异构卫星网络中的智能抗干扰的路由算法.智能体通过学习历史信息构成的状态s , 感知受到干扰的卫星节点, 从而获取可选的路由路径集合.仿真结果表明, 相比传统抗干扰路由算法, 所提算法的路由代价更低, 收敛速度更快. ...
... 在已有传统方法中, 卫星切换主要依据以下3个指标: 最大服务时长[23 ] 、最大仰角和最多可用信道资源, 分别影响切换次数、服务质量和网络负载.传统切换方法通常采用综合加权进行决策, 各指标的权值来自专家对其重要性的判断.这种决策方法一方面缺乏客观性, 大规模异构SIN的复杂性令专家难以归纳最优权重; 另一方面, 这种决策方法对指标的偏好在多样动态的卫星业务场景中会发生变化, 专家归纳的固定规则难以在各时刻始终保持最优效果. ...
Analysis of coverage time and handoff number on LEO satellite communication systems
2
2014
... 文献[22 -23 ]则将卫星节点的运行状况加入状态空间S , 具体包括能量状况和受干扰情况.针对巨型星座不考虑卫星电池状态的路由策略会集中消耗某些卫星能量因而导致其电池寿命过早耗尽的问题, 文献[21 ]提出了一种基于DRL的能耗均匀路由算法.智能体感知由各节点能量状况、当前剩余时延等信息构成的状态s , 并将下一跳路由作为动作a .仿真结果表明, 所提算法能将端到端时延限制在所需范围内, 并有效延长了卫星寿命.文献[22 ]则利用DRL感知各卫星节点的受干扰情况, 提出了一种大规模异构卫星网络中的智能抗干扰的路由算法.智能体通过学习历史信息构成的状态s , 感知受到干扰的卫星节点, 从而获取可选的路由路径集合.仿真结果表明, 相比传统抗干扰路由算法, 所提算法的路由代价更低, 收敛速度更快. ...
... 在已有传统方法中, 卫星切换主要依据以下3个指标: 最大服务时长[23 ] 、最大仰角和最多可用信道资源, 分别影响切换次数、服务质量和网络负载.传统切换方法通常采用综合加权进行决策, 各指标的权值来自专家对其重要性的判断.这种决策方法一方面缺乏客观性, 大规模异构SIN的复杂性令专家难以归纳最优权重; 另一方面, 这种决策方法对指标的偏好在多样动态的卫星业务场景中会发生变化, 专家归纳的固定规则难以在各时刻始终保持最优效果. ...
QoE-driven intelligent hand- over for user-centric mobile satellite networks
2
2020
... 针对上述问题, 文献[24 ]提出了一种用户体验质量(quality of experience, QoE)驱动的智能切换机制.首先, 针对用户终端高速运动和业务分布不均衡问题, 将剩余服务时间、可用信道资源和端到端时延作为切换因子, 建立模型对其进行估计, 并进一步构成状态空间S .随后, 利用DRL感知切换因子, 进行切换决策, 并将用户体验指标作为即时收益r , 优化切换策略π.文献[25 ]针对集中式切换控制造成的信令开销问题, 提出了基于MARL的分布式切换方法.基于各可选卫星的剩余服务时间和负载情况构成的状态S , 采用分布式Q 学习学习切换策略π, 并将是否发生切换和卫星是否超载作为即时收益r , 用于优化策略π.这种机制避免了乒乓切换, 大幅降低了平均切换次数和用户阻塞率. ...
... A summary of existing research related to DRL in SIN
Table 3 领域 文献 场景 针对问题 优化目标 DRL方法 资源分配 [3 ] 多波束GEO卫星网络 用户时隙分配 用户满意度、能量和频谱利用率 DQN [4 ] 多波束GEO卫星网络 用户信道分配 呼通率 DQN [6 ] LEO卫星物联网 用户信道分配 能量利用率 DQN [7 ] 多波束GEO卫星网络 波束带宽分配 公平性、流量满足程度 MARL [8 ] 多波束GEO卫星网络 波束功率分配 功率消耗、流量满足程度 DDPG [10 ] GEO卫星网络 配置链路参数 吞吐量、误码率、功耗、带宽稳定 DQN 跳波束 [11 ] 多波束GEO卫星 波束点亮方案 传输时延 DQN [12 ] 多波束GEO卫星 波束点亮方案 实时服务时延, 非实时服务吞吐量, 公平性 双环DQN 计算卸载与缓存 [14 ] 空天地一体化网络 任务卸载位置决策 平均处理时延 DQN [15 ] GEO卫星辅助车联网 任务卸载、计算和通信资源联合分配 时延 优化、DQN [16 ] 天地一体化网络 通信、缓存和计算资源联合分配 通信、缓存和计算开销 DQN [17 ] 多层卫星网络 缓存策略、计算卸载、接入选择联合决策 缓存和计算开销 A3C 路由选择 [19 ] LEO卫星星座 下一跳路由选择 跳数、丢包率、拥塞避免 Double DQN [20 ] 天地一体化网络 下一跳路由选择 时延、丢包率、吞吐量 DDPG [21 ] LEO卫星星座 下一跳路由选择 时延、卫星电池能量寿命 DQN [22 ] LEO卫星星座 抗干扰路径集合计算 集合中链路不受干扰 近似策略优化 卫星切换 [24 ] LEO卫星星座 切换选择 QoE DQN [25 ] LEO卫星星座 切换选择 切换次数 MARL 接入选择 [26 ] 空天地一体化网络 接入选择 吞吐量 DQN [27 ] 空天地一体化网络 接入选择与航迹调整 吞吐量 DQN
3 基于DRL的星地网络中继选择算法 对于星地网络中继节点选择的已有研究, 大多集中于信号强度、地理空间距离、信道质量、负载等因素, 将中继节点选择问题建模为针对传输速率、系统吞吐量、中断概率、能量利用率等指标的优化问题, 并利用优化、博弈论等方法进行求解.通过分析已有研究工作, 可以发现已有的星地网络中继选择算法面临的挑战主要包括以下几点[34 ] : ...
2
... 针对上述问题, 文献[24 ]提出了一种用户体验质量(quality of experience, QoE)驱动的智能切换机制.首先, 针对用户终端高速运动和业务分布不均衡问题, 将剩余服务时间、可用信道资源和端到端时延作为切换因子, 建立模型对其进行估计, 并进一步构成状态空间S .随后, 利用DRL感知切换因子, 进行切换决策, 并将用户体验指标作为即时收益r , 优化切换策略π.文献[25 ]针对集中式切换控制造成的信令开销问题, 提出了基于MARL的分布式切换方法.基于各可选卫星的剩余服务时间和负载情况构成的状态S , 采用分布式Q 学习学习切换策略π, 并将是否发生切换和卫星是否超载作为即时收益r , 用于优化策略π.这种机制避免了乒乓切换, 大幅降低了平均切换次数和用户阻塞率. ...
... A summary of existing research related to DRL in SIN
Table 3 领域 文献 场景 针对问题 优化目标 DRL方法 资源分配 [3 ] 多波束GEO卫星网络 用户时隙分配 用户满意度、能量和频谱利用率 DQN [4 ] 多波束GEO卫星网络 用户信道分配 呼通率 DQN [6 ] LEO卫星物联网 用户信道分配 能量利用率 DQN [7 ] 多波束GEO卫星网络 波束带宽分配 公平性、流量满足程度 MARL [8 ] 多波束GEO卫星网络 波束功率分配 功率消耗、流量满足程度 DDPG [10 ] GEO卫星网络 配置链路参数 吞吐量、误码率、功耗、带宽稳定 DQN 跳波束 [11 ] 多波束GEO卫星 波束点亮方案 传输时延 DQN [12 ] 多波束GEO卫星 波束点亮方案 实时服务时延, 非实时服务吞吐量, 公平性 双环DQN 计算卸载与缓存 [14 ] 空天地一体化网络 任务卸载位置决策 平均处理时延 DQN [15 ] GEO卫星辅助车联网 任务卸载、计算和通信资源联合分配 时延 优化、DQN [16 ] 天地一体化网络 通信、缓存和计算资源联合分配 通信、缓存和计算开销 DQN [17 ] 多层卫星网络 缓存策略、计算卸载、接入选择联合决策 缓存和计算开销 A3C 路由选择 [19 ] LEO卫星星座 下一跳路由选择 跳数、丢包率、拥塞避免 Double DQN [20 ] 天地一体化网络 下一跳路由选择 时延、丢包率、吞吐量 DDPG [21 ] LEO卫星星座 下一跳路由选择 时延、卫星电池能量寿命 DQN [22 ] LEO卫星星座 抗干扰路径集合计算 集合中链路不受干扰 近似策略优化 卫星切换 [24 ] LEO卫星星座 切换选择 QoE DQN [25 ] LEO卫星星座 切换选择 切换次数 MARL 接入选择 [26 ] 空天地一体化网络 接入选择 吞吐量 DQN [27 ] 空天地一体化网络 接入选择与航迹调整 吞吐量 DQN
3 基于DRL的星地网络中继选择算法 对于星地网络中继节点选择的已有研究, 大多集中于信号强度、地理空间距离、信道质量、负载等因素, 将中继节点选择问题建模为针对传输速率、系统吞吐量、中断概率、能量利用率等指标的优化问题, 并利用优化、博弈论等方法进行求解.通过分析已有研究工作, 可以发现已有的星地网络中继选择算法面临的挑战主要包括以下几点[34 ] : ...
Deep reinforcement learning for multi-user access control in non-terrestrial networks
2
2020
... 针对空天地一体化网络接入基站选择问题, 文献[26 ]指出,传统基于信号强度的方法会导致负载不均衡和频繁切换, 因此提出一种基于DQN的智能接入选择方法, 将每个用户节点作为智能体, 感知各基站信号强度和用户数量, 并参考上一时刻连接基站和数据传输速率, 将上述信息构成状态S , 优化接入基站选择策略π, 有效提高了吞吐量并减少了网络切换次数.在无人机辅助中继的低轨卫星通信场景中, 由于网络拓扑动态变化、卫星数量繁多, 文献[27 ]利用DRL, 将无人机接入选择和飞行轨迹调整决策共同作为动作空间A , 有效提高了系统的端到端数据传输速率和频谱利用率. ...
... A summary of existing research related to DRL in SIN
Table 3 领域 文献 场景 针对问题 优化目标 DRL方法 资源分配 [3 ] 多波束GEO卫星网络 用户时隙分配 用户满意度、能量和频谱利用率 DQN [4 ] 多波束GEO卫星网络 用户信道分配 呼通率 DQN [6 ] LEO卫星物联网 用户信道分配 能量利用率 DQN [7 ] 多波束GEO卫星网络 波束带宽分配 公平性、流量满足程度 MARL [8 ] 多波束GEO卫星网络 波束功率分配 功率消耗、流量满足程度 DDPG [10 ] GEO卫星网络 配置链路参数 吞吐量、误码率、功耗、带宽稳定 DQN 跳波束 [11 ] 多波束GEO卫星 波束点亮方案 传输时延 DQN [12 ] 多波束GEO卫星 波束点亮方案 实时服务时延, 非实时服务吞吐量, 公平性 双环DQN 计算卸载与缓存 [14 ] 空天地一体化网络 任务卸载位置决策 平均处理时延 DQN [15 ] GEO卫星辅助车联网 任务卸载、计算和通信资源联合分配 时延 优化、DQN [16 ] 天地一体化网络 通信、缓存和计算资源联合分配 通信、缓存和计算开销 DQN [17 ] 多层卫星网络 缓存策略、计算卸载、接入选择联合决策 缓存和计算开销 A3C 路由选择 [19 ] LEO卫星星座 下一跳路由选择 跳数、丢包率、拥塞避免 Double DQN [20 ] 天地一体化网络 下一跳路由选择 时延、丢包率、吞吐量 DDPG [21 ] LEO卫星星座 下一跳路由选择 时延、卫星电池能量寿命 DQN [22 ] LEO卫星星座 抗干扰路径集合计算 集合中链路不受干扰 近似策略优化 卫星切换 [24 ] LEO卫星星座 切换选择 QoE DQN [25 ] LEO卫星星座 切换选择 切换次数 MARL 接入选择 [26 ] 空天地一体化网络 接入选择 吞吐量 DQN [27 ] 空天地一体化网络 接入选择与航迹调整 吞吐量 DQN
3 基于DRL的星地网络中继选择算法 对于星地网络中继节点选择的已有研究, 大多集中于信号强度、地理空间距离、信道质量、负载等因素, 将中继节点选择问题建模为针对传输速率、系统吞吐量、中断概率、能量利用率等指标的优化问题, 并利用优化、博弈论等方法进行求解.通过分析已有研究工作, 可以发现已有的星地网络中继选择算法面临的挑战主要包括以下几点[34 ] : ...
3
... 随着网络规模的扩大, 网络结构的日趋复杂, 接入选择问题也愈加复杂.与切换方法类似, 传统接入选择方法往往基于某时刻的信号强度、链路质量等指标的组合加权, 而难以优化动态网络的长期性能.基于DRL的接入选择方法[27 ] 通过感知动态变化的环境信息进行序列决策. ...
... 针对空天地一体化网络接入基站选择问题, 文献[26 ]指出,传统基于信号强度的方法会导致负载不均衡和频繁切换, 因此提出一种基于DQN的智能接入选择方法, 将每个用户节点作为智能体, 感知各基站信号强度和用户数量, 并参考上一时刻连接基站和数据传输速率, 将上述信息构成状态S , 优化接入基站选择策略π, 有效提高了吞吐量并减少了网络切换次数.在无人机辅助中继的低轨卫星通信场景中, 由于网络拓扑动态变化、卫星数量繁多, 文献[27 ]利用DRL, 将无人机接入选择和飞行轨迹调整决策共同作为动作空间A , 有效提高了系统的端到端数据传输速率和频谱利用率. ...
... A summary of existing research related to DRL in SIN
Table 3 领域 文献 场景 针对问题 优化目标 DRL方法 资源分配 [3 ] 多波束GEO卫星网络 用户时隙分配 用户满意度、能量和频谱利用率 DQN [4 ] 多波束GEO卫星网络 用户信道分配 呼通率 DQN [6 ] LEO卫星物联网 用户信道分配 能量利用率 DQN [7 ] 多波束GEO卫星网络 波束带宽分配 公平性、流量满足程度 MARL [8 ] 多波束GEO卫星网络 波束功率分配 功率消耗、流量满足程度 DDPG [10 ] GEO卫星网络 配置链路参数 吞吐量、误码率、功耗、带宽稳定 DQN 跳波束 [11 ] 多波束GEO卫星 波束点亮方案 传输时延 DQN [12 ] 多波束GEO卫星 波束点亮方案 实时服务时延, 非实时服务吞吐量, 公平性 双环DQN 计算卸载与缓存 [14 ] 空天地一体化网络 任务卸载位置决策 平均处理时延 DQN [15 ] GEO卫星辅助车联网 任务卸载、计算和通信资源联合分配 时延 优化、DQN [16 ] 天地一体化网络 通信、缓存和计算资源联合分配 通信、缓存和计算开销 DQN [17 ] 多层卫星网络 缓存策略、计算卸载、接入选择联合决策 缓存和计算开销 A3C 路由选择 [19 ] LEO卫星星座 下一跳路由选择 跳数、丢包率、拥塞避免 Double DQN [20 ] 天地一体化网络 下一跳路由选择 时延、丢包率、吞吐量 DDPG [21 ] LEO卫星星座 下一跳路由选择 时延、卫星电池能量寿命 DQN [22 ] LEO卫星星座 抗干扰路径集合计算 集合中链路不受干扰 近似策略优化 卫星切换 [24 ] LEO卫星星座 切换选择 QoE DQN [25 ] LEO卫星星座 切换选择 切换次数 MARL 接入选择 [26 ] 空天地一体化网络 接入选择 吞吐量 DQN [27 ] 空天地一体化网络 接入选择与航迹调整 吞吐量 DQN
3 基于DRL的星地网络中继选择算法 对于星地网络中继节点选择的已有研究, 大多集中于信号强度、地理空间距离、信道质量、负载等因素, 将中继节点选择问题建模为针对传输速率、系统吞吐量、中断概率、能量利用率等指标的优化问题, 并利用优化、博弈论等方法进行求解.通过分析已有研究工作, 可以发现已有的星地网络中继选择算法面临的挑战主要包括以下几点[34 ] : ...
Single and multi-agent deep reinforcement learning for AI-enabled wireless networks: a tutorial
1
2021
... 尽管DRL在无线通信领域的应用已有一定研究成果[29 ] , 但其在SIN领域中的应用尚处于起步阶段.针对现有工作中应用DRL的研究方向, 本节试图根据其实用性的高低进行列表排序, 如表 2 所示.对实用性的讨论主要根据DRL方法在训练阶段和实际使用阶段的计算换取策略的优化效果, 因此需要考察在SIN实际问题中是否能够满足DRL对计算能力的需求.同时也需要考虑算法实时性能是否能满足应用需要, 综合考虑应用DRL方法是否能给此领域带来收益. ...
Reinforcement learning for satellite communications: From LEO to deep space operations
1
2019
... Feasibility analysis for SIN's research direction with DRL available
Table 2 研究方向 计算能力 实时性要求 算法效果 综合收益 进展 资源分配 有限, 星上计算 较低, 可根据算法速度设定动态调整资源的时隙 较好, 可大幅提高资源利用率 较高, 资源紧缺是SIN面临的重要问题 NASA已进行星上验证[30 ] 跳波束 有限, 星上计算 较低, 可根据算法速度设定跳波束时隙 基于MADRL的方法效果较好, DRL方法面临维度灾难 较高, 解决了流量空间分布不均匀对资源的浪费 理论研究 接入网络选择 终端分布式决策, 不需星上计算 较低, 可根据算法速度设定接入调整频率 较好, 但需要收集多层异构网络的信息 较高, 优化了空天地一体化网络中的接入决策 理论研究 拥塞控制[31 ] 终端分布式决策, 不需星上计算 较低, 可根据算法速度设定窗口调整频率 较好, 问题简单直接, 且决策空间有限 较高, 但需要考虑网络设备更换的代价 理论研究 计算卸载 较高, 终端分布式决策, 不需星上计算 高, 但对卫星无要求, 对终端能力和算法时效性有要求 有待提高, 其与通信过程的资源分配问题耦合, 考虑因素多, 决策维度高, DRL训练难度大 目前有限, 但在计算任务日益增加、边缘能力日益增强的未来场景[32 ] 中较有前景 理论研究 卫星切换 终端分布式决策, 不需星上计算 较低, LEO卫星过顶时间为分钟级, DRL算法使用阶段的决策时间为毫秒级 有待提高, 现有方法没能与资源分配结合, 因此效果有待优化 现阶段收益有限, 对未来超大规模星座[33 ] 有意义 理论研究 路由选择 有限, 星上计算 高, 数据包转发对时效性要求高 在拥塞或者受干扰的网络中性能优于其他方法 较低, 路由决策无法牺牲时间代价 理论研究 接入协议优化[34 ] 终端分布式决策, 不需星上计算 高, 数据包流量大 MARL效果较好, 而DRL在节点规模增大时, 收敛效果变差 较低, 每个发送数据包需要承受DRL决策的时间代价 理论研究 缓存 有限, 星上计算 高, 内容访问请求流量大 有待提高, 内容数量多, 缓存决策动作空间大 较低, 卫星缓存资源有限, 优化缓存策略取得的收益有限 理论研究
随后, 本节总结了SIN中基于DRL的解决方案的设计思路(见图 6 ).图 6 概括了SIN领域的DRL方法常见的状态空间S、即时收益r 和动作空间A 所考虑的因素.研究者需要首先分析SIN领域具体问题的相关影响因素、优化目标和决策任务, 随后分别对应设计DRL方法的状态空间S 、即时收益r 和动作空间A , 即可初步形成解决此问题的DRL思路.表 3 总结了本文介绍的现有研究, 归纳概括了其应用场景、针对问题、优化目标与采用的DRL方法. ...
1
... Feasibility analysis for SIN's research direction with DRL available
Table 2 研究方向 计算能力 实时性要求 算法效果 综合收益 进展 资源分配 有限, 星上计算 较低, 可根据算法速度设定动态调整资源的时隙 较好, 可大幅提高资源利用率 较高, 资源紧缺是SIN面临的重要问题 NASA已进行星上验证[30 ] 跳波束 有限, 星上计算 较低, 可根据算法速度设定跳波束时隙 基于MADRL的方法效果较好, DRL方法面临维度灾难 较高, 解决了流量空间分布不均匀对资源的浪费 理论研究 接入网络选择 终端分布式决策, 不需星上计算 较低, 可根据算法速度设定接入调整频率 较好, 但需要收集多层异构网络的信息 较高, 优化了空天地一体化网络中的接入决策 理论研究 拥塞控制[31 ] 终端分布式决策, 不需星上计算 较低, 可根据算法速度设定窗口调整频率 较好, 问题简单直接, 且决策空间有限 较高, 但需要考虑网络设备更换的代价 理论研究 计算卸载 较高, 终端分布式决策, 不需星上计算 高, 但对卫星无要求, 对终端能力和算法时效性有要求 有待提高, 其与通信过程的资源分配问题耦合, 考虑因素多, 决策维度高, DRL训练难度大 目前有限, 但在计算任务日益增加、边缘能力日益增强的未来场景[32 ] 中较有前景 理论研究 卫星切换 终端分布式决策, 不需星上计算 较低, LEO卫星过顶时间为分钟级, DRL算法使用阶段的决策时间为毫秒级 有待提高, 现有方法没能与资源分配结合, 因此效果有待优化 现阶段收益有限, 对未来超大规模星座[33 ] 有意义 理论研究 路由选择 有限, 星上计算 高, 数据包转发对时效性要求高 在拥塞或者受干扰的网络中性能优于其他方法 较低, 路由决策无法牺牲时间代价 理论研究 接入协议优化[34 ] 终端分布式决策, 不需星上计算 高, 数据包流量大 MARL效果较好, 而DRL在节点规模增大时, 收敛效果变差 较低, 每个发送数据包需要承受DRL决策的时间代价 理论研究 缓存 有限, 星上计算 高, 内容访问请求流量大 有待提高, 内容数量多, 缓存决策动作空间大 较低, 卫星缓存资源有限, 优化缓存策略取得的收益有限 理论研究
随后, 本节总结了SIN中基于DRL的解决方案的设计思路(见图 6 ).图 6 概括了SIN领域的DRL方法常见的状态空间S、即时收益r 和动作空间A 所考虑的因素.研究者需要首先分析SIN领域具体问题的相关影响因素、优化目标和决策任务, 随后分别对应设计DRL方法的状态空间S 、即时收益r 和动作空间A , 即可初步形成解决此问题的DRL思路.表 3 总结了本文介绍的现有研究, 归纳概括了其应用场景、针对问题、优化目标与采用的DRL方法. ...
Satellite-terrestrial integrated edge computing networks: architecture, challenges, and open issues
1
2020
... Feasibility analysis for SIN's research direction with DRL available
Table 2 研究方向 计算能力 实时性要求 算法效果 综合收益 进展 资源分配 有限, 星上计算 较低, 可根据算法速度设定动态调整资源的时隙 较好, 可大幅提高资源利用率 较高, 资源紧缺是SIN面临的重要问题 NASA已进行星上验证[30 ] 跳波束 有限, 星上计算 较低, 可根据算法速度设定跳波束时隙 基于MADRL的方法效果较好, DRL方法面临维度灾难 较高, 解决了流量空间分布不均匀对资源的浪费 理论研究 接入网络选择 终端分布式决策, 不需星上计算 较低, 可根据算法速度设定接入调整频率 较好, 但需要收集多层异构网络的信息 较高, 优化了空天地一体化网络中的接入决策 理论研究 拥塞控制[31 ] 终端分布式决策, 不需星上计算 较低, 可根据算法速度设定窗口调整频率 较好, 问题简单直接, 且决策空间有限 较高, 但需要考虑网络设备更换的代价 理论研究 计算卸载 较高, 终端分布式决策, 不需星上计算 高, 但对卫星无要求, 对终端能力和算法时效性有要求 有待提高, 其与通信过程的资源分配问题耦合, 考虑因素多, 决策维度高, DRL训练难度大 目前有限, 但在计算任务日益增加、边缘能力日益增强的未来场景[32 ] 中较有前景 理论研究 卫星切换 终端分布式决策, 不需星上计算 较低, LEO卫星过顶时间为分钟级, DRL算法使用阶段的决策时间为毫秒级 有待提高, 现有方法没能与资源分配结合, 因此效果有待优化 现阶段收益有限, 对未来超大规模星座[33 ] 有意义 理论研究 路由选择 有限, 星上计算 高, 数据包转发对时效性要求高 在拥塞或者受干扰的网络中性能优于其他方法 较低, 路由决策无法牺牲时间代价 理论研究 接入协议优化[34 ] 终端分布式决策, 不需星上计算 高, 数据包流量大 MARL效果较好, 而DRL在节点规模增大时, 收敛效果变差 较低, 每个发送数据包需要承受DRL决策的时间代价 理论研究 缓存 有限, 星上计算 高, 内容访问请求流量大 有待提高, 内容数量多, 缓存决策动作空间大 较低, 卫星缓存资源有限, 优化缓存策略取得的收益有限 理论研究
随后, 本节总结了SIN中基于DRL的解决方案的设计思路(见图 6 ).图 6 概括了SIN领域的DRL方法常见的状态空间S、即时收益r 和动作空间A 所考虑的因素.研究者需要首先分析SIN领域具体问题的相关影响因素、优化目标和决策任务, 随后分别对应设计DRL方法的状态空间S 、即时收益r 和动作空间A , 即可初步形成解决此问题的DRL思路.表 3 总结了本文介绍的现有研究, 归纳概括了其应用场景、针对问题、优化目标与采用的DRL方法. ...
Dense small satellite networks for modern terrestrial communication systems: benefits, infrastructure, and technologies
1
2020
... Feasibility analysis for SIN's research direction with DRL available
Table 2 研究方向 计算能力 实时性要求 算法效果 综合收益 进展 资源分配 有限, 星上计算 较低, 可根据算法速度设定动态调整资源的时隙 较好, 可大幅提高资源利用率 较高, 资源紧缺是SIN面临的重要问题 NASA已进行星上验证[30 ] 跳波束 有限, 星上计算 较低, 可根据算法速度设定跳波束时隙 基于MADRL的方法效果较好, DRL方法面临维度灾难 较高, 解决了流量空间分布不均匀对资源的浪费 理论研究 接入网络选择 终端分布式决策, 不需星上计算 较低, 可根据算法速度设定接入调整频率 较好, 但需要收集多层异构网络的信息 较高, 优化了空天地一体化网络中的接入决策 理论研究 拥塞控制[31 ] 终端分布式决策, 不需星上计算 较低, 可根据算法速度设定窗口调整频率 较好, 问题简单直接, 且决策空间有限 较高, 但需要考虑网络设备更换的代价 理论研究 计算卸载 较高, 终端分布式决策, 不需星上计算 高, 但对卫星无要求, 对终端能力和算法时效性有要求 有待提高, 其与通信过程的资源分配问题耦合, 考虑因素多, 决策维度高, DRL训练难度大 目前有限, 但在计算任务日益增加、边缘能力日益增强的未来场景[32 ] 中较有前景 理论研究 卫星切换 终端分布式决策, 不需星上计算 较低, LEO卫星过顶时间为分钟级, DRL算法使用阶段的决策时间为毫秒级 有待提高, 现有方法没能与资源分配结合, 因此效果有待优化 现阶段收益有限, 对未来超大规模星座[33 ] 有意义 理论研究 路由选择 有限, 星上计算 高, 数据包转发对时效性要求高 在拥塞或者受干扰的网络中性能优于其他方法 较低, 路由决策无法牺牲时间代价 理论研究 接入协议优化[34 ] 终端分布式决策, 不需星上计算 高, 数据包流量大 MARL效果较好, 而DRL在节点规模增大时, 收敛效果变差 较低, 每个发送数据包需要承受DRL决策的时间代价 理论研究 缓存 有限, 星上计算 高, 内容访问请求流量大 有待提高, 内容数量多, 缓存决策动作空间大 较低, 卫星缓存资源有限, 优化缓存策略取得的收益有限 理论研究
随后, 本节总结了SIN中基于DRL的解决方案的设计思路(见图 6 ).图 6 概括了SIN领域的DRL方法常见的状态空间S、即时收益r 和动作空间A 所考虑的因素.研究者需要首先分析SIN领域具体问题的相关影响因素、优化目标和决策任务, 随后分别对应设计DRL方法的状态空间S 、即时收益r 和动作空间A , 即可初步形成解决此问题的DRL思路.表 3 总结了本文介绍的现有研究, 归纳概括了其应用场景、针对问题、优化目标与采用的DRL方法. ...
Distributed Q-learning based joint relay selection and access control scheme for IoT-oriented satellite terrestrial relay networks
2
2021
... Feasibility analysis for SIN's research direction with DRL available
Table 2 研究方向 计算能力 实时性要求 算法效果 综合收益 进展 资源分配 有限, 星上计算 较低, 可根据算法速度设定动态调整资源的时隙 较好, 可大幅提高资源利用率 较高, 资源紧缺是SIN面临的重要问题 NASA已进行星上验证[30 ] 跳波束 有限, 星上计算 较低, 可根据算法速度设定跳波束时隙 基于MADRL的方法效果较好, DRL方法面临维度灾难 较高, 解决了流量空间分布不均匀对资源的浪费 理论研究 接入网络选择 终端分布式决策, 不需星上计算 较低, 可根据算法速度设定接入调整频率 较好, 但需要收集多层异构网络的信息 较高, 优化了空天地一体化网络中的接入决策 理论研究 拥塞控制[31 ] 终端分布式决策, 不需星上计算 较低, 可根据算法速度设定窗口调整频率 较好, 问题简单直接, 且决策空间有限 较高, 但需要考虑网络设备更换的代价 理论研究 计算卸载 较高, 终端分布式决策, 不需星上计算 高, 但对卫星无要求, 对终端能力和算法时效性有要求 有待提高, 其与通信过程的资源分配问题耦合, 考虑因素多, 决策维度高, DRL训练难度大 目前有限, 但在计算任务日益增加、边缘能力日益增强的未来场景[32 ] 中较有前景 理论研究 卫星切换 终端分布式决策, 不需星上计算 较低, LEO卫星过顶时间为分钟级, DRL算法使用阶段的决策时间为毫秒级 有待提高, 现有方法没能与资源分配结合, 因此效果有待优化 现阶段收益有限, 对未来超大规模星座[33 ] 有意义 理论研究 路由选择 有限, 星上计算 高, 数据包转发对时效性要求高 在拥塞或者受干扰的网络中性能优于其他方法 较低, 路由决策无法牺牲时间代价 理论研究 接入协议优化[34 ] 终端分布式决策, 不需星上计算 高, 数据包流量大 MARL效果较好, 而DRL在节点规模增大时, 收敛效果变差 较低, 每个发送数据包需要承受DRL决策的时间代价 理论研究 缓存 有限, 星上计算 高, 内容访问请求流量大 有待提高, 内容数量多, 缓存决策动作空间大 较低, 卫星缓存资源有限, 优化缓存策略取得的收益有限 理论研究
随后, 本节总结了SIN中基于DRL的解决方案的设计思路(见图 6 ).图 6 概括了SIN领域的DRL方法常见的状态空间S、即时收益r 和动作空间A 所考虑的因素.研究者需要首先分析SIN领域具体问题的相关影响因素、优化目标和决策任务, 随后分别对应设计DRL方法的状态空间S 、即时收益r 和动作空间A , 即可初步形成解决此问题的DRL思路.表 3 总结了本文介绍的现有研究, 归纳概括了其应用场景、针对问题、优化目标与采用的DRL方法. ...
... 对于星地网络中继节点选择的已有研究, 大多集中于信号强度、地理空间距离、信道质量、负载等因素, 将中继节点选择问题建模为针对传输速率、系统吞吐量、中断概率、能量利用率等指标的优化问题, 并利用优化、博弈论等方法进行求解.通过分析已有研究工作, 可以发现已有的星地网络中继选择算法面临的挑战主要包括以下几点[34 ] : ...
Human-level control through deep reinforcement learning
2
2015
... 采用一种简单直接的MADRL方法, 即每个智能体采用独立的DQN算法[35 ] , 将其他智能体视为环境的一部分.智能体利用环境交互反馈得到的即时收益, 通过下式迭代更新表征Q值的神经网络参数. ...
... 参照DQN[35 ] 算法, 用神经网络表征的状态值函数Q i s , a i i
1
... 根据文献[36 ], 各个智能体两两相互作用的Q值函数Q i s , a )可以进一步简化为 ...
Channel estimation and detection in satellite communication systems
1
2016
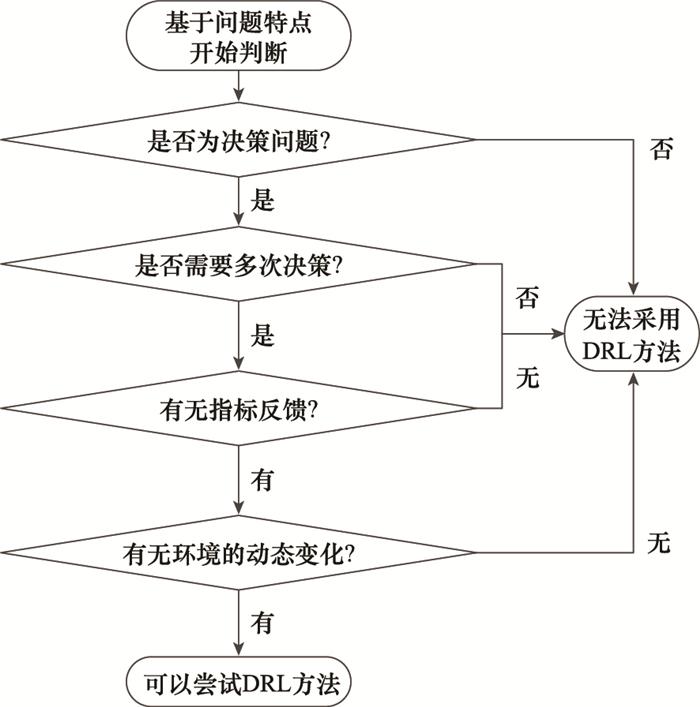
... 如图 9 所示, 首先非决策类问题无法用DRL方法优化, 例如信道估计[37 ] 、性能分析[38 ] 、异常数据流检测[39 ] 和天线设计[40 ] 问题.其次, 不需要多次决策的问题无法建模为MDP, 无法利用DRL进行序列决策, 例如卫星地球站选址、卫星天线设计等问题,这类问题只能决策一次.且DRL方法的优势在于对序列决策问题能有效优化长期收益, 因而不适合只进行一次决策的问题.再次, 对于没有明确指标反馈以判断策略优劣的问题, 例如网络运行状态评估问题, DRL无法解决.最后, 需要对环境是否变化进行判断, 对于静态问题, DRL方法难以表现出超过优化等方法的优势. ...
Performance analysis of multi-antenna multiuser hybrid satellite-terrestrial relay systems for mobile services delivery
1
2018
... 如图 9 所示, 首先非决策类问题无法用DRL方法优化, 例如信道估计[37 ] 、性能分析[38 ] 、异常数据流检测[39 ] 和天线设计[40 ] 问题.其次, 不需要多次决策的问题无法建模为MDP, 无法利用DRL进行序列决策, 例如卫星地球站选址、卫星天线设计等问题,这类问题只能决策一次.且DRL方法的优势在于对序列决策问题能有效优化长期收益, 因而不适合只进行一次决策的问题.再次, 对于没有明确指标反馈以判断策略优劣的问题, 例如网络运行状态评估问题, DRL无法解决.最后, 需要对环境是否变化进行判断, 对于静态问题, DRL方法难以表现出超过优化等方法的优势. ...
A framework to classify heterogeneous Internet traffic with machine learning and deep learning techniques for satellite communications
1
2020
... 如图 9 所示, 首先非决策类问题无法用DRL方法优化, 例如信道估计[37 ] 、性能分析[38 ] 、异常数据流检测[39 ] 和天线设计[40 ] 问题.其次, 不需要多次决策的问题无法建模为MDP, 无法利用DRL进行序列决策, 例如卫星地球站选址、卫星天线设计等问题,这类问题只能决策一次.且DRL方法的优势在于对序列决策问题能有效优化长期收益, 因而不适合只进行一次决策的问题.再次, 对于没有明确指标反馈以判断策略优劣的问题, 例如网络运行状态评估问题, DRL无法解决.最后, 需要对环境是否变化进行判断, 对于静态问题, DRL方法难以表现出超过优化等方法的优势. ...
Advanced antenna technologies for satellite communications payloads
1
2015
... 如图 9 所示, 首先非决策类问题无法用DRL方法优化, 例如信道估计[37 ] 、性能分析[38 ] 、异常数据流检测[39 ] 和天线设计[40 ] 问题.其次, 不需要多次决策的问题无法建模为MDP, 无法利用DRL进行序列决策, 例如卫星地球站选址、卫星天线设计等问题,这类问题只能决策一次.且DRL方法的优势在于对序列决策问题能有效优化长期收益, 因而不适合只进行一次决策的问题.再次, 对于没有明确指标反馈以判断策略优劣的问题, 例如网络运行状态评估问题, DRL无法解决.最后, 需要对环境是否变化进行判断, 对于静态问题, DRL方法难以表现出超过优化等方法的优势. ...
深度强化学习理论及其应用综述
1
2019
... 不同于凸优化、博弈论等较为成熟的方法, DRL类方法属于人工智能的新兴研究领域, 其在经典方法的基础上还在不断发展完善.本章简要介绍了DRL方法的前沿进展[41 -42 ] , 有助于研究者有效利用其解决SIN中面临的挑战. ...
A review of deep reinforcement learning theory and application
1
2019
... 不同于凸优化、博弈论等较为成熟的方法, DRL类方法属于人工智能的新兴研究领域, 其在经典方法的基础上还在不断发展完善.本章简要介绍了DRL方法的前沿进展[41 -42 ] , 有助于研究者有效利用其解决SIN中面临的挑战. ...
Deep reinforcement learning: a brief survey
1
2017
... 不同于凸优化、博弈论等较为成熟的方法, DRL类方法属于人工智能的新兴研究领域, 其在经典方法的基础上还在不断发展完善.本章简要介绍了DRL方法的前沿进展[41 -42 ] , 有助于研究者有效利用其解决SIN中面临的挑战. ...
1
... 现有的经典DRL方法往往采用人工设定的即时收益.然而, 一旦奖励功能设计不当, 就会对DRL的效果产生巨大影响.逆强化学习[43 ] 从观察到的专家示例中学习适当的奖励函数.此方法适用于存在可以模仿的历史决策记录的应用问题. ...
1
... 学习效率低是强化学习面临的一大难题, 往往需要数万个训练样本才能有效收敛.针对这一问题, 迁移强化学习[44 ] 提出根据先前的任务获取有用的知识, 来解决新的任务, 从而使智能体在一个新的目标域环境中, 仅利用源域的学习成果, 使用少量可用数据快速学习到最优策略. ...
元强化学习综述
1
2021
... 元强化学习[45 ] 是迁移强化学习的一类, 其目标在于通过学习如何高效学习策略这一元知识, 而在面对新任务或新环境时, 具有较强泛化能力, 能利用少量样本快速学习. ...
Review on meta reinforcement learning
1
2021
... 元强化学习[45 ] 是迁移强化学习的一类, 其目标在于通过学习如何高效学习策略这一元知识, 而在面对新任务或新环境时, 具有较强泛化能力, 能利用少量样本快速学习. ...
分层强化学习综述
1
2017
... 分层强化学习[46 ] 的核心思路是将复杂问题抽象为不同层级, 从而将复杂问题分解为子问题,分别进行解决, 适合解决大规模复杂问题.高级别智能体主要关注高层目标是否达成, 而低级别智能体则更关注精细的决策问题. ...
Summarize of hierarchical reinforcement learning
1
2017
... 分层强化学习[46 ] 的核心思路是将复杂问题抽象为不同层级, 从而将复杂问题分解为子问题,分别进行解决, 适合解决大规模复杂问题.高级别智能体主要关注高层目标是否达成, 而低级别智能体则更关注精细的决策问题. ...
Hierarchical reinforcement learning for relay selection and power optimization in two-hop cooperative relay network
1
2021
... 此方法已经被应用于无线通信领域, 文献[47 ]利用分层强化学习将中继选择和功率分配分解为两个分层优化目标, 并在不同的层次上进行训练, 避免了由联合决策造成的高维动作空间导致的DRL方法难以收敛的问题. ...
1
... 针对多个互相矛盾的优化目标, 在未来动态的SIN中, 不同应用、不同网络环境, 对目标偏好是动态可变的, 因此需要同时学习动态偏好和适应这一动态偏好的多目标DRL策略[48 ] , 针对此领域有待进一步研究. ...
Long short-term memory
1
1997
... 针对DRL方法在SIN中面临的环境信息数据缺失、数据噪音和数据分布偏差挑战, 结合其他机器学习方法对环境数据进行预处理, 值得深入研究.针对数据缺失问题, 可以采用矩阵补全对缺失的信道质量数据进行补全, 或利用循环神经网络[49 ] 等方法对缺失的时序数据进行估计; 针对数据噪声问题, 可以利用主成分分析等数据投影方法在降维的同时对数据进行降噪; 针对仿真数据与真实数据存在的分布偏差, 针对系统部署运行前真实数据积累量过少的问题, 可以采用对抗生成网络[50 ] 降低仿真数据与真实数据分布之间的偏差, 生成与真实数据同分布的仿真数据, 辅助DRL的训练. ...
Generative adversarial nets
1
2014
... 针对DRL方法在SIN中面临的环境信息数据缺失、数据噪音和数据分布偏差挑战, 结合其他机器学习方法对环境数据进行预处理, 值得深入研究.针对数据缺失问题, 可以采用矩阵补全对缺失的信道质量数据进行补全, 或利用循环神经网络[49 ] 等方法对缺失的时序数据进行估计; 针对数据噪声问题, 可以利用主成分分析等数据投影方法在降维的同时对数据进行降噪; 针对仿真数据与真实数据存在的分布偏差, 针对系统部署运行前真实数据积累量过少的问题, 可以采用对抗生成网络[50 ] 降低仿真数据与真实数据分布之间的偏差, 生成与真实数据同分布的仿真数据, 辅助DRL的训练. ...
1
... 对具有动态图关系的各卫星和用户节点深入挖掘时空规律的可行研究思路之一是图神经网络[51 ] 及其重要分支——时间图神经网络. ...
1
... 未来SIN的发展方向是通信、导航、遥感一体化的服务系统, 从而实现一星多用、多星组网, 通过系统集成提高资源利用率和服务效率[52 ] .上述一体化天基信息港的核心在于对通信、导航和遥感任务进行协同资源分配、任务调度.包含大规模异构节点与多种任务的复杂系统难以准确建模, 因此传统方法难以求解.而DRL方法依靠其学习能力可以规避精确建模问题, 是解决多任务协同问题的可行思路之一. ...
论军民融合的卫星通信、遥感、导航一体天基信息实时服务系统
1
2017
... 针对星上资源受限问题, 有以下几种可能的解决思路: ①直接在方法设计时考虑相对浅层的神经网络结构,研究神经网络算法如何在嵌入式平台上提高计算效率[53 ] ; ②利用深度学习领域中的知识蒸馏[54 ] 、网络结构剪枝[55 ] 或网络参数量化等方法, 降低DRL中深度神经网络的计算量, 因而节省能量消耗; ③将迁移学习结合仿真环境训练机制, 降低模型部署过程中所需要的训练开销; ④更加关注分布式的MARL, 将切换、资源分配、计算卸载、网络接入等决策问题从卫星集中式控制框架转换为用户自组织智能化决策框架, DRL方法部署在运算能力较强的地面终端, 做出决策后, 卫星只需要简单地判断是否可以对其服务即可. ...
On civil-military integrated space-based real-time information service system
1
2017
... 针对星上资源受限问题, 有以下几种可能的解决思路: ①直接在方法设计时考虑相对浅层的神经网络结构,研究神经网络算法如何在嵌入式平台上提高计算效率[53 ] ; ②利用深度学习领域中的知识蒸馏[54 ] 、网络结构剪枝[55 ] 或网络参数量化等方法, 降低DRL中深度神经网络的计算量, 因而节省能量消耗; ③将迁移学习结合仿真环境训练机制, 降低模型部署过程中所需要的训练开销; ④更加关注分布式的MARL, 将切换、资源分配、计算卸载、网络接入等决策问题从卫星集中式控制框架转换为用户自组织智能化决策框架, DRL方法部署在运算能力较强的地面终端, 做出决策后, 卫星只需要简单地判断是否可以对其服务即可. ...
1
... 针对星上资源受限问题, 有以下几种可能的解决思路: ①直接在方法设计时考虑相对浅层的神经网络结构,研究神经网络算法如何在嵌入式平台上提高计算效率[53 ] ; ②利用深度学习领域中的知识蒸馏[54 ] 、网络结构剪枝[55 ] 或网络参数量化等方法, 降低DRL中深度神经网络的计算量, 因而节省能量消耗; ③将迁移学习结合仿真环境训练机制, 降低模型部署过程中所需要的训练开销; ④更加关注分布式的MARL, 将切换、资源分配、计算卸载、网络接入等决策问题从卫星集中式控制框架转换为用户自组织智能化决策框架, DRL方法部署在运算能力较强的地面终端, 做出决策后, 卫星只需要简单地判断是否可以对其服务即可. ...
1
... 针对星上资源受限问题, 有以下几种可能的解决思路: ①直接在方法设计时考虑相对浅层的神经网络结构,研究神经网络算法如何在嵌入式平台上提高计算效率[53 ] ; ②利用深度学习领域中的知识蒸馏[54 ] 、网络结构剪枝[55 ] 或网络参数量化等方法, 降低DRL中深度神经网络的计算量, 因而节省能量消耗; ③将迁移学习结合仿真环境训练机制, 降低模型部署过程中所需要的训练开销; ④更加关注分布式的MARL, 将切换、资源分配、计算卸载、网络接入等决策问题从卫星集中式控制框架转换为用户自组织智能化决策框架, DRL方法部署在运算能力较强的地面终端, 做出决策后, 卫星只需要简单地判断是否可以对其服务即可. ...



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}