Systems Engineering and Electronics ›› 2021, Vol. 43 ›› Issue (2): 420-433.doi: 10.12305/j.issn.1001-506X.2021.02.17
• Systems Engineering • Previous Articles Next Articles
Parallel priority experience replay mechanism of MADDPG algorithm
Ang GAO1( ), Zhiming DONG1,*(), Liang LI1(), Jinghua SONG1(), Li DUAN2()
), Zhiming DONG1,*(), Liang LI1(), Jinghua SONG1(), Li DUAN2()
- 1. Military Exercise and Training Center, Army Academy of Armored Forces, Beijing 100072, China
2. Unit 61516 of the PLA, Beijing 100076, China
-
Received:2020-03-06Online:2021-02-01Published:2021-03-16 -
Contact:Zhiming DONG E-mail:15689783388@163.com;236211588@qq.com;liliang_zgy@163.com;jhsong@sina.com;E-mail:236211566@qq.com
CLC Number:
Cite this article
Ang GAO, Zhiming DONG, Liang LI, Jinghua SONG, Li DUAN. Parallel priority experience replay mechanism of MADDPG algorithm[J]. Systems Engineering and Electronics, 2021, 43(2): 420-433.
share this article

Fig.1
Schematic diagram of single agent DRL method and MADRL method"


Fig.2
RL algorithm classification diagram"

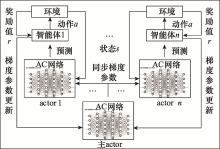
Fig.3
Algorithm diagram of A3C"

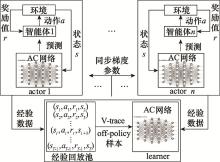
Fig.4
IMPALA framework diagram"

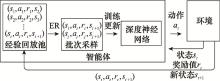
Fig.5
Experience replay mechanism diagram"

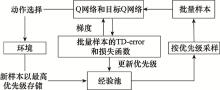
Fig.6
Schematic diagram of PER principle"


Fig.7
Schematic diagram of MADDPG algorithm framework"


Fig.8
Schematic diagram of PPER-MADDPG algorithm"


Fig.9
MADDPG parallel method flowchart"

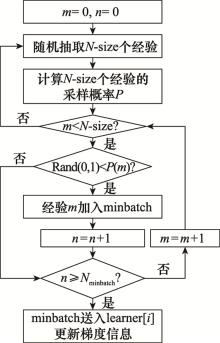
Fig.10
PER mechanism algorithm flow chart"

Fig.11
Schematic diagram of Q-learning iteration in MDP"


Fig.12
Neural network structure of Actor、Critic"


Fig.13
"Predator and prey" environment diagram"

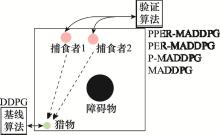
Fig.14
Schematic diagram of experimental design of confrontation"

Table 1
Agent winning percentage statistics"
| 算法胜率对比 | 训练轮数 | ||||
| 4 501~4 600 | 4 601~4 700 | 4 701~4 800 | 4 801~4 900 | 4 901~5 000 | |
| (PPER-MADDPG, PER-MADDPG) | (0.97, 0.02) | (0.96, 0.03) | (0.94, 0.01) | (0.96, 0.01) | (0.94, 0.02) |
| (PPER-MADDPG, P-MADDPG) | (0.97, 0.00) | (0.96, 0.01) | (0.95, 0.01) | (0.97, 0.00) | (0.96, 0.01) |
| (PPER-MADDPG, MADDPG) | (0.96, 0.01) | (0.97, 0.01) | (0.97, 0.00) | (0.96, 0.00) | (0.94, 0.01) |
| (PPER-MADDPG, DDPG) | (0.96, 0.02) | (0.97, 0.01) | (0.93, 0.04) | (0.95, 0.04) | (0.96, 0.02) |

Fig.15
Agent winning curve"
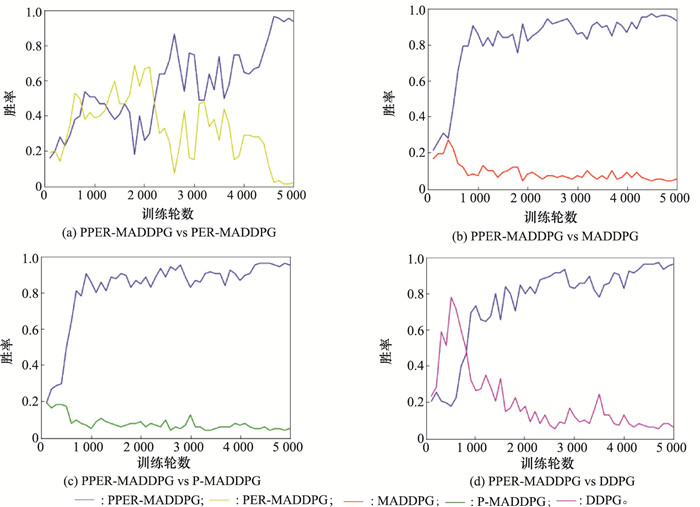
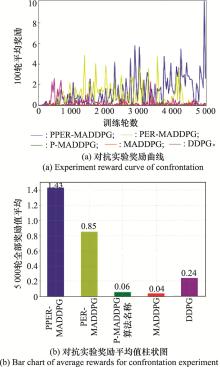
Fig.16
Counter experiment data graph (episode dimension)"

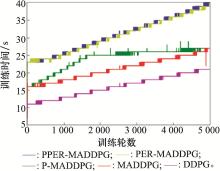
Fig.17
Chart of time spent in each training round"

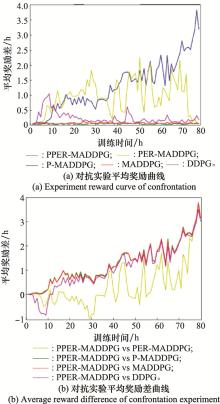
Fig.18
Counter experiment data graph (time dimension)"

Table 2
Agent average reward difference statistical table"
| 算法奖励差值对比 | 训练时间/h | ||||
| 75~76 | 76~77 | 77~78 | 78~79 | 79~80 | |
| PPER-MADDPG-PER-MADDPG | 2.19 | 2.76 | 2.93 | 3.77 | 3.14 |
| PPER-MADDPG-P-MADDPG | 2.46 | 2.81 | 3.10 | 3.79 | 3.15 |
| PPER-MADDPG-MADDPG | 2.41 | 2.80 | 3.11 | 3.75 | 3.15 |
| PPER-MADDPG-DDPG | 2.38 | 2.69 | 2.98 | 3.51 | 3.01 |

Fig.19
"Cooperative navigation" environment diagram"

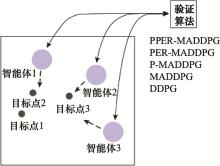
Fig.20
Schematic diagram of experimental design of cooperation"
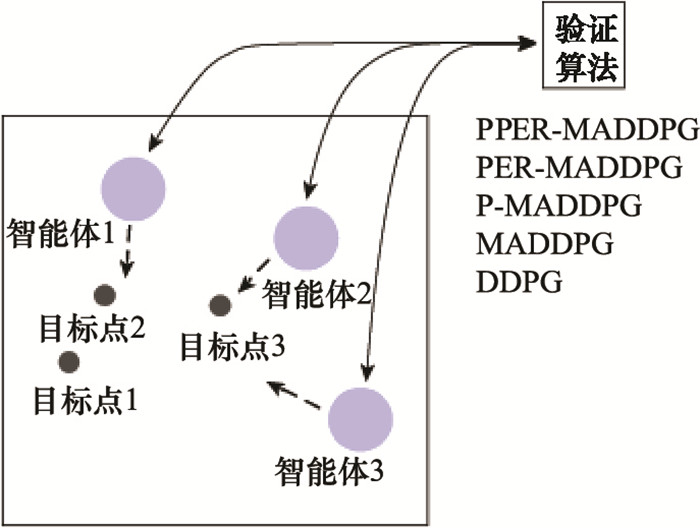

Fig.21
Cooperation experiment data graph(episode dimension)"

Table 3
Statistical table of mean value and standard deviation of agent rewards (different training rounds)"
| 算法对比 | 训练轮数 | ||||
| 4 501~4 600 | 4 601~4 700 | 4 701~4 800 | 4 801~4 900 | 4 901~5 000 | |
| PPER-MADDPG | (-0.23, 0.16) | (-0.24, 0.07) | (-0.29, 0.16) | (-0.24, 0.07) | (-0.23, 0.05) |
| PER-MADDPG | (-0.29, 0.27) | (-0.25, 0.09) | (-0.24, 0.07) | (-0.24, 0.07) | (-0.27, 0.16) |
| P-MADDPG | (-0.59, 0.73) | (-0.72, 0.73) | (-0.81, 0.78) | (-0.52, 0.50) | (-0.62, 0.70) |
| MADDPG | (-0.63, 0.74) | (-0.76, 0.74) | (-0.85, 0.79) | (-0.56, 0.50) | (-0.66, 0.71) |
| DDPG | (-0.22, 0.07) | (-0.24, 0.09) | (-0.28, 0.14) | (-0.28, 0.09) | (-0.26, 0.07) |
Table 4
5 000 rounds of agent average rewards"
| 算法 | 奖励值 |
| PPER-MADDPG | -0.38 |
| PER-MADDPG | -0.42 |
| P-MADDPG | -0.95 |
| MADDPG | -1.01 |
| DDPG | -0.69 |

Fig.22
Chart of time spent in each training round"


Fig.23
Cooperation experiment data graph(time dimension)"

Table 5
Statistical table of mean value and standard deviation of agent rewards (different training time)"
| 算法对比 | 训练时间/h | ||||
| 75~76 | 76~77 | 77~78 | 78~79 | 79~80 | |
| PPER-MADDPG | (-0.29, 0.11) | (-0.26, 0.14) | (-0.24, 0.19) | (-0.22, 0.08) | (-0.24, 0.04) |
| PER-MADDPG | (-0.27, 0.34) | (-0.31, 0.20) | (-0.26, 0.10) | (-0.25, 0.09) | (-0.25, 0.08) |
| P-MADDPG | (-0.98, 0.91) | (-0.55, 0.50) | (-0.59, 0.63) | (-0.69, 0.75) | (-0.41, 0.38) |
| MADDPG | (-0.82, 0.84) | (-0.71, 0.62) | (-0.95, 0.88) | (-0.57, 0.49) | (-0.61, 0.77) |
| DDPG | (-0.25, 0.09) | (-0.25, 0.09) | (-0.41, 0.08) | (-0.61, 0.17) | (-0.26, 0.07) |
Table 6
80 h ours of agent average rewards"
| 算法 | 奖励值 |
| PPER-MADDPG | -0.38 |
| PER-MADDPG | -0.39 |
| P-MADDPG | -0.95 |
| MADDPG | -1.01 |
| DDPG | -0.63 |
| 1 |
ZHANG J , WANG G , YUE S H , et al. Multi-agent system application in accordance with game theory in bi-directional coordination network model[J]. Journal of Systems Engineering and Electronics, 2020, 31 (2): 279- 289.
doi: 10.23919/JSEE.2020.000006 |
| 2 | 孙彧, 曹雷, 陈希亮, 等. 多智能体深度强化学习研究综述[J]. 计算机工程与应用, 2020, 56 (5): 13- 24. |
| SUN Y , CAO L , CHEN X L , et al. Research review on multi-agent deep reinforcement learning[J]. Computer Engineering and Applications, 2020, 56 (5): 13- 24. | |
| 3 |
LECUN Y , BENGIO Y , HINTON G . Deep learning[J]. Nature, 2015, 521 (7553): 436- 444.
doi: 10.1038/nature14539 |
| 4 | MNIH V, KAVUKCUOGLU K, SILVER D, et al. Playing atari with deep reinforcement learning[EB/OL].[2020-02-07].http://arxiv.org/pdf/1312.5602.pdf. |
| 5 | 刘全, 翟建伟, 章宗长, 等. 深度强化学习综述[J]. 计算机学报, 2018, 41 (1): 1- 27. |
| LIU Q , ZHAI J W , ZHANG Z C , et al. Review of deep reinforcement learning[J]. Journal of Computer Science, 2018, 41 (1): 1- 27. | |
| 6 | 谭浪.强化学习在多智能体对抗中的应用研究[D].北京:中国运载火箭技术研究院, 2019. |
| TAN L. Application research of reinforcement learning on multi-agent competition[D]. Beijing: China Academy of Launch Vehicle Technology, 2019. | |
| 7 | HERNANDEZ-LEAL P , KARTAL B , TAYLOR M E . A survey and critique of multiagent deep reinforcement learning[J]. Autonomous Agents and Multi-agent Systems, 2019, 33 (6): 750- 797. |
| 8 | 杜威, 丁世飞. 多智能体强化学习综述[J]. 计算机科学, 2019, 46 (8): 1- 8. |
| DU W , DING S F . A review of multi-agent reinforcement learning[J]. Computer Science, 2019, 46 (8): 1- 8. | |
| 9 | RICHARD S , SUTTON A G . Reinforcement learning:an introduction[M]. Cambridge: MIT Press, 2018. |
| 10 | FOERSTER J, ASSAEL I A, DE F N, et al. Learning to communicate with deep multi-agent reinforcement learning[C]//Proc.of the 30th Annual Conference on Neural Information Processing, 2016: 2137-2145. |
| 11 | LANCTOT M, ZAMBALDI V, GRUSLYS A, et al. A unified game-theoretic approach to multiagent reinforcement learning[C]//Proc.of the Advances in Neural Information Processing Systems, 2017: 4190-4203. |
| 12 | PALMER G, TUYLS K, BLOEMBERGEN D, et al. Lenient multi-agent deep reinforcement learning[C]//Proc.of the 17th International Conference on Autonomous Agents and Multiagent Systems: International Foundation for Autonomous Agents and Multiagent Systems, 2018: 443-451. |
| 13 | OMIDSHAFIEI S, PAZIS J, AMATO C, et al. Deep decentralized multi-task multi-agent reinforcement learning under partial observability[C]//Proc.of the 34th International Conference on Machine Learning, 2017: 2681-2690. |
| 14 | ZHENG Y, HAO J Y, ZHANG Z Z. Weighted double deep multi-agent reinforcement learning in stochastic cooperative environments[C]//Proc.of the Pacific Rim International Confe-rence on Artificial Intelligence, 2018: 421-429. |
| 15 |
JADERBERG M , CZARNECKI W M , DUNNING I , et al. Human-level performance in 3d multiplayer games with population-based reinforcement learning[J]. Science, 2019, 364 (6443): 859- 865.
doi: 10.1126/science.aau6249 |
| 16 | SUNEHAG P, LEVER G, GRUSLYS A, et al. Value-decomposition networks for cooperative multi-agent learning based on team reward[C]//Proc.of the 17th International Conference on Autonomous Agents and MultiAgent Systems, 2018: 2085-2087. |
| 17 | RASHID T, SAMVELYAN M, DE W C S, et al. Qmix: monotonic value function factorisation for deep multi-agent reinforcement learning[EB/OL].[2020-02-07]. http://arxiv.org/pdf/1803.11485.pdf. |
| 18 | FOERSTER J N, FARQUHAR G, AFOURAS T, et al. Counterfactual multi-agent policy gradients[C]//Proc.of the AAAI 32nd Conference on Artificial Intelligence, 2018: 2974-2982. |
| 19 | GUPTA J K, EGOROV M, KOCHENDERFER M. Cooperative multi-agent control using deep reinforcement learning[C]//Proc.of the International Conference on Autonomous Agents and Multiagent Systems, 2017: 66-83. |
| 20 | LOWE R, WU Y, TAMAR A, et al. Multi-agent actor-critic for mixed cooperative-competitive environments[C]//Proc.of the Advances in Neural Information Processing Systems, 2017: 6379-6390. |
| 21 | 何明,张斌,柳强,等. MADDPG算法经验优先抽取机制研究[EB/OL].[2020-02-07]. http://doi.org/10.13195/j.kzyjc.2019.0834. |
| HE M, ZHANG B, LIU Q, et al. Study on the preferential extraction mechanism of MADDPG algorithm experience[EB/OL].[2020-02-07]. http://doi.org/10.13195/j.kzyjc.2019.0834. | |
| 22 | KONDA V R, TSITSIKLIS J N. Actor-critic algorithms[C]//Proc.of the Advances in Neural Information Processing Systems, 2000: 1008-1014. |
| 23 | MNIH V, BADIA A P, MIRZA M, et al. Asynchronous methods for deep reinforcement learning[C]//Proc.of the International Conference on Machine Learning, 2016: 1928-1937. |
| 24 | BABAEIZADEH M, FROSIO I, TYREE S, et al. Reinforcement learning through asynchronous advantage actor-critic on a GPU[EB/OL].[2020-02-07].http://arxiv.org/pdf/1611.06256.pdf. |
| 25 | ESPEHOLT L, SOYER H, MUNOS R, et al. Impala: scalable distributed deep-RL with importance weighted actor-learner architectures[EB/OL].[2020-02-07]. http://arxiv.org/pdf/1802.01561.pdf. |
| 26 | TAI L, PAOLO G, LIU M. Virtual-to-real deep reinforcement learning: continuous control of mobile robots for mapless navigation[C]//Proc.of the IEEE/RSJ International Conference on Intelligent Robots and Systems, 2017: 31-36. |
| 27 | BARTH-MARON G, HOFFMAN M W, BUDDEN D, et al. Distributed distributional deterministic policy gradients[EB/OL].[2020-02-07].http://arxiv.org/pdf/1804.08617.pdf. |
| 28 | HEESS N, SRIRAM S, LEMMON J, et al. Emergence of locomotion behaviours in rich environments[EB/OL].[2020-02-07].http://arxiv.org/pdf/1707.02286.pdf. |
| 29 | LIN L J. Reinforcement learning for robots using neural networks[R].Carnegie Mellon University, 1993: 50-77. |
| 30 | MNIH V, KAVUKCUOGLU K, SILVER D, et al. Playing atari with deep reinforcement learning[EB/OL].[2020-02-07].http://arxiv.org/pdf/1312.5602.pdf. |
| 31 |
MNIH V , KAVUKCUOGLU K , SILVER D , et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518 (7540): 529- 540.
doi: 10.1038/nature14236 |
| 32 | VAN H H, GUEZ A, SILVER D. Deep reinforcement learning with double Q-learning[C]//Proc.of the AAAI 30th Conference on Artificial Intelligence, 2016: 2094-2100. |
| 33 | WANG Z, SCHAUL T, HESSEL M, et al. Dueling network architectures for deep reinforcement learning[EB/OL].[2020-02-07]. http://arxiv.org/pdf/1511.06581.pdf. |
| 34 | HAUSKNECHT M, STONE P. Deep recurrent Q-learning for partially observable MDPS[C]//Proc.of the AAAI Fall Symposium Series, 2015: 29-37. |
| 35 | LILLICRAP T P, HUNT J J, PRITZEL A, et al. Continuous control with deep reinforcement learning[EB/OL].[2020-02-07]. http://arxiv.org/pdf/1509.02971.pdf. |
| 36 | WANG Z, BAPST V, HEESS N, et al. Sample efficient actor-critic with experience replay[2020-02-07].http://arxiv.org/pdf/1611.01224.pdf. |
| 37 | SCHULMAN J, LEVINE S, ABBEEL P, et al. Trust region policy optimization[C]//Proc.of the International Conference on Machine Learning, 2015: 1889-1897. |
| 38 | SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[EB/OL].[2020-02-07].http://arxiv.org/pdf/1707.06347.pdf. |
| 39 | HAARNOJA T, ZHOU A, ABBEEL P, et al. Soft actor-critic: off-policy maximum entropy deep reinforcement learning with a stochastic actor[EB/OL].[2020-02-07].http://arxiv.org/pdf/1801.01290.pdf. |
| 40 | SCHAUL T, QUAN J, ANTONOGLOU I, et al. Prioritized experience replay[EB/OL].[2020-02-07].http://arxiv.org/pdf/1511.05952.pdf. |
| 41 | BRITTAIN M, BERTRAM J, YANG X, et al. Prioritized sequence experience replay[EB/OL].[2020-02-07].http://arxiv.org/pdf/1905.12726.pdf. |
| 42 | ZHANG H, XIONG K, BAI J. Improved deep deterministic policy gradient algorithm based on prioritized sampling[C]//Proc.of the Chinese Intelligent Systems Conference, 2019: 205-215. |
| 43 | KHAN A, ZHANG C, LEE D D, et al. Scalable centralized deep multi-agent reinforcement learning via policy gradients[EB/OL].[2020-02-07].http://arxiv.org/pdf/1805.08776.pdf. |
| 44 | LIU R S, ZOU J. The effects of memory replay in reinforcement learning[C]//Proc.of the 56th Annual Allerton Conference on Communication, Control and Computing, 2019: 478-485. |
| 45 | 陈希亮, 曹雷, 李晨溪, 等. 基于重抽样优选缓存经验回放机制的深度强化学习方法[J]. 控制与决策, 2018, 33 (4): 600- 606. |
| [1] | Zijie MA, Yongjun XIE. Dynamic stealth of cruise missile in system combat [J]. Systems Engineering and Electronics, 2022, 44(9): 2826-2831. |
| [2] | Guan WANG, Haizhong RU, Dali ZHANG, Guangcheng MA, Hongwei XIA. Design of intelligent control system for flexible hypersonic vehicle [J]. Systems Engineering and Electronics, 2022, 44(7): 2276-2285. |
| [3] | Lingyu MENG, Bingli GUO, Wen YANG, Xinwei ZHANG, Zuoqing ZHAO, Shanguo HUANG. Network routing optimization approach based on deep reinforcement learning [J]. Systems Engineering and Electronics, 2022, 44(7): 2311-2318. |
| [4] | Dongzi GUO, Rong HUANG, Hechuan XU, Liwei SUN, Naigang CUI. Research on deep deterministic policy gradient guidance method for reentry vehicle [J]. Systems Engineering and Electronics, 2022, 44(6): 1942-1949. |
| [5] | Qingqing YANG, Yingying GAO, Yu GUO, Boyuan XIA, Kewei YANG. Target search path planning for naval battle field based on deep reinforcement learning [J]. Systems Engineering and Electronics, 2022, 44(11): 3486-3495. |
| [6] | Wen MA, Hui LI, Zhuang WANG, Zhiyong HUANG, Zhaoxin WU, Xiliang CHEN. Close air combat maneuver decision based on deep stochastic game [J]. Systems Engineering and Electronics, 2021, 43(2): 443-451. |
| [7] | Ang GAO, Qisheng GUO, Zhiming DONG, Shaoqing YANG. Research on efficiency evaluation method of multi unmanned ground vehicle system based on EAS+MADRL [J]. Systems Engineering and Electronics, 2021, 43(12): 3643-3651. |
| [8] | Kun ZHANG, Ke LI, Haotian SHI, Zhenchong ZHANG, Zekun LIU. Autonomous guidance maneuver control and decision-making algorithm [J]. Systems Engineering and Electronics, 2020, 42(7): 1567-1574. |
| [9] | Jiayi LIU, Gang WANG, Jie ZHANG, Chuang WANG, Xituan SONG. Target optimal assignment model based on improved AGD-distributed multi-Agent system [J]. Systems Engineering and Electronics, 2020, 42(4): 863-870. |
| [10] | XIE Hao, GUO Aihuang, SONG Chunlin, JIAO Runze. eNB selection for LTE-V using deep reinforcement learning [J]. Systems Engineering and Electronics, 2019, 41(7): 1652-1657. |
| [11] | LI Chenxi, CAO Lei, ZHANG Yongliang, CHEN Xiliang, ZHOU Yuhuan, DUAN Liwen. Knowledge-based deep reinforcement learning: a review [J]. Systems Engineering and Electronics, 2017, 39(11): 2603-2613. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||