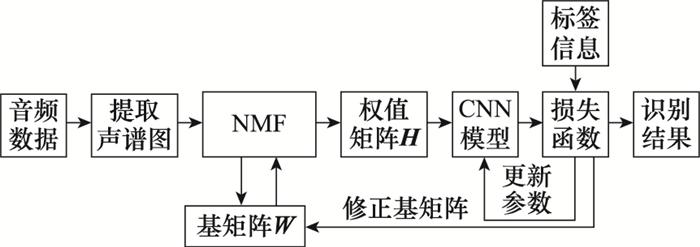
To solve the problem of feature representation of complex acoustic environment in acoustic scene classification task, an optimization algorithm of joint training feature extraction and classification model is proposed. In order to learn more discriminative and supervised features, non-negative matrix factorization is combined with convolution neural network training, and the loss value of network is used to realize feature extraction and network parameters updating. The logarithmic spectrogram is extracted from the TUT2017 dataset as the basic feature. And the deep convolutional neural network is built for experimental verification.The simulation results show that the recognition accuracy of the proposed algorithm is improved by 3.9% compared with that before optimization, and is superior to the other two commonly used acoustic features, which proves that the algorithm can effectively improve the overall classification effect.
WEI Juan. Acoustic scene classification based on joint optimization of NMF and CNN. Systems Engineering and Electronics[J], 2022, 44(5): 1433-1438 doi:10.12305/j.issn.1001-506X.2022.05.01
0 引言
声学场景分类(acoustic scene classification, ASC)旨在从不同音频片段中识别出各自包含的场景信息并加以分类。相比利用图像或视频信息实现场景分类, ASC技术具有全向性, 且不会受遮挡和光线条件的影响, 在智能穿戴设备、物联网音频监控、巡检机器人等领域有着广泛的应用前景[1-2]。
为验证联合优化算法的实际效果, 将SNMF特征与TUT2017数据集的官方基线系统[27]、无监督NMF特征、以对数声谱图为基础提取的TNMF特征[11]、CQT特征与LM特征进行对比。其中, NMF特征和SNMF特征的特征维数K=256。为保证所有特征能够拥有适合其自身特点的分类器, 令NMF与SNMF特征的分类器为CNN10模型, TNMF特征的分类器同文献[11], 而LM和CQT特征则选取在2020年声学场景和事件的检测与分类挑战赛(Detection and Classification of Acoustic Scenes and Events, DCASE)中表现优异的类VGGNet模型[28]。获得的分类结果如表 4所示。
Table 4
表4
表4不同特征的识别准确率对比
Table 4 Comparison of recognition accuracy of different features
MCDONNELL M D, GAO W. Acoustic scene classification using deep residual networks with late fusion of separated high and low frequency paths[C]//Proc. of the IEEE International Conference on Acoustics, Speech and Signal Processing, 2020.
SONG H W, HAN J Q, DENG S W, et al. Acoustic scene classification by implicitly identifying distinct sound events[C]//Proc. of the Interspeech, 2019: 3860-3864.
WANG M, WANG R, ZHANG X L, et al. Hybrid constant-Q transform based CNN ensemble for acoustic scene classification[C]//Proc. of the Asia-Pacific Signal and Information Processing Association Annual Summit and Conference, 2019: 1511-1516.
SPRECHMANN P, BRONSTEIN A M, SAPIRO G. Supervised non-euclidean sparse NMF via bilevel optimization with applications to speech enhancement[C]//Proc. of the Hands-free Speech Communication and Microphone Arrays, 2014: 11-15.
PODWINSKA Z, SOBIERAJ I, FAZENDA B M, et al. Acoustic event detection from weakly labeled data using auditory salience[C]//Proc. of the IEEE International Conference on Acoustics, Speech and Signal Processing, 2019.
Feature extraction based on the non-negative matrix factorization of convolutional neural networks for monitoring domestic activity with acoustic signals
BISOT V, SERIZEL R, ESSID S, et al. Supervised non-negative matrix factorization for acoustic scene classification[C]//Proc. of the IEEE International Evaluation Campaign on Detection and Classification of Acousitc Scenes and Events, 2016.
DOAN T, NGUYEN H, NGO D T, et al. Acoustic scene classification using adeeper training method for convolution neural network[C]//Proc. of the International Symposium on Electrical and Electronics Engineering, 2019: 63-67.
KOMATSU T, SENDA Y, KONDO R. Acoustic event detection based on non-negative matrix factorization with mixtures of local dictionaries and activation aggregation[C]//Proc. of the IEEE International Conference on Acoustics, Speech and Signal Processing, 2016: 2259-2263.
GIANNOULIS P, POTAMIANOS G, MARAGOS P. Multi-channel non-negative matrix factorization for overlapped acoustic event detection[C]//Proc. of the 26th European Signal Processing Conference, 2018: 857-861.
LI X Y, CHEBIYYAM V, KIRCHHOFF K. Multi-stream network with temporal attention for environmental sound classification[C]//Proc. of the Interspeech, 2019: 3604-3608.
KONG Q, CAO Y, IQBAL T, et al. Cross-task learning for audio tagging, sound event detection and spatial localization: Dcase 2019 baseline systems[EB/OL]. [2021-05-28]. http://arxiv.org/abs/1904.03476v3.
MCDONNELL M D. Training wide residual networks for deployment using a single bit for each weight[EB/OL]. [2021-05-28]. http://arxiv.org/abs/1802.08530.
MESAROS A, HEITTOLA T, DIMENT A, et al. DCASE 2017 Challenge setup: tasks, datasets and baseline system[C]//Proc. of the Detection and Classification of Acoustic Scenes and Events Workshop, 2017: 85-92.
WANG H L, ZOU Y X, CHONG D D. Acoustic scene classification with spectrogram processing strategies[C]//Pro. of the Detection and Classification of Acoustic Scenes and Events Workshop, 2020.
WANG C, SANTOSO A, WANG J. Acoustic scene classification using self-determination convolutional neural network[C]//Proc. of the Asia-Pacific Signal and Information Processing Association Annual Summit and Conference, 2017: 19-22.
DANG A, VUT H, WANG J. Acoustic scene classification using convolutional neural networks and multi-scale multi-feature extraction[C]//Proc. of the IEEE International Conference on Consumer Electronics, 2018.
Feature extraction based on the non-negative matrix factorization of convolutional neural networks for monitoring domestic activity with acoustic signals
... 为验证联合优化算法的实际效果, 将SNMF特征与TUT2017数据集的官方基线系统[27]、无监督NMF特征、以对数声谱图为基础提取的TNMF特征[11]、CQT特征与LM特征进行对比.其中, NMF特征和SNMF特征的特征维数K=256.为保证所有特征能够拥有适合其自身特点的分类器, 令NMF与SNMF特征的分类器为CNN10模型, TNMF特征的分类器同文献[11], 而LM和CQT特征则选取在2020年声学场景和事件的检测与分类挑战赛(Detection and Classification of Acoustic Scenes and Events, DCASE)中表现优异的类VGGNet模型[28].获得的分类结果如表 4所示. ...
... =256.为保证所有特征能够拥有适合其自身特点的分类器, 令NMF与SNMF特征的分类器为CNN10模型, TNMF特征的分类器同文献[11], 而LM和CQT特征则选取在2020年声学场景和事件的检测与分类挑战赛(Detection and Classification of Acoustic Scenes and Events, DCASE)中表现优异的类VGGNet模型[28].获得的分类结果如表 4所示. ...
Deep convolutional neural networks and data augmentation for environmental sound classification



{kind=link}
{kind=link}