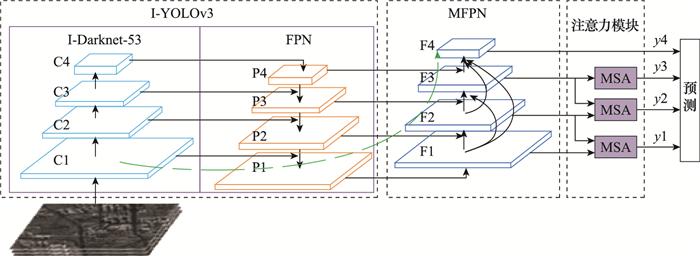
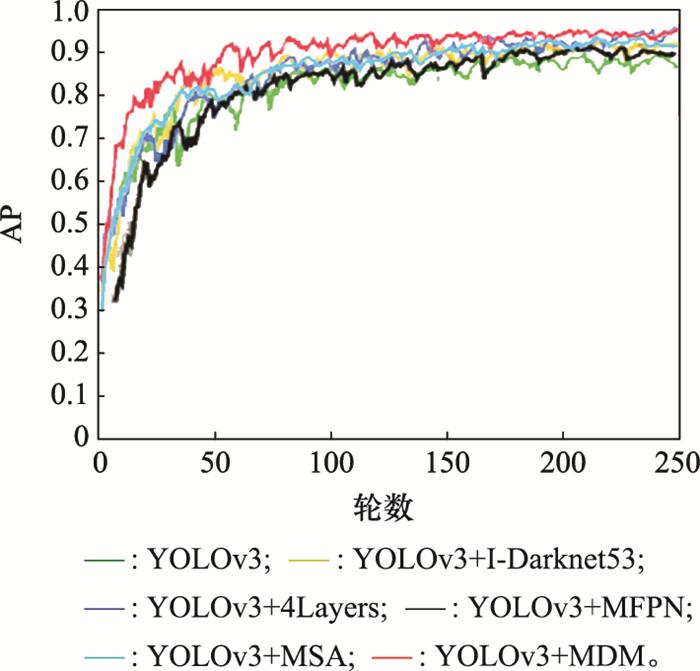
本文提出了一种基于YOLOv3的多尺度检测框架(multi-scale detection model based on YOLOv3, YOLO-M-DM), 其网络结构如图 1 所示, 将对原YOLOv3的改进部分命名为I-YOLOv3(improved YOLOv3)。首先, YOLO-MDM利用I-Darknet-53(improved Darknet-53)进行特征提取, 并构建4层特征金字塔网络(feature pyramid network, FPN), 提高网络特征利用率以及对小尺度目标的敏感性。其次, 通过设计密集连接多尺度FPN(multi-scale FPN, MFPN)结构重构特征金字塔[16 ] , 进一步丰富各特征层的语义特征和细粒度特征。最后, 引入多尺度注意力(multi-scale attention, MSA)模块融合相邻两层的空间特征, 提升目标的显著性特征, 为检测器提供强有力的判断依据, 提升预测结果的可信度。
图1
基于YOLO-MDM的SAR图像舰船检测模型结构
Fig.1
Structure of SAR image ship detection model based on YOLO-MDM
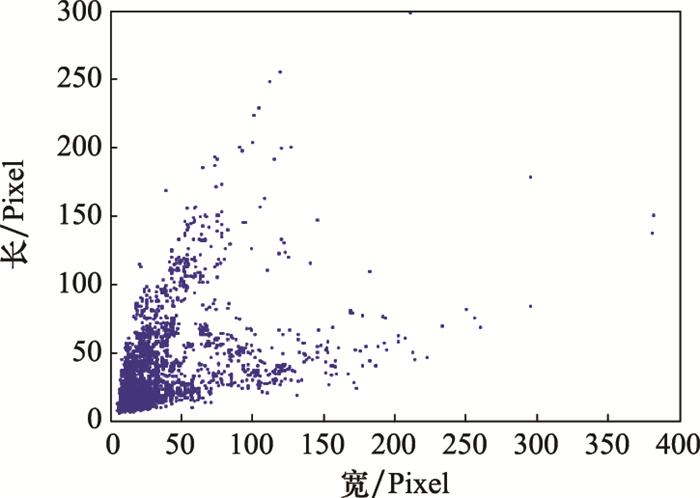
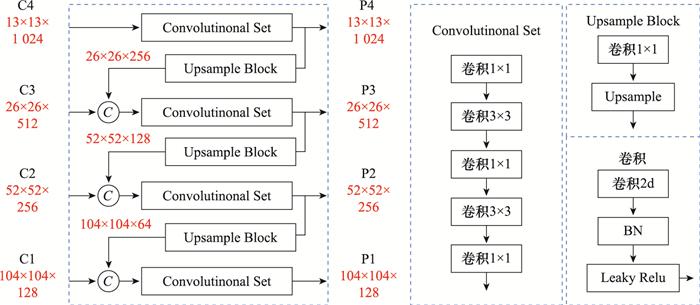
YOLOv3利用特征金字塔融合不同尺度的特征信息, 在一定程度上改善了多尺度目标的检测性能, 但是不适用于SAR图像舰船目标尺度差异大的情况。YOLOv3 3层下采样的步长分别为32、16、8, 在输入图片为416×416的情况下, 若舰船的长或宽小于8, 那么该目标用于预测的像素将不足一个像素, 该模型理论上能检测到的最小目标分辨率在8×8左右。以SAR图像舰船公开数据集SSDD[18 ] 为例, 舰船目标的长、宽所占像素的分布如图 2 所示, 可以看出, 有部分舰船目标的长或者宽小于8, 因此会很大几率造成漏检。基于上述分析, 重新设计特征提取网络, 将下采样步长为4且具有更高分辨率的P2层加入特征金字塔中, 在保留原深层语义信息的基础上获得更多的浅层细节信息, 进一步提高小尺度目标检测的细粒度, 形成四尺度目标预测网络。4层FPN的结构如图 3 所示, C1、C2、C3、C4为I-Darknet-53的输出, P1、P2、P3、P4为经过特征融合后的输出。C4经过5个卷积层后得到P4, P4经过一个1×1卷积和2倍上采样后与C3按通道相加(concat)的方式进行融合, 经过5个卷积后得到P3。P2、P1的构建与P3相同。
图2
SSDD数据集舰船目标尺度分布
Fig.2
Distribution of ship target scales in SSDD dataset
图3
4层FPN网络结构图
Fig.3
Four-layer FPN network structure diagram
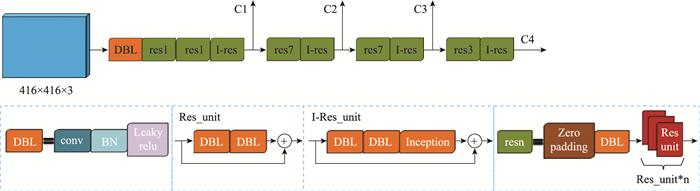
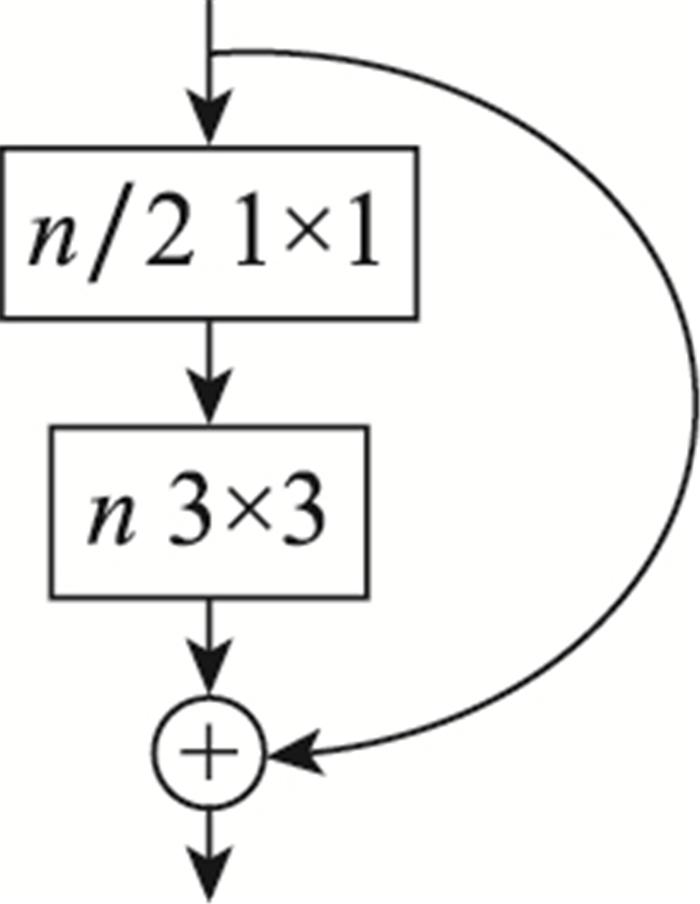
图4
I-Darknet-53网络结构图
Fig.4
I-Darknet-53 network structure diagram
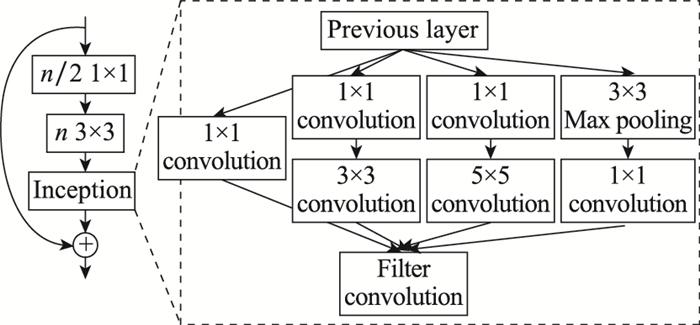
图6
Inception-ResNet网络结构
Fig.6
Inception-ResNet network structure
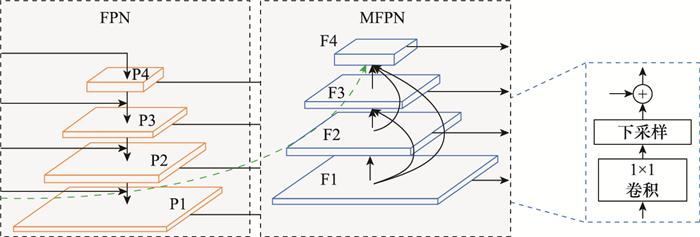
就目前而言, 对于多尺度目标的识别仍然是一个很大的挑战。为了保证尺度的不变性, 通常在网络中加入特征金字塔结构。浅层特征图包含丰富的细节信息, 而深层特征图包含的语义信息较为丰富。低层特征图更利于小尺度目标的检测, 因为随着池化层和卷积层的不断堆叠, 小尺度目标的特征被逐步综合成全局语义信息, 导致小目标的特征被覆盖甚至是丢失。针对以上问题, 本文提出了MFPN网络结构, 将低层特征信息与高层语义信息相融合, 丰富高层的特征信息, 同时提高了高层对小尺度目标的敏感度。通常, FPN结构将低层的细节信息传递到最高层需要经历多个卷积, 而本文提出的MFPN结构, 将细节信息传递到最高层只需要经过几个卷积层, 比路径聚合网络(path aggregation network, PANet)[22 ] 还要高效。此种特征传递和融合方式解决了信息从低层特征图到高层特征图上的传递路径长以及细节信息从低层传到高层困难的问题。
图7
MFPN网络结构
Fig.7
MFPN network structure
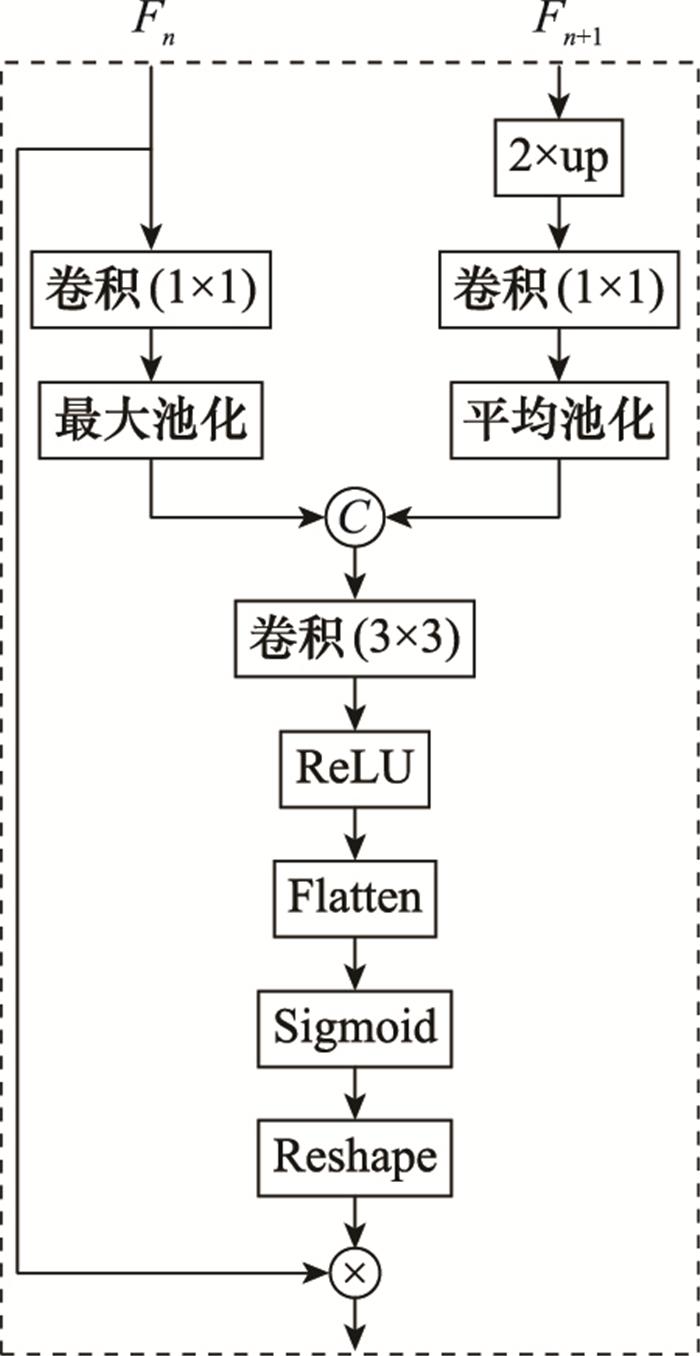
SAR图像舰船检测的一大难点就是场景复杂度高, 而训练数据集不可能包含所有的场景, 因此对于像素占比小的舰船目标而言, 如果能够对输入图像的物体空间信息自动定位, 就能减少背景对于检测的干扰, 从而提高模型的识别精度和鲁棒性。本文提出MSA模块用来突出感兴趣目标的显著性, 图 8 是本文提出的注意力模型, 其在两组不同尺度特征图构建上下文联系, 是一种多尺度注意力模型。对于两路输入F n F n +1F n F n +1n =1, 2, 3), F n +1F n F n +1α 。将显著性系数转化成与F n F n
图8
MSA网络结构
Fig.8
MSA network structure
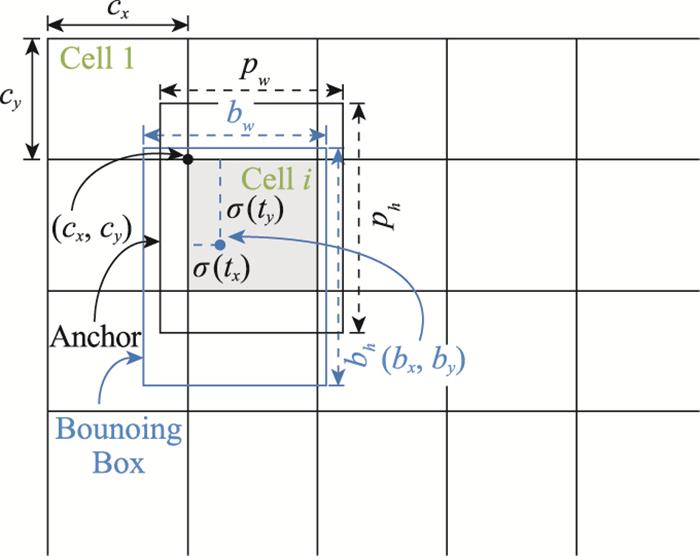
图9
边框回归过程示意图
Fig.9
Schematic diagram of border regression process
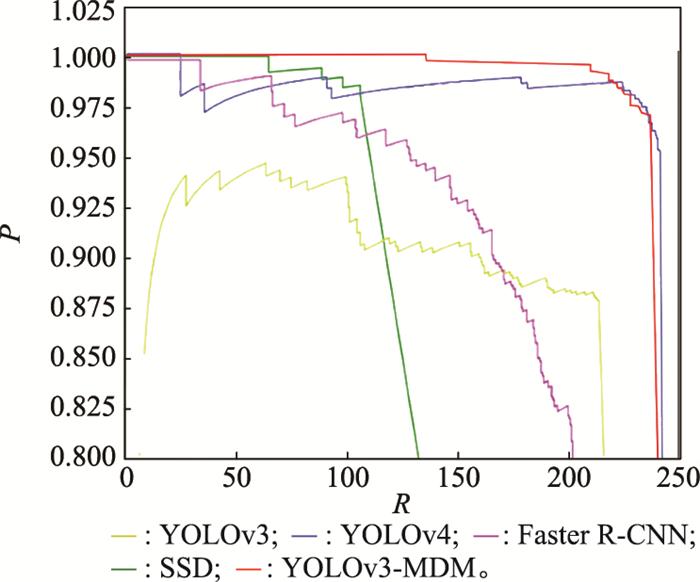
图11
不同网络模型的PR曲线
Fig.11
PR curves of different network model
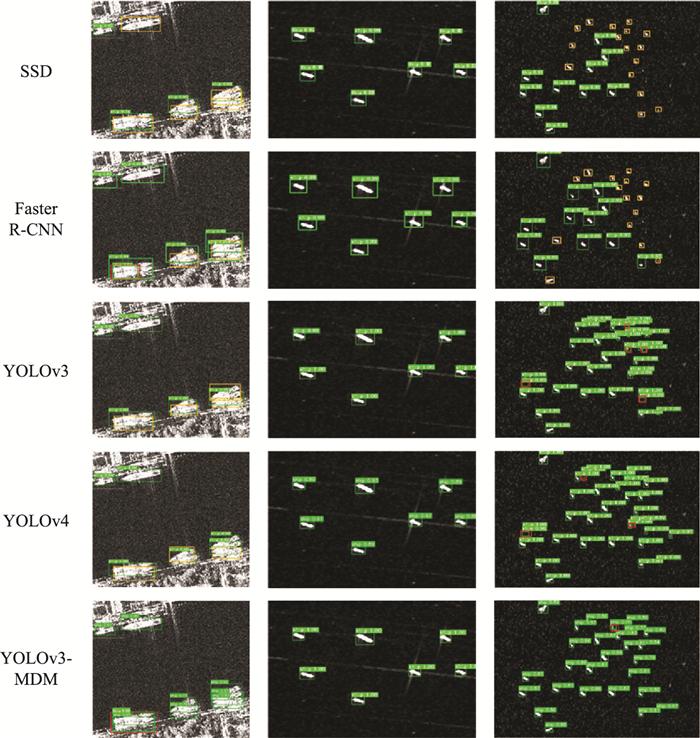
图12
SSDD数据集上不同算法检测结果对比
Fig.12
Comparison of detection results with different algorithms in SSDD dataset
[1]
刘洁瑜 , 赵彤 , 刘敏 . 基于RetinaNet的SAR图像舰船目标检测
[J]. 湖南大学学报(自然科学版) , 2020 , 47 (2 ): 85 - 91 .
URL
[本文引用: 1]
LIU J Y , ZHAO T , LIU M . Ship target detection in SAR image based on RetinaNet
[J]. Journal of Hunan University (Natural Science Edition) , 2020 , 47 (2 ): 85 - 91 .
URL
[本文引用: 1]
[2]
韩子硕 , 王春平 , 付强 , 等 . 基于超密集特征金字塔网络的SAR图像舰船检测
[J]. 系统工程与电子技术 , 2020 , 42 (10 ): 2214 - 2222 .
DOI:10.3969/j.issn.1001-506X.2020.10.09
[本文引用: 1]
HAN Z S , WANG C P , FU Q , et al . Ship detection in SAR images based on super dense feature pyramid networks
[J]. Systems Engineering and Electronics , 2020 , 42 (10 ): 2214 - 2222 .
DOI:10.3969/j.issn.1001-506X.2020.10.09
[本文引用: 1]
[3]
WANG C L , BI F K , ZHANG W P , et al . An intensity-space domain CFAR method for ship detection in HR SAR images
[J]. IEEE Geoscience and Remote Sensing Letters , 2017 , 14 (4 ): 529 - 533 .
DOI:10.1109/LGRS.2017.2654450
[本文引用: 1]
[4]
ZHAO Z , JI K F , XING X W , et al . Ship surveillance by integration of space-borne SAR and AIS-review of current research
[J]. Journal of Navigation , 2014 , 67 (1 ): 177 - 189 .
DOI:10.1017/S0373463313000659
[6]
KRIZHEVSKY A , SUTSKEVER I , HINTON G E . ImageNet classification with deep convolutional neural networks
[J]. Artificial Neural Network , 2017 , 60 (6 ): 84 - 90 .
[本文引用: 1]
[7]
GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2014: 580-587.
[本文引用: 1]
[8]
GIRSHICK R. Fast R-CNN[C]//Proc. of the IEEE International Conference on Computer Vision, 2015: 1440-1448.
[本文引用: 1]
[9]
REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[C]//Proc. of the 28th International Conference on Neural Information Processing Systems, 2015: 91-99.
[本文引用: 1]
[10]
HE K, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN[C]//Proc. of the IEEE International Conference on Computer Vision, 2017: 2980-2988.
[本文引用: 1]
[11]
LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot MultiBox detector[C]//Proc. of the European Conference on Computer Vision, 2016: 21-37.
[本文引用: 1]
[12]
LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[C]//Proc. of the IEEE Trans. on Pattern Analysis and Machine Intelligence, 2017: 318-327.
[本文引用: 1]
[13]
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2016: 779-788.
[本文引用: 1]
[14]
REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 6517-6525.
[15]
REDMON J, FARHADI A. YOLOv3: an incremental improvement[EB/OL]. [2021-04-10]. https://arxiv.org/abs/1804.02767.
[本文引用: 2]
[16]
LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 936-944.
[本文引用: 1]
[17]
SZEGEDY C, IOFFE S, VANHOUCKE V, et al. Inception-v4, inception-ResNet and the impact of residual connections on learning[C]//Proc. of the 31st AAAI Conference on Artificial Intelligence, 2017: 4278-4284.
[本文引用: 2]
[18]
LI J W, QU C W, SHAO J Q. Ship detection in SAR images based on an improved faster R-CNN[C]//Proc. of the SAR in Big Data Era: Models, Methods and Applications, 2017.
[本文引用: 1]
[19]
HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2016: 770-778.
[本文引用: 1]
[20]
XIE S, GIRSHICK R, DOLLÁR P, et al. Aggregated residual transformations for deep neural networks[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 5987-5995.
[本文引用: 1]
[21]
HUANG G, LIU Z, VAN D M L, et al. Densely connected convolutional networks[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 2261-2269.
[本文引用: 1]
[22]
LIU S, QI L, QIN H F, et al. Path aggregation network for instance segmentation[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 8759-8768.
[本文引用: 1]
[23]
刘杰平 , 温竣文 , 梁亚玲 . 基于多尺度注意力导向网络的单目图像深度估计
[J]. 华南理工大学学报(自然科学版) , 2020 , 48 (12 ): 52 - 62 .
URL
[本文引用: 1]
LIU J P , WEN J W , LIANG Y L . Monocular image depth estimation based on multi-scale attention oriented networl
[J]. Journal of South China University of Technology (Natural Science Edition) , 2020 , 48 (12 ): 52 - 62 .
URL
[本文引用: 1]
[24]
刘元宁 , 吴迪 , 朱晓冬 , 等 . 基于YOLOv3改进的用户界面组件检测算法
[J]. 吉林大学学报(工学版) , 2021 , 51 (3 ): 1026 - 1033 .
URL
[本文引用: 1]
LIU Y N , WU D , ZHU X D , et al . User interface components detection algorithm based on improved YOLOv3
[J]. Journal of Jilin University (Engineering and Technology Edition) , 2021 , 51 (3 ): 1026 - 1033 .
URL
[本文引用: 1]
基于RetinaNet的SAR图像舰船目标检测
1
2020
... 随着各国经济和军事装备的发展, 海上经济贸易和军事演习活动愈加频繁, 海域监测能力的重要性日益凸显.舰船检测作为海上交通动态检测、渔业管理、安全威胁监测、非法活动捕捉等领域的重要监测手段, 备受国内外研究人员的关注.目前海上主流的监测手段包括: 光学遥感雷达、远程红外、高光谱成像、合成孔径雷达(synthetic aperture radar, SAR)等.前3种检测手段易受雷雨、云层、沙尘、光照等多种复杂环境影响, 难以定点定时完成舰船检测任务.与传统的光学传感器成像模式不同, SAR通过将高频电磁波与合成孔径原理相结合, 主动对特定区域进行探测而生成的高分辨率图像, 可以对目标进行全天候、任时段、多角度的监测[1 -2 ] .随着星载SAR技术的发展, SAR图像的质量得到进一步提升, 被广泛地应用到舰船目标检测领域, 并且已经成为当前舰船检测的研究热点. ...
Ship target detection in SAR image based on RetinaNet
1
2020
... 随着各国经济和军事装备的发展, 海上经济贸易和军事演习活动愈加频繁, 海域监测能力的重要性日益凸显.舰船检测作为海上交通动态检测、渔业管理、安全威胁监测、非法活动捕捉等领域的重要监测手段, 备受国内外研究人员的关注.目前海上主流的监测手段包括: 光学遥感雷达、远程红外、高光谱成像、合成孔径雷达(synthetic aperture radar, SAR)等.前3种检测手段易受雷雨、云层、沙尘、光照等多种复杂环境影响, 难以定点定时完成舰船检测任务.与传统的光学传感器成像模式不同, SAR通过将高频电磁波与合成孔径原理相结合, 主动对特定区域进行探测而生成的高分辨率图像, 可以对目标进行全天候、任时段、多角度的监测[1 -2 ] .随着星载SAR技术的发展, SAR图像的质量得到进一步提升, 被广泛地应用到舰船目标检测领域, 并且已经成为当前舰船检测的研究热点. ...
基于超密集特征金字塔网络的SAR图像舰船检测
1
2020
... 随着各国经济和军事装备的发展, 海上经济贸易和军事演习活动愈加频繁, 海域监测能力的重要性日益凸显.舰船检测作为海上交通动态检测、渔业管理、安全威胁监测、非法活动捕捉等领域的重要监测手段, 备受国内外研究人员的关注.目前海上主流的监测手段包括: 光学遥感雷达、远程红外、高光谱成像、合成孔径雷达(synthetic aperture radar, SAR)等.前3种检测手段易受雷雨、云层、沙尘、光照等多种复杂环境影响, 难以定点定时完成舰船检测任务.与传统的光学传感器成像模式不同, SAR通过将高频电磁波与合成孔径原理相结合, 主动对特定区域进行探测而生成的高分辨率图像, 可以对目标进行全天候、任时段、多角度的监测[1 -2 ] .随着星载SAR技术的发展, SAR图像的质量得到进一步提升, 被广泛地应用到舰船目标检测领域, 并且已经成为当前舰船检测的研究热点. ...
Ship detection in SAR images based on super dense feature pyramid networks
1
2020
... 随着各国经济和军事装备的发展, 海上经济贸易和军事演习活动愈加频繁, 海域监测能力的重要性日益凸显.舰船检测作为海上交通动态检测、渔业管理、安全威胁监测、非法活动捕捉等领域的重要监测手段, 备受国内外研究人员的关注.目前海上主流的监测手段包括: 光学遥感雷达、远程红外、高光谱成像、合成孔径雷达(synthetic aperture radar, SAR)等.前3种检测手段易受雷雨、云层、沙尘、光照等多种复杂环境影响, 难以定点定时完成舰船检测任务.与传统的光学传感器成像模式不同, SAR通过将高频电磁波与合成孔径原理相结合, 主动对特定区域进行探测而生成的高分辨率图像, 可以对目标进行全天候、任时段、多角度的监测[1 -2 ] .随着星载SAR技术的发展, SAR图像的质量得到进一步提升, 被广泛地应用到舰船目标检测领域, 并且已经成为当前舰船检测的研究热点. ...
An intensity-space domain CFAR method for ship detection in HR SAR images
1
2017
... 针对SAR图像舰船检测, 传统方法[3 -5 ] 先进行海陆分割然后再进行目标检测, 并基于人工制作的特征进行识别.这类方法虚警概率高、耗时量大、近岸区域检测性能差.此外, SAR图像中的散斑噪声和运动模糊也严重制约着传统算法的性能提升.近年来, 深度学习方法逐步发展成熟, 基于深度学习[6 ] 的目标检测技术已经成为目标检测领域的主流方法.当前用于目标检测的网络模型可大致分为两类: 双阶段网络和单阶段网络.双阶段网络将检测过程分为建议区域生成和边框分类与回归两个阶段, 检测精度高但速度慢不具备实时性.这类网络的典型代表有区域卷积神经网络(residual convolutional neural network, R-CNN)[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 等.单阶段网络模型摒弃了建议区域生成阶段, 直接在卷积神经网络(convolutional neural network, CNN)提取的特征图上进行目标预测, 典型网络有单次多盒检测器(single shot multibox detector, SSD)[11 ] 、Retina-Net[12 ] 、YOLO (you only look once)[13 -15 ] .相较于双阶段网络, 其检测速度快但精度略有不足. ...
Ship surveillance by integration of space-borne SAR and AIS-review of current research
0
2014
Review of ship detection from airborne platforms
1
2001
... 针对SAR图像舰船检测, 传统方法[3 -5 ] 先进行海陆分割然后再进行目标检测, 并基于人工制作的特征进行识别.这类方法虚警概率高、耗时量大、近岸区域检测性能差.此外, SAR图像中的散斑噪声和运动模糊也严重制约着传统算法的性能提升.近年来, 深度学习方法逐步发展成熟, 基于深度学习[6 ] 的目标检测技术已经成为目标检测领域的主流方法.当前用于目标检测的网络模型可大致分为两类: 双阶段网络和单阶段网络.双阶段网络将检测过程分为建议区域生成和边框分类与回归两个阶段, 检测精度高但速度慢不具备实时性.这类网络的典型代表有区域卷积神经网络(residual convolutional neural network, R-CNN)[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 等.单阶段网络模型摒弃了建议区域生成阶段, 直接在卷积神经网络(convolutional neural network, CNN)提取的特征图上进行目标预测, 典型网络有单次多盒检测器(single shot multibox detector, SSD)[11 ] 、Retina-Net[12 ] 、YOLO (you only look once)[13 -15 ] .相较于双阶段网络, 其检测速度快但精度略有不足. ...
ImageNet classification with deep convolutional neural networks
1
2017
... 针对SAR图像舰船检测, 传统方法[3 -5 ] 先进行海陆分割然后再进行目标检测, 并基于人工制作的特征进行识别.这类方法虚警概率高、耗时量大、近岸区域检测性能差.此外, SAR图像中的散斑噪声和运动模糊也严重制约着传统算法的性能提升.近年来, 深度学习方法逐步发展成熟, 基于深度学习[6 ] 的目标检测技术已经成为目标检测领域的主流方法.当前用于目标检测的网络模型可大致分为两类: 双阶段网络和单阶段网络.双阶段网络将检测过程分为建议区域生成和边框分类与回归两个阶段, 检测精度高但速度慢不具备实时性.这类网络的典型代表有区域卷积神经网络(residual convolutional neural network, R-CNN)[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 等.单阶段网络模型摒弃了建议区域生成阶段, 直接在卷积神经网络(convolutional neural network, CNN)提取的特征图上进行目标预测, 典型网络有单次多盒检测器(single shot multibox detector, SSD)[11 ] 、Retina-Net[12 ] 、YOLO (you only look once)[13 -15 ] .相较于双阶段网络, 其检测速度快但精度略有不足. ...
1
... 针对SAR图像舰船检测, 传统方法[3 -5 ] 先进行海陆分割然后再进行目标检测, 并基于人工制作的特征进行识别.这类方法虚警概率高、耗时量大、近岸区域检测性能差.此外, SAR图像中的散斑噪声和运动模糊也严重制约着传统算法的性能提升.近年来, 深度学习方法逐步发展成熟, 基于深度学习[6 ] 的目标检测技术已经成为目标检测领域的主流方法.当前用于目标检测的网络模型可大致分为两类: 双阶段网络和单阶段网络.双阶段网络将检测过程分为建议区域生成和边框分类与回归两个阶段, 检测精度高但速度慢不具备实时性.这类网络的典型代表有区域卷积神经网络(residual convolutional neural network, R-CNN)[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 等.单阶段网络模型摒弃了建议区域生成阶段, 直接在卷积神经网络(convolutional neural network, CNN)提取的特征图上进行目标预测, 典型网络有单次多盒检测器(single shot multibox detector, SSD)[11 ] 、Retina-Net[12 ] 、YOLO (you only look once)[13 -15 ] .相较于双阶段网络, 其检测速度快但精度略有不足. ...
1
... 针对SAR图像舰船检测, 传统方法[3 -5 ] 先进行海陆分割然后再进行目标检测, 并基于人工制作的特征进行识别.这类方法虚警概率高、耗时量大、近岸区域检测性能差.此外, SAR图像中的散斑噪声和运动模糊也严重制约着传统算法的性能提升.近年来, 深度学习方法逐步发展成熟, 基于深度学习[6 ] 的目标检测技术已经成为目标检测领域的主流方法.当前用于目标检测的网络模型可大致分为两类: 双阶段网络和单阶段网络.双阶段网络将检测过程分为建议区域生成和边框分类与回归两个阶段, 检测精度高但速度慢不具备实时性.这类网络的典型代表有区域卷积神经网络(residual convolutional neural network, R-CNN)[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 等.单阶段网络模型摒弃了建议区域生成阶段, 直接在卷积神经网络(convolutional neural network, CNN)提取的特征图上进行目标预测, 典型网络有单次多盒检测器(single shot multibox detector, SSD)[11 ] 、Retina-Net[12 ] 、YOLO (you only look once)[13 -15 ] .相较于双阶段网络, 其检测速度快但精度略有不足. ...
1
... 针对SAR图像舰船检测, 传统方法[3 -5 ] 先进行海陆分割然后再进行目标检测, 并基于人工制作的特征进行识别.这类方法虚警概率高、耗时量大、近岸区域检测性能差.此外, SAR图像中的散斑噪声和运动模糊也严重制约着传统算法的性能提升.近年来, 深度学习方法逐步发展成熟, 基于深度学习[6 ] 的目标检测技术已经成为目标检测领域的主流方法.当前用于目标检测的网络模型可大致分为两类: 双阶段网络和单阶段网络.双阶段网络将检测过程分为建议区域生成和边框分类与回归两个阶段, 检测精度高但速度慢不具备实时性.这类网络的典型代表有区域卷积神经网络(residual convolutional neural network, R-CNN)[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 等.单阶段网络模型摒弃了建议区域生成阶段, 直接在卷积神经网络(convolutional neural network, CNN)提取的特征图上进行目标预测, 典型网络有单次多盒检测器(single shot multibox detector, SSD)[11 ] 、Retina-Net[12 ] 、YOLO (you only look once)[13 -15 ] .相较于双阶段网络, 其检测速度快但精度略有不足. ...
1
... 针对SAR图像舰船检测, 传统方法[3 -5 ] 先进行海陆分割然后再进行目标检测, 并基于人工制作的特征进行识别.这类方法虚警概率高、耗时量大、近岸区域检测性能差.此外, SAR图像中的散斑噪声和运动模糊也严重制约着传统算法的性能提升.近年来, 深度学习方法逐步发展成熟, 基于深度学习[6 ] 的目标检测技术已经成为目标检测领域的主流方法.当前用于目标检测的网络模型可大致分为两类: 双阶段网络和单阶段网络.双阶段网络将检测过程分为建议区域生成和边框分类与回归两个阶段, 检测精度高但速度慢不具备实时性.这类网络的典型代表有区域卷积神经网络(residual convolutional neural network, R-CNN)[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 等.单阶段网络模型摒弃了建议区域生成阶段, 直接在卷积神经网络(convolutional neural network, CNN)提取的特征图上进行目标预测, 典型网络有单次多盒检测器(single shot multibox detector, SSD)[11 ] 、Retina-Net[12 ] 、YOLO (you only look once)[13 -15 ] .相较于双阶段网络, 其检测速度快但精度略有不足. ...
1
... 针对SAR图像舰船检测, 传统方法[3 -5 ] 先进行海陆分割然后再进行目标检测, 并基于人工制作的特征进行识别.这类方法虚警概率高、耗时量大、近岸区域检测性能差.此外, SAR图像中的散斑噪声和运动模糊也严重制约着传统算法的性能提升.近年来, 深度学习方法逐步发展成熟, 基于深度学习[6 ] 的目标检测技术已经成为目标检测领域的主流方法.当前用于目标检测的网络模型可大致分为两类: 双阶段网络和单阶段网络.双阶段网络将检测过程分为建议区域生成和边框分类与回归两个阶段, 检测精度高但速度慢不具备实时性.这类网络的典型代表有区域卷积神经网络(residual convolutional neural network, R-CNN)[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 等.单阶段网络模型摒弃了建议区域生成阶段, 直接在卷积神经网络(convolutional neural network, CNN)提取的特征图上进行目标预测, 典型网络有单次多盒检测器(single shot multibox detector, SSD)[11 ] 、Retina-Net[12 ] 、YOLO (you only look once)[13 -15 ] .相较于双阶段网络, 其检测速度快但精度略有不足. ...
1
... 针对SAR图像舰船检测, 传统方法[3 -5 ] 先进行海陆分割然后再进行目标检测, 并基于人工制作的特征进行识别.这类方法虚警概率高、耗时量大、近岸区域检测性能差.此外, SAR图像中的散斑噪声和运动模糊也严重制约着传统算法的性能提升.近年来, 深度学习方法逐步发展成熟, 基于深度学习[6 ] 的目标检测技术已经成为目标检测领域的主流方法.当前用于目标检测的网络模型可大致分为两类: 双阶段网络和单阶段网络.双阶段网络将检测过程分为建议区域生成和边框分类与回归两个阶段, 检测精度高但速度慢不具备实时性.这类网络的典型代表有区域卷积神经网络(residual convolutional neural network, R-CNN)[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 等.单阶段网络模型摒弃了建议区域生成阶段, 直接在卷积神经网络(convolutional neural network, CNN)提取的特征图上进行目标预测, 典型网络有单次多盒检测器(single shot multibox detector, SSD)[11 ] 、Retina-Net[12 ] 、YOLO (you only look once)[13 -15 ] .相较于双阶段网络, 其检测速度快但精度略有不足. ...
1
... 针对SAR图像舰船检测, 传统方法[3 -5 ] 先进行海陆分割然后再进行目标检测, 并基于人工制作的特征进行识别.这类方法虚警概率高、耗时量大、近岸区域检测性能差.此外, SAR图像中的散斑噪声和运动模糊也严重制约着传统算法的性能提升.近年来, 深度学习方法逐步发展成熟, 基于深度学习[6 ] 的目标检测技术已经成为目标检测领域的主流方法.当前用于目标检测的网络模型可大致分为两类: 双阶段网络和单阶段网络.双阶段网络将检测过程分为建议区域生成和边框分类与回归两个阶段, 检测精度高但速度慢不具备实时性.这类网络的典型代表有区域卷积神经网络(residual convolutional neural network, R-CNN)[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 等.单阶段网络模型摒弃了建议区域生成阶段, 直接在卷积神经网络(convolutional neural network, CNN)提取的特征图上进行目标预测, 典型网络有单次多盒检测器(single shot multibox detector, SSD)[11 ] 、Retina-Net[12 ] 、YOLO (you only look once)[13 -15 ] .相较于双阶段网络, 其检测速度快但精度略有不足. ...
2
... 针对SAR图像舰船检测, 传统方法[3 -5 ] 先进行海陆分割然后再进行目标检测, 并基于人工制作的特征进行识别.这类方法虚警概率高、耗时量大、近岸区域检测性能差.此外, SAR图像中的散斑噪声和运动模糊也严重制约着传统算法的性能提升.近年来, 深度学习方法逐步发展成熟, 基于深度学习[6 ] 的目标检测技术已经成为目标检测领域的主流方法.当前用于目标检测的网络模型可大致分为两类: 双阶段网络和单阶段网络.双阶段网络将检测过程分为建议区域生成和边框分类与回归两个阶段, 检测精度高但速度慢不具备实时性.这类网络的典型代表有区域卷积神经网络(residual convolutional neural network, R-CNN)[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 等.单阶段网络模型摒弃了建议区域生成阶段, 直接在卷积神经网络(convolutional neural network, CNN)提取的特征图上进行目标预测, 典型网络有单次多盒检测器(single shot multibox detector, SSD)[11 ] 、Retina-Net[12 ] 、YOLO (you only look once)[13 -15 ] .相较于双阶段网络, 其检测速度快但精度略有不足. ...
... 在光学图像目标检测领域中, YOLOv3[15 ] 的出现改变了双阶段网络的精度高于单阶段网络的状况, 其同时兼顾了检测的速度和精度.但是SAR图像跟光学图像的成像原理存在着本质的差别.SAR图像中, 舰船目标特征少、尺寸变化大, 伴随着多种噪声的干扰.若将YOLOv3直接用于SAR图像目标检测会存在漏检、召回率低、精度不高等问题.基于以上分析, 本文在YOLOv3的基础上进行改进, 提出了一种YOLOv3的多尺度检测框架.通过在四尺度特征图上进行目标预测, 提升网络对小尺度目标的敏感度; 自下而上的建立增强型特征金字塔, 构建目标信息丰富的特征图; 利用注意力机制增强目标的显著性特征, 提升检测器对SAR图像多尺度舰船目标的检测性能. ...
1
... 本文提出了一种基于YOLOv3的多尺度检测框架(multi-scale detection model based on YOLOv3, YOLO-M-DM), 其网络结构如图 1 所示, 将对原YOLOv3的改进部分命名为I-YOLOv3(improved YOLOv3).首先, YOLO-MDM利用I-Darknet-53(improved Darknet-53)进行特征提取, 并构建4层特征金字塔网络(feature pyramid network, FPN), 提高网络特征利用率以及对小尺度目标的敏感性.其次, 通过设计密集连接多尺度FPN(multi-scale FPN, MFPN)结构重构特征金字塔[16 ] , 进一步丰富各特征层的语义特征和细粒度特征.最后, 引入多尺度注意力(multi-scale attention, MSA)模块融合相邻两层的空间特征, 提升目标的显著性特征, 为检测器提供强有力的判断依据, 提升预测结果的可信度. ...
2
... YOLOv3在特征提取上采用的是Darknet-53模型, 使用连续的3×3和1×1卷积以及shortcut连接前后特征层.Darknet-53网络特征提取能力强, 引入残差网络(residual network, ResNet), 解决了梯度消失的问题.但就YOLOv3而言, 因为其3层预测模式和无针对性的特征处理过程, 导致对小目标的检测效果并不理想.而一般星载SAR图像中包含大量的小尺度舰船目标, 因此进一步增大了YOLOv3预测层数, 提高低层特征丰富度, 并用Inception-ResNet[17 ] 代替原模型输出降维前的残差结构, 构建了I-YOLOv3模型. ...
... 残差网络结构最早在文献[19 ]中被提出, 主要是用于解决由卷积层堆积导致的性能下降问题.Darknet-53在网络连接中引入了大量的残差结构, 不仅解决了因卷积层数增加而出现的梯度消失问题, 并且加速了网络收敛.基于残差网络的强大功能和优势, 其结构也在不断地发生变化, 衍生出了一系列的变体残差结构, 典型代表有: ResNeXt[20 ] 、Inception-ResNet[17 ] 、DenseNet(dense convolutional network)[21 ] 等. ...
1
... YOLOv3利用特征金字塔融合不同尺度的特征信息, 在一定程度上改善了多尺度目标的检测性能, 但是不适用于SAR图像舰船目标尺度差异大的情况.YOLOv3 3层下采样的步长分别为32、16、8, 在输入图片为416×416的情况下, 若舰船的长或宽小于8, 那么该目标用于预测的像素将不足一个像素, 该模型理论上能检测到的最小目标分辨率在8×8左右.以SAR图像舰船公开数据集SSDD[18 ] 为例, 舰船目标的长、宽所占像素的分布如图 2 所示, 可以看出, 有部分舰船目标的长或者宽小于8, 因此会很大几率造成漏检.基于上述分析, 重新设计特征提取网络, 将下采样步长为4且具有更高分辨率的P2层加入特征金字塔中, 在保留原深层语义信息的基础上获得更多的浅层细节信息, 进一步提高小尺度目标检测的细粒度, 形成四尺度目标预测网络.4层FPN的结构如图 3 所示, C1、C2、C3、C4为I-Darknet-53的输出, P1、P2、P3、P4为经过特征融合后的输出.C4经过5个卷积层后得到P4, P4经过一个1×1卷积和2倍上采样后与C3按通道相加(concat)的方式进行融合, 经过5个卷积后得到P3.P2、P1的构建与P3相同. ...
1
... 残差网络结构最早在文献[19 ]中被提出, 主要是用于解决由卷积层堆积导致的性能下降问题.Darknet-53在网络连接中引入了大量的残差结构, 不仅解决了因卷积层数增加而出现的梯度消失问题, 并且加速了网络收敛.基于残差网络的强大功能和优势, 其结构也在不断地发生变化, 衍生出了一系列的变体残差结构, 典型代表有: ResNeXt[20 ] 、Inception-ResNet[17 ] 、DenseNet(dense convolutional network)[21 ] 等. ...
1
... 残差网络结构最早在文献[19 ]中被提出, 主要是用于解决由卷积层堆积导致的性能下降问题.Darknet-53在网络连接中引入了大量的残差结构, 不仅解决了因卷积层数增加而出现的梯度消失问题, 并且加速了网络收敛.基于残差网络的强大功能和优势, 其结构也在不断地发生变化, 衍生出了一系列的变体残差结构, 典型代表有: ResNeXt[20 ] 、Inception-ResNet[17 ] 、DenseNet(dense convolutional network)[21 ] 等. ...
1
... 残差网络结构最早在文献[19 ]中被提出, 主要是用于解决由卷积层堆积导致的性能下降问题.Darknet-53在网络连接中引入了大量的残差结构, 不仅解决了因卷积层数增加而出现的梯度消失问题, 并且加速了网络收敛.基于残差网络的强大功能和优势, 其结构也在不断地发生变化, 衍生出了一系列的变体残差结构, 典型代表有: ResNeXt[20 ] 、Inception-ResNet[17 ] 、DenseNet(dense convolutional network)[21 ] 等. ...
1
... 就目前而言, 对于多尺度目标的识别仍然是一个很大的挑战.为了保证尺度的不变性, 通常在网络中加入特征金字塔结构.浅层特征图包含丰富的细节信息, 而深层特征图包含的语义信息较为丰富.低层特征图更利于小尺度目标的检测, 因为随着池化层和卷积层的不断堆叠, 小尺度目标的特征被逐步综合成全局语义信息, 导致小目标的特征被覆盖甚至是丢失.针对以上问题, 本文提出了MFPN网络结构, 将低层特征信息与高层语义信息相融合, 丰富高层的特征信息, 同时提高了高层对小尺度目标的敏感度.通常, FPN结构将低层的细节信息传递到最高层需要经历多个卷积, 而本文提出的MFPN结构, 将细节信息传递到最高层只需要经过几个卷积层, 比路径聚合网络(path aggregation network, PANet)[22 ] 还要高效.此种特征传递和融合方式解决了信息从低层特征图到高层特征图上的传递路径长以及细节信息从低层传到高层困难的问题. ...
基于多尺度注意力导向网络的单目图像深度估计
1
2020
... 损失函数由3部分组成: 边框损失、置信度损失和分类损失[23 ] , 具体的计算如下所示: ...
Monocular image depth estimation based on multi-scale attention oriented networl
1
2020
... 损失函数由3部分组成: 边框损失、置信度损失和分类损失[23 ] , 具体的计算如下所示: ...
基于YOLOv3改进的用户界面组件检测算法
1
2021
... 为了验证网络的检测性能, 本文使用的评价指标为目标检测领域中的通用指标, 主要包括准确率P 、召回率R 和平均精度AP[24 ] .PR曲线描述了P 和R 之间的关系, PR曲线下的面积即为AP.P 、R 、AP的计算公式分别为 ...
User interface components detection algorithm based on improved YOLOv3
1
2021
... 为了验证网络的检测性能, 本文使用的评价指标为目标检测领域中的通用指标, 主要包括准确率P 、召回率R 和平均精度AP[24 ] .PR曲线描述了P 和R 之间的关系, PR曲线下的面积即为AP.P 、R 、AP的计算公式分别为 ...



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}